
A Framework for Building Comprehensive Driver Profiles

Abstract
:1. Introduction
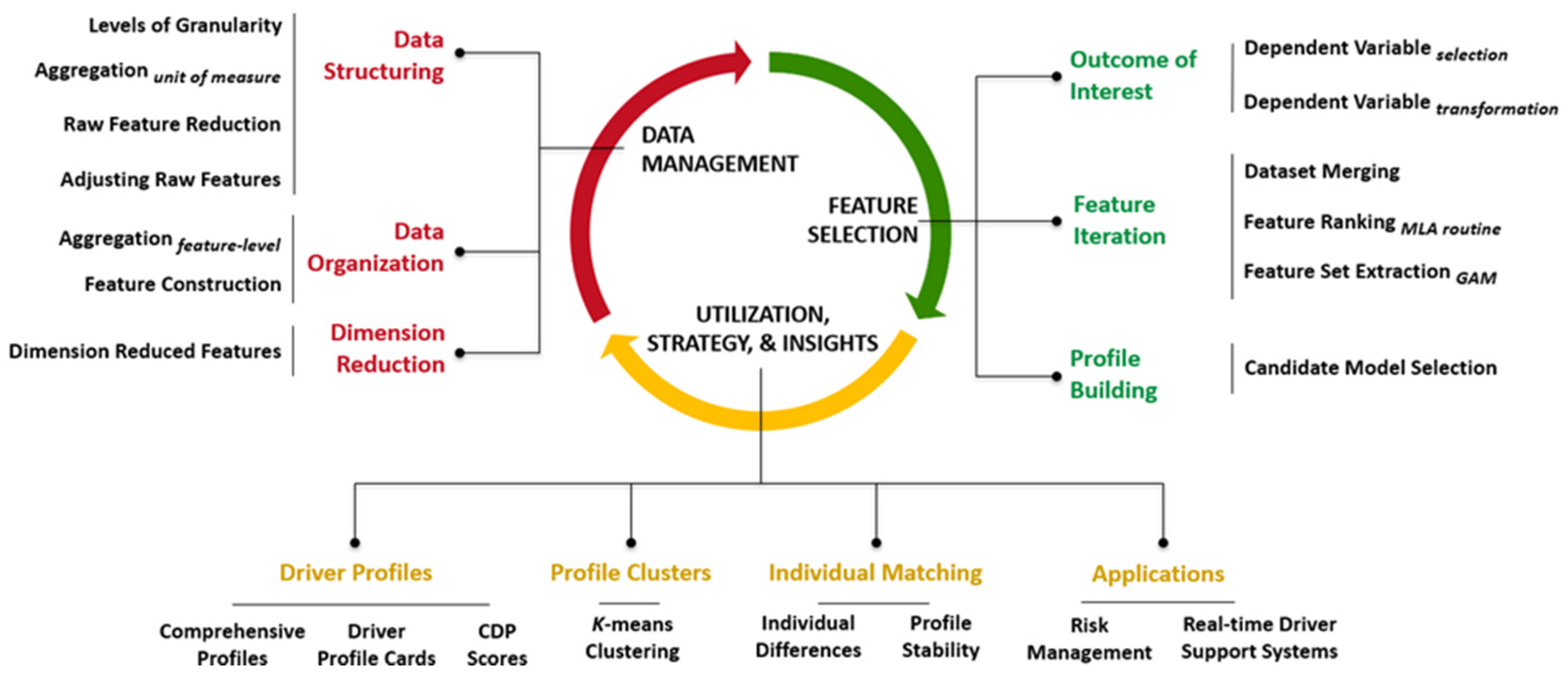
2. A Framework for Building Comprehensive Driver Profiles
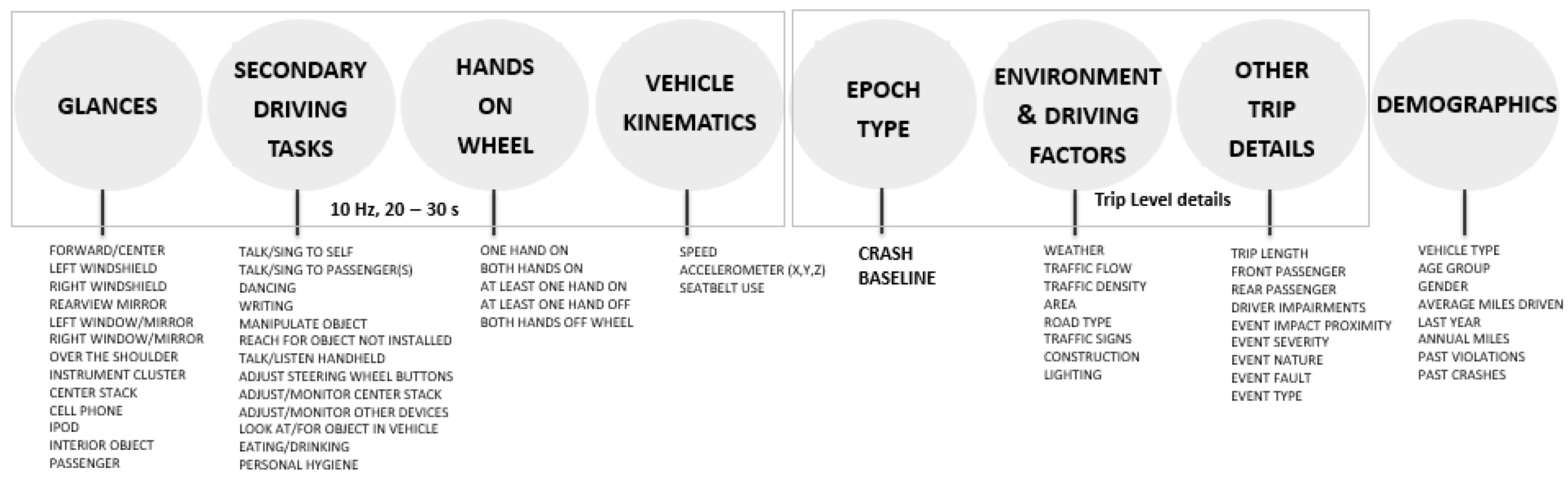
2.1. Naturalistic Engagement in Secondary Tasks (NEST) Dataset
2.2. CDP Step 1: Data Management
2.3. CDP Step 2: Feature Selection
3. Results: CDP Step 3: Utilization, Strategy, and Insights
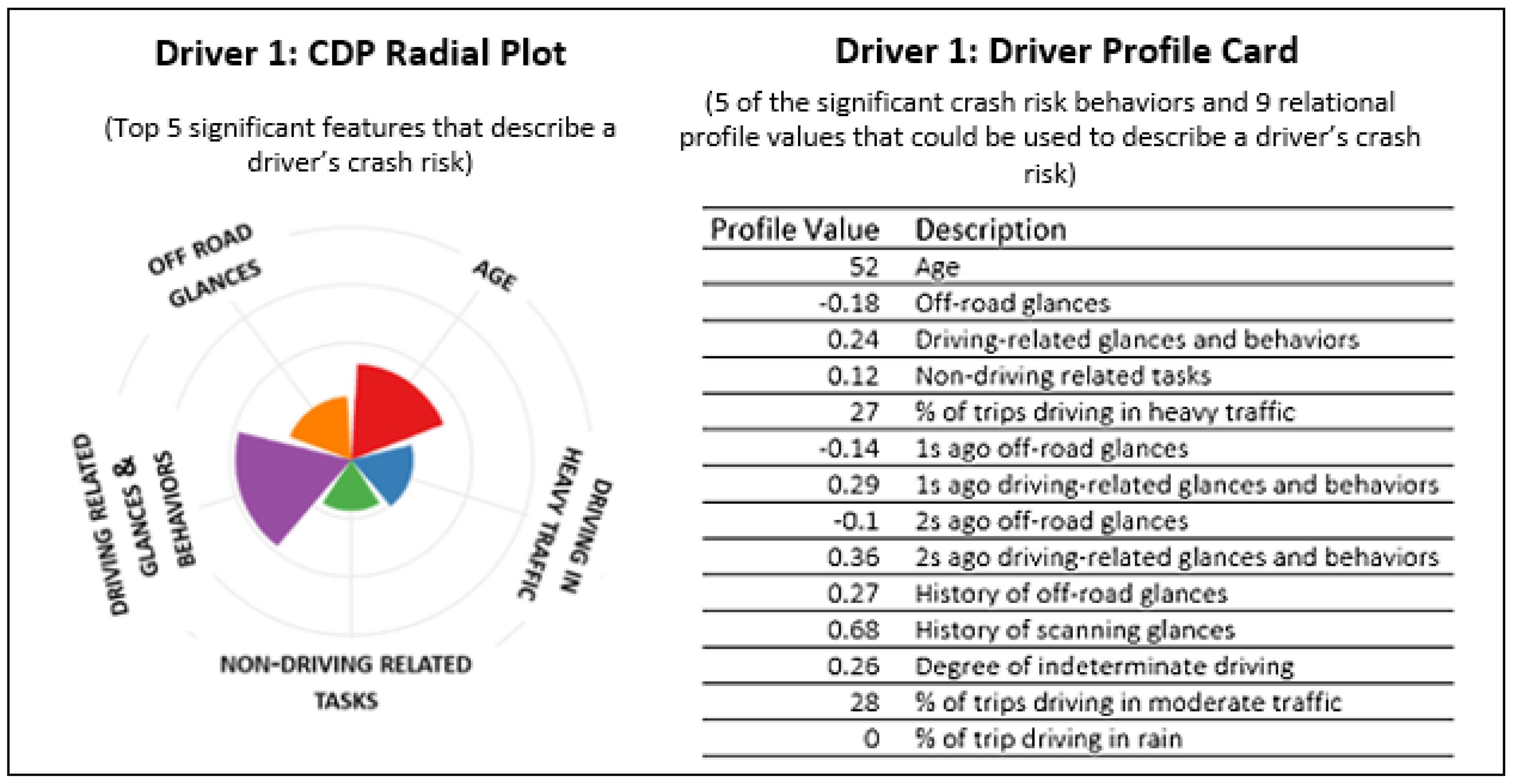
3.1. Driver Profile Cards
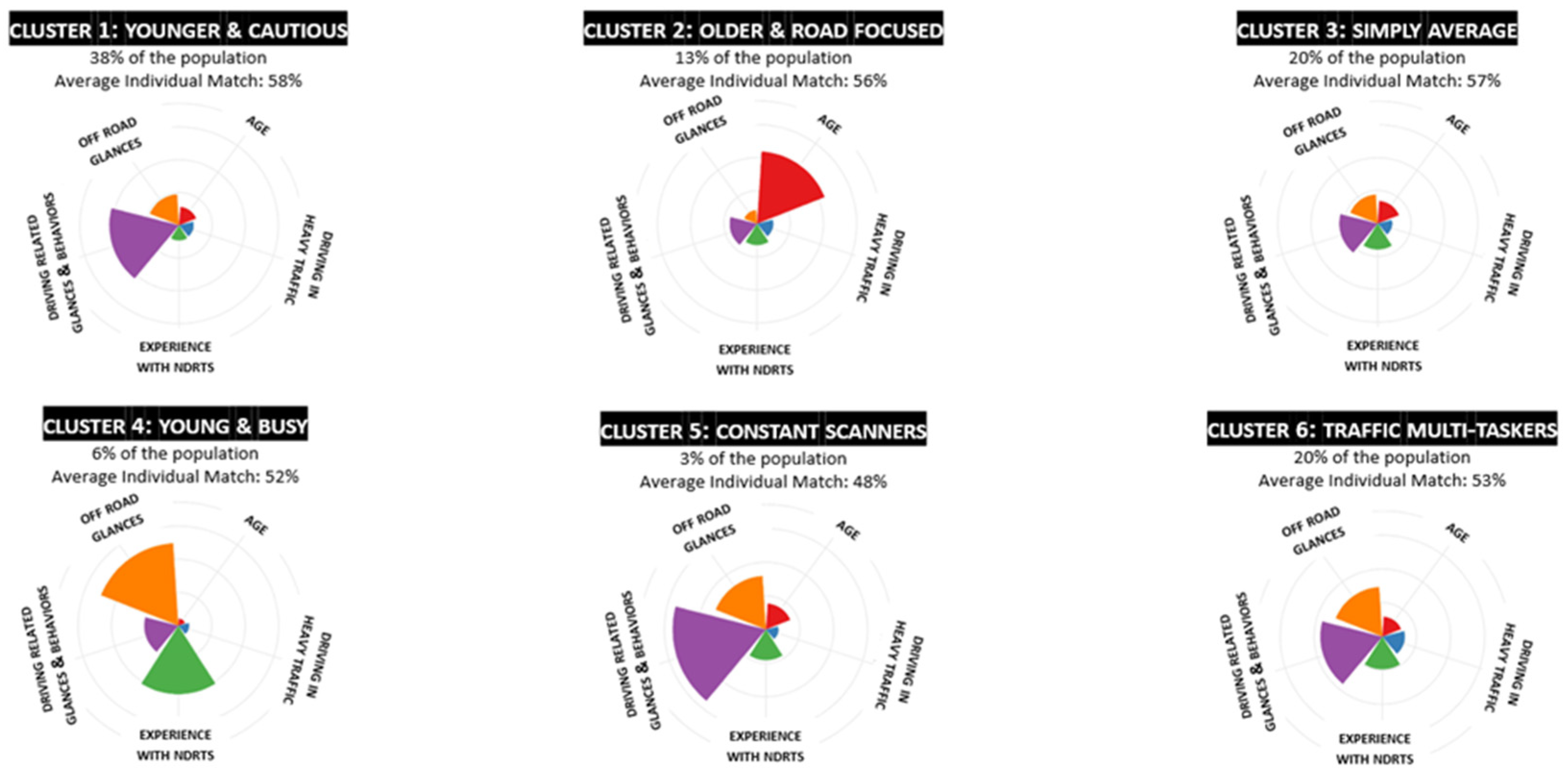
3.2. Comprehensive Driver Profile (CDP) Clusters
3.3. Driver Profile Stability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- De Winter, J.C.F.; Happee, R. Modelling Driver Behaviour: A Rationale for Multivariate Statistics. Theor. Issues Ergon. Sci. 2012, 3, 528–545. [Google Scholar] [CrossRef]
- Abdelrahman, A. Driver Behavior Modelling and Risk Profiling Using Large-Scale Naturalistic Driving Data. Ph.D. Thesis, Queen’s University, Kingston, ON, Canada, 2019. [Google Scholar]
- Sagberg, F.; Selpi; Piccinini, G.F.B.; Engström, J. A Review of Research on Driving Styles and Road Safety. Hum. Factors J. Hum. Factors Ergon. Soc. 2015, 57, 1248–1275. [Google Scholar] [CrossRef] [PubMed]
- Griesche, S.; Krähling, M.; Käthner, D. Conform—A Visualization Tool and Method to Classify Driving Styles in Context of Highly Automated Driving. VDI/VW Gem. Fahr. Integr. Sich. 2014, 30, 101–110. [Google Scholar]
- Toledo, T.; Musicant, O.; Lotan, T. In-vehicle data recorders for monitoring and feedback on drivers’ behavior. Transp. Res. Part C Emerg. Technol. 2008, 16, 320–331. [Google Scholar] [CrossRef]
