
Topic Models Ensembles for AD-HOC Information Retrieval


Abstract
1. Introduction
- -
- We extend topic modeling ensembles to the ad hoc IR domain, showing that this approach performs well in precision and recall in benchmark data;
- -
- We combine the partial lists of each model into a consolidated ranking list. Our results show that the strategy is effective.
- -
- RQ1: What is the level of improvement that the strategies of ensembles of LDA-based models introduce in IR?
- -
- RQ2: Which ensemble strategies, based on LDA, are most useful in IR?
2. Related Work
3. Topic Modeling Ensembles for IR
3.1. Background
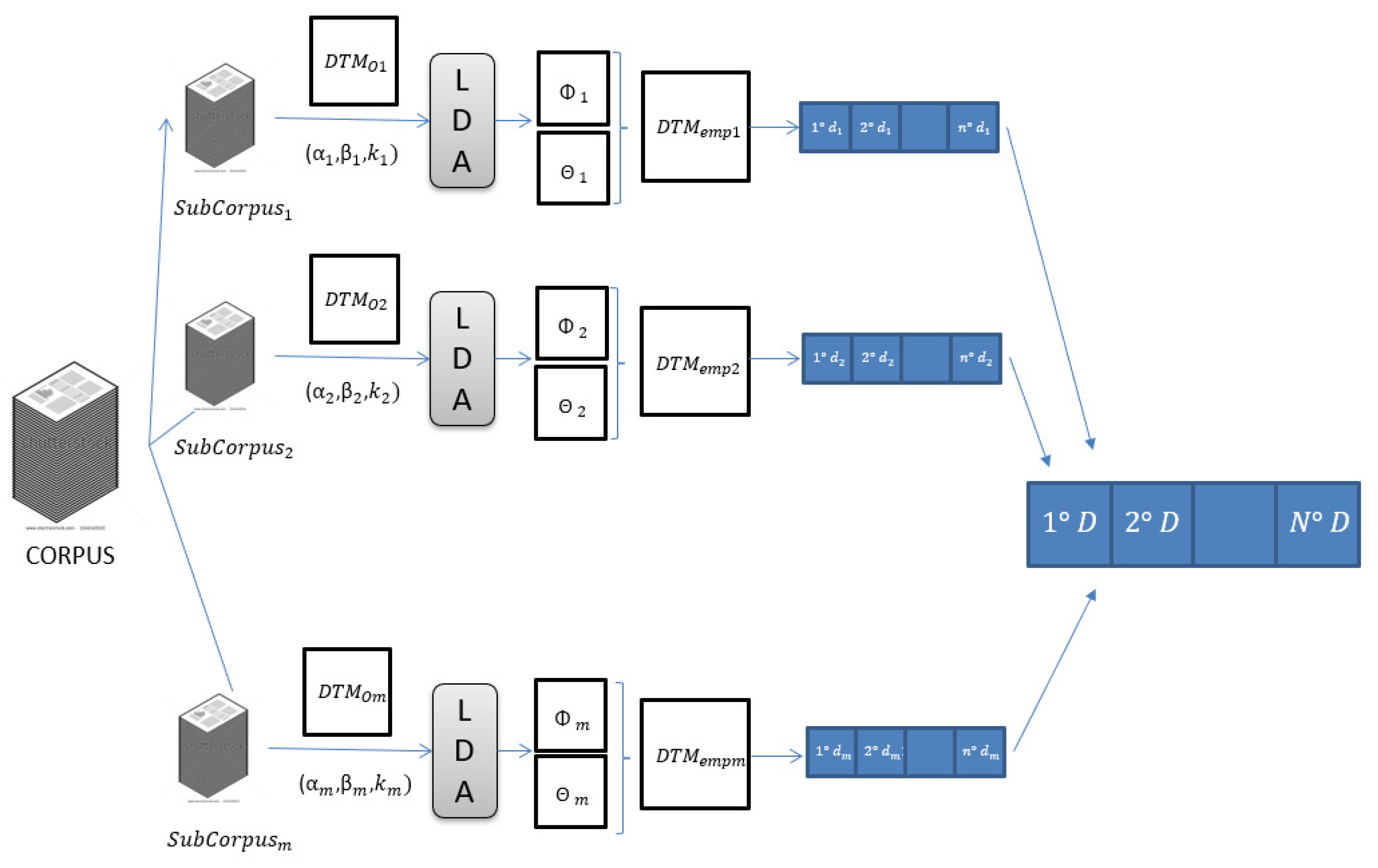
3.2. Topic Modeling Ensembles
3.3. Ranking Fusion Strategy
4. Experimental Results
5. Discussion
Limitations of This Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Doyle, L.; Becker, J. Information Retrieval and Processing; Melville Pub. Co.: Hoboken, NJ, USA, 1975. [Google Scholar]
- Mendoza, M.; Marín, M.; Gil-Costa, V.; Ferrarotti, F. Reducing hardware hit by queries in web search engines. Inf. Process. Manag. 2016, 52, 1031–1052. [Google Scholar] [CrossRef]
- Abernethy, J.; Chapelle, O.; Castillo, C. Graph regularization methods for Web spam detection. Mach. Learn. 2010, 81, 207–225. [Google Scholar] [CrossRef]
- Bracamonte, T.; Bustos, B.; Poblete, B.; Schreck, T. Extracting semantic knowledge from web context for multimedia IR: A taxonomy, survey and challenges. Multimed. Tools Appl. 2018, 77, 13853–13889. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Ning, H. Mining user interest based on personality-aware hybrid filtering in social networks. Knowl. Based Syst. 2020, 206, 106227. [Google Scholar] [CrossRef]
- Aggarwal, C. Recommender Systems—The Textbook; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Arenas, M.; Barceló, P.; Libkin, L.; Murlak, F. Foundations of Data Exchange; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 6–11 June 2019; pp. 4171–4186. [Google Scholar]
- Hao, S.; Shi, C.; Niu, Z.; Cao, L. Concept coupling learning for improving concept lattice-based document retrieval. Eng. Appl. Artif. Intell. 2018, 69, 65–75. [Google Scholar] [CrossRef]
- Jansen, B.; Rieh, S. The Seventeen Theoretical Constructs of Information Searching and Information Retrieval. J. Am. Soc. Inf. Sci. Technol. (JASIST) 2010, 61, 1517–1534. [Google Scholar] [CrossRef]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press/Addison-Wesley: New York, NY, USA, 1999. [Google Scholar]
- Salton, G.; Buckley, C. Term-Weighting Approaches in Automatic Text Retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Silva, A.; Mendoza, M. Improving query expansion strategies with word embeddings. In Proceedings of the ACM Symposium on Document Engineering (DocEng), Virtual Event, San Jose, CA, USA, 29 September–1 October 2020; pp. 10:1–10:4. [Google Scholar]
- Buttcher, S.; Clarke, C.; Cormack, G. Information Retrieval—Implementing and Evaluating Search Engines; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Azzopardi, L. Incorporating context within the language modeling approach for ad-hoc information retrieval. SIGIR Forum 2006, 40, 70. [Google Scholar] [CrossRef]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Boyd-Graber, J.; Blei, D.; Zhu, X. A Topic Model for Word Sense Disambiguation. In Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 1024–1033. [Google Scholar]
