
A Test Management System to Support Remote Usability Assessment of Web Applications




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Research Background
2.1. Usability Testing
2.2. Methods and Tools for Web Usability Assessment
2.3. Related Work
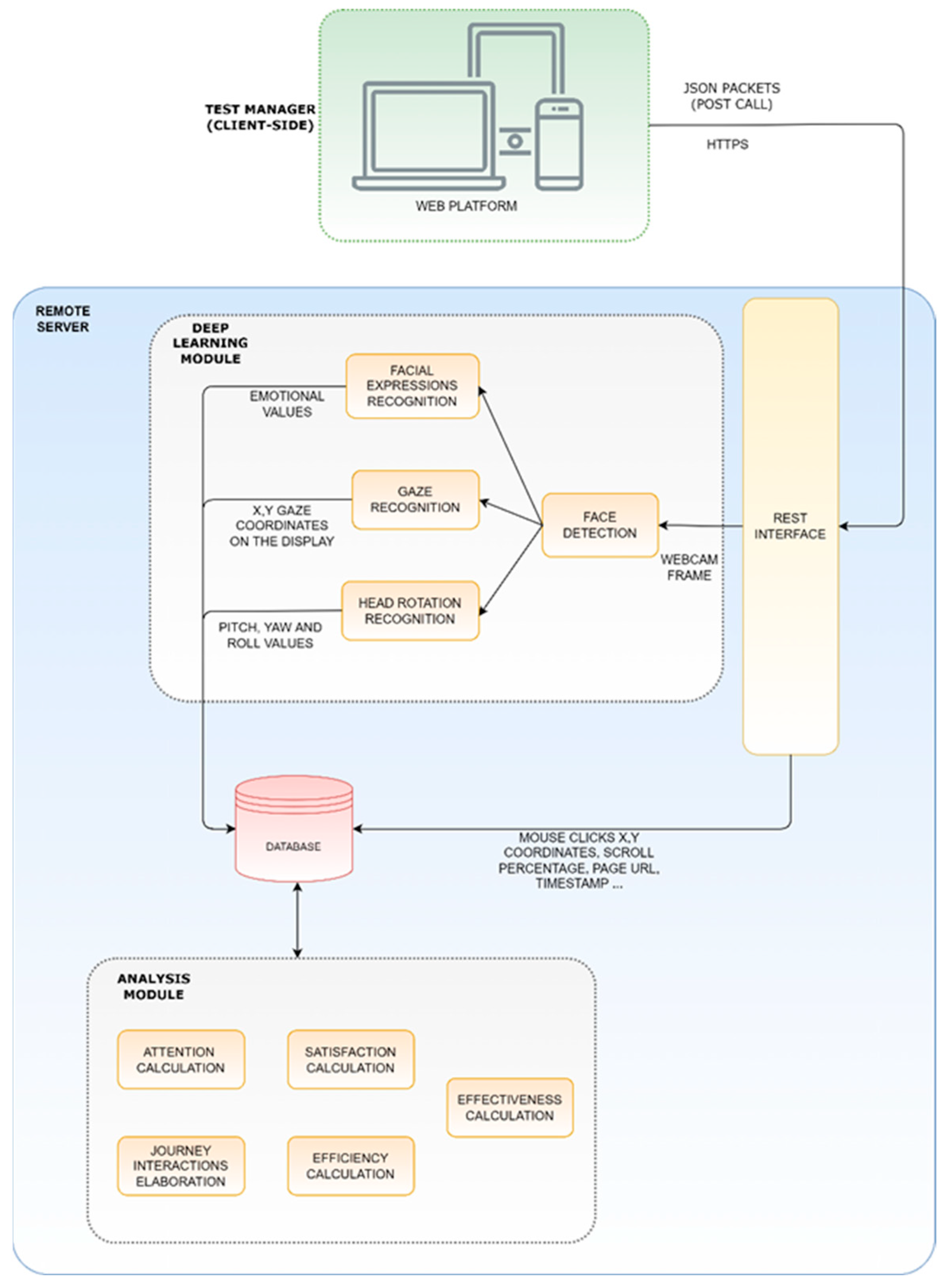
3. Miora, a Tool for Remote Usability Assessment
3.1. The Remote Server
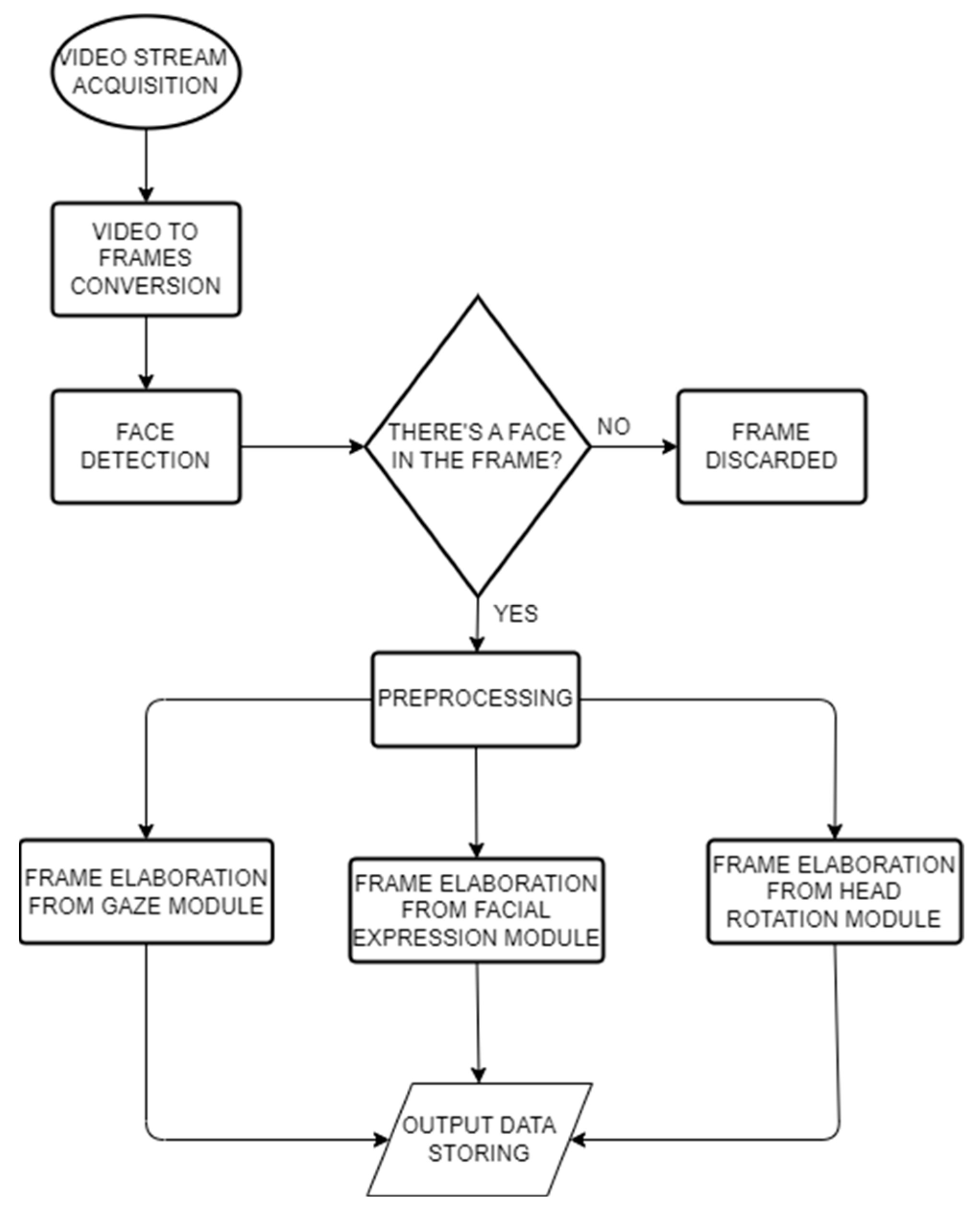
3.1.1. Deep Learning Module
- Face detection: the third-party library Dlib [52] is used to detect one or more human faces and provide the coordinates of the main face landmarks.
