
A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection



Abstract
1. Introduction
- This paper surveys various feature-based methods and an assortment of ML and state-of-the-art transformer-based models used in the literature for fake news detection.
- This paper provides a benchmark study for a wide range of classical and advanced ML algorithms with pretrained word-embedding methods (i.e., context-free and context-aware) as well as advanced pretrained transformer-based models using various datasets.
- The experimental results indicate that no single technique can deliver the best performance scores across all datasets.
- In general, advanced PLMs such as BERT and RoBERTa are effective at detecting fake news.
2. Problem Definition
3. Related Works
3.1. Classical ML Algorithms
3.2. Advanced ML and DL Models
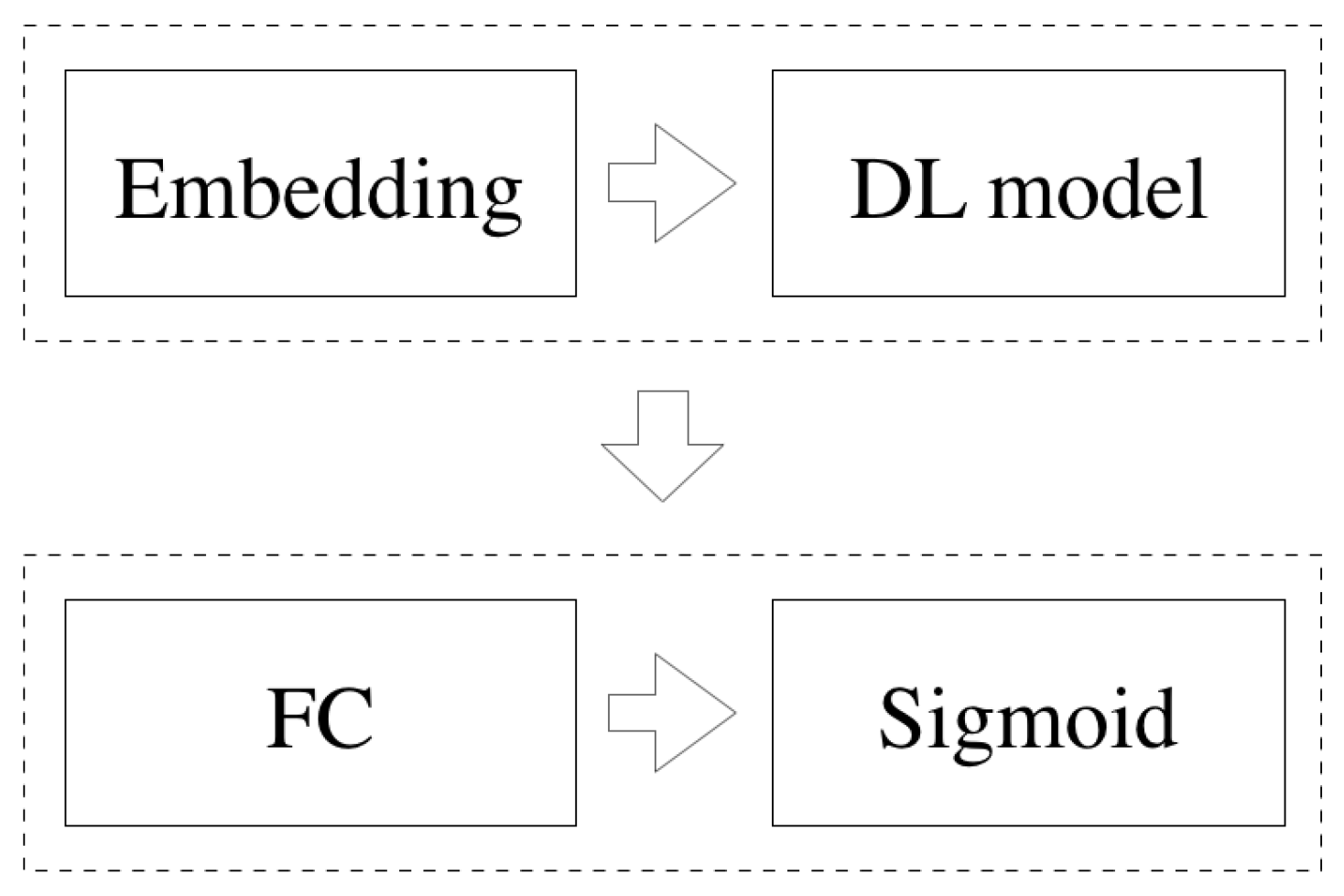
4. Comparative Study
4.1. Embeddings
4.1.1. Non-Contextualised Embeddings: Sparse Vector Representation-Based
4.1.2. Non-Contextualized Embeddings: Dense Vector Representation-Based
4.1.3. Contextualized Embeddings: Context-Aware Embeddings
4.2. ML Algorithms
4.2.1. Classical ML Models
- Logistic Regression (LR): LR is a statistical model applied as a great baseline algorithm in a wide range of text classification tasks.
- Support Vector Machine (SVM): The SVM classifier is a strong classifier that yields promising results in a suite of NLP tasks.
- Multinomial Naive Bayes (MNB): MNB is a kind of probabilistic algorithm (a Bayesian learning approach) that is also popular and yields great results in different NLP tasks.
- Decision Tree (DT): This is a tree-based algorithm whose end nodes represent high-level features. A branch represents an output, while a leaf represents a label class. There are internal nodes that test one attribute and branch from a node that selects one value for the attribute. The leaf node is used to predict the class label. Classification is carried out based on supervised learning, which involves mapping the features and values to desired outcomes.
- Random Forest (RF): RF models consist of a set of decision trees, each trained from a random selection of features.
- XGBoost (XGB): This is an ensemble ML algorithm. The XGB algorithm uses a gradient-boosting framework whose algorithm is based on decision trees. Through boosting, the trees are constructed sequentially, with each one (i.e., weak learners) aimed at reducing the errors of the previous one. With the help of these weak learners, the boosting technique is able to combine these weak learners to produce a strong learner.
- Ensemble: This is a hard voting ensemble learning method that combines the ML algorithms, including LR, SVM, DT, MNB, RF and XGB, which is built for better performance.
4.2.2. Advanced ML Models
- CNN: A one-dimensional convolutional neural network is a powerful ML approach for automatically extracting features from text inputs. A CNN can extract local features automatically but is less computationally expensive than other ML algorithms. Here, the architecture includes a single CNN layer with 128 filters with a kernel size of 5, which are activated with ReLU as an activation function. The generated feature map is then refined and reduced using the max-pooling layer, resulting in the most relevant information. After that, the output is flattened and passed to a dense output layer, with a single unit activated with a sigmoid as an activation function.
- LSTM: The LSTM model [111] improves on the RNN’s flaws by adding an additive and multiplicative interaction to the recurrence formula and a distinct memory state. A model’s complexity can also be increased by stacking LSTM layers. With three gates—an input gate, a forget gate and an output gate—LSTM models eliminate the gradient vanishing and explosion concerns brought by RNNs. An important characteristic of LSTM models is their ability to capture long-term dependency. The LSTM method has been proven to be effective when used for long sentences [112]. Mathematically, the LSTM components can be formulated as follows [113]:In the formulas above, represents the logistic sigmoid activation function. W, b and represent the weight matrix, the bias and the state of the memory unit at time t, respectively. Here, a single BiLSTM layer with 128 units is used to encode the input text.
