1. Introduction
The exponential growth of social media such as Twitter and community forums has revolutionized communication and content publishing, but it is also increasingly being exploited for the spread of hate speech and the organization of hate activity. The term “hate speech” has been defined as “any communication that denigrates a person or group based on certain characteristics (called types of hate or classes of hate) such as race, color, ethnicity, gender, sexual orientation, nationality, religion or other characteristics” [
1]. An official EU definition of hate speech [
2] states that “it is based on the unjustified assumption that a person or a group of persons are superior to others; it incites acts of violence or discrimination, thus undermining respect for minority groups and damaging social cohesion.”
Hate content on the internet can create fear, anxiety and threats to the safety of individuals. In the case of a business or online platform, the business or platform may lose its reputation or the reputation of its product. Failure to moderate such content can cost the company in multiple ways: loss of users, a drop in stock value, sanctions from legal authorities, etc. A news article [
3] and several academic studies [
4,
5] indicate that during the recent COVID-19 crisis, there was a drastic increase in hate speech against people from China and other Asian countries on Twitter.
In many countries, online hate speech is a crime and is punishable by law. In this case, social media are held liable if they do not remove hateful content quickly. However, the anonymity and mobility that these media offer means that the creation and dissemination of hate speech—which can lead to hate crimes—occurs effortlessly in a virtual landscape that eludes traditional law enforcement. Manual analysis of this content and its moderation is impossible due to the enormous amount of data circulating on the internet. An effective solution to this problem would be to automatically detect and moderate hate speech comments.
In the EU, surveys and reports focusing on young people in the European Economic Area (EEA) region show an increase in hate speech and related crimes based on religious beliefs, ethnicity, sexual orientation or gender, as 80% of the respondents had experienced online hate speech and 40% had felt attacked or threatened [
6,
7]. The statistics also show that in the United States, hate speech and hate crimes have been on the rise since Trump’s election [
8].
There are many works on automatic hate speech detection (explored below in
Section 2), but most of them address hate speech in English, with much fewer works in French. Additionally, racial profiling is less investigated than hate speech, especially in French. Racism is also harder to detect because often it is conveyed implicitly with stereotypes, as shown in [
9,
10]. To breach this gap, we have collected, annotated and evaluated a new dataset for racist speech detection in French. Our contribution is multifold: (1) we introduce a new dataset for racist speech detection in French called FTR (French Twitter Racist speech dataset); (2) we evaluate this dataset with multiple supervised models and text representations for the task of racist language detection; (3) we perform experiments for extending the FTR dataset with general hate speech data in French; and (4) we perform cross-lingual evaluations of the explored representations and methods. Our dataset is derived from Twitter and is suitable for facilitating the detection of racism on Twitter. The cross-lingual experiments are motivated by a lack of resources for racist speech detection in general, and in French in particular. In the case of successful transfer learning, one may use annotated sets in English for training systems aimed at the analysis of French texts.
The paper is organized as follows.
Section 2 describes existing methods and datasets relevant to our goal.
