
CANet: A Combined Attention Network for Remote Sensing Image Change Detection


Abstract
:1. Introduction
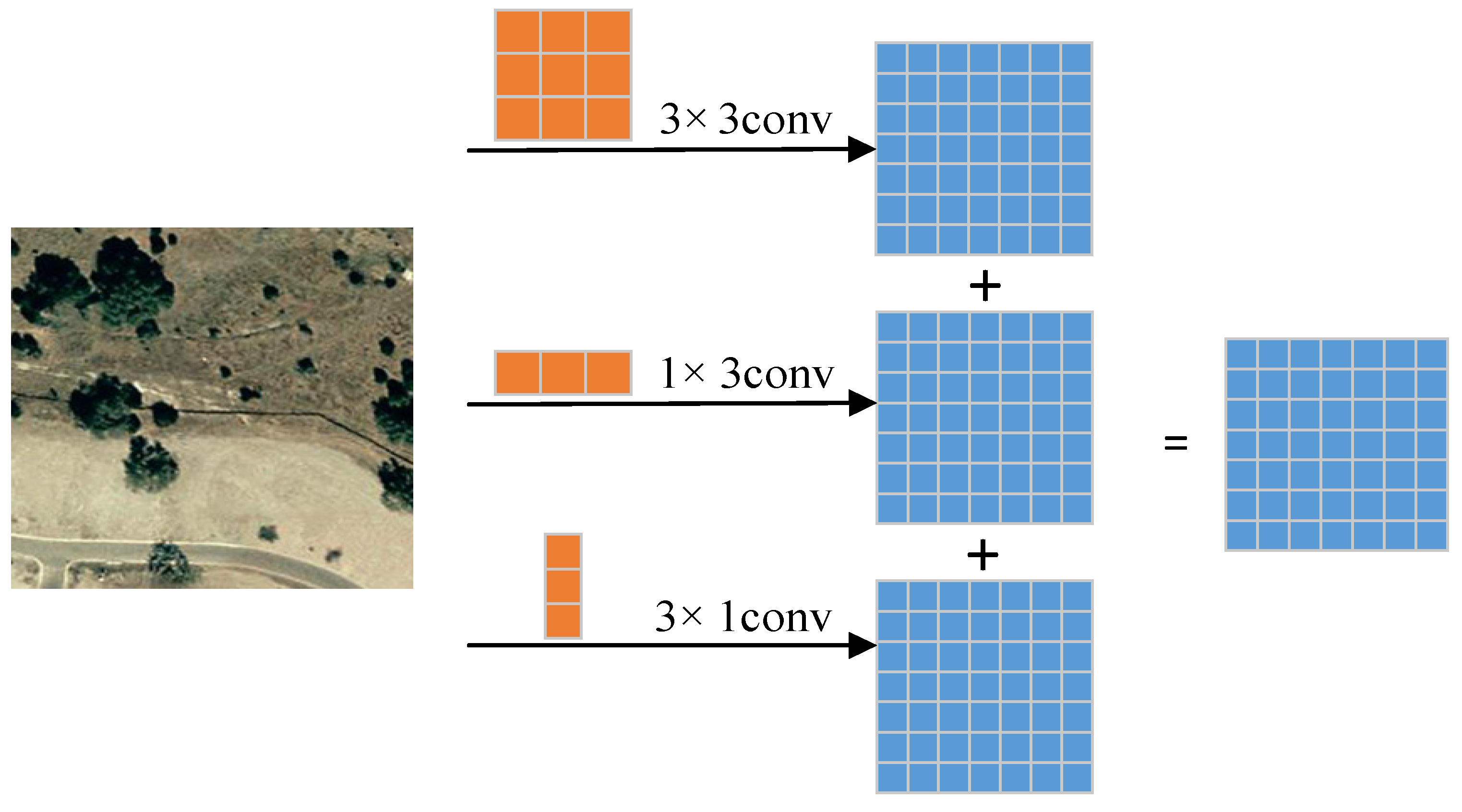
- We introduce an asymmetric convolution block (ACB) in our model. It contributes to the robustness of the model against rotation distortion, with a better generalization ability, without introducing additional hyperparameters and inference times;
- We propose a remote sensing image CD network, which is based on the combined attention and ACB. The CANet achieves state-of-the-art performance on widely used benchmarks, and it effectively alleviates the loss in localization information in the deep layers of convolutional networks.
2. Methodology
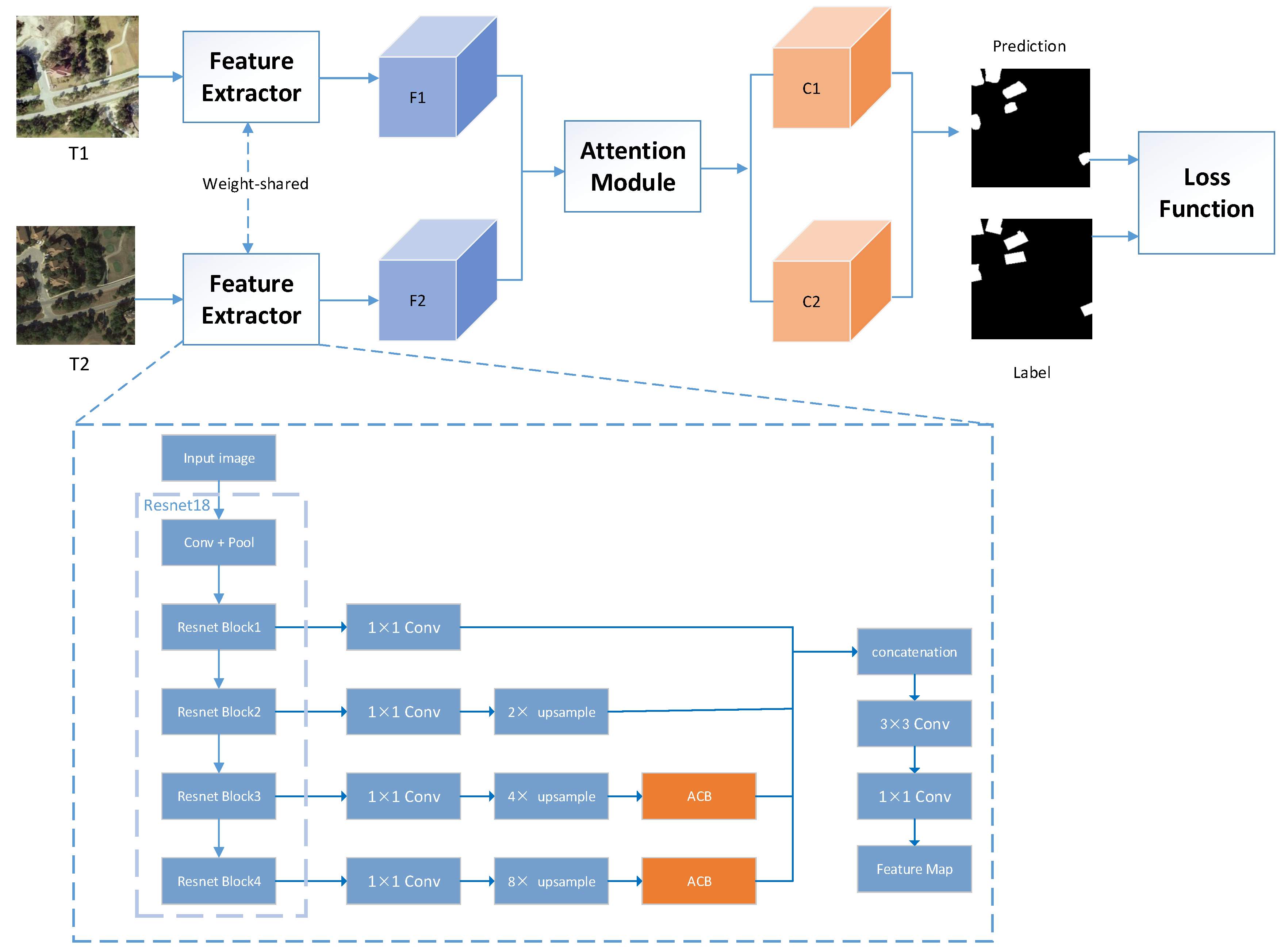
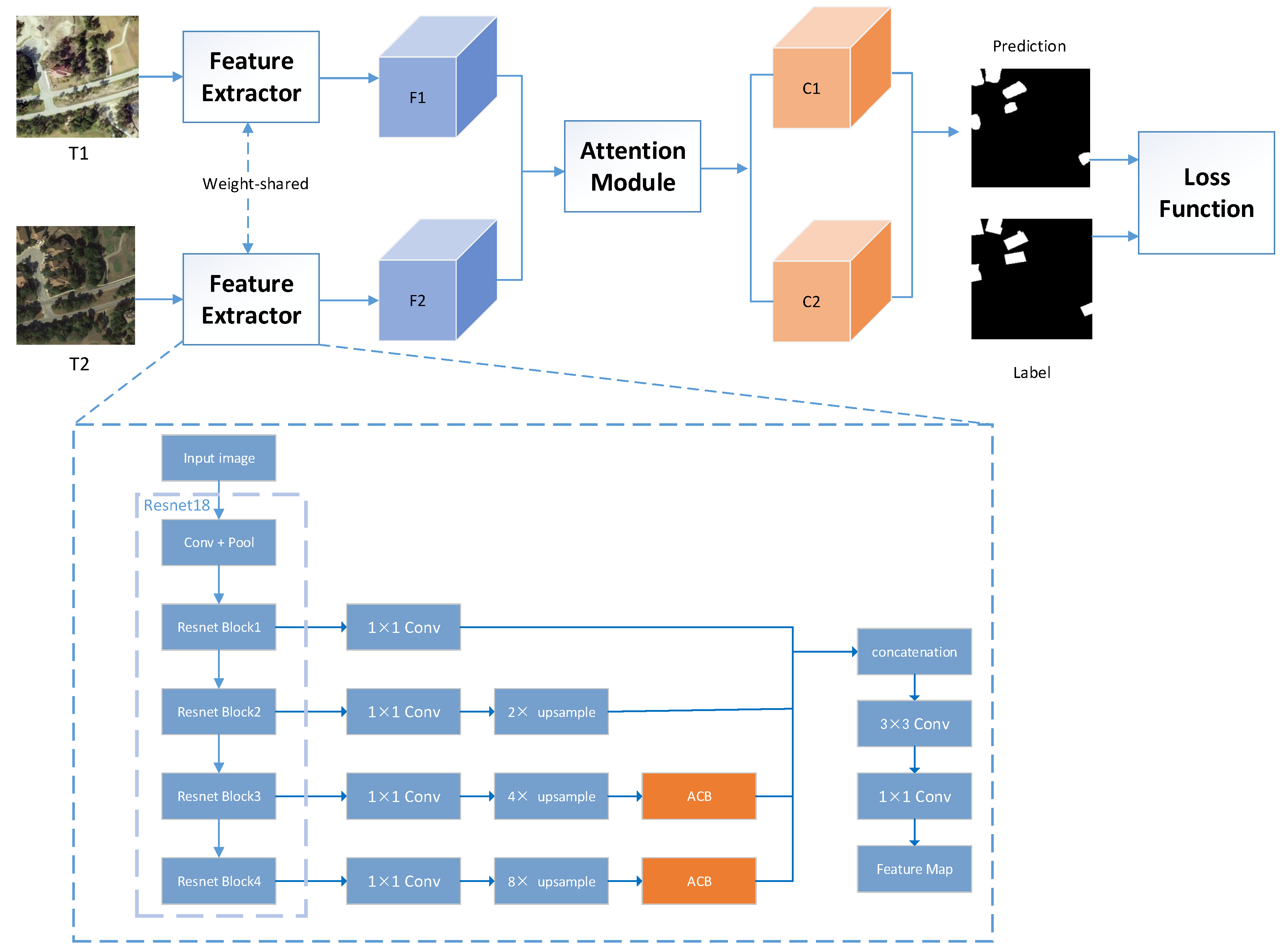
2.1. Overview
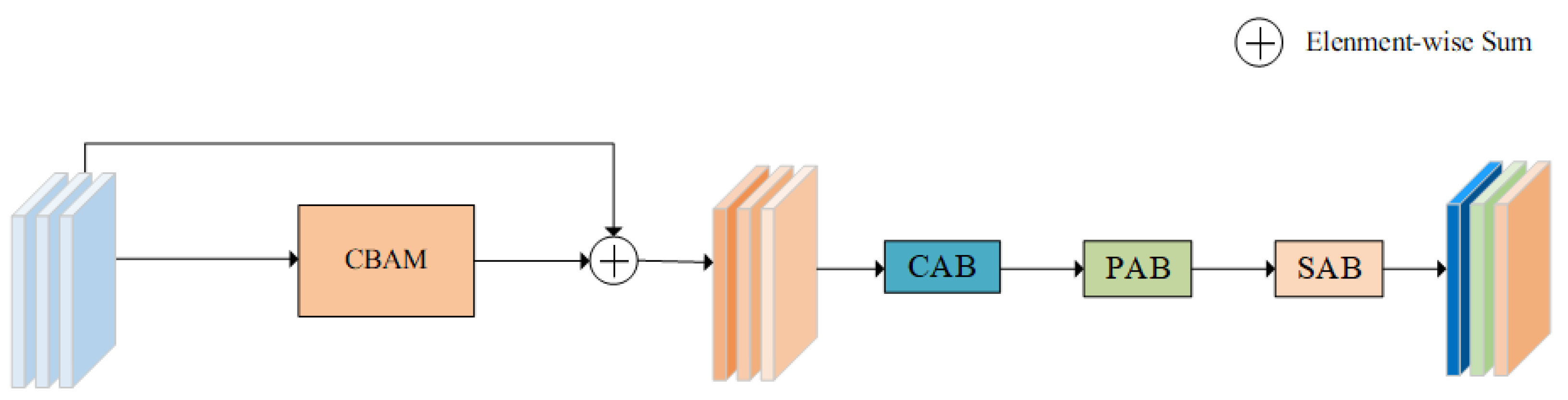
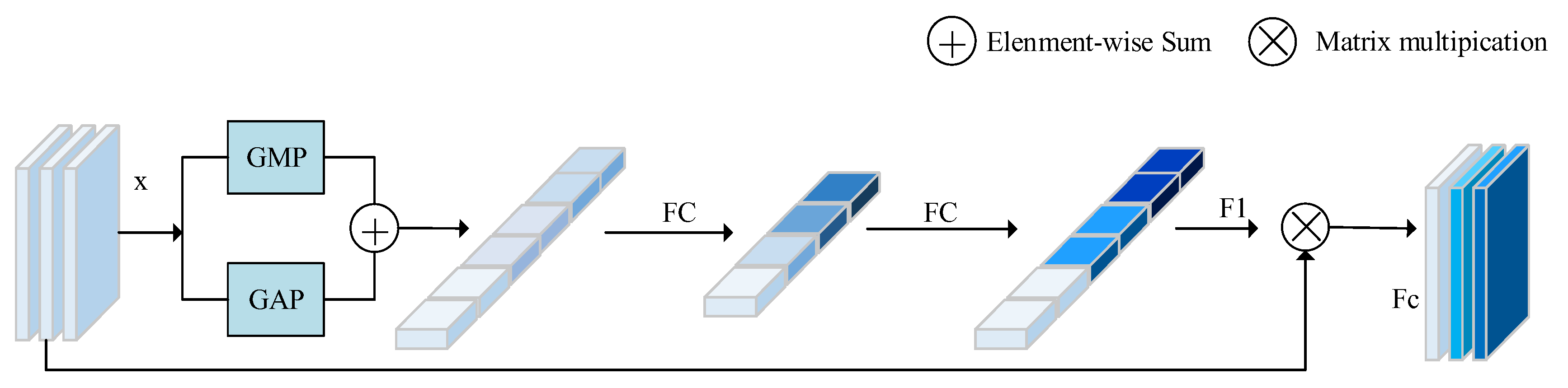
2.2. Combined Attention Module
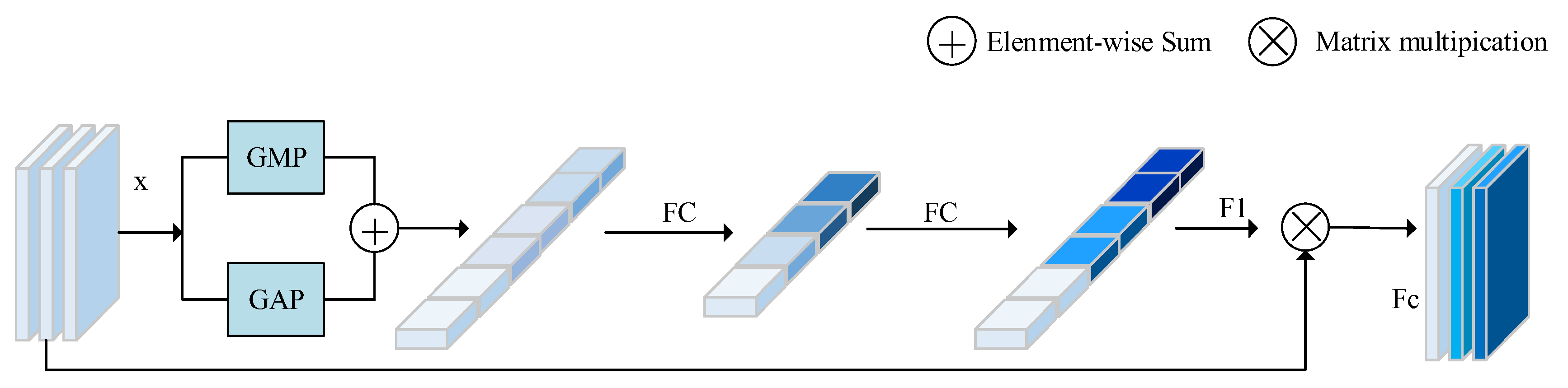
2.2.1. Channel Attention Block
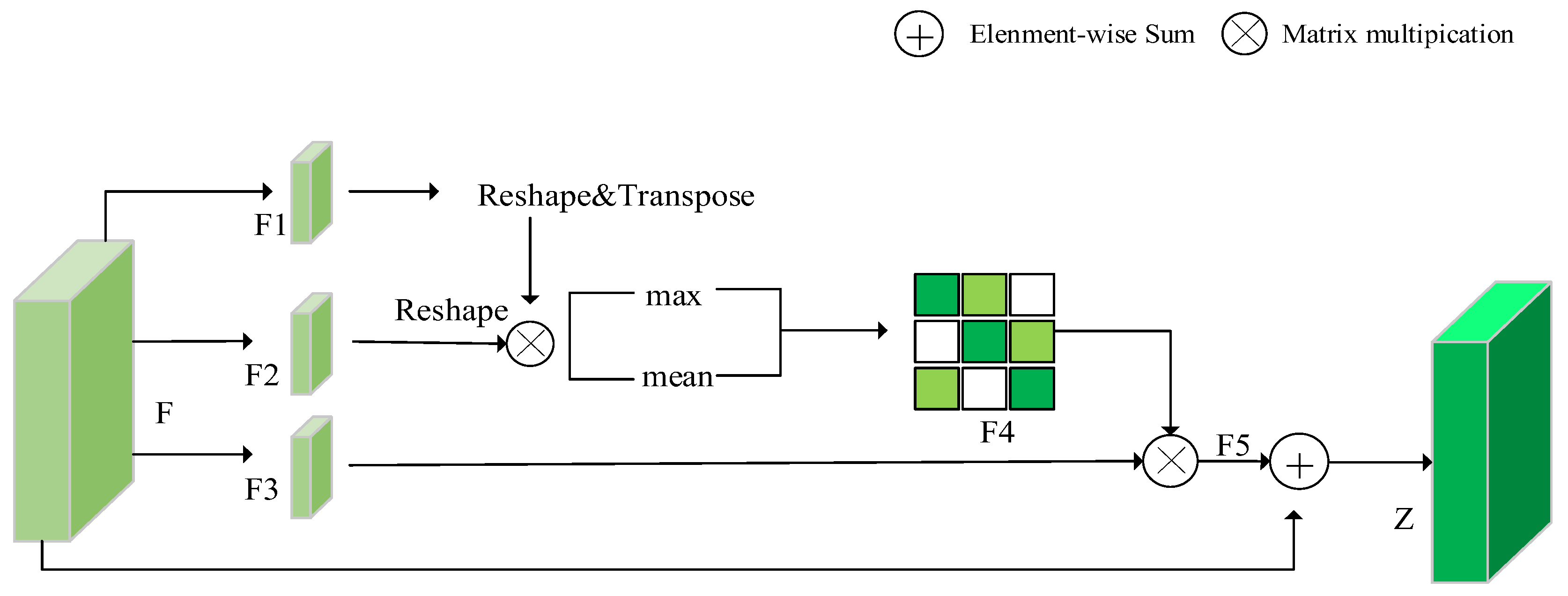
2.2.2. Spatial Attention Block
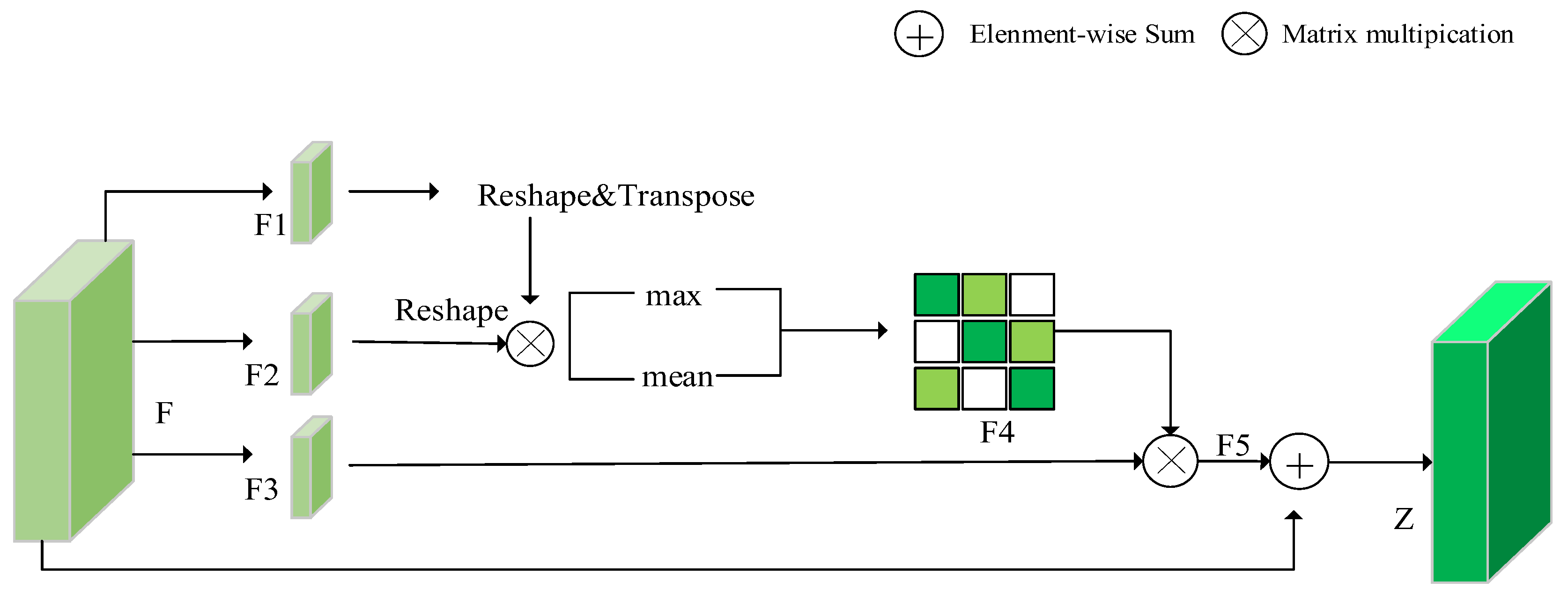
2.2.3. Position Attention Block
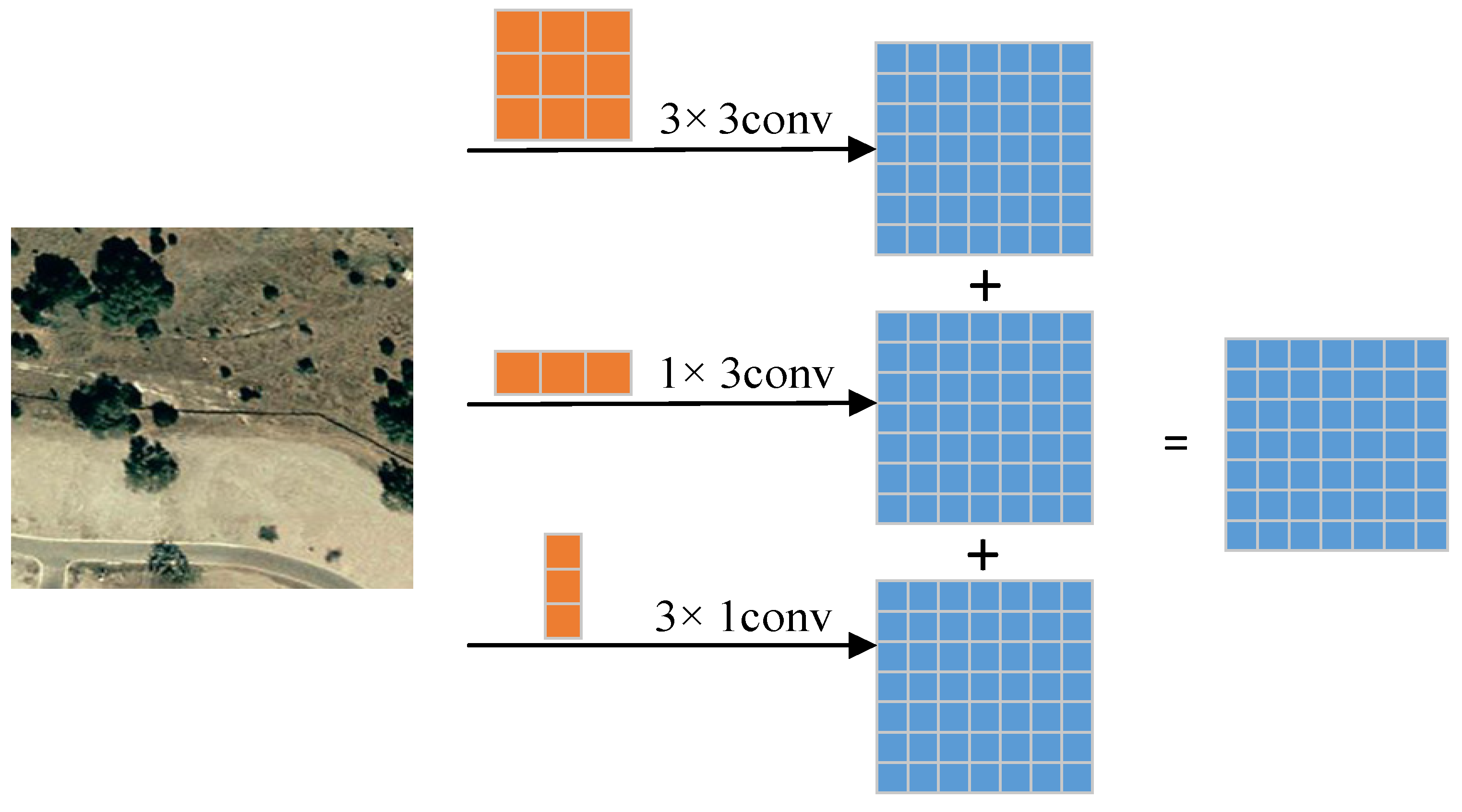
