
A Game Theory Approach for Assisting Humans in Online Information-Sharing


Abstract
1. Introduction
2. Related Work
3. Increasing Information-Sharing Utility Methodology
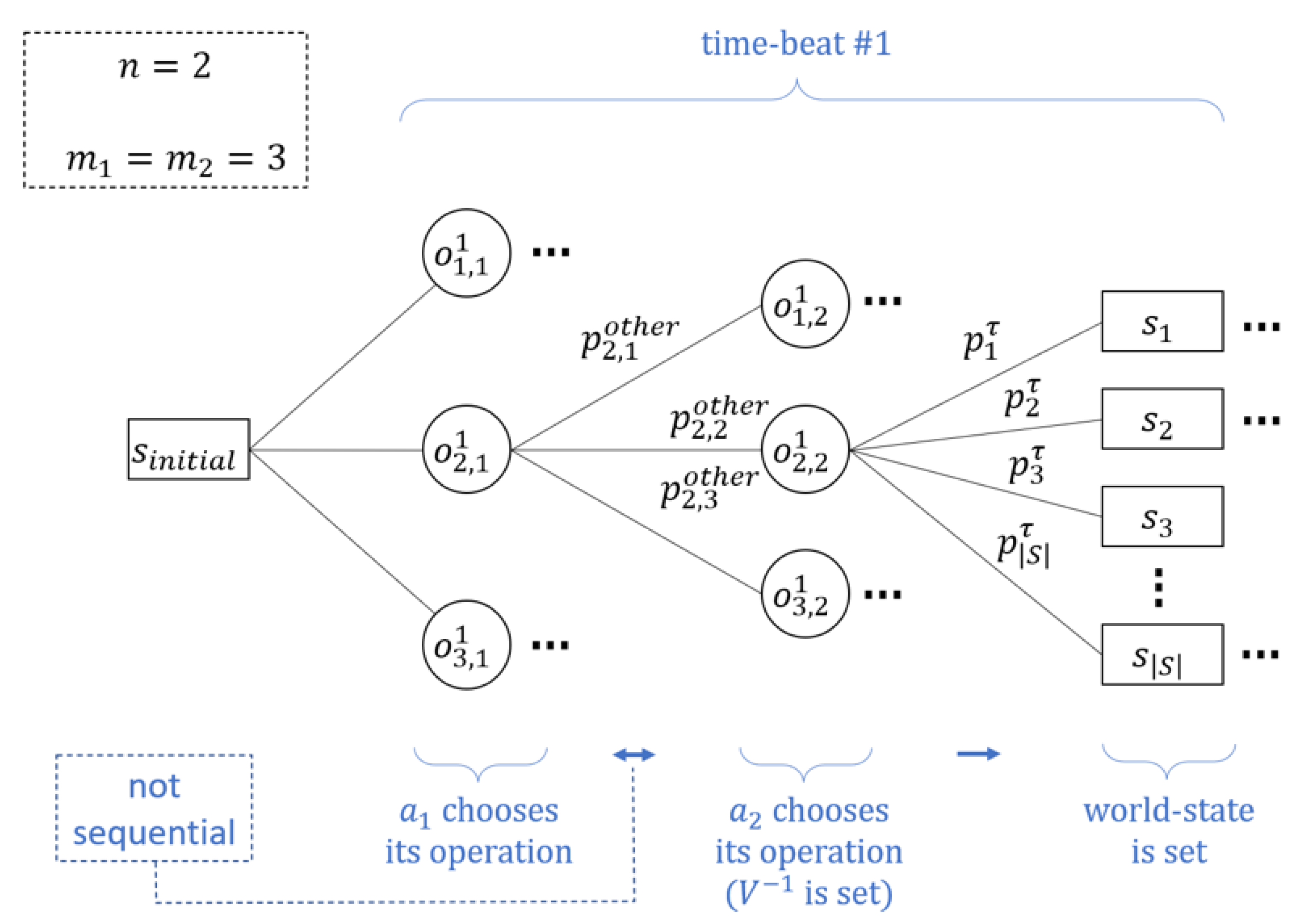
3.1. Model
3.2. Information-Sharing Benefits and Costs
3.3. Game Theoretical Representation
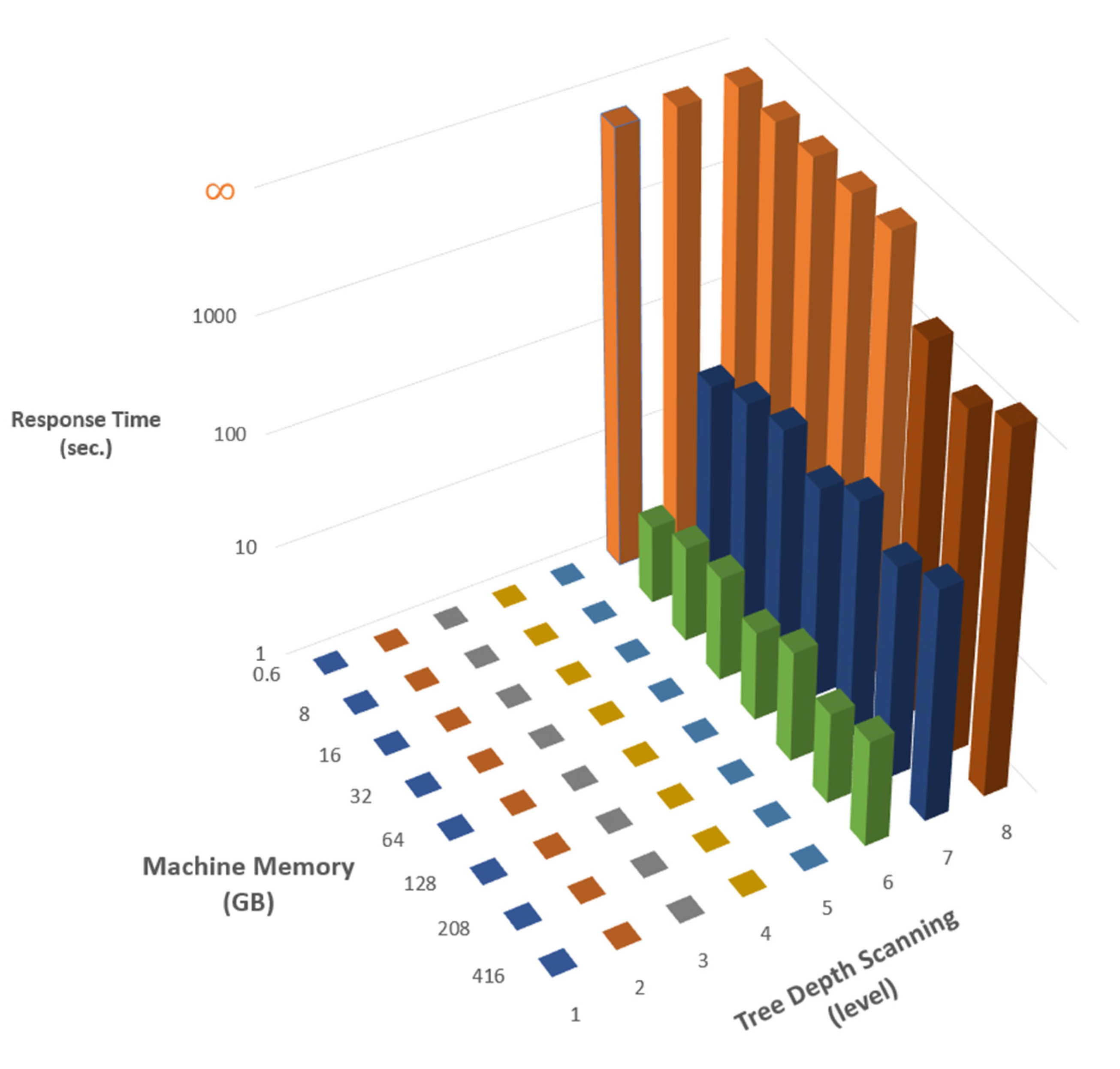
3.4. Heuristic Search Algorithms
| Algorithm 1. Local search, probabilistic first choice |
 |
| Algorithm 2. Local search, next best choice |
 |