- Jun, J. Potential Crash Measures Based On Gps-Observed Driving Behavior Activity Metrics. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2006. [Google Scholar]
- Bagdadi, O.; Várhelyi, A. Jerky Driving—An Indicator of Accident Proneness? Accid. Anal. Prev. 2011, 43, 1359–1363. [Google Scholar] [CrossRef]
- Ellison, A.B.; Greaves, S.P.; Bliemer, M.C. Driver behaviour profiles for road safety analysis. Accid. Anal. Prev. 2015, 76, 118–132. [Google Scholar] [CrossRef]
- Shope, J.T. Influences on youthful driving behavior and their potential for guiding interventions to reduce crashes. Inj. Prev. 2006, 12, i9–i14. [Google Scholar] [CrossRef]
- Ellickson, P.L.; Tucker, J.S.; Klein, D.J.; Saner, H. Antecedents and Outcomes of Marijuana Use Initiation during Adolescence. Prev. Med. 2004, 39, 976–984. [Google Scholar] [CrossRef]
- Bina, M.; Graziano, F.; Bonino, S. Risky driving and lifestyles in adolescence. Accid. Anal. Prev. 2005, 38, 472–481. [Google Scholar] [CrossRef]
- Strayer, D.L.; Drews, F.A. Profiles in Driver Distraction: Effects of Cell Phone Conversations on Younger and Older Drivers. Hum. Factors J. Hum. Factors Ergon. Soc. 2004, 46, 640–649. [Google Scholar] [CrossRef]
- Júnior, J.F.; Carvalho, E.; Ferreira, B.V.; de Souza, C.; Suhara, Y.; Pentland, A.; Pessin, G. Driver Behavior Profiling: An Investigation with Different Smartphone Sensors and Machine Learning. PLoS ONE 2017, 12, e0174959. [Google Scholar]
- Chang, W. Research on Driving Intention Identification Based on Hidden Markov Model. Master’s Thesis, Jilin University, Changchun, China, 2011. [Google Scholar]