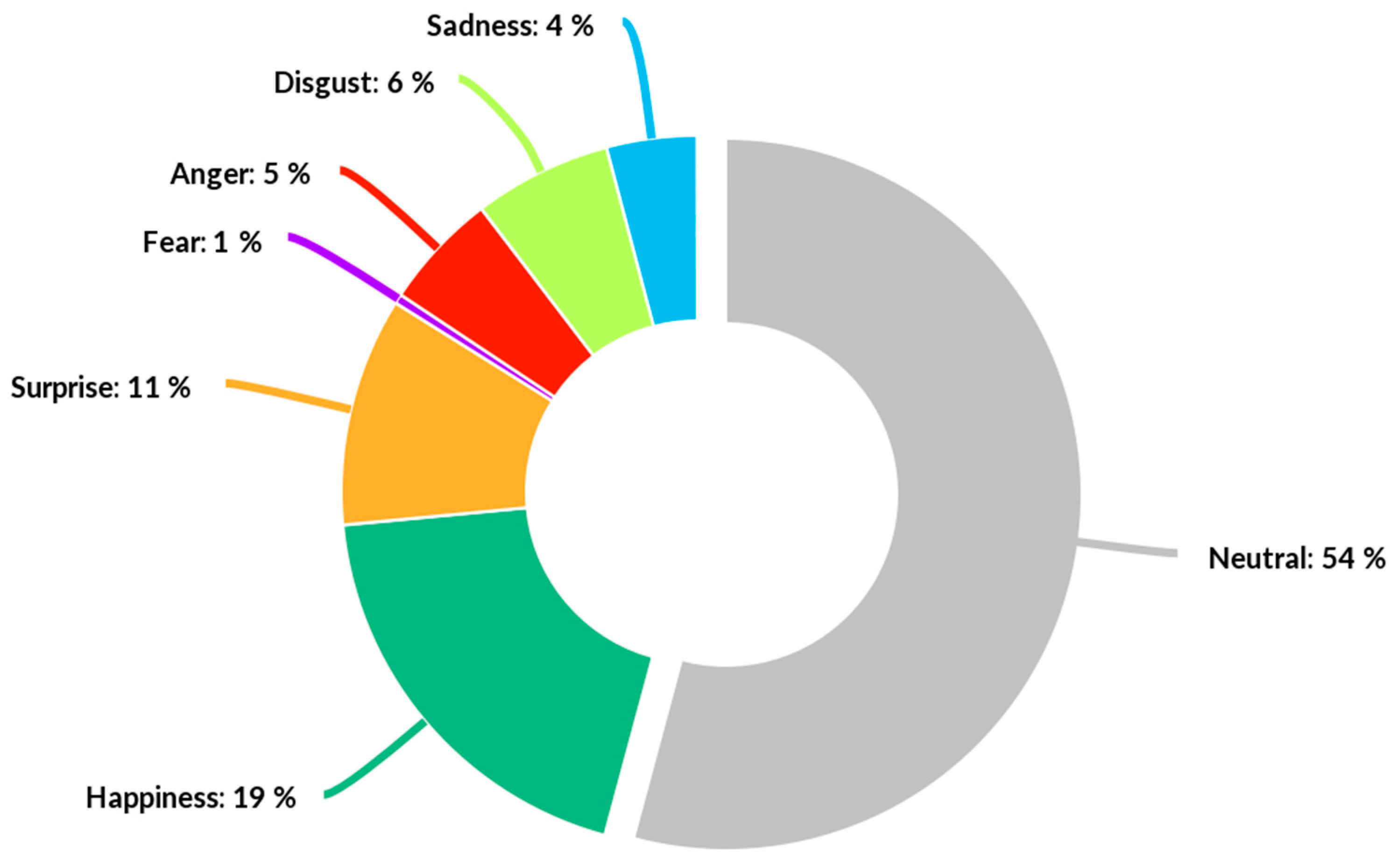
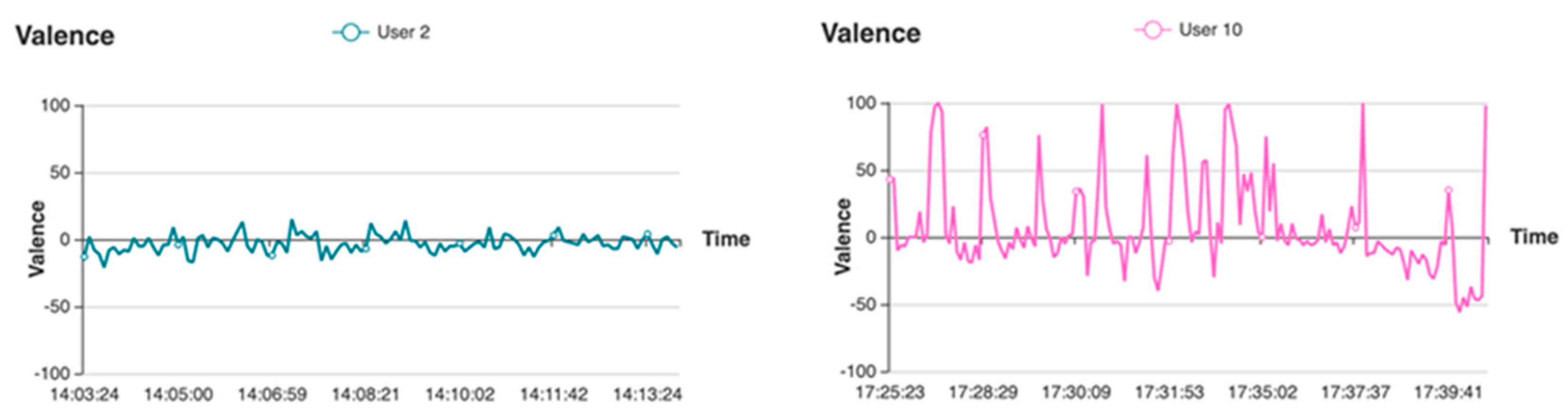
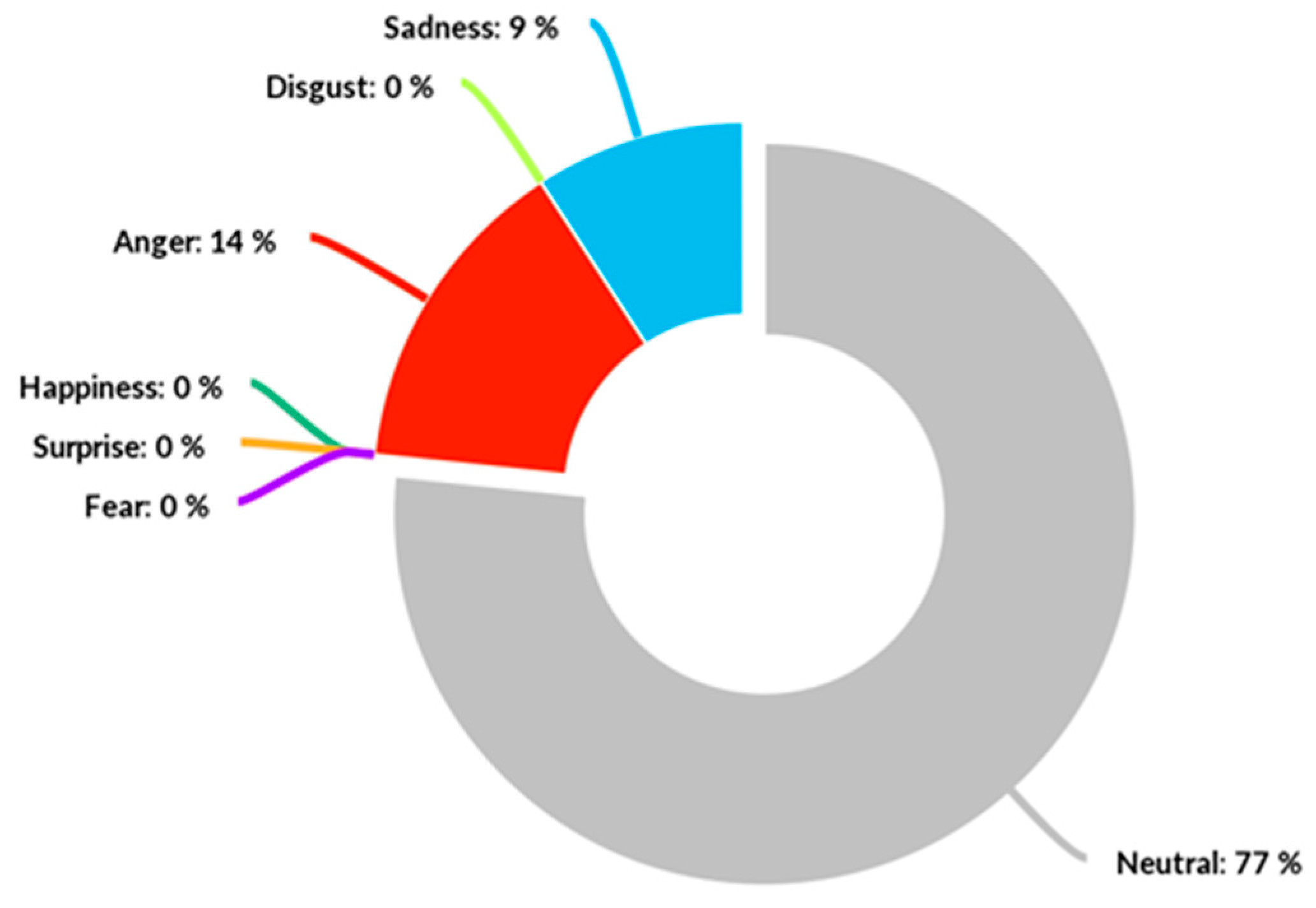
- Facial Expressions recognition: a VGG Convolutional Neural Network has been trained to take 64 × 64 pixel grayscale facial images from the input layer and return the classification probability of the six Ekman emotions (joy, surprise, anger, disgust, sadness, fear) from the output layer. The training process has been described and validated in [53]. The emotions expressed by the user are summed at each instant and normalised up to the value of 100 as a percentage. Valence can then be computed at each instant following the approach used in [54] to differentiate between Ekman’s positive and negative emotions. Therefore, Valence ranges from −100 to 100 and indicates the total positivity or negativity expressed by the participants. The user’s emotional Engagement is instead computed with the following formula:and averaged over time using a moving average with a step of 1 s.Engagement = 100 − Neutral (%),
- Gaze recognition: a Convolutional Neural Network-based model has been trained to perform gaze tracking, taking in as input the cropped images of the left and right eyes separately, the detected face image cropped from the original frame, and a binary mask (face grid) used to indicate the position and size of the face within the frame, producing the x–y coordinates of the eye fixation respect to the observed monitor. The training process has been described in [51,53].