- GRU: In a GRU variant, there are only two gates: an update gate and a reset gate. The update gate combines the forget and input gates and decides what information will be passed to the current state. The reset gates determine when to ignore the previously hidden state [114]. As with LSTM, the update and reset gates are computed as follows [114]:In the formulas above, denotes the logistic sigmoid function and W and U show the weight matrices of gates and b, respectively, referring to the hidden state and bias vectors. A basic RNN considers the context of the past but cannot consider the context of the future. Hence, to account for future and previous contexts, bidirectional LSTM (BiLSTM) and bidirectional GRU (BiGRU) are excellent choices thanks to their breakthrough designs. To accomplish this, the forward and backward hidden layers are combined, thereby controlling the temporal information flow in both directions and leading to better learning.Here, we used a single BiGRU layer with 128 neurons. Even though BiLSTM and BiGRU have shown their superiority in a suite of NLP problems, they are not free from two shortcomings: (1) as the high-dimensional input space increases, so does the complexity of these models, leading to further complexity in optimizing such models, and (2) as these models can capture succeeding and proceeding contextual information (bidirectionality concept), they are not able to focus on the most salient parts of the contextual information of the text. Therefore, to overcome the former issue, a CNN can be used to reduce the dimensionality of the feature space while retaining the informative features from the text. In addition, a CNN can capture and extract local patterns.
- CNN-BiLSTM: Hybridising recurrence-based models with a CNN helps extract salient features, capturing local contextualised patterns and improving the model’s accuracy. First, a single CNN layer of 128 filters with a kernel size of 5 is used to process the input vectors and extract the local features. The resultant feature maps of the CNN layer are then fed to a single BiLSTM layer with 128 units to learn the long-term dependencies of the local features of news articles. This is followed by an output layer with a single unit activated with a sigmoid function. The temporal and contextual features and long-term dependencies of the input text can be learned and captured from the text by using an RNN, and important local features can be detected by harnessing the power of the CNN in handling the spatial relations [115,116].
- CNN-BiGRU: Similar to the CNN-BiLSTM model, the architecture with a BiLSTM layer was replaced with a BiGRU layer.
- Hybrid: This is a hybrid model that combines three models: a single CNN layer with 128 neurons of a kernel size of 5, followed by a max-pooling and then a BiLSTM layer with 128 units and then a BiGRU layer with 128 units.
4.2.3. Transformer-Based Models
- BERT: Originally introduced by Devlin et al. [74], BERT stands for Bidirectional Encoder Representation from Transformers. As the first deeply bidirectional and unsupervised language representation, this model uses a multi-layer bidirectional transformer encoder that simultaneously conditions the left and right contexts. As a result, BERT generates embeddings that are context-aware. BERT further eliminates the unidirectional constraint by performing pretraining using an unsupervised prediction task that includes a masked language model (MLM) which understands context and predicts words. A vector representation can therefore be generated by the model that captures the general information of the input text. The semantic representation of each word in the input text can be improved using an attention mechanism by boosting semantic representation based on the context of the word. The attention mechanism plays an important role in transformer architecture in that it assigns varying weights to different parts of text according to their contributions to the output. An Attention function maps queries and follows key-value and output-vector pairs, which can be seen in Equation (14):where Q, K and V denote the query, key and value itself, respectively. denotes the dimension of the key vector k and query vector q. Attention uses a Softmax activation function that normalises the inputs to a value between 0 and 1. BERT uses a multi-head attention mechanism which can be seen in Equation (15), where each specific head and the associated weight matrices are denoted with the subscript i:where denotes a weight matrix that was trained jointly with the model and each is calculated as follows:Even though BERT contains millions of parameters (i.e., BERT contains 110 million parameters, while BERT has 340 million parameters) [74], in contrast to pretraining, BERT is relatively inexpensive to apply to downstream tasks using jointly fine-tuned parameters based on a pretrained model. In this work, we use BERT.
- RoBERTa [78]: An optimised version of the BERT approach was introduced by Facebook. In this method, BERT is retrained with an improved training methodology by (1) removing the Next Sentence Prediction task from pretraining; (2) using 10 times as much data as BERT to train RoBERTa and (3) introducing dynamic masking with larger batch sizes so that the masked tokens change during training, as opposed to the static masking pattern used in BERT. In this way, RoBERTa differs from BERT in the way it approaches pretraining. We experiment with RoBERTa in this paper.
4.3. Preprocessing
4.4. Experimental Set-Up
4.5. Evaluation Metrics
- Accuracy (A): Accuracy is a measure of the classifier’s ability to correctly classify a piece of information as either fake or real. The accuracy can be estimated using Equation (17):
- Precsion (P): Precision is a measure for the classifier’s exactness such that a low value indicates a large number of false positives. The precsion represents the number of positive predictions divided by the total number of positive class values predicted and is calculated using Equation (18):
- Recall (R): Recall is considered a measure of a classifier’s completeness (e.g., a low value of recall indicates many false negatives), where the number of true positives is divided by the number of true positives and the number of false negatives, as can be clearly seen in Equation (19):
- F1 score (F1): The F1 score is calculated as the weighted harmonic mean of the precision and recall measures of the classifier using Equation (20):where , , and are true positive, true negative, false positive and false negative, respectively.
4.6. Datasets
4.6.1. LIAR
4.6.2. FakeNewsNet
4.6.3. COVID-19
5. Analysis of Experimental Results
5.1. Analysis of Results on the LIAR Dataset
5.2. Analysis of Results on FakeNewsNet Dataset
5.3. Analysis of Results on COVID-19 Dataset
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a Social Network or a News Media? In Proceedings of the 19th International Conference on World Wide Web; Association for Computing Machinery: New York, NY, USA, 2010; pp. 591–600. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media: A Data Mining Perspective. arXiv 2017, arXiv:1708.01967. [Google Scholar] [CrossRef]
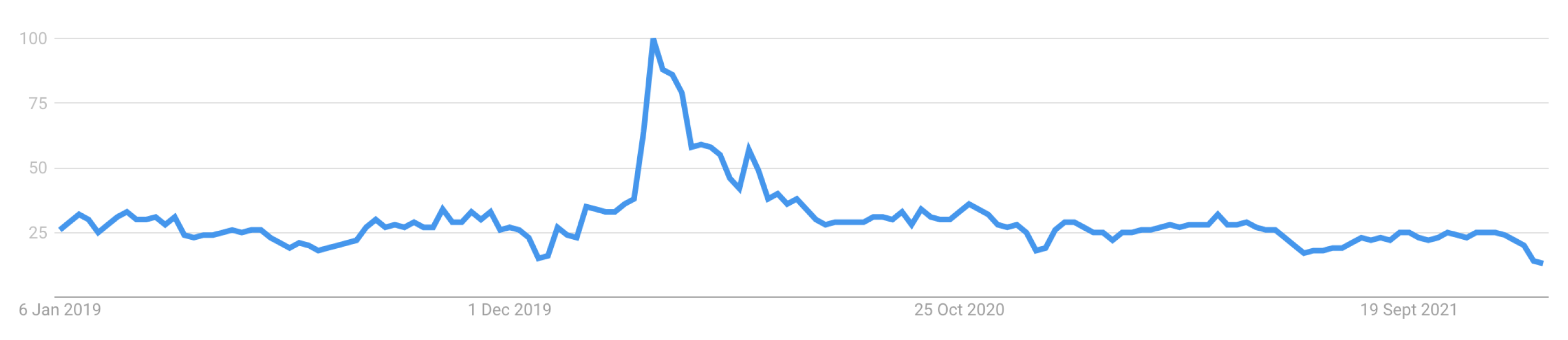
- Trends, G. “Fake News—Explore—Google Trends”. Available online: https://trends.google.com/trends/explore?date=2010-01-01%202022-07-14&q=%22fake%20news%22 (accessed on 20 July 2022).