- Li, W.; Yin, J.; Chen, H. Supervised Topic Modeling Using Hierarchical Dirichlet Process-Based Inverse Regression: Experiments on E-Commerce Applications. IEEE Trans. Knowl. Data Eng. 2018, 30, 1192–1205. [Google Scholar] [CrossRef]
- Wei, X.; Croft, B. LDA-based document models for ad-hoc retrieval. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 28 July–1 August 2006; pp. 178–185. [Google Scholar]
- Zhai, C.; Lafferty, J. A Study of Smoothing Methods for Language Models Applied to Ad-Hoc Information Retrieval. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; pp. 334–342. [Google Scholar]
- Kuncheva, L. Combining Pattern Classifiers: Methods and Algorithms; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Shen, Z.; Luo, P.; Yang, S.; Shen, X. Topic Modeling Ensembles. In Proceedings of the 10th IEEE International Conference on Data Mining (ICDM), Sydney, Australia, 14–17 December 2010; pp. 1031–1036. [Google Scholar]
- Rider, A.; Chawla, N. An Ensemble Topic Model for Sharing Healthcare Data and Predicting Disease Risk. In Proceedings of the ACM Conference on Bioinformatics, Computational Biology and Biomedical Informatics (ACM-BCB), Washington, DC, USA, 22–25 September 2013; p. 333. [Google Scholar]
- Onan, A. Biomedical Text Categorization Based on Ensemble Pruning and Optimized Topic Modelling. Comput. Math. Methods Med. 2018, 2018, 2497471. [Google Scholar] [CrossRef] [PubMed]
- Baechle, C.; Huang, C.; Agarwal, A.; Behara, R.; Goo, J. Latent topic ensemble learning for hospital readmission cost optimization. Eur. J. Oper. Res. 2020, 281, 517–531. [Google Scholar] [CrossRef]
- Blair, S.; Bi, Y.; Mulvenna, M. Aggregated topic models for increasing social media topic coherence. Appl. Intell. 2020, 50, 138–156. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Schapire, R.; Singer, Y. BoosTexter: A Boosting-based System for Text Categorization. Mach. Learn. 2000, 39, 135–168. [Google Scholar] [CrossRef]
- La, L.; Guo, Q.; Cao, Q.; Li, Q. LDA boost classification: Boosting by topics. EURASIP J. Adv. Signal Process. 2012, 233. [Google Scholar] [CrossRef]
- Gai, F.; Li, Z.; Jiang, X.; Guo, H. Enhance AdaBoost Algorithm by Integrating LDA Topic Model. In Proceedings of the First International Conference on Data Mining and Big Data (DMBD), Bali, Indonesia, 25–30 June 2016; pp. 27–37. [Google Scholar]
- Tang, S.; Zheng, Y.; Cao, G.; Zhang, Y.D.; Li, J.T. Ensemble Learning with LDA Topic Models for Visual Concept Detection. In Multimedia—A Multidisciplinary Approach to Complex Issues; Book Chapter 9; IntechOpen Limited: London, UK, 2012; pp. 175–200. [Google Scholar]
- Ramanathan, V.; Wechsler, H. Phishing website detection using Latent Dirichlet Allocation and AdaBoost. In Proceedings of the IEEE International Conference on Intelligence and Security Informatics (ISI), Washington, DC, USA, 11–14 June 2012; pp. 102–107. [Google Scholar]
- Korkontzelos, I.; Thomas, B.; Miwa, M.; Ananiadou, S. Ensemble Classification of Grants using LDA-based Features. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC), Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Wang, Y.; Guo, Q. Multi-LDA hybrid topic model with boosting strategy and its application in text classification. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014. [Google Scholar]
