
GenericConv: A Generic Model for Image Scene Classification Using Few-Shot Learning


Abstract
:1. Introduction
2. Related Work
2.1. Machine Learning Approaches
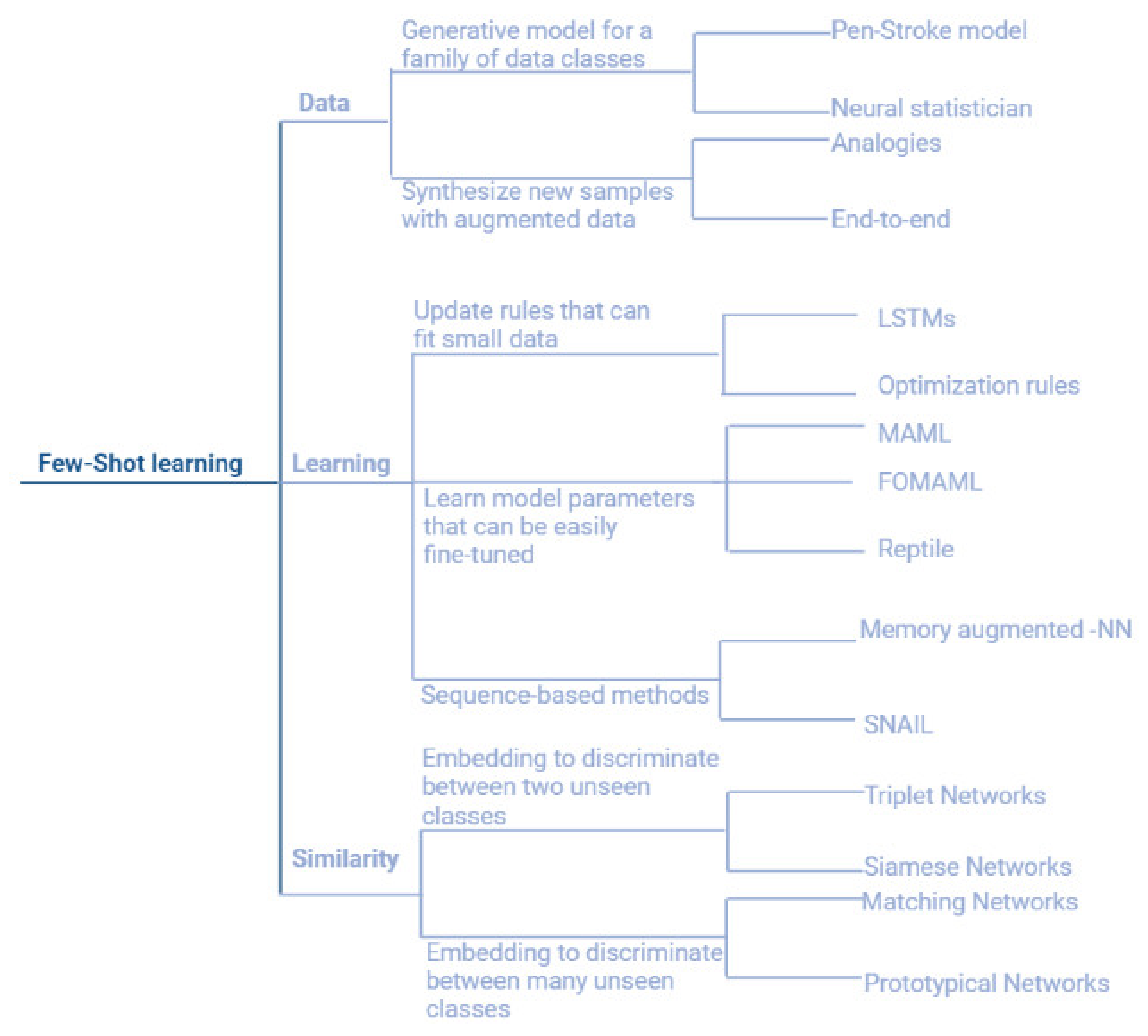
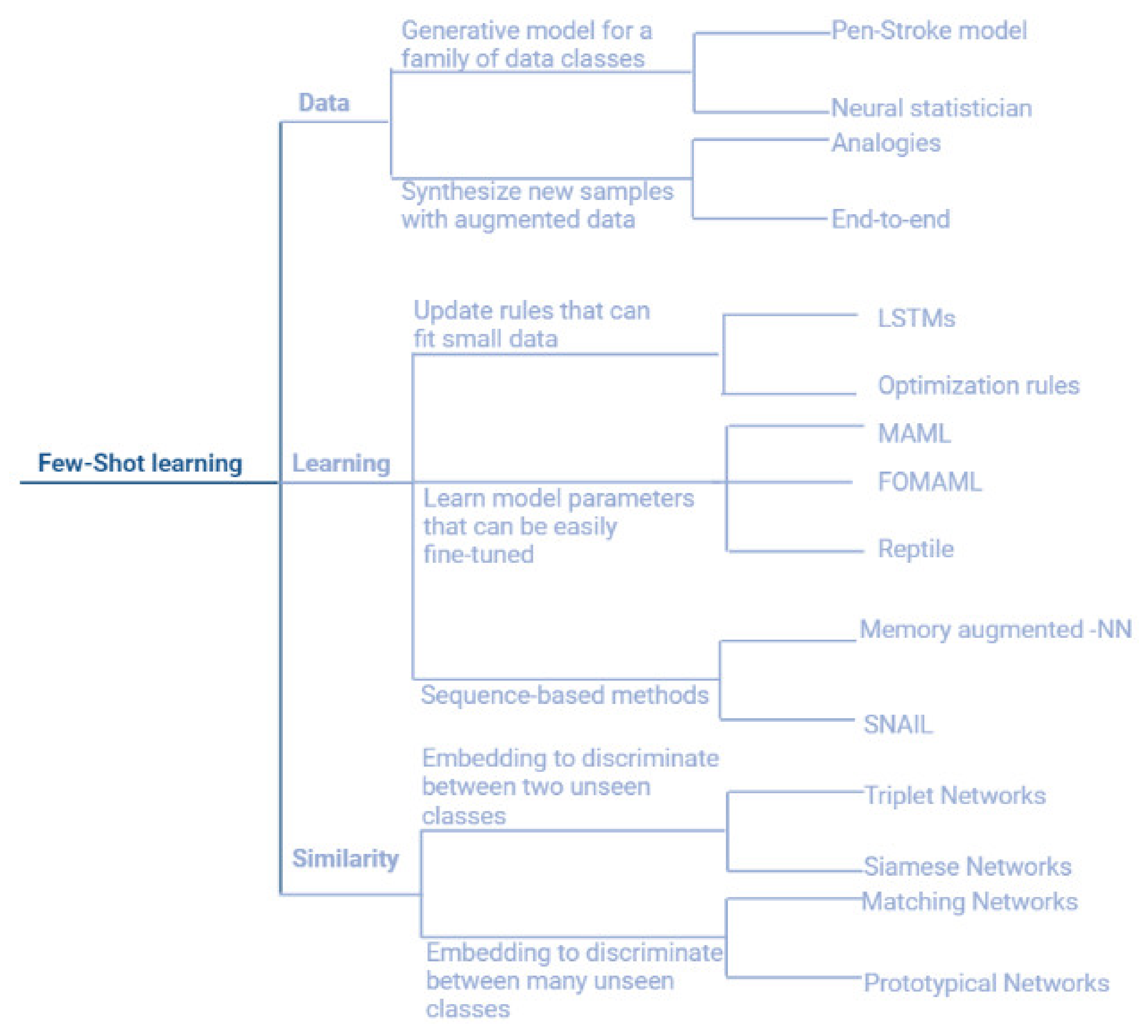
2.2. Few-Shot Learning Approaches
3. Materials and Methods
3.1. Datasets
3.1.1. MiniSun Dataset
3.1.2. MiniPlaces Dataset
3.1.3. MIT-Indoor 67 Dataset
3.2. Benchmarked Models
3.2.1. Conv4
3.2.2. Conv6
3.2.3. Conv8
3.2.4. ResNet12
3.2.5. MobileBlock1
3.2.6. MobileConv
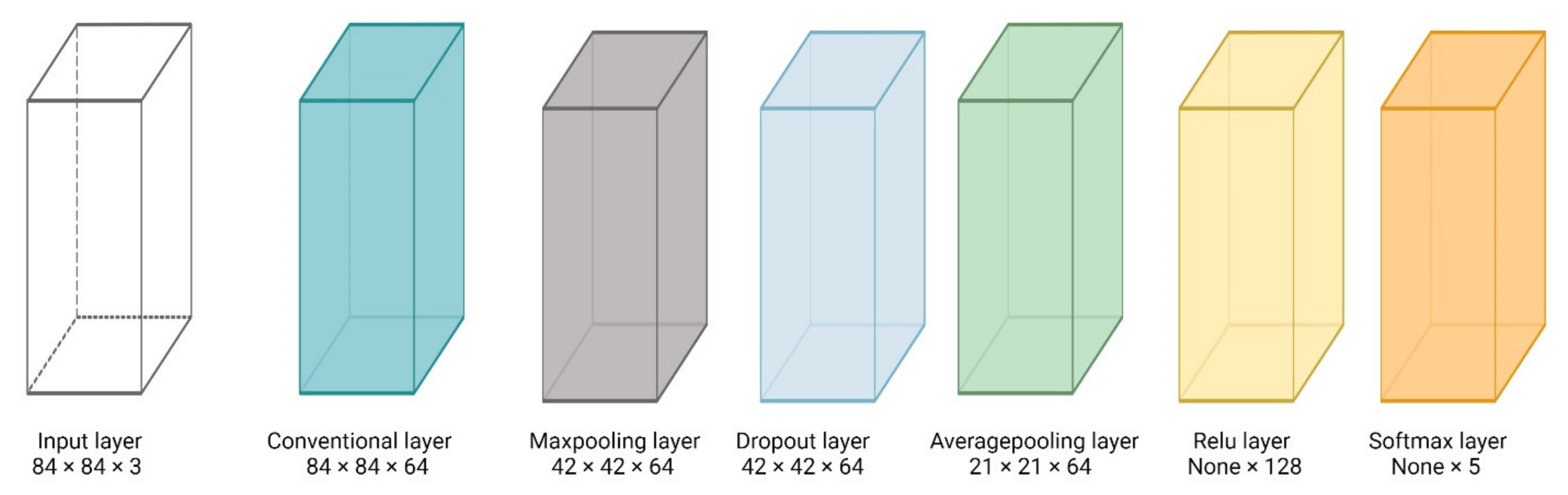
3.2.7. Proposed Model Pipeline
3.2.8. Proposed Model
3.2.9. Proposed Model Hyperparameters
4. Results
4.1. Mini-Sun
4.2. Mini-Places
4.3. MIT Indoor-67
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
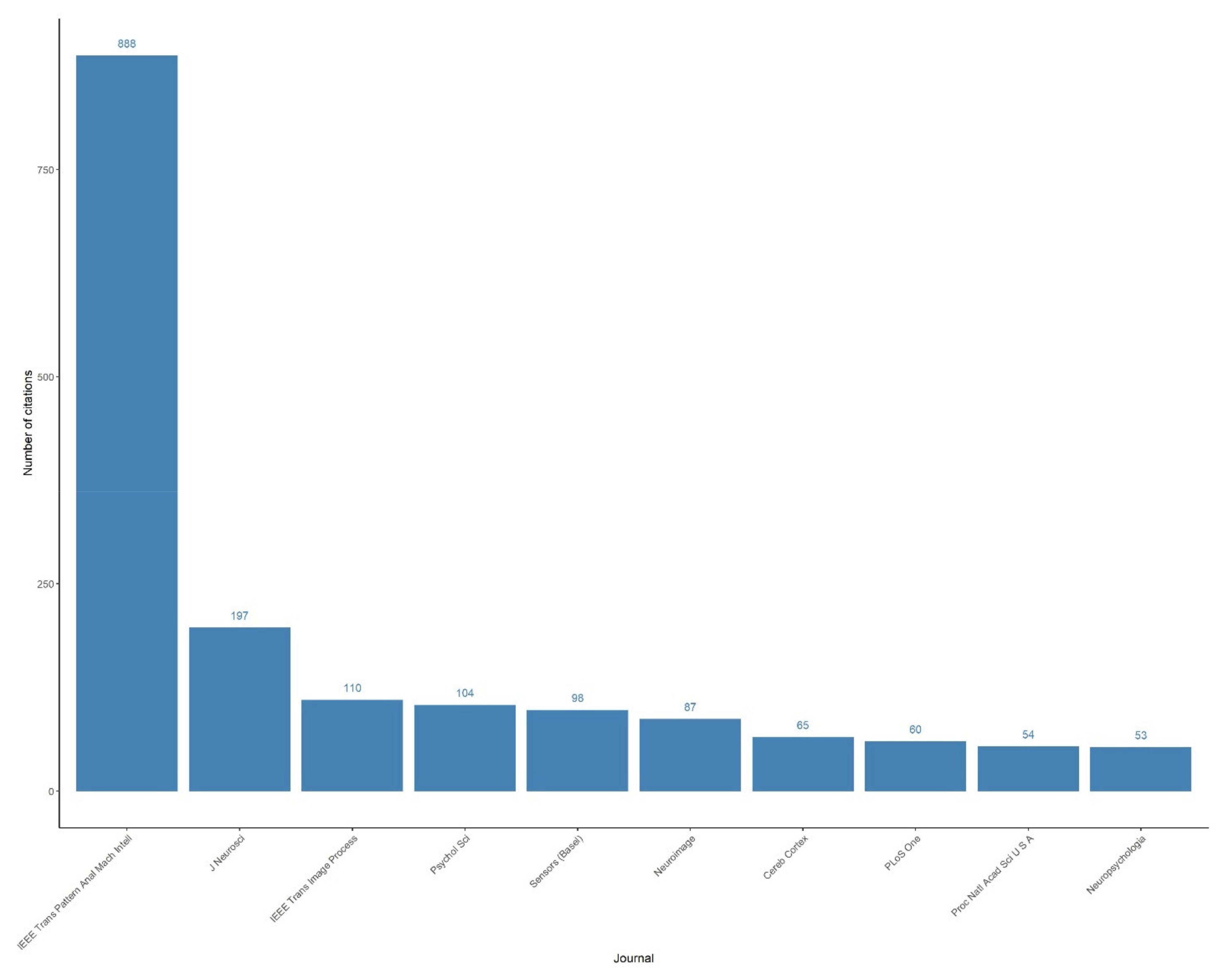
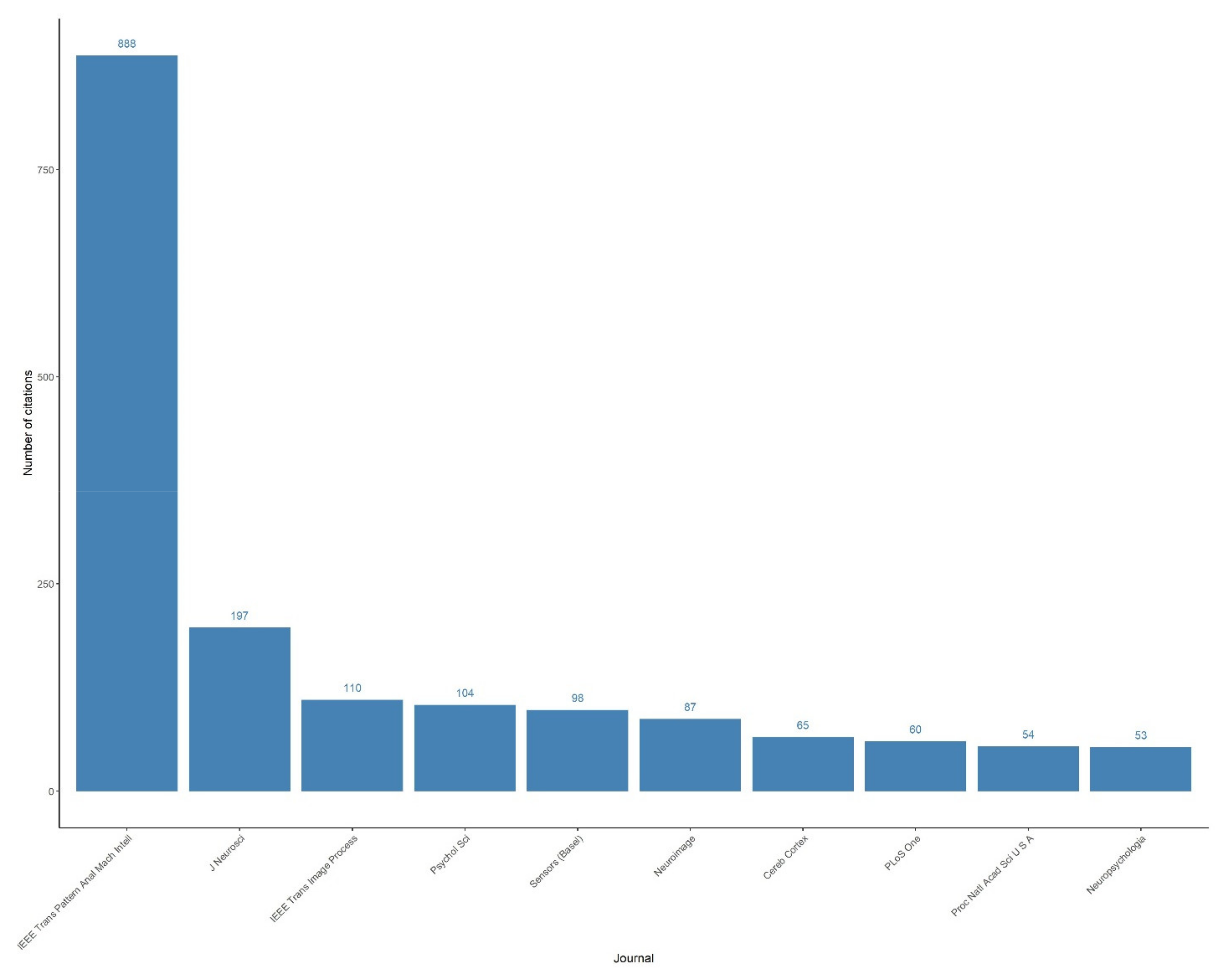
References
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis, and Machine Vision; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Singh, V.; Girish, D.; Ralescu, A. Image Understanding-a Brief Review of Scene Classification and Recognition. MAICS 2017, 85–91. [Google Scholar]
