1. Introduction
In recent years, online shopping has become far more important than offline shopping for several reasons: it is more efficient, convenient, and cost-effective, and offers more product categories than offline shopping. Companies that sell multiple product categories emerge due to convenience and offer a variety of products at varying prices. These stores have become online malls [
1].
This has resulted in a massive increase in online shopping, and consequently in the number of online retailers. Competition increases as more online retailers enter the market. Therefore, companies must optimize their business strategies to compete with other companies in the e-commerce market.
While every company is attempting to remain one step ahead of the competition, they must ensure that they consider all variables that contribute to their long-term success. Customer lifetime value (CLV) is a critical factor that multi-category e-commerce businesses should leverage as a competitive advantage.
CLV is a metric used to assess a customer’s worth in a company. It is the customer’s net present value based on future transactions with the company [
2]. The CLV assists businesses in ranking customers based on their contributions to earnings. This can be used to develop and implement customer-level strategies to maximize lifetime profitability and lengthen lifetime duration. That is, rather than treating all consumers identically, the CLV helps the company treat each one differently based on their contribution.
Determining the CLV of a company’s customers is the first step toward implementing a customer-specific strategy. The CLV can be used to justify a company’s ongoing marketing and infrastructure upgrades. Businesses can use the CLV framework to evaluate which customers are most likely to generate the highest profit in the future, the elements that contribute to a higher CLV, and the ideal amount of resource allocation across multiple communication channels. The lifetime value of a customer is critical in determining their importance to online retailers. However, according to Kumar [
3], the CLV should not be the only factor used to determine which customers generate the most revenue for a company. Companies must consider other criteria that distinguish each customer to determine the genuinely valuable ones. Consequently, particular models and methodologies for predicting and evaluating CLV are necessary. According to the literature, CLV models come in a wide range of shapes and sizes [
2,
4]. However, our literature review revealed significant research gaps in this topic for multi-category e-commerce businesses.
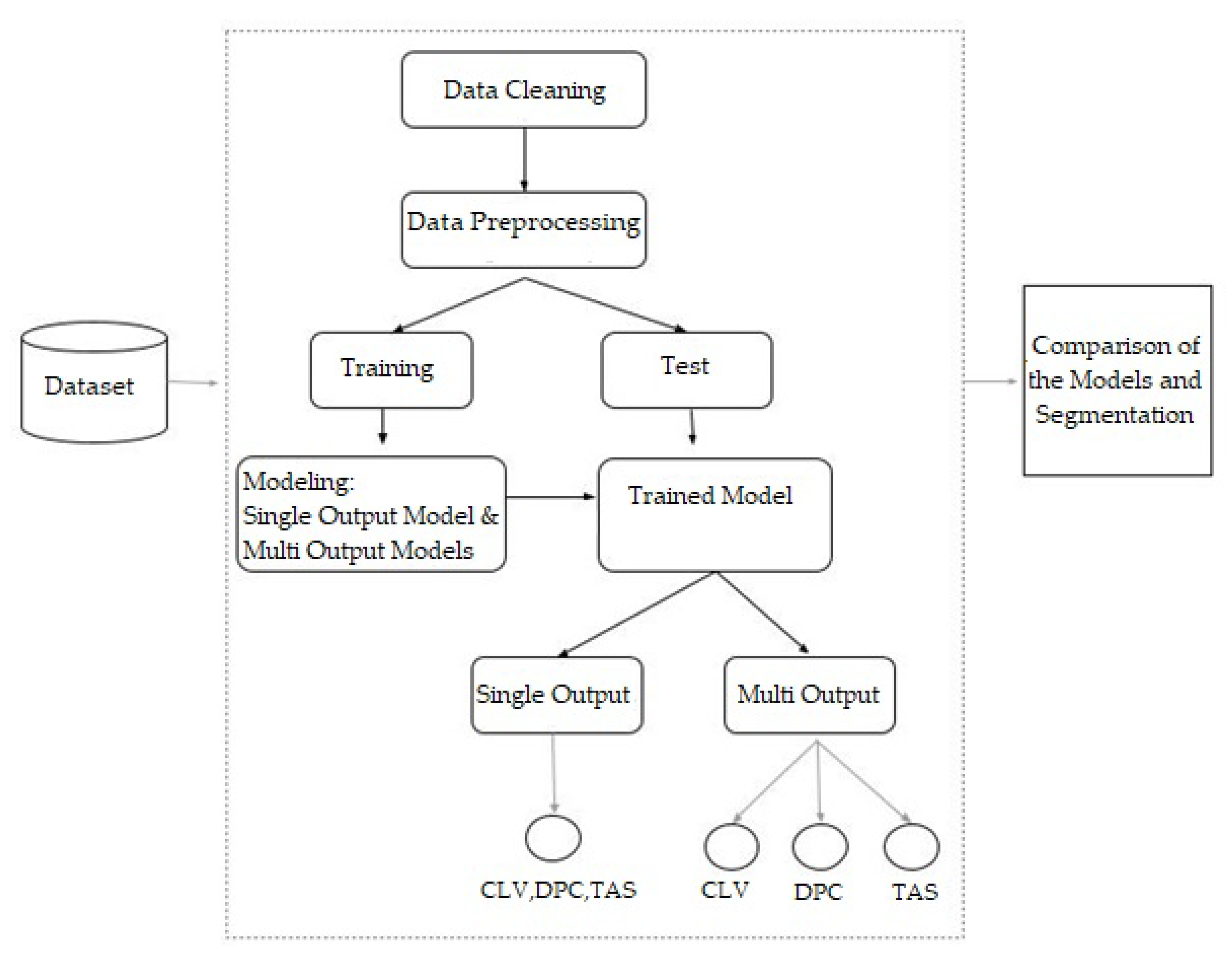
To address these research gaps and to assist multi-category e-commerce retailers in handling every area of CLV for their businesses and gaining a competitive advantage over other firms, we propose a novel 360° framework for CLV prediction and customer segmentation. We separated the framework into four components to answer the following four questions:
Does forecasting CLV along with other variables better predict customer value and segment consumers than predicting CLV alone?
Which algorithm is the best to use while predicting additional output features along with CLV?
How to interpret the deep neural network (DNN) model results?
Which customers will be the most profitable in the future for multi-category e-commerce companies?
The remainder of this paper is organized as follows.
Section 2 presents a sample of literature on this topic.