- Head rotation recognition: head rotation recognition is performed to have an evaluation of the attention level. As for the face detection module, the Dlib library has been used to retrieve a mapping of the user’s facial features. In particular, the distances between six pairs of landmarks were considered to estimate the orientation of the head with respect to the webcam, according to how it is described in [55]. The results will be the calculation of the yaw, pitch, and roll values in relation to the webcam.
3.1.2. Database
- url: URL of the page that was active while data was being captured;
- timestamp: the timestamp when the event happened;
- xCoordinate and yCoordinate: coordinates of the point in the screen the user was looking at while data was being captured;
- yaw, pitch and roll: head rotation indicators on the 3 spatial axes x, y and z;
- viewportWidth and viewportHeight: size of the viewport used to visit the site;
- scroll: whether the scroll event is triggered or not;
- scroll depth: percentage of page scroll at the time data were being captured;
- timeSpent: time spent by the user completing the task;
- note: notes written during the task.
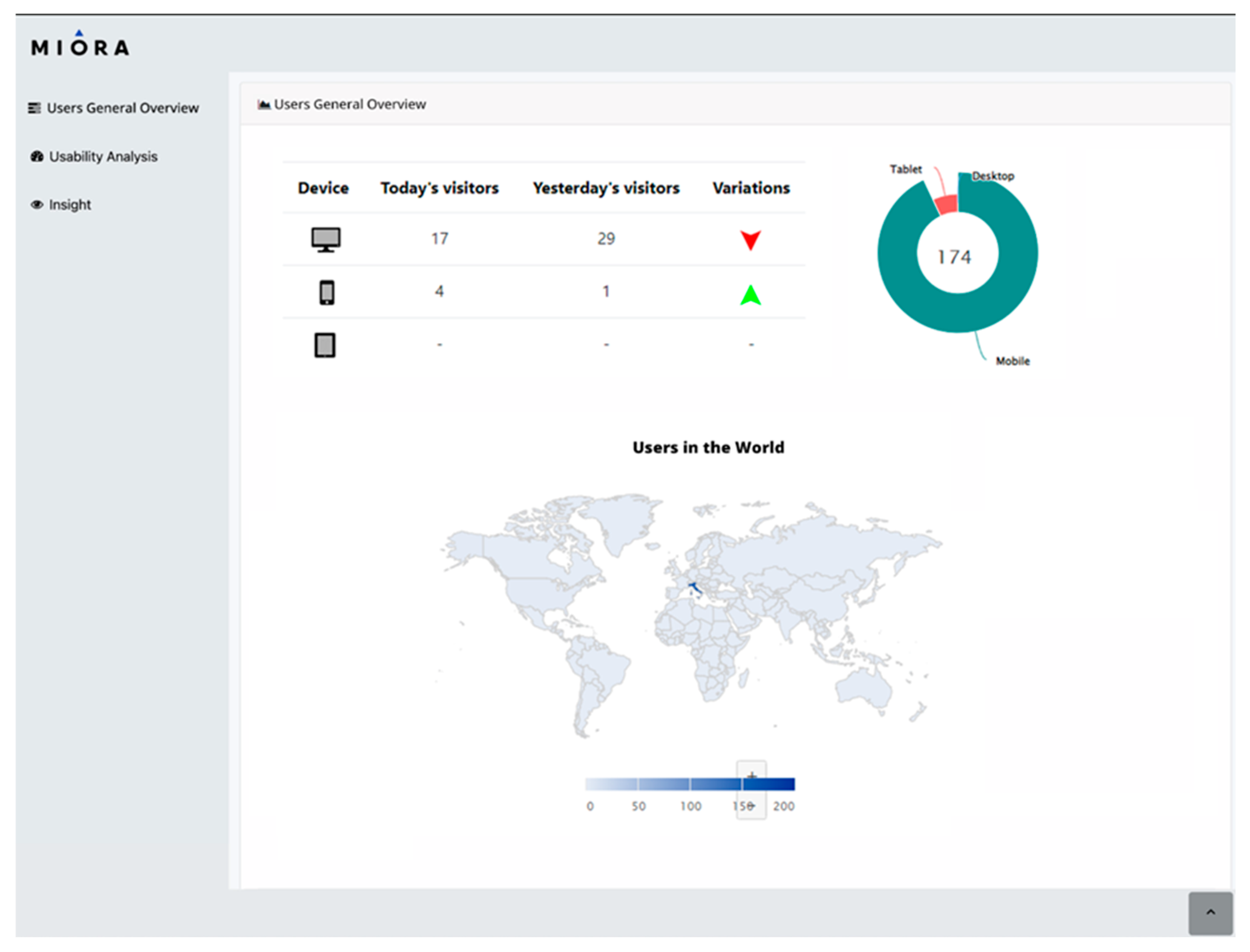
3.1.3. Analysis Module
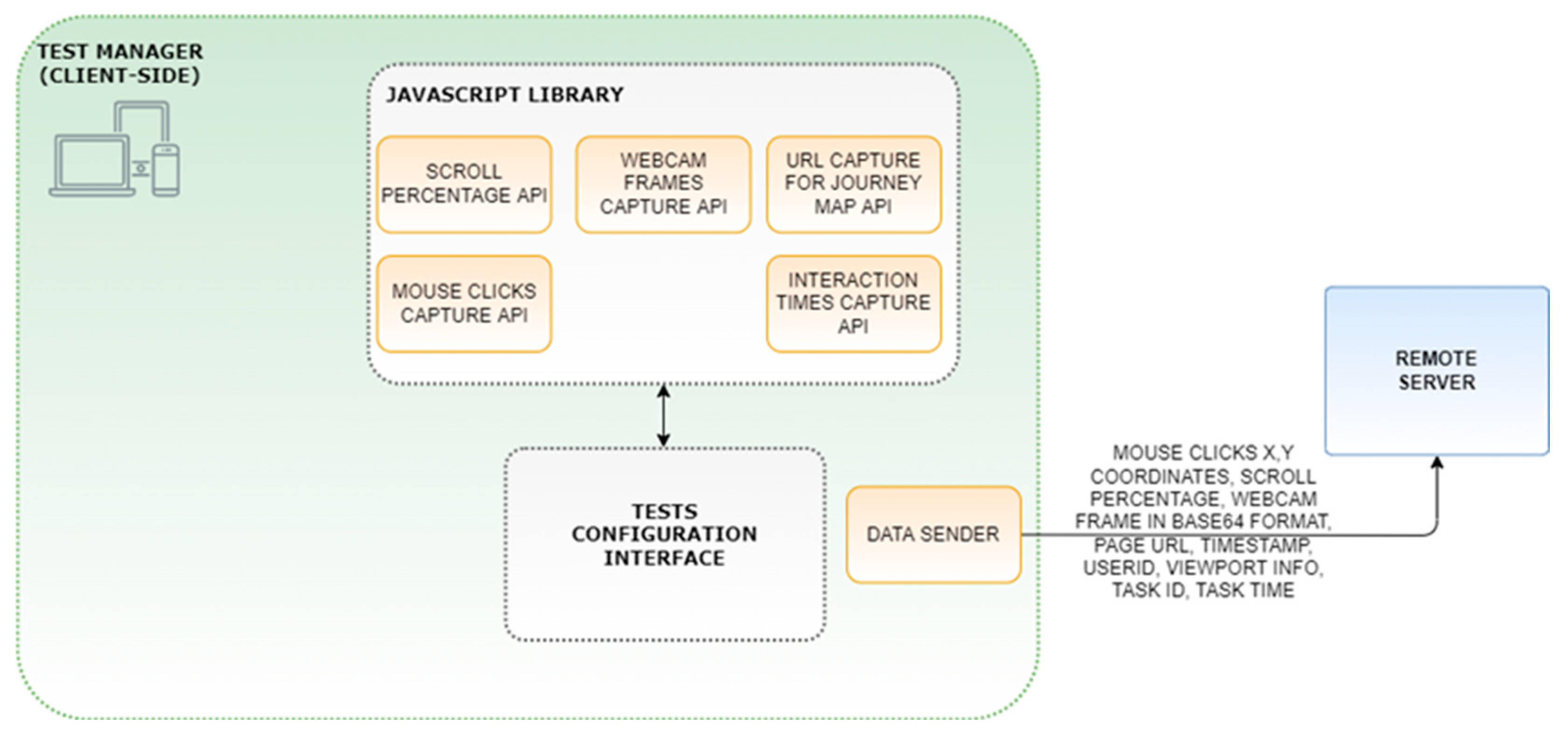
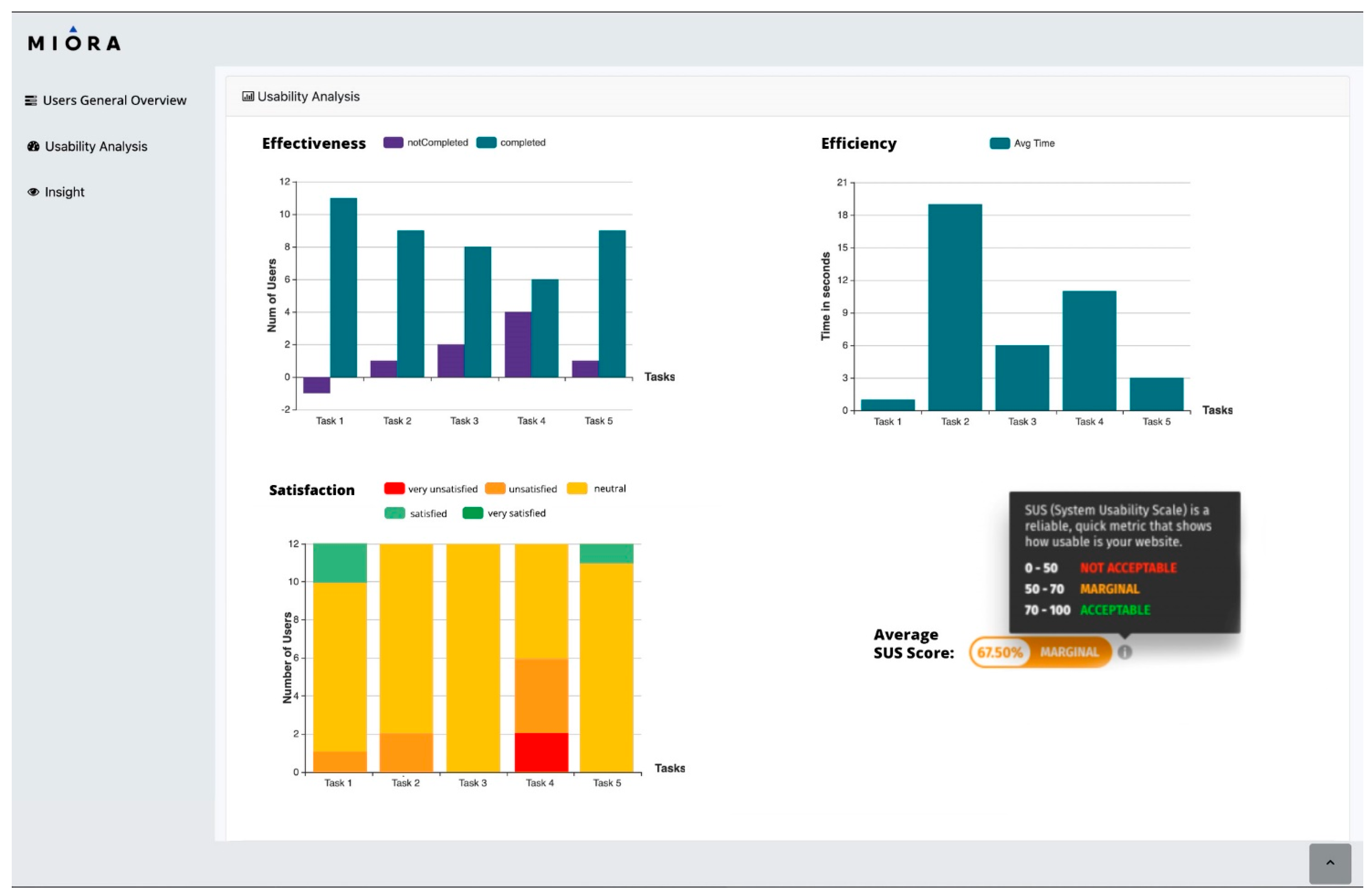
3.2. The Test Manager
- Mouse clicks capture API: it retrieves the mouse clicks’ coordinates (or taps on a mobile device) on the entire screen with the related timestamp and computes the relative coordinates on the window currently opened by considering the viewportWidth and viewportHeight variables, whether a scrolling event occurred and with the scroll percentage relative to the open window. For example, each time the user scrolls the current view, the y-offset from the top-left corner of the screen is updated. This allows us to build a real map of all the clicks that have occurred on a web page. Furthermore, the clicks can be connected in a chronological order thanks to the timestamps collected.