- Mei, N.N.; Wang, Z.J. Moving Object Detection Algorithm Based on Gaussian Mixture Model. Comput. Eng. Des. 2012, 33, 3149–3153. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction Apis. arXiv 2016, arXiv:1609.02943. [Google Scholar]
- Castignani, G.; Derrmann, T.; Frank, R.; Engel, T. Driver Behavior Profiling Using Smartphones: A Low-Cost Platform for Driver Monitoring. IEEE Intell. Transp. Syst. Mag. 2015, 7, 91–102. [Google Scholar] [CrossRef]
- Owens, J.M.; Angell, L.; Hankey, J.M.; Foley, J.; Ebe, K. Creation of the Naturalistic Engagement in Secondary Tasks (NEST) distracted driving dataset. J. Saf. Res. 2015, 54, 33.e29–36. [Google Scholar] [CrossRef] [Green Version]
- Antin, J.; Lee, S.; Hankey, J.; Dingus, T. Design of the In-Vehicle Driving Behavior and Crash Risk Study. In Support of the SHRP 2 Naturalistic Driving Study; Strategic Highway Research Program Safety Focus Area; Transportation Research Board: Washington, DC, USA, 2011. [Google Scholar]
- Dingus, T.A.; Guo, F.; Lee, S.; Antin, J.F.; Perez, M.; Buchanan-King, M.; Hankey, J. Replication Data for: Driver crash risk factors and prevalence evaluation using naturalistic driving data. Proc. Natl. Acad. Sci. USA 2016, 113, 2636–2641. [Google Scholar] [CrossRef] [Green Version]
- Lewis, E.; Sheridan, C.; O’Farrell, M.; King, D.; Flanagan, C.; Lyons, W.; Fitzpatrick, C. Principal component analysis and artificial neural network based approach to analysing optical fibre sensors signals. Sens. Actuators A Phys. 2007, 136, 28–38. [Google Scholar] [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2019, 143, 106839. [Google Scholar] [CrossRef]