Section 3 discusses the details of the proposed framework, models utilized in this study, the data used, the models’ explainability, and how the outcome measures can be used to segment users and design customer-centric strategies. In
Section 4, the results are discussed. Finally, in
Section 5, the research conclusions, problems, and future study recommendations are discussed and presented.
2. Literature Background
Customers are at the heart of a company’s marketing efforts as they not only create revenue, but also boost the company’s market worth. Kotler [
5] stated that customer relationship management (CRM) is an illustration of how marketing emphasizes the interconnectedness of all processes and activities involved in the production, communication, and provision of value to consumers.
According to Ryals et al. [
6], CRM efforts are primarily designed to retain current customers, develop long-term relationships, and attract new ones. The calculation and usage of CLV are critical in this process because they allow organizations to group their customers and identify those who generate the most value over time [
7].
Jasek et al. [
8] stated that with the growth of technology and online shopping in recent years, conventional patterns in relationship management, such as brand equity, transactions, and product centricity, have shifted to a customer-centric strategy in which the customer is a valued asset of the organization. According to Heldt et al. [
9], companies have become more customer-centric, with the inclusion of a customer perspective in the analysis of anticipated revenues, which were formerly forecasted primarily based on expected product sales. Regardless of the importance of this new customer-oriented strategy, the product adaptability perspective should not be disregarded. Even when a customer-centric approach is critical, businesses require their products to fulfil consumers’ needs. Most managers want to analyze and make decisions based on both product (and brand) and consumer perceptions [
9].
According to [
10], both points of view are critical because branded products are marketed to customers and those customers purchase them. This means that combining product and customer evaluations would produce better results than conducting the two analyses separately.
Add-on selling is another important product-based strategy commonly used by businesses to maximize customer equity. Sales are boosted through the provision of additional items or product categories to customers and through providing more highly priced (enhanced) products or a greater supply of the same product; this common practice helps to increase customer spending [
11]. This is especially important for multi-category e-commerce companies. It enables the end-user to find all their needs on the firm’s website. They become more loyal to the company and boost their spending and CLV proportionately. Switching costs are significant when customers buy different products from an online retailer selling multiple product categories [
12]. Customers may be less likely to visit other retailers, especially when they find everything they are looking for on one website [
12].
Businesses must understand the quality of their customers, which best explains why one is more valuable than the other. According to [
13], this condition can be influenced by several circumstances. The three variables considered are worth examining—the extent to which consumers make cross-purchases, time between transactions, and number of product returns. The number of distinct product categories that customers purchase indicates the degree of cross-buying, which is an important aspect for CLV prediction. As proof, Reinartz et al. [
14] found that customers shopping within only one category have a lower CLV compared to multi-category shoppers. In addition, a study of catalogue retailers found that customers increased their CLV by an average of 5% for each add-on product category they purchased.
This is also a crucial metric for determining a customer’s worth, as purchasing a wide range of products from the same company demonstrates loyalty, and loyal customers spend more during their lifetime according to [
12].
Consequently, we hypothesize that distinct product category (DPC) is a significant element in determining which customers are the most valuable and should also be predicted as an additional output while predicting CLV.
Separately, it was noted in [
13] that there is an inverted U-shape in the effect of time between purchases on the longevity of earnings. Customers with a moderate but steady inter-purchase time between consecutive purchases may have a longer period of profitability than other customers.
In this study, we also consider inter-purchase times and calculate the trend in amount spent (TAS) with each succeeding purchase, using the inter-purchase time to determine how customers’ transaction trends evolve.
Although considering information on the product category sold and the trends regarding the amount spent with each subsequent transaction are significant practices when determining high-value consumers, many CLV-related studies have failed to consider these factors [
11]. As a novel approach, we created these two features as additional output features to our model and introduced them to the literature.
CLV prediction has received considerable research interest, and numerous accessible models are available. For decades, the statistical modelling of customer lifetime value has been explored. Due to insufficient data, early models were typically limited to adapting basic parametric statistical models, such as the negative binomial distribution (NBD) model of Morrison et al. [
15] and the Pareto/NBD model. The Pareto/NBD model is a classic recency, frequency, and monetary (RFM) model that is widely used for calculating the CLV, concentrating exclusively on the number of purchases made over a lifetime [
16,
17,
18,
19].
Probability models have been extensively utilized for CLV prediction; however, as technology advances, large-scale e-commerce platforms arise, and businesses begin to collect and store more data. This has drawn the attention of machine learning (ML) specialists. Recent studies have shown that ML-based CLV models can outperform probability models [
20,
21,
22]. ML models, unlike conventional probability models, can integrate a large number of parameters or features and thus might produce better results with greater precision. For instance, a two-stage Random Forest model was used to predict the CLV of all users of e-commerce sites with the same model [
20,
21]. Sifa et al. [
23] compared Random Forest, Decision Tree, and DNN algorithms. Malthouse and Blattberg [
24] employed a neural network to predict CLV. Moro et al. [
25] used a neural network, SVM, logistic regression, and Decision Tree (DT) to predict the success of marketing measures undertaken by a business. They discovered that the NN performed better than the other approaches. Wang et al. [
22] employed a DNN with a new loss function, claiming that the DNN with the ZILN loss function outperformed the other models.
To our knowledge, no studies have been undertaken in which researchers used multi-output prediction models to forecast CLV and other related features to segment users. According to [
26], most classical machine learning algorithms are designed for single-output prediction, which is a time-consuming task because of the requirement for separate training processes for each output and the low performance of the models. In addition, these methods exhibit a significant degree of nonlinearity between the input and output, indicating that their robustness, predictability, and adaptability can be enhanced.
