
RETRACTED: WDN: A One-Stage Detection Network for Wheat Heads with High Performance


Abstract
:1. Introduction
2. Related Work
2.1. Two-Stage Algorithms
- Stage 1:
- Generate regional proposals from images.
- Stage 2:
- Generate final object borders from region proposals.
2.2. One-Stage Algorithms
3. Materials and Methods
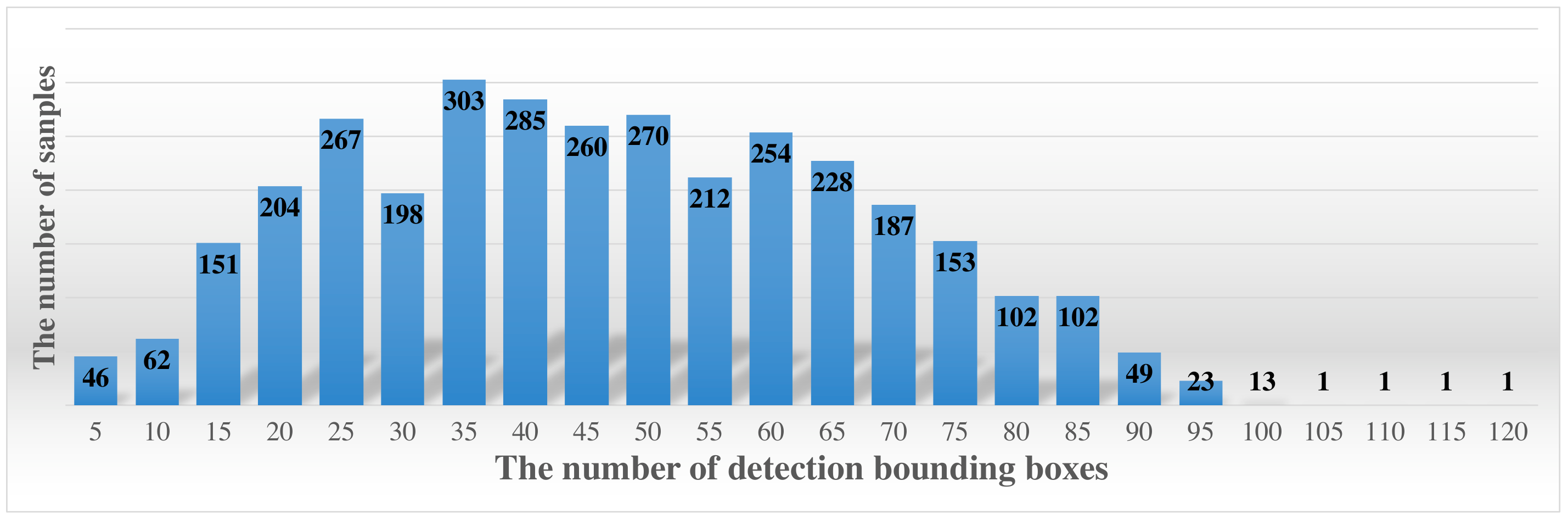
3.1. Dataset Analysis
- Dense wheat plants overlap frequently;
- Wind blurs the photos occasionally;
- The appearance varies with maturity, color, genotype, and head orientation.