- Hand, D.J.; Till, R.J. A Simple Generalisation of the Area Under the Roc Curve for Multiple Class Classification Problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- Anukrishna, P.R.; Paul, V. A Review on Feature Selection for High Dimensional Data. In Proceedings of the 2017 International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2017; pp. 1–4. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM Sigkdd International Conference On Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression By Randomforest. R News 2002, 2, 18–22. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Cutler, A. Random Forest. 1995. Available online: https://www.Stat.Berkeley.Edu/~Breiman/Randomforests/ (accessed on 6 February 2021).
- Xu, R.; Nettleton, D.; Nordman, D.J. Case-Specific Random Forests. J. Comput. Graph. Stat. 2016, 25, 49–65. [Google Scholar] [CrossRef]
- Hastie, T.J. Generalized Additive Models; Routledge: Boca Raton, FL, USA, 2017. [Google Scholar]
- Derksen, S.; Keselman, H.J. Backward, forward and stepwise automated subset selection algorithms: Frequency of obtaining authentic and noise variables. Br. J. Math. Stat. Psychol. 1992, 45, 265–282. [Google Scholar] [CrossRef]
- Pan, W. Akaike’s Information Criterion in Generalized Estimating Equations. Biometrics 2001, 57, 120–125. [Google Scholar] [CrossRef]
- Weisstein, E.W. Bonferroni Correction. 2004. Available online: https://mathworld.wolfram.com/ (accessed on 23 May 2021).
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. Nbclust: An R Package for Determining the Relevant Number of Clusters In A Data Set. Ournal of Statistical Software 2014. Available online: Http://Www.Jstatsoft.Org/V61/I06/ (accessed on 4 March 2021).