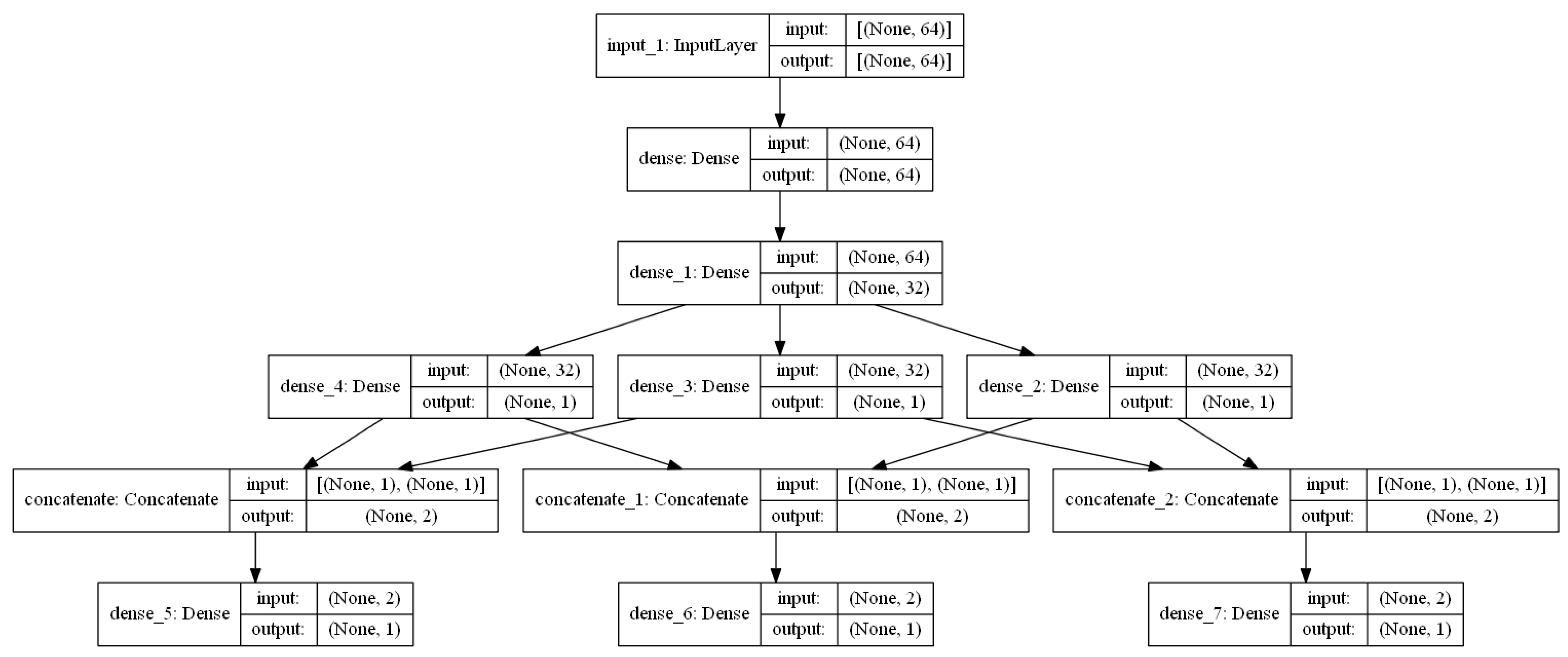
Developing a single neural network model that can predict multiple outputs from the same input features is a straightforward strategy. These models are simpler to create and test than managing one single-output neural network model for each output feature separately. Authors in [
26] suggested a multi-output deep neural network (DNN) technique to address these challenges, which successfully predicted their two output variables simultaneously. They ran multiple experiments comparing single-output ML models to multi-output ML models, and the suggested multi-output model outperformed all the other single-output models.
Other studies have used the computer science approaches outlined above to model CLV directly. However, to our knowledge no studies exist that predict CLV and other output features together.
In this study, we tested our data with a multi-output DNN model, in which we predicted three outputs–CLV, DPC, and TAS–and compared the results with the baseline single-output DNN model where we built one for each output separately. Additionally, to prove the superiority of the multi-output DNN models over other ML models, we selected Random Forest and Decision Trees. These two models have been used multiple times as single-output models to predict CLV. Thus, we wanted to compare the multi-output DNN model with the multi-output versions of Random Forest and Decision Tree algorithms.