- Langin, K. Fake news spreads faster than true news on Twitter—Thanks to people, not bots. Sci. Mag. 2018. Available online: https://www.science.org/content/article/fake-news-spreads-faster-true-news-twitter-thanks-people-not-bots (accessed on 20 February 2022).
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and Resolution of Rumours in Social Media: A Survey. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Zhao, Z.; Resnick, P.; Mei, Q. Enquiring Minds: Early Detection of Rumors in Social Media from Enquiry Posts. In Proceedings of the 24th International Conference on World Wide Web; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2015; pp. 1395–1405. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Kumar, S.; West, R.; Leskovec, J. Disinformation on the web: Impact, characteristics, and detection of wikipedia hoaxes. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 591–602. [Google Scholar]
- Friggeri, A.; Adamic, L.; Eckles, D.; Cheng, J. Rumor cascades. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8. [Google Scholar]
- Zhou, X.; Zafarani, R. A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53, 1–40. [Google Scholar] [CrossRef]
- Conroy, N.K.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. Proc. Assoc. Inf. Sci. Technol. 2015, 52, 1–4. [Google Scholar] [CrossRef]
- Zhou, X.; Jain, A.; Phoha, V.V.; Zafarani, R. Fake News Early Detection: An Interdisciplinary Study. arXiv 2019, arXiv:1904.11679. [Google Scholar]
- Feng, S.; Banerjee, R.; Choi, Y. Syntactic Stylometry for Deception Detection. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Jeju Island, Republic of Korea, 2012; pp. 171–175. [Google Scholar]
- Karimi, H.; Tang, J. Learning hierarchical discourse-level structure for fake news detection. arXiv 2019, arXiv:1903.07389. [Google Scholar]
- Pisarevskaya, D. Deception detection in news reports in the russian language: Lexics and discourse. In Proceedings of the 2017 EMNLP Workshop: Natural Language Processing Meets Journalism, Copenhagen, Denmark, 7 September 2017; pp. 74–79. [Google Scholar]
- Pérez-Rosas, V.; Kleinberg, B.; Lefevre, A.; Mihalcea, R. Automatic detection of fake news. arXiv 2017, arXiv:1708.07104. [Google Scholar]
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading Online Content: Recognizing Clickbait as “False News”. In Proceedings of the 2015 ACM on Workshop on Multimodal Deception Detection; Association for Computing Machinery: New York, NY, USA, 2015; pp. 15–19. [Google Scholar] [CrossRef]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. arXiv 2017, arXiv:1702.05638. [Google Scholar]
- Fuller, C.M.; Biros, D.P.; Wilson, R.L. Decision support for determining veracity via linguistic-based cues. Decis. Support Syst. 2009, 46, 695–703. [Google Scholar] [CrossRef]
- Zhou, L.; Burgoon, J.K.; Nunamaker, J.F.; Twitchell, D. Automating linguistics-based cues for detecting deception in text-based asynchronous computer-mediated communications. Group Decis. Negot. 2004, 13, 81–106. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic inquiry and word count: LIWC 2001. Mahway Lawrence Erlbaum Assoc. 2001, 71, 2001. [Google Scholar]
- Riedel, B.; Augenstein, I.; Spithourakis, G.P.; Riedel, S. A simple but tough-to-beat baseline for the Fake News Challenge stance detection task. arXiv 2018, arXiv:cs.CL/1707.03264. [Google Scholar]
- Ahmed, H.; Traore, I.; Saad, S. Detection of online fake news using n-gram analysis and machine learning techniques. In Proceedings of the International Conference on Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments; Springer: Berlin/Heidelberg, Germany, 2017; pp. 127–138. [Google Scholar]
- Bharadwaj, P.; Shao, Z. Fake news detection with semantic features and text mining. Int. J. Nat. Lang. Comput. (IJNLC) 2019, 8, 17–22. [Google Scholar] [CrossRef]
- Wynne, H.E.; Wint, Z.Z. Content based fake news detection using n-gram models. In Proceedings of the 21st International Conference on Information Integration and Web-Based Applications & Services, Munich, Germany, 2–4 December 2019; pp. 669–673. [Google Scholar]
- Gravanis, G.; Vakali, A.; Diamantaras, K.; Karadais, P. Behind the cues: A benchmarking study for fake news detection. Expert Syst. Appl. 2019, 128, 201–213. [Google Scholar] [CrossRef]
- Burgoon, J.K.; Blair, J.P.; Qin, T.; Nunamaker, J.F. Detecting deception through linguistic analysis. In Proceedings of the International Conference on Intelligence and Security Informatics; Springer: Berlin/Heidelberg, Germany, 2003; pp. 91–101. [Google Scholar]
- Hancock, J.T.; Curry, L.E.; Goorha, S.; Woodworth, M. On lying and being lied to: A linguistic analysis of deception in computer-mediated communication. Discourse Process. 2007, 45, 1–23. [Google Scholar] [CrossRef]
- Newman, M.L.; Pennebaker, J.W.; Berry, D.S.; Richards, J.M. Lying Words: Predicting Deception from Linguistic Styles. Personal. Soc. Psychol. Bull. 2003, 29, 665–675. [Google Scholar] [CrossRef]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Vrij, A. Detecting Lies and Deceit: The Psychology of Lying and Implications for Professional Practice; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Knapp, M.L.; Hart, R.P.; Dennis, H.S. An exploration of deception as a communication construct. Hum. Commun. Res. 1974, 1, 15–29. [Google Scholar] [CrossRef]
- Horne, B.; Adali, S. This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 759–766. [Google Scholar]
- Papadopoulou, O.; Zampoglou, M.; Papadopoulos, S.; Kompatsiaris, I. A two-level classification approach for detecting clickbait posts using text-based features. arXiv 2017, arXiv:1710.08528. [Google Scholar]
- Rubin, V.L.; Conroy, N.; Chen, Y.; Cornwell, S. Fake news or truth? using satirical cues to detect potentially misleading news. In Proceedings of the Second Workshop on Computational Approaches to Deception Detection, San Diego, CA, USA, 17 June 2016; pp. 7–17. [Google Scholar]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef]
- Qazvinian, V.; Rosengren, E.; Radev, D.R.; Mei, Q. Rumor has it: Identifying Misinformation in Microblogs. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Edinburgh, UK, 2011; pp. 1589–1599. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web; Association for Computing Machinery: New York, NY, USA, 2011; pp. 675–684. [Google Scholar] [CrossRef]
- Hamidian, S.; Diab, M.T. Rumor Detection and Classification for Twitter Data. arXiv 2019, arXiv:1912.08926. [Google Scholar]
- Yang, F.; Liu, Y.; Yu, X.; Yang, M. Automatic Detection of Rumor on Sina Weibo. In Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Ajao, O.; Bhowmik, D.; Zargari, S. Sentiment Aware Fake News Detection on Online Social Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2507–2511. [Google Scholar]
- Ratkiewicz, J.; Conover, M.; Meiss, M.; Gonçalves, B.; Flammini, A.; Menczer, F. Detecting and tracking political abuse in social media. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Samonte, M.J.C. Polarity analysis of editorial articles towards fake news detection. In Proceedings of the 2018 International Conference on Internet and e-Business, Singapore, 25–27 April 2018; pp. 108–112. [Google Scholar]
- Volkova, S.; Shaffer, K.; Jang, J.Y.; Hodas, N. Separating facts from fiction: Linguistic models to classify suspicious and trusted news posts on twitter. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 647–653. [Google Scholar]
- Bhelande, M.; Sanadhya, A.; Purao, M.; Waldia, A.; Yadav, V. Identifying controversial news using sentiment analysis. Imp. J. Interdiscip. Res. 2017, 3. Available online: https://www.semanticscholar.org/paper/Identifying-Controversial-News-using-Sentiment-Bhelande-Sanadhya/23862325ff7b53e7851cd4398553d82cbca483f4 (accessed on 22 May 2022).