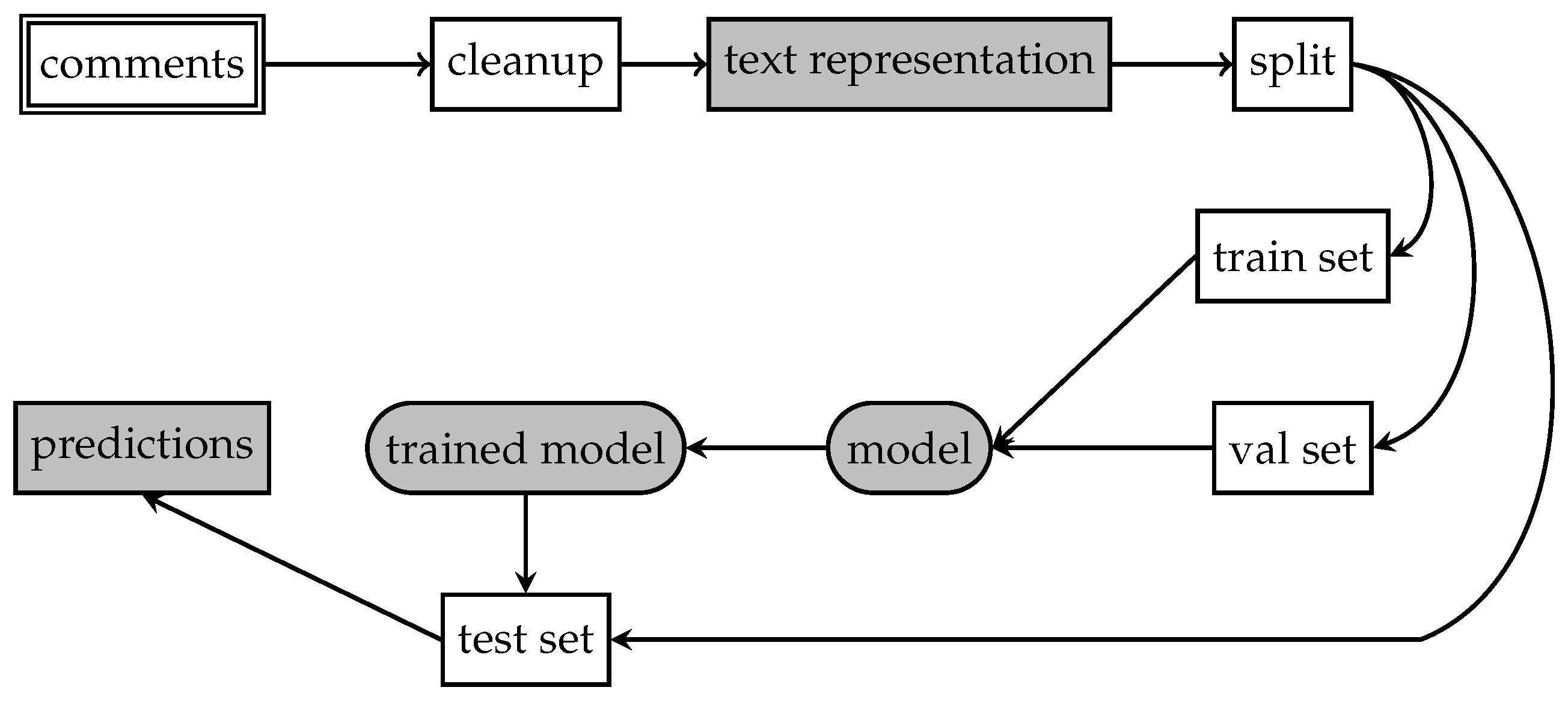
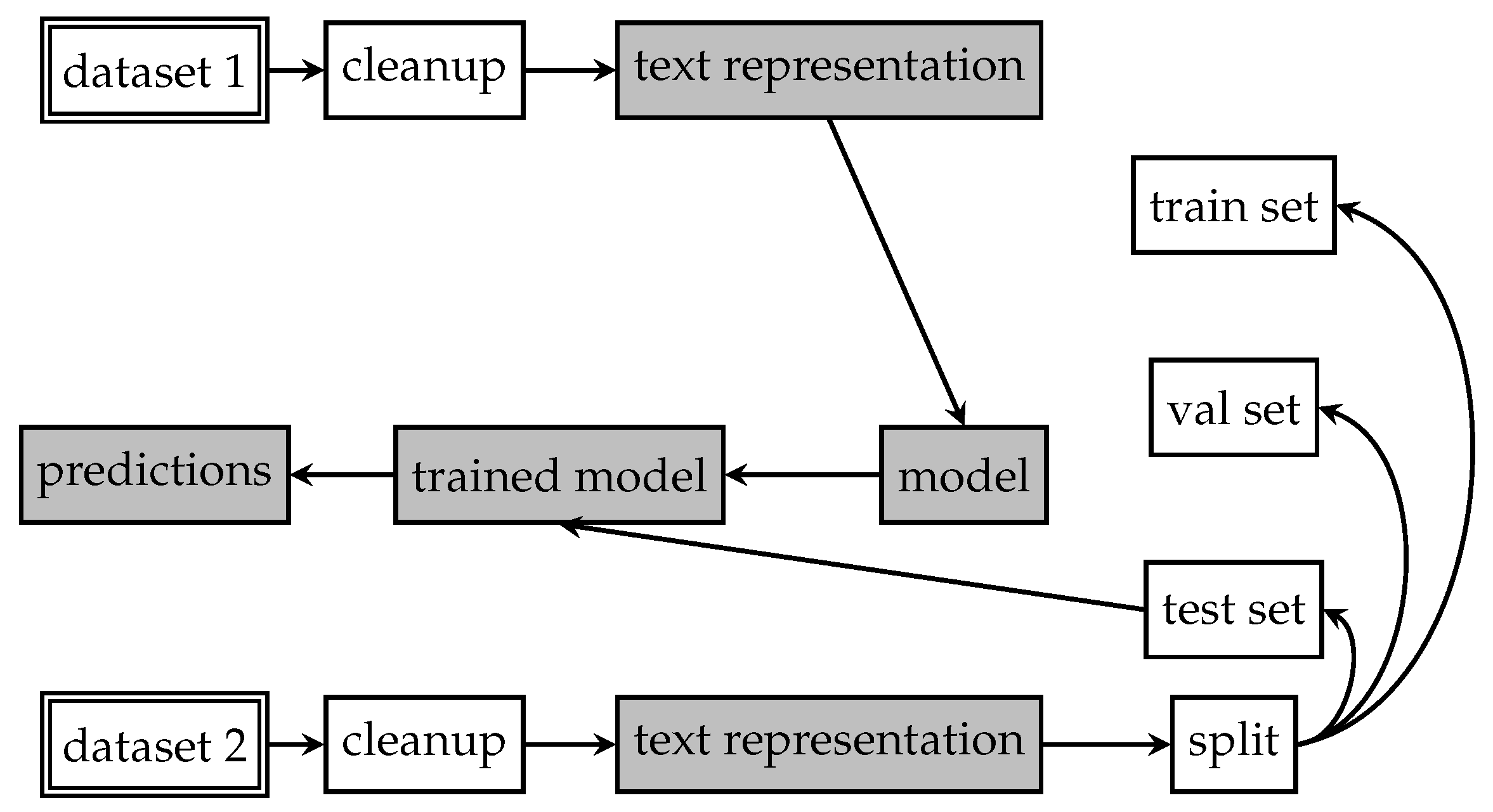
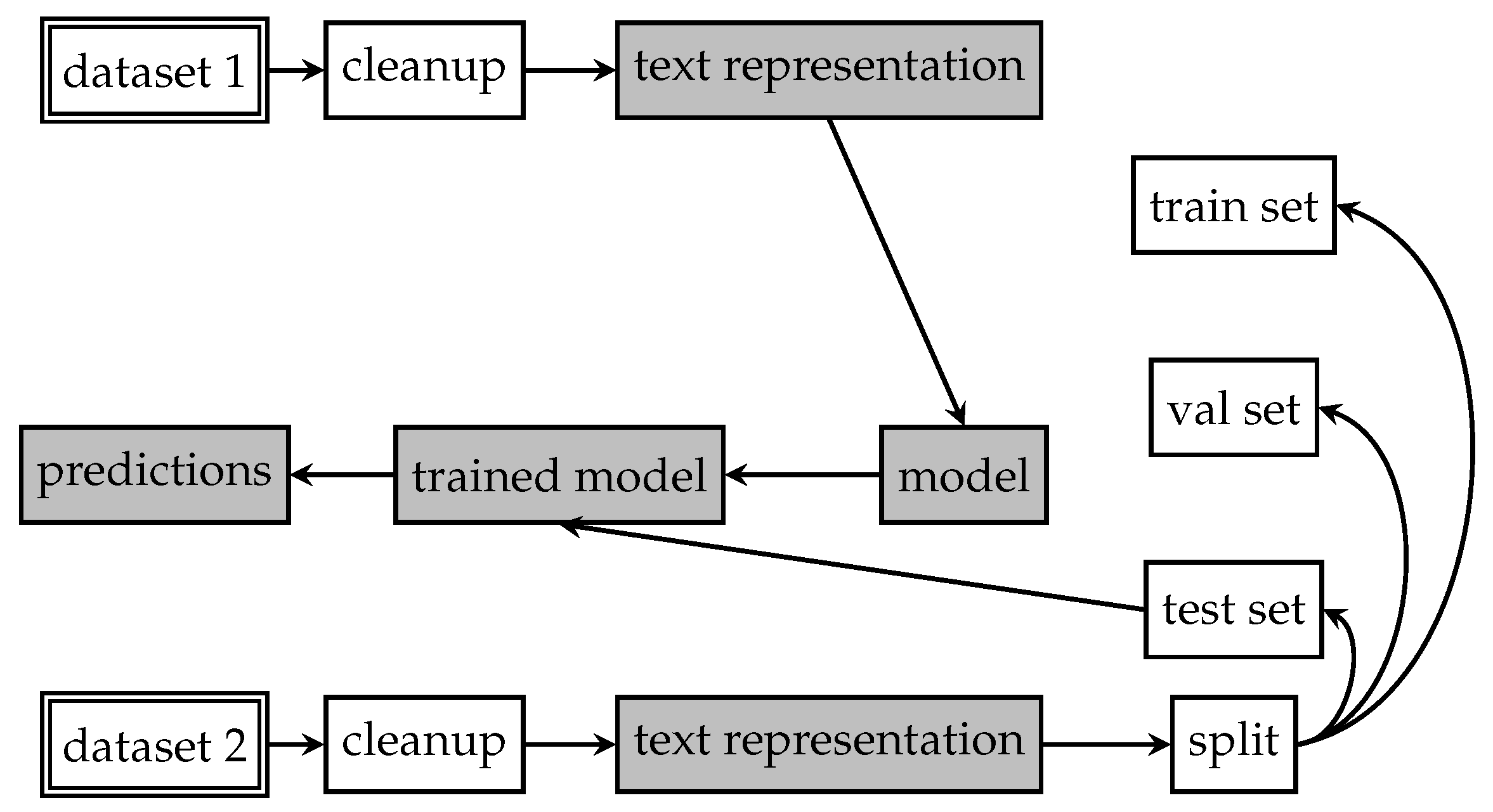
Section 3 describes the dataset and text representation and models used for its evaluation.
Section 5 contains the results of experimental evaluation.
Section 6 analyzes the evaluation results, and
Section 7 summarizes our findings.
2. Background
Automatic detection of hate speech is a challenging problem in the field of natural language processing. The proposed approaches for automatic hate speech detection are based on representing the text in numerical form and using classification models on these numerical representations. In the state of the art in this domain, lexical features such as word and character n-grams [
11], term frequency-inverse document frequency (tf-idf), bag of words (BoW), polar intensity and noun patterns [
12] are used as input features.