DNNs are incredibly accurate; however, because they are black-box models, it has been difficult for some firms to embrace them. Users are unaware of the underlying logic and internal dynamics of these models, which is a significant drawback because it prohibits a person from verifying, interpreting, and comprehending a system’s thinking and how certain decisions are reached. XAI is an AI topic of research that is designed to interpret complex models and focuses on understanding ML models and interpreting their outcomes. Numerous methods have been proposed to accomplish this goal, however, many of them suffer from an inherent flaw: they lack theoretical underpinning, except for the SHAP method developed by [
27]. According to [
28], SHAP combines the benefits of the Shapley values [
29] and LIME [
30] by creating Shapley values for the conditional expectation function of the original model. The Shapley values are based on game theory. When a feature is included in the “coalition,” its importance is defined as its average contribution to the variance. The significance of a variable is assessed by averaging the (absolute) SHAP values overall observations, according to [
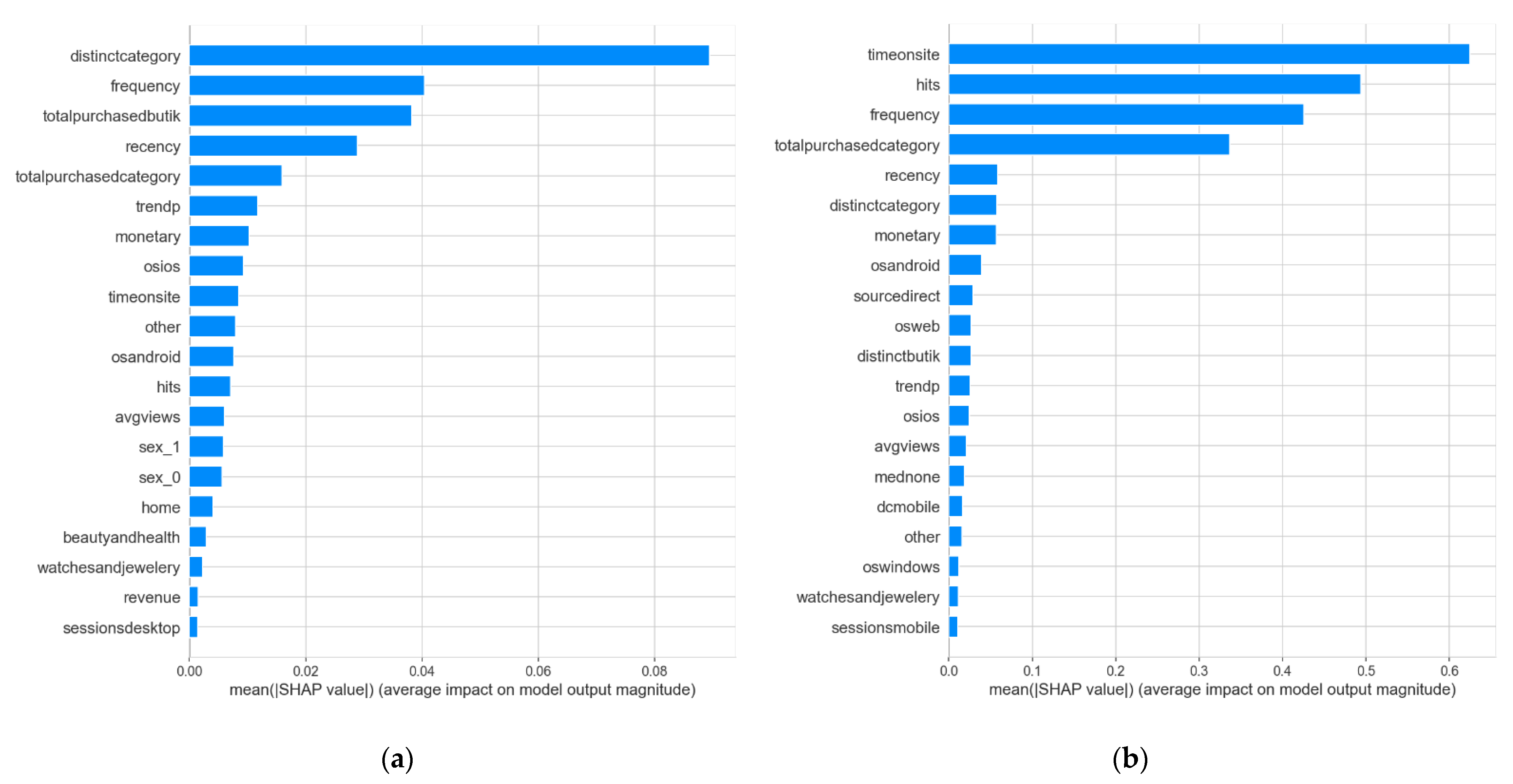
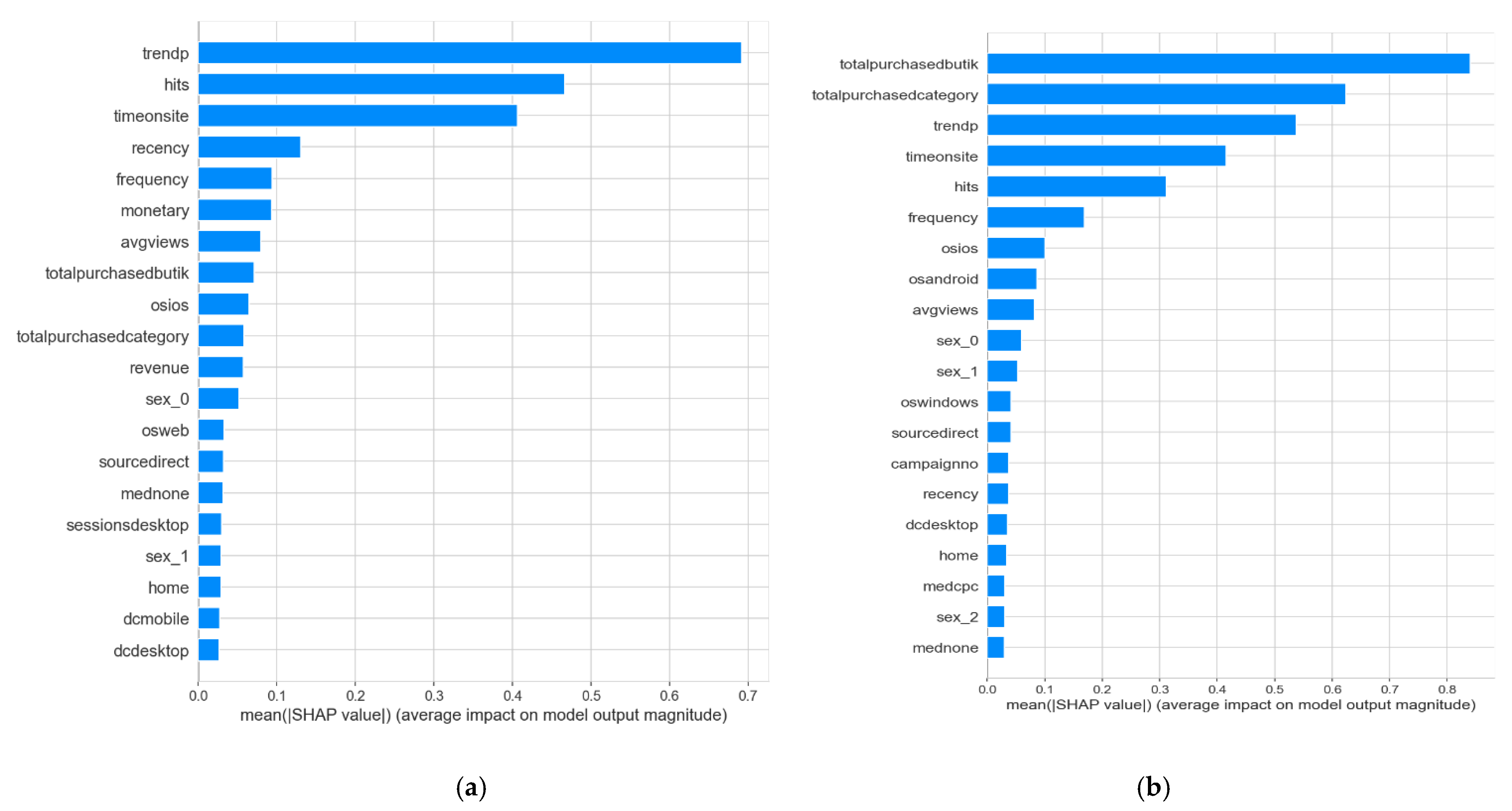
31]. Furthermore, no work has employed XAI for DNNs to determine the relevance of marketing features specific to CLV prediction, which makes our study unique in this area.
Finally, this study also aims to help businesses determine the importance of each customer. Management can create customized customer strategies by segmenting customers into different groups. CLV-based segmentation has been investigated for several years [
3,
7,
32]. In our scenario, we will not only separate customers based on CLV, as in earlier studies, but also based on DPC and TAS. In this study, k-means clustering was performed to segment customers.