- Qin, Y.; Wurzer, D.; Lavrenko, V.; Tang, C. Spotting Rumors via Novelty Detection. arXiv 2016, arXiv:1611.06322. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K. Rumor Detection over Varying Time Windows. PLoS ONE 2017, 12, e0168344. [Google Scholar] [CrossRef]
- Wei, W.; Wan, X. Learning to identify ambiguous and misleading news headlines. arXiv 2017, arXiv:1705.06031. [Google Scholar]
- Chakraborty, A.; Paranjape, B.; Kakarla, S.; Ganguly, N. Stop Clickbait: Detecting and Preventing Clickbaits in Online News Media. arXiv 2016, arXiv:1610.09786. [Google Scholar]
- Feng, V.W.; Hirst, G. Detecting Deceptive Opinions with Profile Compatibility. In Proceedings of the Sixth International Joint Conference on Natural Language Processing; Asian Federation of Natural Language Processing: Nagoya, Japan, 2013; pp. 338–346. [Google Scholar]
- Potthast, M.; Köpsel, S.; Stein, B.; Hagen, M. Clickbait Detection. In Proceedings of the ECIR, Padua, Italy, 20–23 March 2016. [Google Scholar]
- Gupta, A.; Kumaraguru, P.; Castillo, C.; Meier, P. Tweetcred: Real-time credibility assessment of content on twitter. In Proceedings of the International Conference on Social Informatics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 228–243. [Google Scholar]
- Bhattacharjee, S.D.; Talukder, A.; Balantrapu, B.V. Active learning based news veracity detection with feature weighting and deep-shallow fusion. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 556–565. [Google Scholar]
- Ribeiro, M.H.; Calais, P.H.; Almeida, V.A.; Meira, W., Jr. “Everything I Disagree With is# FakeNews”: Correlating Political Polarization and Spread of Misinformation. arXiv 2017, arXiv:1706.05924. [Google Scholar]
- Popat, K. Assessing the Credibility of Claims on the Web. In Proceedings of the 26th International Conference on World Wide Web Companion; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 735–739. [Google Scholar] [CrossRef]
- Cardoso Durier da Silva, F.; Vieira, R.; Garcia, A.C. Can machines learn to detect fake news? A survey focused on social media. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Maui, HI, USA, 8–11 January 2019. [Google Scholar]
- Markowitz, D.M.; Hancock, J.T. Linguistic Traces of a Scientific Fraud: The Case of Diederik Stapel. PLoS ONE 2014, 9, e105937. [Google Scholar] [CrossRef] [PubMed]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A Hybrid Deep Model for Fake News Detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management; Association for Computing Machinery: New York, NY, USA, 2017; pp. 797–806. [Google Scholar]
- Lahby, M.; Aqil, S.; Yafooz, W.M.S.; Abakarim, Y. Online Fake News Detection Using Machine Learning Techniques: A Systematic Mapping Study. In Combating Fake News with Computational Intelligence Techniques; Lahby, M., Pathan, A.S.K., Maleh, Y., Yafooz, W.M.S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 3–37. [Google Scholar] [CrossRef]
- Klyuev, V. Fake news filtering: Semantic approaches. In Proceedings of the 2018 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 29–31 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 9–15. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Zubiaga, A.; Liakata, M.; Procter, R. Exploiting context for rumour detection in social media. In Proceedings of the International Conference on Social Informatics; Springer: Berlin/Heidelberg, Germany, 2017; pp. 109–123. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Wang, W.Y. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. arXiv 2017, arXiv:1705.00648. [Google Scholar]
- Qian, F.; Gong, C.; Sharma, K.; Liu, Y. Neural User Response Generator: Fake News Detection with Collective User Intelligence. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 18, pp. 3834–3840. [Google Scholar]
- Goldani, M.H.; Momtazi, S.; Safabakhsh, R. Detecting fake news with capsule neural networks. Appl. Soft Comput. 2021, 101, 106991. [Google Scholar] [CrossRef]
- Girgis, S.; Amer, E.; Gadallah, M. Deep learning algorithms for detecting fake news in online text. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 93–97. [Google Scholar]
- Sarnovskỳ, M.; Maslej-Krešňáková, V.; Ivancová, K. Fake News Detection Related to the COVID-19 in Slovak Language Using Deep Learning Methods. Acta Polytech. Hung. 2022, 19, 43–57. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 10 August 2022).
