1. Introduction
In a contact centre (CC), human resources (HR) employees need to answer often complex questions from organisational users that necessitate access to personal files and a thorough understanding of HR documentation. However, much time is spent answering simple questions. Substantial time would be saved if we could handle the simple questions automatically. Therefore, we need to determine whether a computer can handle a particular question or not.
For a long time, researchers have tried to let a computer answer questions. In recent years, enormous datasets have been publicly available to let computers learn how to answer questions. In Squad 2.0 [
1], the dataset’s structure is modelled to learn how to answer questions and determine whether a particular question cannot be answered.
This research will examine whether this technique can be employed in a CC at the Dutch government. Our case study organisation is P-Direkt; it has a CC of more than 425 full-time employees. Questions cover policies, such tax benefits for bicycle commuting and how the HR portal works.
Every year around 240,000 questions are registered from 130,000 users, creating a very high workload. With the end goal of reducing this workload, we investigated the following research questions: Can Dutch question answering (QA) datasets help CCs answer questions automatically? How do modelled HR questions perform on current Dutch QA models? How well does a self-trained QA model perform on answering CC questions? What kind of dataset varieties support modelling our Dutch HR QA dataset?
One important constraint is that the Dutch QA community is much smaller than the English community. Currently, there are no suitable publicly available Dutch QA datasets. We investigated whether we could employ machine-translated QA datasets in Dutch.
Therefore, our contributions include how to make a small QA dataset from e-mail. Another contribution was to explore how a small organisation-specific QA dataset performed, as opposed to a sizeable general-purpose QA dataset developed using crowdsourcing platforms such as Amazon Mechanical Turk.
The paper is structured as follows: in
Section 2, entity linking, QA datasets, and translated datasets are elaborated. In
Section 3, we describe the creation of the P-Direkt QA dataset.
Section 4 explains how the analysis was performed.
Section 5 reports the details of the created dataset and the test statistics, followed by discussion and suggested future work in
Section 5.3 and
Section 6. We answer our research questions in
Section 7.
3. Dataset
In this study, we needed to create a dataset to examine whether the data structure of the Squad 2.0 dataset was suitable for questions in the HR domain. The starting point was a dataset from approximately 170,000 P-Direkt e-mails and 295 HR documentation pages from the Dutch government intranet.
The e-mails were sent between 2018 and 2020. The personal identifiers in the e-mails were morphed into pseudonymised placeholders [
16]. The intranet documentation was scraped with Scrapy [
17] in May 2021 and cleaned with Beautiful Soup [
18].
The questions in the e-mails showed us that every question was answerable with either documentation, personnel files, or both. We focused only on the questions with an answer from documentation. Our first exploration with a subset of 202 e-mails showed that 18% of the questions could be answered from written documentation.
We created an answerable question identification dataset that distinguished between questions answerable by documentation and those that were not by randomly selecting sentences with a question mark, each with at least six tokens or more. From a random selection of 5409 questions, we categorised 820 questions as valid, i.e., answerable from documentation. These questions were not linked to answers and were only used to identify questions for the QA dataset creation.
