
Semantically-Aware Retrieval of Oceanographic Phenomena Annotated on Satellite Images

 , ,
, ,  , ,
, ,  , and
, and 
Abstract
:1. Introduction
2. Background & Related Work
2.1. Marine Phenomena and Remote Sensing
2.1.1. Turbidity
2.1.2. Algal Blooms (Estimated by Chl-a Concentration)
2.1.3. Oil-Spill Detection
2.2. Marine Domain Ontologies
- Image metadata: this section includes predicates that describe image properties. A small number of metadata are included, such as time and area of acquisition, sensor, image mode, incidence angle.
- Elements of annotation: this section includes classes about patches, images, vectors used to describe an EO Image after the knowledge discovery step.
- Concepts about the land cover: this section includes an object visible in an EO image such as agriculture areas, bare grounds, forests, transport areas, urban areas, water bodies.
2.3. Semantic Image Retrieval
3. Methodology
3.1. Annotation of Marine Phenomena
3.1.1. Turbidity
3.1.2. Algal Blooms
3.1.3. Oil-Spill Detection
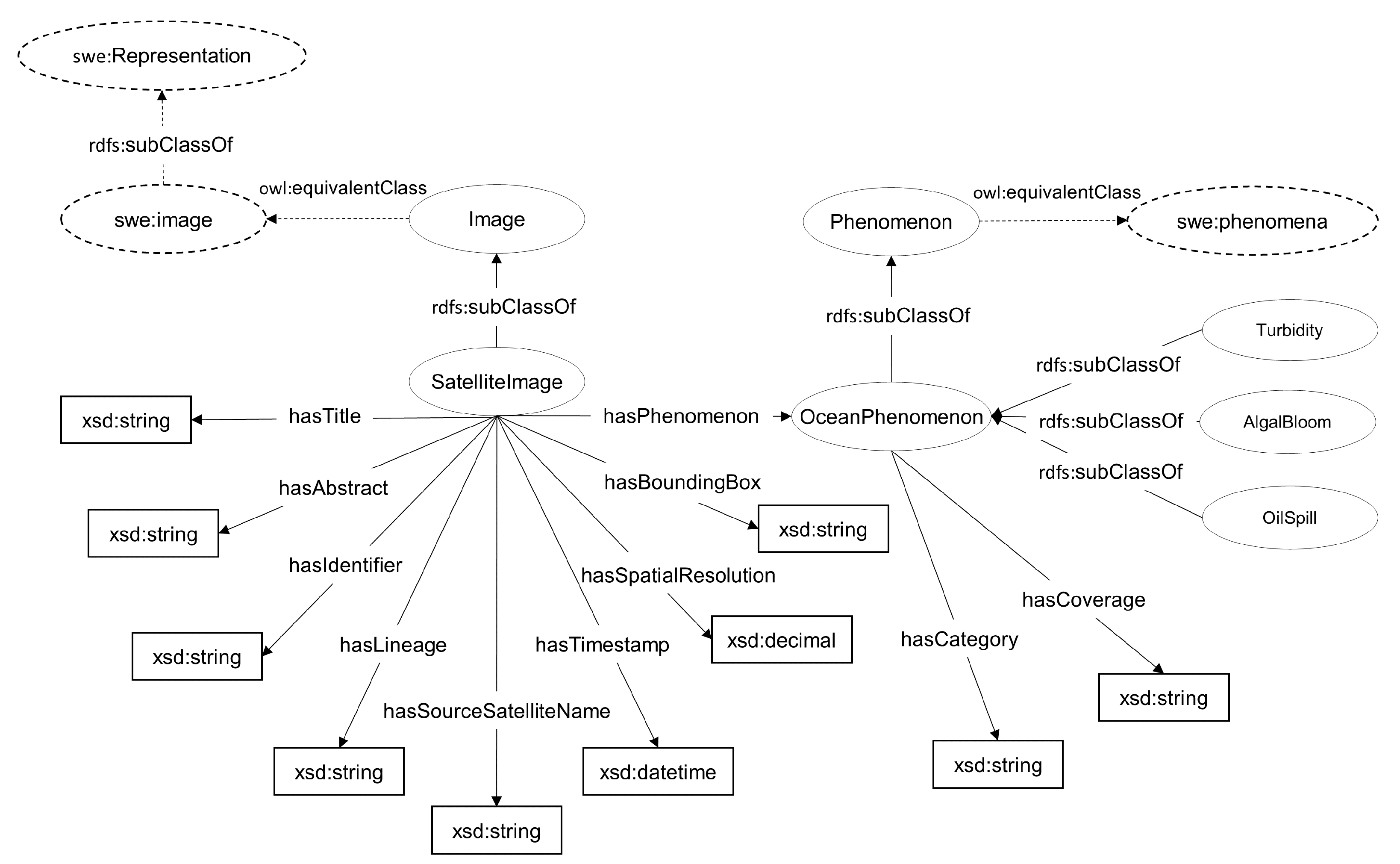
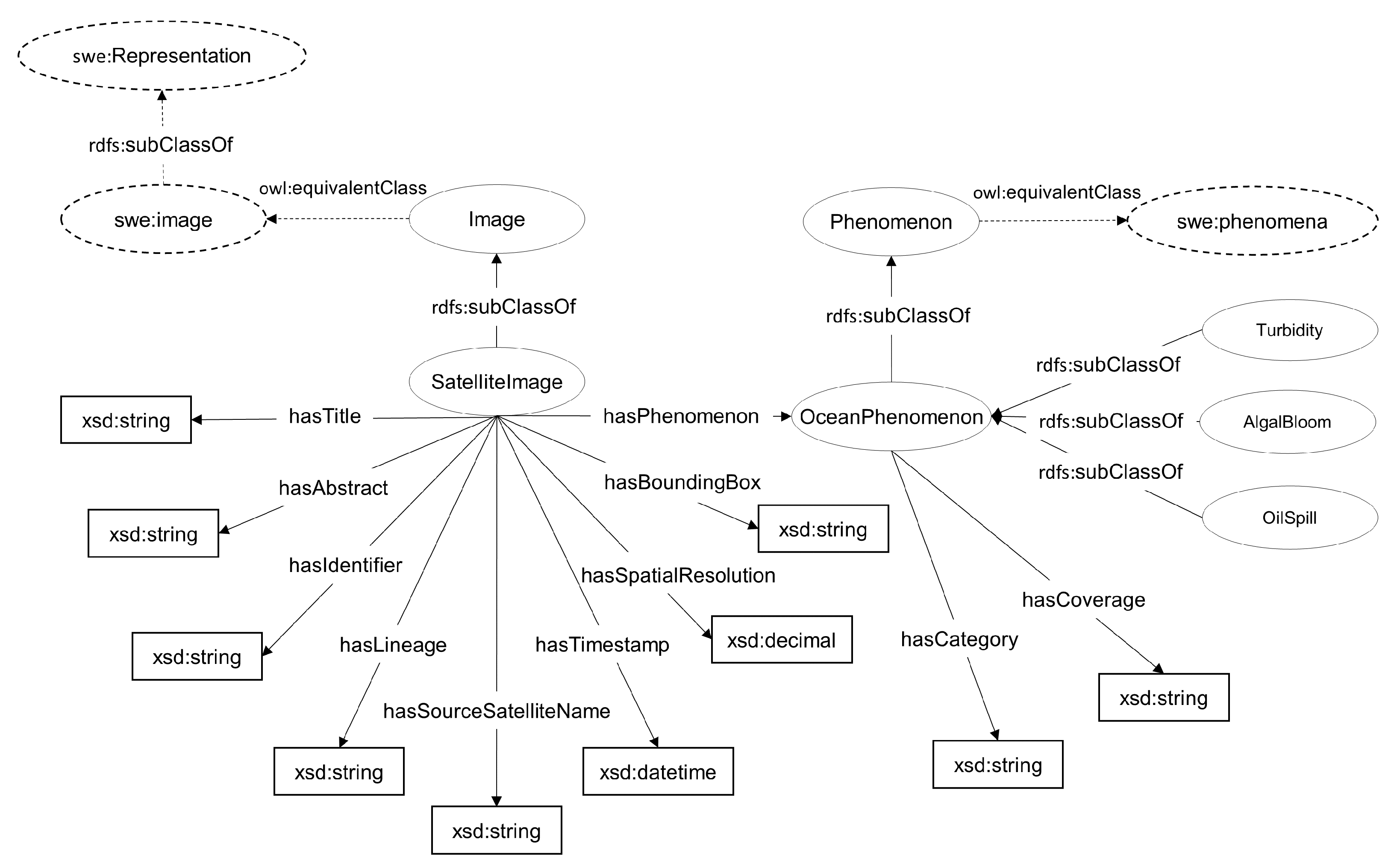
3.2. Ontology
- Title (property seo:hasTitle): the title assigned to the image.
- Identifier (property seo:hasIdentifier): a unique identifier of the image.