3.2. Data Augmentation
3.2.1. Cutout
3.2.2. Cutmix
3.2.3. Mosaic
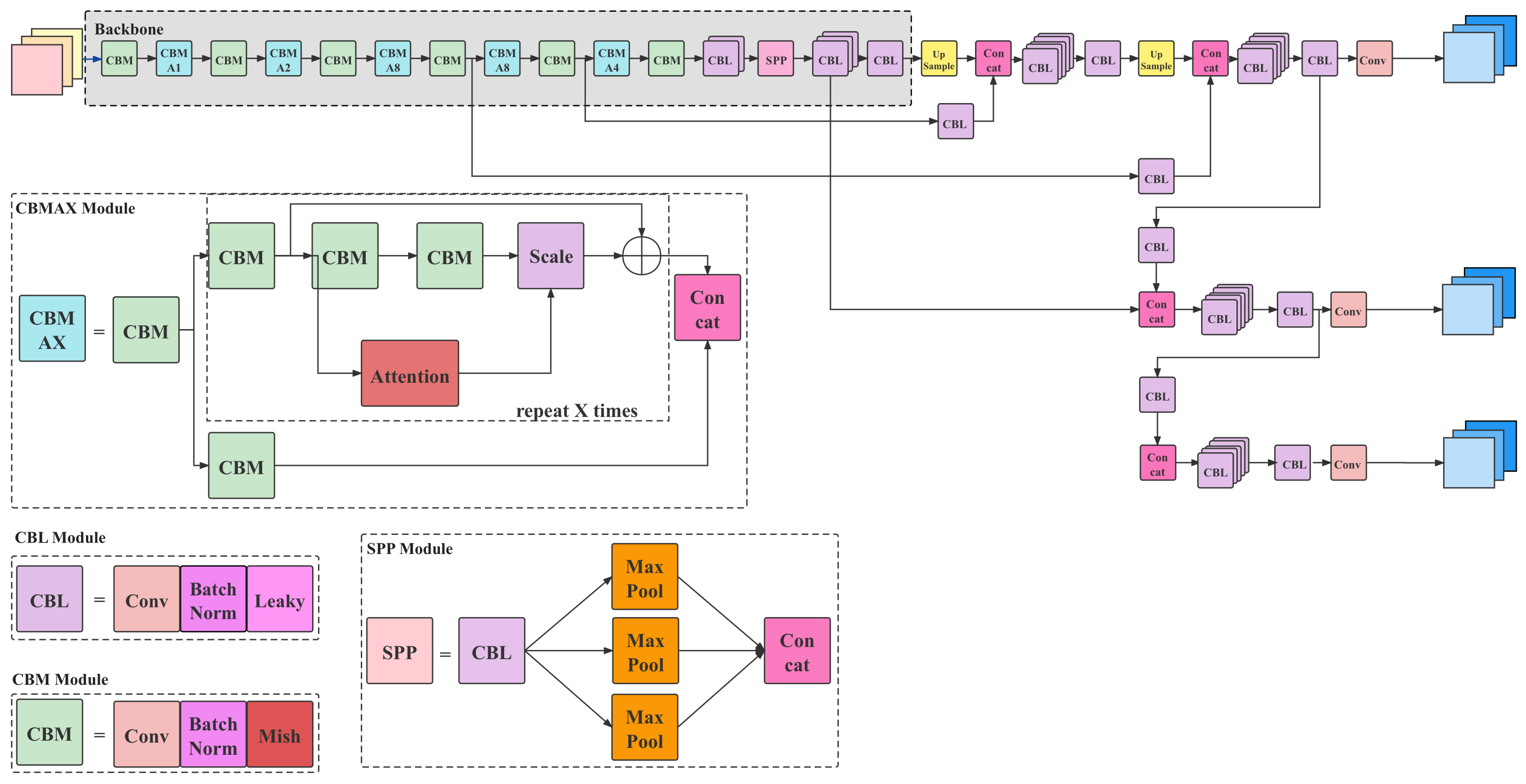
3.3. Wheat Detection Network
- The aforementioned algorithms were used on the COCO and VOC datasets, so the anchor points of the algorithms are not universal and need to be adjusted.
- The detection accuracy of the aforementioned networks, especially when it comes to small objects, is low. Therefore, based on the idea of a one-stage network, the Wheat Detection Net model was proposed, with the aim of wheat labeling. Its main features include: (1) adding an attention module to the backbone networks to enhance the ability to extract features; (2) adding a multi-scale feature fusion module to the backbone network, and referring to the ideas of two feature fusion networks, Feature Pyramid Networks (FPN) and the Path Aggregation Network (PANet), to optimize the fusion module.
- The loss functions cannot perform different loss calculations on the wheat heads and the background, that is, the foreground and the background.
