Abstract
With the rapid development of the internet of things, there are more and more end devices, such as wearable devices, USVs and intelligent automobiles, connected to the internet. These devices tend to require large amounts of computing resources with stringent latency requirements, which inevitably increases the burden on edge server nodes. Therefore, in order to alleviate the problem that the computing capacity of edge server nodes is limited and cannot meet the computing service requirements of a large number of end devices in the internet of things scenario, we combined the characteristics of rich computing resources of cloud servers and low transmission delay of edge servers to build a hybrid computing task-offloading architecture of cloud-edge-end collaboration. Then, we study offloading based on this architecture for complex dependent tasks generated on end devices. We introduce a two-dimensional offloading decision factor to model latency and energy consumption, and formalize the model as a multi-objective optimization problem with the optimization objective of minimizing the average latency and average energy consumption of the task’s computation offloading. Based on this, we propose a multi-objective offloading (SPMOO) algorithm based on an improved strength Pareto evolutionary algorithm (SPEA2) for solving the problem. A large number of experimental results show that the algorithm proposed in this paper has good performance.
1. Introduction
With the rapid development of various internet-of-things (IoT) fields, such as intelligent traffic, intelligent home and intelligent manufacturing [1,2,3,4], the number of various IoT devices (e.g., wearable devices, unmanned surface vehicles (USVs) and intelligent automobiles [5,6,7] etc.) has increased significantly. According to Cisco, there are now more than 30 billion mobile IoT devices worldwide, generating about 2.5 EB of data per day, which often requires further processing and analysis. However, IoT devices have limited computing power and storage resources because they are mostly small, battery-powered and equipped with sensors. So, many latency-sensitive computing tasks generated in real time, such as face recognition, virtual reality (VR) and augmented reality (AR) [8,9,10], are present difficulties in guaranteeing users’ real-time experience when executed on local devices. These tasks are usually passed to the cloud, which costs time and computation power in maintaining the long-distance connection [11]. However, since the ultra-long-distance communication between IoT devices and remote clouds in real-world scenarios requires a large amount of bandwidth resources, sending all locally generated tasks to remote clouds for processing would bring serious problems, such as high latency and network congestion.
To alleviate these problems, one of the more effective approaches today is to offload all complex computing tasks from the local device to a nearby edge server. The edge servers are geographically closer to the local devices, they feature low communication costs and short response times. SDN can be set up at the edge layer to manage network traffic and resources with more flexibility and scalability support [12]. This not only ensures the real-time requirements of latency-sensitive tasks, but also reduces the energy consumption of the local devices. However, due to cost and scale constraints, the computing resources on edge servers are not unlimited. When a large number of tasks are offloaded to edge servers at the same time or when resource-poor local devices require more computing and storage resources, the edge servers can be overloaded and cannot effectively meet the complex application requirements.
Since these single-computing paradigms cannot solve all offload problems, there is a need to jointly consider the heterogeneity of cloud and edge computing to build a cloud-edge-end-collaborative computing architecture. A white paper from ETSI illustrates that cloud and edge computing are highly complementary, and that cloud-edge-end-collaborative computing can provide better computing performance and transport performance than cloud or edge computing alone [13]. However, it remains a challenge to effectively offload in a cloud-edge-end-computing environment due to resource heterogeneity, the diversity of user requirements, network complexity and task dependencies. At present, a part of the related work does not consider the complexity of tasks in realistic scenarios and only considers each computing task as an indivisible whole when performing offloading [14,15,16,17,18,19,20,21], which is obviously unreasonable. Another part of the related work considers the complexity of the tasks and partitions the tasks, but the complexity of calculating the communication cost between subtasks makes it extremely difficult to perform offloading research in cloud-edge-end architectures [22,23,24,25,26], so their work is often performed in two-tier offloading architectures (cloud–edge architecture or edge–end architecture, etc.). Therefore, in this paper, we propose a multi-objective optimal offloading algorithm for the offloading problem of complex tasks in IoT cloud-edge-end-computing architectures, aiming to optimize both the average latency and average energy consumption through the offloading of subtasks and the scheduling of resources in a heterogeneous environment. The main contributions of this paper are as follows:
- We integrate the characteristics of edge computing and cloud computing, and then fully integrate and, based on heterogeneous computing resources, establish an IoT cloud-edge-end-collaborative computing offload architecture.
- Defining tasks as a directed, acyclic graph (DAG) composed of a set of nodes with interdependent subtasks, we then establish latency and energy consumption models by introducing two-dimensional offloading factors.
- Based on the delay and energy consumption models, the offloading problem is formalized as a multi-objective optimization problem with the objective of minimizing the average delay and average energy consumption of task offloading, and a multi-objective offloading (SPMOO) algorithm based on an improved strength Pareto evolutionary algorithm (SPEA2) is proposed for solving the problem.
The rest of the paper is organized as follows. Section 2 discusses the related work; Section 3 presents the system model and the analysis of the problem; Section 4 describes the proposed multi-objective task offloading algorithm in detail; in Section 5 we perform extensive simulations and analyze different aspects; finally, Section 6 concludes the paper and discusses future work.
2. Related Work
To address the important challenges of working together with IoT systems and emerging computing paradigms, some researchers have proposed many effective task offloading algorithms to maximize application service performance from different perspectives. Based on whether the computing tasks are divisible or not, the tasks involved in the current related offloading research work are divided into two main categories: indivisible independent tasks and complex tasks consisting of multiple subtasks with data or logical dependencies.
2.1. Offloading Strategies for Independent Tasks
Since the dependency between subtasks is not involved, the offloading problem of independent tasks is much easier than that of dependent tasks. Therefore, there are many studies on the offloading strategy of independent tasks at present.
The study [15] proposed an online task scheduling algorithm for improving the total weighted response time (WRT) of all jobs. The study [16] considered the optimization problem of minimizing the long-term average delay of an IoT fog–cloud system and applied the Lyapunov drift-plus-penalty method to solve it. However, the optimization of long-term average delay may lead to performance imbalance among different tasks or time slots. The study [17] proposed an online method that attempts to maximize the number of tasks that meet the deadline while minimizing the average completion time (ACT) of the tasks through joint scheduling of network and computing resources. The study [18] proposed an energy-efficient dynamic task offloading (EEDTO) algorithm with the goal of minimizing energy consumption and task response time. This algorithm could adaptively select the optimal computation location for each task without requiring future system information as a priori knowledge. The study [19] transformed the dynamic performance optimization problem of service deployment for each user during system operation into a multi-arm bandit problem (MAB), which was then solved using a contextual Thompson sampling learning approach. The study [20] proposed a distributed, deep-learning method. They used a parallel deep neural network (DNN) to input the output of task load and offload decisions and updated the DNN parameters with the newly generated data.
2.2. Offloading Strategies for Dependent Tasks
The tasks generated by IoT devices in real scenarios are usually composed of a number of subtasks with logical or data dependencies. Any subtask must start execution only after all its predecessors have been executed; and, when executing these subtasks at different locations, data transfer between subtasks with dependencies is required, which can incur communication costs. Therefore, achieving optimal offloading decisions should not only focus on user requirements, complex access networks and resource utilization, but also take into account the dependencies between subtasks.