Recently, word embeddings have been used as an alternative to these lexical features. A multi-feature-based approach combining various lexicons and semantic-based features is presented by Almatarneh in [
13]. Liu used fuzzy methods in [
14] to classify ambiguous instances of hate speech. The notion of word embeddings is based on the idea that semantically and syntactically similar words should be close to each other in an n-dimensional space [
15]. The embeddings trained on a huge corpus of data capture the generic semantics of words. Word2Vec embeddings and CNN input n-character features were compared by Gambäck in [
16]. Djuric [
17] proposed a low-dimensional sentence representation using paragraph vector embeddings [
18].
Deep learning techniques are very powerful in classifying hate speech [
19]. The performance of deep learning-based approaches surpassed that of classical machine learning techniques such as support vector machines, gradient boosting decision trees and logistic regression [
20]. Among the deep learning-based classifiers, a convolutional neural network captures local patterns in the text. The deep learning-based LSTM [
21] model captures long-range dependencies. Such properties are important for modeling hate speech [
22]. Park [
23] designed a hybrid CNN by combining the word CNN and character CNN to classify hate speech. Zhang [
24] designed convolutional recurrent neural networks by passing CNN inputs to GRU for hate speech classification. Del Vigna [
25] showed that LSTMs performed better than SVMs for hate speech detection on Facebook. Founta [
26] used an attention layer with the recurrent neural network to improve the performance of hate speech classification over a longer text sequence.
