1. Introduction
Injection molding is considered the most significant technology for processing plastic material which is heavily used in industries. The production of plastic-based goods or components in the world through the injection molding process has approximately reached up to 30% [
1]. Injection mold-based products are either semifinal parts or final parts of any kind of product [
2]. We can take, for example, the production of a smartphone case or interior components of an aircraft. The injection molding industry can be considered a basic industry since it supplies the spare parts required for a production process in other industries [
3]. In this case, injection mold-based products are either semifinal parts or final parts of any kind of product and intensively used in various industries from households, electronics, and even automobiles. Another reason for the intensive use of injection molding is its ability to process a large amount of plastic material for producing complex shapes [
4]. Hence, the injection molding approach is considered a suitable production technique for the mass production of plastic parts which require precise dimensions.
There are three basic phases in the injection molding process, namely, filling, holding, and cooling [
5]. At first, the molten plastic material is filled into the cavity to make the required shape of the product. Afterward, extra material is packed into the cavity to raise the pressure on the holding stage. Finally, in the cooling phase, the temperature will be lowered significantly to solidify the molten materials. The final stage guarantees that the product of the molding process is stable enough for the ejection process. The product of the injection molding process is considered acceptable when it does not contain any defects [
6]. Nevertheless, due to the complexity of the thermoviscoelastic character of plastic material, maintaining quality during the injection molding process is difficult. The unpredictable behavioral change in injection molding factors commonly cause defective final products [
7]. Obviously, the delivery of a defective product to the customer would decrease customer satisfaction.
The types of defects in injection molding products can be classified into several categories, namely, shrinkage and warpage, short-shot, and sink mark. This research addresses the short-shot defect in the injection molding of plastic material. The different types of defects are caused by different factors which influence the injection molding process. In the case of a short-shot defect, it usually occurs during the filling process, when the material injected into the mold is not sufficient enough to fill up the cavity [
8]. Several factors lead to the occurrence of the short-shot defect such as incorrect selection of plastic materials, the wrong configuration of processing parameters, etc. [
9]. Among other factors, the ones which can be controlled by the operator and can be adjusted during the process are the processing parameters, which generally consist of pressure, temperature, and processing time [
10].
A product of the appropriate quality requires precise combinations of input process conditions. To determine the configuration of the process condition, a trial-and-error approach has frequently been utilized in manufacturing facilities that use the injection molding process [
11]. However, the trial-and-error approach involves a lot of uncertainty, requires a lot of time and money, and heavily relies on molding workers’ experience. Hence, traditional quality control based on the injection molding machine’s parameters has limitations that result in inaccurate assessments of the part quality [
12]. To solve this problem, the early approach used computer-assisted engineering (CAS) to control the process parameter of injection molding. The use of computer-aided engineering (CAE) can be applied to simulate and investigate the effects of different configurations of injection molding parameters on the quality of the final mold product [
13]. Hence, the parameters of the simulation model which yield the best result can be further used to optimize the real process of injection molding [
14]. Nevertheless, the CAE approach for optimizing injection molding parameters required a lot of time and incorporated many prerequisite criteria of the material properties [
15].
The employment of a CAE-based approach for simulating injection molding provides better results compared with the traditional approach. Nevertheless, CAE simulation failed to deal with the nonlinearity of the viscoelastic character of plastic material [
16]. Hence, there is a need for a more sophisticated approach to improve the quality prediction of the injection molding process. In recent years, there has been an increasing amount of work on implementing a data-driven approach using machine learning technology in the manufacturing domain, including the process of injection molding [
17,
18]. Those works were motivated by the development of sensing technology which is widely applied in manufacturing. The installment of a sensor within an injection molding machine generates valuable data to investigate the behavioral changes during the molding process which can be used to predict the final output [
3,
19]. Another AI-based approach by using computer vision was also developed for injection molding process inspection and monitoring [
20]. In that research, the computer vision algorithm was deployed to detect any kind of defect. There are several distinct approaches of machine learning applied to the injection molding process. Among those approaches, the artificial neural network (ANN)-based method is the most popular since it yields significantly higher performance compared with others [
17]. For instance, the multi-layered perceptron (MLP) architecture of ANN, which was developed by Ke and Huang [
21], reaches 94% accuracy in predicting the defective/non-defective output of the molding process.