The study [27] proposed a greedy task graph partitioned offloading algorithm in order to minimize task communication overhead and energy consumption, which offloaded tasks at the device layer, cloudlet layer and cloud layer based on the computing power of the device and the type of task. However, the algorithm easily fell into local optimal solutions. The study [22] proposed an adaptive content-aware task scheduling (CATSA) framework. The approach was based on a multi-criteria technique to determine the way each task pair matches each computing paradigm and then selected an optimal solution from the solution set using a random search method. However, this work did not consider the resource heterogeneity between different computing layers. The study [28] used a long-short-term memory (LSTM) approach to predict the data size for each task. Based on the predicted values, the latency of each user task was optimized. However, this work simply partitioned the tasks without considering the dependencies between subtasks. The study [23] considered response time, reliability, and task execution cost in an edge cloud environment, and then formulated the offloading problem as an NP-hard, multi-objective optimization problem based on then on-dominated sorting genetic algorithm (NSGA-II) [29] and simulated binary crossover and polynomial variation to provide an offloading policy in the Pareto frontier. However, this work did not consider the power consumption model. The study [24] designed an online recurring score matrix-based heuristic algorithm (RSM-H) using a network state prediction method for the offloading problem of stateful, dataflow applications. However, this work only offloaded to the edge cloud and did not consider the power consumption model. The study [30] quantified the execution overhead as a weighted sum of task completion time and data transfer energy consumption and used this as an optimization objective to determine the execution location of a task. However, this work ignored the queueing order of tasks and the waiting execution time.
3. System Model and Problem Formulation
3.1. Overview
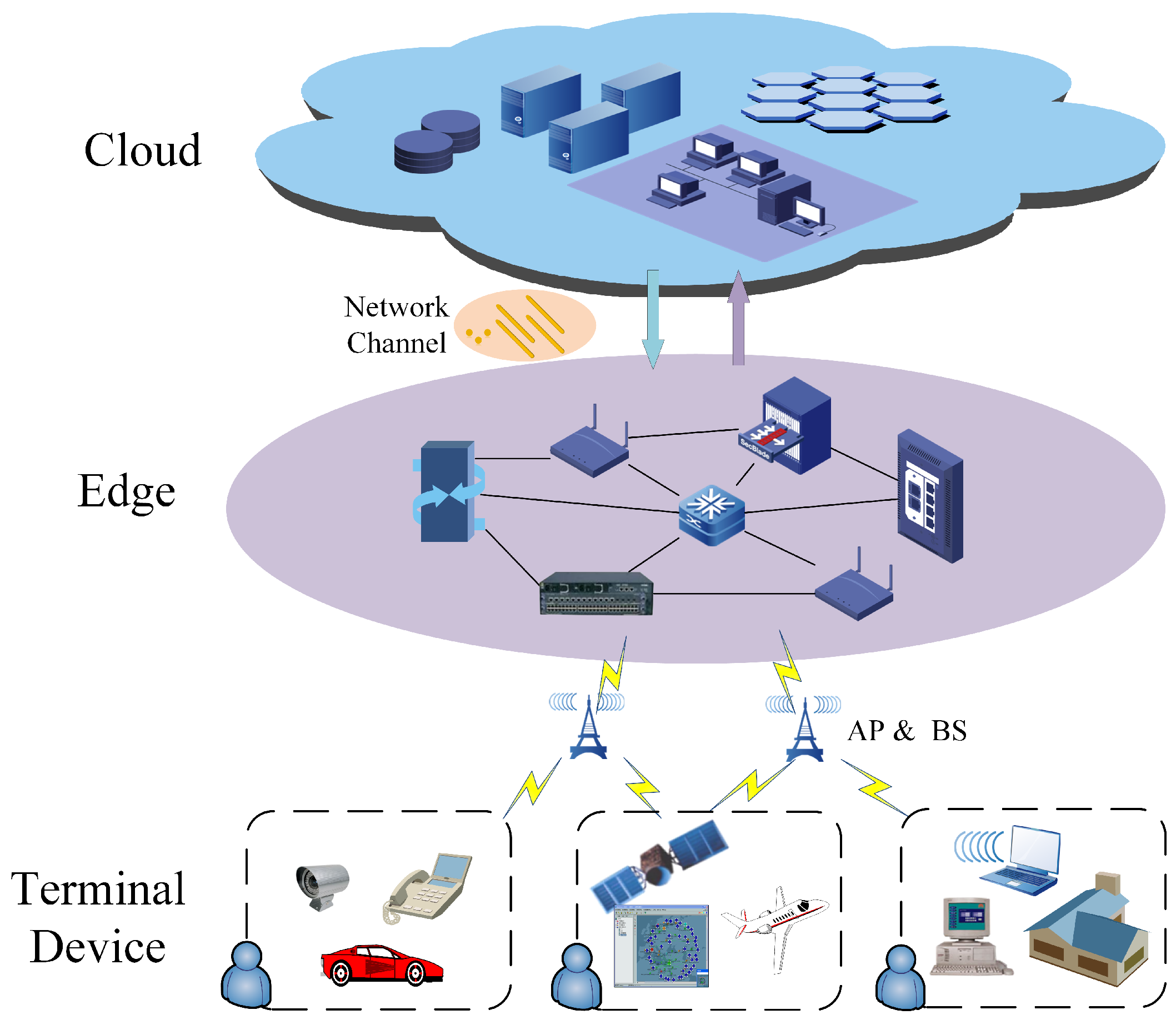
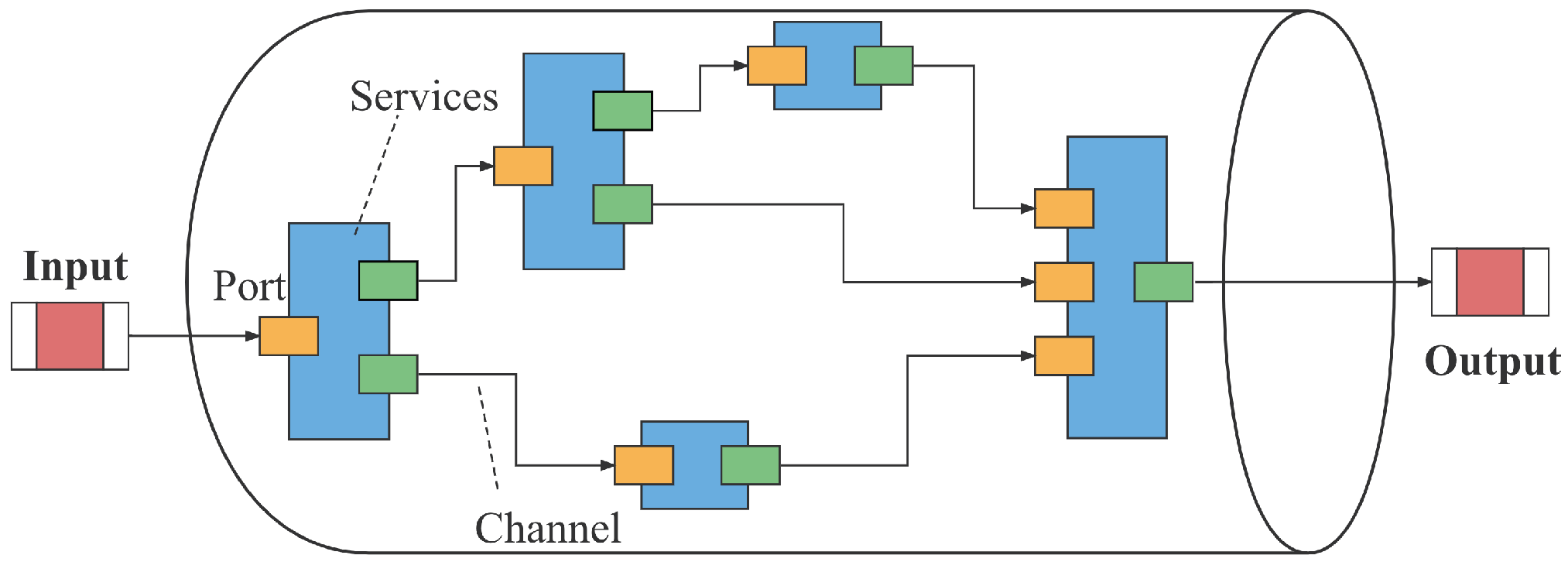
Since cloud servers have powerful computing and storage resources and rich applications, while edge servers have advantages of low communication cost, short response time, and strong network adaptability, we establish an IoT cloud-edge-end-collaborative computing offload architecture by combining the characteristics of both, fully integrating and invoking heterogeneous computing resources, and offloading tasks to the appropriate location based on the requirements of different applications in terms of computing power, energy cost and latency. As shown in Figure 1, the architecture consists of three layers, the end-device layer, edge layer and cloud layer. The end-device layer consists of a wide variety of IoT devices with sensors. These devices are usually small in size, have limited battery capacity, and have only limited computing and storage capabilities. So, to further process the data, these devices transmit the task data to the edge or cloud layers through wireless access points (APs) or base stations (BSs) [31]. The edge layer mainly consists of some lightweight edge servers that can provide low-latency computing services at the edge of the network. Meanwhile, to avoid overload, the edge servers can transfer tasks to the cloud servers for processing via wired links. The cloud layer has many cloud servers with rich computing and storage resources, and these servers provide services for users in different areas at the same time. However, the sharing among multiple users and the long transmission distance of connections to other layers lead to high communication cost for data transmission.