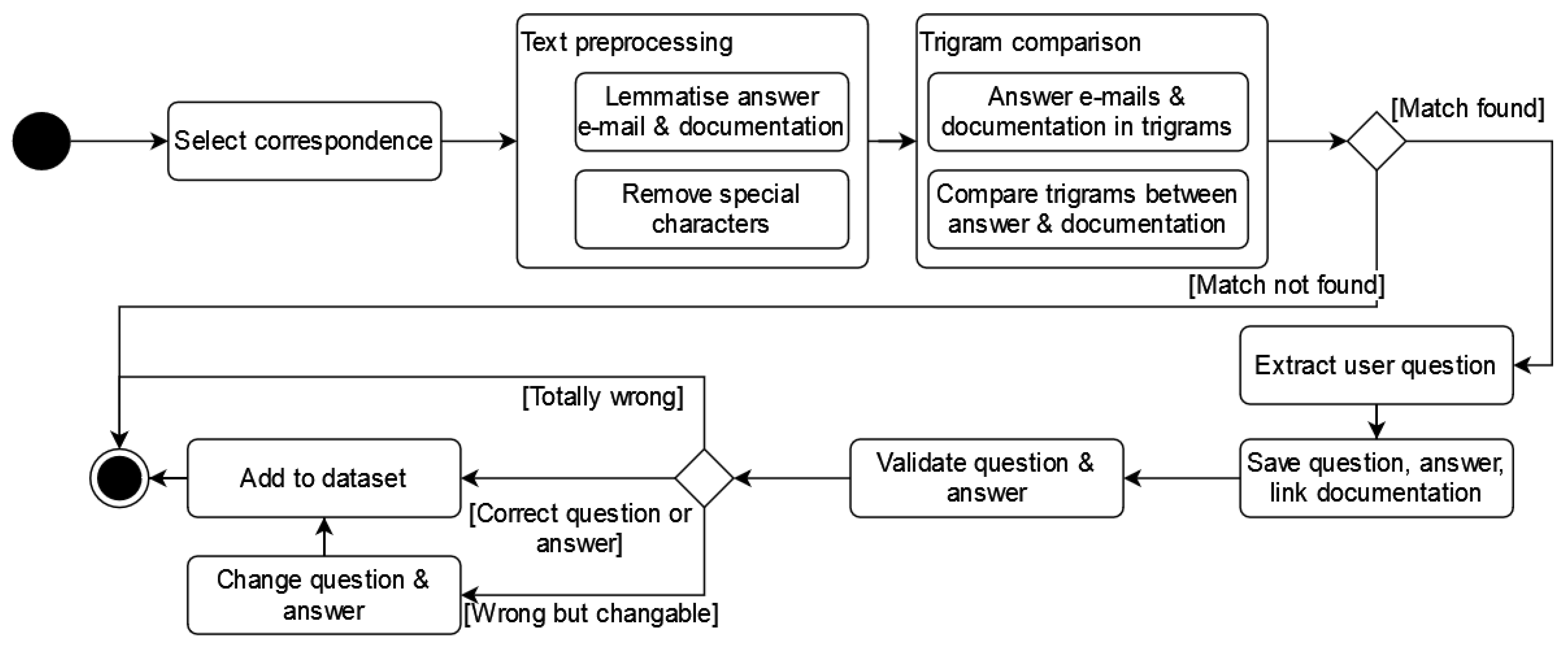
Figure 1 gives a brief overview of the construction of the dataset. The first step is selecting the correspondence. With this answerable question identification dataset, we created a model with the Roberta For Sequence Classification algorithm with the Dutch language model RobBERT [
19]. We could therefore identify well-written questions with an information need based on documentation instead of their personal files. These correspondences were chosen to analyse further.
In the second step, the preprocessing was performed for the texts. For both answer e-mails and documentation, we removed stopwords and non-alphabetical tokens and lemmatised the remaining tokens using the spaCy toolkit [
20].
The third step was to find a link between the answers and the documentation. A link must have an exact match between the answer and documentation [
21]. This was performed by forming the texts in trigrams and finding comparisons between the answer e-mails and the documentation.
The fourth step extracted the question from the customer’s e-mail. A straightforward method found the question. The method tokenised the sentences and selected the first sentence with a question mark as the leading question [
22]. In the fifth step, the question, answer and documentation were combined in a JSON file, as an invalidated temporary dataset.
After data mining the e-mail dataset, the validation began, at step six. The tokenisation process did not always give clear sentences. Sometimes, the questions had noise from previous sentences and incomplete tokenisation (substep change question and answer,
Figure 1). We cleaned the noisy questions to their essence. The same applied to the documentation. Sometimes, the documentation link had headings or was too extensive and had unnecessary information. We also cleaned those answers to their essence. We noticed that not every paragraph could be connected to an answer. Therefore, we added 30 additional questions with answers from the documentation.