Predicting trends and separate product categories are additional essential subjects in this study, as we aim to present a 360° framework that includes every area of CLV prediction to focus on a more profitable group of high-value customers. We utilize a multi-output model instead of separately predicting each feature. To the best of our knowledge, a multi-output model for predicting extra factors together with CLV and determining the user segment based on these outputs has never been examined, nor have the results been projected as additional CLV outcomes.
Contribution to the Literature
Using the 360° framework we introduce, our contribution to the literature is as below:
The two new output features–namely DPC and TAS, created and added to the model for prediction in addition to CLV–allow multi-category e-commerce companies to focus on strategies that will bring them more valuable customers. CLV should not be the only indicator for determining a customer’s worth, and predicting CLV, DPC, and TAS together is important to understand the actual high-value customers as it increases the accuracy of the results.
The multi-output DNN model is suggested and tested to take advantage of a more robust model that is easy to maintain and better in terms of capturing the relationships among the three outputs–CLV, DPC, and TAS–against to build a single-output model for each output separately or against the commonly used Decision Tree (DT) and Random Forest (RF) algorithms.
XAI was used for the first time while predicting CLV to interpret the multi-output DNN model results to explain the feature importance details and increase user confidence in DNN models that were previously regarded as black-box models.
Finally, customer segmentation is conducted based on the three output features instead of using only the CLV. Segmentation based on the combined results of the three outcomes provides a useful guide for multi-category e-commerce businesses to focus on the right customers and define their strategies accordingly.
4. Results and Evaluation
The purpose of this study was to compare the prediction ability and quality of the proposed multi-output DNN model to a single-output DNN model, multi-output DT, and multi-output RF models using statistical metrics. In this section, we present the results for each model for the multi-category e-commerce dataset using the MSE, MAE, RMSE, and Spearman correlation metrics.
Section 3.2 has already provided an overview of the evaluation measures and methodology used for comparisons.
Section 5 expands on these findings and their consequences.
Table 4 shows that the multi-output DNN model was the best-performing model based on every metric. The relationship between CLV, the distinct product category, and the trend in the amount purchased is important, providing better results when they are predicted together and being captured better with the proposed DNN algorithm.
We also aimed to show that the model could distinguish high-value customers from others, in addition to the above measures. The hit-ratio metric was used because we aimed to segment users of e-commerce companies into multiple categories, and the ability to distinguish high-value users is critical when predicting multiple outcomes with the same model. Donkers et al. [
50] proposed this hit-ratio measure, which is the percentage of consumers who’s anticipated CLV is the same as their genuine CLV. If the most valuable 20% of customers have a CLV above a certain amount, the hit-ratio determines how many of these customers have a predicted CLV above that amount. An ordering-based hit-ratio was also considered in [
24]. Chiang and Yang [
51] also evaluated the performance of the CLV prediction model using the hit-ratio.
First the hit-ratio of the multi-output DNN model, that is, the percentage of properly predicted observations, was compared to the hit ratio of the single-output DNN model, multi-output DT, and multi-output RF models in this study. The findings regarding the hit-ratios for the CLV, DPC ratio, and TAS metrics are shown separately in
Table 5.
Each of the three outputs was calculated by comparing the projected and actual top 20% of customers. The hit-ratio obtained for the multi-output DNN model performed better across all three outcomes than for each model alone, as shown in
Table 5. CLV exhibited the highest hit-ratio, followed by the distinct product category ratio and trend prediction for the amount spent. Specifically, 29% of the 20% comprising the most profitable customers (the top 20%) could not be identified using the multi-output DNN model for CLV. With a 71% accuracy rate, the multi-output model performed well.
The results were lower for the distinct product category purchase ratio and the trend in the amount spent with hit ratios of 64% and 41% for the multi-output model projections for the DPC and TAS output predictions, respectively.
The single-output DNN model, however, scored worse than the multi-output DNN model in predicting the percentage of customers with a true CLV, DPC, and TAS in the top 20% based on the calculated numbers than the predicted CLV, DPC, and TAS, which was likewise in the top 20% based on the projected CLV, DPC, and TAS. The hit ratios for the single-output models’ CLV, DPC, and TAS measures were 70%, 30%, and 28%, respectively. However, on the other hand, the single-output DNN performed better compared to the multi-output DT and RF in terms of CLV prediction.
Second, we chose this hit-ratio criterion to compare our proposed model results with those of existing studies that utilized the same criterion, such as [
24,
51]. Malthouse and Blattberg [
24] developed a hit-ratio rule (20–55) for CLV prediction. They sorted the CLV values and divided all clients into four equal-sized groups based on their actual CLV. They replicated this process for the predicted CLV values. Then, the hit ratio was calculated as the proportion of consumers whose anticipated CLV and their actual CLV groups match. They found that about 55% of the actual top 20% will be misclassified. Chiang and Yang [
51] also used the hit ratio to evaluate their model prediction accuracy for CLV. They made a comparison between the predicted top 20% of customers and the actual top 20% of customers, and 35% of the top 20% of most profitable customers (top 20%) could not be identified with their CLV prediction methodology. Their study outperforms other studies with a 35% misclassification ratio. Based on these results, our multi-output DNN model’s hit ratio for the CLV output–which has a 29% misclassification rate–is quite competitive, compared to both Malthouse and Blattberg’s [
24] and Chiang and Yang’s [
51] studies. A comparison between our proposed model and the two previous studies can be seen in
Table 6.