- Lewis-Evans, B.; de Waard, D.; Brookhuis, K.A. Speed maintenance under cognitive load—Implications for theories of driver behaviour. Accid. Anal. Prev. 2011, 43, 1497–1507. [Google Scholar] [CrossRef] [Green Version]
- Abney, S. Bootstrapping. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadephia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 360–367. [Google Scholar]
- Angkititrakul, P.; Ryuta, T.; Wakita, T.; Takeda, K.; Miyajima, C.; Suzuki, T. Evaluation Of Driver-Behavior Models In Real-World Car-Following Task. In Proceedings of the 2009 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Pune, India, 11–12 November 2009; pp. 113–118. [Google Scholar]
- Ericsson, E. Variability in urban driving patterns. Transp. Res. Part D Transp. Environ. 2000, 5, 337–354. [Google Scholar] [CrossRef]
- Dong, W.; Li, J.; Yao, R.; Li, C.; Yuan, T.; Wang, L. Characterizing Driving Styles with Deep Learning. arXiv 2016, arXiv:1607.03611. [Google Scholar]
- Lin, N.; Zong, C.; Tomizuka, M.; Song, P.; Zhang, Z.; Li, G. An Overview on Study of Identification of Driver Behavior Characteristics for Automotive Control. Math. Probl. Eng. 2014, 2014, 569109. [Google Scholar] [CrossRef]
- Petkovic, D.; Altman, R.B.; Wong, M.; Vigil, A. Improving The Explainability of Random Forest Classifier-User Centered Approach. Pac. Symp. Biocomput. 2018, 23, 204–215. [Google Scholar]
- Watsford, R. The Success of the ’pinkie’ Campaign-Speeding. No One Thinks Big of You: A New Approach to Road Safety Marketing. In Proceedings of the Australasian College of Road Safety Conference, Washington, DC, USA, 9–13 January 2008; pp. 390–395. [Google Scholar]
- Faulks, I. Road Safety Advertising And Social Marketing. J. Australas. Coll. Road Saf. 2011, 22, 27. [Google Scholar]
- Lund, J.; Aarø, L. Accident prevention. Presentation of a model placing emphasis on human, structural and cultural factors. Saf. Sci. 2004, 42, 271–324. [Google Scholar] [CrossRef]
- Edquist, J.; Rudin-Brown, C.M.; Lenné, M.G. The Effects of On-Street Parking and Road Environment Visual Complexity on Travel Speed and Reaction Time. Accid. Anal. Prev. 2012, 45, 759–765. [Google Scholar] [CrossRef]
- World Health Organization. Global Status Report on Road Safety; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Richter, M.; Pape, H.C.; Otte, D.; Krettek, C. Improvements In Passive Car Safety Led To Decreased Injury Severity–A Comparison Between the 1970s and 1990s. Injury 2005, 36, 484–488. [Google Scholar] [CrossRef] [PubMed]
- Ellison, A.B. Evaluating Changes in Driver Behaviour for Road Safety Outcomes: A Risk Profiling Approach. Ph.D. Thesis, The University of Sydney, Sydney, Australia, 2013. [Google Scholar]
- SAE. Surface Vehicle Recommended Practice; SAE: Warrendale, PA, USA, 2016. [Google Scholar]
- Lee, J.D.; See, K.A. Trust in Automation: Designing for Appropriate Reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef] [PubMed]
- Pyta, V.; Mctiernan, D. Development of A Model for Improving Safety in School Zones. In Proceedings of the Australasian Road Safety Research, Policing and Education Conference, Monash University, Melbourne, Australia, 31 August–3 September 2010. [Google Scholar]
- Litman, T. Distance-Based Vehicle Insurance Feasibility, Costs and Benefits; Victoria Transport Policy Institute: Victoria, BC, Canada, 2007. [Google Scholar]
- Ong, P.M.; Stoll, M.A. Why Do Inner City Residents Pay Higher Premiums? The Determinants of Automobile Insurance Premiums; School of Public Affairs: Los Angeles, CA, USA, 2008. [Google Scholar]
- Handel, P.; Skog, I.; Wahlstrom, J.; Bonawiede, F.; Welch, R.; Ohlsson, J.; Ohlsson, M. Insurance Telematics: Opportunities and Challenges with the Smartphone Solution. IEEE Intell. Transp. Syst. Mag. 2014, 6, 57–70. [Google Scholar] [CrossRef]
- Regan, M.A.; Prabhakharan, P.; Wallace, P.; Cunningham, M.L.; Bennett, J.M. Education and Training for Drivers of Assisted and Automated Vehicles; ARRB Group Limited: Sydney, Australia, 2020. [Google Scholar]
- NHTSA. Federal Automated Vehicles Policy–Accelerating the Next Revolution in Roadway Safety; NHTSA: Washington, DC, USA, 2016.