- Abstract (property seo:hasAbstact): textual description of the image.
- Timestamp (property seo:hasTimeStamp): the date the image was acquired.
- Lineage (property seo:hasLineage): contains textual information about the image, such as the process of its production.
- Spatial Resolution (property seo:hasSpatialResolution): a resolution value for the image.
- Bounding Box (property seo:hasBoundingBox): the spatial extent of the image in WKT (Well Known Text) format (https://www.ogc.org/standards/wkt-crs, accessed on 4 August 2021) using the WGS84 reference system.
- Satellite of provenience (property seo:hasSourceSatelliteName): the name of the satellite that provides the image.
- Phenomena (property seo:hasPhenomenon): a concept representing a phenomenon associated with the image.
- Turbidity (class seo:Turbidity): it refers to the cloudiness or haziness of a fluid caused by large numbers of individual particles. The concept is placed as subclass of seo:OceanPhenomenon and is linked with the SWEET ontology concept swe:turbidity current with an owl:equivalentClass relation.
- Algal Bloom (class seo:AlgalBloom): it refers to the rapid increase or accumulation in the population of algae in a water system. The concept is placed as subclass of seo:OceanPhenomenon and is linked with the SWEET ontology concept swe:algal bloom with an owl:equivalentClass relation.
- Oil Spill (class seo:OilSpill): it refers to areas where liquid petroleum is released into the environment, especially marine areas. The concept is placed as subclass of seo:OceanPhenomenon and is linked with the SWEET ontology concept swe:oil spill with an owl:equivalentClass relation.
- Category (Property seo:hasCategory): the category of a phenomenon (see Section 3.1), a value for characterizing the phenomenon.
- Coverage (Property seo:hasCoverage): the geometry of a phenomenon in WKT (Well Known Text) format using the WGS84 reference system.
3.3. Question Answering Module
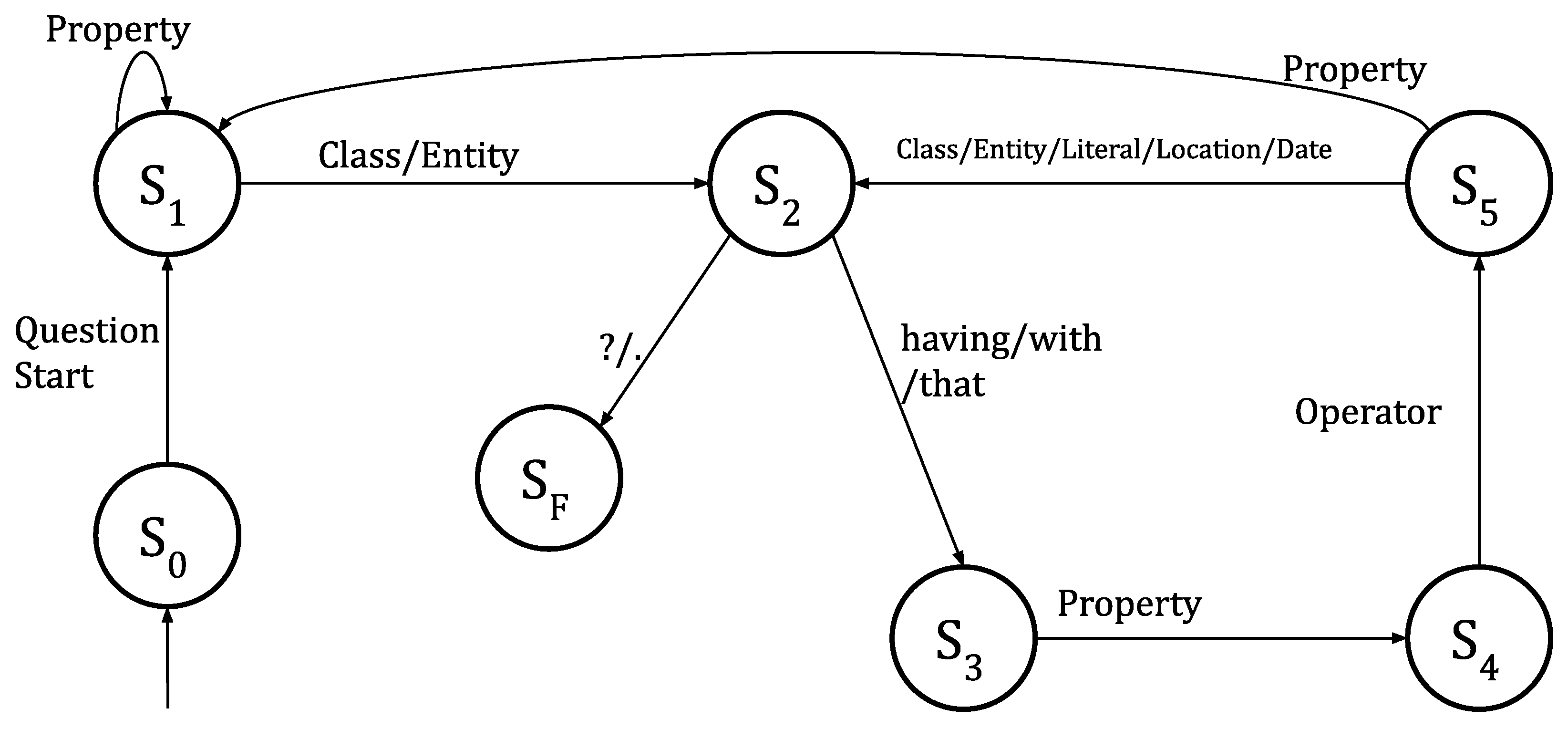
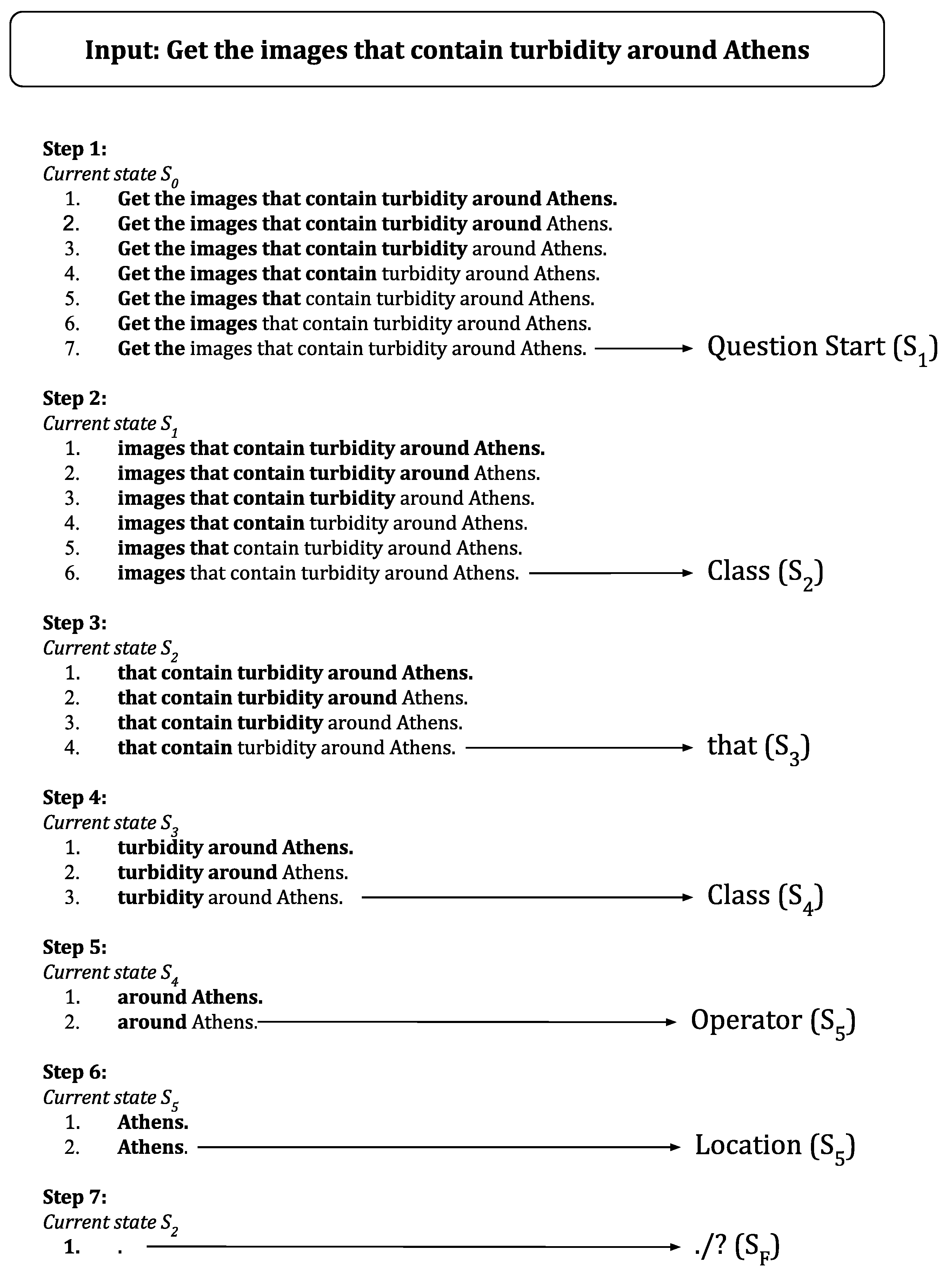
3.3.1. Extraction of Spatial Entities
- Module for the management of the user query in natural language;
- Module for the recognition of the geographical entities within the query;
- Geocoding module for the geographical entity;
- Module for the management of adverbs of place in the query;
- Module for parsing lexical dependencies between query words;
- Module for generating the custom output polygon.