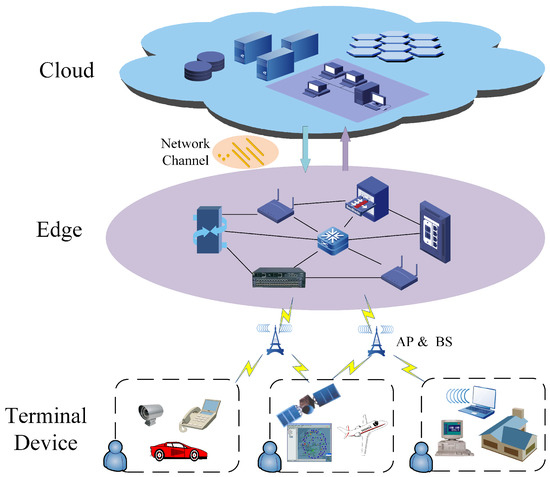
Figure 1.
Cloud-edge-end-collaborative computing offload system architecture.
In this three-tier computing offload architecture, it is assumed that a total of computing tasks are generated at the end device layer and sent to the edge layer, with edge server nodes and cloud server nodes available to provide services. Then we partition the computing tasks from end devices into multiple subtasks with dependencies, which are offloaded to edge servers or cloud services for execution.
In this paper, these interdependent subtasks are defined architecturally as a directed acyclic graph (DAG) as shown in Figure 2. Where the vertex represents the services or microservices used by all subtasks of the task u. The modularity of the services or microservices makes it possible to deploy each service or microservice on various types of hardware, virtualized devices and specific libraries, thus solving the compatibility problem. The edge represents the dependency between subtask and subtask , and indicates the size of data to be transferred between and , which will incur additional communication cost when these two subtasks are executed at different locations when data transfer is required.
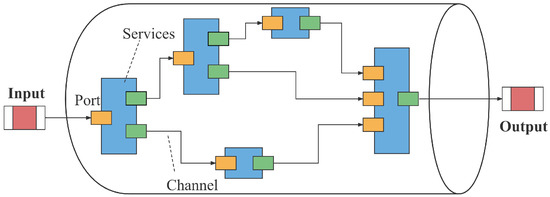
Figure 2.
Task execution pipeline model.
Meanwhile, we introduce the offloading decision factor to indicate whether the subtask is offloaded or not, and the offloading location factor to indicate the specific location where the subtask is offloaded. When indicates that subtask is executed locally, at this time indicates that is not offloaded. When , indicates that subtask is offloaded to the edge node, and when , indicates that subtask is offloaded to the cloud node. For convenience, some important symbols adopted in this paper and their description are listed in Table 1.

Table 1.
Important symbols used in the paper and their description.
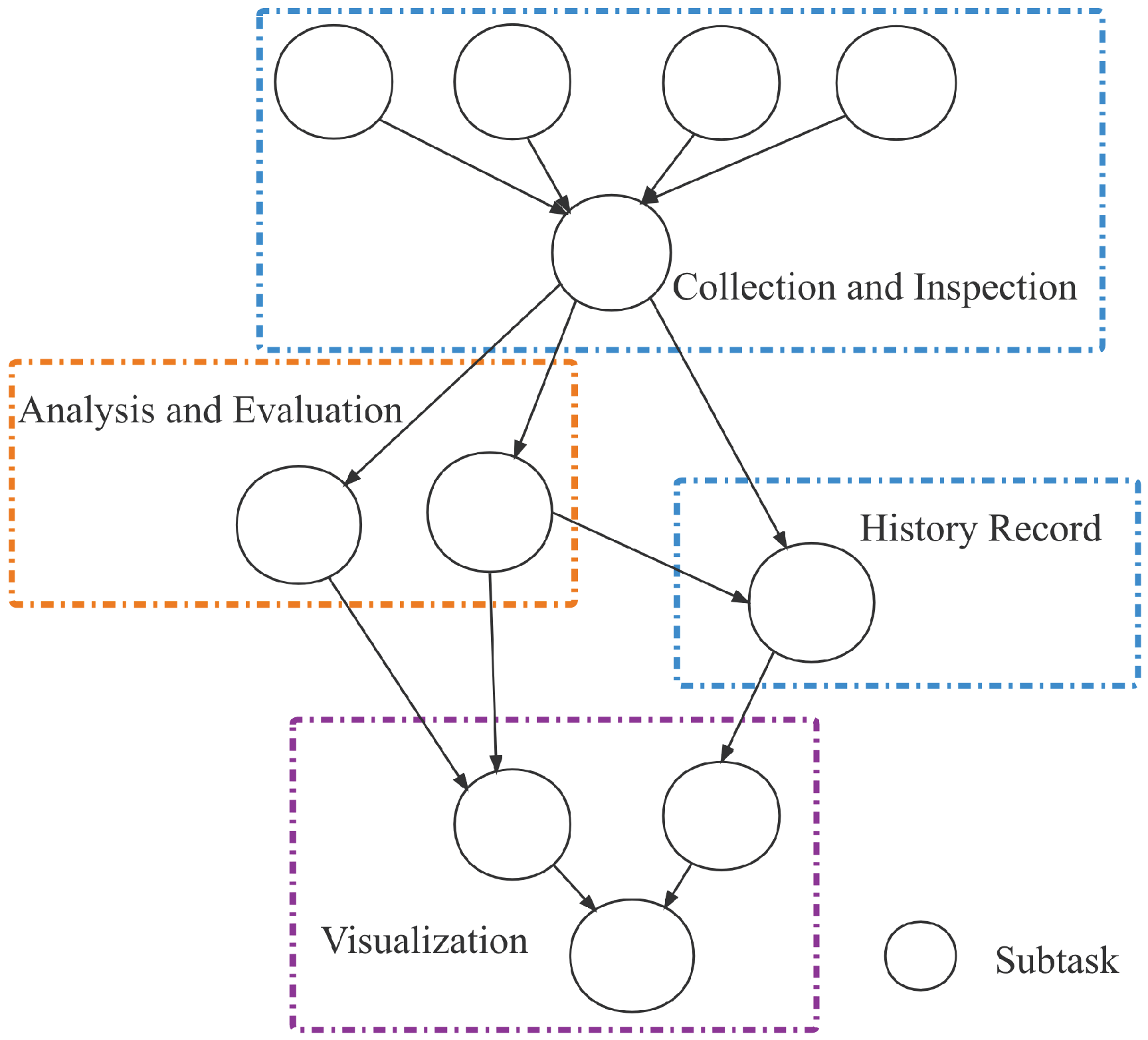
Here is an example which takes USVs as end devices for intelligent water quality monitoring application. The application breaks through the limits of conventional manual sampling monitoring, realizing the collection of changes of water quality, water temperature and other data in a certain area, and can regularly report the regional water quality analysis results. As shown in Figure 3, the application includes the following four parts: information collection and inspection, water quality level analysis and evaluation, historical water quality data query and water-quality distribution visualization. Among them, information collection and inspection can only be run locally, while the other three parts can be run locally, on the edge or cloud. The specific task offload execution position is determined by the scheduler according to the system state and task configuration information.