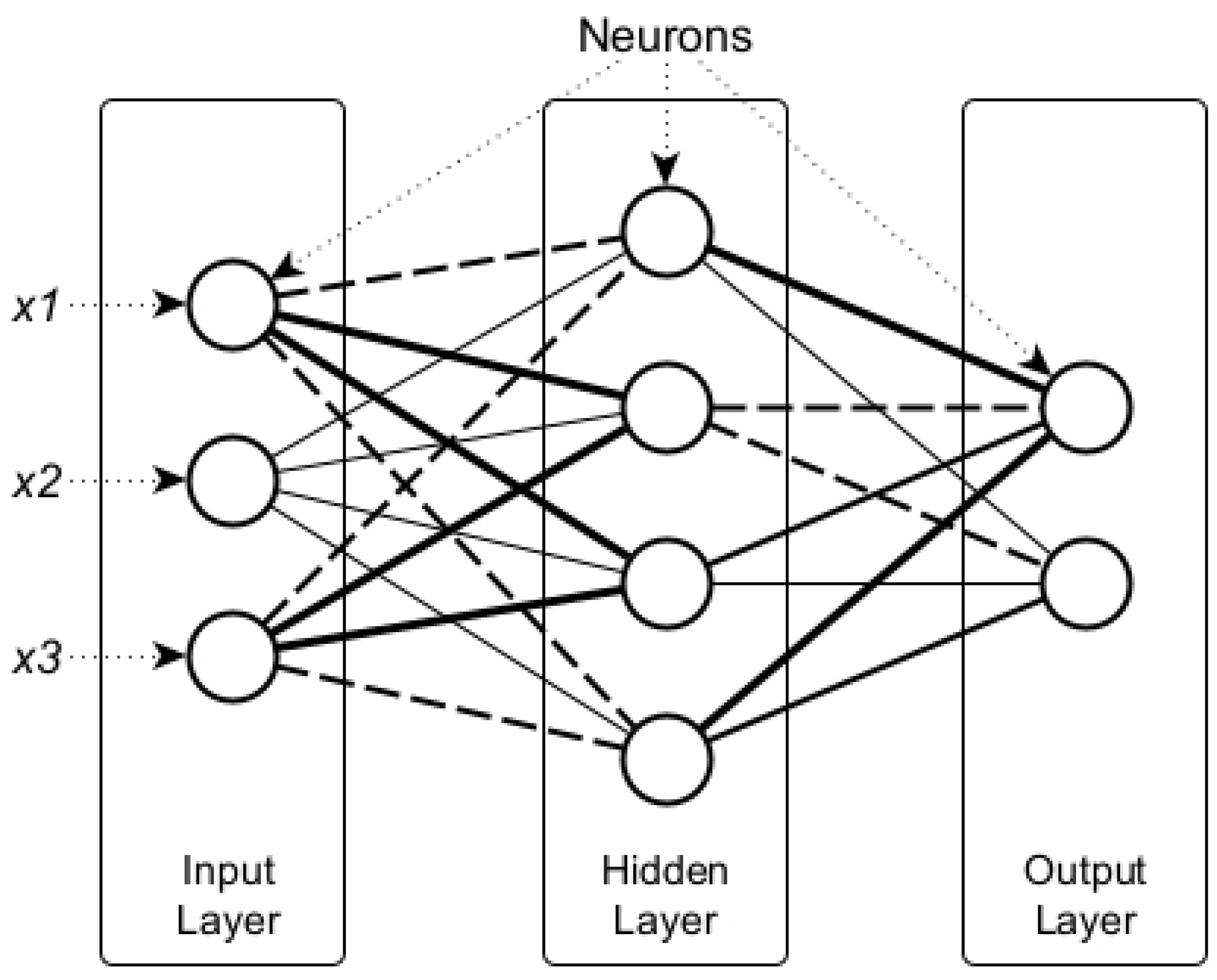
The ANN-based approach which currently outperforms other machine learning techniques is mainly due to its ability to identify complex nonlinearity relationships within the dataset [
21]. Therefore, in the case of injection molding, the relationship of process parameters such as mold temperature, pressure, and cycle time with their corresponding output can be modeled and optimized by using ANN [
22]. Nevertheless, modeling the nonlinearity within the data commonly leads to the complexity of the ANN itself. The increasing complexity of the ANN model is identified by the increasing number of hidden layers and neurons which represent more nonlinearity within the dataset. The complexity of the ANN model makes it well known as a “black box” model [
23]. Despite the great success of ANN, the concern of a black box system has also received higher concern over time [
24,
25]. Black box interpretation prevents people from gaining understandable knowledge, which is essential for improving engineering design [
26]. In terms of the injection molding process, having a better understanding of what factors have significant influence on the final results would give an advantage to the design of a better molding machine or technology.
Some studies have tried to infer significant process parameters of injection molding from the machine learning model. Zhou et al. [
27] used an unsupervised approach named sparse autoencoder to cluster the learned parameter within the neural network training of various configuration injection molding experiments. Another study by Román et al. [
28] used the Bayesian approach to optimize the parameter selection of deep neural network training for the defect prediction model of the injection molding surface. The developed model has successfully selected the parameter which yields the optimal model. A similar approach was proposed by Gim and Lee [
29] by using interpretable machine-learning techniques to explain the significance of each injection molding parameter. A more innovative approach was deployed by using a transfer learning mechanism [
30]. In that research, they deployed the deep neural network model which was successfully developed for another type of injection molding in their current experiment.