- Klauer, S.G.; Dingus, T.A.; Neale, V.L.; Sudweeks, J.D.; Ramsey, D.J. Comparing Real-World Behaviors of Drivers With High versus Low Rates of Crashes and Near-Crashes; NHTSA: Washington, DC, USA, 2009.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Levels | ||||
|---|---|---|---|---|
| Variables | Varies at Sample (M Dataset) | Varies at Segment (S Dataset) | Varies at Trip (T Dataset) | Varies at Driver (D Dataset) |
| Elevated driving kinematics (EDKs) | x | |||
| Glances | x | |||
| non-driving related tasks (NDRTs) | x | |||
| Hands-off-wheel | x | |||
| Environmental factors | x | |||
| Driver demographics | x | |||
| Dataset Feature Groups | Glances | Hands on Wheel | Tasks | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset Features (n = 141) | Forward Road Glance | Glance to Cell Phone | … | Glances to the Left Window | One Hand on One Hand Off | Talking to Passenger | … | Center Stack Controls | |
| Aggregated to 1 s (sample level) | 5 s | 0.72 | 0.12 | 0.15 | 0.06 | 0.00 | 0.00 | ||
| 6 s | 0.76 | 0.09 | 0.10 | 0.26 | 0.00 | 0.00 | |||
| 7 s | 0.84 | 0.06 | 0.00 | 0.46 | 0.00 | 0.00 | |||
| PCA Quadrant | Quadrant Description |
|---|---|
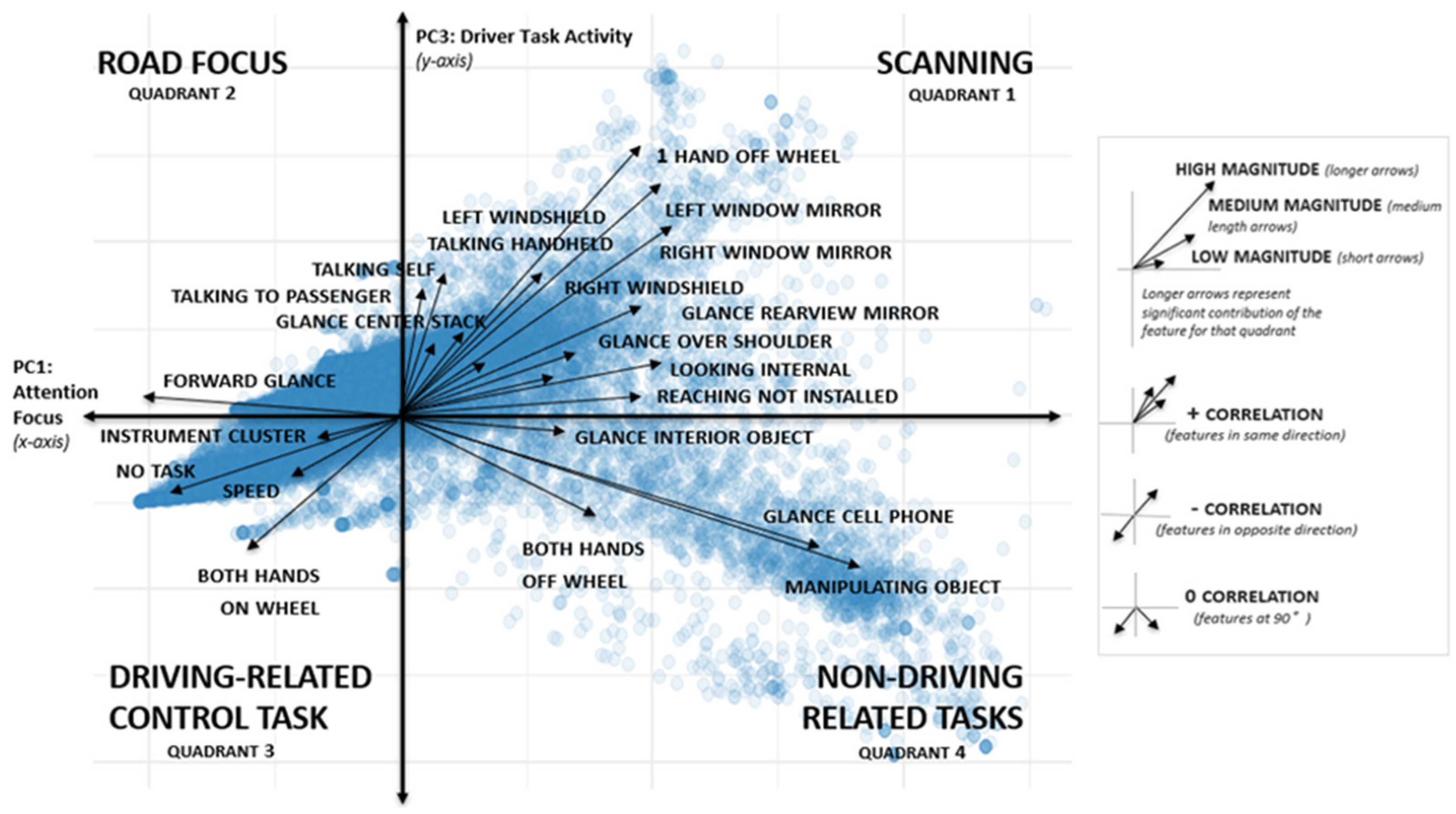
| Quadrant 1: Scanning | Data show glance behavior in which the eyes were actively scanning (from the road ahead to the vehicle interior and back to the road, as well as moving to check mirrors (right, left, and inside rear-view mirrors), moving to view right and left peripheral areas of the road (through the windshield, etc.). These glance behaviors were associated with one-hand-off-steering-wheel, reaching for devices that are not installed (e.g., handheld phones), and also three types of talking (to self, passenger, and handheld phone). Additionally, when talking on a handheld phone, drivers may be holding it with one hand. It is also possible that when talking to passengers, drivers might be gesturing with one hand. |
| Quadrant 2: Road Focus | Shows glance behavior in which the eyes were “focused on the road”. This tended to be associated with road-focused driving in the absence of other maneuvers and non-driving related tasks. |
| Quadrant 3: Driving-Related Control Task | In this quadrant, drivers tended to have both hands-on-the-wheel, checked the speedometer, were doing no other tasks (and this quadrant fell on the same horizontal side of the coordinate system as glances that were focused forward on the road in Quadrant 2). |