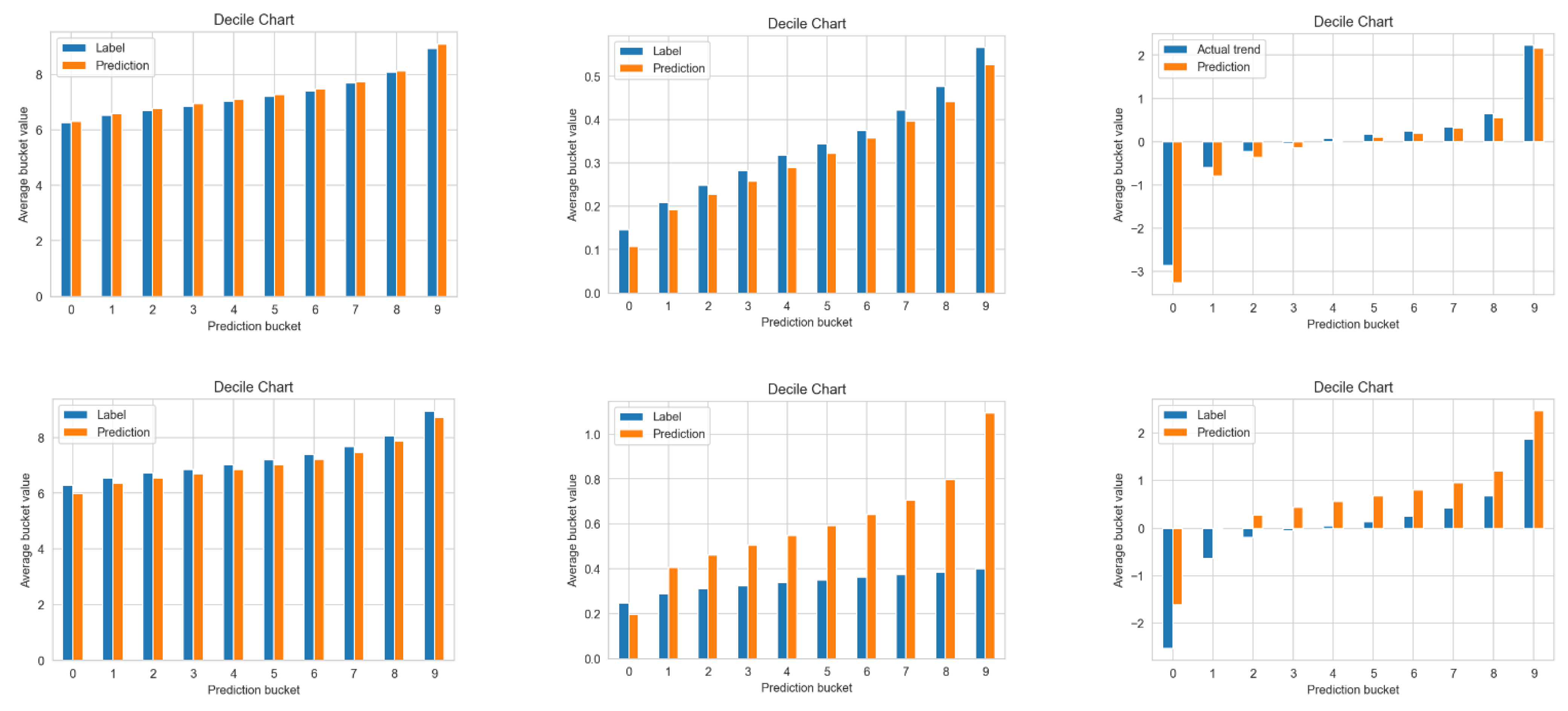
We also added calibration plots (decile charts), which are graphs of the goodness of fit that illustrate the anticipated probability and the fraction of positive labels [
22]. According to Wang et al. [
22], for example, if we predict that 20% of customers will be high-value customers, the observed frequency of high-value customers should be approximately 20% and the predictions should correspond to the 45° line.
We used decile charts to plot the labels of forecasts by decile and compared the average prediction and average label for each decile of the forecasts.
The predicted mean for each prediction decile in a properly calibrated model should be close to the actual mean.
Figure 3 illustrates the model calibrations for each of the three outputs for the best performing multi-output DNN model and the baseline single-output DNN models. The projected CLV values from the multi-output DNN model were extremely similar to the actual values, as indicated by the charts. The DPC forecasts for the top and bottom 10% of the higher ratios for the multi-output model deteriorated. However, for the DPC, the predictions of the single-output DNN model were higher than the actual values. The trend had negative values, stable values near zero, and positive values. Model calibration for the trend was poor for both the single- and multi-output DNN models, particularly for the single-output and for the top and bottom 10%. However, the predicted mean from the multi-output DNN model for the remaining variables was close to the real mean for the trend output variable.
4.1. Marketing Segmentation Strategies
According to [
28], CLV prediction expresses the total value of each customer. This helps companies because it enables them to identify specific customers regarding the target. However, to devise a marketing plan, companies must obtain knowledge about several different consumer groups rather than just one. As a result, it is important to group data into clusters or segments, which makes it easier to build marketing strategies.
Customers must be treated uniquely in order to manage a profitable customer relationship, and it is critical to consider how to allocate resources, choose customers, analyze purchase sequences, and acquire and retain the right customers in each segment. Companies must first understand the key characteristics that distinguish each group. This explains why some customers are more profitable than others, according to [
3].
According to [
3], firms want to know how much their customers are worth over time and what factors they can influence to increase their value. Reinartz and Kumar [
14] discovered aspects of the duration of consumer lifetime profitability. Feature exchange and customer diversity drive profitable lifespans. Customer–company exchange characteristics can be used to identify and describe customer–firm exchanges, whereas demographic factors capture customer variability. Companies’ mailing efforts and customer spending levels have all been identified as helpful drivers of profitable lifespan length in both the B2C and B2B contexts.
Knowing the factors that contribute toward the development of a lucrative life cycle enables managers to take tangible steps to enhance drivers and, as a result, increase customer profitability. Using the antecedents to the profitability life cycle linked to a specific customer, managers can also identify customers who may be valuable in the future and determine when it is time to stop investing in those consumers. Profitable lifetime driver/customer lifetime values (CLVs) are an important component of any marketing plan [
3].
According to [
32], several CLV segmentation strategies have been proposed, but they can be broadly classified into three categories: category one is segmentation using only CLV values; category two is segmentation using both CLV values and other data, such as purchase history; and category three is segmentation using only CLV components, such as current value, potential value, and loyalty. In our case, similar to Category 2 above, we use other information (the dynamic product category ratio and the trend in the amount spent) in addition to CLV as our drivers to segment users of multi-category e-commerce companies.
Other variables, as mentioned above, can be used by multi-category e-commerce companies to categorize their visitors. The purchased product category is a critical variable for businesses that sell a variety of products. Customers who have recently acquired an additional service in addition to what they previously purchased are more inclined to purchase even more, according to [
44]. Another study of a catalog retailer found that the CLV increased by 5% on average for each extra product category purchased by a consumer [
13]. The distinct product category purchase ratio was one of our output variables because, in this study, we collected data from a multi-category e-commerce retailer that sells items in 10 distinct main product categories (Apparel, Kids and Baby, Beauty and Health, Shoes and Bags, Watches and Jewelry, Home and Furniture, Electronics, Sports and Outdoor, Grocery and Multi). The product price range of this retailer was very wide. This is because the retailer was selling low-priced items and luxury/premium and other highly priced product categories such as electronics.