2.3. Asymmetric Convolution Block
3. Datasets and Metrics
3.1. Datasets
3.2. Metrics
4. Experiment
4.1. Experimental Setting
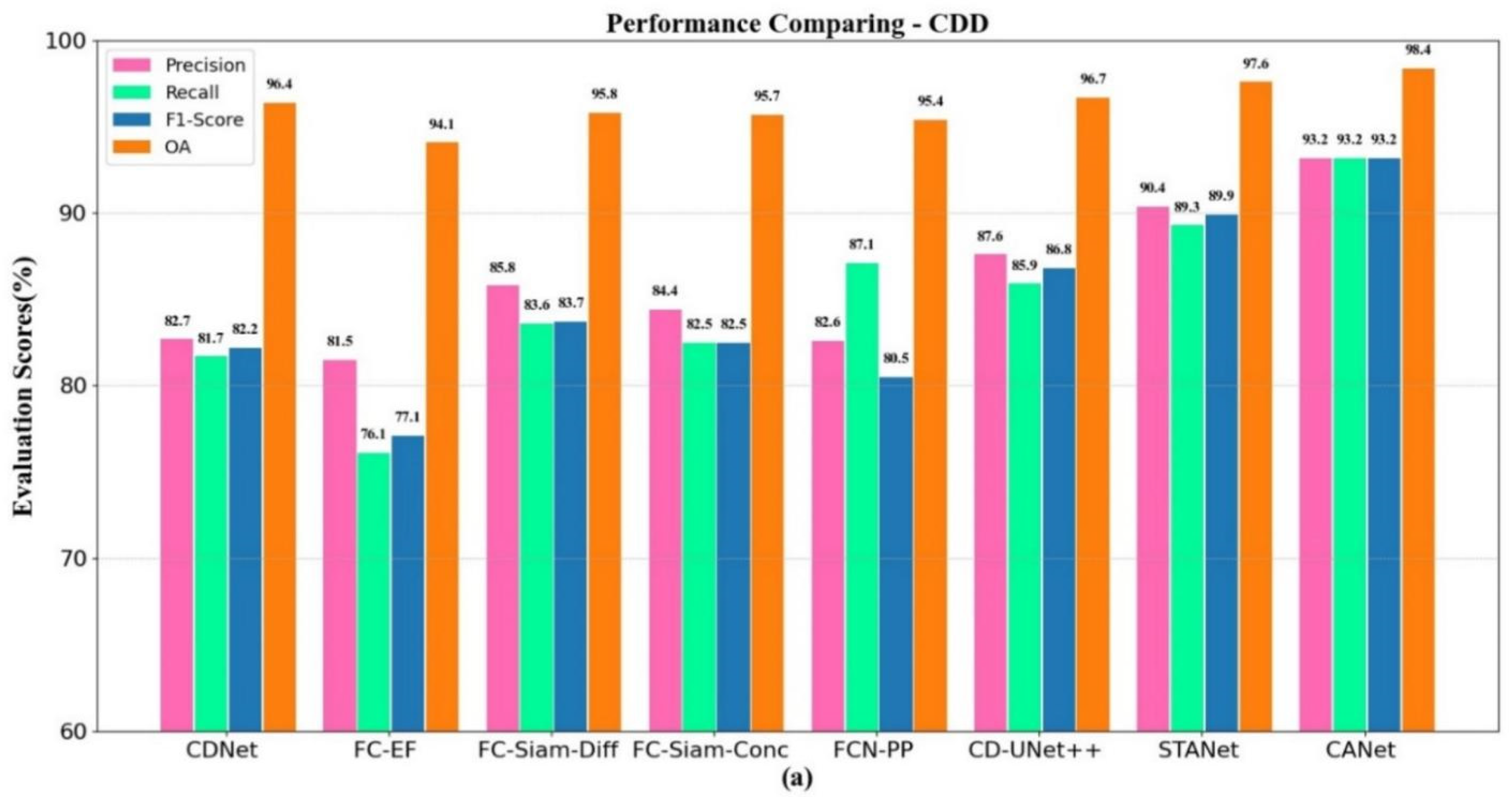
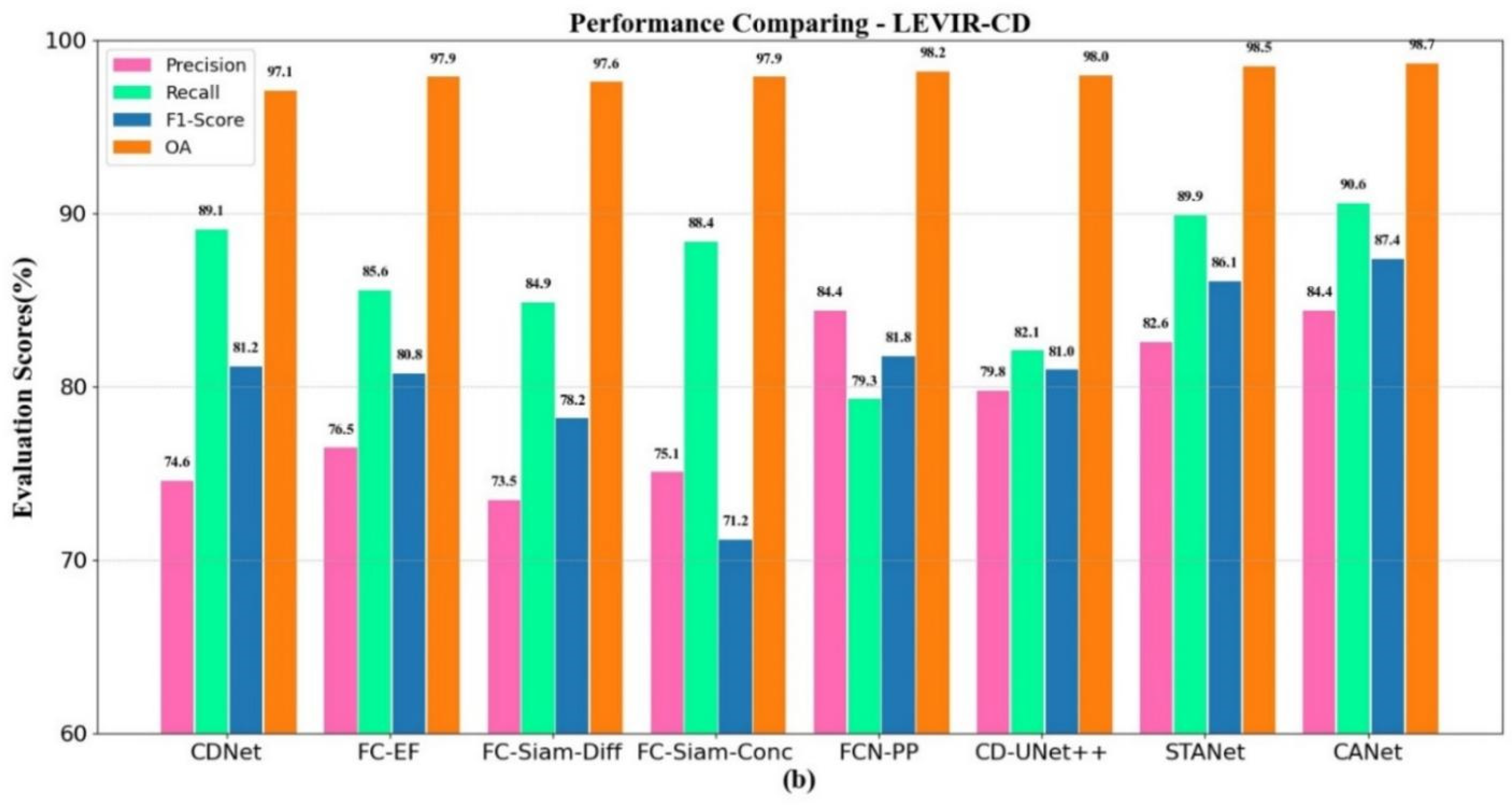
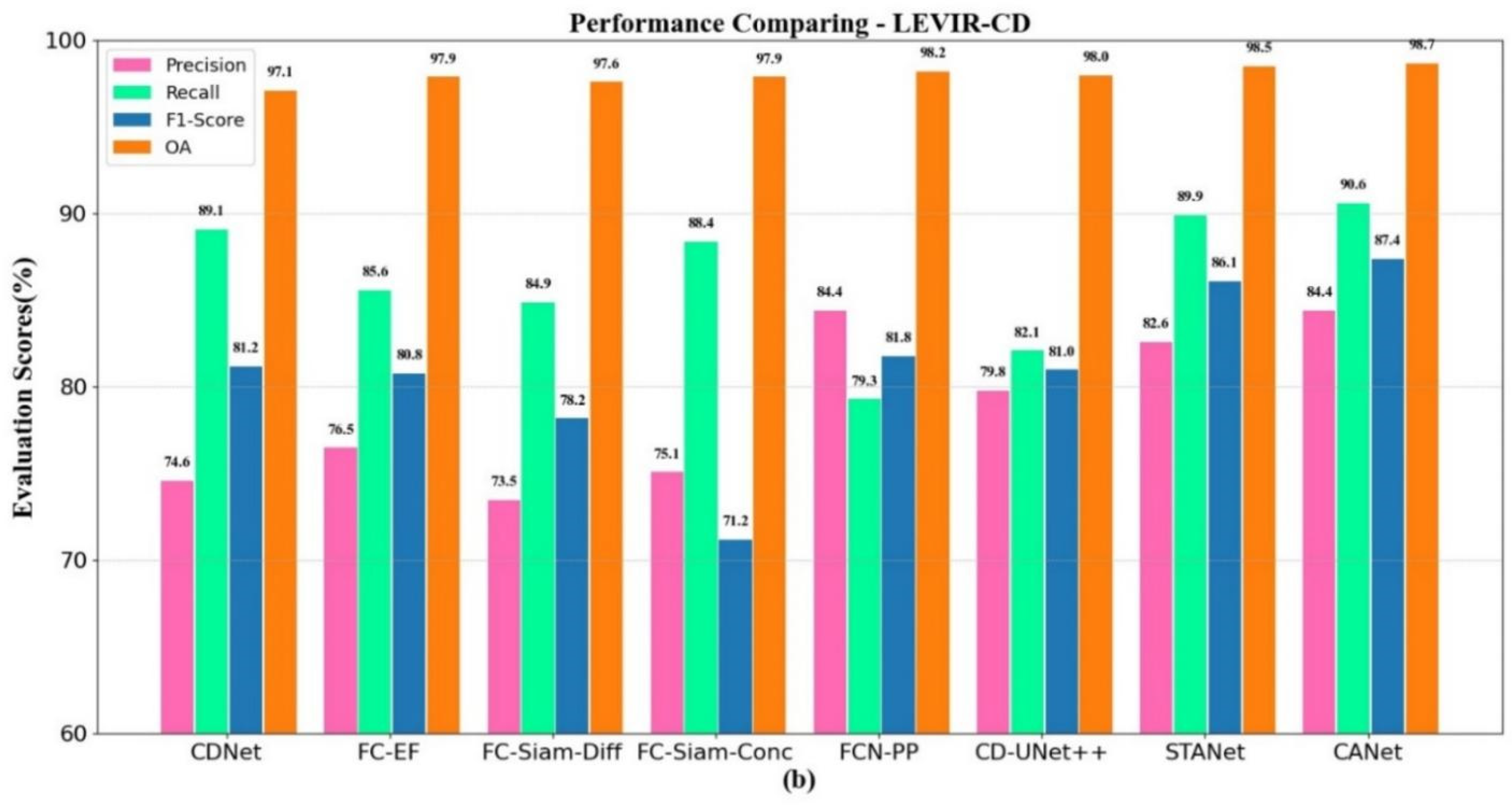
4.2. Results on Different Datasets
4.3. Accuracy/Efficiency Trade-Offs
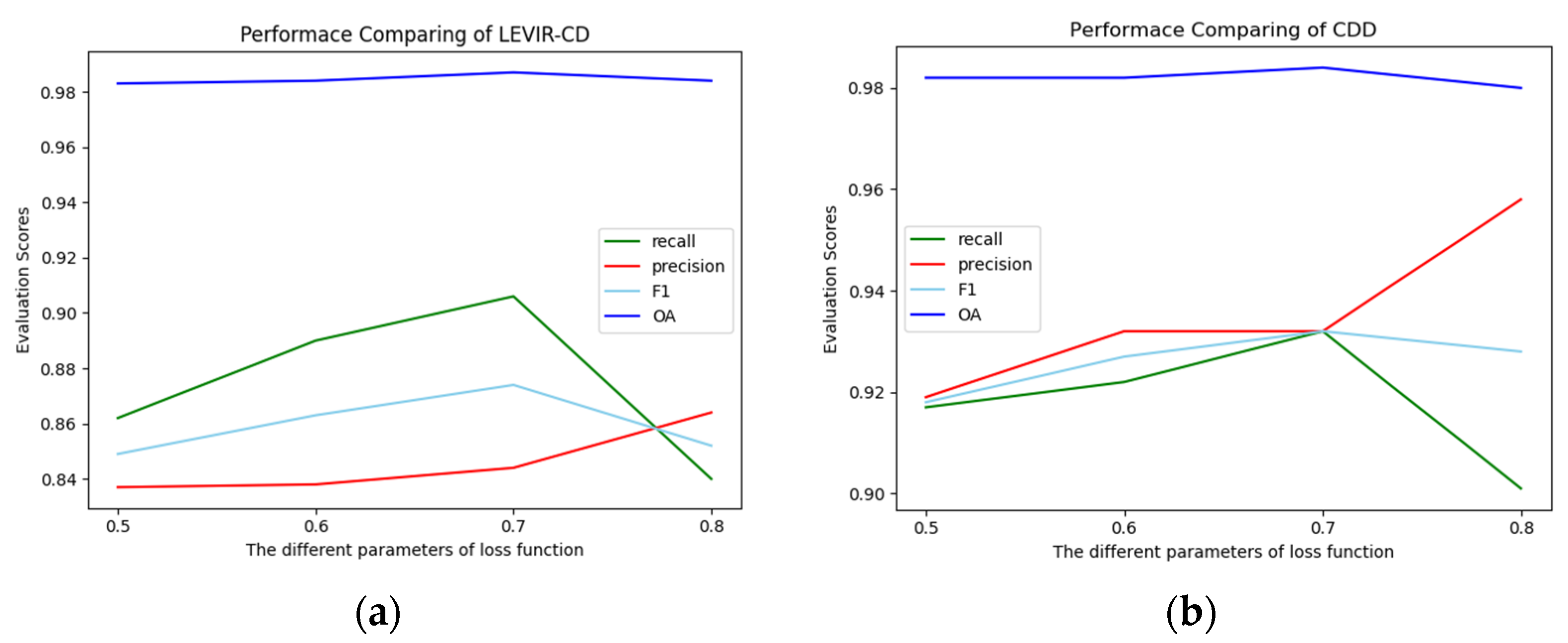
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singh, A. Review Article Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Lv, Z.Y.; Shi, W.; Zhang, X.; Benediktsson, J.A. Landslide Inventory Mapping from Bitemporal High-Resolution Remote Sensing Images Using Change Detection and Multiscale Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1520–1532. [Google Scholar] [CrossRef]
- Sofina, N.; Ehlers, M. Building Change Detection Using High Resolution Remotely Sensed Data and GIS. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 9, 3430–3438. [Google Scholar] [CrossRef]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Digital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches—Sciencedirect. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Cui, X.; Zhang, L. A post-classification change detection method based on iterative slow feature analysis and bayesian soft fusion. Remote Sens. Environ. 2017, 199, 241–255. [Google Scholar] [CrossRef]
- Deng, J.S.; Wang, K.; Deng, Y.H.; Qi, G.J. Pca-based land-use change detection and analysis using multitemporal and multisensor satellite data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D.; Bovolo, F.; Kanevski, M.; Bruzzone, L. Supervised change detection in VHR images using contextual information and support vector machines. Int. J. Appl. Earth Obs. Geoinf. 2013, 20, 77–85. [Google Scholar] [CrossRef]
- Zhang, C.; Li, G.; Cui, W. High-resolution remote sensing image change detection by statistical-object-based method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2440–2447. [Google Scholar] [CrossRef]
- Gil-Yepes, J.L.; Ruiz, L.A.; Recio, J.A.; Balaguer-Beser, A.; Hermosilla, T. Description and validation of a new set of object-based temporal geostatistical features for land-use/land-cover change detection. ISPRS J. Photogramm. Remote Sens. 2016, 121, 77–91. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Alcantarilla, P.F.; Simon, S.; Ros, G.; Roberto, A.; Riccardo, G. Street-view change detection with deconvolutional networks. Auton. Robot. 2018, 42, 1301–1322. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Verma, S.; Vakalopoulou, M.; Gupta, S.; Karantzalos, K. Detecting urban changes with recurrent neural networks from multitemporal sentinel-2 data. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 214–217. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Li, H. Dasnet: Dual attentive fully convolutional siamese networks for change detection of high resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change Detection in Synthetic Aperture Radar Images Based on Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 125–138. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. Getnet: A general end-to-end 2-d cnn framework for hyperspectral image change detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide inventory mapping from bitemporal images using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Fan, J.; Chen, J.; Zhang, P.; Han, L. Nestnet: A multiscale convolutional neural network for remote sensing image change detection. Int. J. Remote Sens. 2021, 42, 4902–4925. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the 4th International Workshop on Deep Learning in Medical Image Analysis, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- Long, C.; Zhang, H.; Xiao, J.; Nie, L.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional metworks for image captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6298–6306. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Lebedev, M.A.; Vizilter, Y.V.; Vygolov, O.V.; Knyaz, V.A.; Rubis, A.Y. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 565–571. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation by global convolutional network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Chen, W.; Yang, Y.; Ren, Z.; Wang, Z. ABD-Net: Attentive but diverse person re-identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8350–8360. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Zhang, X.; Yue, Y.; Gao, W.; Yun, S.; Zhang, Y. Difunet++: A satellite images change detection network based on unet++ and differential pyramid. IEEE Geosci. Remote Sens. Lett. 2021. [Google Scholar] [CrossRef]
- Zhi, Z.A.; Yi, W.A.; Yz, A.; Sx, A.; Dpb, C.; Bz, A. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Operation | Input | Output |
|---|---|---|---|
| Conv + Pool | {k = (7,7), s = (2,2), p = (3,3), BN, ReLU} | 3 × 256 × 256 | 64 × 64 × 64 |
| maxpool {k = (3,3), s = (2,2), p = (1,1)} | |||
| Resnet Block1 | {k = (3,3), s = (1,1), p = (1,1), BN} × 4 | 64 × 64 × 64 | 64 × 64 × 64 |
| Resnet Block2 | {k = (3,3), s = (2,2), p = (1,1), BN, ReLU} | 64 × 64 × 64 | 128 × 32 × 32 |
| {k = (3,3), s = (1,1), p = (1,1), BN} × 3 | |||
| Resnet Block3 | {k = (3,3), s = (2,2), p = (1,1), ReLU} | 128 × 32 × 32 | 256 × 16 × 16 |
| {k = (3,3), s = (1,1), p = (1,1), BN} × 3 | |||
| Resnet Block4 | {k = (3,3), s = (2,2), p = (1,1), BN, ReLU} | 256 × 16 × 16 | 512 × 8 × 8 |
| {k = (3,3), s = (1,1), p = (1,1), BN} × 3 |
| True Value | Predicted Value | |
|---|---|---|
| Positive | Negative | |
| positive | TP | FN |
| negative | FP | TN |
| Method | Rec (%) | Pre (%) | F1 (%) | OA (%) |
|---|---|---|---|---|
| CDNet | 81.7 | 82.7 | 82.2 | 96.4 |
| FC-EF | 76.1 | 81.5 | 77.1 | 94.1 |
| FC-Siam-Diff | 83.6 | 85.8 | 83.7 | 95.8 |