| Algorithm 3. Random paths tree search |
 |
4. Empirical Study
4.1. Experimental Environment
4.2. Experimental Framework
4.3. Experimental Design
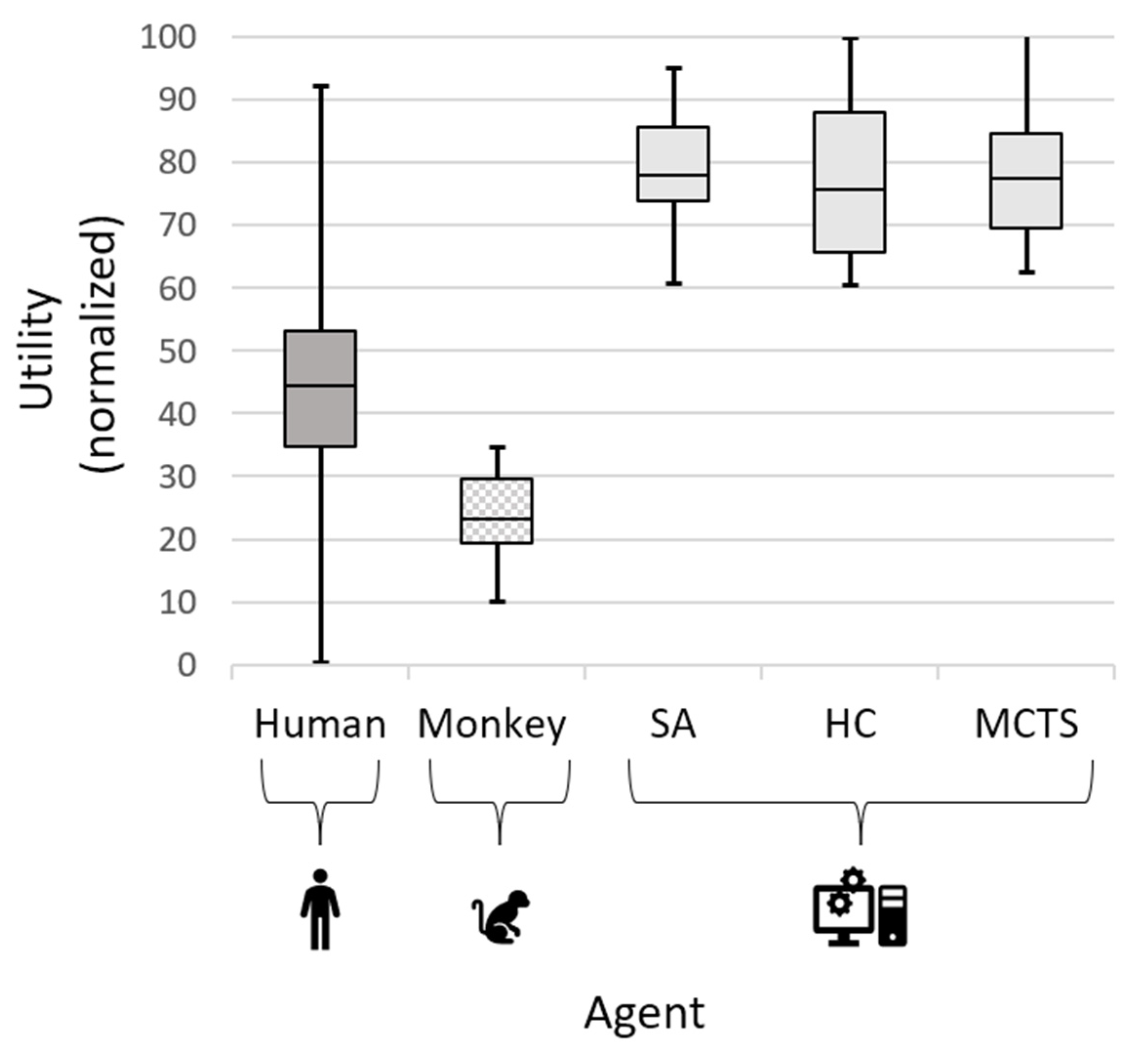
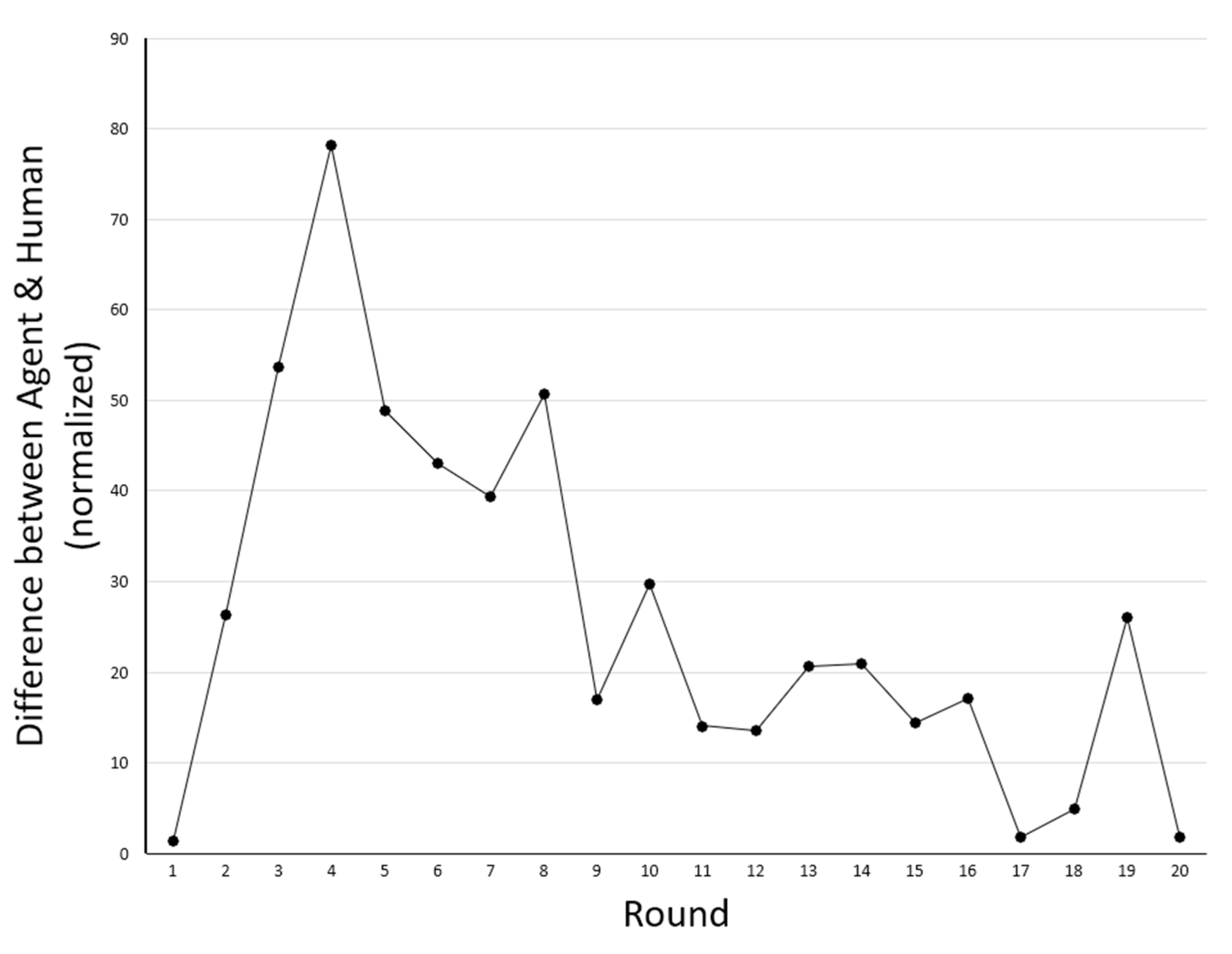
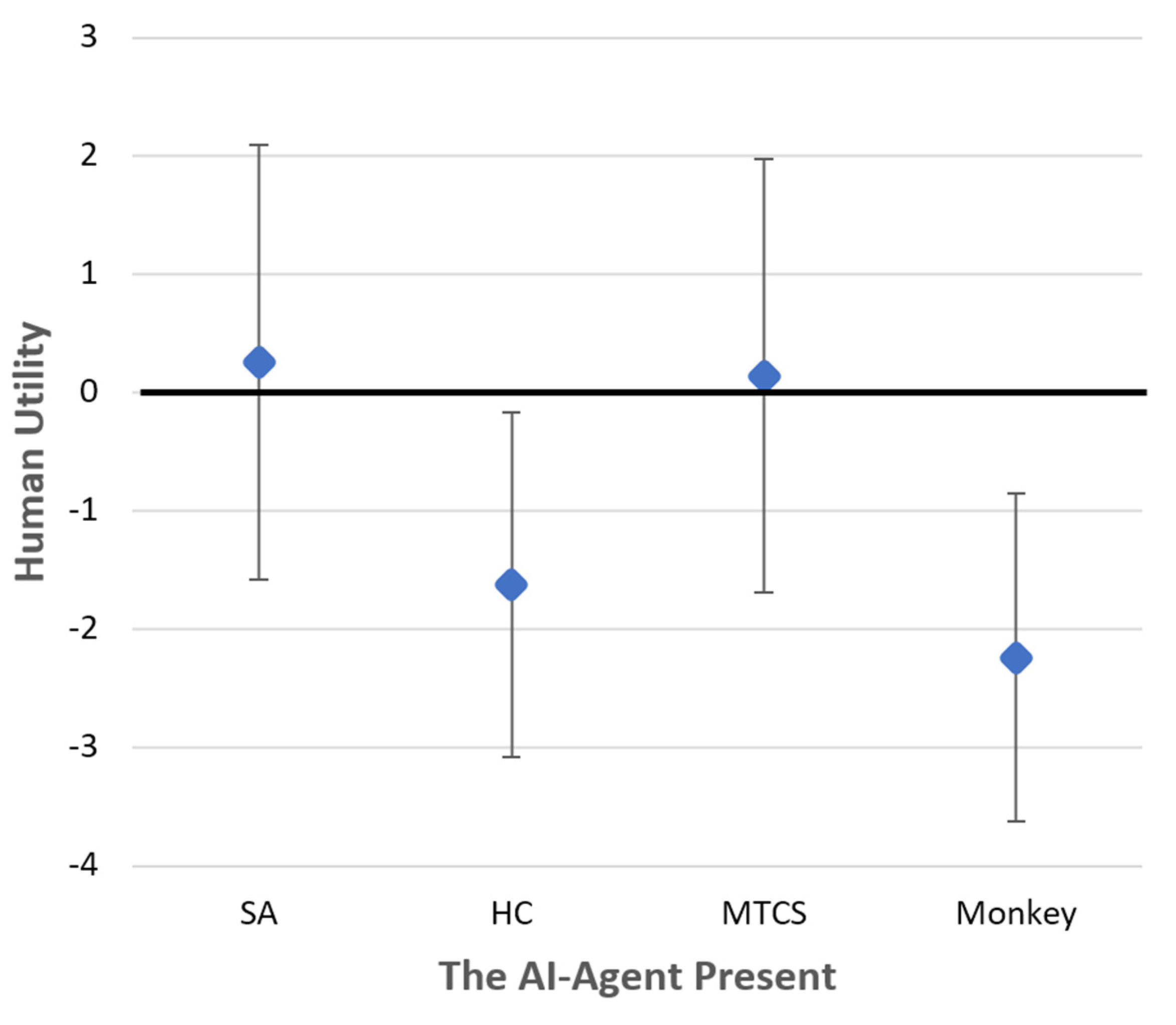
4.4. Results
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- ITUNews. New ITU Statistics Show More than Half the world Is Now Using the Internet. 2018. Available online: https://news.itu.int/itu-statistics-leaving-no-one-offline/ (accessed on 6 December 2018).
- Romansky, R. A survey of digital world opportunities and challenges for user’s privacy. Int. J. Inf. Technol. Secur. 2017, 9, 97–112. [Google Scholar]
- Dwivedi, Y.K.; Rana, N.P.; Jeyaraj, A.M.; Clement, M.; Williams, M.D. Re-examining the unified theory of acceptance and use of technology (UTAUT): Towards a revised theoretical model. Inf. Syst. Front. 2019, 21, 719–734. [Google Scholar] [CrossRef]
- Asswad, J.; Marks, J.G. Data Ownership: A Survey. Information 2021, 12, 465. [Google Scholar] [CrossRef]
- Gurung, A.; Raja, M. Online privacy and security concerns of consumers. Inf. Comput. Secur. 2016, 24, 348–371. [Google Scholar] [CrossRef]
- Marriott, H.R.; Williams, M.D.; Dwivedi, Y.K. Risk, privacy and security concerns in digital retail. Mark. Rev. 2017, 17, 337–365. [Google Scholar] [CrossRef]
- Rotman, D. Are You Looking At Me? Social Media and Privacy Literacy, IDEALS. Available online: http://hdl.handle.net/2142/15339 (accessed on 26 January 2022).
