
Facial Emotion Recognition Using Conventional Machine Learning and Deep Learning Methods: Current Achievements, Analysis and Remaining Challenges


Abstract
:1. Introduction
Main Contributions
- The main focus is to provide a general understanding of the recent research and help newcomers to understand the essential modules and trends in the FER field.
- We present the use of several standard datasets consisting of video sequences and images with different characteristics and purposes.
- We compare DL and conventional ML approaches for FER in terms of resource utilization and accuracy. The DL-based approaches provide a high degree of accuracy but consume more time in training and require substantial processing capabilities, i.e., CPU and GPU. Thus, recently, several FER approaches have been used in an embedded system, e.g., Raspberry Pi, Jetson Nano, smartphones, etc.
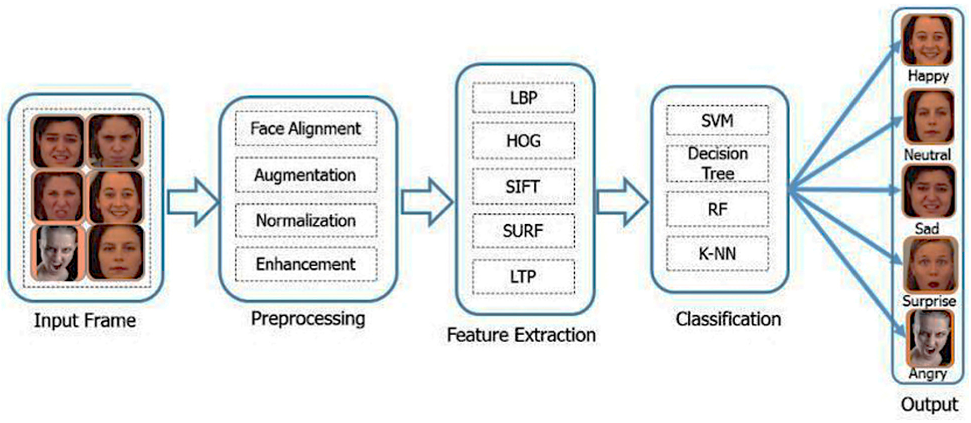
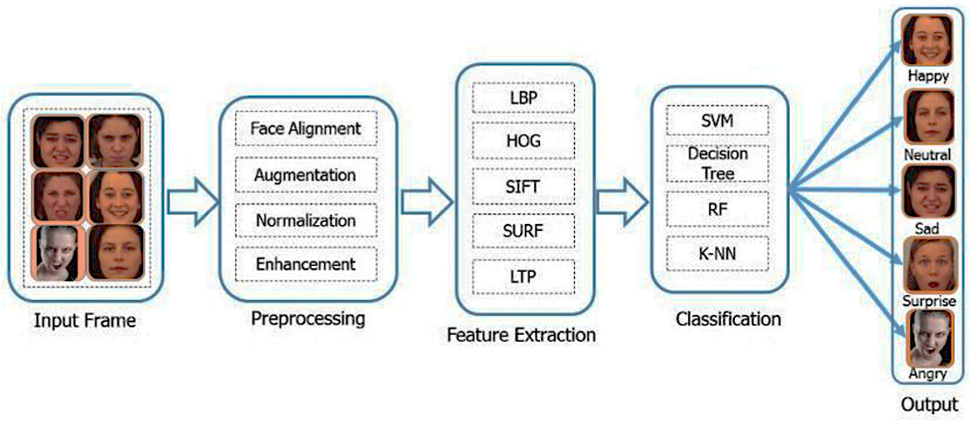
2. Facial Emotion Recognition Using Traditional Machine Learning Approaches
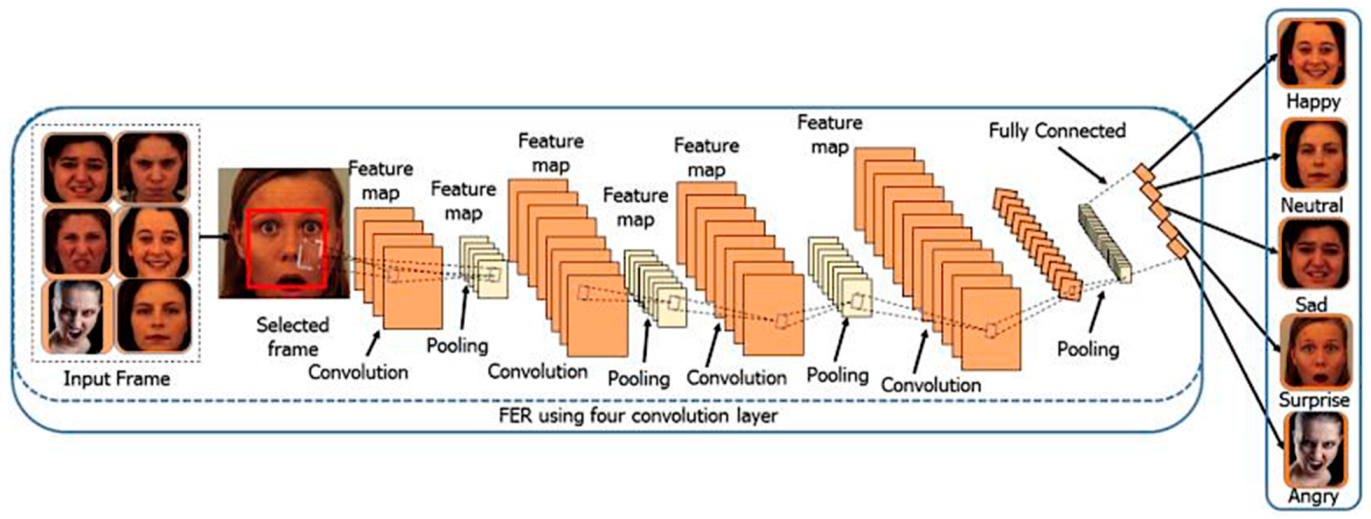
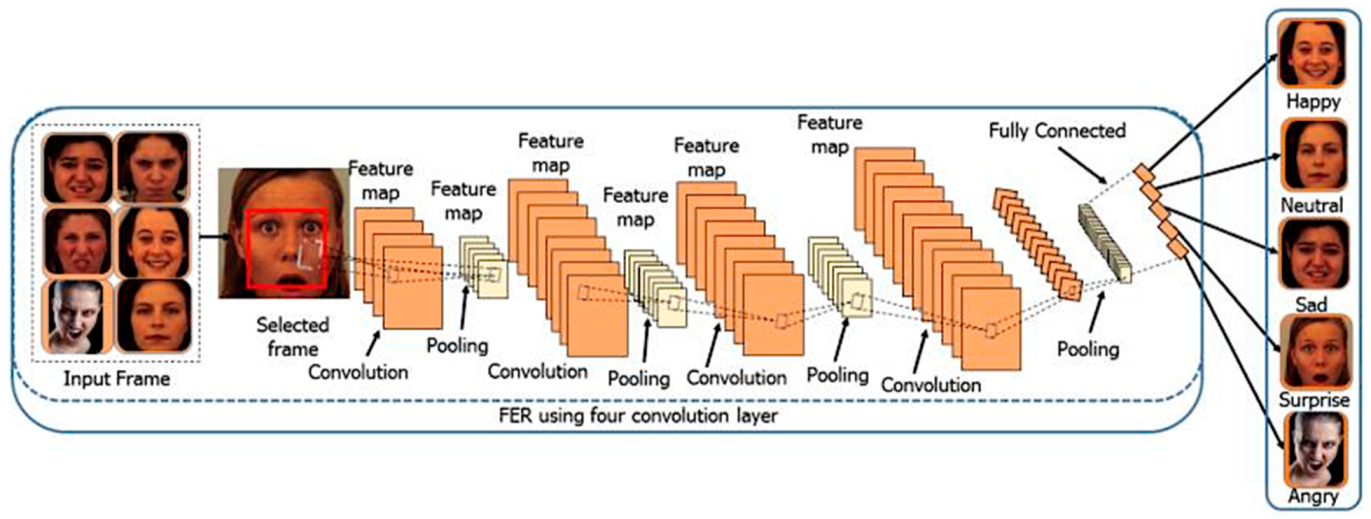
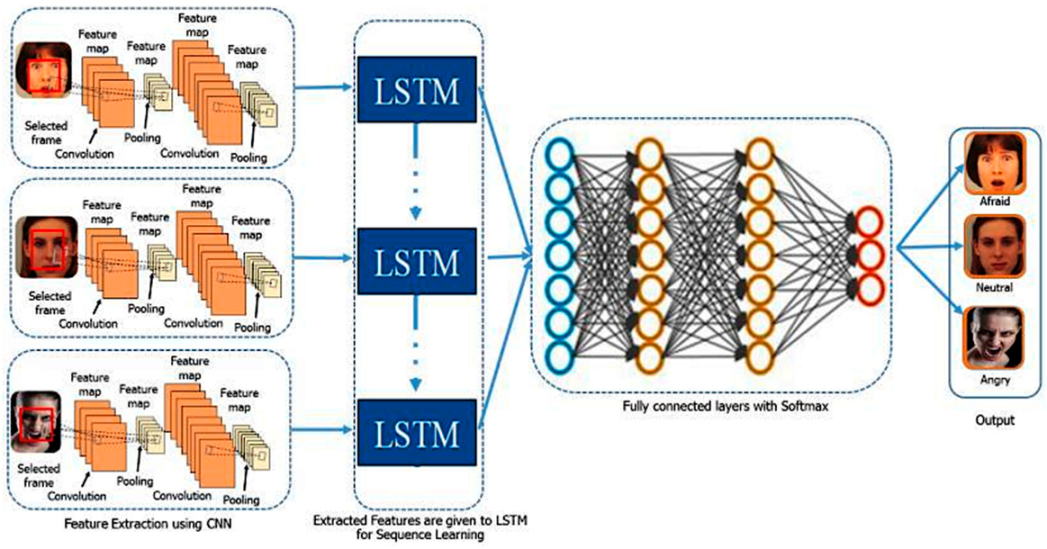
3. Facial Emotion Recognition Using Deep-Learning-Based Approaches
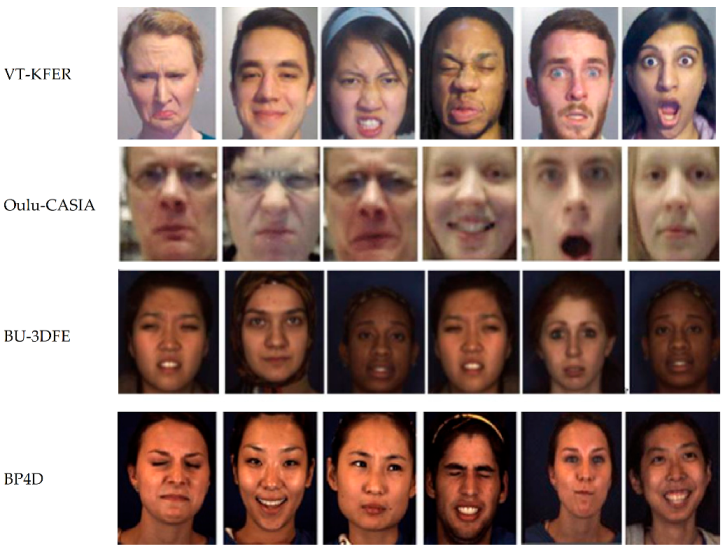
4. Facial Emotion Datasets
- The CK+ Cohen Kanade Dataset:
- Bosphorus dataset
- A rich collection of facial emotions is included:
- Per person, at least 35 facial emotions are recoded;
- FACS scoring;
- Each third person is a professional actresses/actors.