| Quadrant 4: Non-Driving-Related Tasks (NDRTs) | In this quadrant, drivers tended to take both hands off the wheel, tended to manipulate their cell phone (not dial or talk, perhaps texting or browsing), and manipulate other objects. |
| NEST Driving Behaviour Features | Rank | Relative Importance (Scaled to 0–1, with 1 Most Important) | Absolute Importance |
|---|---|---|---|
| 1 s Lagged Glances in Principal Component 1 | 1 | 1.00 | 0.0066 |
| 2 s Lagged Glances in Principal Component 1 | 2 | 0.84 | 0.0055 |
| Glances in Principal Component 1 | 3 | 0.72 | 0.0047 |
| Speed | 4 | 0.68 | 0.0045 |
| 2 s Lagged Glances in Principal Component 3 | 5 | 0.59 | 0.0039 |
| 2 s Lagged Road Glances | 6 | 0.51 | 0.0033 |
| 1 s Lagged Glances in Principal Component 3 | 7 | 0.49 | 0.0032 |
| 1 s Lagged Road Glances | 8 | 0.49 | 0.0032 |
| 3 s Lagged Road Glances | 9 | 0.43 | 0.0028 |
| Glances in Principal Component 3 | 10 | 0.41 | 0.0027 |
| Model Testing Requirements | Settings |
|---|---|
| Metric for determining quality of profile | AUC |
| Desired level of metric | AUC ≥ 0.75 |
| Lowest acceptable AUC level for statistical type I and type II errors | AUC > 0.70 |
| Significance level for determining metric that satisfies desired goal | 0.10 |
| Number of candidate models | 9 |
| Bonferroni corrected significance level | 0.011 |
| IF the TRUE AUC of the Profile Model Is: | Power Using 0.75 and 0.05 for the Minimal Accepted AUC and Significance Level | Power Using 0.70 and 0.10 for the Minimal Accepted AUC and Significance Level |
|---|---|---|
| 0.75 | 1% | 15% |
| 0.76 | 1% | 21% |
| 0.77 | 2% | 29% |
| 0.78 | 4% | 38% |
| 0.79 | 6% | 48% |
| 0.8 | 10% | 58% |
| 0.81 | 15% | 67% |
| 0.82 | 21% | 75% |
| 0.83 | 29% | 82% |
| 0.84 | 38% | 88% |
| 0.85 | 47% | 92% |
| 0.86 | 57% | 95% |
| 0.87 | 67% | 97% |
| 0.88 | 75% | 98% |
| 0.89 | 82% | 99% |
| 0.9 | 88% | 100% |
| Model Rank | Observed AUC on | Number of Features in Model | Profile Model Class | p-Value | Qualifies |
|---|---|---|---|---|---|
| 1 | 0.954 | 40 | Random Forest | 0.0000 | Yes |
| 2 | 0.864 | 25 | GAM | 0.0024 | Yes |
| 3 | 0.853 | 15 | GAM | 0.0054 | Yes |
| 4 | 0.847 | 8 | GAM | 0.0080 | Yes |
| 5 | 0.838 | 24 | GAM | 0.0145 | No |
| 6 | 0.819 | 13 | GAM | 0.0440 | No |
| 7 | 0.807 | 20 | GAM | 0.0788 | No |
| 8 | 0.785 | 17 | GAM | 0.1943 | No |
| 9 | 0.599 | 15 | GAM | 0.9999 | No |