- Müller, M.; Salathé, M.; Kummervold, P.E. Covid-twitter-bert: A natural language processing model to analyse COVID-19 content on twitter. arXiv 2020, arXiv:2005.07503. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Kula, S.; Choraś, M.; Kozik, R. Application of the bert-based architecture in fake news detection. In Proceedings of the Computational Intelligence in Security for Information Systems Conference; Springer: Berlin/Heidelberg, Germany, 2019; pp. 239–249. [Google Scholar]
- Alghamdi, J.; Lin, Y.; Luo, S. Modeling Fake News Detection Using BERT-CNN-BiLSTM Architecture. In Proceedings of the 2022 IEEE 5th International Conference on Multimedia Information Processing and Retrieval (MIPR), Online, 2–4 August 2022; pp. 354–357. [Google Scholar] [CrossRef]
- Aggarwal, A.; Chauhan, A.; Kumar, D.; Mittal, M.; Verma, S. Classification of fake news by fine-tuning deep bidirectional transformers based language model. EAI Endorsed Trans. Scalable Inf. Syst. 2020, 7, e10. [Google Scholar] [CrossRef]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.M.; Lim, H. exBAKE: Automatic fake news detection model based on bidirectional encoder representations from transformers (bert). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Baruah, A.; Das, K.A.; Barbhuiya, F.A.; Dey, K. Automatic Detection of Fake News Spreaders Using BERT. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Khan, J.Y.; Khondaker, M.T.I.; Afroz, S.; Uddin, G.; Iqbal, A. A benchmark study of machine learning models for online fake news detection. Mach. Learn. Appl. 2021, 4, 100032. [Google Scholar] [CrossRef]
- Elhadad, M.K.; Li, K.F.; Gebali, F. A Novel Approach for Selecting Hybrid Features from Online News Textual Metadata for Fake News Detection. In Proceedings of the Advances on P2P, Parallel, Grid, Cloud and Internet Computing; Barolli, L., Hellinckx, P., Natwichai, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 914–925. [Google Scholar]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. FakeNewsNet: A Data Repository with News Content, Social Context and Spatialtemporal Information for Studying Fake News on Social Media. arXiv 2018, arXiv:1809.01286. [Google Scholar] [CrossRef]
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. DEFEND: Explainable Fake News Detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; Association for Computing Machinery: New York, NY, USA, 2019; pp. 395–405. [Google Scholar] [CrossRef]
- Koloski, B.; Perdih, T.S.; Robnik-Šikonja, M.; Pollak, S.; Škrlj, B. Knowledge graph informed fake news classification via heterogeneous representation ensembles. Neurocomputing 2022, 496, 208–226. [Google Scholar] [CrossRef]
- Oriola, O. Exploring N-gram, word embedding and topic models for content-based fake news detection in FakeNewsNet evaluation. Int. J. Comput. Appl. 2021, 975, 8887. [Google Scholar] [CrossRef]
- Sadeghi, F.; Jalaly Bidgoly, A.; Amirkhani, H. Fake News Detection on Social Media Using A Natural Language Inference Approach. Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Gautam, A.; Venktesh, V.; Masud, S. Fake News Detection System using XLNet model with Topic Distributions: CONSTRAINT@AAAI2021 Shared Task. arXiv 2021, arXiv:2101.11425. [Google Scholar] [CrossRef]
- Shifath, S.M.S.U.R.; Khan, M.F.; Islam, M.S. A transformer based approach for fighting COVID-19 fake news. arXiv 2021, arXiv:2101.12027. [Google Scholar] [CrossRef]
- Veyseh, A.P.B.; Thai, M.T.; Nguyen, T.H.; Dou, D. Rumor detection in social networks via deep contextual modeling. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 113–120. [Google Scholar]
- Wani, A.; Joshi, I.; Khandve, S.; Wagh, V.; Joshi, R. Evaluating Deep Learning Approaches for COVID-19 Fake News Detection. In Combating Online Hostile Posts in Regional Languages during Emergency Situation; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 153–163. [Google Scholar] [CrossRef]
- Shushkevich, E.; Cardiff, J. TUDublin team at Constraint@ AAAI2021–COVID19 Fake News Detection. arXiv 2021, arXiv:2101.05701. [Google Scholar]
- Felber, T. Constraint 2021: Machine learning models for COVID-19 fake news detection shared task. arXiv 2021, arXiv:2101.03717. [Google Scholar]
- Patwa, P.; Sharma, S.; Pykl, S.; Guptha, V.; Kumari, G.; Akhtar, M.S.; Ekbal, A.; Das, A.; Chakraborty, T. Fighting an infodemic: COVID-19 fake news dataset. In Proceedings of the International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 21–29. [Google Scholar]
- Goldberg, Y. Neural network methods for natural language processing. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–309. [Google Scholar]
- Wallach, H.M. Topic modeling: Beyond bag-of-words. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 977–984. [Google Scholar]
- Damashek, M. Gauging similarity with n-grams: Language-independent categorization of text. Science 1995, 267, 843–848. [Google Scholar] [CrossRef] [PubMed]
- Joachims, T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. Technical Report, Carnegie-Mellon univ Pittsburgh pa Dept of Computer Science. 1996. Available online: https://www.cs.cornell.edu/people/tj/publications/joachims_97a.pdf (accessed on 11 January 2022).