- Yao, J.; Fidler, S.; Urtasun, R. Describing the scene as a whole: Joint object detection, scene classification, and semantic segmentation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 702–709. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Viola, P.; Michael, J. Fast and Robust Classification Using Asymmetric Adaboost and a Detector Cascade. Advances in Neural Information Processing Systems 14. 2001. Available online: https://www.researchgate.net/publication/2539888_Fast_and_Robust_Classification_using_Asymmetric_AdaBoost_and_a_Detector_Cascade (accessed on 12 May 2022).
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Wightman, R.; Touvron, H.; Jégou, H. Resnet strikes back: An improved training procedure in timm. arXiv 2021, arXiv:2110.00476. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In ICML Deep Learning Workshop; ICML: Lille, France, 2015; Volume 2. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In International Workshop on Similarity-Based Pattern Recognition; Springer: Cham, Switzerland, 2015; pp. 84–92. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Advances in Neural Information Processing Systems 29 (NIPS 2016); Curran Associates: Red Hook, NY, USA, 2016; Available online: https://proceedings.neurips.cc/paper/2016/hash/90e1357833654983612fb05e3ec9148c-Abstract.html (accessed on 12 May 2022).
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhu, J.; Jang-Jaccard, J.; Singh, A.; Welch, I.; Ai-Sahaf, H.; Camtepe, S. A few-shot meta-learning based siamese neural network using entropy features for ransomware classification. Comput. Secur. 2022, 117, 102691. [Google Scholar] [CrossRef]
- Sobti, P.; Nayyar, A.; Nagrath, P. EnsemV3X: A novel ensembled deep learning architecture for multi-label scene classification. PeerJ Comput. Sci. 2021, 7, e557. [Google Scholar] [CrossRef] [PubMed]
- Soudy, M.; Yasmine, A.; Nagwa, B. Insights into few shot learning approaches for image scene classification. PeerJ Comput. Sci. 2021, 7, e666. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, A.S.; Danelljan, M.; Van Gool, L.; Timofte, R. Few-Shot Classification by Few-Iteration Meta-Learning. arXiv 2020, arXiv:2010.00511. [Google Scholar]
- Quattoni, A.; Antonio, T. Recognizing indoor scenes. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009; pp. 413–420. [Google Scholar]
- Hong, J.; Fang, P.; Li, W.; Zhang, T.; Simon, C.; Harandi, M.; Petersson, L. Reinforced attention for few-shot learning and beyond. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 913–923. [Google Scholar]