| FC-Siam-Conc | 82.5 | 84.4 | 82.5 | 95.7 |
| FCN-PP | 87.1 | 82.6 | 80.5 | 95.4 |
| CD-UNet++ | 85.9 | 87.6 | 86.8 | 96.7 |
| STANet | 89.3 | 90.4 | 89.9 | 97.6 |
| CANet | 93.2 | 93.2 | 93.2 | 98.4 |
| Method | Rec (%) | Pre (%) | F1 (%) | OA (%) |
|---|---|---|---|---|
| CDNet | 89.1 | 74.6 | 81.2 | 97.1 |
| FC-EF | 85.6 | 76.5 | 80.8 | 97.9 |
| FC-Siam-Diff | 84.9 | 73.5 | 78.2 | 97.6 |
| FC-Siam-Conc | 88.4 | 75.1 | 71.2 | 97.9 |
| FCN-PP | 79.3 | 84.4 | 81.8 | 98.2 |
| CD-UNet++ | 82.1 | 79.8 | 81.0 | 98.0 |
| STANet | 89.9 | 82.6 | 86.1 | 98.5 |
| CANet | 90.6 | 84.4 | 87.4 | 98.7 |
| Method | Train | Test | ||||
|---|---|---|---|---|---|---|
| F1 (%) | OA (%) | T/E | Parameter | Test Time (3000 Images) | ||
| CDNet | 82.2 | 96.4 | ~1879 s | ~1.28 M | 14.68 | ~1020 s |
| FC-EF | 77.1 | 94.1 | ~978 s | ~1.47 M | 6.65 | ~253 s |
| FC-Siam-Diff | 83.7 | 95.8 | ~1134 s | ~1.51 M | 7.51 | ~287 s |
| FC-Siam-Conc | 82.5 | 95.7 | ~1207 s | ~1.62 M | 7.45 | ~288 s |
| FCN-PP | 80.5 | 95.4 | ~1226 s | ~10.02 M | 1.22 | ~149 s |
| CD-UNet++ | 86.8 | 96.7 | ~4637 s | ~9.13 M | 5.07 | ~152 s |
| STANet | 89.9 | 97.6 | ~564 s | ~16.93 M | 0.33 | ~576 s |