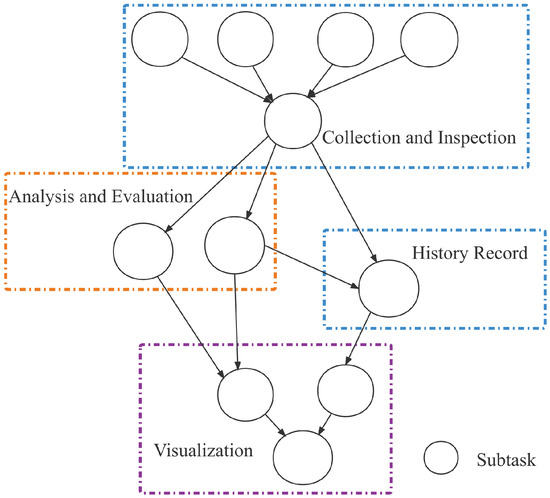
Figure 3.
USVs intelligent water quality monitoring.
3.1.1. Delay Model
Since each subtask has a time to start execution and a time to finish execution, in this paper we use to denote the subtask start execution time and to denote the subtask finish execution time. Then we denote the delay required for subtask to be executed at the local device as , the delay required at the edge server node as , and the delay required at the cloud server node as , where denotes the CPU resources required to execute subtask , denotes the CPU frequency of local device, denotes the CPU frequency of edge server, and denotes the CPU frequency of cloud server. From this we can obtain:
Since the end device layer generally communicates with the edge server and the cloud server through wireless access points (APs) or small base stations (BSs), the transmission rate between the end device and the edge server can be obtained according to Shannon’s formula as:
where B denotes the channel bandwidth of wireless transmission, denotes the channel gain of the end device communicating through the wireless channel or base station, denotes the transmitting power of the end device for wireless transmission, and denotes the path loss between the end device and the edge server. Similarly, the transmission rate between the end device and the cloud server can be expressed as:
since edge servers usually communicate with cloud servers through wired links, we denote the transmission rate between them as .
For each subtask, its earliest start execution time is mainly limited by the completion execution time of all its predecessor nodes, and if the subtask is not executed at the same location as its predecessor nodes, the time consumed by data transmission is also considered, which can be expressed as:
where, denotes the completion execution time of the predecessor nodes of subtask , denotes the set of all predecessor nodes of subtask , and denotes the amount of data to be transferred between subtask and its predecessor nodes.
To facilitate the representation of the total delay of the task computation, we abstracted the input and output of the task as two subtasks and , which do not need to consider the amount of computation, placed at the beginning and end of the task, respectively, so that the total delay required for the execution of task u can be expressed as:
3.1.2. Energy Consumption Model
When the task is executed in the cloud server, the energy required is often negligible compared to the abundant computing resources of the cloud service nodes themselves, so this paper mainly considers the energy consumption of three parts, local computing energy, edge server node computing energy and communication transmission energy. Among them, the computing energy consumption of the task u can be expressed as:
where, and denote the CPU energy conversion factors of the end device and the edge server node, respectively.
The energy consumption generated by data transmission during the execution of task u includes the communication energy consumption between the local device and the edge server, the communication energy consumption between the local device and the cloud server and the communication energy consumption between the edge server and the cloud server, which can be expressed as:
Therefore, the total communication energy consumption generated by performing data transfer during the execution of task u is
Finally, the total energy consumption required during the computation and offloading performed by task u can be expressed as:
3.2. Problem Formulation
Considering the real scenario where there is a conflict between the objectives of minimizing the average delay and minimizing the average energy consumption of task computation offload, if we use the weighted sum aggregation method to assign weights to the objectives, we can only obtain a single optimal solution, for which it is often difficult to meet the diverse needs of different users or service providers in a resource-variant environment. Therefore, in order to better meet the needs of users and providers, and to improve user experience and resource utilization as much as possible, we formalize the problem as a multi-objective optimization problem, where the optimization objective is to minimize the average delay and average energy consumption of task computation offloading. According to Equations (5) and (11), the optimization objective can be expressed as:
Constraint C1 in Equation (14) indicates that for any subtask can only be executed on the edge server node or on the cloud server node. Constraint C2 indicates that for any task u, its input and output are at the local device. Constraint C3 indicates that each subtask must complete all its predecessors before it can start execution. Constraint C4 indicates that any edge server node and cloud server node cannot process multiple subtasks simultaneously in parallel. In this paper, we divide the time duration into a sequence of time slots, and for each time slot, the number of offloaded subtasks cannot exceed the sum of the number of edge servers and cloud servers.
4. The Proposed SPMOO Algorithm
For the multi-objective optimization problems formulated in Section 3.2, the more frequently used solution algorithms are NSGA-II, MOEA/D, SPEA2, and etc. [29,32,33,34]. In this paper, a multi-objective offloading algorithm (SPMOO) based on the improved strength Pareto evolutionary algorithm (SPEA2) is proposed considering the parallel processing mechanism and global optimization. Since the standard SPEA2 algorithm has high randomness and poor ability in local search, we add local search set to enhance the local search ability of the algorithm based on the original algorithm, and we also adopt intergenerational crossover and individual similarity judgment strategies to improve population diversity and convergence speed. Therefore, our algorithm is able to obtain a set of Pareto-optimal solutions for user or supplier selection in a short time.
As shown in Algorithm 1, we initialize the population with size M and create an empty external archive set and an empty local search set , both with size . Then we calculate the fitness of all individuals in the population and external archive set and local search set, and save all the non-dominated solution sets in them to the next generation of external archive set and local search set . If the number of individuals in the external archive set exceeds at this time, truncate the operation; if the number of individuals does not reach, we select some of the dominant liberation from and into and . After that, the local search update is performed for , and the individuals from the external archive set at this time are selected into the mating pool for crossover and mutation and the results are kept into the next generation population to recalculate the fitness, thus iterating. Finally, the non-dominated solution set in is taken as the final output of the offloading policy.
| Algorithm 1: SPMOO |
 |
4.1. Fitness Calculation
To avoid the situation that individuals have the same fitness, the SPEA2 algorithm calculates the number of dominated solutions for each individual in the population and external archive set and defines it as the strength value , and based on this, the original fitness is defined to represent the number of dominated solutions for individual i. The larger the , the more individuals dominate individual i.