- Al-Salemi, B.; Ayob, M.; Noah, S.; Ab Aziz, M. Feature Selection based on Supervised Topic Modeling for Boosting-Based Multi-Label Text Categorization. In Proceedings of the 6th International Conference on Electrical Engineering and Informatics (ICEEI), Langkawi, Malaysia, 25–27 November 2017. [Google Scholar]
- Blei, D.; McAuliffe, J. Supervised Topic Models. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 3–6 December 2007; pp. 121–128. [Google Scholar]
- Belford, M.; MacNamee, B.; Greene, D. Ensemble Topic Modeling via Matrix Fact orization. In Proceedings of the 24th Irish Conference on Artificial Intelligence and Cognitive Science (AICS), Dublin, Ireland, 20–21 September 2016; pp. 21–32. [Google Scholar]
- Dhillon, I.; Sra, S. Generalized Nonnegative Matrix Approximations with Bregman Divergences. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 5–8 December 2005; pp. 283–290. [Google Scholar]
- Pourvali, M.; Orlando, S.; Omidvarborna, H. Topic Models and Fusion Methods: A Union to Improve Text Clustering and Cluster Labeling. Int. J. Interact. Multimed. Artif. Intell. 2019, 5, 28–34. [Google Scholar] [CrossRef]
- Mendoza, M.; Ormeño, P.; Valle, C. Boosting Text Clustering using Topic Selection. In Proceedings of the International Conference on Pattern Recognition Systems (ICPRS), Valparaíso, Chile, 22–24 May 2018. [Google Scholar]
- Xu, J.; Li, H. AdaRank: A boosting algorithm for information retrieval. In Proceedings of the 30th Annual International ACM Conference on Research and Development in Information Retrieval (SIGIR), Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar]
- Wu, S.; Bi, X.; McClean, S. Applying statistical principles to data fusion in information retrieval. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC), Montreal, QC, Canada, 7–10 October 2007; pp. 313–319. [Google Scholar]
- Vogt, C.; Cottrell, G. Fusion Via a Linear Combination of Scores. Inf. Retr. 1999, 1, 151–173. [Google Scholar] [CrossRef]
- Garrouch, K.; Omri, M. Bayesian Network Based Information Retrieval Model. In Proceedings of the International Conference on High Performance Computing & Simulation, (HPCS), Genoa, Italy, 17–21 July 2017; pp. 193–200. [Google Scholar]
- Rosen-Zvi, M.; Griffiths, T.; Steyvers, M.; Smyth, P. The Author-Topic Model for Authors and Documents. In Proceedings of the 20th Conference in Uncertainty in Artificial Intelligence (UAI), Banff, AB, Canada, 7–11 July 2004; pp. 487–494. [Google Scholar]



{kind=link}
{kind=link}
| Dataset | Documents | Querys | Terms |
|---|---|---|---|
| MED | 1.033 | 30 | 5.775 |
| CRAN | 1.400 | 225 | 8213 |
| CISI | 1.460 | 112 | 10.170 |
| CACM | 3.204 | 64 | 9.961 |
| # Models | 1 | 5 | 10 | 15 | 20 | |
|---|---|---|---|---|---|---|
| LDA Ens | 0.722 | 0.771 | 0.756 | 0.757 | 0.756 | |
| MED | BAGG Ens | 0.802 | 0.797 | 0.805 | 0.806 | 0.805 |
| ADA Ens | 0.799 | 0.778 | 0.773 | 0.771 | 0.766 | |
| LDA Ens | 0.518 | 0.582 | 0.576 | 0.575 | 0.576 | |
| CRAN | BAGG Ens | 0.554 | 0.576 | 0.577 | 0.578 | 0.576 |
| ADA Ens | 0.565 | 0.576 | 0.575 | 0.573 | 0.573 | |
| LDA Ens | 0.398 | 0.442 | 0.392 | 0.391 | 0.393 | |