- Li, X.; Wu, J.; Sun, Z.; Ma, Z.; Cao, J.; Xue, J.H. BSNet: Bi-Similarity Network for Few-shot Fine-grained Image Classification. IEEE Trans. Image Process. 2020, 30, 1318–1331. [Google Scholar] [CrossRef] [PubMed]
- Purkait, N. Hands-On Neural Networks with Keras: Design and Create Neural Networks Using Deep Learning and Artificial Intelligence Principles; Packt Publishing Ltd: Birmingham, UK, 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Model | Number of Layers | Developed by | Top5-Error Rate | # of Parameters |
|---|---|---|---|---|---|
| 1998 | LeNet | 8 | Yann LeCun et al. | NA | 60 thousand |
| 2012 | AlexNet | 7 | Krizhevsky, Geoffrey Hinton, llya Sutskever | 15.3% | 60 million |
| 2013 | ZFNetO | NA | Matthew Zeiler and Rob Fergus | 14.8% | NA |
| 2014 | GoogLeNet | 19 | 6.67% | 4 million | |
| 2014 | VGG Net | 16 | Simonyan, Zisserman | 7.3% | 138 million |
| 2015 | ResNet | 152 | Kaiming He | 3.6% | 60.4 million |
| 2017 | Inception-ResNet | NA | Szegedy, Christian et al. | 3.08% | 55.9 million |
| 2018 | ResNet | 50 | Jiang, Yun et al. | NA | 25.6 million |
| 2020 | ReXNet_2.0 | NA | Zhou, Daquan et al. | NA | 19 million |
| 2021 | SENet | 101 | Srinivas, Aravind et al. | NA | 49 million |