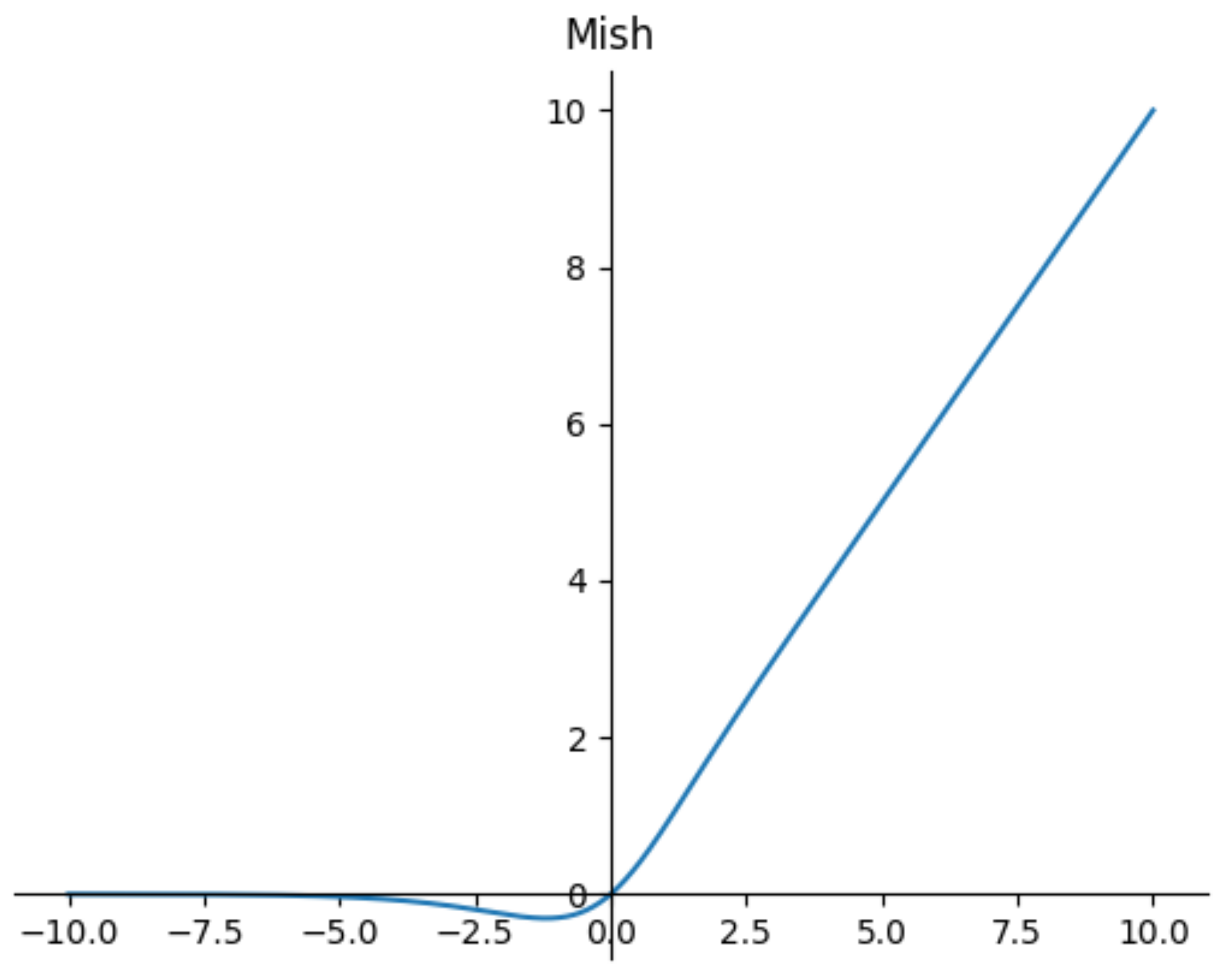
- Smooth activation functions allow better information penetration into the neural network, resulting in better accuracy and generalization. Therefore, we replaced the LeLU and LeakyReLU commonly used in CNN with the Mish function, as shown in Figure 4.