- Brenda, J. Understanding Ecommerce Consumer Privacy from the Behavioral Marketers’ Viewpoint. Ph.D. Thesis, Walden University, Minneapolis, MN, USA, 2019. [Google Scholar]
- Steinke, G. Data privacy approaches from US and EU perspectives. Telemat. Inform. 2002, 19, 193–200. [Google Scholar] [CrossRef]
- Bellekens, X.; Hamilton, A.; Seeam, P.; Nieradzinska, K.; Franssen, Q.; Seeam, A. Pervasive eHealth services a security and privacy risk awareness survey. In Proceedings of the 2016 International Conference On Cyber Situational Awareness, Data Analytics And Assessment (CyberSA), London, UK, 13–14 June 2016. [Google Scholar] [CrossRef]
- Price, W.N.; Cohen, I.G. Privacy in the age of medical big data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, L.; Yin, G.; Li, L.; Zhao, H. A survey on security and privacy issues in Internet-of-Things. IEEE Internet Things J. 2017, 4, 120–1258. [Google Scholar] [CrossRef]
- Regan, P.M. Privacy as a common good in the digital world. Inf. Commun. Soc. 2002, 5, 382–405. [Google Scholar] [CrossRef]
- Mokrosinska, D. Privacy and Autonomy: On Some Misconceptions Concerning the Political Dimensions of Privacy. Law Philos. 2018, 37, 117–143. [Google Scholar] [CrossRef]
- Dorraji, S.E.; Barcys, M. Privacy in digital age: Dead or alive? Regarding the new EU data protection regulations. Soc. Technol. 2014, 4, 306–317. [Google Scholar] [CrossRef]
- Li, H.; Yu, L.; He, W. The impact of GDPR on global technology development. J. Glob. Inf. Technol. Manag. 2019, 22, 1–6. [Google Scholar] [CrossRef]
- Min, J.; Kim, B. How are people enticed to disclose personal information despite privacy concerns in social network sites? The calculus between benefit and cost. J. Assoc. Inf. Sci. Technol. 2015, 66, 839–857. [Google Scholar] [CrossRef]
- Kung, S. A compressive privacy approach to generalized information bottleneck and privacy funnel problems. J. Frankl. Inst. 2018, 355, 1846–1872. [Google Scholar] [CrossRef]
- Cambridge Dictionary (Online). Information Exchange. Available online: https://dictionary.cambridge.org/dictionary/english/information-exchange (accessed on 22 March 2022).
- Talja, S.; Hansen, P. Information sharing. In New Directions in Human Information Behavior; Spink, A., Cole, C., Eds.; Springer: Dordrecht, The Netherlands, 2006; Volume 8, pp. 113–134. [Google Scholar] [CrossRef]
- Baruh, L.; Secinti, E.; Cemalcilar, Z. Online privacy concerns and privacy management: A meta-analytical review. J. Commun. 2017, 67, 26–53. [Google Scholar] [CrossRef]
- Olson, J.S.; Grudin, J.; Horvitz, E. A study of preferences for sharing and privacy. In Proceedings of the CHI’05 Extended Abstracts on Human Factors in Computing Systems, New York, NY, USA, 2–7 April 2005; pp. 1985–1988. [Google Scholar] [CrossRef]
- Puaschunder, J. A Utility Theory of Privacy and Information Sharing. In Encyclopedia of Information Science and Technology, 5th ed.; IGI Global: Hershey, PA, USA, 2021; pp. 428–448. [Google Scholar] [CrossRef]
- Kahneman, D.; Tversky, A. Prospect Theory: An analysis of decision under risk. Econom. J. Econom. Soc. 1979, 47, 263–292. [Google Scholar] [CrossRef]
- Modi, C.; Patel, D.; Borisaniya, B.; Patel, H.; Patel, A.; Rajarajan, M. A survey of intrusion detection techniques in cloud. J. Netw. Comput. Appl. 2013, 36, 42–57. [Google Scholar] [CrossRef]
- Gouda, M.G.; Liu, A.X. Structured firewall design. Comput. Netw. 2007, 51, 1106–1120. [Google Scholar] [CrossRef]
- Newton, J. Evolutionary game theory: A renaissance. Games 2018, 9, 31. [Google Scholar] [CrossRef]
- Myerson, R.B. On the value of game theory in social science. Ration. Soc. 1992, 4, 62–73. [Google Scholar] [CrossRef]
- Alvari, H.; Hashemi, S.; Hamzeh, A. Detecting Overlapping Communities in Social Networks by Game Theory and Structural Equivalence Concept. In Artificial Intelligence and Computational Intelligence; Deng, H., Miao, D., Lei, J., Wang, F.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 620–630. [Google Scholar] [CrossRef]
- Wahab, O.A.; Bentahar, J.; Otrok, H.; Mourad, A. Towards Trustworthy Multi-Cloud Services Communities: A Trust-Based Hedonic Coalitional Game. IEEE Trans. Serv. Comput. 2018, 11, 184–201. [Google Scholar] [CrossRef]
- Phan, C. Coalition Information Sharing. In Proceedings of the MILCOM 2007—IEEE Military Communications Conference, Orlando, FL, USA, 29–31 October 2007; pp. 1–7. [Google Scholar] [CrossRef]
- Myers, K.; Ellis, T.; Lepoint, T.; Moore, R.A.; Archer, D.; Denker, G.; Lu, S.; Magill, S.; Ostrovsky, R. Privacy technologies for controlled information sharing in coalition operations. In Proceedings of the Symposium on Knowledge System for Coalition Operations, Los Angeles, LA, USA, 6–8 November 2017. [Google Scholar]