| 2021 | ResNet | 152 | Wightman, Ross et al. | NA | 60 million |
| Learning Rate | Meta Step Size | Inner Batch Size | Evaluation Batch Size | Meta Iterations | Inner Iterations | Evaluation Iterations | Shots | Classes |
|---|---|---|---|---|---|---|---|---|
| 0.003 | 0.25 | 25 | 25 | 2000 | 4 | 5 | 1/5 | 5 |
| Backbone Model | Parameters Fine-Tuning | Optimizer | 5 Shots | 1 Shot |
|---|---|---|---|---|
| MobileNetV2 | Reptile | SGD | 20.16 ± 0.011 | |
| Conv4 | 39.14 ± 0.015 | 26.03 ± 0.013 | ||
| Conv6 | 33.42 ± 0.0155 | 24.58 ± 0.012 | ||
| Conv8 | 29.32 ± 0.012 | 21.48 ± 0.011 | ||
| ResNet-12 | 20.16 ± 0.015 | |||
| MobileBlock1 | 40.12 ± 0.015 | 30.86 ± 0.013 | ||
| MobileConv | 47.5 ± 0.0158 | 30.72 ± 0.013 | ||
| Proposed GenericConv | 52.16 ± 0.015 | 32.72 ± 0.014 |
| Backbone Model | Parameters Fine-Tuning | Optimizer | 5 Shots | 1 Shot |
|---|---|---|---|---|
| Conv4 | Reptile | SGD | 27.9 ± 0.014 | 29.62 ± 0.013 |
| Conv6 | 19.84 ± 0.007 | 21.42 ± 0.009 | ||
| Conv8 | 25.2 ± 0.011 | 21.14± 0.004 | ||
| ResNet-12 | 20.16 ± 0.011 | |||
| MobileBlock1 | 20.1 ± 0.001 | |||
| MobileConv | 34.64 ± 0.014 | 26.36 ± 0.013 | ||
| Proposed GenericConv | 35.86 ± 0.014 | 23.80 ± 0.012 |
| Backbone Model | Parameters Fine-Tuning | Optimizer | 5 Shots | 1 Shot |