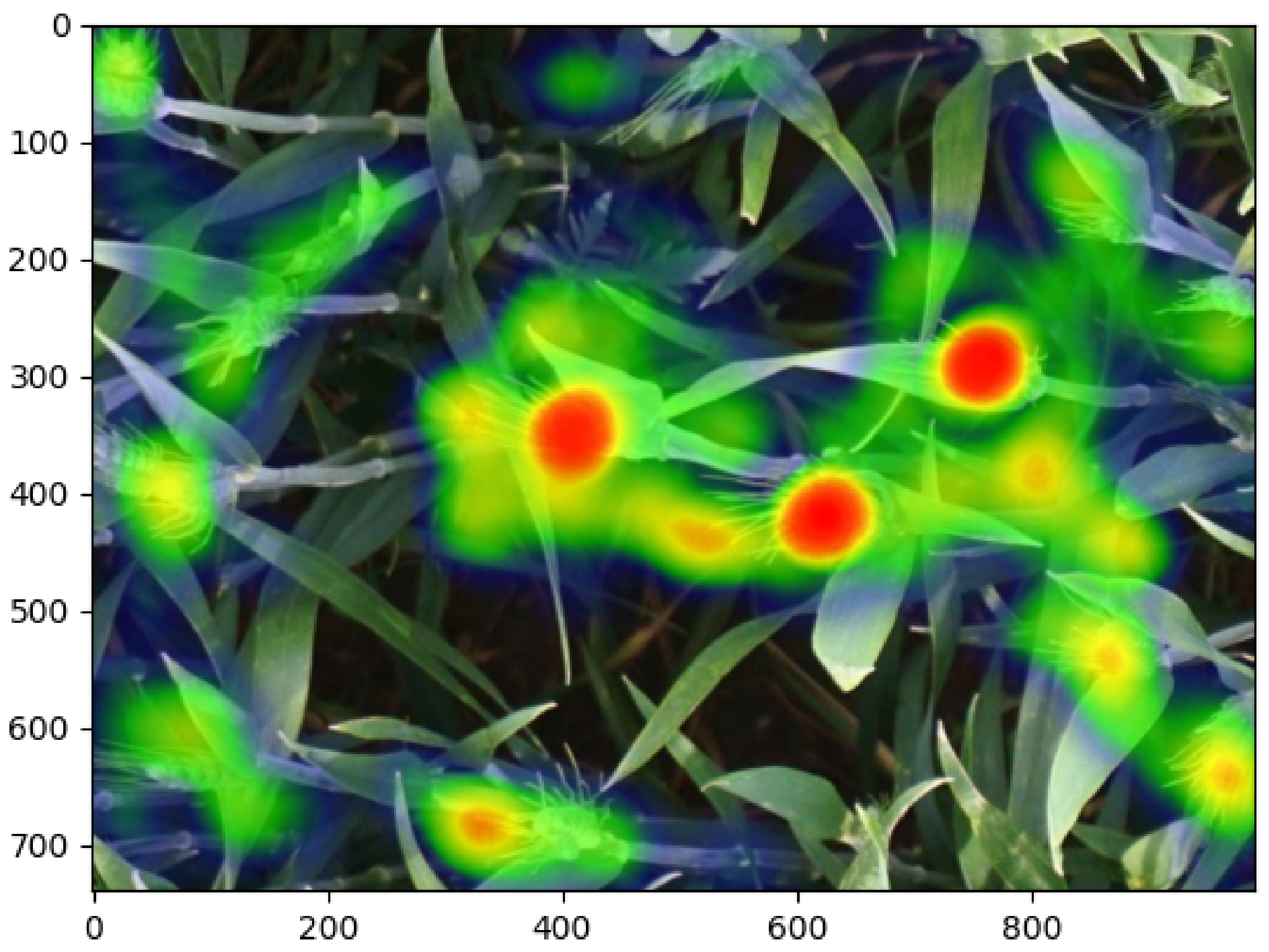
3.3.1. Attention Refinement Module
3.3.2. Feature Fusion Module
3.3.3. Loss Function
4. Results
4.1. Training
4.1.1. Warm-Up
4.1.2. Label-Smoothing
4.1.3. Pseudo-Label
4.2. Test Time Augmentation
4.2.1. Out of Fold
4.2.2. Optimization for NMS
- When objects overlap, there will be a frame with the highest score. When several objects overlap, there will be a bounding box with the highest score. In this case, if NMS is used, bounding boxes representing other objects whose confidences are lower and the overlap with a bounding box with a higher score will be deleted.