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization; Citeseer: State College, PA, USA, 1998; Volume 752, pp. 41–48. [Google Scholar]
- Trstenjak, B.; Mikac, S.; Donko, D. KNN with TF-IDF based framework for text categorization. Procedia Eng. 2014, 69, 1356–1364. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Salton, G. MCGILL, Michael. In Introduction to Modern Information Retrieval; McGraw-Hill, Inc.: New York, NY, USA, 1986. [Google Scholar]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Mikolov, T.; Yih, W.t.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Graves, A. Supervised sequence labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 5–13. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhang, X.; Chen, F.; Huang, R. A combination of RNN and CNN for attention-based relation classification. Procedia Comput. Sci. 2018, 131, 911–917. [Google Scholar] [CrossRef]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM neural network for text classification. arXiv 2015, arXiv:1511.08630. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Patwa, P.; Bhardwaj, M.; Guptha, V.; Kumari, G.; Sharma, S.; Pykl, S.; Das, A.; Ekbal, A.; Akhtar, M.S.; Chakraborty, T. Overview of constraint 2021 shared tasks: Detecting english COVID-19 fake news and hindi hostile posts. In Proceedings of the International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 42–53. [Google Scholar]
- Horne, L.; Matti, M.; Pourjafar, P.; Wang, Z. GRUBERT: A GRU-Based Method to Fuse BERT Hidden Layers for Twitter Sentiment Analysis. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: Student Research Workshop; Association for Computational Linguistics: Suzhou, China, 2020; pp. 130–138. [Google Scholar]



{kind=link}
{kind=link}
| Models | Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | |
| RoBERTa [85] | 0.62 | 0.63 | 0.62 | 0.62 |
| SVM [86] | 0.62 | NA | NA | NA |
| Models | Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | |
| Social Article Fusion [87] | 0.69 | 0.64 | 0.79 | 0.71 |
| Logistic Regression (N-Gram) [90] | 0.80 | 0.79 | 0.78 | 0.78 |
| BiLSTM-BERT [91] | 0.8558 | NA | NA | NA |
| LNN-KG [89] | 0.880 | 0.9011 | 0.880 | 0.8892 |
| DEFEND [88] | 0.904 | 0.902 | 0.956 | 0.928 |
| Models | Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | |
| CNN [87] | 0.723 | 0.751 | 0.701 | 0.725 |
| Logistic Regression (N-Gram) [90] | 0.82 | 0.75 | 0.79 | 0.77 |
| DEFEND [88] | 0.808 | 0.729 | 0.782 | 0.755 |
| Models | Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | |
| SVM+LR+NB+biLSTM [96] | NA | NA | NA | 0.94 |
| SVM [97] | 0.9570 | 0.9571 | 0.9570 | 0.9570 |
| SNN(LM+KG) [89] | 0.9570 | 0.9533 | 0.9652 | 0.9569 |
| BERT-Based [95] | 0.9841 | NA | NA | NA |
| Ensemble Transformer Models [93] | 0.9799 | 0.9799 | 0.9799 | 0.9799 |
| XLNet with Topic Distributions [92] | NA | 0.968 | 0.967 | 0.967 |
| SVM [98] | 0.9332 | 0.9333 | 0.9332 | 0.9332 |
| Model | Hyperparameters | ||||
|---|---|---|---|---|---|
| Hidden Layer(s) | Activation Function | Neurons or Filters | Kernel Size | Dropout | |
| CNN | 1 | ReLU | 128 | 5 | 0.3 |
| BiLSTM | 1 | N/A | 128 | N/A | 0.3 |
| BiGRU | 1 | N/A | 128 | N/A | 0.3 |
| # Candidate News | 12,791 |
|---|---|
| # True news | 7134 |
| # Fake news | 5657 |
| Dataset | PolitiFact | GossipCop |
|---|---|---|
| # Candidate news | 694 | 18,676 |
| # True news | 356 | 14,129 |
| # Fake news | 338 | 4547 |
| # Candidate News | 6420 |
|---|---|
| # True news | 3360 |
| # Fake news | 3060 |
| Dataset | |||||
|---|---|---|---|---|---|
| LIAR | |||||
| Model | Feature | A (%) | P (%) | R (%) | F1 (%) |
| LR | CV | 0.6196 | 0.6530 | 0.6933 | 0.6726 |
| SVM | CV | 0.6346 | 0.6441 | 0.7857 | 0.7079 |
| MNB | CV | 0.6243 | 0.6530 | 0.7115 | 0.6810 |
| DT | CV | 0.5730. | 0.6137 | 0.6541 | 0.6332 |
| RF | CV | 0.6275 | 0.6360 | 0.7927 | 0.7057 |
| XGB | CV | 0.6093 | 0.6085 | 0.8599 | 0.7127 |
| Ensemble | CV | 0.6306 | 0.6504 | 0.7451 | 0.6945 |
| LR | TFIDF | 0.6354 | 0.6493 | 0.7675 | 0.8655 |
| SVM | TFIDF | 0.6101 | 0.6421 | 0.6961 | 0.6680 |
| MNB | TFIDF | 0.6093 | 0.6311 | 0.7381 | 0.6804 |
| DT | TFIDF | 0.5414 | 0.5917 | 0.6008 | 0.5962 |
| RF | TFIDF | 0.5659 | 0.5658 | 0.9874 | 0.7194 |
| XGB | TFIDF | 0.6093 | 0.6121 | 0.8375 | 0.7073 |
| Ensemble | TFIDF | 0.6393 | 0.6503 | 0.7787 | 0.7087 |
| LR | Word2Vec | 0.6361 | 0.6462 | 0.7829 | 0.7080 |
| SVM | Word2Vec | 0.6314 | 0.6438 | 0.7745 | 0.7031 |
| MNB | Word2Vec | 0.5762 | 0.5778 | 0.9202 | 0.7099 |
| DT | Word2Vec | 0.5493 | 0.6032 | 0.5854 | 0.5942 |
| RF | Word2Vec | 0.5675 | 0.5707 | 0.9384 | 0.7097 |
| XGB | Word2Vec | 0.6156 | 0.6300 | 0.7703 | 0.6931 |
| Ensemble | Word2Vec | 0.6267 | 0.6355 | 0.7913 | 0.7049 |
| LR | GloVe | 0.6172 | 0.6265 | 0.7941 | 0.7004 |
| SVM | GloVe | 0.6212 | 0.6306 | 0.7913 | 0.7019 |
| MN | GloVe | 0.5635 | 0.5635 | 0.5635 | 0.7208 |
| DT | GloVe | 0.5178 | 0.5724 | 0.5700 | 0.5712 |
| RF | GloVe | 0.6006 | 0.6042 | 0.8445 | 0.7044 |
| XGB | GloVe | 0.5943 | 0.6109 | 0.7717 | 0.6819 |
| Ensemble | GloVe | 0.5983 | 0.6099 | 0.7969 | 0.6910 |
| Dataset | |||||
|---|---|---|---|---|---|
| LIAR | |||||
| Model | Feature | A (%) | P (%) | R (%) | F1 (%) |
| CNN | Word2Vec | 0.5825 | 0.6219 | 0.6611 | 0.6409 |
| BiLSTM | Word2Vec | 0.5533 | 0.6028 | 0.6078 | 0.6053 |