- Guo, Z.; Cho, J. Game Theoretic Opinion Models and Their Application in Processing Disinformation. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Kuchta, M.; Vaskova, L.; Miklosik, A. Facebook Explore Feed: Perception and Consequences of the Experiment. Rev. Socionetwork Strateg. 2019, 14, 93–107. [Google Scholar] [CrossRef]
- Vishwanath, A.; Xu, W.; Ngoh, Z. How people protect their privacy on Facebook: A cost-benefit view. J. Assoc. Inf. Sci. Technol. 2018, 69, 700–709. [Google Scholar] [CrossRef]
- Bhagat, S.; Saminathan, K.; Agarwal, A.; Dowsley, R.; De Cock, M.; Nascimento, A. Privacy-Preserving User Profiling with Facebook Likes. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5298–5299. [Google Scholar] [CrossRef]
- Nilashi, M.; Asadi, S.; Minaei-Bidgoli, B.; Abumalloh, R.A.; Samad, S.; Ghabban, F.; Ahani, A. Recommendation agents and information sharing through social media for coronavirus outbreak. Telemat. Inform. 2021, 61, 101597. [Google Scholar] [CrossRef] [PubMed]
- Wattal, S.; Telang, R.; Mukhopadhyay, T.; Boatwright, P. Examining the personalization-privacy tradeoff—An empirical investigation with email advertisements. In Carnegie Mellon University Journal Contribution; Carnegie Mellon University: Pittsburgh, PA, USA, 2005. [Google Scholar] [CrossRef]
- Rafieian, O.; Yoganarasimhan, H. Targeting and privacy in mobile advertising. Marketing Science. 2020, 40, 193–394. [Google Scholar] [CrossRef]
- Rastogi, V.; Suciu, D.; Hong, S. The boundary between privacy and utility in data publishing. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 531–542. [Google Scholar]
- Zhang, D. Big data security and privacy protection. In Proceedings of the 8th International Conference on Management and Computer Science (ICMCS 2018), Shenyang, China, 10–12 August 2018. [Google Scholar] [CrossRef]
- Kalantari, K.; Sankar, L.; Sarwate, A.D. Robust Privacy-Utility Tradeoffs Under Differential Privacy and Hamming Distortion. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2816–2830. [Google Scholar] [CrossRef]
- Price, B.A.; Adam, K.; Nuseibehm, B. Keeping ubiquitous computing to yourself: A practical model for user control of privacy. Int. J. Hum.-Comput. Stud. 2005, 63, 228–253. [Google Scholar] [CrossRef]
- Gutierrez, A.; O’Leary, S.; Rana, N.P.; Dwivedi, Y.K.; Calle, T. Using privacy calculus theory to explore entrepreneurial directions in mobile location-based advertising: Identifying intrusiveness as the critical risk factor. Comput. Hum. Behav. 2019, 95, 295–306. [Google Scholar] [CrossRef]
- Zhang, A.; Lin, X. Towards secure and privacy-preserving data sharing in e-health systems via consortium blockchain. J. Med. Syst. 2018, 42, 140. [Google Scholar] [CrossRef]
- Sun, Y.; Yin, L.; Sun, Z.; Tian, Z.; Du, X. An IoT data sharing privacy preserving scheme. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020. [Google Scholar] [CrossRef]
- Sharma, S.; Chen, K.; Sheth, A. Toward practical privacy-preserving analytics for IoT and cloud-based healthcare systems. IEEE Internet Comput. 2018, 22, 42–51. [Google Scholar] [CrossRef]
- Kenneally, E.; Claffy, K. An internet data sharing framework for balancing privacy and utility. In Proceedings of the Engaging Data: First International Forum on the Application and Management of Personal Electronic Information, Cambridge, MA, USA, 12–13 October 2009. [Google Scholar]
- Bhumiratana, B.; Bishop, M. Privacy aware data sharing: Balancing the usability and privacy of datasets. In Proceedings of the 2nd International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 9–13 June 2009. [Google Scholar] [CrossRef]
- Hirschprung, R.; Toch, E.; Schwartz-Chassidim, H.; Mendel, T.; Maimon, O. Analyzing and optimizing access control choice architectures in online social networks. ACM Trans. Intell. Syst. Technol. 2017, 8, 1–22. [Google Scholar] [CrossRef]
- Beam, M.A.; Child, J.T.; Hutchens, M.J.; Hmielowski, J.D. Context collapse and privacy management: Diversity in Facebook friends increases online news reading and sharing. New Media Soc. 2018, 20, 2296–2314. [Google Scholar] [CrossRef]
- Garcia, D.; Goel, M.; Agrawal, A.K.; Kumaraguru, P. Collective aspects of privacy in the Twitter social network. EPJ Data Sci. 2018, 7, 3. [Google Scholar] [CrossRef]
- Choi, B.; Wu, Y.; Yu, J.; Land, L. Love at first sight: The interplay between privacy dispositions and privacy calculus in online social connectivity management. J. Assoc. Inf. Syst. 2018, 19, 124–151. [Google Scholar] [CrossRef]
- Madejskiy, M.; Johnson, M.; Bellovin, S.M. The Failure of Online Social Network Privacy Settings; Columbia University Computer Science Technical Reports, CUCS-010-11; Columbia University: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Acquisti, A. Privacy in electronic commerce and the economics of immediate gratification. In Proceedings of the 5th ACM Conference on Electronic Commerce, New York, NY, USA, 17–20 May 2004. [Google Scholar] [CrossRef]