- Sometimes all the bounding boxes around an object are marked, but they are inaccurate.
- The NMS method is based on the confidence score, so only the prediction bounding box with the highest score can remain. Nevertheless, in most cases, the IoU and the classification score are not strongly correlated, and many boxes with high confidences for classification labels are not highly accurate.
4.2.3. Model Ensemble
4.3. Experiment Results
4.3.1. Yolo and SSD Transfer Learning
4.3.2. Experiment Results
5. Discussion
5.1. Ablation Experiments
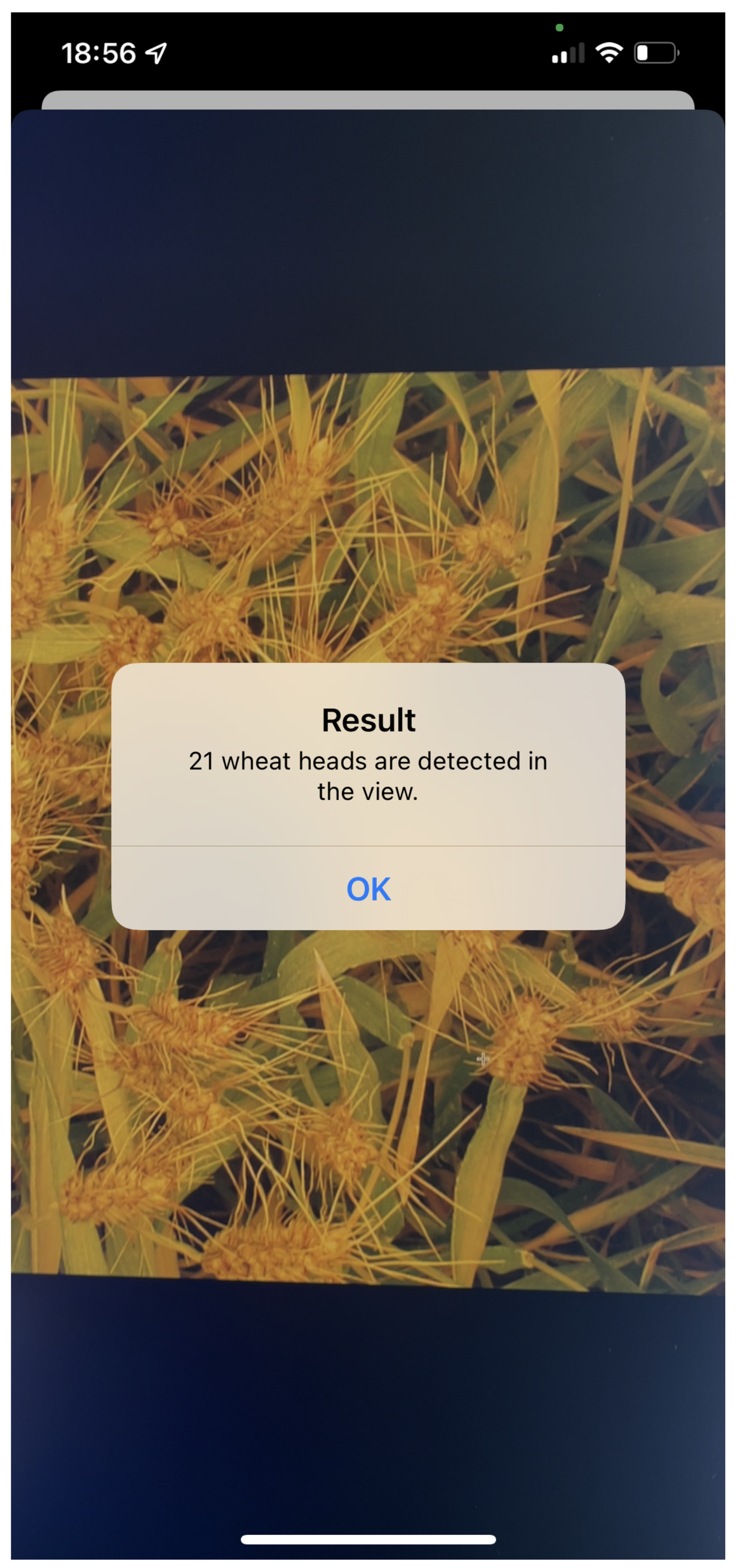
5.2. Intelligent Wheat Detection System
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fischer, R. Wheat physiology: A review of recent developments. Crop Pasture Sci. 2011, 62, 95–114. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Sun, P.; Wang, Y. Pear Defect Detection Method Based on ResNet and DCGAN. Information 2021, 12, 397. [Google Scholar] [CrossRef]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Liu, Y. Using Generative Module and Pruning Inference for the Fast and Accurate Detection of Apple Flower in Natural Environments. Information 2021, 12, 495. [Google Scholar] [CrossRef]
- Tang, L.; Gao, H.; Yoshihiro, H.; Koki, H.; Tetsuya, N.; Liu, T.S.; Tatsuhiko, S.; Zheng-Jin, X.U. Erect panicle super rice varieties enhance yield by harvest index advantages in high nitrogen and density conditions. J. Integr. Agric. 2017, 16, 1467–1473. [Google Scholar] [CrossRef]
- Tan, Y.; Ouyang, C. Image recognition of rice diseases based on deep convolutional neural network. J. Jinggangshan Univ. (Nat. Sci.) 2019, 40, 38–45. [Google Scholar]
- Allego, J.F.; Lootens, P.; Borralog, E.I.; Derycke, V.; Kefauver, S.C. Automatic wheat ear counting using machine learning based on RGB UAV imagery. Plant J. 2020, 103, 1603–1613. [Google Scholar]
- Fernandez-Gallego, J.A.; Kefauver, S.C.; Gutiérrez, N.; Nieto-Taladriz, M.T.; Araus, J.L. Wheat ear counting in-field conditions: High throughput and low-cost approach using RGB images. Plant Methods 2018, 14, 22. [Google Scholar] [CrossRef] [PubMed]
- Grbovi, E.; Pani, M.; Marko, O.; Brdar, S.; Crnojevi, V. Wheat Ear Detection in RGB and Thermal Images Using Deep Neural Networks. In Proceedings of the International Conference on Machine Learning and Data Mining, MLDM 2019, New York, NY, USA, 15 January 2019. [Google Scholar]
