
Human Evaluation of English–Irish Transformer-Based NMT



Abstract
:1. Introduction
2. Background
2.1. Hyperparameter Optimization
2.1.1. RNN
2.1.2. Transformer
2.2. SentencePiece
2.3. Human Evaluation
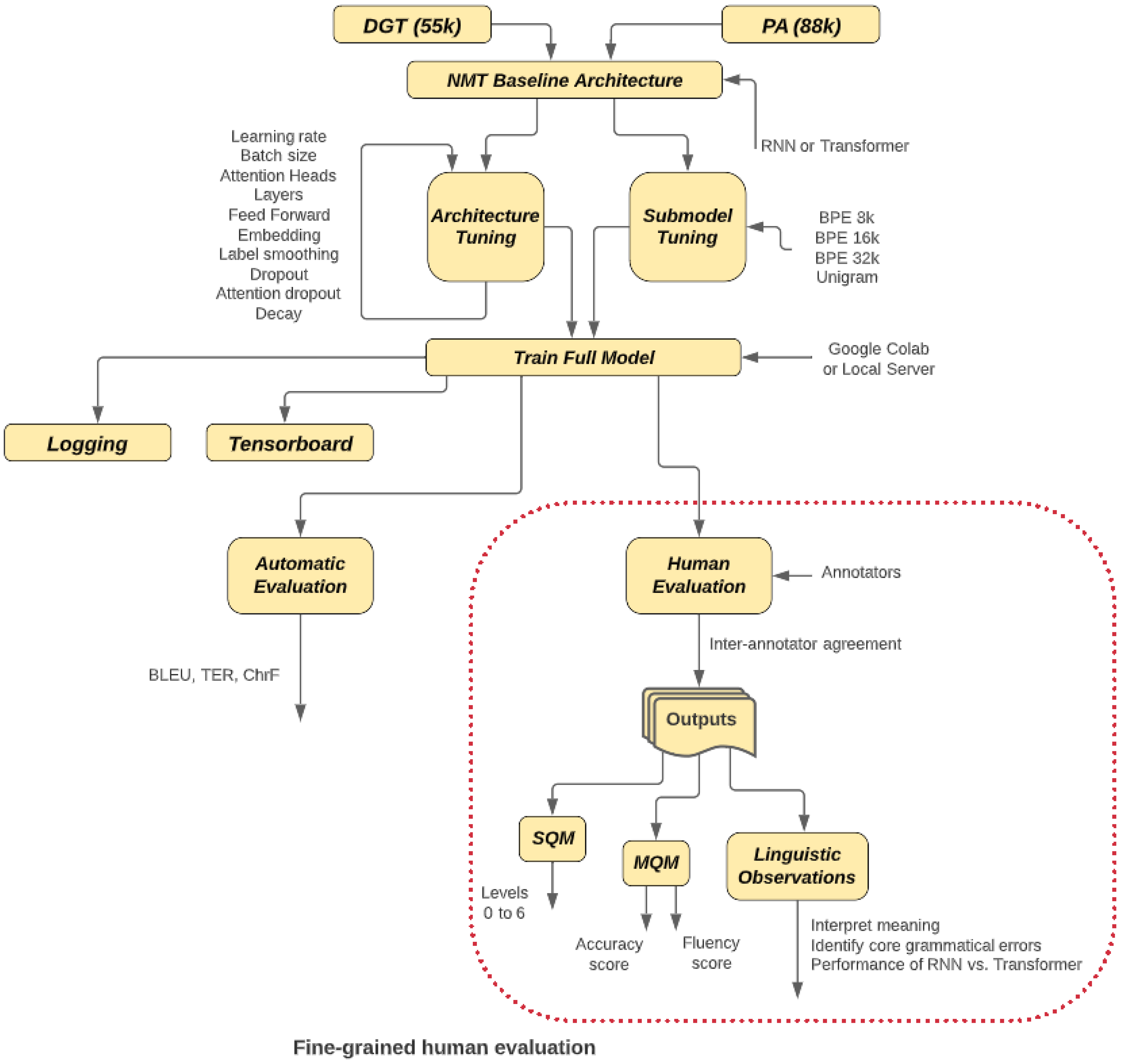
3. Proposed Approach
3.1. Architecture Tuning
3.2. Subword Models
3.3. Human Evaluation of NMT
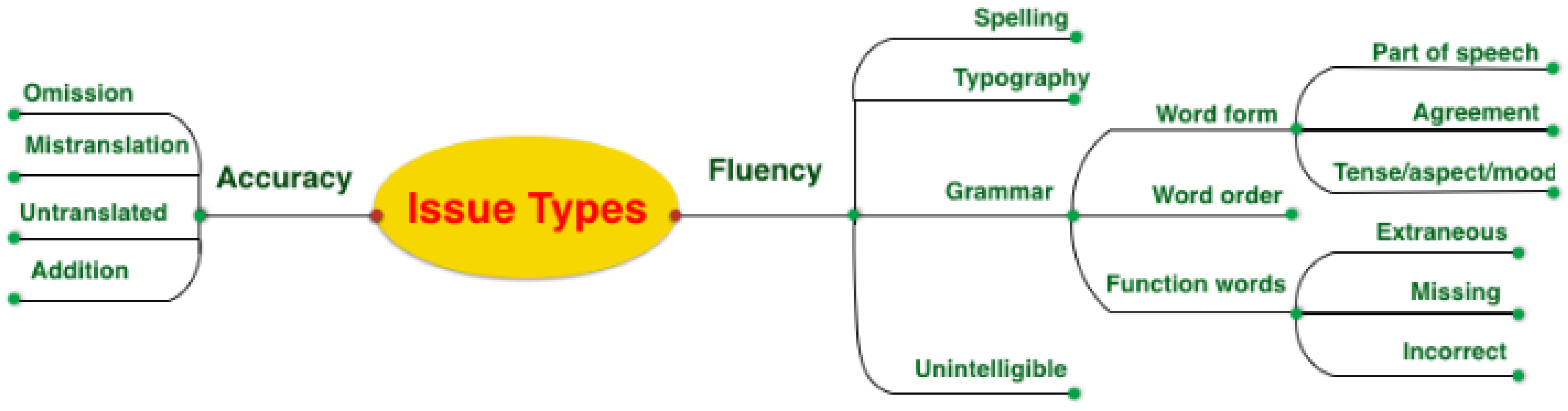
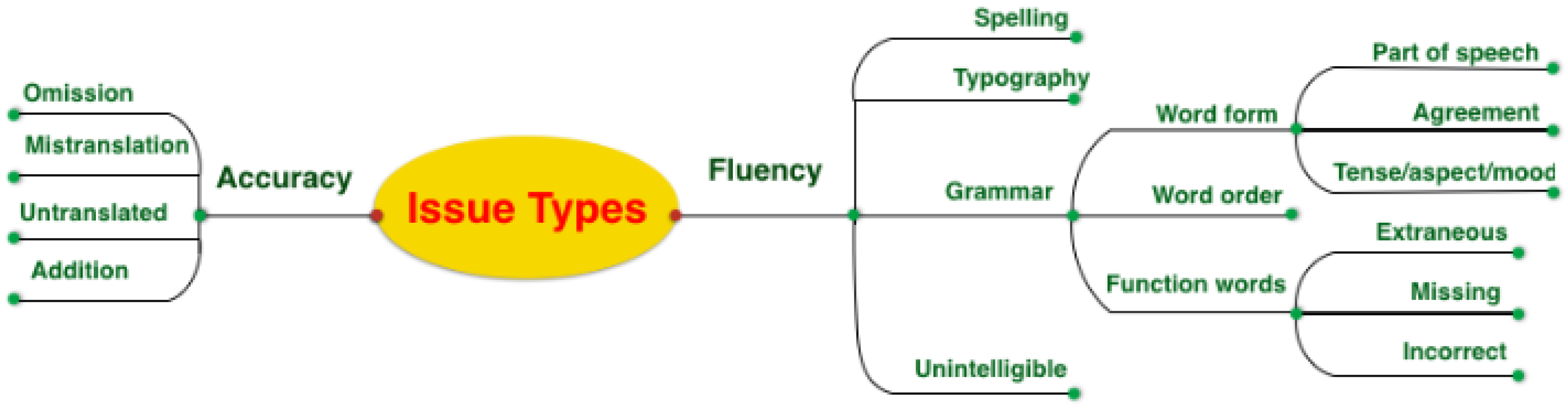
3.3.1. Scalar Quality Metrics
3.3.2. Multidimensional Quality Metrics
3.3.3. Annotation Setup
3.3.4. Inter-Annotator Agreement
4. Empirical Evaluation
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Infrastructure
4.1.3. Metrics
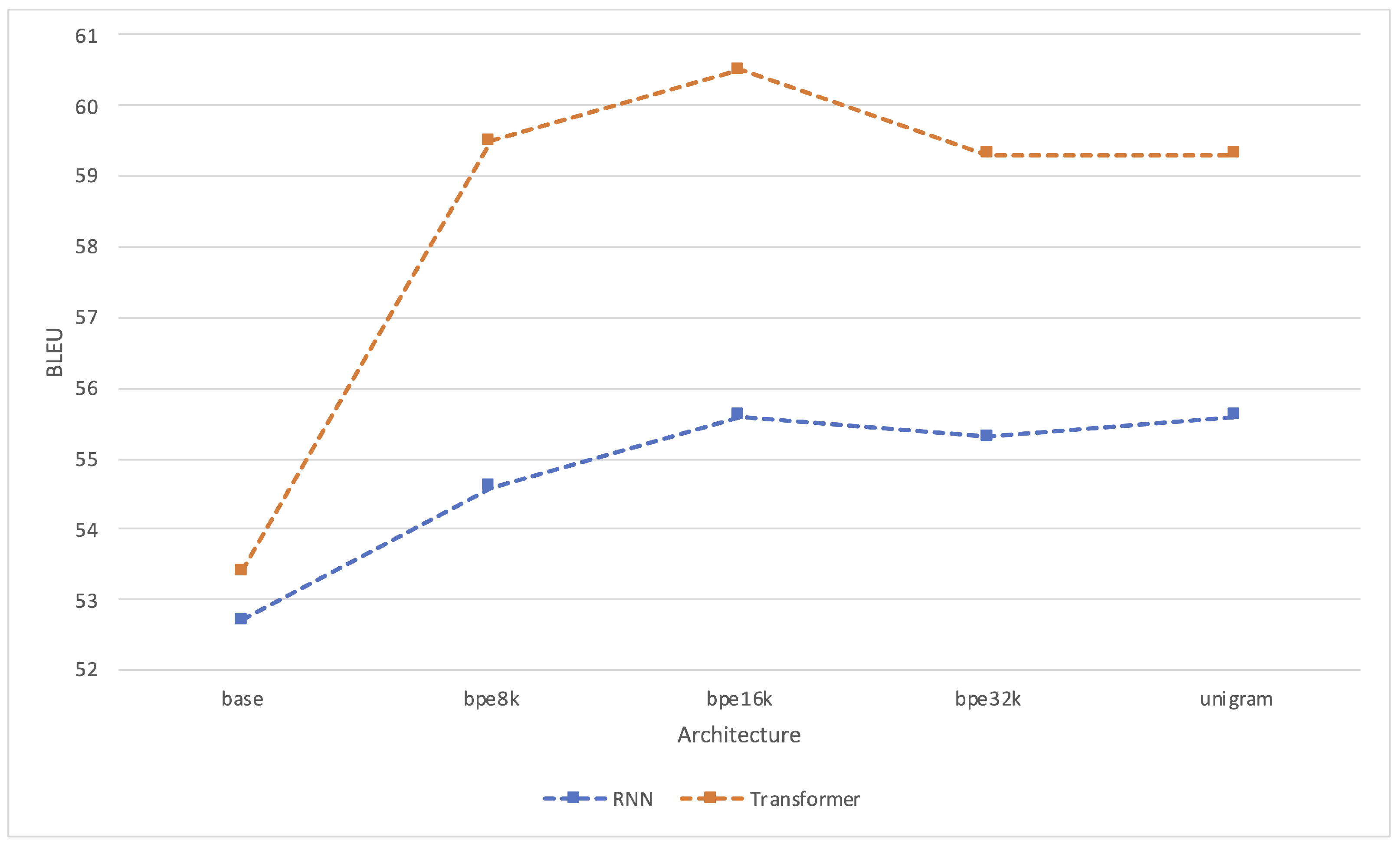
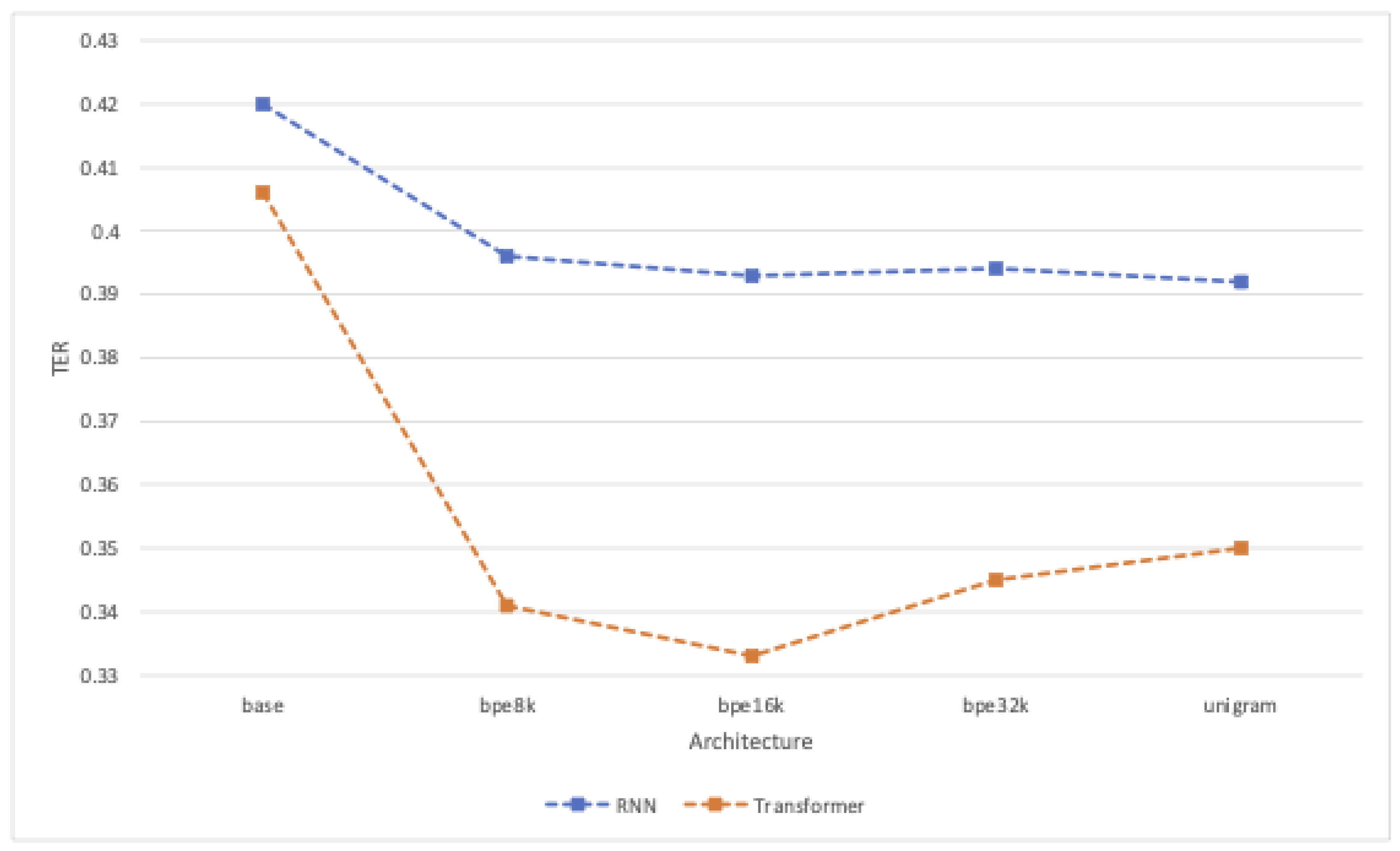
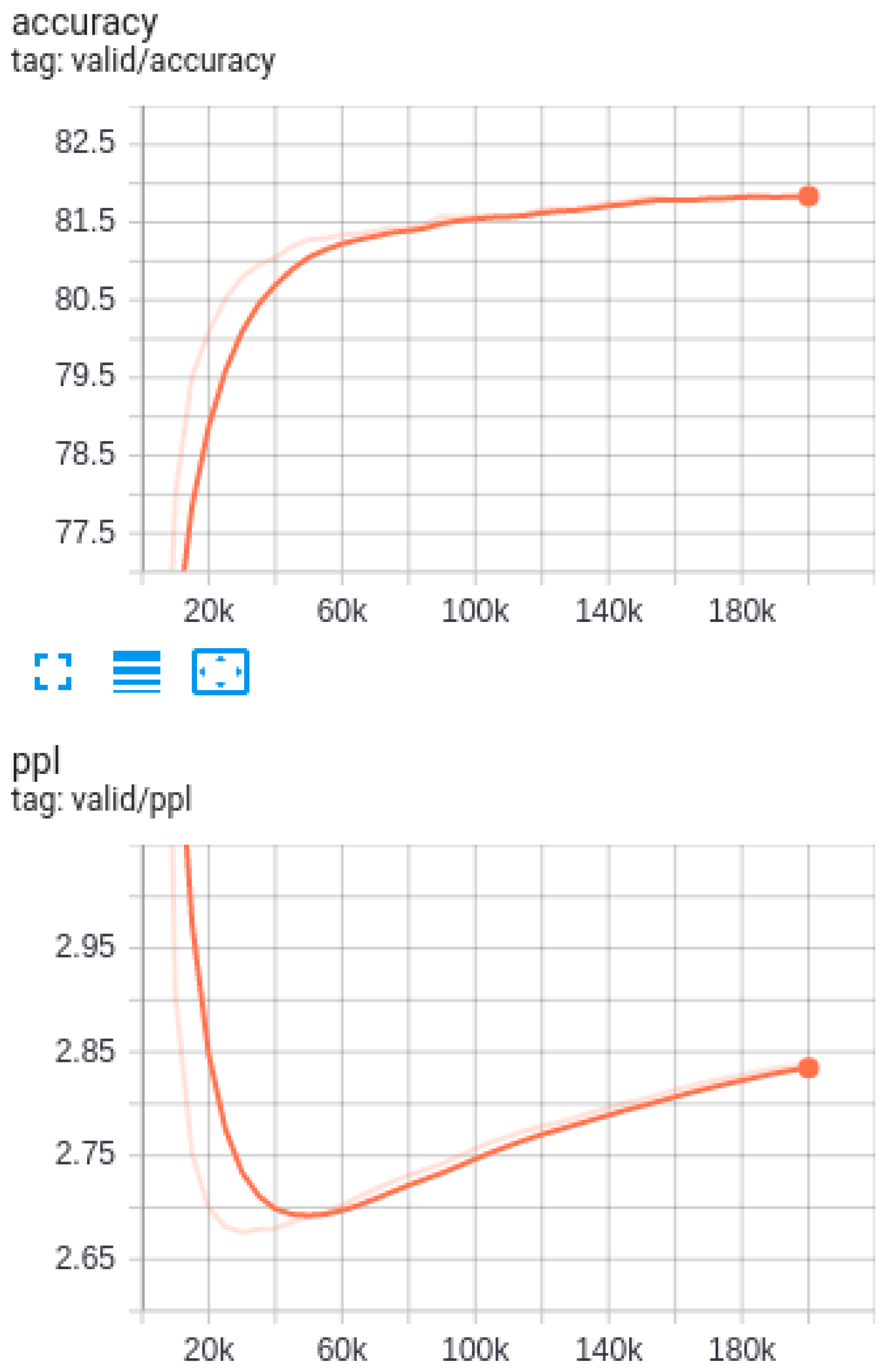
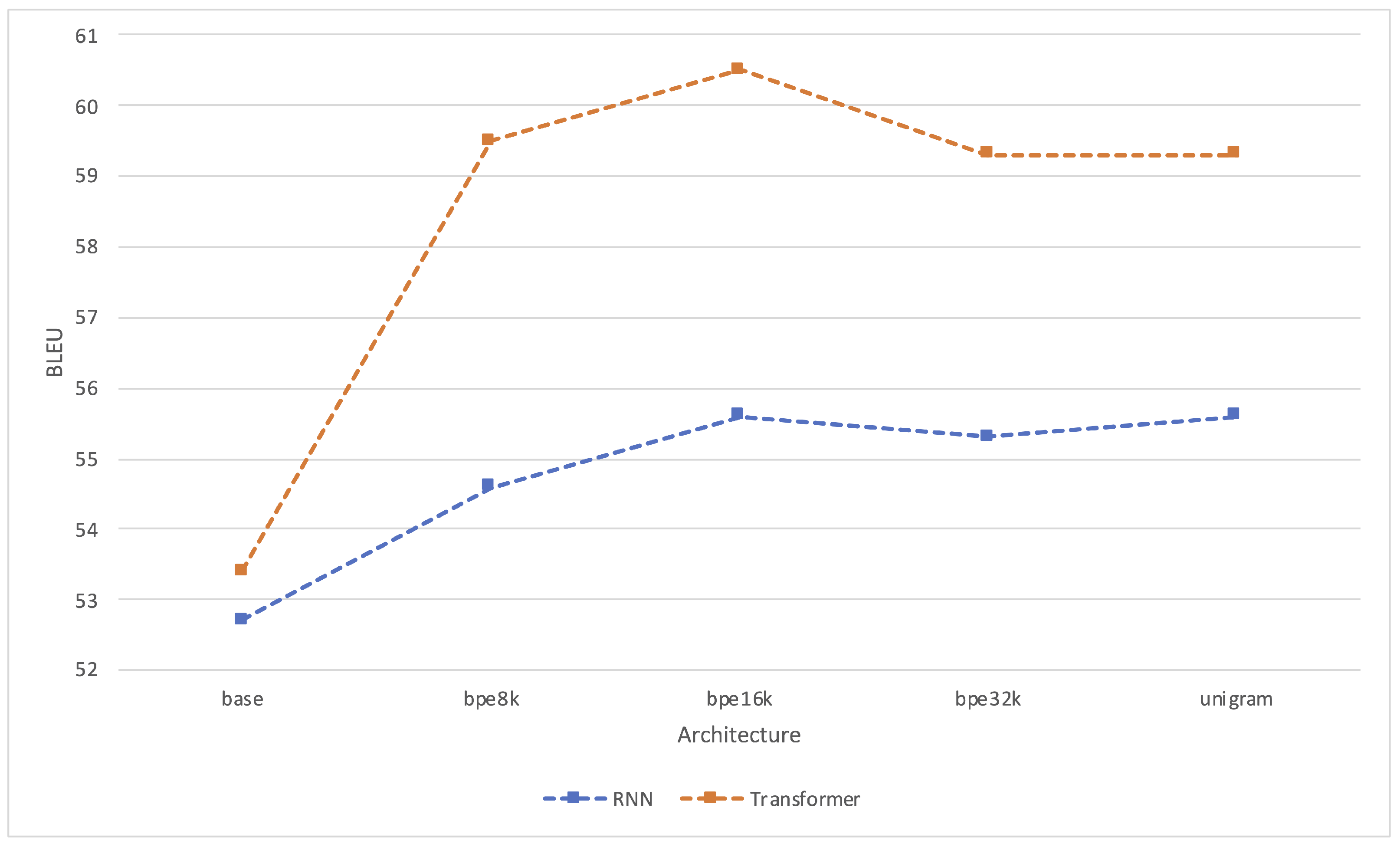
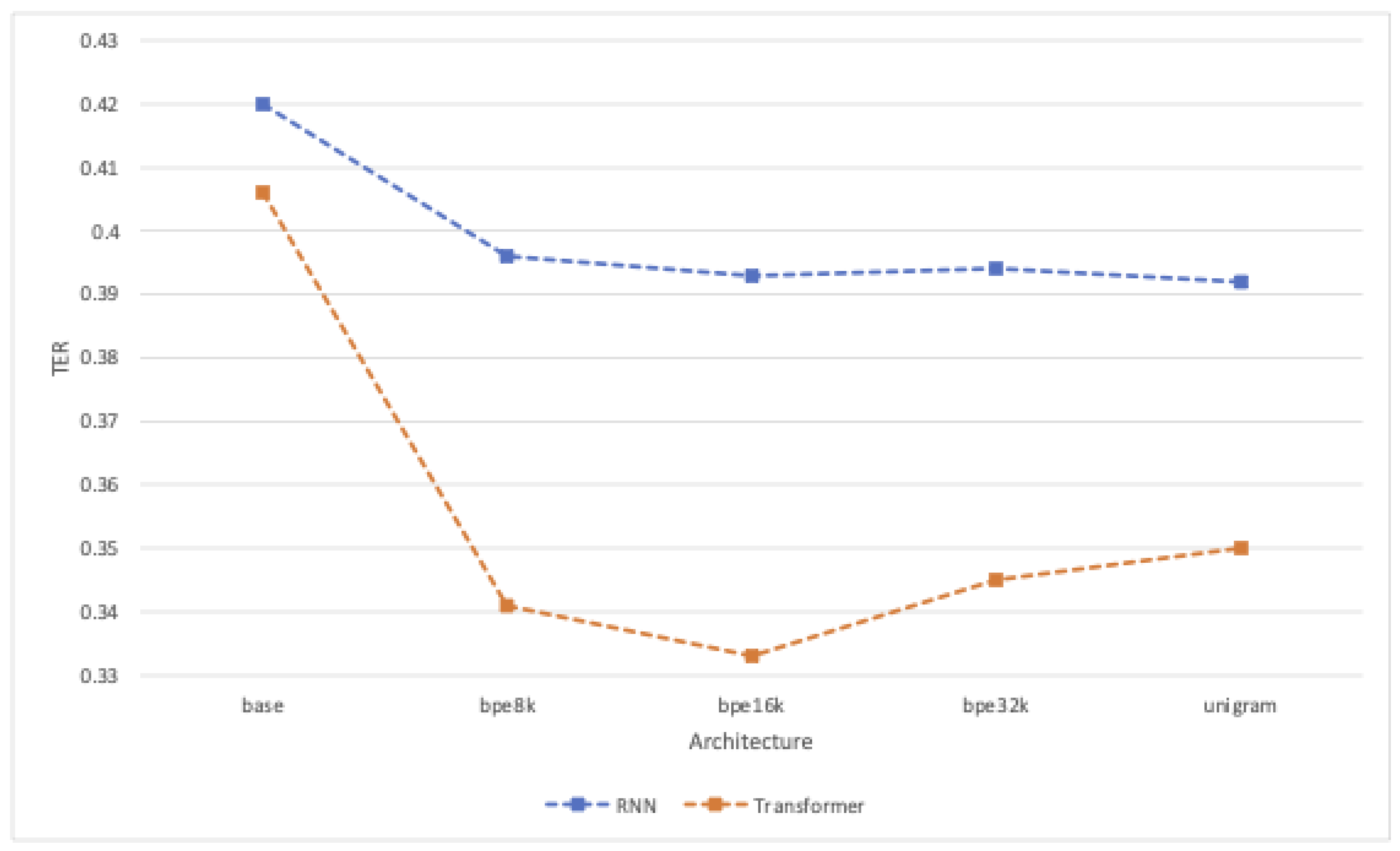
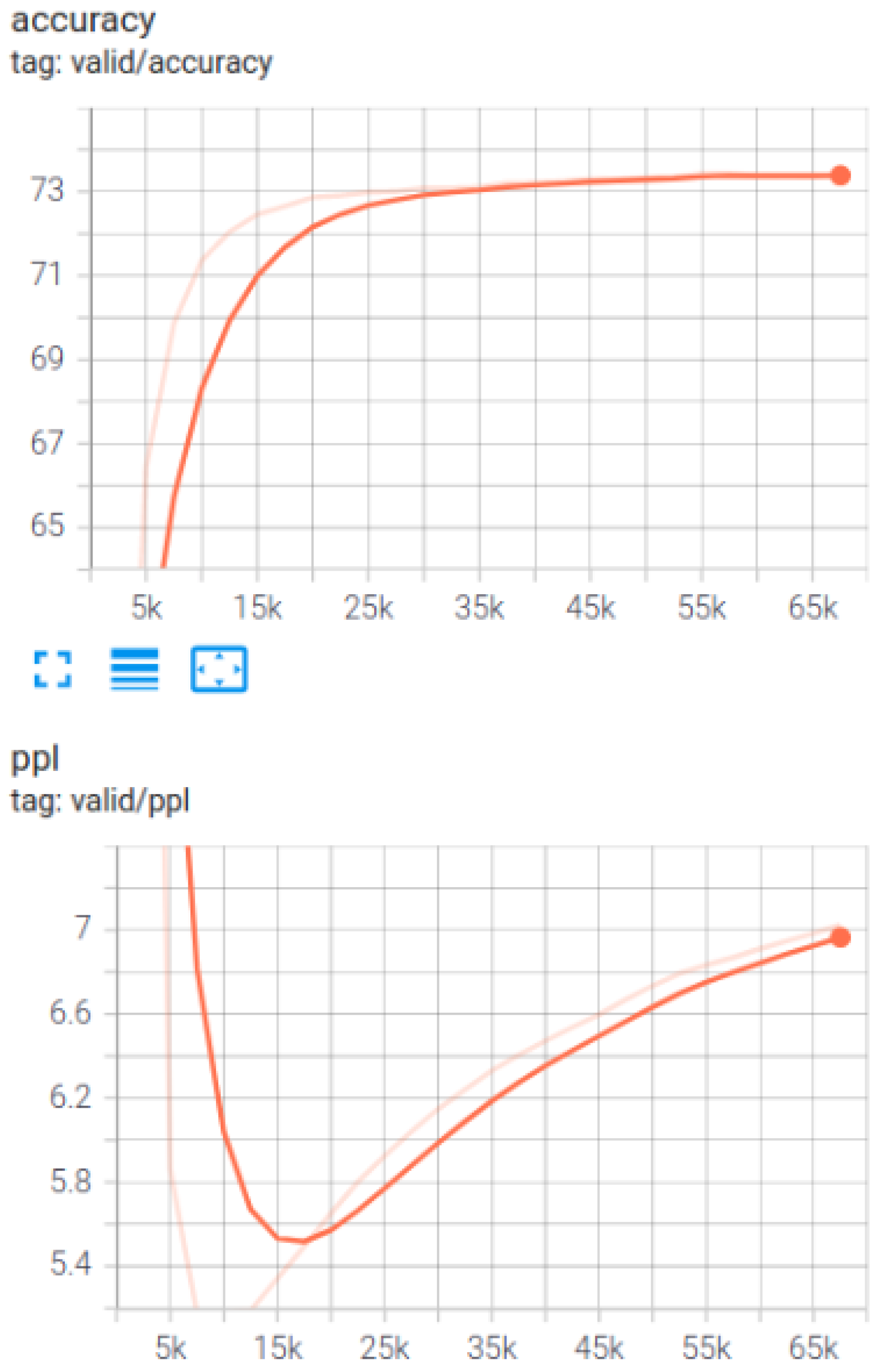
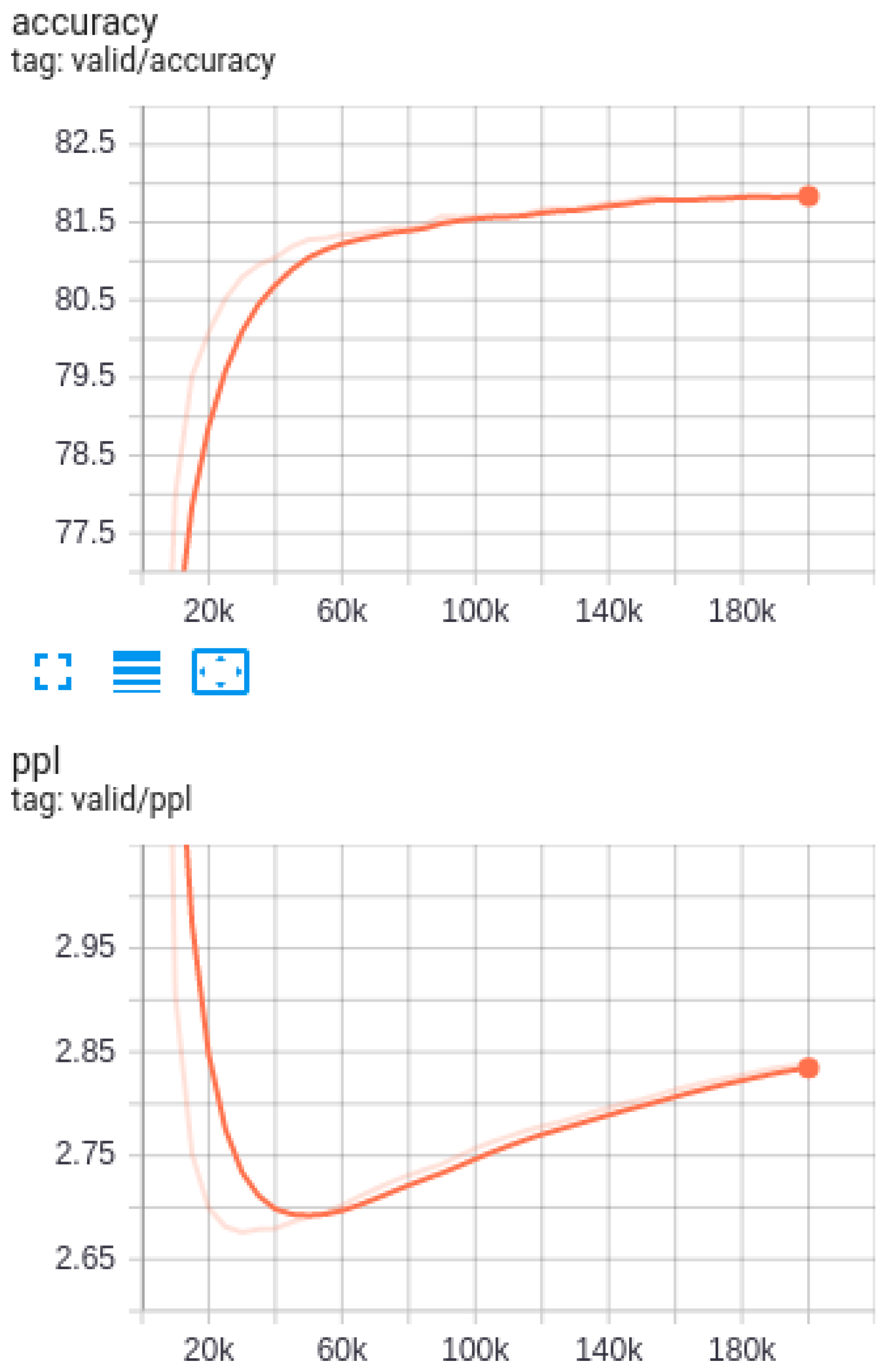
4.2. Automatic Evaluation Results
4.2.1. Performance of Subword Models
4.2.2. Transformer Performance Compared with RNN
4.3. Human Evaluation Results
5. Environmental Impact
6. Discussion
6.1. Inter-Annotator Reliability
6.2. Performance of Is Féidir Linn Models Relative to Google
6.3. Linguistic Observations
6.3.1. Interpreting Meaning
6.3.2. Core Grammatical Errors
6.3.3. Commonly-Used Irregular Verbs
6.3.4. Performance of RNN Approach Relative to Transformer Approach
6.4. Limitations of the Study
7. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Glossary
| Déan | To do or to make |
| Bí | To be |
| Ná bídís | Let it not be |
| Ní bheidh siad | They will not |
| Ní bheidh sé | He will not |
References
- He, D.; Xia, Y.; Qin, T.; Wang, L.; Yu, N.; Liu, T.Y.; Ma, W.Y. Dual learning for machine translation. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Ahmadnia, B.; Dorr, B.J. Augmenting neural machine translation through round-trip training approach. Open Comput. Sci. 2019, 9, 268–278. [Google Scholar] [CrossRef]
- Dowling, M.; Lynn, T.; Poncelas, A.; Way, A. SMT versus NMT: Preliminary comparisons for Irish. In Proceedings of the AMTA 2018 Workshop on Technologies for MT of Low Resource Languages (LoResMT 2018), Boston, MA, USA, 21 March 2018; pp. 12–20. [Google Scholar]
- Ding, S.; Renduchintala, A.; Duh, K. A call for prudent choice of subword merge operations in neural machine translation. arXiv 2019, arXiv:1905.10453. [Google Scholar]