Due to this wide price range, a challenge is that if the retailer segments its customers according to the CLV signals only, because only the total amount spent by a certain customer is considered:, (e.g., a customer who has purchased only one expensive item could be categorized as “high-value customer”, while a customer who purchased from multiple categories and still spent the same total amount will also be categorized as “high-value customer”, but this categorization will be missing one important factor), the person spending the same amount of money in different categories will actually have a higher value to the retailer. This is because they will be more loyal to the retailer in the future. Therefore, segmenting customers only according to the total amount spent at a certain time misses customers who are potentially more loyal and are therefore higher valued customers. Due to the reasons above, our premise was that a consumer who buys products from numerous different categories is a more valuable customer, because buying from multiple categories shows loyalty and switching costs are significant when customers buy products from multiple categories in one store; therefore, they may be less likely to visit other stores [
12].
Another consideration is the trend in terms of the money spent. A consumer’s worth can be determined by the amount of money they spend. However, the amount spent on each transaction also plays a significant role in assessing a customer’s value. Each purchase may result in an increase in a user’s spending, culminating in a large overall value. Additionally, if we focus exclusively on the amount spent in dollars, a customer who spends a lot on their initial purchase but then spends less on subsequent purchases might also be considered a valuable customer. The value and segmentation of a customer may fluctuate because of an increasing, decreasing, or stable trend.
In our study, K-means clustering was used to create groups based on the actual CLV, DPC, and TAS values. The dataset was separated into five clusters based on the elbow method.
Table 7 shows the final cluster centers.
Cluster 1, representing 30% of customers, included those with the highest total amount of spend and second highest distinct product category ratios but with a negative purchase amount trend. These customers are expected to spend significantly more than average as they make purchases from a variety of unique product categories, although their spending will likely decrease over time. Thus, to retain these important customers, multi-category e-commerce enterprises may employ retention-based techniques and strategies that appeal to them.
Cluster 4 represents the majority of customers with close to 45% of the total customers, including those with a moderate amount of spend, lowest degree of different product category purchases, and a stable spending pattern. This is the company’s core group, and numerous methods, such as discounts, should be implemented to ensure that Cluster 4 does not churn. The multi-category e-commerce business must develop a strategy to attract these types of customers by utilizing cross- and upselling methods to boost the specific product category from which each user is purchasing, resulting in a higher average order value. Companies can generate more compelling up- and cross-selling opportunities for targeted customers through further analysis. For the upsell and cross-sell opportunities, companies can use these results and then leverage recommendation systems by using a relatively new method–the latent factor-based approach (LF) [
52].
Cluster 5 represents 23% of customers. This set of customers spends less and purchases from different product categories with the highest DPC ratio, but they have the most stable spend trend. With appropriate methods, they can spend more and grow their purchase trend with each subsequent purchase because they are more loyal than other clusters based on the DPC ratio.
Finally, Cluster 2 and Cluster 3 are 2% of the overall customers in total. They have the second and third highest average spend, respectively. Trend values for these two clusters are the highest and lowest. Cluster 2 has the highest increasing trend and shows a low amount at the first purchase and then a significant increase in the respective purchases. On the contrary, Cluster 3 has the highest decreasing trend, which shows a high amount at the first purchase and then an important decline in the consecutive purchases. These two groups of customers may be more expensive to retain than Clusters 1, 4, and 5; thus, multi-category e-commerce businesses must conduct a cost-benefit analysis of these customers. They may wish to assign resources to Clusters 1, 4, and 5 rather than to these two groups (Cluster 2 and Cluster 3).
The results reported in this ectionn demonstrate that the multi-output DNN model consistently outperformed the single-output DNN model, multi-output DT model, and multi-output RF model across a wide variety of evaluation metrics, and hence is suitable and reliable for multi-category e-commerce firms. Furthermore, segmentation based on the outcomes of the multi-output DNN model can provide a useful guide for multi-category e-commerce businesses.
5. Discussions and Conclusions
In this study, we developed a new 360° framework for CLV prediction specific to multi-category e-commerce companies so that they can address all aspects of CLV prediction and user segmentation. Providing a solution to this issue may result in greater revenue because companies can focus their attention on certain consumers, for example, by allocating additional marketing resources to them. Customer behavior data from a multi-category e-commerce company was used. Our study was motivated by four components.
The first is that we developed the proposed framework in addition to CLV to anticipate a distinct product category ratio (DPC) and a trend in the amount spent (TAS) as additional outcomes. CLV can be used to predict a company’s most profitable customers; however, this metric alone is insufficient for businesses that sell products across multiple categories. Therefore, we suggested predicting DPC and TAS along with CLV to increase the accuracy of CLV prediction and to segment customers of multi-category e-commerce companies more accurately.
The second component was to choose the best approach for predicting CLV for a multi-category business. We employed a multi-output DNN model that used the same inputs to predict many outputs to obtain predictions for multiple variables. This new approach has not been previously used for CLV prediction. This is a robust approach for companies that aim to construct and maintain ML models more easily, and is a better way to capture the relationships between output attributes.
The third component is the interpretation of the multi-output DNN model results to explain the feature importance details and increase user confidence in DNN models. According to [
54], interpretability is a prerequisite for the success of ML and artificial intelligence because, despite the high prediction accuracy, people would like to understand why a certain prediction was made and the rationale behind it.
The final component is to segment customers based on the proposed output features: DPC and TAS along with CLV (rather than using only CLV).
The findings of each phase are stated below, along with a model comparison and possible reasons for their performance.