The clear majority of the offensive detection studies deal with English, partially because most available annotated datasets contain English data. For example, SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval) was based on the Offensive Language Identification Dataset (OLID), which contains over 14,000 English tweets. The main findings of this task can be found in [
27]. SemEval-2019 Task 5: Shared Task on Multilingual Detection of Hate [
28] focused on detecting hate speech against immigrants and women (Task A) and detecting aggressive behavior in English and Spanish tweets (Task B). SemEval-2020 task 12: Multilingual Offensive Language Identification in Social Media [
29] offered three subtasks related to offensive language detection, categorization and target identification.
Since social media became the most popular multilingual communication tool worldwide, many researchers contributed to this area by developing multilingual methodologies and annotated corpora in multiple languages. For example, Arabic [
19], Dutch [
30], French [
31], Turkish [
32], Danish [
33], Greek [
34], Italian [
35], Portuguese [
36], Slovene [
37] and Dravidian [
38] languages were explored for the task of general offensive speech detection.
However, there are much fewer corpora dedicated to the study of racist speech, and even fewer of them are in French. The Hate Speech Dataset Catalogue [
39] contains two datasets in French only, COunter NArratives through Nichesourcing (CONAN [
40]) and the Multilingual and Multi-Aspect Hate Speech Analysis dataset (MLMA [
41]). The CONAN dataset is multilingual, and its French part contains 6840 comments, all of which are labeled Islamophobic. Therefore, it cannot be of help in detecting general racist content. The MLMA dataset contains 4014 comments, all of which are hate speech, with multi-class labels. Motivated by this shortage, we introduced our dataset containing annotated tweets written in French.
Author Contributions
Data curation, E.M.; Investigation, N.V. and E.M.; Methodology, N.V.; Software, N.V. and E.M.; Writing—original draft, N.V. and E.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Z.; Luo, L. Hate speech detection: A solved problem? the challenging case of long tail on twitter. Semant. Web 2019, 10, 925–945. [Google Scholar] [CrossRef] [Green Version]
- European Commission against Racism and Intolerance. ECRI General Policy Recommendation N. 15 on Combating Hate Speech; European Commission against Racism and Intolerance: Strasbourg, France, 2016. [Google Scholar]
- Coronavirus: Huge surge of hate speech toward Chinese on Twitter. The Federal. Available online: https://thefederal.com/ (accessed on 1 May 2022).
- Gover, A.R.; Harper, S.B.; Langton, L. Anti-Asian hate crime during the COVID-19 pandemic: Exploring the reproduction of inequality. Am. J. Crim. Justice 2020, 45, 647–667. [Google Scholar] [CrossRef] [PubMed]
- Ng, R. Anti-Asian Sentiments During the COVID-19 Pandemic Across 20 Countries: Analysis of a 12-Billion-Word News Media Database. J. Med. Internet Res. 2021, 23, e28305. [Google Scholar] [CrossRef] [PubMed]
- Pan-European Anti-Racism Network. ENAR Shadow Report 2006. Available online: https://www.enar-eu.org/shadow-reports-on-racism-in-europe-203/ (accessed on 1 May 2022).