- Gowda, T.; May, J. Finding the optimal vocabulary size for neural machine translation. arXiv 2020, arXiv:2004.02334. [Google Scholar]
- Gage, P. A new algorithm for data compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Kudo, T. Subword regularization: Improving neural network translation models with multiple subword candidates. arXiv 2018, arXiv:1804.10959. [Google Scholar]
- Lankford, S.; Alfi, H.; Way, A. Transformers for Low-Resource Languages: Is Féidir Linn! In Proceedings of the 18th Biennial Machine Translation Summit (Volume 1: Research Track), Virtual, 16–20 August 2021; pp. 48–60. [Google Scholar]
- MacFarlane, A.; Glynn, L.G.; Mosinkie, P.I.; Murphy, A.W. Responses to language barriers in consultations with refugees and asylum seekers: A telephone survey of Irish general practitioners. BMC Fam. Pract. 2008, 9, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Alam, K.; Imran, S. The digital divide and social inclusion among refugee migrants. Inf. Technol. People 2015, 28, 344–365. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.H.; Silva, C.C.; Wang, L.; Way, A. Pivot machine translation using chinese as pivot language. In Proceedings of the China Workshop on Machine Translation, Wuyishan, China, 25–26 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 74–85. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D.; Li, W. Deep reconstruction-classification networks for unsupervised domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 597–613. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Bojar, O.; Chatterjee, R.; Federmann, C.; Graham, Y.; Haddow, B.; Huang, S.; Huck, M.; Koehn, P.; Liu, Q.; Logacheva, V.; et al. Findings of the 2017 Conference on Machine Translation (WMT17). In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 169–214. [Google Scholar] [CrossRef] [Green Version]
- Bojar, O.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Koehn, P.; Monz, C. Findings of the 2018 Conference on Machine Translation (WMT18). In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Brussels, Belgium, 31 October–1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 272–303. [Google Scholar] [CrossRef]