Regarding the efforts to develop better injection molding systems, there is much research that investigates the influential parameters of the molding process. Some researchers argued that cavity pressure has a significant parameter on the quality of injection molded products [
31,
32,
33]. For instance, in an experiment conducted by Chen et al. [
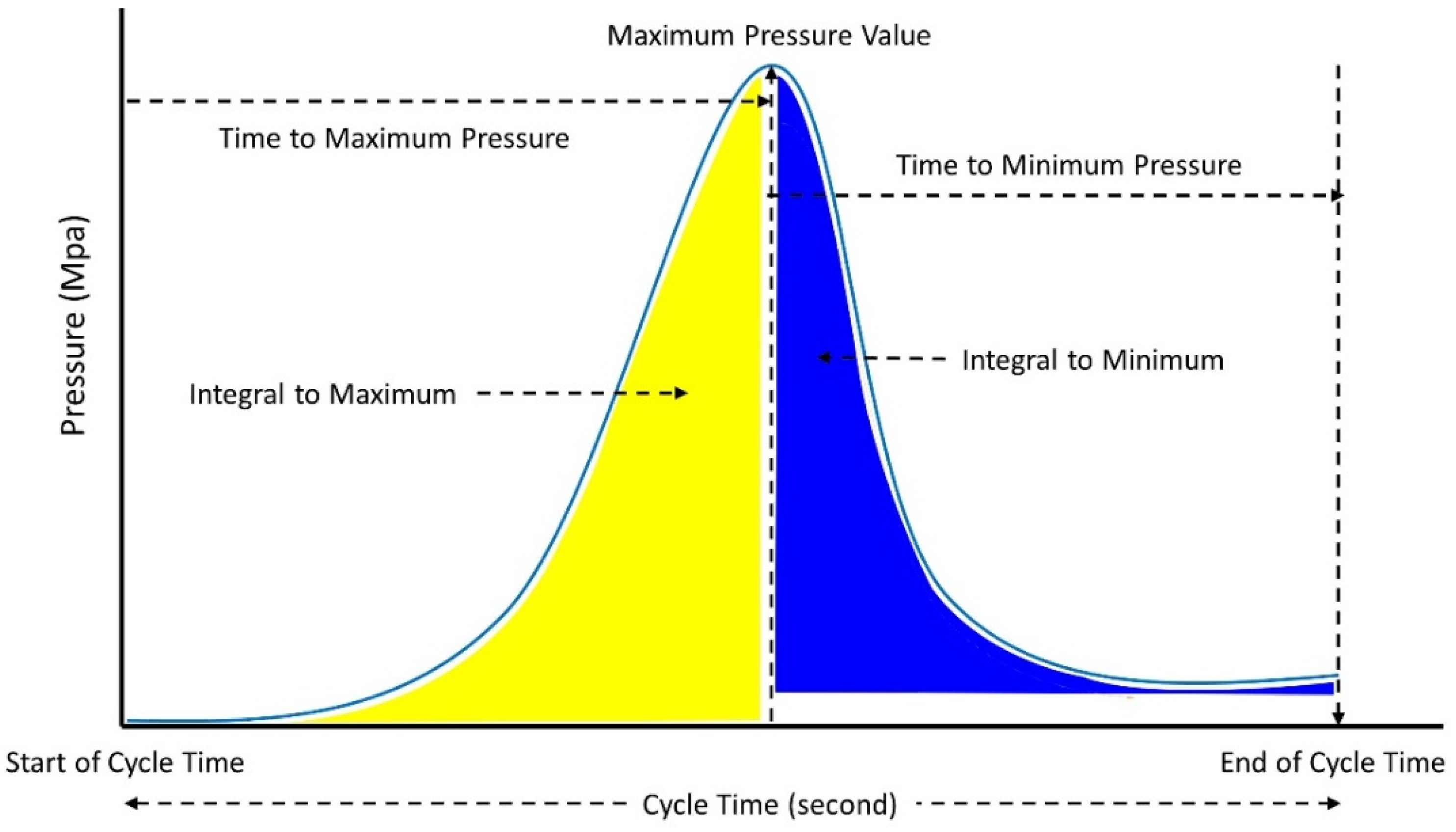
34], four cavity pressures, named peak pressure, gradient pressure, viscosity index, and energy index, were used to estimate the quality of injection molding output. In addition, Gim and Rhee [