- Wine, M. National monitoring of hate crime in Europe: The case for a European level policy. Glob. Hate 2016, 213–232. [Google Scholar]
- Williams, A. Hate crimes rose the day after Trump was elected, FBI data show. Wash. Post 2018, 23. [Google Scholar]
- Kambhatla, G.; Stewart, I.; Mihalcea, R. Surfacing Racial Stereotypes through Identity Portrayal. In Proceedings of the FAccT ’22: 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Korea, 21–24 June 2022. [Google Scholar]
- Sánchez-Junquera, J.; Chulvi, B.; Rosso, P.; Ponzetto, S.P. How do you speak about immigrants? taxonomy and stereoimmigrants dataset for identifying stereotypes about immigrants. Appl. Sci. 2021, 11, 3610. [Google Scholar] [CrossRef]
- Nobata, C.; Tetreault, J.; Thomas, A.; Mehdad, Y.; Chang, Y. Abusive language detection in online user content. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 145–153. [Google Scholar]
- Wiegand, M.; Ruppenhofer, J.; Schmidt, A.; Greenberg, C. Inducing a lexicon of abusive words–a feature-based approach. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LO, USA, 1–6 June 2018; pp. 1046–1056, Volume 1 (Long Papers). [Google Scholar]
- Almatarneh, S.; Gamallo, P.; Pena, F.J.R. CiTIUS-COLE at semeval-2019 task 5: Combining linguistic features to identify hate speech against immigrants and women on multilingual tweets. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 387–390. [Google Scholar]
- Liu, H.; Burnap, P.; Alorainy, W.; Williams, M.L. A fuzzy approach to text classification with two-stage training for ambiguous instances. IEEE Trans. Comput. Soc. Syst. 2019, 6, 227–240. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Gambäck, B.; Sikdar, U.K. Using convolutional neural networks to classify hate-speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017; pp. 85–90. [Google Scholar]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate speech detection with comment embeddings. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 29–30. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Mohaouchane, H.; Mourhir, A.; Nikolov, N.S. Detecting offensive language on arabic social media using deep learning. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 466–471. [Google Scholar]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep learning for hate speech detection in tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, WA, Australia, 3–7 April 2017; pp. 759–760. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Bodapati, S.B.; Gella, S.; Bhattacharjee, K.; Al-Onaizan, Y. Neural word decomposition models for abusive language detection. arXiv 2019, arXiv:1910.01043. [Google Scholar]
- Park, J.H.; Fung, P. One-step and two-step classification for abusive language detection on twitter. arXiv 2017, arXiv:1706.01206. [Google Scholar]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting hate speech on twitter using a convolution-gru based deep neural network. In Proceedings of the European Semantic Web Conference, Crete, Greece, 3–7 June 2018; pp. 745–760. [Google Scholar]
- Del Vigna12, F.; Cimino23, A.; Dell’Orletta, F.; Petrocchi, M.; Tesconi, M. Hate me, hate me not: Hate speech detection on facebook. In Proceedings of the First Italian Conference on Cybersecurity (ITASEC17), Venice, Italy, 17–20 January 2017; pp. 86–95. [Google Scholar]
- Founta, A.M.; Chatzakou, D.; Kourtellis, N.; Blackburn, J.; Vakali, A.; Leontiadis, I. A unified deep learning architecture for abuse detection. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30–3 July 2019; pp. 105–114. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval). In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 75–86. [Google Scholar]
- Basile, V.; Bosco, C.; Fersini, E.; Debora, N.; Patti, V.; Pardo, F.M.R.; Rosso, P.; Sanguinetti, M. Semeval-2019 task 5: Multilingual detection of hate speech against immigrants and women in twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation. Association for Computational Linguistics, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar]
- Zampieri, M.; Nakov, P.; Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Mubarak, H.; Derczynski, L.; Pitenis, Z.; Çöltekin, Ç. SemEval-2020 task 12: Multilingual offensive language identification in social media (OffensEval 2020). arXiv 2020, arXiv:2006.07235. [Google Scholar]
- Tulkens, S.; Hilte, L.; Lodewyckx, E.; Verhoeven, B.; Daelemans, W. A dictionary-based approach to racism detection in dutch social media. arXiv 2016, arXiv:1608.08738. [Google Scholar]