- Sanders, S.; Giraud-Carrier, C. Informing the use of hyperparameter optimization through metalearning. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: New York, NY, USA, 2017; pp. 1051–1056. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Belz, A.; Agarwal, S.; Graham, Y.; Reiter, E.; Shimorina, A. Proceedings of the Workshop on Human Evaluation of NLP Systems (HumEval). In Proceedings of the Workshop on Human Evaluation of NLP Systems (HumEval), Kiev, Ukraine, 19–20 April 2021; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2021. [Google Scholar]
- Toral, A.; Castilho, S.; Hu, K.; Way, A. Attaining the unattainable? reassessing claims of human parity in neural machine translation. arXiv 2018, arXiv:1808.10432. [Google Scholar]
- Castilho, S.; Moorkens, J.; Gaspari, F.; Calixto, I.; Tinsley, J.; Way, A. Is neural machine translation the new state of the art? Prague Bull. Math. Linguist. 2017, 108, 109. [Google Scholar] [CrossRef] [Green Version]
- Bayón, M.D.C.; Sánchez-Gijón, P. Evaluating machine translation in a low-resource language combination: Spanish-Galician. In Proceedings of the Machine Translation Summit XVII: Translator, Project and User Tracks, Dublin, Ireland, 19–23 August 2019; pp. 30–35. [Google Scholar]
- Imankulova, A.; Dabre, R.; Fujita, A.; Imamura, K. Exploiting out-of-domain parallel data through multilingual transfer learning for low-resource neural machine translation. arXiv 2019, arXiv:1907.03060. [Google Scholar]
- Läubli, S.; Castilho, S.; Neubig, G.; Sennrich, R.; Shen, Q.; Toral, A. A set of recommendations for assessing human–machine parity in language translation. J. Artif. Intell. Res. 2020, 67, 653–672. [Google Scholar] [CrossRef] [Green Version]
- Dowling, M.; Castilho, S.; Moorkens, J.; Lynn, T.; Way, A. A human evaluation of English-Irish statistical and neural machine translation. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisbon, Portugal, 3–5 November 2020; pp. 431–440. [Google Scholar]
- Araabi, A.; Monz, C. Optimizing Transformer for Low-Resource Neural Machine Translation. arXiv 2020, arXiv:2011.02266. [Google Scholar]
- Van Biljon, E.; Pretorius, A.; Kreutzer, J. On optimal transformer depth for low-resource language translation. arXiv 2020, arXiv:2004.04418. [Google Scholar]
- Klubička, F.; Toral, A.; Sánchez-Cartagena, V.M. Quantitative fine-grained human evaluation of machine translation systems: A case study on English to Croatian. Mach. Transl. 2018, 32, 195–215. [Google Scholar] [CrossRef] [Green Version]