- Scroll percentage API: it acquires data about whether a scrolling event was triggered or not and how much a participant scrolled on a specific page is expressed in percentage values. By capturing the scroll events, we can offset the position of the clicks/taps on the page and thus build a map of all the click events.
- Webcam frame capture API: it takes photos with a predefined frequency by accessing the webcam and sending Base64 encoded images to the server. These images are subsequently decoded and processed by the Deep Learning module to infer emotions, and with the gaze and head rotation recognition modules to identify the attention. In particular, the face detection module used is face-api.js [58], built on top of the tensorflow.js core that implements a CNN to detect faces. Participants are asked to grant access to the camera when they start the task so as to periodically capture the participants’ frontal face, resize the captured image to 640 × 480, and convert the image to a Base64 string. The moderator can set the capture frequency up to 10 fps in a lab setting with a good bandwidth, and the resolution of the captured frames to be sent to the server. All the user interaction data are sent to the server with asynchronous HTTPS web requests once the page URL changes.
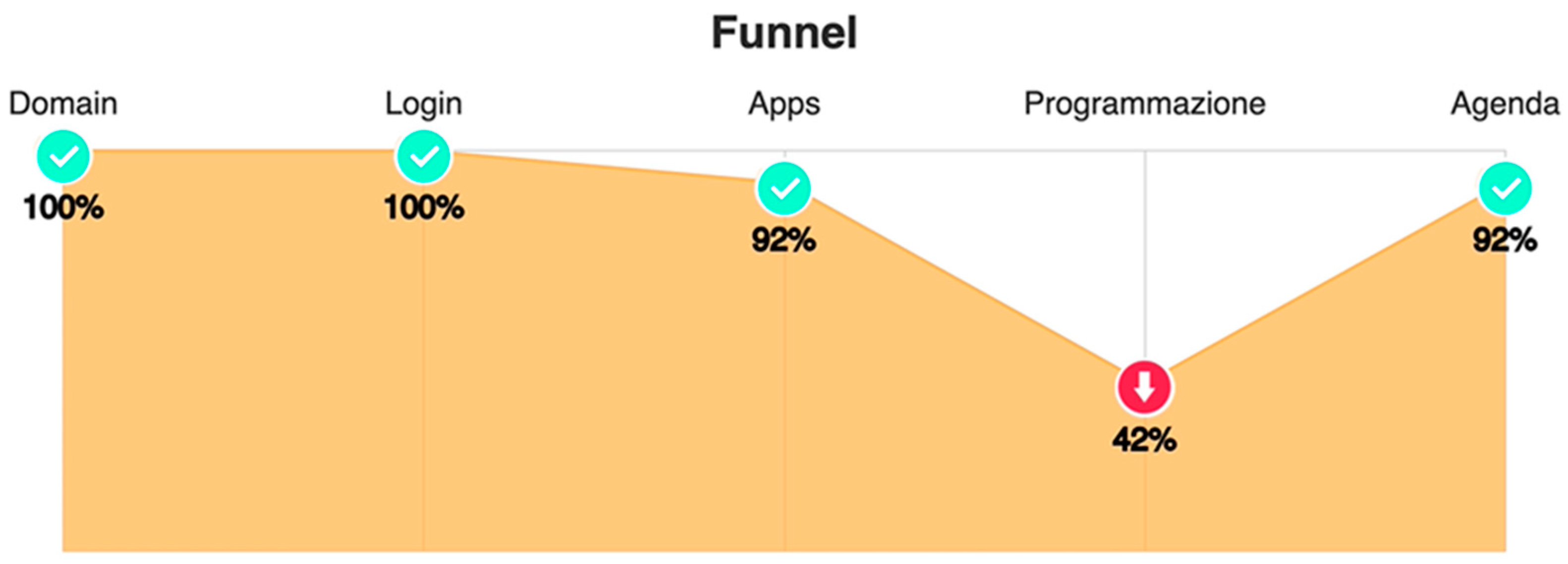
- URL capture for structure graph journey map API: it retrieves the web pages URL and the timestamps at which those pages were being visited. This allows the tool to build a structured graph of web pages visited by the user, visualise the percentage of users who visited each page in a funnel graph, and make it all available for funnel analysis.
- Interaction times capture API: it retrieves the timestamps for any user interaction. Once collected, interaction times can be correlated with the emotions being expressed at that time for satisfaction analysis, or with the gaze paths to analyse attention, stress, or fatigue.
- to configure and set up each usability task;
- to record the navigation of the expert user with automatic recordings of the URLs visited by the expert in the task preparation and the relative times, so that they can be compared with the users’ times;
- to specify a set of parameters from the data collection APIs, such as how and when to activate the camera, the frames acquisition frequency, frames resolution and the other metrics previously described;
- to manage invitations and participant access.
4. Case Studies and Results
4.1. Usability Testing of an Online Store: Analyzing the Reliability of the Proposed Framework
- Task 1: Search for a washing machine of A+++ class with a price not exceeding €400. This task requires inserting appropriate words in the search bar and/or selecting the necessary filters;
- Task 2: Compare the several washing machine models and perform a choice. This task requires looking for information regarding each model shown in the results page, comparing the data, and performing a choice based on subjective preferences;
- Task 3: Buy the washing machine selected in the previous step. This task involved filling in a form with personal data and a billing address to simulate the transaction.