- Systematic head poses are included.
- A variety of facial occlusions are included (eyeglasses, hands, hair, moustaches and beards).
- SMIC dataset
- BBC dataset
5. Performance Evaluation of FER
6. Evaluation Metrics/Performance Parameters
Comparisons on Benchmark Datasets
- As the framework becomes increasingly deeper for preparation, a large-scale dataset and significant computational resources are needed.
- Significant quantities of datasets that are manually compiled and labeled are required.
- A significant amount of memory is required for experiments and testing, which is time-consuming.
7. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jabeen, S.; Mehmood, Z.; Mahmood, T.; Saba, T.; Rehman, A.; Mahmood, M.T. An effective content-based image retrieval technique for image visuals representation based on the bag-of-visual-words model. PLoS ONE 2018, 13, e0194526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moret-Tatay, C.; Wester, A.G.; Gamermann, D. To Google or not: Differences on how online searches predict names and faces. Mathematics 2020, 8, 1964. [Google Scholar] [CrossRef]
- Ubaid, M.T.; Khalil, M.; Khan, M.U.G.; Saba, T.; Rehman, A. Beard and Hair Detection, Segmentation and Changing Color Using Mask R-CNN. In Proceedings of the International Conference on Information Technology and Applications, Dubai, United Arab Emirates, 13–14 November 2021; Springer: Singapore, 2022; pp. 63–73. [Google Scholar]
- Meethongjan, K.; Dzulkifli MRehman, A.; Altameem, A.; Saba, T. An intelligent fused approach for face recognition. J. Intell. Syst. 2013, 22, 197–212. [Google Scholar] [CrossRef]
- Elarbi-Boudihir, M.; Rehman, A.; Saba, T. Video motion perception using optimized Gabor filter. Int. J. Phys. Sci. 2011, 6, 2799–2806. [Google Scholar]
- Joudaki, S.; Rehman, A. Dynamic hand gesture recognition of sign language using geometric features learning. Int. J. Comput. Vis. Robot. 2022, 12, 1–16. [Google Scholar] [CrossRef]
- Abunadi, I.; Albraikan, A.A.; Alzahrani, J.S.; Eltahir, M.M.; Hilal, A.M.; Eldesouki, M.I.; Motwakel, A.; Yaseen, I. An Automated Glowworm Swarm Optimization with an Inception-Based Deep Convolutional Neural Network for COVID-19 Diagnosis and Classification. Healthcare 2022, 10, 697. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Khan, Z.A.; Koundal, D.; Lee, M.Y.; Baik, S.W. Vision sensor-based real-time fire detection in resource-constrained IoT environments. Comput. Intell. Neurosci. 2021, 2021, 5195508. [Google Scholar] [CrossRef]
- Yasin, M.; Cheema, A.R.; Kausar, F. Analysis of Internet Download Manager for collection of digital forensic artefacts. Digit. Investig. 2010, 7, 90–94. [Google Scholar] [CrossRef]
- Rehman, A.; Alqahtani, S.; Altameem, A.; Saba, T. Virtual machine security challenges: Case studies. Int. J. Mach. Learn. Cybern. 2014, 5, 729–742. [Google Scholar] [CrossRef]
- Afza, F.; Khan, M.A.; Sharif, M.; Kadry, S.; Manogaran, G.; Saba, T.; Ashraf, I.; Damaševičius, R. A framework of human action recognition using length control features fusion and weighted entropy-variances based feature selection. Image Vis. Comput. 2021, 106, 104090. [Google Scholar] [CrossRef]
- Rehman, A.; Khan, M.A.; Saba, T.; Mehmood, Z.; Tariq, U.; Ayesha, N. Microscopic brain tumor detection and classification using 3D CNN and feature selection architecture. Microsc. Res. Tech. 2021, 84, 133–149. [Google Scholar] [CrossRef]
- Haji, M.S.; Alkawaz, M.H.; Rehman, A.; Saba, T. Content-based image retrieval: A deep look at features prospectus. Int. J. Comput. Vis. Robot. 2019, 9, 14–38. [Google Scholar] [CrossRef]
- Alkawaz, M.H.; Mohamad, D.; Rehman, A.; Basori, A.H. Facial animations: Future research directions & challenges. 3D Res. 2014, 5, 12. [Google Scholar]
- Saleem, S.; Khan, M.; Ghani, U.; Saba, T.; Abunadi, I.; Rehman, A.; Bahaj, S.A. Efficient facial recognition authentication using edge and density variant sketch generator. CMC-Comput. Mater. Contin. 2022, 70, 505–521. [Google Scholar] [CrossRef]
- Rahim, M.S.M.; Rad, A.E.; Rehman, A.; Altameem, A. Extreme facial expressions classification based on reality parameters. 3D Res. 2014, 5, 22. [Google Scholar] [CrossRef]
- Rashid, M.; Khan, M.A.; Alhaisoni, M.; Wang, S.H.; Naqvi, S.R.; Rehman, A.; Saba, T. A sustainable deep learning framework for object recognition using multi-layers deep features fusion and selection. Sustainability 2020, 12, 5037. [Google Scholar] [CrossRef]
- Lung, J.W.J.; Salam, M.S.H.; Rehman, A.; Rahim, M.S.M.; Saba, T. Fuzzy phoneme classification using multi-speaker vocal tract length normalization. IETE Tech. Rev. 2014, 31, 128–136. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.; Raza, M.; Saba, T.; Sial, R.; Shad, S.A. Brain tumor detection: A long short-term memory (LSTM)-based learning model. Neural Comput. Appl. 2020, 32, 15965–15973. [Google Scholar] [CrossRef]