- Isaak, J.; Hanna, M.J. User data privacy: Facebook, Cambridge Analytica, and privacy protection. Computer 2018, 51, 56–59. [Google Scholar] [CrossRef]
- Wisniewski, P.; Lipford, H.; Wilson, D. Fighting for my space: Coping mechanisms for SNS boundary regulation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 5–10 May 2012. [Google Scholar] [CrossRef]
- Desimpelaere, L.; Hudders, L.; Van de Sompel, D. Knowledge as a strategy for privacy protection: How a privacy literacy training affects children’s online disclosure behaviour. Comput. Hum. Behav. 2020, 110, 106382. [Google Scholar] [CrossRef]
- Korneeva, E.; Cichy, P.; Salge, T.O. Privacy Risk Perceptions and the Role of Evaluability, Framing and Privacy Literacy. Acad. Manag. Proc. 2019, 2019, 18986. [Google Scholar] [CrossRef]
- Pingo, Z.; Narayan, B. Privacy Literacy and the Everyday Use of Social Technologies. In Proceedings of the European Conference on Information Literacy, Oulu, Finland, 18–27 September 2018; p. 18. [Google Scholar] [CrossRef]
- Spiering, A. Improving Cyber Security Safety Awareness Education at Dutch Elementary Schools. Available online: https://openaccess.leidenuniv.nl/bitstream/handle/1887/64565/Spiering_A_2018_CS.docx?sequence=2 (accessed on 22 March 2022).
- Furnell, S.; Moore, L. Security literacy: The missing link in today’s online society? Comput. Fraud Secur. 2014, 5, 12–18. [Google Scholar] [CrossRef]
- Masur, P.K. How online privacy literacy supports self-data protection and self-determination in the age of information. Media Commun. 2020, 8, 258–269. [Google Scholar] [CrossRef]
- Harborth, D.; Pape, S. How Privacy Concerns, Trust and Risk Beliefs, and Privacy Literacy Influence Users’ Intentions to Use Privacy-Enhancing Technologies: The Case of Tor. ACM SIGMIS Database DATABASE Adv. Inf. Syst. 2020, 51, 51–69. [Google Scholar] [CrossRef]
- Andrew, H. Facebook’s Implementing New Rules and Processes to Stop the Spread of Harmful Content. Available online: https://www.socialmediatoday.com/news/facebooks-implementing-new-rules-and-processes-to-stop-the-spread-of-harmf/552481/ (accessed on 22 March 2022).
- Craciun, G. Choice defaults and social consensus effects on online information sharing: The moderating role of regulatory focus. Comput. Hum. Behav. 2018, 88, 89–102. [Google Scholar] [CrossRef]
- Anaraky, R.G.; Knijnenburg, B.P.; Risius, M. Exacerbating mindless compliance: The danger of justifications during privacy decision making in the context of Facebook applications. AIS Trans. Hum.-Comput. Interact. 2020, 12, 70–95. [Google Scholar] [CrossRef]
- Maxwell, G. How Will the Latest Facebook Algorithm Change. Available online: https://www.falcon.io/insights-hub/industry-updates/social-media-updates/facebook-algorithm-change/ (accessed on 22 March 2022).
- Trepte, S.; Teutsch, D.; Masur, P.K.; Eicher, C.; Fischer, M.; Hennhöfer, A.; Lind, F. Do people know about privacy and data protection strategies? Towards the: Online Privacy Literacy Scale”(OPLIS). In Reforming European Data Protection Law; Gutwirth, S., Leenes, R., de Hert, P., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 333–365. [Google Scholar] [CrossRef]
- Bartsch, M.; Dienlin, T. Control your Facebook: An analysis of online privacy literacy. Comput. Hum. Behav. 2016, 56, 147–154. [Google Scholar] [CrossRef]
- Brough, A.R.; Martin, K.D. Critical roles of knowledge and motivation in privacy research. Curr. Opin. Psychol. 2020, 31, 11–15. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Yu, S.; Gao, L.; Zhou, Z.; Peng, S. A hybrid privacy protection scheme in cyber-physical social networks. IEEE Trans. Comput. Soc. Syst. 2018, 5, 773–784. [Google Scholar] [CrossRef]
- Gupta, A.; Cedric, L.; Basar, T. Optimal control in the presence of an intelligent. In Proceedings of the 49th IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010. [Google Scholar] [CrossRef]
- Wu, H.; Wang, W. A game theory based collaborative security detection method for Internet of Things systems. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1432–1445. [Google Scholar] [CrossRef]
- Katz, J. Bridging game theory and cryptography: Recent results and future directions. In Proceedings of the Theory of Cryptography Conference, New York, NY, USA, 19–21 March 2008. [Google Scholar] [CrossRef]
- Ding, K.; Zhang, J. Multi-Party Privacy Conflict Management in Online Social Networks: A Network Game Perspective. IEEE/ACM Trans. Netw. 2020, 28, 2685–2698. [Google Scholar] [CrossRef]