When most of the individuals are non-dominated, it is difficult to distinguish them by alone, so the density value is introduced, and the density value is calculated using the K-nearest neighbor method, where the density value of any individual is a function of the distance of its k neighboring individuals.
In the above equations, represents the Euclidean distance between individual i and its adjacent individual k. Finally, the fitness of individual i is obtained:
4.2. Local Search Update
In order to avoid falling into local optimum, we replicate the external archive set to create a local search set, and then rank the individuals in this set according to their fitness and perform domain search on some of them with higher fitness. First, the decision factor of the selected individuals is the center of the circle, and then the search is performed within the determined search range, where the search radius and search density can be set by ourselves, and the higher the radius and density, the stronger the local search capability, and at the same time the computing effort will increase. Generally speaking, individuals with high adaptability will be closer to the Pareto optimal solution boundary, and the local search operation for these individuals can effectively improve the search efficiency of the algorithm.
4.3. Intergenerational Crossover
The standard SPEA2 algorithm uses tournament selection to select individuals from an external archive to generate a mating pool. As the number of individuals in the non-dominated solution gradually increases, this approach reduces the genetic composition of the resulting next generation because it has a high probability of selecting similar individuals to generate a mating pool. Intergenerational crossover uses tournament selection with replacement to select an individual from the current generation external archive set while selecting an individual from the previous generation archive set. Compared to the original crossover, intergenerational crossover generates both good and bad individuals, so we keep only the best solutions from both intergenerational and original crossovers.
On the other hand, we evaluate the similarity of individuals before performing a crossover, and only perform a crossover operation on two individuals when the difference between them exceeds the maximum threshold of similarity. Many related works use the number of identical gene positions of chromosomes as individual similarity, which is simple to operate but has some drawbacks. For binary coding, there may be many identical gene positions in two chromosomes corresponding to the same position, but their corresponding actual values may be very different, which may easily cause the Hamming cliff phenomenon [35]. Therefore, this paper adopts the Euclidean distance of individuals to be crossed as the measure of individual similarity. Its corresponding formula is:
where, denotes the Euclidean distance between individuals to be crossed and denotes the set maximum similarity threshold.
4.4. Algorithm Complexity Analysis
The computational complexity of the NSGA-II, MOEA/D and SPEA2 algorithms are , and . The computational complexity of SPMOO proposed in this paper is , where r is the number of objective functions and N is the population size. The evaluation population set P, external archive A and empty local search set are taken into consideration simultaneously in SPMOO, so . Compared with the SPEA2 algorithm, the SPMOO algorithm optimizes the evolutionary selection mechanism without increasing time complexity, which reduces mutation and crossover operations of optimal solutions and accelerates the iteration speed.
5. Simulation Results
In this section, we conducted a large number of experiments to verify and evaluate our algorithm. Firstly, we describe the experimental setup and several benchmark methods. Then, we do some comparison with the benchmark methods and finally we analyze and evaluate the experimental results.
5.1. Simulation Settings
In the simulation experiments, we set the number of endpoint devices to 40 by default. Since the number of edge layer nodes is usually much smaller than the number of endpoint layers, we set the number of servers to eight by default. The execution time of the tasks varies from device to device, since they have different processing capabilities. All parameters used in the experiments are shown in Table 2.
Table 2.
Parameters and values.
We compare the proposed SPMOO algorithm with the following three benchmark algorithms, which are described as follows.
ALE (All Local Execution), which does not consider the resources of edge nodes and cloud nodes, with all tasks processed locally on the device.
RA (Random Allocation), which randomly places all subtasks, except those that can only be executed locally, to the edge or cloud nodes.
GA (Genetic Algorithm), which simulates the natural biological evolution mechanism and performs efficient, parallel random global search and optimization for all policies, and adaptively controls the search process to find the optimal solution.
5.2. Analysis and Evaluation
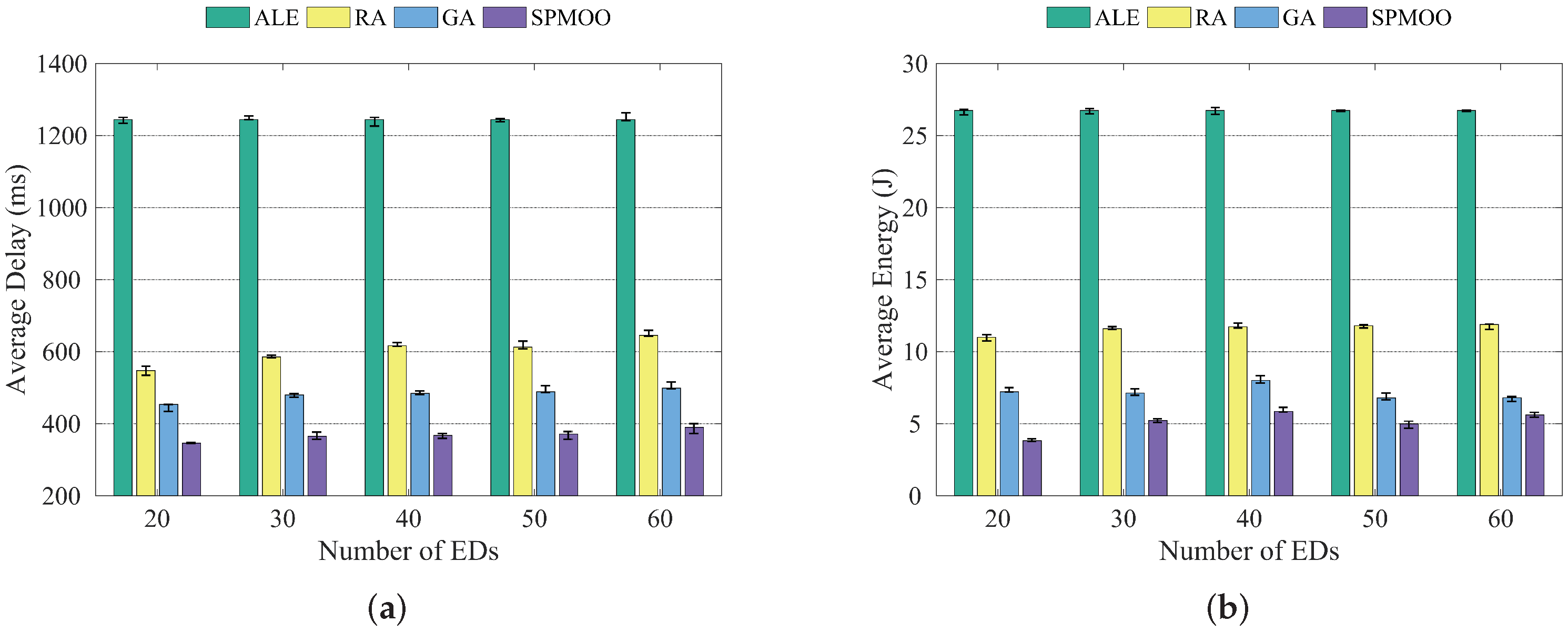
From Figure 4a, we can see that the average delay of the four algorithms does not change much when the number of end devices increases, and the average delay of the SPMOO algorithm proposed in this paper is the lowest among the four algorithms. This is mainly due to the full consideration of the environmental factors in the subtask offloading process, such as the computing power of the edge server and the communication laws between subtasks and nodes, which make our algorithm more accurate and efficient in performing task offloading. The traditional GA algorithm does not introduce methods such as local search strategy and intergenerational crossover strategy, which leads to a gap between it and the algorithm proposed in this paper in terms of constraint processing. The RA algorithm does not use an optimization algorithm for the node offloading location, so it performs poorly in terms of both average delay and average energy consumption. The analysis of the average energy consumption in Figure 4a is similar to the analysis in Figure 4b.