- Kołakowska, A. A review of emotion recognition methods based on keystroke dynamics and mouse movements. In Proceedings of the 6th IEEE International Conference on Human System Interactions (HSI), Sopot, Poland, 6–8 June 2013; pp. 548–555. [Google Scholar]
- Ghayoumi, M. A quick review of deep learning in facial expression. J. Commun. Comput. 2017, 14, 34–38. [Google Scholar]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef]
- Sharif, M.; Naz, F.; Yasmin, M.; Shahid, M.A.; Rehman, A. Face recognition: A survey. J. Eng. Sci. Technol. Rev. 2017, 10, 166–177. [Google Scholar] [CrossRef]
- Khan, M.Z.; Jabeen, S.; Khan, M.U.G.; Saba, T.; Rehmat, A.; Rehman, A.; Tariq, U. A realistic image generation of face from text description using the fully trained generative adversarial networks. IEEE Access 2020, 9, 1250–1260. [Google Scholar] [CrossRef]
- Cornejo, J.Y.R.; Pedrini, H.; Flórez-Revuelta, F. Facial expression recognition with occlusions based on geometric representation. In Iberoamerican Congress on Pattern Recognition; Springer: Cham, Switzerland, 2015; pp. 263–270. [Google Scholar]
- Mahata, J.; Phadikar, A. Recent advances in human behaviour understanding: A survey. In Proceedings of the Devices for Integrated Circuit (DevIC), Kalyani, India, 23–24 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 751–755. [Google Scholar]
- Siddiqi, M.H.; Ali, R.; Khan, A.M.; Kim, E.S.; Kim, G.J.; Lee, S. Facial expression recognition using active contour-based face detection, facial movement-based feature extraction, and non-linear feature selection. Multimed. Syst. 2015, 21, 541–555. [Google Scholar] [CrossRef]
- Varma, S.; Shinde, M.; Chavan, S.S. Analysis of PCA and LDA features for facial expression recognition using SVM and HMM classifiers. In Techno-Societal 2018; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Reddy, C.V.R.; Reddy, U.S.; Kishore, K.V.K. Facial Emotion Recognition Using NLPCA and SVM. Traitement du Signal 2019, 36, 13–22. [Google Scholar] [CrossRef] [Green Version]
- Sajjad, M.; Nasir, M.; Ullah, F.U.M.; Muhammad, K.; Sangaiah, A.K.; Baik, S.W. Raspberry Pi assisted facial expression recognition framework for smart security in law-enforcement services. Inf. Sci. 2019, 479, 416–431. [Google Scholar] [CrossRef]
- Nazir, M.; Jan, Z.; Sajjad, M. Facial expression recognition using histogram of oriented gradients based transformed features. Clust. Comput. 2018, 21, 539–548. [Google Scholar] [CrossRef]
- Zeng, N.; Zhang, H.; Song, B.; Liu, W.; Li, Y.; Dobaie, A.M. Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 2018, 273, 643–649. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M.; Almogren, A.; Zuair, M.; Fortino, G.; Torresen, J. A facial expression recognition system using robust face features from depth videos and deep learning. Comput. Electr. Eng. 2017, 63, 114–125. [Google Scholar] [CrossRef]
- Al-Agha, S.A.; Saleh, H.H.; Ghani, R.F. Geometric-based feature extraction and classification for emotion expressions of 3D video film. J. Adv. Inf. Technol. 2017, 8, 74–79. [Google Scholar] [CrossRef]
- Ghimire, D.; Lee, J.; Li, Z.N.; Jeong, S. Recognition of facial expressions based on salient geometric features and support vector machines. Multimed. Tools Appl. 2017, 76, 7921–7946. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Yang, H. Face detection based on template matching and 2DPCA algorithm. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; pp. 575–579. [Google Scholar]
- Wu, P.P.; Liu, H.; Zhang, X.W.; Gao, Y. Spontaneous versus posed smile recognition via region-specific texture descriptor and geometric facial dynamics. Front. Inf. Technol. Electron. Eng. 2017, 18, 955–967. [Google Scholar] [CrossRef]
- Acevedo, D.; Negri, P.; Buemi, M.E.; Fernández, F.G.; Mejail, M. A simple geometric-based descriptor for facial expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 802–808. [Google Scholar]
- Kim, D.J. Facial expression recognition using ASM-based post-processing technique. Pattern Recognit. Image Anal. 2016, 26, 576–581. [Google Scholar] [CrossRef]
- Chang, K.Y.; Chen, C.S.; Hung, Y.P. Intensity rank estimation of facial expressions based on a single image. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Manchester, UK, 13–16 October 2013; pp. 3157–3162. [Google Scholar]
- Abbas, N.; Saba, T.; Mohamad, D.; Rehman, A.; Almazyad, A.S.; Al-Ghamdi, J.S. Machine aided malaria parasitemia detection in Giemsa-stained thin blood smears. Neural Comput. Appl. 2018, 29, 803–818. [Google Scholar] [CrossRef]
- Iqbal, S.; Khan, M.U.G.; Saba, T.; Mehmood, Z.; Javaid, N.; Rehman, A.; Abbasi, R. Deep learning model integrating features and novel classifiers fusion for brain tumor segmentation. Microsc. Res. Tech. 2019, 82, 1302–1315. [Google Scholar] [CrossRef]