| CISI | BAGG Ens | 0.412 | 0.437 | 0.432 | 0.432 | 0.438 |
| ADA Ens | 0.428 | 0.441 | 0.443 | 0.441 | 0.437 | |
| LDA Ens | 0.138 | 0.157 | 0.162 | 0.161 | 0.160 | |
| CACM | BAGG Ens | 0.192 | 0.186 | 0.185 | 0.183 | 0.181 |
| ADA Ens | 0.188 | 0.167 | 0.166 | 0.165 | 0.162 | |
| LDA [19] | TF-IDF [12] | DBNIRM [45] | CCLR [9] | LDA Ens | BAGG Ens | ADA Ens | ||
|---|---|---|---|---|---|---|---|---|
| MED | MAP | 0.869 | 0.789 | 0.758 | 0.714 | 0.789 ± 0.001 | 0.867 ± 0.012 | 0.809 ± 0.007 |
| P | 0.706 | 0.706 | 0.712 | 0.684 | 0.706 ± 0.002 | 0.751 ± 0.008 | 0.715 ± 0.011 | |
| R | 0.171 | 0.175 | 0.178 | 0.162 | 0.175 ± 0.001 | 0.186 ± 0.002 | 0.178 ± 0.002 | |
| 0.276 | 0.281 | 0.284 | 0.262 | 0.281 ± 0.001 | 0.298 ± 0.003 | 0.285 ± 0.004 | ||
| CRAN | MAP | 0.604 | 0.621 | 0.605 | 0.587 | 0.621 ± 0.001 | 0.629 ± 0.006 | 0.618 ± 0.005 |
| P | 0.344 | 0.352 | 0.358 | 0.342 | 0.351 ± 0.002 | 0.363 ± 0.004 | 0.361 ± 0.001 | |
| R | 0.257 | 0.269 | 0.264 | 0.245 | 0.268 ± 0.001 | 0.277 ± 0.003 | 0.275 ± 0.001 | |
| 0.294 | 0.305 | 0.303 | 0.285 | 0.304 ± 0.001 | 0.314 ± 0.004 | 0.312 ± 0.001 | ||
| CISI | MAP | 0.464 | 0.468 | 0.460 | 0.443 | 0.472 ± 0.001 | 0.472 ± 0.001 | 0.464 ± 0.008 |
| P | 0.307 | 0.292 | 0.298 | 0.286 | 0.285 ± 0.002 | 0.314 ± 0.004 | 0.314 ± 0.011 | |
| R | 0.059 | 0.056 | 0.061 | 0.052 | 0.053 ± 0.001 | 0.061 ± 0.002 | 0.063 ± 0.002 | |
| 0.099 | 0.093 | 0.101 | 0.088 | 0.091 ± 0.001 | 0.101 ± 0.003 | 0.105 ± 0.003 | ||
| CACM | MAP | 0.158 | 0.146 | 0.148 | 0.135 | 0.146 ± 0.001 | 0.161 ± 0.004 | 0.149 ± 0.004 |
| P | 0.107 | 0.103 | 0.106 | 0.112 | 0.103 ± 0.001 | 0.115 ± 0.005 | 0.106 ± 0.001 | |
| R | 0.039 | 0.038 | 0.041 | 0.042 | 0.038 ± 0.001 | 0.047 ± 0.004 | 0.039 ± 0.001 | |
| 0.057 | 0.055 | 0.059 | 0.061 | 0.056 ± 0.002 | 0.067 ± 0.005 | 0.057 ± 0.001 | ||
| LDA [19] | TF-IDF [12] | DBNIRM [45] | CCLR [9] | LDA Ens | BAGG Ens | ADA Ens | ||
|---|---|---|---|---|---|---|---|---|
| MED | MAP | 0.802 | 0.756 | 0.780 | 0.689 | 0.771 ± 0.001 | 0.806 ± 0.006 | 0.799 ± 0.001 |
| P | 0.680 | 0.611 | 0.625 | 0.606 | 0.607 ± 0.003 | 0.658 ± 0.008 | 0.636 ± 0.011 | |
| R | 0.324 | 0.291 | 0.308 | 0.288 | 0.291 ± 0.002 | 0.315 ± 0.005 | 0.307 ± 0.006 | |
| 0.439 | 0.394 | 0.412 | 0.391 | 0.392 ± 0.002 | 0.427 ± 0.006 | 0.414 ± 0.008 | ||
| CRAN | MAP | 0.568 | 0.572 | 0.573 | 0.447 | 0.582 ± 0.001 | 0.578 ± 0.007 | 0.576 ± 0.006 |
| P | 0.265 | 0.261 | 0.264 | 0.249 | 0.259 ± 0.001 | 0.271 ± 0.001 | 0.269 ± 0.003 | |
| R | 0.386 | 0.384 | 0.381 | 0.346 | 0.384 ± 0.001 | 0.394 ± 0.001 | 0.391 ± 0.005 | |
| 0.315 | 0.311 | 0.311 | 0.289 | 0.309 ± 0.001 | 0.321 ± 0.001 | 0.319 ± 0.004 | ||
| CISI | MAP | 0.426 | 0.431 | 0.438 | 0.396 | 0.442 ± 0.003 | 0.438 ± 0.004 | 0.443 ± 0.008 |
| P | 0.275 | 0.263 | 0.274 | 0.268 | 0.258 ± 0.004 | 0.271 ± 0.002 | 0.266 ± 0.003 | |
| R | 0.095 | 0.111 | 0.107 | 0.108 | 0.107 ± 0.003 | 0.101 ± 0.006 | 0.097 ± 0.002 | |
| 0.142 | 0.156 | 0.153 | 0.154 | 0.151 ± 0.003 | 0.146 ± 0.007 | 0.142 ± 0.002 | ||
| CACM | MAP | 0.191 | 0.161 | 0.184 | 0.165 | 0.162 ± 0.001 | 0.192 ± 0.004 | 0.188 ± 0.001 |
| P | 0.121 | 0.088 | 0.116 | 0.084 | 0.088 ± 0.001 | 0.112 ± 0.003 | 0.101 ± 0.002 | |
| R | 0.116 | 0.078 | 0.099 | 0.101 | 0.078 ± 0.002 | 0.102 ± 0.003 | 0.098 ± 0.003 | |