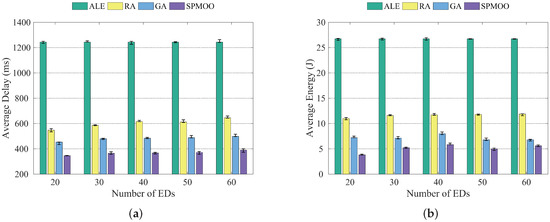
Figure 4.
Comparison of the four algorithms when the number of end devices is {20, 30, 40, 50, 60}; (a) Average delay; (b) Average energy consumption.
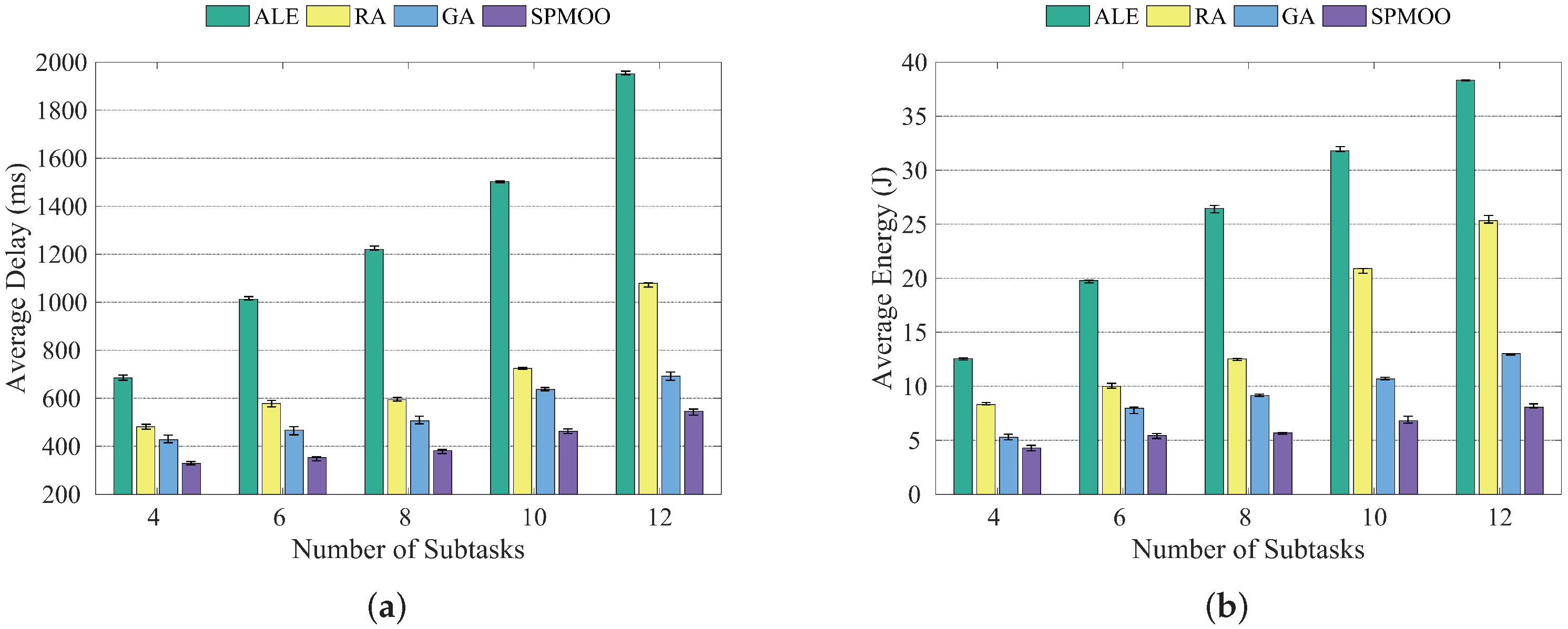
It can be seen in Figure 5a,b that when the number of end devices is kept constant and the number of subtasks increases, the average latency of all four algorithms increases accordingly, while the SPMOO algorithm proposed in this paper has the best results.
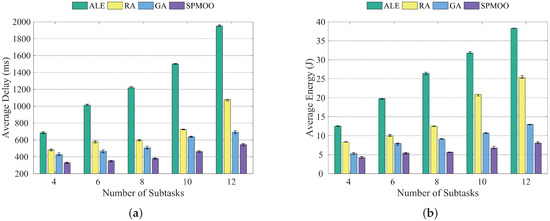
Figure 5.
Comparison of the four algorithms when the number of subtasks is {4, 6, 8, 10, 12}; (a) Average delay; (b) Average energy consumption.
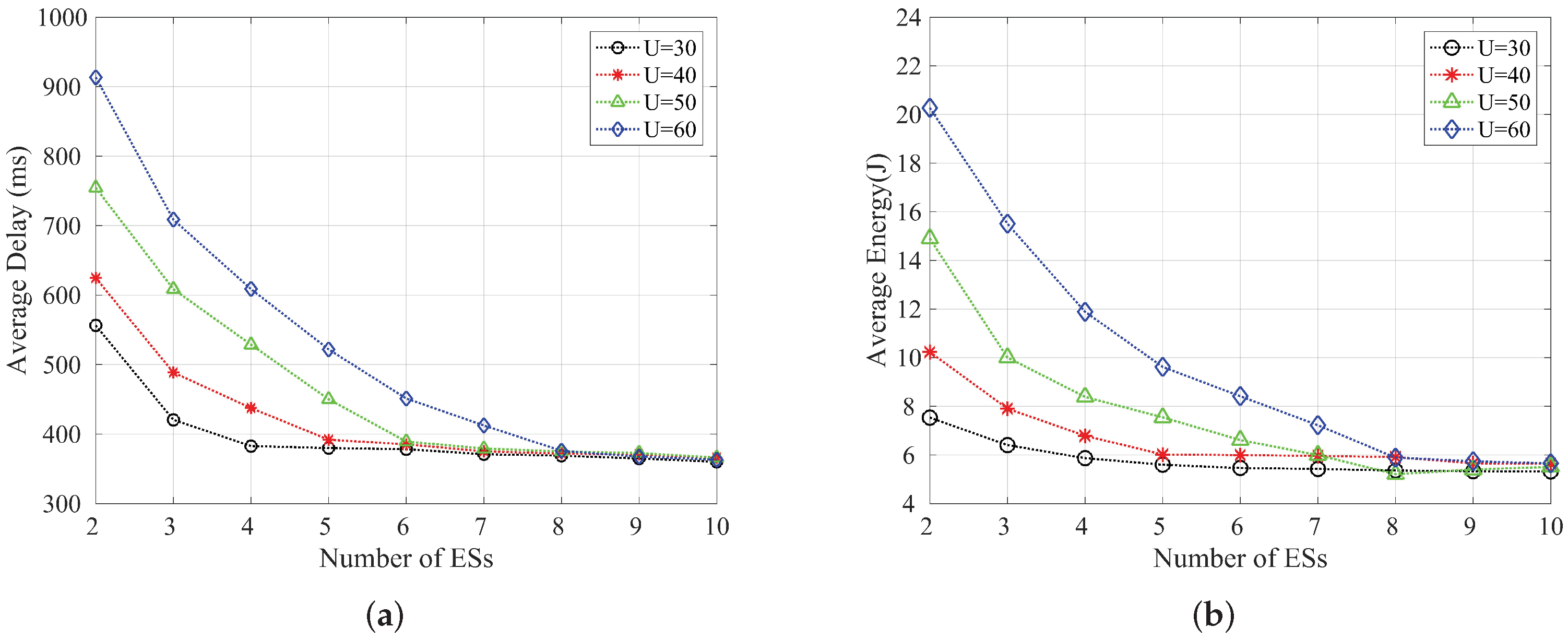
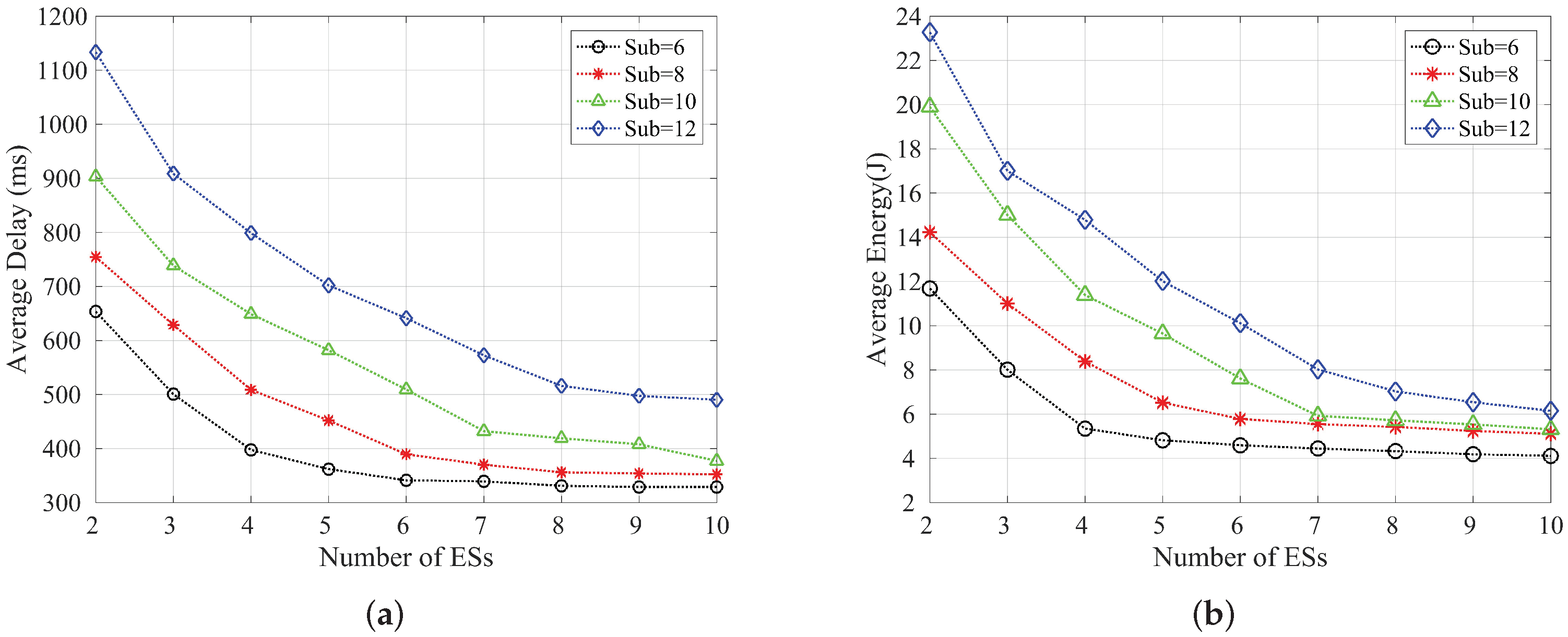
Figure 6a,b show the graphs of average delay and average energy consumption with the number of edge servers when the number of end devices is 10, 15, 20 and 25, respectively. We can see that the latency and energy consumption slowly decrease with the increase of the number of edge servers, and when the number of edge servers reaches eight, the average latency and average energy consumption can basically reach an optimal state. Therefore, in order to improve the utilization of resources and allocate them rationally, we can occupy as few edge servers’ resources as possible while ensuring the latency and energy consumption requirements. Figure 7a,b show the graphs of average delay and average energy consumption with the number of edge servers when the number of subtasks is 6, 8, 10 and 12, respectively. Similarly, the average delay and average energy consumption can be seen to decrease and stabilize as the number of edge servers increases.
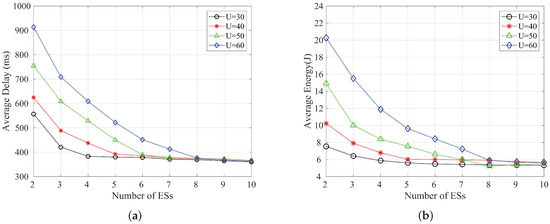
Figure 6.
Variation of the average delay and the average energy consumption with the number of edge servers when the number of end devices is {30, 40, 50, 60} respectively; (a) Average delay; (b) Average energy consumption.
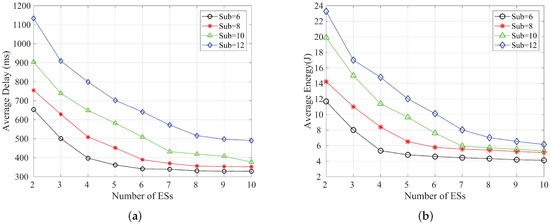
Figure 7.