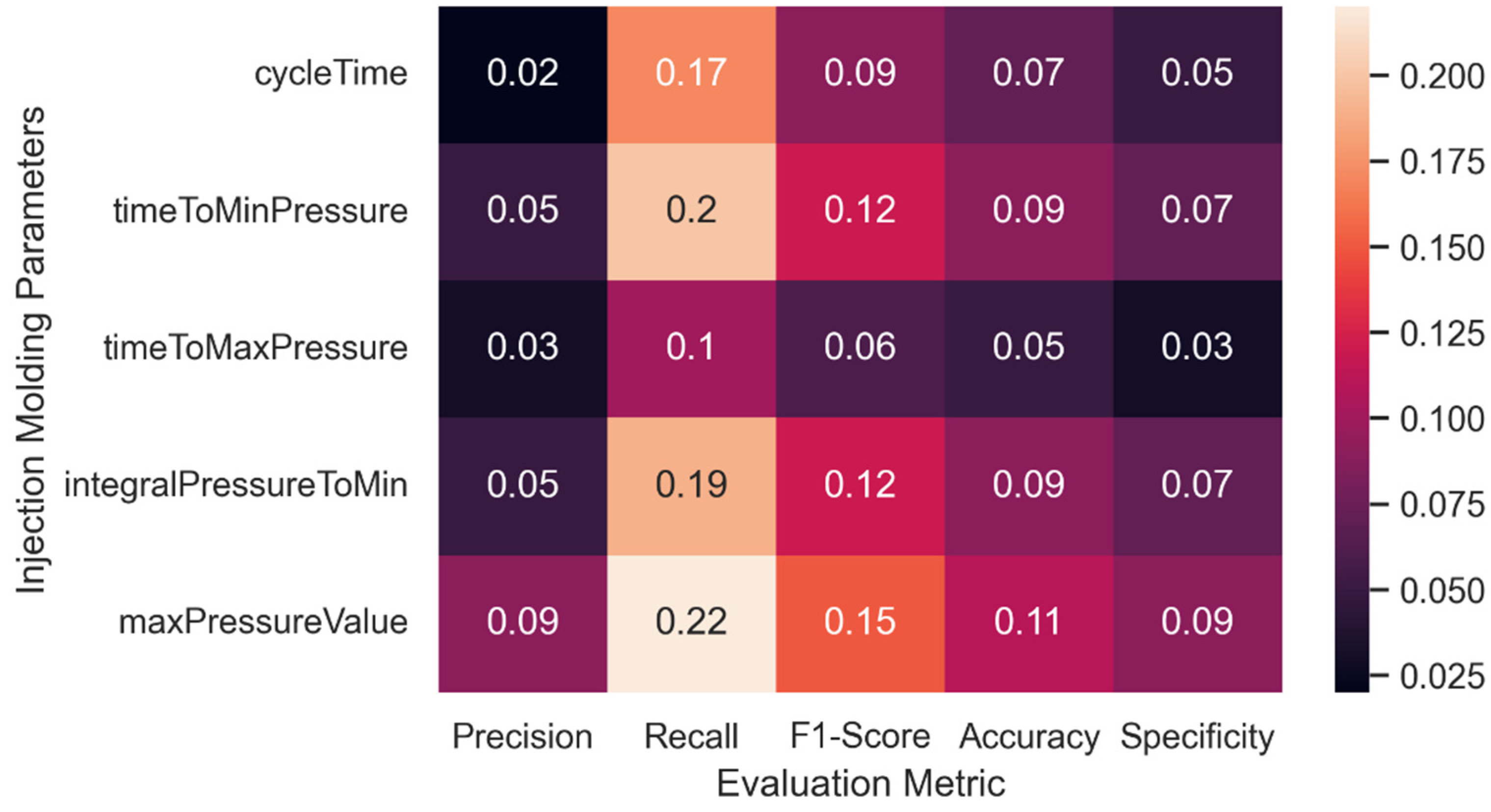
29] extracted five parameters from cavity pressure: initial pressure, maximum pressure, the integral value of pressure changes from the initial to the end of the process, final pressure at the filling stage, and final pressure from the cooling stage. Nevertheless, the determination of significant parameters is a difficult task which leads to the question of which parameters should be extracted from cavity pressure for accurate prediction [
15].
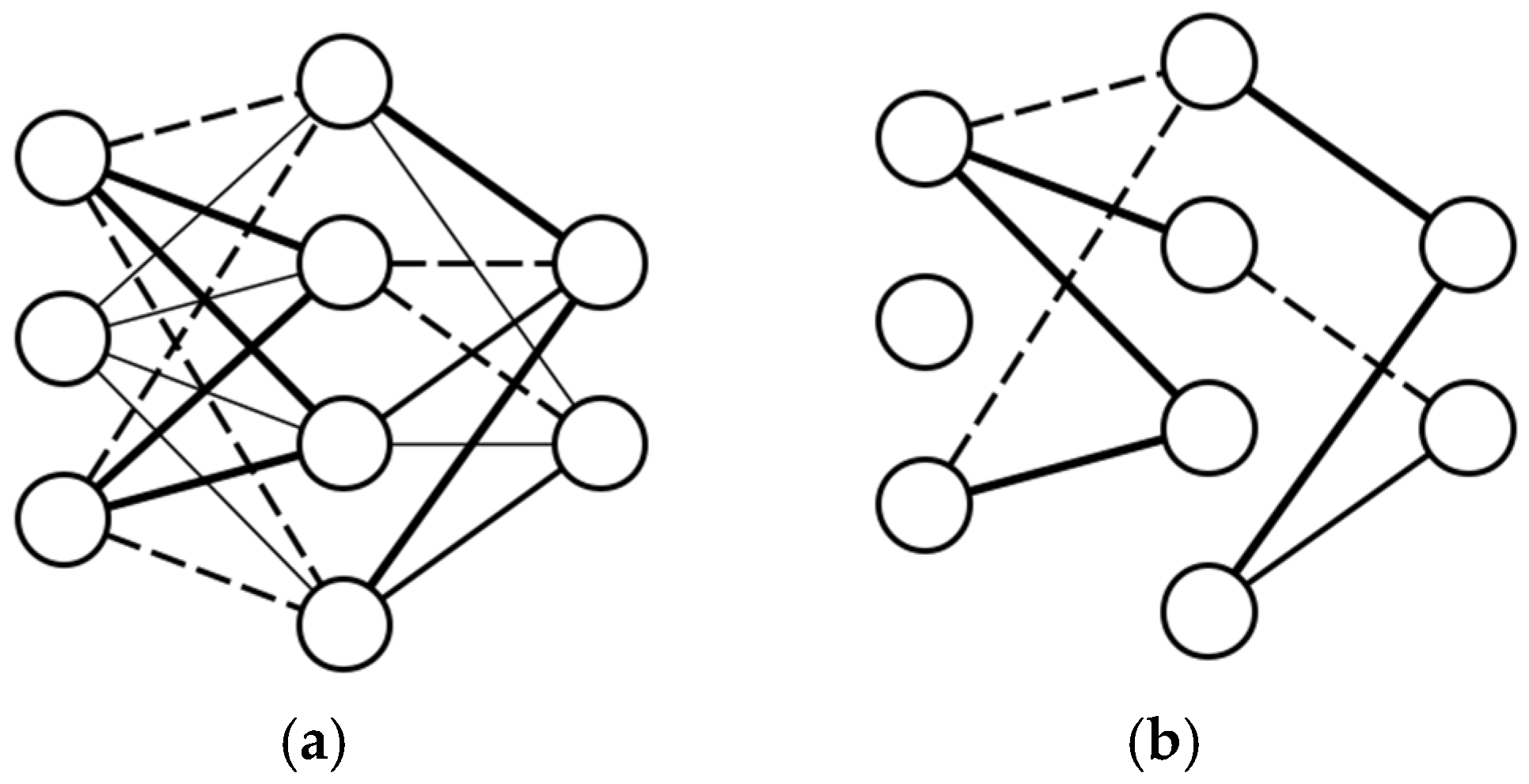
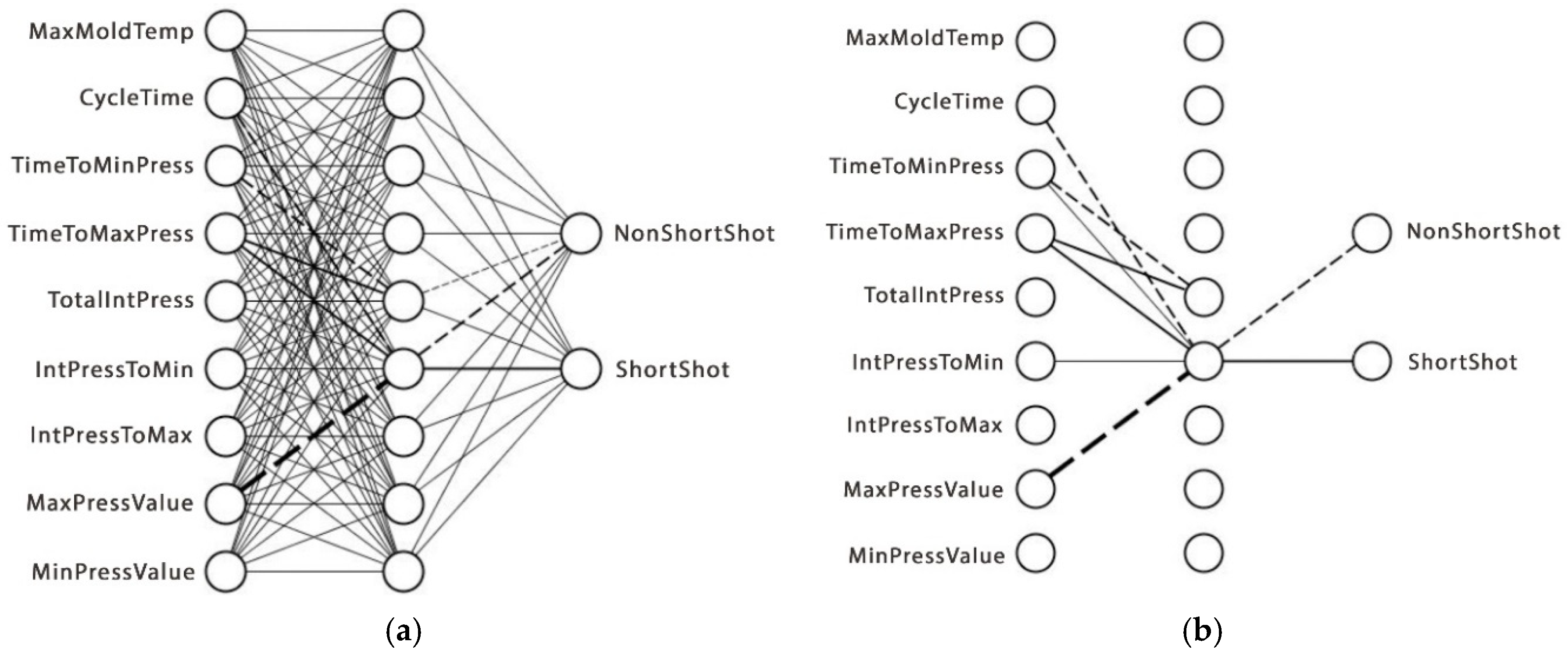
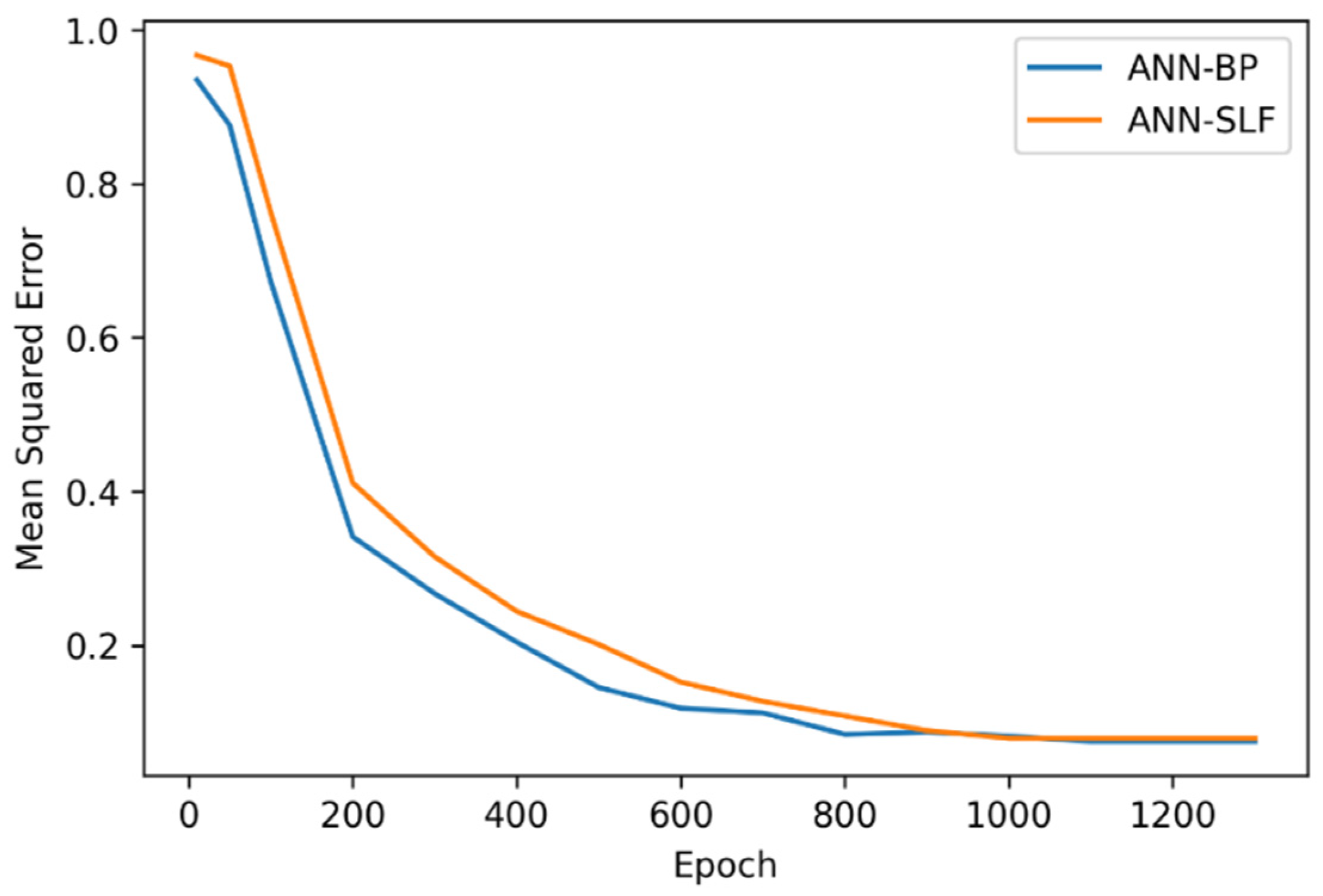