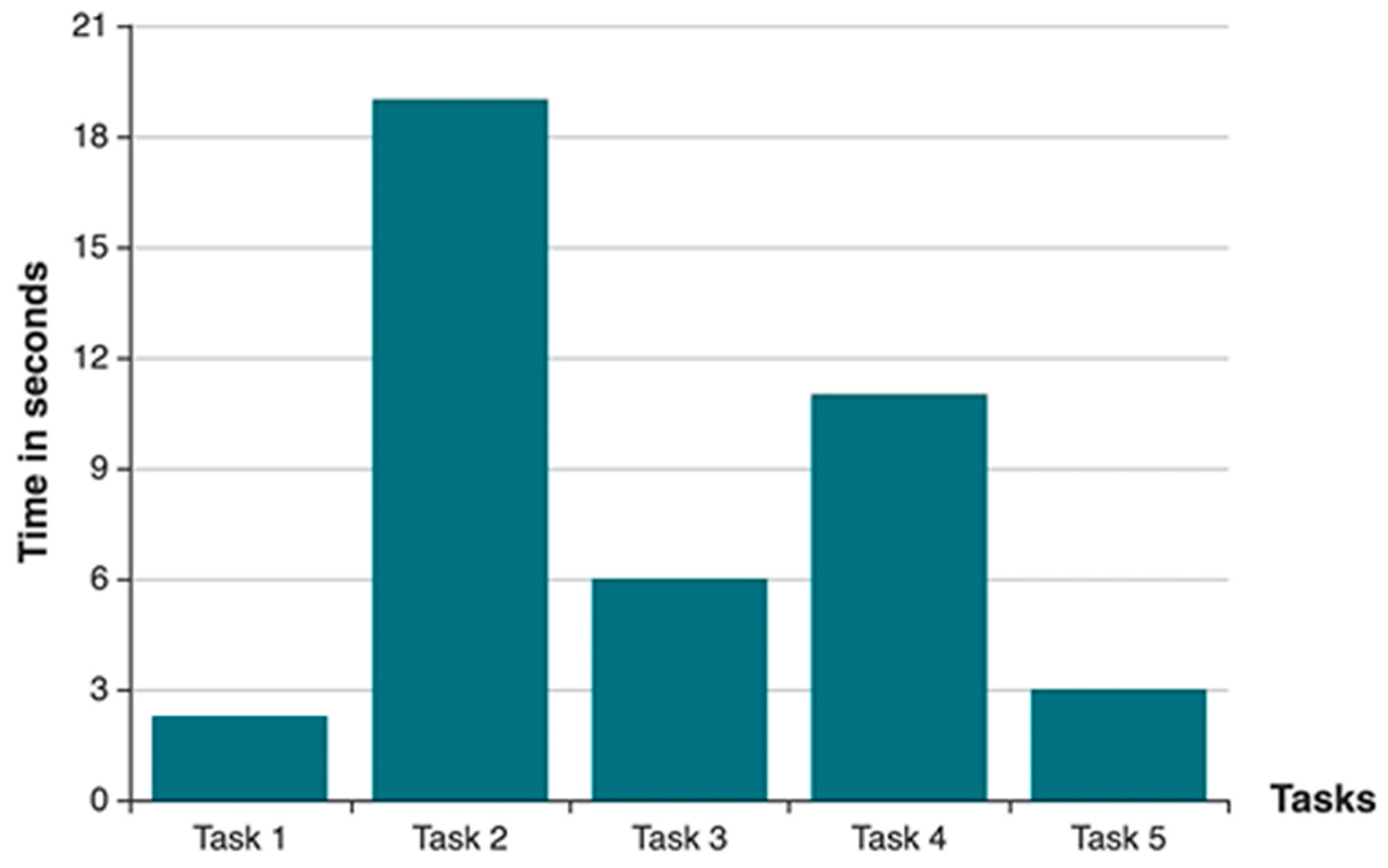
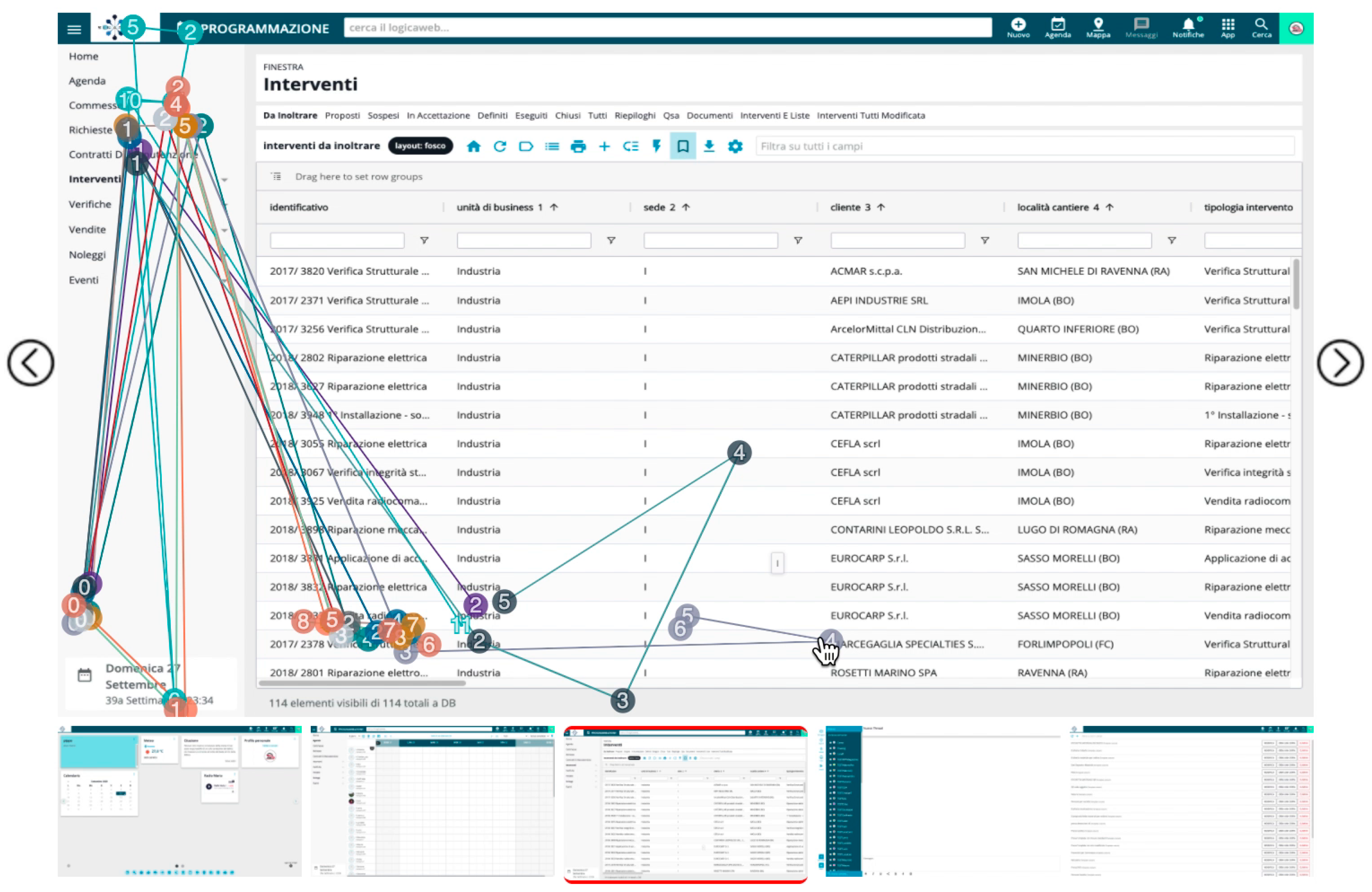
4.2. Usability Testing of a Management Web Platform
- Task 1: Log in into the system and add a weather widget of your current city, to the platform desktop. This task involved accessing the system, selecting the appropriate widget, and choosing the current city from a drop-down menu in the weather widget;
- Task 2: Log in into the system and assign a job to a team member. This task required accessing a toolbar menu (the Apps menu) not visible by default. Then, users had to navigate to the appropriate app in the toolbar, select a specific team member from the list, select a timeframe in which a job must be performed, write a brief description of the job, and assign the job to them;
- Task 3: Log in into the system and change the layout of the grid by selecting “up to today”. This involved navigating to the Interventions menu and clicking the button on top of the grid that changes the layout;
- Task 4: Log in into the system and send a message without an attachment to a team member. This involved finding the messaging app in the Apps menu, selecting the recipient by clicking on a specific checkbox, and sending the message by pressing the “Enter” key on the keyboard;
- Task 5: Log in into the system and delete the first report on the list. This last task involved going into the reports grid and clicking on the “Delete” button of the chosen report.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zaki, T.; Islam, M.N. Neurological and physiological measures to evaluate the usability and user-experience (UX) of information systems: A systematic literature review. Comput. Sci. Rev. 2021, 40, 100375. [Google Scholar] [CrossRef]
- Cooper, R.G. The drivers of success in new-product development. Ind. Mark. Manag. 2018, 76, 36–47. [Google Scholar] [CrossRef]
- Piller, F.; Susumu, O. Reducing the risks of new product development. MIT Sloan Manag. Rev. 2006, 47, 65–71. [Google Scholar]
- Nielsen, J. Usability Engineering; Morgan Kaufman: San Diego, CA, USA, 1994. [Google Scholar]
- International Organization for Standardization. ISO 9241-11:2018; Ergonomics of Human-System Interaction—Part 11: Usability: Definitions and Concepts (ISO 9241-11:2018). ISO: Geneva, Switzerland, 2018. Available online: https://www.iso.org/standard/63500.html (accessed on 22 April 2022).
- Tullis, T.; Albert, B. Measuring the User Experience: Collecting, Analyzing, and Presenting Usability Metrics, 2nd ed.; Morgan Kaufmann: San Francisco, CA, USA, 2013. [Google Scholar]
- Bevan, N.; Carter, J.; Earthy, J.; Geis, T.; Harker, S. New ISO Standards for Usability, Usability Reports and Usability Measures. In Human-Computer Interaction. Theory, Design, Development and Practice, Proceedings of the 2016 International Conference on Human-Computer Interaction (HCI’2016), Toronto, ON, Canada, 17–22 July 2016; Springer: Cham, Switzerland, 22 July 2016; pp. 268–278. [Google Scholar] [CrossRef]
- Kirakowski, J.; Corbett, M. SUMI: The Software Usability Measurement Inventory. Br. J. Educ. Technol. 1993, 24, 210–212. [Google Scholar] [CrossRef]
- Brooke, J. SUS: A ’Quick and Dirty’ Usability Scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
- Altieri, A.; Ceccacci, S.; Mengoni, M. Emotion-Aware Ambient Intelligence: Changing Smart Environment Interaction Paradigms Through Affective Computing. In International Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2019; pp. 258–270. [Google Scholar] [CrossRef]