| 0.118 | 0.082 | 0.106 | 0.092 | 0.082 ± 0.002 | 0.107 ± 0.003 | 0.101 ± 0.001 | ||
| LDA [19] | TF-IDF [12] | DBNIRM [45] | CCLR [9] | LDA Ens | BAGG Ens | ADA Ens | ||
|---|---|---|---|---|---|---|---|---|
| MED | MAP | 0.759 | 0.711 | 0.736 | 0.712 | 0.711 ± 0.001 | 0.738 ± 0.011 | 0.713 ± 0.001 |
| P | 0.596 | 0.497 | 0.562 | 0.573 | 0.497 ± 0.002 | 0.558 ± 0.007 | 0.527 ± 0.008 | |
| R | 0.546 | 0.455 | 0.514 | 0.489 | 0.455 ± 0.001 | 0.516 ± 0.005 | 0.481 ± 0.008 | |
| 0.571 | 0.475 | 0.536 | 0.527 | 0.475 ± 0.002 | 0.536 ± 0.006 | 0.503 ± 0.008 | ||
| CRAN | MAP | 0.509 | 0.525 | 0.517 | 0.496 | 0.525 ± 0.001 | 0.522 ± 0.008 | 0.516 ± 0.002 |
| P | 0.188 | 0.172 | 0.198 | 0.164 | 0.171 ± 0.001 | 0.181 ± 0.001 | 0.179 ± 0.001 | |
| R | 0.526 | 0.484 | 0.499 | 0.414 | 0.483 ± 0.001 | 0.506 ± 0.001 | 0.504 ± 0.003 | |
| 0.278 | 0.253 | 0.283 | 0.235 | 0.252 ± 0.001 | 0.267 ± 0.001 | 0.264 ± 0.001 | ||
| CISI | MAP | 0.385 | 0.396 | 0.391 | 0.351 | 0.397 ± 0.003 | 0.395 ± 0.011 | 0.386 ± 0.002 |
| P | 0.245 | 0.221 | 0.237 | 0.208 | 0.214 ± 0.002 | 0.232 ± 0.001 | 0.228 ± 0.001 | |
| R | 0.176 | 0.163 | 0.168 | 0.152 | 0.156 ± 0.001 | 0.166 ± 0.003 | 0.161 ± 0.003 | |
| 0.205 | 0.187 | 0.196 | 0.175 | 0.181 ± 0.002 | 0.193 ± 0.002 | 0.189 ± 0.001 | ||
| CACM | MAP | 0.188 | 0.169 | 0.181 | 0.159 | 0.169 ± 0.001 | 0.184 ± 0.005 | 0.171 ± 0.001 |
| P | 0.098 | 0.079 | 0.092 | 0.076 | 0.079 ± 0.001 | 0.101 ± 0.004 | 0.093 ± 0.001 | |
| R | 0.164 | 0.132 | 0.154 | 0.125 | 0.131 ± 0.001 | 0.177 ± 0.003 | 0.159 ± 0.004 | |
| 0.122 | 0.098 | 0.115 | 0.094 | 0.098 ± 0.001 | 0.128 ± 0.004 | 0.118 ± 0.002 | ||
| TID | LDA [19] | LDA Ens | BAGG Ens | ADA Ens | |
|---|---|---|---|---|---|
| MED | 1 | alveolar, line, lung | acid, alveolar, lung | alveolar, line, lung | alveolar, information, |
| pulmonary, surface | perform, rate | mouse, pulmonary | line, lung, lymphatic | ||
| 2 | female, male, rat, | demonstrate, female, intact, | conjugate, female, normal, | female, normal, patient, | |
| testosterone, tissue | show, testosterone | plasma, testosterone | plasma, testosterone | ||
| 3 | body, cool, hypothermia, | heart, hypothermia, patient | body, cool, hypothermia, | body, coronary, hypothermia, | |
| perfusion, temperature | perfusion, surgery | perfusion, temperature | perfusion, temperature | ||
| 4 | blood, brain, control, | blood, brain, group, | blood, brain, increase, | blood, brain, hypoxia, | |
| lactate, response | study, surface | lactate, rise | lactate, rise | ||
| 5 | cancer, carcinoma, case, | cancer, carcinoma, decrease, | cancer, carcinoma, case, | cancer, carcinoma, cell, | |
| lung, primary | enzyme, pulmonary | lung, tumor | lung, radiation | ||
| CRAN | 1 | equation, method, numerical, | base, equation, method, | equation, method, problem, | boundary, method, problem, |
| problem, solution | problem, solution | solution, solve | solution, solve | ||
| 2 | body, flow, hypersonic, | flow, hypersonic, show | body, flow, hypersonic, | flow, hypersonic, inviscid, | |
| nose, pressure | theory, velocity | pressure, shock | pressure, shock | ||
| 3 | buckling, cylinder, pressure, | buckling, cylinder, shell, | buckling, creep, cylinder, | buckling, creep, cylinder, | |