Variation of the average delay and the average energy consumption with the number of edge servers when the number of subtasks is {6, 8, 10, 12} respectively; (a) Average delay; (b) Average energy consumption.
6. Conclusions
In this paper, we study the multi-objective optimization task offloading problem with resource-constrained edge servers in an IoT environment. To address this problem, we construct a cloud-edge-end-collaborative computing offload architecture consisting of end device layer, edge layer and cloud layer. Based on this, we construct a latency and energy consumption model by introducing two-dimensional offloading decision factors, and formalize the model as a multi-objective optimization problem with the optimization objective of minimizing the average latency and average energy consumption of task offloading, and then propose a multi-objective offloading (SPMOO) algorithm based on an improved strength Pareto evolutionary algorithm (SPEA2) for solving the problem. Extensive experiments show that our proposed method can significantly reduce the overall average delay and average energy consumption of the system. However, our method is less adaptable to new scenarios and takes a lot of time to get new offload decisions when the type of offload tasks or device resources change. Therefore, in future work we will further explore how to get offload decisions faster in dynamically changing heterogeneous scenarios by combining the feature of deep reinforcement learning that builds on prior experience to significantly accelerate the learning of new tasks.
Author Contributions
Data curation, L.L.; methodology, L.L.; funding acquisition, H.C.; formal analysis, Z.X.; visualization, L.L.; supervision, H.C.; writing—original draft, L.L.; writing—review and editing, H.C. and Z.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Ningbo Natural Science Foundation grant number 2021J090.
Institutional Review Board Statement
Not Applicable, the study does not involve humans or animals.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not Applicable, the study does not report any data.