To mimic the Squad 2.0 dataset, our data was stored in JSON. A key difference with Squad 2.0 was our use of a helpdesk e-mail archive as a source, as opposed to Squad 2.0, which was a crowdsourced approach to create artificial fact-based questions.
This dataset came in three different versions: full, medium, and small.
Figure 2 gives a global overview of the differences between the three versions. The full dataset contained all the found questions and answers divided over six pages of HR-related texts, for six documents. The medium dataset contained questions with unique answers but only answerable questions. The unanswerable questions were the same in number as the full dataset. The small dataset contained questions with unique answers and unanswerable questions linking to unique plausible answers.
Figure 2 gives a brief overview of the construction of the dataset. The first step was to find a link between the answers and the documentation. A link must have an exact match between the answer and documentation [
21]. The next step extracted the question from the customer’s e-mail.
Author Contributions
Conceptualization, C.v.T.; methodology, C.v.T.; software, C.v.T.; validation, C.v.T.; formal analysis, C.v.T.; investigation, C.v.T. and F.v.D.; resources, C.v.T. and F.v.D.; data curation, C.v.T. and F.v.D.; writing—original draft preparation, C.v.T.; writing—review and editing, C.v.T., M.S. (Marijn Schraagen), F.v.D., M.B. and M.S. (Marco Spruit); visualization, C.v.T.; supervision, M.S. (Marijn Schraagen), M.B. and M.S. (Marco Spruit); project administration, C.v.T.; funding acquisition, M.B. and M.S. (Marco Spruit). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by P-Direkt, Ministry of the Interior and Kingdom Relations, The Netherlands.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
We would like to thank the employees of P-Direkt who made the data available for doing research.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| CC | Contact Centre |
| HR | Human Resources |
| QA | Question answering |
| NER | Named entity recognition |
References
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Rao, D.; McNamee, P.; Dredze, M. Entity Linking: Finding Extracted Entities in a Knowledge Base. In Multi-Source, Multilingual Information Extraction and Summarization; Poibeau, T., Saggion, H., Piskorski, J., Yangarber, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 93–115. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, J.; Zhao, H. Retrospective reader for machine reading comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 14506–14514. [Google Scholar]
- Trischler, A.; Wang, T.; Yuan, X.; Harris, J.; Sordoni, A.; Bachman, P.; Suleman, K. NewsQA: A Machine Comprehension Dataset. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 3 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 191–200. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Choi, E.; He, H.; Iyyer, M.; Yatskar, M.; Yih, W.t.; Choi, Y.; Liang, P.; Zettlemoyer, L. QuAC: Question Answering in Context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 2174–2184. [Google Scholar] [CrossRef]
- Reddy, S.; Chen, D.; Manning, C.D. CoQA: A Conversational Question Answering Challenge. Trans. Assoc. Comput. Linguist. 2019, 7, 249–266. [Google Scholar] [CrossRef]
- Yagcioglu, S.; Erdem, A.; Erdem, E.; Ikizler-Cinbis, N. RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking Recipes. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 1358–1368. [Google Scholar] [CrossRef]
- Castelli, V.; Chakravarti, R.; Dana, S.; Ferritto, A.; Florian, R.; Franz, M.; Garg, D.; Khandelwal, D.; McCarley, J.S.; McCawley, M.; et al. The TechQA Dataset. In Proceedings of the Association for Computational Linguistics (ACL), Seattle, WA, USA, 5–10 July 2020; pp. 1269–1278. [Google Scholar]