- Kotra, A. A Game Theoretic Approach Applied in k-Anonymization for Preserving Privacy in Shared Data. Ph.D. Thesis, University of Nevada, Reno, NV, USA, 2020. [Google Scholar]
- Liu, F.; Pan, L.; Yao, L. Evolutionary Game Based Analysis for User Privacy Protection Behaviors in Social Networks. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 274–279. [Google Scholar] [CrossRef]
- Hu, H.; Ahn, G.; Zhao, Z.; Yang, D. Game theoretic analysis of multiparty access control in online social networks. In Proceedings of the 19th ACM Symposium on Access Control Models and Technologies, New York, NY, USA, 25–27 June 2014; pp. 93–102. [Google Scholar] [CrossRef]
- Do, C.T.; Tran, N.H.; Hong, C.; Kamhoua, C.A.; Kwiat, K.A.; Blasch, E.; Ren, S.; Pissinou, N.; Iyengar, S.S. Game theory for cyber security and privacy. ACM Comput. Surv. (CSUR) 2017, 50, 1–37. [Google Scholar] [CrossRef]
- Manshaei, M.H.; Zhu, Q.; Alpcan, T.; Bacşar, T.; Hubaux, J. Game theory meets network security and privacy. ACM Comput. Surv. (CSUR) 2013, 45, 1–39. [Google Scholar] [CrossRef]
- Tsuruoka, Y.; Yokoyama, D.; Chikayama, T. Game-tree search algorithm based on realization probability. Icga J. 2002, 25, 145–152. [Google Scholar] [CrossRef]
- Van Laarhoven, P.J.; Aarts, E.H. Simulated annealing. In Simulated Annealing: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2010; Volume 37, pp. 7–15. [Google Scholar]
- Selman, B.; Gomes, C.P. Hill-climbing search. Encycl. Cogn. Sci. 2006, 81, 82. [Google Scholar] [CrossRef]
- Coulom, R. Efficient selectivity and backup operators in Monte-Carlo tree search. In Proceedings of the International Conference on Computers and Games, Turin, Italy, 29–31 May 2006; pp. 72–83. [Google Scholar] [CrossRef]
- Karl. The 15 Biggest Social Media Sites and Apps. 2022. Available online: https://www.dreamgrow.com/top-15-most-popular-social-networking-sites/ (accessed on 17 January 2022).
- Statista. Leading Countries Based on Facebook Audience Size as of January 2022. Available online: https://www.statista.com/statistics/268136/top-15-countries-based-on-number-of-facebook-users/ (accessed on 17 January 2022).
- Hirschprung, R.; Toch, E.; Bolton, F.; Maimon, O. A methodology for estimating the value of privacy in information disclosure systems. Comput. Hum. Behav. 2016, 61, 443–453. [Google Scholar] [CrossRef]
- Paolacci, G.; Chandler, J.; Ipeirotis, P.G. Running experiments on Amazon Mechanical Turk. Judgm. Decis. Mak. 2010, 5, 411–419. [Google Scholar]
- Xiao, Y.; Li, H. Privacy preserving data publishing for multiple sensitive attributes based on security level. Information 2020, 11, 166. [Google Scholar] [CrossRef]
- Huberman, B.A.; Adar, E.; Fine, L.R. Valuating privacy. IEEE Secur. Priv. 2005, 3, 22–25. [Google Scholar] [CrossRef]
- Sent, E.M. Rationality and bounded rationality: You can’t have one without the other. Eur. J. Hist. Econ. Thought 2018, 25, 1370–1386. [Google Scholar] [CrossRef]
- Fernandes, T.; Pereira, N. Revisiting the privacy calculus: Why are consumers (really) willing to disclose personal data online? Telemat. Inform. 2021, 65, 101717. [Google Scholar] [CrossRef]
- Kekulluoglu, D.; Kokciyan, N.; Yolum, P. Preserving privacy as social responsibility in online social networks. ACM Trans. Internet Technol. (TOIT) 2018, 18, 1–22. [Google Scholar] [CrossRef]
- Rajtmajer, S.; Squicciarini, A.; Such, J.M.; Semonsen, J.; Belmonte, A. An ultimatum game model for the evolution of privacy in jointly managed content. In Decision and Game Theory for Security; Rass, S., An, B., Kiekintveld, C., Fang, F., Schauer, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 112–130. [Google Scholar] [CrossRef]
- Lampinen, A.; Lehtinen, V.; Lehmuskallio, A.; Tamminen, S. We’re in it together: Interpersonal management of disclosure in social network services. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 3217–3226. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Likes | Low | Med | High | |
| Friend- Ship | ||||
| Low | SA | SA | N/A | |
| Med | HC | HC | MCTS | |
| High | HC | MCTS | SA | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirschprung, R.S.; Alkoby, S. A Game Theory Approach for Assisting Humans in Online Information-Sharing. Information 2022, 13, 183. https://doi.org/10.3390/info13040183
Hirschprung RS, Alkoby S. A Game Theory Approach for Assisting Humans in Online Information-Sharing. Information. 2022; 13(4):183. https://doi.org/10.3390/info13040183
Chicago/Turabian StyleHirschprung, Ron S., and Shani Alkoby. 2022. "A Game Theory Approach for Assisting Humans in Online Information-Sharing" Information 13, no. 4: 183. https://doi.org/10.3390/info13040183
APA StyleHirschprung, R. S., & Alkoby, S. (2022). A Game Theory Approach for Assisting Humans in Online Information-Sharing. Information, 13(4), 183. https://doi.org/10.3390/info13040183