- Freitag, M.; Foster, G.; Grangier, D.; Ratnakar, V.; Tan, Q.; Macherey, W. Experts, errors, and context: A large-scale study of human evaluation for machine translation. Trans. Assoc. Comput. Linguist. 2021, 9, 1460–1474. [Google Scholar] [CrossRef]
- Ma, Q.; Graham, Y.; Wang, S.; Liu, Q. Blend: A novel combined MT metric based on direct assessment—CASICT-DCU submission to WMT17 metrics task. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–11 September 2017; pp. 598–603. [Google Scholar]
- Lommel, A. Metrics for translation quality assessment: A case for standardising error typologies. In Translation Quality Assessment; Springer: Berlin/Heidelberg, Germany, 2018; pp. 109–127. [Google Scholar]
- Lommel, A.; Burchardt, A.; Popović, M.; Harris, K.; Avramidis, E.; Uszkoreit, H. Using a new analytic measure for the annotation and analysis of MT errors on real data. In Proceedings of the 17th Annual Conference of the European Association for Machine Translation, Dubrovnik, Croatia, 16–18 June 2014; pp. 165–172. [Google Scholar]
- Callison-Burch, C.; Fordyce, C.S.; Koehn, P.; Monz, C.; Schroeder, J. (Meta-) evaluation of machine translation. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007; pp. 136–158. [Google Scholar]
- Artstein, R. Inter-annotator agreement. In Handbook of Linguistic Annotation; Springer: Berlin/Heidelberg, Germany, 2017; pp. 297–313. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Steinberger, R.; Eisele, A.; Klocek, S.; Pilos, S.; Schlüter, P. DGT-TM: A freely available translation memory in 22 languages. arXiv 2013, arXiv:1309.5226. [Google Scholar]
- Bisong, E. Google colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019; pp. 59–64. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. Opennmt: Open-source toolkit for neural machine translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, Cambridge, MA, USA, 8–12 August 2006; Citeseer: Forest Grove, OR, USA, 2006; Volume 200. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisboa, Portugal, 17–18 September 2015; pp. 392–395. [Google Scholar]
- Stanojević, M.; Kamran, A.; Koehn, P.; Bojar, O. Results of the WMT15 metrics shared task. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisboa, Portugal, 17–18 September 2015; pp. 256–273. [Google Scholar]