| CANet | 93.2 | 98.4 | ~302 s | ~17.03 M | 0.18 | ~322 s |
| Method | Rec (%) | Pre (%) | F1 (%) | OA (%) |
|---|---|---|---|---|
| baseline | 89.5 | 77.1 | 82.9 | 98.1 |
| +ACB | 88.9 | 79.5 | 83.9 | 98.3 |
| +attention | 89.1 | 83.9 | 86.4 | 98.6 |
| CANet | 90.6 | 84.4 | 87.4 | 98.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, D.; Wang, L.; Cheng, S.; Li, Y.; Du, A. CANet: A Combined Attention Network for Remote Sensing Image Change Detection. Information 2021, 12, 364. https://doi.org/10.3390/info12090364
Lu D, Wang L, Cheng S, Li Y, Du A. CANet: A Combined Attention Network for Remote Sensing Image Change Detection. Information. 2021; 12(9):364. https://doi.org/10.3390/info12090364
Chicago/Turabian StyleLu, Di, Liejun Wang, Shuli Cheng, Yongming Li, and Anyu Du. 2021. "CANet: A Combined Attention Network for Remote Sensing Image Change Detection" Information 12, no. 9: 364. https://doi.org/10.3390/info12090364
APA StyleLu, D., Wang, L., Cheng, S., Li, Y., & Du, A. (2021). CANet: A Combined Attention Network for Remote Sensing Image Change Detection. Information, 12(9), 364. https://doi.org/10.3390/info12090364