- Munim, K.M.; Islam, I.; Khatun, M.; Karim, M.; Islam, M.N. Towards developing a tool for UX evaluation using facial expression. In Proceedings of the 2017 3rd International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 7–9 December 2017; 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, B.; Dong, Y.; Kim, S.; Lee, K.-P. Development of Integrated Analysis System and Tool of Perception, Recognition, and Behavior for Web Usability Test: With Emphasis on Eye-Tracking, Mouse-Tracking, and Retrospective Think Aloud. In International Conference on Usability and Internationalization; Springer: Berlin, Germany, 2007; Volume 4559, pp. 113–121. [Google Scholar] [CrossRef]
- Hussain, J.; Khan, W.A.; Hur, T.; Bilal, H.S.M.; Bang, J.; Hassan, A.U.; Afzal, M.; Lee, S. A Multimodal Deep Log-Based User Experience (UX) Platform for UX Evaluation. Sensors 2018, 18, 1622. [Google Scholar] [CrossRef] [PubMed]
- Franco, R.Y.D.S.; De Freitas, A.A.; Lima, R.S.D.A.D.; Mota, M.P.; dos Santos, C.G.R.; Meiguins, B.S. UXmood—A Tool to Investigate the User Experience (UX) Based on Multimodal Sentiment Analysis and Information Visualization (InfoVis). In Proceedings of the 2019 23rd International Conference Information Visualisation (IV), Paris, France, 2–5 July 2019; pp. 175–180. [Google Scholar] [CrossRef]
- Sivaji, A.; Ahmad, W.F.W. Benefits of Complementing Eye-Tracking Analysis with Think-Aloud Protocol in a Multilingual Country with High Power Distance. In Current Trends in Eye Tracking Research; Springer: Cham, Switzerland, 2014; pp. 267–278. [Google Scholar] [CrossRef]
- Dixit, S.; Padmadas, V. Automated Usability Evaluation of Web Applications. In Proceedings of the International Congress on Information and Communication Technology, Singapore, 26–29 November 2016; pp. 139–149. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Tzafilkou, K.; Protogeros, N. Diagnosing user perception and acceptance using eye tracking in web-based end-user development. Comput. Hum. Behav. 2017, 72, 23–37. [Google Scholar] [CrossRef]
- Moro, R.; Daraz, J.; Bielikova, M. Visualization of Gaze Tracking Data for UX Testing on the Web. In Proceedings of the Late-breaking Results, Doctoral Consortium and Workshop Proceedings of the 25th ACM Hypertext and Social Media Conference, Santiago, Chile, 1–4 September 2014. [Google Scholar]
- Barnum, C.M. Usability Testing Essentials: Ready, Set… Test! 2nd ed.; Morgan Kaufman: Cambridge, MA, USA, 2020. [Google Scholar]
- Gardner, J. Remote Web Site Usability Testing—Benefits Over Traditional Methods. Int. J. Public Inf. Syst. 2007, 3, 63–73. [Google Scholar]
- Peres, S.C.; Pham, T.; Phillips, R. Validation of the System Usability Scale (SUS). Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2013, 57, 192–196. [Google Scholar] [CrossRef]
- Reeves, S. How UX Practitioners Produce Findings in Usability Testing. ACM Trans. Comput. Interact. 2019, 26, 1–38. [Google Scholar] [CrossRef]
- Jabbar, J.; Urooj, I.; JunSheng, W.; Azeem, N. Real-time Sentiment Analysis On E-Commerce Application. In Proceedings of the IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, 9–11 May 2019; pp. 391–396. [Google Scholar] [CrossRef]
- Nielsen, J. Why You Only Need to Test with 5 Users. Available online: https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/ (accessed on 18 October 2022).