3.3.2. Question Processing
4. Implementation
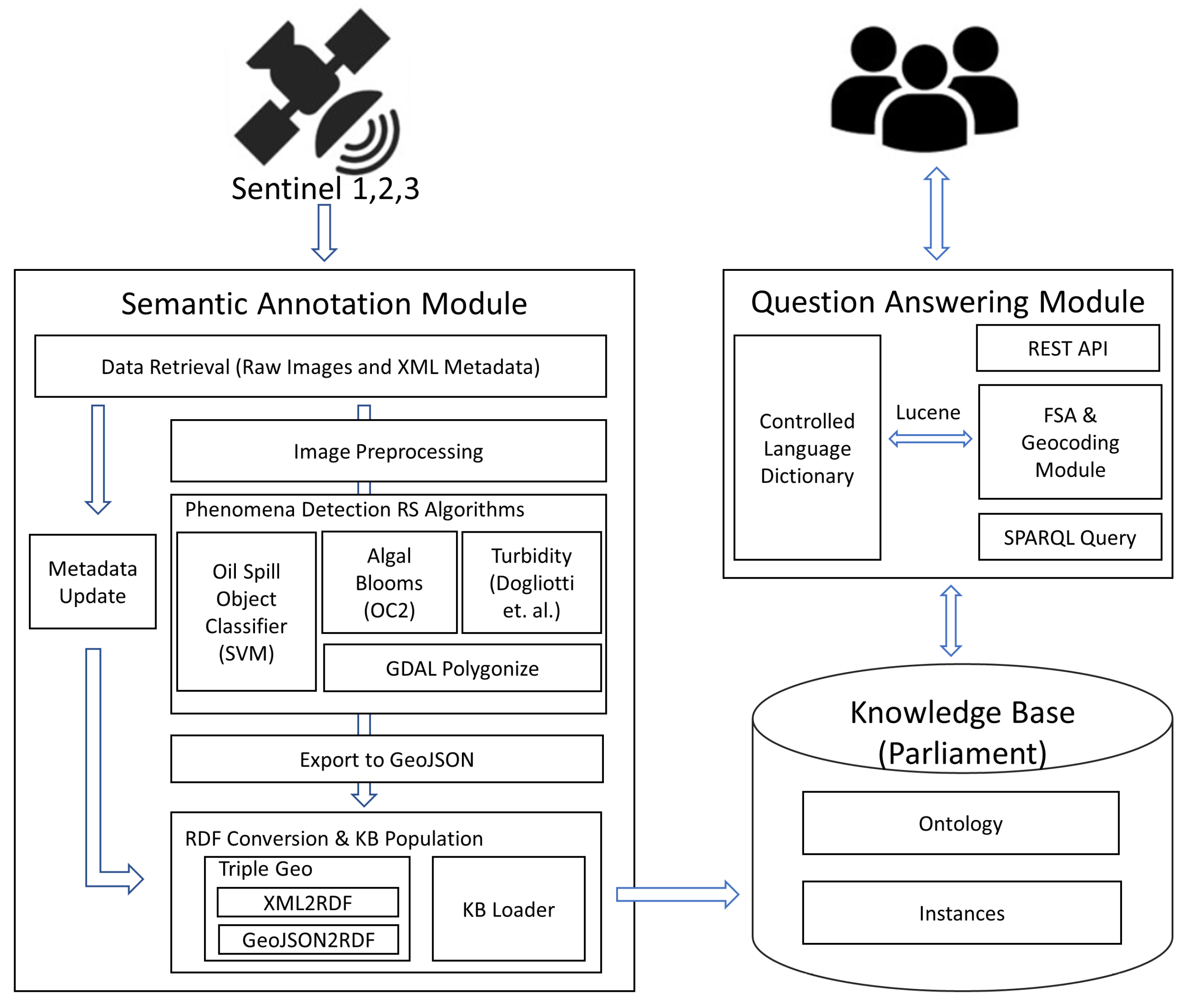
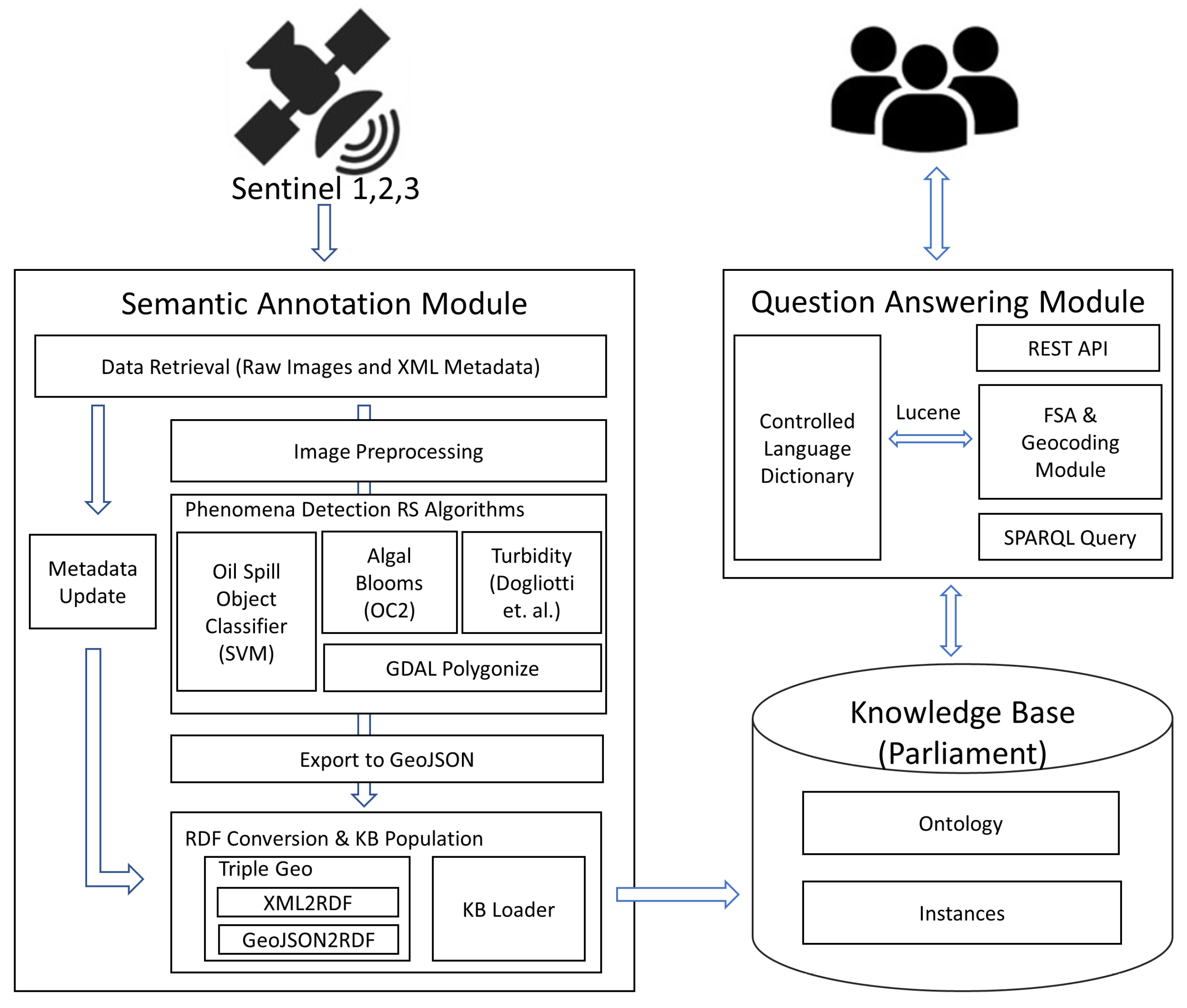
4.1. Semantic Annotation Module
- Image and XML metadata download;
- Image pre-processing (radiometric/atmospheric corrections, cloud masking, etc.);
- Phenomenon-specific image processing (see Section 3.1);
- Creation of phenomenon-specific raster map;
- Conversion of the raster map to vector (GeoJSON);
- Update of the INSPIRE compliant enriched metadata combining image metadata and phenomenon-specific processing results.