|---|---|---|---|---|
| Conv4 | Reptile | SGD | 28.7 ± 0.013 | 22.0 ± 0.012 |
| Conv6 | 20.16 ± 0.003 | 20.0 ± 0.0014 | ||
| Conv8 | 22.18 ± 0.005 | 20.10 ± 0.003 | ||
| ResNet-12 | 20 ± 0.00011 | 20 ± 0.00011 | ||
| MobileBlock1 | 34.1 ± 0.014 | 24.6 ± 0.012 | ||
| MobileConv | 33.18 ± 0.014 | 23.82 ± 0.012 | ||
| Proposed GenericConv | 37.26 ± 0.014 | 24.82 ± 0.013 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soudy, M.; Afify, Y.M.; Badr, N. GenericConv: A Generic Model for Image Scene Classification Using Few-Shot Learning. Information 2022, 13, 315. https://doi.org/10.3390/info13070315
Soudy M, Afify YM, Badr N. GenericConv: A Generic Model for Image Scene Classification Using Few-Shot Learning. Information. 2022; 13(7):315. https://doi.org/10.3390/info13070315
Chicago/Turabian StyleSoudy, Mohamed, Yasmine M. Afify, and Nagwa Badr. 2022. "GenericConv: A Generic Model for Image Scene Classification Using Few-Shot Learning" Information 13, no. 7: 315. https://doi.org/10.3390/info13070315
APA StyleSoudy, M., Afify, Y. M., & Badr, N. (2022). GenericConv: A Generic Model for Image Scene Classification Using Few-Shot Learning. Information, 13(7), 315. https://doi.org/10.3390/info13070315