- Zhong, H.; Xiao, C.; Tu, C.; Zhang, T.; Liu, Z.; Sun, M. JEC-QA: A Legal-Domain Question Answering Dataset. arXiv 2019, arXiv:1911.12011. [Google Scholar] [CrossRef]
- Carrino, C.P.; Costa-jussà, M.R.; Fonollosa, J.A.R. Automatic Spanish Translation of SQuAD Dataset for Multi-lingual Question Answering. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Marseille, France, 2020; pp. 5515–5523. [Google Scholar]
- d’Hoffschmidt, M.; Belblidia, W.; Heinrich, Q.; Brendlé, T.; Vidal, M. FQuAD: French Question Answering Dataset. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1193–1208. [Google Scholar] [CrossRef]
- Abadani, N.; Mozafari, J.; Fatemi, A.; Nematbakhsh, M.A.; Kazemi, A. ParSQuAD: Machine Translated SQuAD dataset for Persian Question Answering. In Proceedings of the 2021 7th International Conference on Web Research (ICWR), Tehran, Iran, 19–20 May 2021; pp. 163–168. [Google Scholar] [CrossRef]
- Mozannar, H.; Maamary, E.; El Hajal, K.; Hajj, H. Neural Arabic Question Answering. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 108–118. [Google Scholar] [CrossRef]
- Rogers, A.; Gardner, M.; Augenstein, I. QA Dataset Explosion: A Taxonomy of NLP Resources for Question Answering and Reading Comprehension. arXiv 2021, arXiv:2107.12708. [Google Scholar] [CrossRef]
- van Toledo, C.; van Dijk, F.; Spruit, M. Dutch Named Entity Recognition and De-Identification Methods for the Human Resource Domain. Int. J. Nat. Lang. Comput. 2020, 9, 23–34. [Google Scholar] [CrossRef]
- Kouzis-Loukas, D. Learning Scrapy; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Richardson, L. Beautiful Soup Documentation. April 2007. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (accessed on 21 August 2022).
- Delobelle, P.; Winters, T.; Berendt, B. RobBERT: A Dutch RoBERTa-based Language Model. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3255–3265. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python; Zenodo: Honolulu, HI, USA, 2022. [Google Scholar] [CrossRef]
- Reeve, J. Text-Matcher; GitHub Repository: San Francisco, CA, USA, 2020. [Google Scholar] [CrossRef]
- Pander Maat, H.; Kraf, R.; Dekker, N. Handleiding T-Scan 2014. Available online: https://raw.githubusercontent.com/proycon/tscan/master/docs/tscanhandleiding.pdf (accessed on 20 August 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Xia, P.; Wu, S.; Durme, B.V. Which *BERT? A Survey Organizing Contextualized Encoders. In Proceedings of the EMNLP, Online, 16–20 November 2020. [Google Scholar]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- de Vries, W.; van Cranenburgh, A.; Bisazza, A.; Caselli, T.; Noord, G.v.; Nissim, M. BERTje: A Dutch BERT Model. arXiv 2019, arXiv:1912.09582. [Google Scholar]
- Brandsen, A.; Dirkson, A.; Verberne, S.; Sappelli, M.; Manh Chu, D.; Stoutjesdijk, K. BERT-NL a set of language models pre-trained on the Dutch SoNaR corpus. In Proceedings of the Dutch-Belgian Information Retrieval Conference (DIR 2019), Wuhan, China, 23–27 May 2019. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Ma, C.; Jernite, Y.; Plu, J.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Borzymowski, H. henryk/bert-base-multilingual-cased-finetuned-dutch-squad2 · Hugging Face. In Proceedings of the Benelux Conference on Artificial Intelligence, Esch-sur-Alzette, Luxembourg, 10–12 November 2020. [Google Scholar]
- Ohsugi, Y.; Saito, I.; Nishida, K.; Asano, H.; Tomita, J. A Simple but Effective Method to Incorporate Multi-turn Context with BERT for Conversational Machine Comprehension. In Proceedings of the First Workshop on NLP for Conversational AI, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 11–17. [Google Scholar] [CrossRef]
- Qu, C.; Yang, L.; Qiu, M.; Croft, W.B.; Zhang, Y.; Iyyer, M. BERT with History Answer Embedding for Conversational Question Answering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; ACM: Paris France, 2019; pp. 1133–1136. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}