- Liu, Z.-Y.; Sun, H.-S. Classification of Empty and Healthy Panicles in Rice Plants by Hyperspectral Reflectance Based on Learning Vector Quantization(LVQ)Neural Network. Chin. J. Rice Sci. 2007, 21, 664–668. [Google Scholar]
- Zhou, C.; Ye, H.; Hu, J.; Shi, X.; Hua, S.; Yue, J.; Xu, Z.; Yang, G. Automated Counting of Rice Panicle by Applying Deep Learning Model to Images from Unmanned Aerial Vehicle Platform. Sensors 2019, 19, 3106. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Uddin, S.; Mia, J.; Bijoy, H.I.; Raza, D.M. Real Time Classification and Localization of Herb’s Leaves Using; Daffodil International University: Dhaka, Bangladesh, 2020. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Sural, S.; Qian, G.; Pramanik, S. Segmentation and histogram generation using the HSV color space for image retrieval. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 2, p. 2. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23–28 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted boxes fusion: Ensembling boxes for object detection models. arXiv 2019, arXiv:1910.13302. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple Detection during Different Growth Stages in Orchards Using the Improved YOLO-V3 Model; Elsevier: Amsterdam, The Netherlands, 2019; Volume 157, pp. 417–426. [Google Scholar]
- Morbekar, A.; Parihar, A.; Jadhav, R. Crop disease detection using YOLO. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–5. [Google Scholar]
- Yuan, T.; Lv, L.; Zhang, F.; Fu, J.; Gao, J.; Zhang, J.; Li, W.; Zhang, C.; Zhang, W. Robust Cherry Tomatoes Detection Algorithm in Greenhouse Scene Based on SSD. Agriculture 2020, 10, 160. [Google Scholar]
- Liang, Q.; Zhu, W.; Long, J.; Wang, Y.; Sun, W.; Wu, W. A real-time detection framework for on-tree mango based on SSD network. In Proceedings of the International Conference on Intelligent Robotics and Applications, Aachen, Germany, 6–8 December 2011; Springer: Berlin/Heidelberg, Germany, 2018; pp. 423–436. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | FPS | Batch Size | Input Resolution |
|---|---|---|---|---|
| FasterRCNN | 0.8396 | 17 | 2 | 600 × 600 |