- An XML file containing the original and the updated metadata of the image. The original metadata file maintained generic metadata about the retrieved image and used the INSPIRE datasets and services in ISO/TS 19139 based XML format (https://inspire.ec.europa.eu/id/document/tg/metadata-iso19139, accessed on 4 August 2021). The updated metadata file extendd the original version during the image processing with additional application-specific elements.
- A GeoJSON file that maintains spatial and descriptive metadata about the identified phenomena within the image. Each phenomenon instance was characterized by (a) the spatial area it covers, that is, its geometry in Well-Known-Text (WKT) format using the WGS84 reference system and (b) the set of its descriptive properties as described in Section 3.1.
4.2. Knowledge Base
- Schema Level: Modeled the marine domain application concepts about phenomena that are present and interpretable in EO images and formalized as an ontology containing the semantic definition of the data and defining what properties each image and phenomenon had as described in Section 3.2.
- Instance Level: Contained the actual data for describing semantically annotated images and phenomena according to the schema.
4.2.1. Schema
- The ontology IRI was specified to http://seodwarf.eu/ontology/v1.0;
- The Pascal case capitalization style used for naming classes (e.g., SatelliteImage);
- The Camel case capitalization style used for naming properties (e.g., hasCoverage).
4.2.2. Instances
4.2.3. Endpoint
4.3. Question Answering Module
- getExpandedQuery, which was used internally to translate a natural language question into its equivalent SPARQL query; and
- getKBResults, which allowed user communication with SeMaRe by retrieving their NLP queries and responding with the appropriate answers.
5. Preliminary Evaluation
- the ease of use of the system, i.e., if the adoption of natural language actually helped the users to express their needs;
- the accuracy of the system, i.e., its ability to correctly retrieve instances when querying a knowledge base in which semantically annotated EO images and phenomena were described as RDF triples;
- the efficiency of the system in terms of response time.
5.1. Ease of Use Evaluation
- Gathering personal information, e.g., age and gender;
- Gathering information about the participant’s skills in IT and SPARQL;
- Participants were asked to interact with the system by freely querying the interface;
- Survey about the system, collecting feedback from the participants.
5.2. Accuracy & Efficiency Evaluation
- images that contained a phenomenon, optionally, for a given location and a given period of time;
- phenomena, optionally, for a given location and a given period of time;
- areas where a user specified threshold of parameters/index, i.e., phenomenon category, was reached.
- collect a real-word set of natural language queries asked to the system;
- define the subset of the relevant images for each query in order to compute the accuracy in terms of the classic precision and recall measures adopted in Information Retrieval.
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smeulders, A.W.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Hay, G.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A new name for a new discipline. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–89. [Google Scholar]
- Blaschke, T.; Hay, G.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.; Meer, F.; van der Werff, H.; Van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [Green Version]
- Arvor, D.; Belgiu, M.; Falomir, Z.; Mougenot, I.; Durieux, L. Ontologies to interpret remote sensing images: Why do we need them? GISci. Remote Sens. 2019, 56, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, P.; Lettmayer, P.; Blaschke, T.; Belgiu, M.; Wegenkittl, S.; Graf, R.; Lampoltshammer, T.; Andrejchenko, V. Towards a framework for agent-based image analysis of remote-sensing data. Int. J. Image Data Fusion 2015, 6, 115–137. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Tomljenovic, I.; Lampoltshammer, T.; Blaschke, T.; Höfle, B. Ontology-Based Classification of Building Types Detected from Airborne Laser Scanning Data. Remote Sens. 2014, 6, 1347–1366. [Google Scholar] [CrossRef] [Green Version]
- Gu, H.; Li, H.; Yan, L.; Liu, Z.; Blaschke, T.; Soergel, U. An Object-Based Semantic Classification Method for High Resolution Remote Sensing Imagery Using Ontology. Remote Sens. 2017, 9, 329. [Google Scholar] [CrossRef] [Green Version]
- Lang, S.; Hay, G.; Baraldi, A.; Tiede, D.; Blaschke, T. GEOBIA Achievements and Spatial Opportunities in the Era of Big Earth Observation Data. Int. J. Geo-Inf. 2019, 8, 474. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Tiede, D.; Wendt, L.; Sudmanns, M.; Lang, S. Transferable instance segmentation of dwellings in a refugee camp-integrating CNN and OBIA. Eur. J. Remote Sens. 2021, 54, 127–140. [Google Scholar] [CrossRef]