| BiGRU | Word2Vec | 0.5572 | 0.6073 | 0.6064 | 0.6069 |
| CNN-LSTM | Word2Vec | 0.5635 | 0.5635 | 1.0000 | 0.7208 |
| CNN-GRU | Word2Vec | 0.5627 | 0.5632 | 0.9986 | 0.7202 |
| CNN-BiLSTM | Word2Vec | 0.5762 | 0.6281 | 0.6078 | 0.6178 |
| CNN-BiGRU | Word2Vec | 0.5714 | 0.6067 | 0.6807 | 0.6416 |
| Hybrid | Word2Vec | 0.5785 | 0.6175 | 0.6625 | 0.6392 |
| CNN | GloVe | 0.6172 | 0.6388 | 0.7381 | 0.6849 |
| BiLSTM | GloVe | 0.5888 | 0.6442 | 0.6036 | 0.6233 |
| BiGRU | GloVe | 0.5927 | 0.6371 | 0.6443 | 0.6407 |
| CNN-LSTM | GloVe | 0.5635 | 0.5635 | 1.0000 | 0.7208 |
| CNN-GRU | GloVe | 0.5635 | 0.5635 | 1.0000 | 0.7208 |
| CNN-BiLSTM | GloVe | 0.5912 | 0.6365 | 0.6401 | 0.6383 |
| CNN-BiGRU | GloVe | 0.6014 | 0.6240 | 0.7367 | 0.6757 |
| Hybrid | GloVe | 0.5809 | 0.6332 | 0.6092 | 0.6210 |
| CNN | BERT | 0.5975 | 0.6555 | 0.6022 | 0.6277 |
| BiLSTM | BERT | 0.6204 | 0.6392 | 0.7493 | 0.6899 |
| BiGRU | BERT | 0.6180 | 0.6386 | 0.7423 | 0.6865 |
| CNN-LSTM | BERT | 0.6306 | 0.6602 | 0.7101 | 0.6842 |
| CNN-GRU | BERT | 0.6077 | 0.6543 | 0.6443 | 0.6493 |
| CNN-BiLSTM | BERT | 0.5793 | 0.6100 | 0.7031 | 0.6532 |
| CNN-BiGRU | BERT | 0.6140 | 0.6313 | 0.7577 | 0.6887 |
| Hybrid | BERT | 0.5912 | 0.6195 | 0.7115 | 0.6623 |
| BERT | BERT | 0.6306 | 0.6662 | 0.6905 | 0.6781 |
| RoBERTa | RoBERTa | 0.6117 | 0.6468 | 0.6849 | 0.6653 |
| Datasets | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| PolitiFact | GossipCop | ||||||||
| Model | Feature | A (%) | P (%) | R (%) | F1 (%) | A (%) | P (%) | R (%) | F1 (%) |
| LR | CV | 0.8311 | 0.7374 | 0.9771 | 0.8405 | 0.8375 | 0.8644 | 0.9333 | 0.8976 |
| SVM | CV | 0.8330 | 0.7248 | 0.9978 | 0.8397 | 0.8183 | 0.8136 | 0.9881 | 0.8924 |
| MNB | CV | 0.7220 | 0.5393 | 1.0000 | 0.7007 | 0.8335 | 0.8417 | 0.9628 | 0.8982 |
| DT | CV | 0.7419 | 0.8050 | 0.7758 | 0.7901 | 0.7875 | 0.8607 | 0.8607 | 0.8607 |
| RF | CV | 0.8131 | 0.6918 | 0.9977 | 0.8171 | 0.8536 | 0.8505 | 0.9803 | 0.9108 |
| XGB | CV | 0.8548 | 0.7720 | 0.9840 | 0.8652 | 0.8429 | 0.8442 | 0.9737 | 0.9043 |
| Ensemble | CV | 0.8993 | 1.0000 | 0.8250 | 0.9041 | 0.8528 | 0.8521 | 0.9765 | 0.9100 |
| LR | TFIDF | 0.8567 | 0.9979 | 0.7642 | 0.8655 | 0.8587 | 0.8605 | 0.9723 | 0.9130 |
| SVM | TFIDF | 0.8416 | 0.9855 | 0.7484 | 0.8508 | 0.8635 | 0.8667 | 0.9702 | 0.9155 |
| MNB | TFIDF | 0.7524 | 0.9973 | 0.5912 | 0.7423 | 0.8212 | 0.8574 | 0.9182 | 0.8868 |
| DT | TFIDF | 0.6841 | 0.8272 | 0.6022 | 0.6970 | 0.7861 | 0.8612 | 0.8578 | 0.8595 |
| RF | TFIDF | 0.7960 | 1.000 | 0.6619 | 0.7966 | 0.8496 | 0.8435 | 0.9856 | 0.9090 |
| XGB | TFIDF | 0.8748 | 0.9846 | 0.8050 | 0.8858 | 0.8410 | 0.8445 | 0.9702 | 0.9030 |
| Ensemble | TFIDF | 0.8777 | 0.9565 | 0.8250 | 0.8859 | 0.8611 | 0.8650 | 0.9691 | 0.9141 |
| LR | Word2Vec | 0.7884 | 0.6525 | 0.9952 | 0.7882 | 0.8383 | 0.8421 | 0.9698 | 0.9015 |
| SVM | Word2Vec | 0.7922 | 0.6651 | 0.9860 | 0.7944 | 0.8367 | 0.8325 | 0.9839 | 0.9019 |
| MNB | Word2Vec | 0.6575 | 0.9791 | 0.4418 | 0.6089 | 0.7626 | 0.7626 | 1.0000 | 0.8653 |
| DT | Word2Vec | 0.6907 | 0.5393 | 0.9122 | 0.6779 | 0.7578 | 0.8529 | 0.8245 | 0.8385 |
| RF | Word2Vec | 0.6907 | 0.4984 | 0.9784 | 0.6604 | 0.8394 | 0.8388 | 0.9772 | 0.9027 |
| XGB | Word2Vec | 0.6983 | 0.5047 | 0.9907 | 0.6688 | 0.8332 | 0.8406 | 0.9642 | 0.8982 |
| Ensemble | Word2Vec | 0.8849 | 0.9324 | 0.8625 | 0.8961 | 0.8410 | 0.8395 | 0.9786 | 0.9037 |
| LR | GloVe | 0.6992 | 0.9819 | 0.5110 | 0.6722 | 0.7628 | 0.7632 | 0.9989 | 0.8653 |
| SVM | GloVe | 0.7239 | 0.9859 | 0.5503 | 0.7064 | 0.7626 | 0.7626 | 1.0000 | 0.8653 |
| MN | GloVe | 0.6575 | 0.9758 | 0.4434 | 0.6097 | 0.7626 | 0.7626 | 1.0000 | 0.8653 |
| DT | GloVe | 0.6262 | 0.8151 | 0.4921 | 0.6137 | 0.7230 | 0.8265 | 0.8059 | 0.8161 |
| RF | GloVe | 0.6546 | 0.9789 | 0.4371 | 0.6043 | 0.8236 | 0.8228 | 0.9796 | 0.8944 |
| XGB | GloVe | 0.7106 | 0.9853 | 0.5283 | 0.6878 | 0.8062 | 0.8137 | 0.9674 | 0.8839 |
| Ensemble | GloVe | 0.7986 | 0.9194 | 0.7125 | 0.8028 | 0.7944 | 0.7912 | 0.9923 | 0.8804 |
| Datasets | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| PolitiFact | GossipCop | ||||||||
| Model | Feature | A (%) | P (%) | R (%) | F1 (%) | A (%) | P (%) | R (%) | F1 (%) |
| CNN | Word2Vec | 0.6475 | 0.9189 | 0.4250 | 0.5812 | 0.8415 | 0.8566 | 0.9516 | 0.9016 |
| BiLSTM | Word2Vec | 0.7770 | 0.9153 | 0.6750 | 0.7770 | 0.8239 | 0.8702 | 0.9038 | 0.8867 |
| BiGRU | Word2Vec | 0.7554 | 0.8194 | 0.7375 | 0.7763 | 0.8263 | 0.8616 | 0.9200 | 0.8898 |
| CNN-LSTM | Word2Vec | 0.7266 | 0.7059 | 0.9000 | 0.7912 | 0.8303 | 0.8700 | 0.9140 | 0.8915 |
| CNN-GRU | Word2Vec | 0.6691 | 0.6848 | 0.7875 | 0.7326 | 0.8266 | 0.8694 | 0.9091 | 0.8888 |
| CNN-BiLSTM | Word2Vec | 0.7050 | 0.7532 | 0.7250 | 0.7389 | 0.8260 | 0.8683 | 0.9098 | 0.8886 |
| CNN-BiGRU | Word2Vec | 0.7338 | 0.7417 | 0.8250 | 0.7811 | 0.8097 | 0.8791 | 0.8701 | 0.8746 |
| Hybrid | Word2Vec | 0.7050 | 0.8197 | 0.6250 | 0.7092 | 0.8298 | 0.8639 | 0.9221 | 0.8920 |
| CNN | GloVe | 0.8561 | 0.8750 | 0.8750 | 0.8750 | 0.8097 | 0.8968 | 0.8480 | 0.8717 |
| BiLSTM | GloVe | 0.8129 | 0.8971 | 0.7625 | 0.8243 | 0.8284 | 0.8548 | 0.9337 | 0.8925 |
| BiGRU | GloVe | 0.8201 | 0.8571 | 0.8250 | 0.8408 | 0.8271 | 0.8580 | 0.9266 | 0.8910 |