- Khan, M.A.; Kadry, S.; Zhang, Y.D.; Akram, T.; Sharif, M.; Rehman, A.; Saba, T. Prediction of COVID-19-pneumonia based on selected deep features and one class kernel extreme learning machine. Comput. Electr. Eng. 2021, 90, 106960. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharif, M.I.; Raza, M.; Anjum, A.; Saba, T.; Shad, S.A. Skin lesion segmentation and classification: A unified framework of deep neural network features fusion and selection. Expert Syst. 2019, e12497. [Google Scholar] [CrossRef]
- Nawaz, M.; Mehmood, Z.; Nazir, T.; Naqvi, R.A.; Rehman, A.; Iqbal, M.; Saba, T. Skin cancer detection from dermoscopic images using deep learning and fuzzy k-means clustering. Microsc. Res. Tech. 2022, 85, 339–351. [Google Scholar] [CrossRef]
- Rehman, A.; Abbas, N.; Saba, T.; Mehmood, Z.; Mahmood, T.; Ahmed, K.T. Microscopic malaria parasitemia diagnosis and grading on benchmark datasets. Microsc. Res. Tech. 2018, 81, 1042–1058. [Google Scholar] [CrossRef]
- Saba, T.; Haseeb, K.; Ahmed, I.; Rehman, A. Secure and energy-efficient framework using Internet of Medical Things for e-healthcare. J. Infect. Public Health 2020, 13, 1567–1575. [Google Scholar] [CrossRef]
- Saba, T.; Bokhari ST, F.; Sharif, M.; Yasmin, M.; Raza, M. Fundus image classification methods for the detection of glaucoma: A review. Microsc. Res. Tech. 2018, 81, 1105–1121. [Google Scholar] [CrossRef]
- Saba, T. Automated lung nodule detection and classification based on multiple classifiers voting. Microsc. Res. Tech. 2019, 8, 1601–1609. [Google Scholar] [CrossRef]
- Sadad, T.; Munir, A.; Saba, T.; Hussain, A. Fuzzy C-means and region growing based classification of tumor from mammograms using hybrid texture feature. J. Comput. Sci. 2018, 29, 34–45. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.; Yasmin, M.; Saba, T.; Anjum, M.A.; Fernandes, S.L. A new approach for brain tumor segmentation and classification based on score level fusion using transfer learning. J. Med. Syst. 2019, 43, 326. [Google Scholar] [CrossRef]
- Javed, R.; Rahim, M.S.M.; Saba, T.; Rehman, A. A comparative study of features selection for skin lesion detection from dermoscopic images. Netw. Modeling Anal. Health Inform. Bioinform. 2020, 9, 4. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; See, J.; Liu, W. Micro-expression recognition based on 3D flow convolutional neural network. Pattern Anal. Appl. 2019, 22, 1331–1339. [Google Scholar] [CrossRef]
- Li, B.Y.; Mian, A.S.; Liu, W.; Krishna, A. Using kinect for face recognition under varying poses, expressions, illumination and disguise. In Proceedings of the IEEE workshop on applications of computer vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 186–192. [Google Scholar]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Processing 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Lopes, A.T.; De Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with Convolutional Neural Networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Breuer, R.; Kimmel, R. A deep learning perspective on the origin of facial expressions. arXiv 2017, arXiv:1705.01842. [Google Scholar]
- Chu, W.S.; De La Torre, F.; Cohn, J.F. Learning spatial and temporal cues for multi-label facial action unit detection. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 25–32. [Google Scholar]
- Hasani, B.; Mahoor, M.H. Facial expression recognition using enhanced deep 3D convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 30–40. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Processing 2017, 26, 4193–4203. [Google Scholar] [CrossRef]
- Jain, D.K.; Zhang ZHuang, K. Multi angle optimal pattern-based deep learning for automatic facial expression recognition. Pattern Recognit. Lett. 2020, 139, 157–165. [Google Scholar] [CrossRef]
- Al-Shabi, M.; Cheah, W.P.; Connie, T. Facial Expression Recognition Using a Hybrid CNN-SIFT Aggregator. arXiv 2016, arXiv:1608.02833. [Google Scholar]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2983–2991. [Google Scholar]
- Yu, Z.; Zhang, C. Image based static facial expression recognition with multiple deep network learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 435–442. [Google Scholar]
- Li, K.; Jin, Y.; Akram, M.W.; Han, R.; Chen, J. Facial expression recognition with convolutional neural networks via a new face cropping and rotation strategy. Vis. Comput. 2020, 36, 391–404. [Google Scholar] [CrossRef]
- Xie, S.; Hu, H.; Wu, Y. Deep multi-path convolutional neural network joint with salient region attention for facial expression recognition. Pattern Recognit. 2019, 92, 177–191. [Google Scholar] [CrossRef]
- Nasir, I.M.; Raza, M.; Shah, J.H.; Khan, M.A.; Rehman, A. Human action recognition using machine learning in uncontrolled environment. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 182–187. [Google Scholar]
- Rehman, A.; Haseeb, K.; Saba, T.; Lloret, J.; Tariq, U. Secured Big Data Analytics for Decision-Oriented Medical System Using Internet of Things. Electronics 2021, 10, 1273. [Google Scholar] [CrossRef]