- Konstantinidou, E.; Kolokoussis, P.; Topouzelis, K.; Moutzouris-Sidiris, I. An open source approach for oil spill detection using Sentinel-1 SAR images. In Seventh International Conference on Remote Sensing and Geo-Information of Environment (RSCy2019); Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Papakonstantinou, A.; Stamati, C.; Topouzelis, K. Comparison of True-Color and Multispectral Unmanned Aerial Systems Imagery for Marine Habitat Mapping Using Object-Based Image Analysis. Remote Sens. 2020, 12, 554. [Google Scholar] [CrossRef] [Green Version]
- Kolokoussis, P.; Karathanassi, V. Oil Spill Detection and Mapping Using Sentinel 2 Imagery. J. Mar. Sci. Eng. 2018, 6, 4. [Google Scholar] [CrossRef] [Green Version]
- Kampouri, M.; Kolokoussis, P.; Argialas, D.; Karathanassi, V. Mapping of forest tree distribution and estimation of forest biodiversity using Sentinel-2 imagery in the University Research Forest Taxiarchis in Chalkidiki, Greece. Geocarto Int. 2019, 34, 1273–1285. [Google Scholar] [CrossRef]
- Ziokas, N.; Soulakellis, N.; Topouzelis, K. Use of Object Based Image Analysis in Very High-Resolution Images to Evaluate Buildings Damage after an Earthquake: The Case of Vryssa Settlement. In Proceedings of the 11th International Conference of the Hellenic Geographical Society (ICHGS-2018), Lavrion, Greece, 12–15 April 2018. [Google Scholar]
- Lawler, D. emTurbidity, Turbidimetry, and Nephelometry. InReference Module in Chemistry, Molecular Sciences and Chemical Engineering; Reedijk, J., Ed.; Elsevier: Waltham, MA, USA, 2016. [Google Scholar]
- Hellweger, F.L.; Schlosser, P.; Lall, U.; Weissel, J. Use of satellite imagery for water quality studies in New York Harbor, Estuar. Coast. Shelf Sci. 2004, 61, 437–448. [Google Scholar] [CrossRef]
- Garaba, S.; Badewien, T.; Braun, A.; Schulz, A.; Zielinski, O. Using ocean colour remote sensing products to estimate turbidity at the Wadden sea time series station Spiekeroog. J. Eur. Opt. Soc. Rapid Publ. 2014, 9, 140120. [Google Scholar] [CrossRef]
- Dogliotti, A.; Ruddick, K.; Nechad, B.; Doxaran, D.; Knaeps, E. A single algorithm to retrieve turbidity from remotely-sensed data in all coastal and estuarine waters. Remote Sens. Environ. 2015, 156, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Nechad, B.; Ruddick, K.; Park, Y. Calibration and validation of a generic multisens or algorithm for mapping of total suspended matter in turbid waters. Remote Sens. Environ. 2010, 114, 854–866. [Google Scholar] [CrossRef]
- Falkowski, P.G.; Raven, J.A. Aquatic Photosynthesis; Princeton University Press: Oxford, UK, 2013. [Google Scholar]
- Blondeau-Patissier, D.; Gower, J.; Dekker, A.; Phinn, S.; Brando, V. A review of ocean color remote sensing methods and statistical techniques for the detection, mapping and analysis of phytoplankton blooms in coastal and open oceans. Prog. Oceanogr. 2014, 123, 123–144. [Google Scholar] [CrossRef] [Green Version]
- Robinson, I. Measuring the Oceans from Space: The Principles and Methods of Satellite Oceanography; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Gordon, H.; Dennis, D.; James, M.; Warren, H. Phytoplankton Pigments from the Nimbus-7 Coastal Zone Color Scanner: Comparisons with Surface Measurements. Science 1980, 210, 63–66. [Google Scholar] [CrossRef]
- Kutser, T. Passive optical remote sensing of cyanobacteria and other intense phytoplankton blooms in coastal and inland waters. Int. J. Remote Sens. 2009, 30, 4401–4425. [Google Scholar] [CrossRef]
- Sathyendranath, S. Remote Sensing of Ocean Colour in Coastal, and Other Optically-Complex, Waters. In Reports of the International Ocean-Colour Coordinating Group; International Ocean Colour Coordinating Group (IOCCG): Dartmouth, NS, Canada, 2000. [Google Scholar]
- Morel, A.; Prieur, L. Analysis of variations in ocean color1. Limnol. Oceanogr. 1977, 22, 709–722. [Google Scholar] [CrossRef]
- Morel, A. Optical modeling of the upper ocean in relation to its biogenous matter content (case I waters). J. Geophys. Res. Ocean. 1988, 93, 10749–10768. [Google Scholar] [CrossRef] [Green Version]
- Dickey, T.; Lewis, M.; Chang, G. Optical oceanography: Recent advances and future directions using global remote sensing and in situ observations. Rev. Geophys. 2006, 44, 1–39. [Google Scholar] [CrossRef] [Green Version]
- Bowers, D.; Mitchelson-Jacob, E. Inherent Optical Properties of the Irish Sea Determined from Underwater Irradiance Measurements. Estuarine Coast. Shelf Sci. 1996, 43, 433–447. [Google Scholar] [CrossRef]
- Gitelson, A.; Gurlin, D.; Moses, W.; Barrow, T. A bio-optical algorithm for the remote estimation of the chlorophyll-a concentration in case 2 waters. Environ. Res. Lett. 2009, 4, 045003. [Google Scholar] [CrossRef]