- Sivaji, A.; Tzuaan, S.S. Website user experience (UX) testing tool development using Open Source Software (OSS). In Proceedings of the Southeast Asian Network of Ergonomics Societies Conference (SEANES), Langkawi, Malaysia, 9–12 July 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Chin, J.P.; Diehl, V.A.; Norman, K.L. Development of an instrument measuring user satisfaction of the human-computer interface. In Proceedings of the SIGCHI ‘88, Washington, DC, USA, 15–19 May 1998; pp. 213–218. [Google Scholar] [CrossRef]
- Claridge, N.; Kirakowski, J. WAMMI: Website Analysis and Measurement Inventory Questionnaire. Available online: http://www.wammi.com/index.html (accessed on 27 July 2022).
- Ceccacci, S.; Generosi, A.; Giraldi, L.; Mengoni, M. An Emotion Recognition System for monitoring Shopping Experience. In Proceedings of the 11th Pervasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–29 June 2018; pp. 102–103. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef]
- Ekman, P. Basic Emotions. In Handbook of Cognition and Emotions; John Wiley & Sons: Sussex, UK, 1999. [Google Scholar]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-Visual Emotion Recognition in Video Clips. IEEE Trans. Affect. Comput. 2017, 10, 60–75. [Google Scholar] [CrossRef]
- Barrett, L.F.; Adolphs, R.; Marsella, S.; Martinez, A.M.; Pollak, S.D. Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements. Psychol. Sci. Public Interes. 2019, 20, 1–68. [Google Scholar] [CrossRef] [PubMed]
- Kaur, H.; McDuff, D.; Williams, A.C.; Teevan, J.; Iqbal, S.T. “I Didn’t Know I Looked Angry”: Characterizing Observed Emotion and Reported Affect at Work. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 29 April–5 May 2022. [Google Scholar] [CrossRef]
- Noordewier, M.K.; Breugelmans, S.M. On the valence of surprise. Cogn. Emot. 2013, 27, 1326–1334. [Google Scholar] [CrossRef]
- Basu, S.; Bag, A.; Aftabuddin, M.; Mahadevappa, M.; Mukherjee, J.; Guha, R. Effects of emotion on physiological signals. In Proceedings of the 2016 IEEE Annual India Conference (INDICON), Bangalore, India, 16–18 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Alhagry, S.; Aly, A.; El-Khoribi, R. Emotion Recognition based on EEG using LSTM Recurrent Neural Network. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 081046. [Google Scholar] [CrossRef]
- Athavipach, C.; Pan-Ngum, S.; Israsena, P. A Wearable In-Ear EEG Device for Emotion Monitoring. Sensors 2019, 19, 4014. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-Based Gaze Estimation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015; pp. 1–10. [Google Scholar]
- Fu, B.; Noy, N.F.; Storey, M.-A. Eye tracking the user experience—An evaluation of ontology visualization techniques. Semant. Web 2016, 8, 23–41. [Google Scholar] [CrossRef]
- De Bleecker, I.; Okoroji, R. Remote Usability Testing: Actionable Insights in User Behavior across Geographies and Time Zones; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Lewis, J.R. Usability: Lessons Learned … and Yet to Be Learned. Int. J. Hum.-Comput. Interact. 2014, 30, 663–684. [Google Scholar] [CrossRef]
- Alhadreti, O. A Comparison of Synchronous and Asynchronous Remote Usability Testing Methods. Int. J. Human-Computer Interact. 2021, 38, 289–297. [Google Scholar] [CrossRef]
- Plaza, B. Google Analytics for measuring website performance. Tour. Manag. 2011, 32, 477–481. [Google Scholar] [CrossRef]
- User Research & UX Testing Solution. Available online: https://www.userzoom.com/ (accessed on 24 February 2022).
- Validately. Available online: https://faq.validately.com/hc/en-us (accessed on 24 February 2022).
- The Human Insight Platform. Available online: https://www.usertesting.com/ (accessed on 24 February 2022).
- Remote User Testing Platform. Available online: https://www.userlytics.com (accessed on 24 February 2022).
- Website Heatmaps & Behavior Analytics Tools. Available online: https://www.hotjar.com (accessed on 24 February 2022).
- Celebrating 20 Years—Global Leader in Eye Tracking. Available online: https://www.tobii.com/ (accessed on 24 February 2022).
- Generosi, A.; Ceccacci, S.; Faggiano, S.; Giraldi, L.; Mengoni, M. A Toolkit for the Automatic Analysis of Human Behavior in HCI Applications in the Wild. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 185–192. [Google Scholar] [CrossRef]
- King, D.E. Dlib-ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar] [CrossRef]
- Talipu, A.; Generosi, A.; Mengoni, M.; Giraldi, L. Evaluation of Deep Convolutional Neural Network architectures for Emotion Recognition in the Wild. In Proceedings of the 2019 IEEE 23rd International Symposium on Consumer Technologies (ISCT), Ancona, Italy, 19–21 June 2019; pp. 25–27. [Google Scholar] [CrossRef]
- Ceccacci, S.; Mengoni, M.; Andrea, G.; Giraldi, L.; Carbonara, G.; Castellano, A.; Montanari, R. A Preliminary Investigation Towards the Application of Facial Expression Analysis to Enable an Emotion-Aware Car Interface. In International Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2020; pp. 504–517. [Google Scholar] [CrossRef]
- Ceccacci, S.; Generosi, A.; Cimini, G.; Faggiano, S.; Giraldi, L.; Mengoni, M. Facial coding as a mean to enable continuous monitoring of student’s behavior in e-Learning. In Proceedings of the CEUR Workshop Proceedings, Foggia, Italy, 21–22 January 2021. [Google Scholar]
- Koonsanit, K.; Nishiuchi, N. Classification of User Satisfaction Using Facial Expression Recognition and Machine Learning. In Proceedings of the 2020 IEEE REGION 10 CONFERENCE (TENCON), Osaka, Japan, 16–19 November 2020; pp. 561–566. [Google Scholar] [CrossRef]
- Landowska, A.; Miler, J. Limitations of emotion recognition in software user experience evaluation context. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016. [Google Scholar]
- Available online: https://justadudewhohacks.github.io/face-api.js/docs/index.html (accessed on 22 April 2022).














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Generosi, A.; Villafan, J.Y.; Giraldi, L.; Ceccacci, S.; Mengoni, M. A Test Management System to Support Remote Usability Assessment of Web Applications. Information 2022, 13, 505. https://doi.org/10.3390/info13100505
Generosi A, Villafan JY, Giraldi L, Ceccacci S, Mengoni M. A Test Management System to Support Remote Usability Assessment of Web Applications. Information. 2022; 13(10):505. https://doi.org/10.3390/info13100505
Chicago/Turabian StyleGenerosi, Andrea, José Yuri Villafan, Luca Giraldi, Silvia Ceccacci, and Maura Mengoni. 2022. "A Test Management System to Support Remote Usability Assessment of Web Applications" Information 13, no. 10: 505. https://doi.org/10.3390/info13100505
APA StyleGenerosi, A., Villafan, J. Y., Giraldi, L., Ceccacci, S., & Mengoni, M. (2022). A Test Management System to Support Remote Usability Assessment of Web Applications. Information, 13(10), 505. https://doi.org/10.3390/info13100505