- Harouni, M.; Rahim, M.S.M.; Al-Rodhaan, M.; Saba, T.; Rehman, A.; Al-Dhelaan, A. Online Persian/Arabic script classification without contextual information. Imaging Sci. J. 2014, 62, 437–448. [Google Scholar] [CrossRef]
- Iftikhar, S.; Fatima, K.; Rehman, A.; Almazyad, A.S.; Saba, T. An evolution based hybrid approach for heart diseases classification and associated risk factors identification. Biomed. Res. 2017, 28, 3451–3455. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the IEEE computer society conference on computer vision and pattern recognition-workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Jamal, A.; Hazim Alkawaz, M.; Rehman, A.; Saba, T. Retinal imaging analysis based on vessel detection. Microsc. Res. Tech. 2017, 80, 799–811. [Google Scholar] [CrossRef]
- Neamah, K.; Mohamad, D.; Saba, T.; Rehman, A. Discriminative features mining for offline handwritten signature verification. 3D Res. 2014, 5, 2. [Google Scholar] [CrossRef]
- Ramzan, F.; Khan, M.U.G.; Iqbal, S.; Saba, T.; Rehman, A. Volumetric segmentation of brain regions from MRI scans using 3D convolutional neural networks. IEEE Access 2020, 8, 103697–103709. [Google Scholar] [CrossRef]
- Keltner, D.; Sauter, D.; Tracy, J.; Cowen, A. Emotional expression: Advances in basic emotion theory. J. Nonverbal Behav. 2019, 43, 133–160. [Google Scholar] [CrossRef]
- Phetchanchai, C.; Selamat, A.; Rehman, A.; Saba, T. Index financial time series based on zigzag-perceptually important points. J. Comput. Sci. 2010, 6, 1389–1395. [Google Scholar]
- Saba, T.; Rehman, A.; Altameem, A.; Uddin, M. Annotated comparisons of proposed preprocessing techniques for script recognition. Neural Comput. Appl. 2014, 25, 1337–1347. [Google Scholar] [CrossRef]
- Saba, T.; Altameem, A. Analysis of vision based systems to detect real time goal events in soccer videos. Appl. Artif. Intell. 2013, 27, 656–667. [Google Scholar] [CrossRef]
- Ullah, H.; Saba, T.; Islam, N.; Abbas, N.; Rehman, A.; Mehmood, Z.; Anjum, A. An ensemble classification of exudates in color fundus images using an evolutionary algorithm based optimal features selection. Microsc. Res. Tech. 2019, 82, 361–372. [Google Scholar] [CrossRef] [PubMed]
- Sharif, U.; Mehmood, Z.; Mahmood, T.; Javid, M.A.; Rehman, A.; Saba, T. Scene analysis and search using local features and support vector machine for effective content-based image retrieval. Artif. Intell. Rev. 2019, 52, 901–925. [Google Scholar] [CrossRef]
- Yousaf, K.; Mehmood, Z.; Saba, T.; Rehman, A.; Munshi, A.M.; Alharbey, R.; Rashid, M. Mobile-health applications for the efficient delivery of health care facility to people with dementia (PwD) and support to their carers: A survey. BioMed Res. Int. 2019, 2019, 7151475. [Google Scholar] [CrossRef]
- Saba, T.; Rehman, A.; Al-Dhelaan, A.; Al-Rodhaan, M. Evaluation of current documents image denoising techniques: A comparative study. Appl. Artif. Intell. 2014, 28, 879–887. [Google Scholar] [CrossRef]
- Saba, T.; Rehman, A.; Sulong, G. Improved statistical features for cursive character recognition. Int. J. Innov. Comput. Inf. Control. 2011, 7, 5211–5224. [Google Scholar]
- Rehman, A.; Saba, T. Document skew estimation and correction: Analysis of techniques, common problems and possible solutions. Appl. Artif. Intell. 2011, 25, 769–787. [Google Scholar] [CrossRef]
- Rehman, A.; Kurniawan, F.; Saba, T. An automatic approach for line detection and removal without smash-up characters. Imaging Sci. J. 2011, 59, 177–182. [Google Scholar] [CrossRef]
- Saba, T.; Javed, R.; Shafry, M.; Rehman, A.; Bahaj, S.A. IoMT Enabled Melanoma Detection Using Improved Region Growing Lesion Boundary Extraction. CMC-Comput. Mater. Contin. 2022, 71, 6219–6237. [Google Scholar] [CrossRef]
- Yousaf, K.; Mehmood, Z.; Awan, I.A.; Saba, T.; Alharbey, R.; Qadah, T.; Alrige, M.A. A comprehensive study of mobile-health based assistive technology for the healthcare of dementia and Alzheimer’s disease (AD). Health Care Manag. Sci. 2020, 23, 287–309. [Google Scholar] [CrossRef]
- Ahmad, A.M.; Sulong, G.; Rehman, A.; Alkawaz, M.H.; Saba, T. Data hiding based on improved exploiting modification direction method and Huffman coding. J. Intell. Syst. 2014, 23, 451–459. [Google Scholar] [CrossRef]
- Rahim MS, M.; Rehman, A.; Kurniawan, F.; Saba, T. Ear biometrics for human classification based on region features mining. Biomed. Res. 2017, 28, 4660–4664. [Google Scholar]
- Rahim, M.S.M.; Norouzi ARehman, A.; Saba, T. 3D bones segmentation based on CT images visualization. Biomed. Res. 2017, 28, 3641–3644. [Google Scholar]
- Nodehi, A.; Sulong, G.; Al-Rodhaan, M.; Al-Dhelaan, A.; Rehman, A.; Saba, T. Intelligent fuzzy approach for fast fractal image compression. EURASIP J. Adv. Signal Processing 2014, 2014, 112. [Google Scholar] [CrossRef] [Green Version]