| shell, theory | wall, wave | initial, shape | equation, flow | ||
| 4 | airplane, altitude, boom, | airplane, altitude, boom, | airplane, altitude, boom, | airplane, altitude, flight, | |
| flight, shock | flight, shock | flight, mach | mach, number | ||
| 5 | dimensional, disturbance, flow, | aircraft, disturbance, flight, | amplitude, dimensional, disturbance, | cone, dimensional, disturbance, | |
| small, solution | ground, level | energy, wave | surface, wave | ||
| CISI | 1 | book, collection, librarian, | base, book, collection, | book, circulation, collection, | book, circulation, collection, |
| library, university | concept, subject | library, medical | fact, size | ||
| 2 | information, provide, reference, | entry, information, provide, | information, organization, | citation, information, | |
| service, university | search, user | provide, service, type | literature, provide, reference | ||
| 3 | health, library, manpower, | center, health, international, | health, hospital, library, | health, library, manpower, | |
| professional, science | library, national | manpower, science | program, scale | ||
| 4 | comparative, economic, problem, | addition, economic, experimental, | country, economic, interest, | economic, international, | |
| project, scientist | system, theoretical | problem, view | project, series, time | ||
| 5 | change, data, model, | data, entry, large, | base, data, information, | data, idea, library, | |
| rate, storage | research, storage | large, model | memory, model | ||
| CACM | 1 | correctness, program, | algorithm, make, program, | correctness, program, proof, | correctness, program, proof, |
| proof, prove, technique | proof, similar | prove, technique | prove, specification | ||
| 2 | algorithm, class, function, | algorithm, class, identify, | algorithm, class, equation, | algorithm class, drum, | |
| processor, schedule | improve, reduce | problem, solution | schedule, time | ||
| 3 | fortran, input, language, | computer, input, processing, | input, machine, output, | data, information, input, | |
| output, program | program, provide | program, user | processing, program | ||
| 4 | debug, design, feature, | applicable, debug, program, | debug, input, operating, | communication, debug, illustrate, | |
| program, system | solve, user | process, program | program, user | ||
| 5 | hash, method, search, | algorithm, efficiency, hash, | hash, method, quadratic, | hash, language, search, | |
| table, technique | length, table | size, table | structure, table |
| QID | Query Words | L | Winning | |
|---|---|---|---|---|
| MED | 3 | [‘electron’, ‘microscopy’, ‘lung’] | 3 | BAGG Ens |
| 12 | [‘effect’, ‘azathioprine’, ‘systemic’, ‘lupus’, ‘erythematosus’, ‘regard’, ‘renal’, ‘lesion’] | 8 | BAGG Ens | |
| 16 | [‘separation’, ‘anxiety’, ‘infancy’, ‘year’, ‘preschool’, ‘child’, ‘separation’, ‘child’, ‘mother’] | 9 | BAGG Ens | |
| 17 | [‘nickel’, ‘nutrition’, ‘requirement’, ‘method’, ‘analysis’, ‘relation’, ‘enzyme’, ‘system’, ‘toxicity’, | 20 | LDA | |
| ‘human’, ‘laboratory’, ‘animal’, ‘deficiency’, ‘sign’, ‘symptom’, ‘level’, ‘foodstuff’, ‘level’, ‘blood’, ‘tissue’] | ||||
| 21 | [‘language’, ‘development’, ‘infancy’, ‘pre’, ‘school’] | 5 | LDA | |