| MaskRCNN | 0.8493 | 19 | 2 | 600 × 600 |
| EfficientDet | 0.8520 | 37 | 8 | 512 × 512 |
| YOLOv3 | 0.880 | 23 | 2 | 608 × 608 |
| YOLOv4 | 0.838 | 47 | 2 | 608 × 608 |
| YOLOv5 | 0.867 | 51 | 2 | 608 × 608 |
| SSD300 | 0.846 | 35 | 2 | 300 × 300 |
| SSD300 | 0.846 | 32 | 8 | 300 × 300 |
| SSD512 | 0.847 | 19 | 2 | 512 × 512 |
| SSD512 | 0.847 | 21 | 8 | 512 × 512 |
| WDT512 | 0.882 | 41 | 2 | 512 × 512 |
| WDT512 | 0.903 | 37 | 8 | 512 × 512 |
| WDT1024 | 0.875 | 29 | 2 | 1024 × 1024 |
| Cutout | Cutmix | Mosaic | Warm-Up | Label-Smoothing | Pseudo Label | mAP |
|---|---|---|---|---|---|---|
| ✓ | ✓ | PL-A | 0.5020 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | PL-C | 0.903 |
| ✓ | ✓ | ✓ | ✓ | PL-A | 0.873 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | PL-B | 0.877 |
| ✓ | ✓ | ✓ | ✓ | PL-C | 0.870 | |
| ✓ | ✓ | ✓ | PL-C | 0.888 | ||
| ✓ | ✓ | ✓ | PL-C | 0.895 |
| Cutout | Cutmix | Mosaic | Warm-Up | Label-Smoothing | Pseudo Label | mAP |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | ✓ | ✓ | PL-C | 0.887 |
| ✓ | ✓ | ✓ | ✓ | PL-A | 0.903 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | PL-B | 0.894 |
| ✓ | ✓ | ✓ | PL-B | 0.871 | ||
| ✓ | ✓ | ✓ | PL-C | 0.880 |
| Models | OoF | NMS Method | mAP |
|---|---|---|---|
| WDT512 | NMS | 0.891 | |
| WDT1024 | NMS | 0.879 | |
| WDT512 | ✓ | soft NMS | 0.903 |
| WDT512 + YOLO series + MaskRCNN | ✓ | WBF | 0.917 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, P.; Cui, J.; Hu, X.; Wang, Q. RETRACTED: WDN: A One-Stage Detection Network for Wheat Heads with High Performance. Information 2022, 13, 153. https://doi.org/10.3390/info13030153
Sun P, Cui J, Hu X, Wang Q. RETRACTED: WDN: A One-Stage Detection Network for Wheat Heads with High Performance. Information. 2022; 13(3):153. https://doi.org/10.3390/info13030153
Chicago/Turabian StyleSun, Pengshuo, Jingyi Cui, Xuefeng Hu, and Qing Wang. 2022. "RETRACTED: WDN: A One-Stage Detection Network for Wheat Heads with High Performance" Information 13, no. 3: 153. https://doi.org/10.3390/info13030153
APA StyleSun, P., Cui, J., Hu, X., & Wang, Q. (2022). RETRACTED: WDN: A One-Stage Detection Network for Wheat Heads with High Performance. Information, 13(3), 153. https://doi.org/10.3390/info13030153