- Haron, H.; Rehman, A.; Adi DI, S.; Lim, S.P.; Saba, T. Parameterization method on B-spline curve. Math. Probl. Eng. 2012, 2012, 640472. [Google Scholar] [CrossRef] [Green Version]
- Rehman, A.; Saba, T. Performance analysis of character segmentation approach for cursive script recognition on benchmark database. Digit. Signal Processing 2011, 21, 486–490. [Google Scholar] [CrossRef]
- Yousuf, M.; Mehmood, Z.; Habib, H.A.; Mahmood, T.; Saba, T.; Rehman, A.; Rashid, M. A novel technique based on visual words fusion analysis of sparse features for effective content-based image retrieval. Math. Probl. Eng. 2018, 2018, 13. [Google Scholar] [CrossRef]
- Saba, T.; Khan, S.U.; Islam, N.; Abbas, N.; Rehman, A.; Javaid, N.; Anjum, A. Cloud-based decision support system for the detection and classification of malignant cells in breast cancer using breast cytology images. Microsc. Res. Tech. 2019, 82, 775–785. [Google Scholar] [CrossRef]
- Yang, B.; Cao, J.M.; Jiang, D.P.; Lv, J.D. Facial expression recognition based on dual-feature fusion and improved random forest classifier. Multimed. Tools Appl. 2017, 9, 20477–20499. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Datasets | Decision Methods | Features | Emotions Analyzed |
|---|---|---|---|---|
| Varma et al. [28] | FECR | support vector machine (SVM) classifier and HMM | PCA and LDA | Six emotions |
| Reddy et al. [29] | CK+ | support vector machine (SVM) classifier | Haar Wavelet Transform (HWT), Gabor wavelets and nonlinear principal component analysis (NLPCA) | Six emotions |
| Sajjad et al. [30] | MMI JAFFE CK+ | support vector machine (SVM) classifier | ORB SIFT SURF | Seven emotions |
| Nazir et al. [31] | CK+ MMI | KNN, SMO and MLP for classification | HOG, DCT | Seven emotions |
| Zeng et al. [32] | CK+ | DSAE | LBP, SIFT, Gabor Function and HOG | Seven emotions |
| Uddin et al. [33] | Real-time dataset from visual depth camera | Deep Belief Network (DBN) | MLDP-GDA features | Six emotions |
| Al-Agha et al. [34] | BOSPHORUS | Euclidean distance | Geometric descriptor | Four emotions |
| Ghimire et al. [35] | CK+ MMI MUG | EBGM, KLT and AdaBoost-ELM | Salient geometric features | Seven emotions |
| Wang and Yang [36] | BVTKFER BCurtinFaces | random forest classifier | LBP | Six emotions |
| Wu et al. [37] | BBC, SPOS MMI UvANEMO | support vector machine (SVM) | RSTD, four conventional features—raw pixels, Gabor, HOG and LBP | Two emotions Smile (genuine and fake) |
| Acevedo et al. [38] | CK+ | Conditional Random Field (CRF) and KNN | Geometric descriptor | Seven emotions |
| Kim [39] | CK JAFFE | embedded hidden Markov model (EHMM) | ASM and 2D DCT | Seven emotions |
| Cornejo et al. [25] | CK+ JAFFE MUG | PCA, LDA, K-NN and SVM | Gabor wavelets and geometric features | Seven emotions |
| Siddiqi et al. [27] | CK JAFFE USTCNVIE Yale FEI | hidden Markov model (HMM) | Chan–Vese energy function, Bhattacharyya distance function wavelet decomposition and SWLDA | Six emotions |
| Chang et al. [40] | CK+ | Support Vector Regression (SVR) | feature descriptors, AAMs, Gabor wavelets | Seven emotions |
| References | Datasets | Methods | Emotions Analyzed |
|---|---|---|---|
| Li et al. [65] | CK+ JAFFE | convolutional neural network (CNN) | Seven emotions |
| Jain et al. [61] | CK+ MMI | For the facial label prediction, they used LSTM-CNN | Six emotions |
| Li et al. [53] | SMIC CASME CASME II | 3D flow-based CNN model for video-based micro-expression recognition | Five emotions |
| Xie et al. [66] | CK+ JAFFE | Attention-based SERD and the MPVS-Net | Six emotions |
| Li et al. [55] | RAF-DB AffectNet SFEW CK+ MMI Oulu-CASIA | CNN with ACNN | Seven emotions |
| Lopes et al. [56] | CK+ JAFFE BU-3DFE | CNN and specific image preprocessing steps | Seven emotions |
| Breuer and Kimmel [57] | CK+ FER2013 | CNN with transfer learning | Seven emotions |
| Chu et al. [58] | BP4D | CNN is used to extract spatial representations and LSTMs used for temporal dependencies | Twelve emotions |
| Hasani and Mahoor [59] | CK+ DISFA | LSTM units extracted both temporal and spatial relations from facial images; as inputs of the network, they used facial landmark points | Twenty-three primary and compound emotions |
| Zhang et al. [60] | CK+ Oulu-CASIA MMI | PHRNN and MSCNN | Seven emotions |
| Al-Shabi et al. [62] | CK+ FER-2013 | Dense SIFT and regular SIFT are merged with CNN features | Seven emotions |
| Jung et al. [63] | CK+ Oulu-CASIA | DTAN and DTGN | Seven emotions |
| Yu and Zhang [64] | FER-2013 SFEW | Used an assembly of DCNNs with seven convolution layers | Seven emotions |
| References | Datasets | Accuracy (%) | Techniques |
|---|---|---|---|
| Varma et al. [28] | FECR | 98.40 (SVM) 87.50 (HMM) | PCA and LDA for feature selection and SVM and HMM classifier |
| Reddy et al. [29] | CK+ | 98.00 | Haar Wavelet Transform (HWT), Gabor wavelets and nonlinear principal component analysis (NLPCA) feature extractor and SVM classifier |