| 22 | [‘mycoplasma’, ‘infection’, ‘presence’, ‘embryo’, ‘fetus’, ‘newborn’, ‘infant’, ‘animal’, ‘pregnancy’, ‘gynecologic’, | 15 | LDA | |
| ‘disease’, ‘related’, ‘chromosome’, ‘chromosome’, ‘abnormality’] | ||||
| 24 | [‘compensatory’, ‘renal’, ‘hypertrophy’, ‘stimulus’, ‘result’, ‘mass’, ‘increase’, ‘hypertrophy’, ‘cell’, ‘proliferation’, | 16 | BAGG Ens | |
| ‘hyperplasia’, ‘remain’, ‘kidney’, ‘unilateral’, ‘nephrectomy’, ‘mammal’] | ||||
| 25 | [‘chlorothiazide’, ‘diuril’, ‘hydrochlorothiazide’, ‘hydrodiuril’, ‘treatment’, ‘nephogenic’, ‘diabetes’, ‘insipidus’, | 18 | BAGG Ens | |
| ‘child’, ‘also’, ‘sodium’, ‘aldactone’, ‘spironolactone’, ‘treatment’, ‘childhood’, ‘nephogenic’, ‘diabetes’, ‘insipidus’] | ||||
| CRAN | 5 | [‘chemical’, ‘kinetic’, ‘applicable’, ‘hypersonic’, ‘aerodynamic’, ‘problem’] | 6 | LDA |
| 17 | [‘three’, ‘dimensional’, ‘problem’, ‘transverse’, ‘potential’, ‘flow’, ‘body’, ‘revolution’, ‘reduce’, ‘two’, ‘dimensional’] | 11 | LDA | |
| 32 | [‘approximate’, ‘correction’, ‘thickness’, ‘slender’, ‘thin’, ‘wing’, ‘theory’] | 7 | BAGG Ens | |
| 33 | [‘interference’, ‘free’, ‘longitudinal’, ‘stability’, ‘measurement’, ‘make’, ‘free’, ‘flight’, ‘model’, ‘compare’, ‘similar’, | 16 | BAGG Ens | |
| ‘measurement’, ‘low’, ‘blockage’, ‘wind’, ‘tunnel’] | ||||
| 37 | [‘theoretical’, ‘method’, ‘predict’, ‘base’, ‘pressure’] | 5 | BAGG Ens | |
| 38 | [‘transition’, ‘hypersonic’, ‘wake’, ‘depend’, ‘body’, ‘geometry’, ‘size’] | 7 | LDA | |
| 40 | [‘transition’, ‘phenomenon’, ‘hypersonic’, ‘wake’] | 4 | LDA | |
| 43 | [‘transonic’, ‘flow’, ‘arbitrary’, ‘smooth’, ‘airfoil’, ‘analyse’, ‘simple’, ‘approximate’] | 8 | BAGG Ens | |
| 47 | [‘exist’, ‘solution’, ‘hypersonic’, ‘viscous’, ‘interaction’, ‘insulate’, ‘flat’, ‘plate’] | 8 | BAGG Ens | |
| 60 | [‘simple’, ‘practical’, ‘method’, ‘numerical’, ‘integration’, ‘mix’, ‘problem’, ‘blasius’, ‘three’, ‘point’, ‘boundary’, | 12 | LDA | |
| ‘condition’] | ||||
| 73 | [‘role’, ‘effect’, ‘chemical’, ‘reaction’, ‘particularly’, ‘equilibrium’, ‘play’, ‘similitude’, ‘law’, ‘govern’, ‘hypersonic’, | 15 | LDA | |
| ‘flow’, ‘slender’, ‘aerodynamic’, ‘body’] | ||||
| 77 | [‘close’, ‘comparison’, ‘shock’, ‘layer’, ‘theory’, ‘exist’, ‘experiment’, ‘reynolds’, ‘number’, ‘merge’, ‘layer’, ‘regime’] | 12 | BAGG Ens | |
| 79 | [‘aerodynamic’, ‘derivative’, ‘measure’, ‘hypersonic’, ‘mach’, ‘number’, ‘comparison’, ‘theoretical’, ‘work’] | 9 | ADA Ens | |
| 88 | [‘satellite’, ‘orbit’, ‘contract’, ‘action’, ‘drag’, ‘atmosphere’, ‘scale’, ‘height’, ‘varies’, ‘altitude’] | 10 | BAGG Ens | |
| 91 | [‘interference’, ‘effect’, ‘transonic’, ‘speed’] | 4 | BAGG Ens | |
| 95 | [‘theoretical’, ‘heat’, ‘transfer’, ‘distribution’, ‘hemisphere’] | 5 | BAGG Ens | |
| 119 | [‘effect’, ‘initial’, ‘axisymmetric’, ‘deviation’, ‘circularity’, ‘linear’, ‘large’, ‘deflection’, ‘load’, ‘deflection’, ‘response’, | 14 | BAGG Ens | |
| ‘cylinder’, ‘hydrostatic’, ‘pressure’] | ||||
| 120 | [‘previous’, ‘analysis’, ‘circumferential’, ‘thermal’, ‘buckling’, ‘circular’, ‘cylindrical’, ‘shell’, ‘unnecessarily’, | 13 | LDA | |
| ‘involve’, ‘assume’, ‘form’, ‘mode’] | ||||
| 126 | [‘thrust’, ‘vector’, ‘control’, ‘fluid’, ‘injection’, ‘dash’, ‘paper’] | 7 | LDA | |
| 165 | [‘stable’, ‘profile’, ‘compressible’, ‘boundary’, ‘layer’, ‘induced’, ‘move’, ‘wave’] | 8 | LDA | |