- Moses, W.; Gitelson, A.; Berdnikov, S.; Saprygin, V.; Povazhnyi, V. Operational MERIS-based NIR-red algorithms for estimating chlorophyll-a concentrations in coastal waters—The Azov Sea case study. Remote Sens. Environ. 2012, 121, 118–124. [Google Scholar] [CrossRef] [Green Version]
- Shanmugam, P. A new bio-optical algorithm for the remote sensing of algal blooms in complex ocean waters. J. Geophys. Res. Ocean. 2011, 116, 4016. [Google Scholar] [CrossRef] [Green Version]
- Pahlevan, N.; Smith, B.; Schalles, J.; Binding, C.; Cao, Z.; Ma, R.; Alikas, K.; Kangro, K.; Gurlin, D.; Hà, N.; et al. Seamless retrievals of chlorophyll-a from Sentinel-2 (MSI) and Sentinel-3 (OLCI) in inland and coastal waters: A machine-learning approach. Remote Sens. Environ. 2020, 240, 111604. [Google Scholar] [CrossRef]
- Ansper, A.; Alikas, K. Retrieval of Chlorophyll a from Sentinel-2 MSI Data for the European Union Water Framework Directive Reporting Purposes. Remote Sens. 2019, 11, 64. [Google Scholar] [CrossRef] [Green Version]
- Misra, A.; Balaji, R. Simple Approaches to Oil Spill Detection Using Sentinel Application Platform (SNAP)-Ocean Application Tools and Texture Analysis: A Comparative Study. J. Indian Soc. Remote Sens. 2017, 45, 1065–1075. [Google Scholar] [CrossRef]
- Espedal, H. Detection of Oil Spill and Natural Film in the Marine Environment by Spaceborne Synthetic Aperture Radar. Ph.D. Thesis, Department of Physics, University of Bergen and Nansen Environment and Remote Sensing Center, Bergen, Norway, 1998. [Google Scholar]
- Brekke, C. Automatic Detection of Oil Spills by SAR Images: Dark Spot detection and Feature Extraction Report; Forsvarets Forskningsinstitutt: Kjeller, Norway, 2005. [Google Scholar]
- Topouzelis, K. Oil Spill Detection by SAR Images: Dark Formation Detection, Feature Extraction and Classification Algorithms. Sensors 2008, 8, 6642–6659. [Google Scholar] [CrossRef] [Green Version]
- Fonseca, F.; Egenhofer, M.; Agouris, P.; Camara, G. Using ontologies for integrated geographic information systems. Trans. GIS 2002, 6, 231–257. [Google Scholar] [CrossRef]
- Kauppinen, T.; de Espindola, G. Ontology-based modeling of land change trajectories in the brazilian amazon. In Proceedings of the Geoinformatik–GeoChange, Münster, Germany, 15–17 June 2011. [Google Scholar]
- Forestier, G.; Wemmert, C.; Puissant, A. Coastal image interpretation using background knowledge and semantics. Comput. Geosci. 2013, 54, 88–96. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Chen, J.; Li, Z.; Gong, F.; Chen, N. Ontology-Guided Image Interpretation for GEOBIA of High Spatial Resolution Remote Sense Imagery: A Coastal Area Case Study. ISPRS Int. J. Geo-Inf. 2017, 6, 105. [Google Scholar] [CrossRef] [Green Version]
- Almendros-Jiménez, J.M.; Domene, L.; Piedra-Fernández, J.A. A Framework for Ocean Satellite Image Classification Based on Ontologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1048–1063. [Google Scholar] [CrossRef]
- Raskin, R.G.; Pan, M.J. Knowledge representation in the semantic web for Earth and environmental terminology (SWEET). Comput. Geosci. 2005, 31, 1119–1125. [Google Scholar] [CrossRef]
- Vassiliadis, V.; Wielemaker, J.; Mungall, C. Processing OWL2 Ontologies using Thea: An Application of Logic Programming. In Proceedings of the 5th International Workshop on OWL: Experiences and Directions (OWLED 2009), Chantilly, VA, USA, 23–24 October 2009. [Google Scholar]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: Addendum 2000; European Environment Agency: Copenhagen, Denmark, 2000.
- Koubarakis, M.; Sioutis, M.; Kyzirakos, K.; Karpathiotakis, M.; Nikolaou, C.; Vassos, S.; Garbis, G.; Bereta, K.; Dumitru, O.; Espinoza-Molina, D.; et al. Building Virtual Earth Observatories Using Ontologies, Linked Geospatial Data and Knowledge Discovery Algorithms. In On the Move to Meaningful Internet Systems: OTM 2012; Meersman, R., Panetto, H., Dillon, T., Rinderle-Ma, S., Dadam, P., Zhou, X., Pearson, S., Ferscha, A., Bergamaschi, S., Cruz, I.F., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7566. [Google Scholar]
- Koubarakis, M.; Datcu, M.; Kontoes, C.; Di Giammatteo, U.; Manegold, S.; Klien, E. TELEIOS: A database-powered virtual earth observatory. Proc. VLDB Endow. 2012, 5, 2010–2013. [Google Scholar] [CrossRef]
- Veganzones, M.A.; Maldonado, J.O.; Graña, M. On Content-Based Image Retrieval Systems for Hyperspectral Remote Sensing Images. In Computational Intelligence for Remote Sensing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 125–144. [Google Scholar]
- Dumitru, C.O.; Molina, D.E.; Cui, S.; Singh, J.; Quartulli, M.; Datcu, M. KDD Concepts and Methods Proposal: Report & Design Recommendations; Del. 3.1, FP7project TELEIOS; DLR: Wessling, Geramny, 2011.