| Parametric Coefficients | ||||
| Features | Estimated Degrees of Freedom | Standard Error | Z-Value | p-Value |
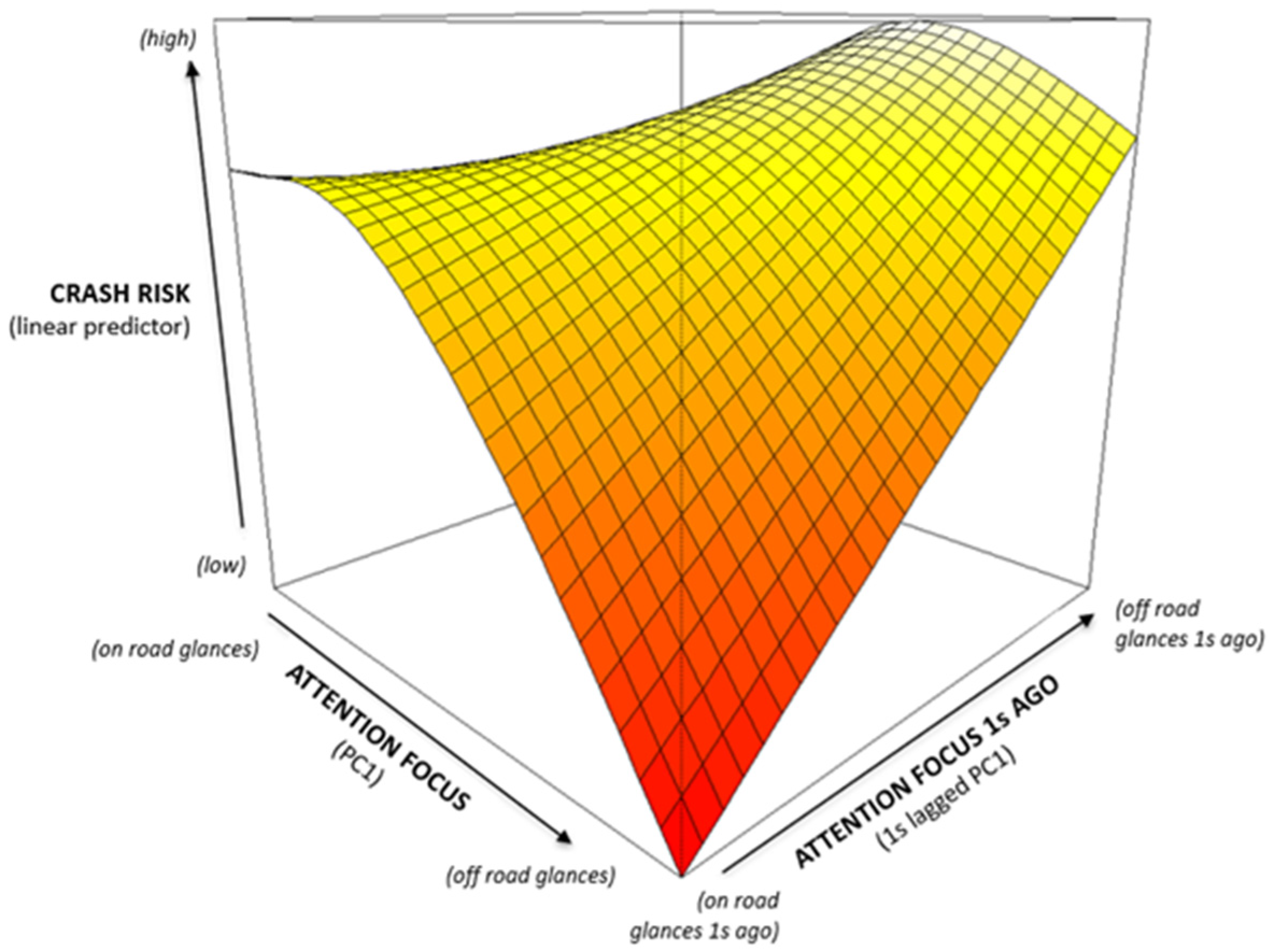
| Intercept | −5.18 | 0.16 | −31.47 | <0.0001 |
| Driving related glances and behaviors | −0.09 | 0.08 | −1.26 | 0.21 |
| Off-road glances | −0.39 | 0.09 | −4.40 | <0.0001 |
| Non-driving related tasks | −0.14 | 0.10 | −1.33 | 0.18 |
| Scanning glances | 0.14 | 0.30 | −0.48 | 0.63 |
| Driving in moderate traffic | 0.13 | 0.20 | 0.70 | 0.49 |
| Driving in heavy traffic | 0.51 | 0.23 | 2.26 | <0.05 |
| Driving in rain | 0.52 | 0.29 | 1.83 | <0.1 |
| Smooth Terms | ||||
| Features | Estimated Degrees of Freedom | Standard Error | ||
| PC1 | 2.90 | <0.0001 | ||
| PC3 | 3.11 | <0.05 | ||
| PC1, PC3 | 3.43 | <0.0001 | ||
| PC1.lag.1 s | 2.64 | <0.0001 | ||
| PC3.lag.1 s | 2.13 | 0.59 | ||
| PC1.lag.1 s, PC3.lag.1 s | 1.00 | <0.0001 | ||
| PC1.lag.2 s | 1.00 | 0.06 | ||
| PC3.lag.2 s | 3.62 | <0.05 | ||
| Driver | Win Cluster | Win % | Clusters | |||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |||
| 1 | 1 | 38% | 38 | 0 | 38 | 0 | 24 | 0 |
| 2 | 5 | 79% | 0 | 0 | 9 | 12 | 79 | 0 |
| 3 | 1 | 68% | 68 | 24 | 2 | 0 | 2 | 4 |
| 4 | 1 | 61% | 61 | 31 | 0 | 0 | 8 | 0 |
| 5 | 1 | 66% | 66 | 0 | 23 | 0 | 11 | 0 |
| 6 | 3 | 75% | 17 | 0 | 75 | 7 | 1 | 10 |
| 7 | 1 | 37% | 37 | 4 | 33 | 0 | 26 | 0 |
| 8 | 5 | 59% | 7 | 9 | 22 | 2 | 59 | 1 |
| 9 | 5 | 36% | 33 | 20 | 11 | 0 | 36 | 0 |
| 10 | 2 | 80% | 20 | 80 | 0 | 0 | 0 | 0 |
| 11 | 1 | 70% | 70 | 0 | 21 | 0 | 9 | 0 |
| 12 | 3 | 32% | 19 | 16 | 32 | 7 | 21 | 5 |
| 13 | 2 | 77% | 13 | 77 | 0 | 1 | 8 | 1 |
| 14 | 1 | 55% | 56 | 33 | 10 | 0 | 0 | 2 |
| 15 | 2 | 100% | 0 | 100 | 0 | 0 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Payyanadan, R.P.; Angell, L.S. A Framework for Building Comprehensive Driver Profiles. Information 2022, 13, 61. https://doi.org/10.3390/info13020061
Payyanadan RP, Angell LS. A Framework for Building Comprehensive Driver Profiles. Information. 2022; 13(2):61. https://doi.org/10.3390/info13020061
Chicago/Turabian StylePayyanadan, Rashmi P., and Linda S. Angell. 2022. "A Framework for Building Comprehensive Driver Profiles" Information 13, no. 2: 61. https://doi.org/10.3390/info13020061
APA StylePayyanadan, R. P., & Angell, L. S. (2022). A Framework for Building Comprehensive Driver Profiles. Information, 13(2), 61. https://doi.org/10.3390/info13020061