- Jooste, W.; Haque, R.; Way, A. Knowledge Distillation: A Method for Making Neural Machine Translation More Efficient. Information 2022, 13, 88. [Google Scholar] [CrossRef]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; pp. 610–623. [Google Scholar]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the carbon emissions of machine learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- SEAI. Sustainable Energy in Ireland; SEAI: Dublin, Ireland, 2020. [Google Scholar]
- Ojha, A.K.; Liu, C.H.; Kann, K.; Ortega, J.; Shatam, S.; Fransen, T. Findings of the LoResMT 2021 Shared Task on COVID and Sign Language for Low-resource Languages. arXiv 2021, arXiv:2108.06598. [Google Scholar]
- Lankford, S.; Afli, H.; Way, A. Machine Translation in the Covid domain: An English-Irish case study for LoResMT 2021. In Proceedings of the 4th Workshop on Technologies for MT of Low Resource Languages (LoResMT2021), Virtual, 16 August 2021; pp. 144–150. [Google Scholar]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Medica 2012, 22, 276–282. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Values |
|---|---|
| Learning rate | 0.1, 0.01, 0.001, 2 |
| Batch size | 1024, 2048, 4096, 8192 |
| Attention heads | 2, 4, 8 |
| Number of layers | 5, 6 |
| Feed-forward dimension | 2048 |
| Embedding dimension | 128, 256, 512 |
| Label smoothing | 0.1, 0.3 |
| Dropout | 0.1, 0.3 |
| Attention dropout | 0.1 |
| Average Decay | 0, 0.0001 |
| SQM Level | Details of Quality |
|---|---|
| 6 | Perfect Meaning and Grammar: The meaning of the translation is completely consistent with the source and the surrounding context (if applicable). The grammar is also correct. |
| 4 | Most Meaning Preserved and Few Grammar Mistakes: The translation retains most of the meaning of the source. This may contain some grammar mistakes or minor contextual inconsistencies. |
| 2 | Some Meaning Preserved: The translation preserves some of the meaning of the source but misses significant parts. The narrative is hard to follow due to fundamental errors. Grammar may be poor. |
| 0 | Nonsense/No meaning preserved: Nearly all information is lost between the translation and source. Grammar is irrelevant. |
| Category | Sub-Category | Description |
|---|---|---|
| Non-translation | Impossible to reliably characterize the 5 most severe errors. | |
| Accuracy | Addition | Translation includes information not present in the source. |
| Omission | Translation is missing content from the source. | |