We compared the performance of the proposed multi-output DNN model with the baseline single-output DNN, multi-output Decision Tree (DT), and multi-output Random Forest (RF) models. First, we employed performance measures–namely MAE, MSE, RMSE, and Spearman coefficients–to evaluate the models and found that the multi-output DNN model outperformed other models for all output variables. The results indicated that the DNN model, which predicted CLV, DPC, and TAS simultaneously, achieved reductions in the RMSE of up to 6%, 70%, and 7%, respectively, compared to separate single-output (CLV, DPC, and TAS) DNN modelling. In particular, DPC values showed significant improvements when predicted together. Additionally, when compared to the multi-output DT and RF algorithms, we achieved 21% and 7% reduction in the RMSE for CLV prediction, respectively. Furthermore, for these metrics, we used the hit ratio to demonstrate the capacity of the model to distinguish high-value customers from others. The multi-output DNN model resulted consistently well in forecasting the hit-ratio measure as well, with a 71% hit-ratio that has a 29% misclassification rate for CLV forecasts. According to the hit-ratio, the other two outcome variables–DPC and TAS–performed somewhat worse, at 64% and 41%, respectively, compared to CLV. Further, to construct an empirically valid and generally applicable model for predicting CLV for multi-category e-commerce companies, we compared the hit-ratio results with those of previous studies. When compared to that in [
24,
51], the performance of the multi-output DNN model was also found to be highly competitive. With this novel approach, we showed that the two new output features, DPC and TAS, are important metrics that improve the CLV prediction accuracy and must also be considered when focusing on initiatives that will bring in more valuable consumers.
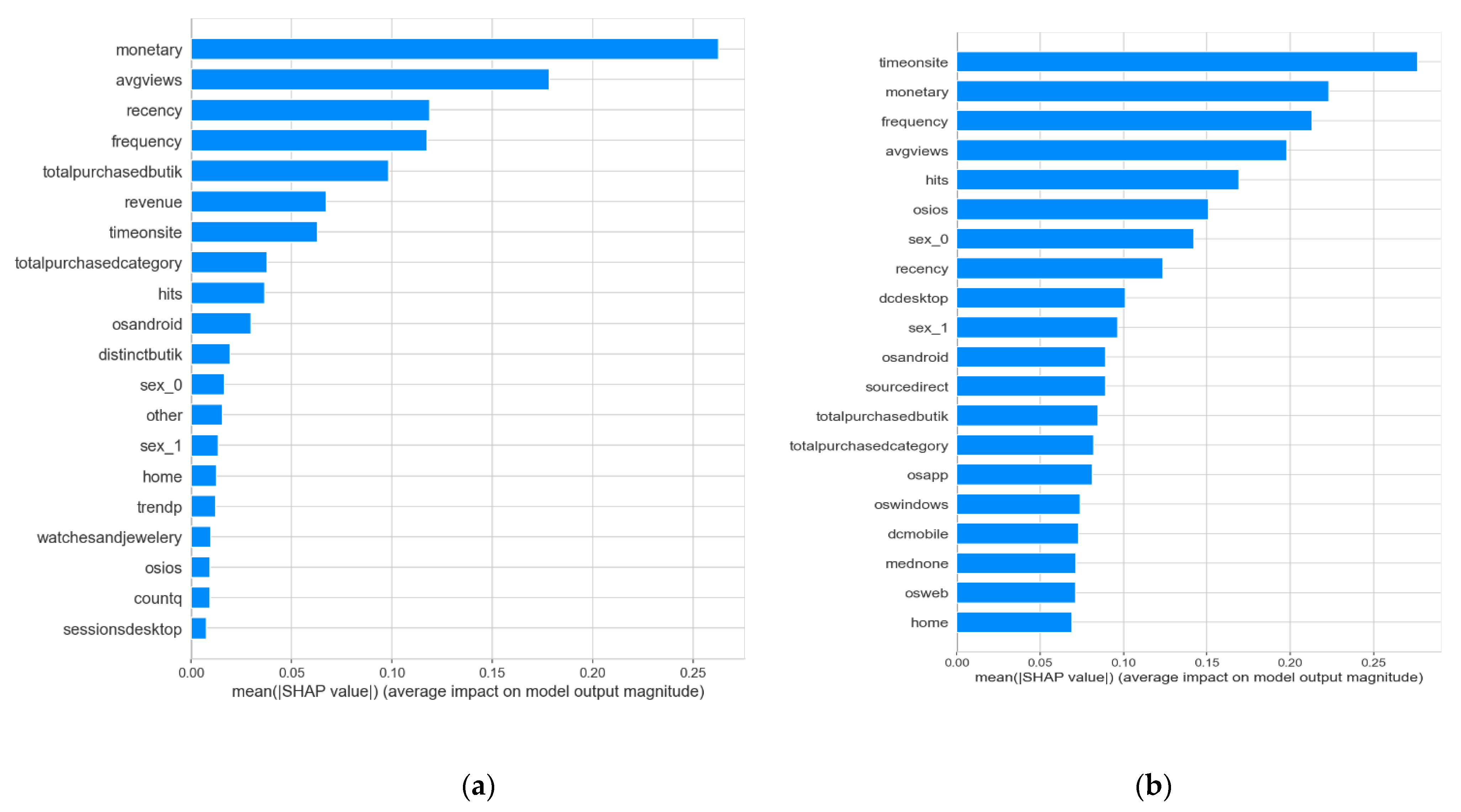
In terms of explainability, we used the Shapley values technique to build feature significance tables, which can provide management with excellent visualization and an emphasis on the key factors. For example, although time spent on the website was significant for each of the outputs, one of the most important aspects for the different categories appeared to be the separate sellers at which clients were shopping. As a result, concentrating on the seller variety might be a key indicator for increasing the number of unique product categories purchased.
Lastly, we showed that the projected outcomes of our multi-output DNN model can be used to segment clients. Our primary conclusion is that each cluster should have separate marketing strategies and be targeted separately. For instance, Cluster 1 clients were forecasted to have a high CLV and a highly distinct product category ratio, but a low spending trend. These clients can be targeted with up- and cross-selling tactics to increase their anticipated spending. Results also showed that customers spend more money while buying from a wider range of product categories. Purchasing from many categories is a form of loyalty and is directly connected with high spending, especially for multi-category e-commerce businesses. Therefore, we recommend that multi-category e-commerce businesses focus not only on CLV but also on product information when segmenting their customers.
Another important finding is that an increasing purchase trend is not always linked to higher spending. Cluster 1 had the lowest trend values, indicating that consumers who spent a large amount of money and bought products from various categories may reduce their spending over time if the management does not devise special strategies for this group. Meanwhile, Cluster 4 showed medium CLV, medium DPC, and a stable trend. These are the most important customers, and management must please them to avoid losing them.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