| CNN-LSTM | GloVe | 0.7554 | 0.8382 | 0.7125 | 0.7703 | 0.8185 | 0.8709 | 0.8947 | 0.8826 |
| CNN-GRU | GloVe | 0.7194 | 0.7356 | 0.8000 | 0.7665 | 0.8137 | 0.8688 | 0.8901 | 0.8793 |
| CNN-BiLSTM | GloVe | 0.7986 | 0.8611 | 0.7750 | 0.8158 | 0.8290 | 0.8590 | 0.9280 | 0.8922 |
| CNN-BiGRU | GloVe | 0.8129 | 0.8375 | 0.8375 | 0.8375 | 0.8180 | 0.8675 | 0.8986 | 0.8828 |
| Hybrid | GloVe | 0.8085 | 0.8354 | 0.8250 | 0.8302 | 0.8349 | 0.8598 | 0.9361 | 0.8963 |
| CNN | BERT | 0.8993 | 0.9342 | 0.8875 | 0.9103 | 0.8616 | 0.8684 | 0.9702 | 0.9145 |
| BiLSTM | BERT | 0.9065 | 0.9589 | 0.8750 | 0.9150 | 0.8391 | 0.8769 | 0.9179 | 0.8969 |
| BiGRU | BERT | 0.9065 | 0.9136 | 0.9250 | 0.9193 | 0.8533 | 0.8754 | 0.9417 | 0.9073 |
| CNN-LSTM | BERT | 0.8561 | 0.8750 | 0.8750 | 0.8750 | 0.8418 | 0.8729 | 0.9277 | 0.8994 |
| CNN-GRU | BERT | 0.8417 | 0.8537 | 0.8750 | 0.8642 | 0.8514 | 0.8784 | 0.9396 | 0.9061 |
| CNN-BiLSTM | BERT | 0.8993 | 0.9125 | 0.9125 | 0.9125 | 0.8370 | 0.8756 | 0.9165 | 0.8956 |
| CNN-BiGRU | BERT | 0.8777 | 0.9437 | 0.8375 | 0.8874 | 0.8322 | 0.8915 | 0.8880 | 0.8897 |
| Hybrid | BERT | 0.9209 | 0.9600 | 0.9000 | 0.9290 | 0.8437 | 0.8719 | 0.9319 | 0.9009 |
| BERT | BERT | 0.9137 | 0.9359 | 0.9125 | 0.9241 | 0.8544 | 0.8724 | 0.9477 | 0.9085 |
| RoBERTa | RoBERTa | 0.9209 | 0.9259 | 0.9375 | 0.9317 | 0.8383 | 0.8794 | 0.9133 | 0.8960 |
| Dataset | |||||
|---|---|---|---|---|---|
| COVID-19 | |||||
| Model | Feature | A (%) | P (%) | R (%) | F1 (%) |
| LR | CV | 0.9313 | 0.9363 | 0.9321 | 0.9342 |
| SVM | CV | 0.9318 | 0.9333 | 0.9366 | 0.9349 |
| MNB | CV | 0.9051 | 0.9127 | 0.9054 | 0.9090 |
| DT | CV | 0.8874 | 0.8921 | 0.8929 | 0.8925 |
| RF | CV | 0.9271 | 0.9221 | 0.9402 | 0.9310 |
| XGB | CV | 0.8944 | 0.8942 | 0.9054 | 0.8997 |
| Ensemble | CV | 0.9327 | 0.9444 | 0.9259 | 0.9351 |
| LR | TFIDF | 0.9294 | 0.9209 | 0.9464 | 0.9335 |
| SVM | TFIDF | 0.9430 | 0.9354 | 0.9571 | 0.9462 |
| MNB | TFIDF | 0.9187 | 0.9085 | 0.9393 | 0.9236 |
| DT | TFIDF | 0.8696 | 0.8778 | 0.8723 | 0.8751 |
| RF | TFIDF | 0.8654 | 0.8467 | 0.9071 | 0.8759 |
| XGB | TFIDF | 0.8883 | 0.8930 | 0.8938 | 0.8934 |
| Ensemble | TFIDF | 0.9360 | 0.9408 | 0.9366 | 0.9387 |
| LR | Word2Vec | 0.9028 | 0.9050 | 0.9098 | 0.9074 |
| SVM | Word2Vec | 0.9051 | 0.9018 | 0.9187 | 0.9102 |
| MNB | Word2Vec | 0.8388 | 0.8083 | 0.9071 | 0.8549 |
| DT | Word2Vec | 0.7916 | 0.7993 | 0.8036 | 0.8014 |
| RF | Word2Vec | 0.8734 | 0.8794 | 0.8786 | 0.8790 |
| XGB | Word2Vec | 0.8916 | 0.8943 | 0.8991 | 0.8967 |
| Ensemble | Word2Vec | 0.9023 | 0.9175 | 0.8938 | 0.9055 |
| LR | GloVe | 0.8182 | 0.8170 | 0.8411 | 0.8289 |
| SVM | GloVe | 0.8173 | 0.8145 | 0.8429 | 0.8284 |
| MN | GloVe | 0.6486 | 0.6024 | 0.6961 | 0.7421 |
| DT | GloVe | 0.7379 | 0.7450 | 0.7589 | 0.7519 |
| RF | GloVe | 0.8280 | 0.8144 | 0.8696 | 0.8411 |
| XGB | GloVe | 0.8416 | 0.8381 | 0.8643 | 0.8510 |
| Ensemble | GloVe | 0.8449 | 0.8493 | 0.8554 | 0.8523 |
| Dataset | |||||
|---|---|---|---|---|---|
| COVID-19 | |||||
| Model | Feature | A (%) | P (%) | R (%) | F1 (%) |
| CNN | Word2Vec | 0.9187 | 0.9022 | 0.9473 | 0.9242 |
| BiLSTM | Word2Vec | 0.9257 | 0.9309 | 0.9268 | 0.9289 |
| BiGRU | Word2Vec | 0.9294 | 0.9246 | 0.9420 | 0.9332 |
| CNN-LSTM | Word2Vec | 0.9290 | 0.9291 | 0.9357 | 0.9324 |
| CNN-GRU | Word2Vec | 0.9332 | 0.9342 | 0.9384 | 0.9363 |
| CNN-BiLSTM | Word2Vec | 0.9304 | 0.9362 | 0.9304 | 0.9333 |
| CNN-BiGRU | Word2Vec | 0.9070 | 0.9656 | 0.8527 | 0.9056 |
| Hybrid | Word2Vec | 0.9294 | 0.9145 | 0.9545 | 0.9340 |
| CNN | GloVe | 0.9542 | 0.9554 | 0.9571 | 0.9563 |
| BiLSTM | GloVe | 0.9355 | 0.9161 | 0.9652 | 0.9400 |
| BiGRU | GloVe | 0.9421 | 0.9220 | 0.9714 | 0.9461 |
| CNN-LSTM | GloVe | 0.8593 | 0.7991 | 0.9768 | 0.8791 |
| CNN-GRU | GloVe | 0.5234 | 0.5234 | 0.9991 | 0.6869 |
| CNN-BiLSTM | GloVe | 0.9477 | 0.9308 | 0.9723 | 0.9511 |
| CNN-BiGRU | GloVe | 0.9472 | 0.9382 | 0.9625 | 0.9502 |
| Hybrid | GloVe | 0.9374 | 0.9143 | 0.9714 | 0.9420 |
| CNN | BERT | 0.9752 | 0.9725 | 0.9804 | 0.9764 |
| BiLSTM | BERT | 0.9650 | 0.9485 | 0.9866 | 0.9672 |
| BiGRU | BERT | 0.9706 | 0.9616 | 0.9830 | 0.9722 |
| CNN-LSTM | BERT | 0.9598 | 0.9434 | 0.9821 | 0.9624 |
| CNN-GRU | BERT | 0.9626 | 0.9710 | 0.9571 | 0.9640 |
| CNN-BiLSTM | BERT | 0.9621 | 0.9529 | 0.9759 | 0.9643 |
| CNN-BiGRU | BERT | 0.9565 | 0.9485 | 0.9696 | 0.9589 |
| Hybrid | BERT | 0.9617 | 0.9642 | 0.9625 | 0.9634 |
| BERT | BERT | 0.9771 | 0.9735 | 0.9830 | 0.9782 |
| RoBERTa | RoBERTa | 0.9668 | 0.9541 | 0.9839 | 0.9688 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alghamdi, J.; Lin, Y.; Luo, S. A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection. Information 2022, 13, 576. https://doi.org/10.3390/info13120576
Alghamdi J, Lin Y, Luo S. A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection. Information. 2022; 13(12):576. https://doi.org/10.3390/info13120576
Chicago/Turabian StyleAlghamdi, Jawaher, Yuqing Lin, and Suhuai Luo. 2022. "A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection" Information 13, no. 12: 576. https://doi.org/10.3390/info13120576
APA StyleAlghamdi, J., Lin, Y., & Luo, S. (2022). A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection. Information, 13(12), 576. https://doi.org/10.3390/info13120576