| Mistranslation | Translation does not accurately represent the source. | |
| Untranslated text | Source text has been left untranslated. | |
| Fluency | Punctuation | Incorrect punctuation |
| Spelling | Incorrect spelling or capitalization. | |
| Grammar | Problems with grammar, other than orthography. | |
| Register | Wrong grammatical register (e.g., inappropriately informal pronouns). | |
| Inconsistency | Internal inconsistency (not related to terminology). | |
| Character encoding | Characters are garbled due to incorrect encoding. |
| Error Type | RNN | NMT |
|---|---|---|
| Non-translation | 1.0 | 1.0 |
| Accuracy | 1.0 | 1.0 |
| Addition | 1.0 | 1.0 |
| Omission | 1.0 | 1.0 |
| Mistranslation | −0.071 | 1.0 |
| Untranslated text | 0.0 | 1.0 |
| Fluency | ||
| Punctuation | 0.651 | 1.0 |
| Spelling | 0.0 | 0.0 |
| Grammar | 0.867 | 0.895 |
| Register | 1.0 | 1.0 |
| Inconsistency | 1.0 | 1.0 |
| Character Encoding | 1.0 | 1.0 |
| Architecture | BLEU ↑ | TER ↓ | ChrF3 ↑ | Steps | Runtime (h) | kgCO2 |
|---|---|---|---|---|---|---|
| dgt-rnn-base | 52.7 | 0.42 | 0.71 | 75k | 4.47 | 0 |
| dgt-rnn-bpe8k | 54.6 | 0.40 | 0.73 | 85k | 5.07 | 0 |
| dgt-rnn-bpe16k | 55.6 | 0.39 | 0.74 | 100k | 5.58 | 0 |
| dgt-rnn-bpe32k | 55.3 | 0.39 | 0.74 | 95k | 4.67 | 0 |
| dgt-rnn-unigram | 55.6 | 0.39 | 0.74 | 105k | 5.07 | 0 |
| Architecture | BLEU ↑ | TER ↓ | ChrF3 ↑ | Steps | Runtime (h) | kgCO2 |
|---|---|---|---|---|---|---|
| dgt-trans-base | 53.4 | 0.41 | 0.72 | 55k | 14.43 | 0.81 |
| dgt-trans-bpe8k | 59.5 | 0.34 | 0.77 | 200k | 24.48 | 1.38 |
| dgt-trans-bpe16k | 60.5 | 0.33 | 0.78 | 180k | 26.90 | 1.52 |
| dgt-trans-bpe32k | 59.3 | 0.35 | 0.77 | 100k | 18.03 | 1.02 |
| dgt-trans-unigram | 59.3 | 0.35 | 0.77 | 125k | 21.95 | 1.24 |
| Annotator 1 | Annotator 2 | |||
|---|---|---|---|---|
| System | RNN | Transformer | RNN | Transformer |
| Total Errors | 41 | 23 | 43 | 23 |
| RNN | NMT | |
|---|---|---|
| Error Type | Error | Error |
| Non-translation | 0 | 0 |
| Accuracy | ||
| Addition | 10 | 4 |
| Omission | 12 | 12 |
| Mistranslation | 26 | 14 |
| Untranslated text | 4 | 1 |
| Fluency | ||
| Punctuation | 5 | 4 |
| Spelling | 1 | 0 |
| Grammar | 20 | 11 |
| Register | 2 | 0 |
| Inconsistency | 2 | 0 |
| Character Encoding | 0 | 0 |
| Total errors | 82 | 46 |
| Source Language (English) | Reference Human Translation (Irish) |