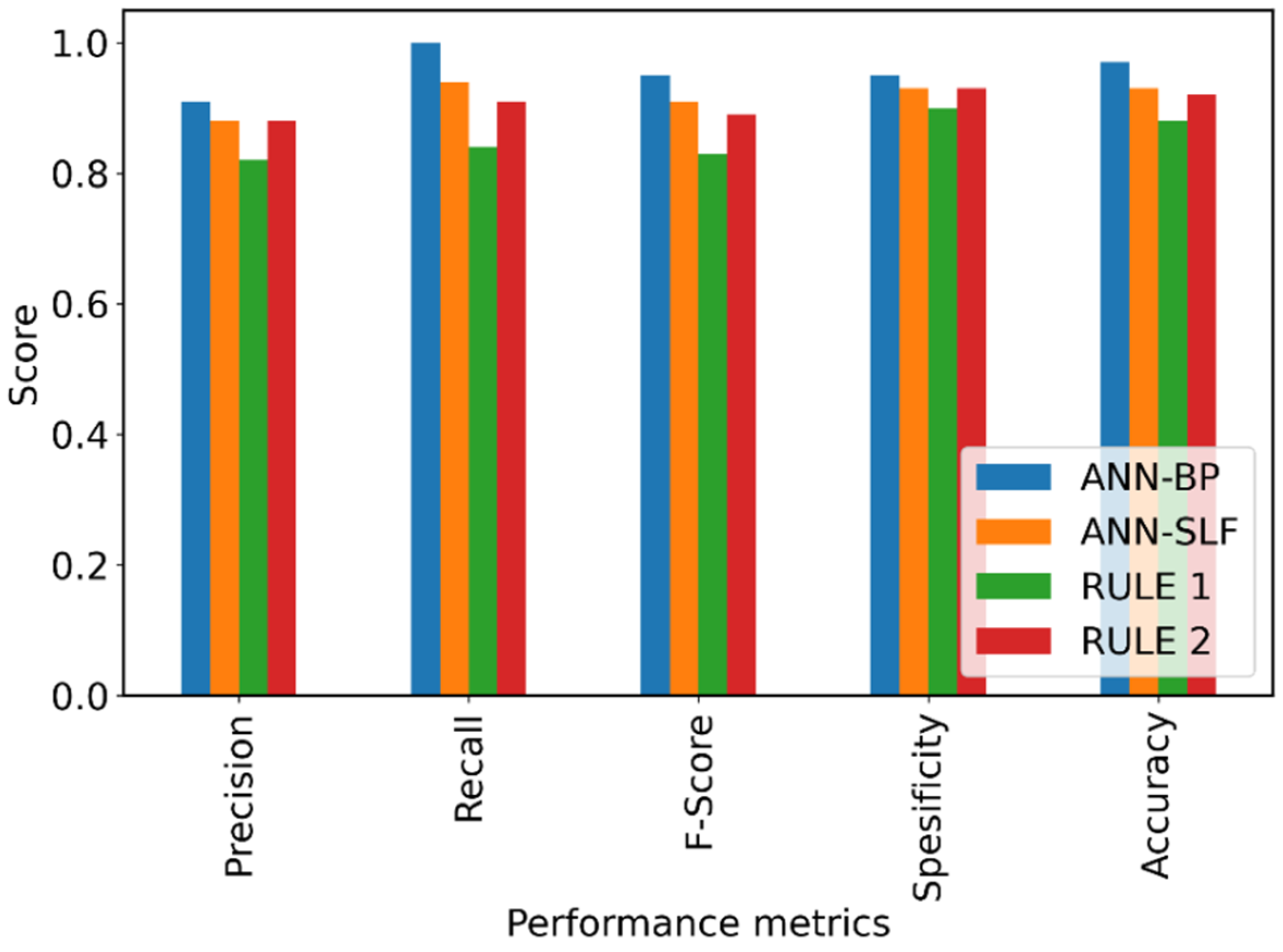
This experiment aims to provide an innovative approach to analyzing the significant attributes of the injection molding process by increasing the visibility of the ANN model. Since the ANN model has a good performance for injection molding quality prediction, reducing its model complexity without losing its performance hypothetically could reveal the injection molding variables as the input of the ANN model has the most significant influence on the prediction results. In this paper, an algorithm named structural learning with forgetting (SLF) was employed to train the ANN architecture. Different from the typical backpropagation algorithm commonly used in ANN training, SLF produced a simpler ANN model compared with the fully distributed model representation of the backpropagation training result. Hence, by using SLF for training the ANN model, significant parameters of injection molding which are represented as the input layer of ANN architecture can be further analyzed. The contributions of the present study can be summarized as follows:
- (i).
We employed SLF to train the ANN model and generate a simpler model as well as to reveal the most significant attributes without any major degradation in prediction performance;
- (ii).
We further analyzed the selected attributes to investigate the linear correlation among those attributes by constructing rules and evaluating the performance of the rules for quality prediction;
- (iii).
We undertook in-depth experiments comparing the proposed model to other prediction models and findings from earlier research.
The remainder of this study is structured as follows. The dataset and detailed methods are presented in
Section 2, including ANN, SLF, and the evaluation method.