- Chiril, P.; Benamara, F.; Moriceau, V.; Coulomb-Gully, M.; Kumar, A. Multilingual and multitarget hate speech detection in tweets. In Proceedings of the Conférence sur le Traitement Automatique des Langues Naturelles (TALN-PFIA 2019), ATALA, Toulouse, France, 1 July 2019; pp. 351–360. [Google Scholar]
- Çöltekin, Ç. A corpus of Turkish offensive language on social media. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6174–6184. [Google Scholar]
- Sigurbergsson, G.I.; Derczynski, L. Offensive Language and Hate Speech Detection for Danish. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 3498–3508. [Google Scholar]
- Pitenis, Z.; Zampieri, M.; Ranasinghe, T. Offensive language identification in greek. arXiv 2020, arXiv:2003.07459. [Google Scholar]
- Poletto, F.; Stranisci, M.; Sanguinetti, M.; Patti, V.; Bosco, C. Hate speech annotation: Analysis of an italian twitter corpus. In Proceedings of the 4th Italian Conference on Computational Linguistics, CLiC-it 2017. CEUR-WS, Rome, Italy, 11–13 December 2017; Volume 2006, pp. 1–6. [Google Scholar]
- Fortuna, P.; da Silva, J.R.; Wanner, L.; Nunes, S. A hierarchically-labeled portuguese hate speech dataset. In Proceedings of the Third Workshop on Abusive Language Online, Venice, Italy, 1 August 2019; pp. 94–104. [Google Scholar]
- Fišer, D.; Erjavec, T.; Ljubešić, N. Legal framework, dataset and annotation schema for socially unacceptable online discourse practices in Slovene. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 46–51. [Google Scholar]
- Yasaswini, K.; Puranik, K.; Hande, A.; Priyadharshini, R.; Thavareesan, S.; Chakravarthi, B.R. IIITT@ DravidianLangTech-EACL2021: Transfer Learning for Offensive Language Detection in Dravidian Languages. In Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages, Kyiv, Ukraine, 19–20 April 2021; pp. 187–194. [Google Scholar]
- Vidgen, B.; Derczynski, L. Directions in abusive language training data, a systematic review: Garbage in, garbage out. PLoS ONE 2020, 15, e0243300. [Google Scholar] [CrossRef]
- Chung, Y.L.; Kuzmenko, E.; Tekiroglu, S.S.; Guerini, M. CONAN–COunter NArratives through Nichesourcing: A Multilingual Dataset of Responses to Fight Online Hate Speech. arXiv 2019, arXiv:1910.03270. [Google Scholar]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and Multi-Aspect Hate Speech Analysis. In Proceedings of the EMNLP, Association for Computational Linguistics, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Makice, K. Twitter API: Up and Running: Learn How to Build Applications with the Twitter API; O’Reilly Media, Inc.: Newton, MA, USA, 2009. [Google Scholar]
- Millstein, F. Natural Language Processing with Python: Natural Language Processing using NLTK; Frank Millstein: North Charleston, SC, USA, 2020. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the Type and Target of Offensive Posts in Social Media. In Proceedings of the NAACL, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote. Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic Regression. 1995. Available online: https://psycnet.apa.org/record/1995-97110-007 (accessed on 1 May 2022).
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme gradient boosting. R Package Version 0.4-2 2015, 1, 1–4. Available online: https://cran.microsoft.com/snapshot/2017-12-11/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 1 May 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Aluru, S.S.; Mathew, B.; Saha, P.; Mukherjee, A. Deep Learning Models for Multilingual Hate Speech Detection. arXiv 2020, arXiv:2004.06465. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–15 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Walker, S.H.; Duncan, D.B. Estimation of the probability of an event as a function of several independent variables. Biometrika 1967, 54, 167–179. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Zampieri, M.; Nakov, P. A large-scale semi-supervised dataset for offensive language identification. arXiv 2020, arXiv:2004.14454. [Google Scholar]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: New York, NY, USA, 2019. [Google Scholar]
- Rey, D.; Neuhäuser, M. Wilcoxon-signed-rank test. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1658–1659. [Google Scholar]
- Uma, A.; Fornaciari, T.; Dumitrache, A.; Miller, T.; Chamberlain, J.; Plank, B.; Simpson, E.; Poesio, M. Semeval-2021 Task 12: Learning with Disagreements; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}