| Sajjad et al. [30] | MMI JAFFE CK+ | 99.1 on MMI accuracy (92) on JAFFE accuracy (90) on CK+ | ORB SIFT SURF using SVM |
| Nazir et al. [31] | CK+ MMI | 99.6 by using only 32 features with KNN | HOG, DCT features and KNN, SMO and MLP for classification |
| Zeng et al. [32] | CK+ | 95.79 | LBP, SIFT, Gabor Function and HOG features and Deep Sparse Auto-Encoder (DSAE) classifier |
| Uddin et al. [33] | Real-time dataset from visual depth camera | 96.25 | MLDP-GDA features fed to Deep Belief Network (DBN) for prediction |
| Ghimire et al. [35] | CK+ MMI MUG | 97.80 77.22 95.50 | Salient geometric features and EBGM, KLT and AdaBoost-ELM class |
| Yang et al. [96] | BVT-KFER BCurtinFaces | 93.33 92.50 | LBP features and a random forest classifier |
| Wu et al. [37] | BBC SPOS MMI UvA-NEMO | 90.00 81.25 92.21 93.95 | RSTD, four conventional features—raw pixel, Gabor, HOG and LBP features Support vector machine (SVM) classifiers |
| Acevedo et al. [38] | CK+ | 89.3 86.9 | Geometric descriptor and Conditional Random Field (CRF) and KNN classifier |
| Al-Agha et al. [34] | BOSPHORUS | 85.00 | Geometric descriptor and Euclidean distance is used for the prediction |
| Kim [39] | CK JAFFE | 77.00 64.7 | ASM and 2D DCT features and embedded hidden Markov model (EHMM) |
| Siddiqi et al. [27] | CK JAFFE USTC-NVIE Yale FEI | 99.33 96.50 99.17 99.33 99.50 | Features are extracted by using Chan–Vese energy function, Bhattacharyya distance function wavelet decomposition and SWLDA and hidden Markov model (HMM) is used for prediction |
| Cornejo et al. [25] | CK+ JAFFE MUG | 99.78 99.17 99.94 | Geometric + PCA + LDA + KNN Geometric + PCA + LDA + K − NN Geometric + PCA + LDA + K − NN |
| Chang et al. [40] | CK+ | Mean Error (AAMs 0.316) Mean Error (Gabor 0.349) MAEs (AAMs 0.324) MAEs (Gabor0.651) | feature descriptors, AAMs, Gabor wavelets and support vector regression (SVR) are used for classification |
| References | Datasets | Accuracy (%) | Methods |
|---|---|---|---|
| Li et al. [65] | CK+ JAFFE | 97.38 0.14 SD 97.18 0.30 SD | Convolutional neural network (CNN) |
| Li et al. [55] | SMIC CASME CASME II | 55.49 54.44 59.11 | 3D flow-based CNN model for video-based micro-expression recognition |
| Xie et al. [66] | CK+ JAFFE | With 10-fold cross-validation accuracy 95.88 99.32 | Expressional Region Descriptor (SERD) and Multi-Path Variation-Suppressing Network (MPVS-Net) |
| Li et al. [55] | RAF-DB AffectNet SFEW CK+ MMI Oulu-CASIA | 91.64 | Convolutional neutral network (CNN) with attention mechanism (ACNN) |
| Lopes et al. [56] | CK+ JAFFE BU-3DFE | Average of C6class (96.76) Average of Cbin (98.92) Average of C6class (72.89) Average of Cbin (90.96) Average of C6class (53.44) Average of Cbin (84.48) | Convolutional neural network and specific image preprocessing steps |
| Breuer and Kimmel [57] | CK+ FER2013 | 98.62 ± 0.11 72 ± 10.5 | Convolutional neural network (CNN) with transfer learning |
| Chu et al. [58] | BP4D | Accuracy on 3-fold (53.2) Accuracy on 10-fold (82.5) | Extracted spatial representations by CNN and for temporal dependencies, LSTMs were used |
| Hasani and Mahoor [58] | CK+ DISFA | 89.5 56.0 | Facial landmark points fed to CNN |
| Jain et al. [61] | CK+ MMI | 96.17 98.72 | LSTM CNN using texture patterns for facial expression prediction |
| (Zhang et al. 2017) | CK+ Oulu-CASIA MMI | 97.78 86.25 79.29 | Part-Based Hierarchical Bidirectional Recurrent Neural Network (PHRNN) and Multi-Signal Convolutional Neural Network (MSCNN) |
| Al-Shabi et al. [62] | CK+ FER-2013 | 99.1 73.4 | Dense SIFT and regular SIFT are merged with CNN features |
| Jung et al. [63] | CK+ Oulu-CASIA | 97.25 81.46 | Fusion of deep temporal appearance network (DTAN) and deep temporal geometry network (DTGN) is employed to predict facial expressions |
| Yu and Zhang [64] | SFEW | Validation accuracy 55.96 Test accuracy 61.29 | Assembly of DCNNs with seven convolution layers |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.R. Facial Emotion Recognition Using Conventional Machine Learning and Deep Learning Methods: Current Achievements, Analysis and Remaining Challenges. Information 2022, 13, 268. https://doi.org/10.3390/info13060268
Khan AR. Facial Emotion Recognition Using Conventional Machine Learning and Deep Learning Methods: Current Achievements, Analysis and Remaining Challenges. Information. 2022; 13(6):268. https://doi.org/10.3390/info13060268
Chicago/Turabian StyleKhan, Amjad Rehman. 2022. "Facial Emotion Recognition Using Conventional Machine Learning and Deep Learning Methods: Current Achievements, Analysis and Remaining Challenges" Information 13, no. 6: 268. https://doi.org/10.3390/info13060268
APA StyleKhan, A. R. (2022). Facial Emotion Recognition Using Conventional Machine Learning and Deep Learning Methods: Current Achievements, Analysis and Remaining Challenges. Information, 13(6), 268. https://doi.org/10.3390/info13060268