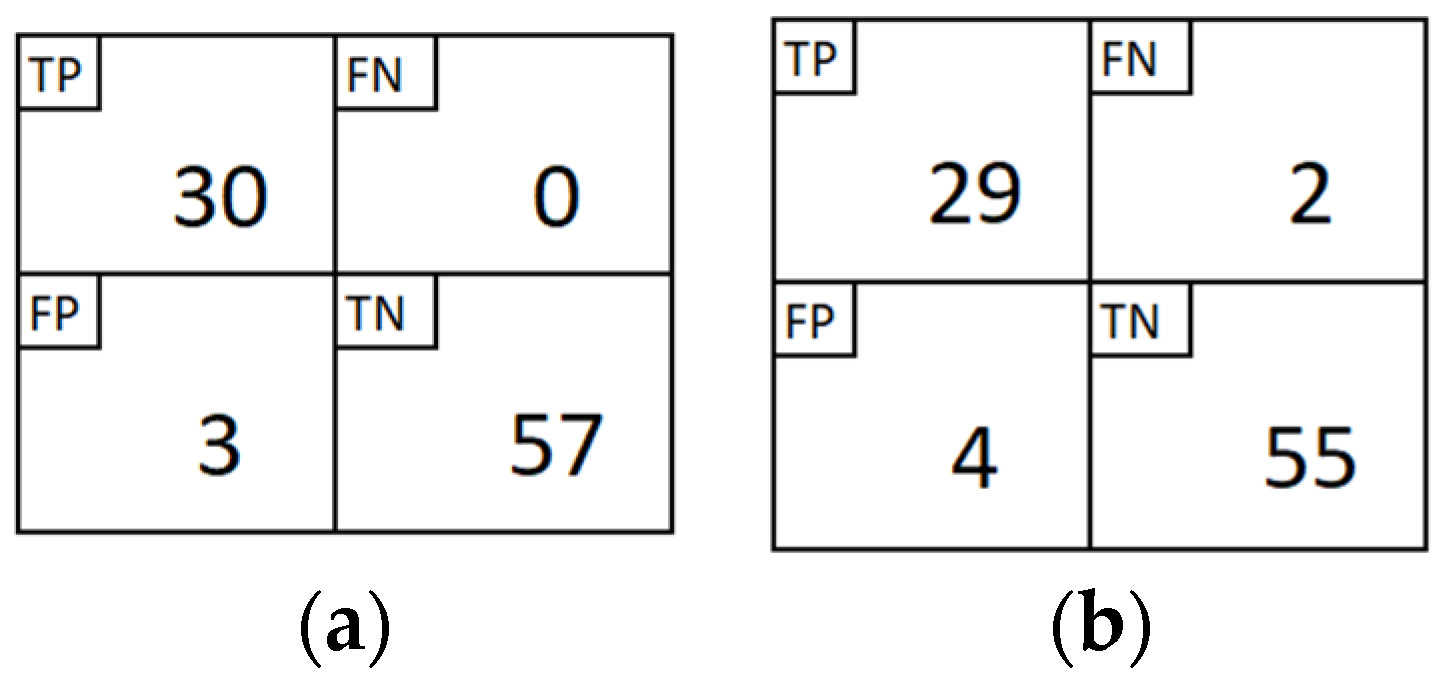
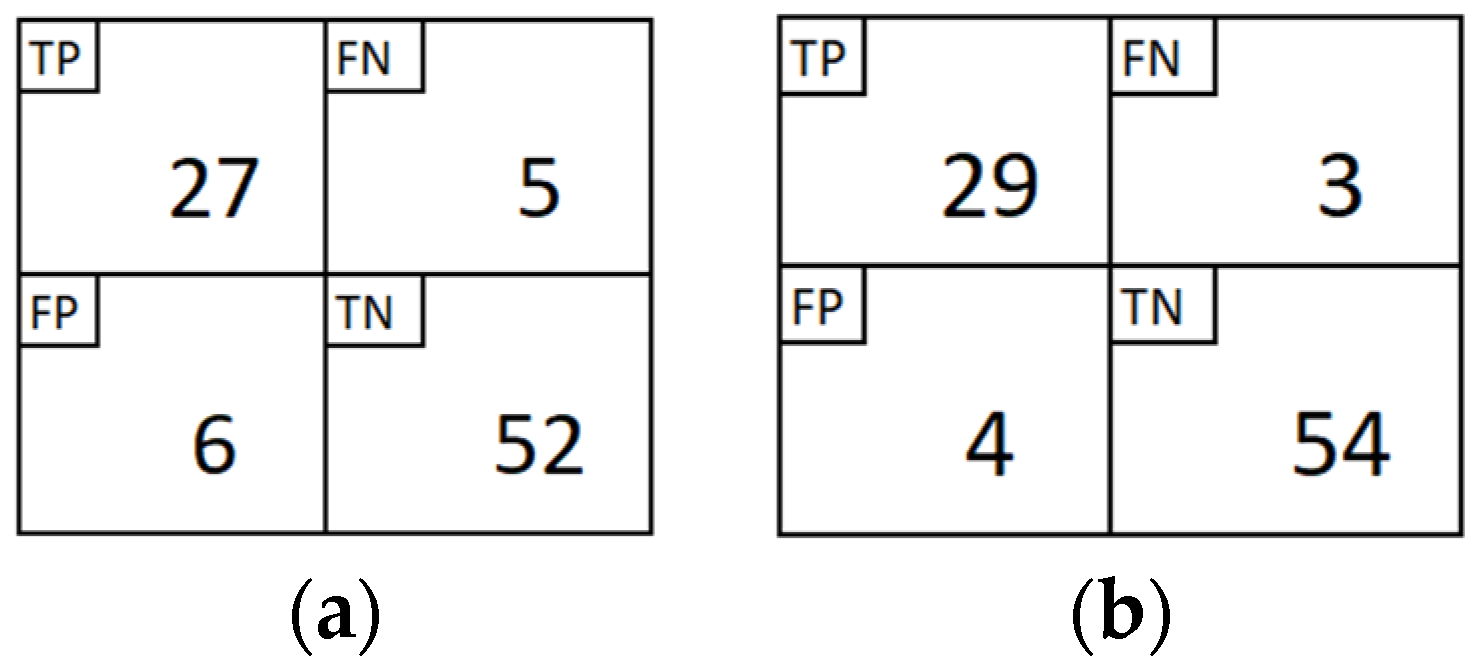
Section 3 provides comprehensive experimental results, parameter analysis with rule extraction, and comparison with earlier works.
Section 4 presents the conclusion, including future research directions. Finally, the list of acronyms and abbreviations used in this paper are provided in the Abbreviations section.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}