|---|---|
| A clear harmonised procedure, including the necessary criteria for disease–free status, should be established for that purpose. | Ba cheart nós imeachta comhchuibhithe soiléir, lena n-áirítear na critéir is gá do stádas saor ó ghalar, a bhunú chun na críche sin. |
| the mark is applied anew, as appropriate. | déanfar an mharcáil arís, mar is iomchuí. |
| If the court decides that a review is justified on any of the grounds set out in paragraph 1, the judgment given in the European Small Claims Procedure shall be null and void. | Má chinneann an chúirt go bhfuil bonn cirt le hathbhreithniú de bharr aon cheann de na forais a leagtar amach i mír 1, beidh an breithiúnas a tugadh sa Nós Imeachta Eorpach um Éilimh Bheaga ar neamhní go hiomlán. |
| households where pet animals are kept; | teaghlaigh ina gcoimeádtar peataí; |
| Transformer (16k BPE) | BLEU ↑ | Google Translate | BLEU ↑ |
|---|---|---|---|
| Ba cheart nós imeachta soiléir comhchuibhithe, lena n-áirítear na critéir is gá maidir le stádas saor ó ghalair, a bhunú chun na críche sin. | 61.6 | Ba cheart nós imeachta comhchuibhithe soiléir, lena n-áirítear na critéir riachtanacha maidir le stádas saor ó ghalair, a bhunú chun na críche sin. | 70.2 |
| go gcuirtear an marc i bhfeidhme, de réir mar is iomchuí. | 21.4 | cuirtear an marc i bhfeidhm as an nua, de réir mar is cuí. | 6.6 |
| Má chinneann an chúirt go bhfuil bonn cirt le hathbhreithniú ar aon cheann de na forais a leagtar amach i mír 1, beidh an breithiúnas a thugtar sa Nós Imeachta Eorpach um Éilimh Bheaga ar neamhní. | 77.3 | Má chinneann an chúirt go bhfuil údar le hathbhreithniú ar aon cheann de na forais atá leagtha amach i mír 1, beidh an breithiúnas a thugtar sa Nós Imeachta Eorpach um Éilimh Bheaga ar neamhní | 59.1 |
| teaghlaigh ina gcoimeádtar peataí; | 100 | teaghlaigh ina gcoinnítear peataí; | 30.2 |
| Type | Sentence |
|---|---|
| EN-1 | The lead supervisory authority may request at any time other supervisory authorities concerned to provide mutual assistance pursuant to Article 61 and may conduct joint operations pursuant to Article 62, in particular for carrying out investigations or for monitoring the implementation of a measure concerning a controller or processor established in another Member State. |