| 172 | [‘solution’, ‘blasius’, ‘problem’, ‘three’, ‘point’, ‘boundary’, ‘condition’] | 7 | BAGG Ens | |
| 184 | [‘work’, ‘small’, ‘oscillation’, ‘re’, ‘entry’, ‘motion’] | 6 | LDA | |
| 203 | [‘simple’, ‘empirical’, ‘method’, ‘estimate’, ‘pressure’, ‘distribution’, ‘cone’] | 7 | ADA Ens | |
| 204 | [‘viscous’, ‘effect’, ‘pressure’, ‘distribution’] | 4 | BAGG Ens | |
| 222 | [‘investigate’, ‘shear’, ‘buckling’, ‘stiffen’, ‘plate’] | 5 | LDA | |
| 223 | [‘paper’, ‘shear’, ‘buckling’, ‘unstiffened’, ‘rectangular’, ‘plate’, ‘shear’] | 7 | BAGG Ens | |
| CISI | 13 | [‘criterion’, ‘developed’, ‘objective’, ‘evaluation’, ‘information’, ‘retrieval’, ‘dissemination’, ‘system’] | 8 | BAGG Ens |
| 19 | [‘technique’, ‘machine’, ‘match’, ‘machine’, ‘search’, ‘system’, ‘cod’, ‘match’, ‘method’] | 9 | BAGG Ens | |
| 28 | [‘computerize’, ‘information’, ‘system’, ‘field’, ‘related’, ‘chemistry’] | 6 | ADA Ens | |
| 34 | [‘method’, ‘cod’, ‘computerize’, ‘index’, ‘system’] | 5 | LDA | |
| 44 | [‘presently’, ‘fifty’, ‘technical’, ‘journal’, ‘publish’, ‘average’, ‘million’, ‘article’, ‘year’, ‘attempt’, ‘cope’, | 18 | BAGG Ens | |
| ‘scientific’, ‘publication’, ‘term’, ‘analysis’, ‘control’, ‘storage’, ‘retrieval’] | ||||
| 98 | [‘online’, ‘retrieval’, ‘system’, ‘difficult’, ‘user’, ‘heterogeneity’, ‘complexity’, ‘investigation’, ‘concerned’, ‘concept’, | 33 | BAGG Ens | |
| ‘computer’, ‘interface’, ‘mean’, ‘simplify’, ‘access’, ‘operation’, ‘heterogeneous’, ‘bibliographic’, …] | ||||
| CACM | 7 | [‘interested’, ‘distribute’, ‘concurrent’, ‘program’, ‘process’, ‘communicate’, ‘message’, ‘passing’, ‘area’, | 19 | LDA |
| ’include’, ‘fault’, ‘tolerance’, ‘technique’, ‘understand’, ‘correctness’, ‘algorithm’, ‘Fred’, ‘Schneider’, ‘dist’] | ||||
| 14 | [‘optimal’, ‘implementation’, ‘sort’, ‘algorithm’, ‘database’, ‘management’, ‘application’, ‘Kenneth’, ‘Wilson’, ‘sort’, | 13 | BAGG Ens | |
| ‘physic’, ‘Newman’, ‘database’] | ||||
| 28 | [‘information’, ‘packet’, ‘network’, ‘algorithm’, ‘rout’, ‘deal’, ‘topography’, ‘interested’, ‘hardware’, ‘Dean’, ‘jJgels’, ‘net’] | 12 | BAGG Ens | |
| 36 | [‘fast’, ‘algorithm’, ‘context’, ‘free’, ‘language’, ‘recognition’, ‘parse’, ‘juris’, ‘hartmanis’, ‘fast’, ‘lang’, ‘recog’, ‘parse’] | 13 | BAGG Ens | |
| 58 | [‘algorithm’, ‘statistical’, ‘package’, ‘anova’, ‘regression’, ‘square’, ‘generalize’, ‘linear’, ‘model’, ‘design’, ‘capability’, | 20 | LDA | |
| ‘formula’, ‘interest’, ‘student’, ‘test’, ‘Wilcoxon’, ‘sign’, ‘multivariate’, ‘component’, ‘include’] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ormeño, P.; Mendoza, M.; Valle, C. Topic Models Ensembles for AD-HOC Information Retrieval. Information 2021, 12, 360. https://doi.org/10.3390/info12090360
Ormeño P, Mendoza M, Valle C. Topic Models Ensembles for AD-HOC Information Retrieval. Information. 2021; 12(9):360. https://doi.org/10.3390/info12090360
Chicago/Turabian StyleOrmeño, Pablo, Marcelo Mendoza, and Carlos Valle. 2021. "Topic Models Ensembles for AD-HOC Information Retrieval" Information 12, no. 9: 360. https://doi.org/10.3390/info12090360
APA StyleOrmeño, P., Mendoza, M., & Valle, C. (2021). Topic Models Ensembles for AD-HOC Information Retrieval. Information, 12(9), 360. https://doi.org/10.3390/info12090360