Conflicts of Interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
References
- Mehmood, Y.; Ahmad, F.; Yaqoob, I.; Adnane, A.; Imran, M.; Guizani, S. Internet-of-Things-Based Smart Cities: Recent Advances and Challenges. IEEE Commun. Mag. 2017, 55, 16–24. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- Mallapuram, S.; Ngwum, N.; Yuan, F.; Lu, C.; Yu, W. Smart City: The State of the Art, Datasets, and Evaluation Platforms. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 447–452. [Google Scholar] [CrossRef]
- Wang, K. Migration strategy of cloud collaborative computing for delay-sensitive industrial IoT applications in the context of intelligent manufacturing. Comput. Commun. 2020, 150, 413–420. [Google Scholar] [CrossRef]
- Arias, O.; Wurm, J.; Hoang, K.; Jin, Y. Privacy and Security in Internet of Things and Wearable Devices. IEEE Trans. Multi-Scale Comput. Syst. 2015, 1, 99–109. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, M.; Su, Z. Task Allocation with Unmanned Surface Vehicles in Smart Ocean IoT. IEEE Internet Things J. 2020, 7, 9702–9713. [Google Scholar] [CrossRef]
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments, and challenges for enterprises. Bus. Horiz. 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Premsankar, G.; Di Francesco, M.; Taleb, T. Edge Computing for the Internet of Things: A Case Study. IEEE Internet Things J. 2018, 5, 1275–1284. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Tian, Y.; Yang, J.; Taleb, T.; Xiang, L.; Hao, Y. Ready Player One: UAV-Clustering-Based Multi-Task Offloading for Vehicular VR/AR Gaming. IEEE Netw. 2019, 33, 42–48. [Google Scholar] [CrossRef] [Green Version]
- Ning, H.; Farha, F.; Mohammad, Z.N.; Daneshmand, M. A Survey and Tutorial on “Connection Exploding Meets Efficient Communication” in the Internet of Things. IEEE Internet Things J. 2020, 7, 10733–10744. [Google Scholar] [CrossRef]
- Bouras, M.A.; Farha, F.; Ning, H. Convergence of Computing, Communication, and Caching in Internet of Things. Intell. Converg. Netw. 2020, 1, 18–36. [Google Scholar] [CrossRef]
- Reznik, A.; Murillo, L.M.C.; Fang, Y.; Featherstone, W.; Filippou, M.; Fontes, F.; Giust, F.; Huang, Q.; Li, A.; Turyagyenda, C.; et al. Cloud RAN and MEC: A Perfect Pairing; ETSI White Paper; ETSI: Sophia Antipolis, France, 2018; pp. 1–24. [Google Scholar]
- Hu, X.; Wang, L.; Wong, K.K.; Tao, M.; Zhang, Y.; Zheng, Z. Edge and Central Cloud Computing: A Perfect Pairing for High Energy Efficiency and Low-Latency. IEEE Trans. Wirel. Commun. 2020, 19, 1070–1083. [Google Scholar] [CrossRef]
- Han, Z.; Tan, H.; Li, X.Y.; Jiang, S.H.C.; Li, Y.; Lau, F.C.M. OnDisc: Online Latency-Sensitive Job Dispatching and Scheduling in Heterogeneous Edge-Clouds. IEEE/ACM Trans. Netw. 2019, 27, 2472–2485. [Google Scholar] [CrossRef]
- Li, L.; Guo, M.; Ma, L.; Mao, H.; Guan, Q. Online Workload Allocation via Fog-Fog-Cloud Cooperation to Reduce IoT Task Service Delay. Sensors 2019, 19, 3830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meng, J.; Tan, H.; Li, X.Y.; Han, Z.; Li, B. Online Deadline-Aware Task Dispatching and Scheduling in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1270–1286. [Google Scholar] [CrossRef]
- Wu, H.; Wolter, K.; Jiao, P.; Deng, Y.; Zhao, Y.; Xu, M. EEDTO: An Energy-Efficient Dynamic Task Offloading Algorithm for Blockchain-Enabled IoT-Edge-Cloud Orchestrated Computing. IEEE Internet Things J. 2021, 8, 2163–2176. [Google Scholar] [CrossRef]
- Ouyang, T.; Li, R.; Chen, X.; Zhou, Z.; Tang, X. Adaptive User-managed Service Placement for Mobile Edge Computing: An Online Learning Approach. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 1468–1476. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Guan, C.; Wolter, K.; Xu, M. Collaborate Edge and Cloud Computing with Distributed Deep Learning for Smart City Internet of Things. IEEE Internet Things J. 2020, 7, 8099–8110. [Google Scholar] [CrossRef]
- Alfakih, T.; Hassan, M.M.; Gumaei, A.; Savaglio, C.; Fortino, G. Task Offloading and Resource Allocation for Mobile Edge Computing by Deep Reinforcement Learning Based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Lakhan, A.; Li, X. Content Aware Task Scheduling Framework for Mobile Workflow Applications in Heterogeneous Mobile-Edge-Cloud Paradigms: CATSA Framework. In Proceedings of the 2019 IEEE Intl Conf on Parallel Distributed Processing with Applications, Big Data Cloud Computing, Sustainable Computing Communications, Social Computing Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 242–249. [Google Scholar] [CrossRef]
- De Maio, V.; Kimovski, D. Multi-objective Scheduling of Extreme Data Scientific Workflows in Fog. Future Gener. Comput. Syst. 2020, 106, 171–184. [Google Scholar] [CrossRef]
- Ding, S.; Yang, L.; Cao, J.; Cai, W.; Tan, M.; Wang, Z. Partitioning Stateful Data Stream Applications in Dynamic Edge Cloud Environments. IEEE Trans. Serv. Comput. 2021, 1, 1. [Google Scholar] [CrossRef]
- Wang, S.; Ding, Z.; Jiang, C. Elastic Scheduling for Microservice Applications in Clouds. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 98–115. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, W. Computation Offloading in Heterogeneous Mobile Edge Computing with Energy Harvesting. IEEE Trans. Green Commun. Netw. 2021, 5, 552–565. [Google Scholar] [CrossRef]
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A Novel Framework for Mobile-Edge Computing by Optimizing Task Offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Miao, Y.; Wu, G.; Li, M.; Ghoneim, A.; Al-Rakhami, M.; Hossain, M.S. Intelligent Task Prediction and Computation Offloading based on Mobile-Edge Cloud Computing. Future Gener. Comput. Syst. 2020, 102, 925–931. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Yu, H.; Fan, G.; Chen, L. Energy and Time Efficient Task Offloading and Resource Allocation on the Generic IoT-Fog-Cloud Architecture. Peer-to-Peer Netw. Appl. 2020, 13, 548–563. [Google Scholar] [CrossRef]
- Liu, H.; Eldarrat, F.; Alqahtani, H.; Reznik, A.; de Foy, X.; Zhang, Y. Mobile Edge Cloud System: Architectures, Challenges, and Approaches. IEEE Syst. J. 2018, 12, 2495–2508. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; Eidgenössische Technische Hochschule Zürich (ETH): Zürich, Switzerland, 2001. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Xu, X.; Wu, Q.; Qi, L.; Dou, W.; Tsai, S.B.; Bhuiyan, M.Z.A. Trust-Aware Service Offloading for Video Surveillance in Edge Computing Enabled Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1787–1796. [Google Scholar] [CrossRef]
- Strasser, S.; Goodman, R.; Sheppard, J.; Butcher, S. A New Discrete Particle Swarm Optimization Algorithm. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), Denver, CO, USA, 20–24 July 2016; pp. 53–60. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).