| GA-1 | Féadfaidh an príomhúdarás maoirseachta iarraidh, tráth ar bith, ar bith eile lena mbaineann cúnamh frithpháirteach a chur ar fáil de bhun Airteagal 61 agus féadfaidh sé oibríochtaí comhpháirteacha a dhéanamh de bhun Airteagal 62, go háirithe maidir le himscrúduithe a dhéanamh nó maidir le faireachán a dhéanamh ar chur chun feidhme beart i ndáil le rialaitheoir nó próiseálaí atá bunaithe i mBallstát eile. |
| EN-2 | The Office shall mention the judgment in the Register and shall take the necessary measures to comply with its operative part. |
| GA-2 | Luafaidh an Oifig an breithiúnas sa Chlár agus glacfaidh sí na bearta is gá chun cloí lena chuid oibríochtúil. |
| EN-3 | The competent authority may at any time wholly or partially suspend or terminate the contract awarded under this provision if the operator fails to meet the performance requirements. |
| GA-3 | Féadfaidh an t-údarás inniúil an conradh a dámhadh faoin bhforáil seo a chur ar fionraí nó a fhoirceannadh go hiomlán nó go páirteach má mhainníonn an t-oibreoir na ceanglais feidhmíochta a chomhlíonadh. |
| EN-4 | This Directive shall enter into force on the day following that of its publication in the Official Journal of the European Union. |
| GA-4 | Tiocfaidh an Treoir seo i bhfeidhm an lá tar éis lá a fhoilsithe in Iris Oifigiúil an Aontais Eorpaigh. |
| EN-5 | Such special measures are interim in nature, and shall not be subject to the conditions set out in Article 7(1) and (2). |
| GA-5 | Tá bearta speisialta den sórt sin eatramhach, agus ní bheidh said faoi réir na gcoinníollacha a leagtar amach in Airteagal 7(1) agus (2) iad. |
| Approach | BLEU ↑ | SQM ↑ | MQM ↑ |
|---|---|---|---|
| Transformer | 60.5 | 4.53 | 77.92 |
| RNN | 52.7 | 3.30 | 43.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lankford, S.; Afli, H.; Way, A. Human Evaluation of English–Irish Transformer-Based NMT. Information 2022, 13, 309. https://doi.org/10.3390/info13070309
Lankford S, Afli H, Way A. Human Evaluation of English–Irish Transformer-Based NMT. Information. 2022; 13(7):309. https://doi.org/10.3390/info13070309
Chicago/Turabian StyleLankford, Séamus, Haithem Afli, and Andy Way. 2022. "Human Evaluation of English–Irish Transformer-Based NMT" Information 13, no. 7: 309. https://doi.org/10.3390/info13070309
APA StyleLankford, S., Afli, H., & Way, A. (2022). Human Evaluation of English–Irish Transformer-Based NMT. Information, 13(7), 309. https://doi.org/10.3390/info13070309