- Maheshwary, P.; Namita, S. Prototype System for Retrieval of Remote Sensing Images based on Color Moment and Gray Level Co-Occurrence Matrix. Int. J. Comput. Sci. Issues 2009, 3, 20–23. [Google Scholar]
- Ruan, N.; Huang, N.; Hong, W. Semantic-Based Image Retrieval in Remote Sensing Archive: An Ontology Approach. In Proceedings of the 2006 IEEE International Symposium on Geoscience and Remote Sensing, Denver, CO, USA, 31 July–4 August 2006; Volume 1, pp. 2888–2891. [Google Scholar]
- Li, Y.; Bretschneider, T.R. Semantic-Sensitive Satellite Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2007, 45, 853–860. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Zhang, L.; Li, P.; Lin, H. Remotely sensed image retrieval based on region-level semantic mining. EURASIP J. Image Video Process. 2012, 2021, 4. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Wan, Q.; Gu, L.; Song, T. Remote-sensing image retrieval by combining image visual and semantic features. Int. J. Remote Sens. 2013, 34, 4200–4223. [Google Scholar] [CrossRef]
- Datcu, M.; Daschiel, H.; Pelizzari, A.; Quartulli, M.; Galoppo, A.; Colapicchioni, A.; Pastori, M.; Seidel, K.; Marchetti, P.; D’Elia, S. Information mining in remote sensing image archives: System concepts. IEEE Trans. Geosci. Remote Sens. 2004, 41, 2923–2936. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Narayanan, R.M. Integrated spectral and spatial information mining in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 673–685. [Google Scholar]
- Aksoy, S.; Koperski, K.; Tusk, C.; Marchisio, G.; Tilton, J. Learning bayesian classifiers for scene classification with a visual grammar. IEEE Trans. Geosci. Remote Sens. 2005, 43, 581–589. [Google Scholar] [CrossRef] [Green Version]
- Tiede, D.; Baraldi, A.; Sudmanns, M.; Belgiu, M.; Lang, S. Architecture and prototypical implementation of a semantic querying system for big Earth observation image bases. Eur. J. Remote Sens. 2017, 50, 452–463. [Google Scholar] [CrossRef] [PubMed]
- Androutsopoulos, I.; Ritchie, G.D.; Thanisch, P. Natural language interfaces to databases–an introduction. Nat. Lang. Eng. 1995, 1, 29–81. [Google Scholar] [CrossRef] [Green Version]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Lopez, V.; Unger, C.; Cimiano, P.; Motta, E. Evaluating question answering over linked data. Web Semant. Sci. Serv. Agents World Wide Web 2013, 21, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Waldinger, R.J.; Appelt, D.E.; Dungan, J.L.; Fry, J.; Hobbs, J.R.; Israel, D.J.; Jarvis, P.; Martin, D.L.; Riehemann, S.; Stickel, M.E.; et al. Deductive Question Answering from Multiple Resources. New Dir. Quest. Answ. 2004, 2004, 253–262. [Google Scholar]
- Luque, J.; Ferrés, D.; Hernando, J.; Mariño, J.B.; Rodríguez, H. GeoVAQA: A voice activated geographical question answering system. In Proceedings of the Actas de las IV Jornadas en Tecnolog´ıa del Habla (4JTH), Zaragoza, Spain, 8–10 November 2006. [Google Scholar]
- Buscaldi, D. Resource Integration for Question Answering and Geographical Information Retrieval; Research Project Report; The Department of Information Systems and Computation, Polytechnic University of Valencia: Valencia, Spain, 2007; Available online: http://users.dsic.upv.es/~{}prosso/resources/BuscaldiDEA.pdf (accessed on 4 August 2021).
- Younis, E.M.; Jones, C.B.; Tanasescu, V.; Abdelmoty, A.I. Hybrid geo-spatial query methods on the Semantic Web with a spatially-enhanced index of DBpedia. In Proceedings of the International Conference on Geographic Information Science, Columbus, OH, USA, 18–21 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 340–353. [Google Scholar]
- Bereta, K.; Koubarakis, M. Ontop of geospatial databases. In Proceedings of the International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 37–52. [Google Scholar]
- Kyzirakos, K.; Karpathiotakis, M.; Koubarakis, M. Strabon: A semantic geospatial DBMS. In Proceedings of the International Semantic Web Conference, Boston, MA, USA, 11–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 295–311. [Google Scholar]
- Punjani, D.; Singh, K.; Both, A.; Koubarakis, M.; Angelidis, I.; Bereta, K.; Beris, T.; Bilidas, D.; Ioannidis, T.; Karalis, N.; et al. Template-based question answering over linked geospatial data. In Proceedings of the 12th Workshop on Geographic Information Retrieval, Seattle, WA, USA, 6 November 2018; pp. 1–10. [Google Scholar]
- Salas, J.; Harth, A. Finding spatial equivalences accross multiple RDF datasets. In Proceedings of the Terra Cognita Workshop on Foundations, Technologies and Applications of the Geospatial Web, Citeseer, Bonn, Germany, 23–27 October 2011; pp. 114–126. [Google Scholar]
- Vanhellemont, Q.; Ruddick, K. Atmospheric correction of metre-scale optical satellite data for inland and coastal water applications. Remote Sens. Environ. 2018, 216, 586–597. [Google Scholar] [CrossRef]
- Lee, Z.; Carder, K.; Arnone, R. Deriving inherent optical properties from water color: A multiband quasi-analytical algorithm for optically deep waters. Appl. Opt. 2002, 41, 5755–5772. [Google Scholar] [CrossRef]
- Poveda-Villalón, M. A reuse-based lightweight method for developing linked data ontologies and vocabularies. In Proceedings of the Extended Semantic Web Conference, Heraklion, Crete, Greece, 27–31 May 2012; Springer: Berlin, Germany, 2012; pp. 833–837. [Google Scholar]
- Castro, G. Vicinity d2. 2: Detailed Specification of the Semantic Model; Technical Report; Universidad Politécnica de Madrid (UPM): Madrid, Spain, 2017; Available online: https://vicinity2020.eu/vicinity/node/229 (accessed on 4 August 2021).
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C.D. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Mazzeo, G.M.; Zaniolo, C. CANaLI: A System for Answering Controlled Natural Language Questions on RDF Knowledge Bases; Technical Report; EDBT 2016; University of California: Los Angeles, CA, USA, 2016. [Google Scholar]
- Hopcroft, J.E.; Motwani, R.; Ullman, J.D. Introduction to automata theory, languages, and computation. ACM Sigact News 2001, 32, 60–65. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Battle, R.; Kolas, D. Enabling the geospatial Semantic Web with Parliament and GeoSPARQL. Semant. Web 2012, 3, 355–370. [Google Scholar] [CrossRef]
- Bellini, P.; Nesi, P. Performance assessment of RDF graph databases for smart city services. J. Vis. Lang. Comput. 2018, 45, 24–38. [Google Scholar] [CrossRef]
- Garbis, G.; Kyzirakos, K.; Koubarakis, M. Geographica: A Benchmark for Geospatial RDF Stores (Long Version). In Proceedings of the The Semantic Web—ISWC 2013, Sydney, NSW, Australia, 21–25 October 2013; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2013; Volume 8219. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Low Level Quantitative Categories | High Level Qualitative Categories |
|---|---|
| <1 FNU | VERY LOW |
| 1–10 FNU | LOW |
| 10–50 FNU | MODERATE |
| 50–100 FNU | HIGH |
| >100 FNU | VERY HIGH |
| Low Level Quantitative Categories | High Level Qualitative Categories |
|---|---|
| <1 mg/L | NOT SIGNIF. |
| 1–5 mg/L | VERY LOW |
| 5–10 mg/L | LOW |
| 10–20 mg/L | MODERATE |
| 20–40 mg/L | HIGH |
| >40 mg/L | VERY HIGH |
| High Level Categories |
|---|
| OIL-SPILL |
| LOOK-ALIKE |
| SEAWATER |
| Adverb | km | Adverb | km |
|---|---|---|---|
| near | 5 | far | 25 |
| above | 10 | nearby | 5 |
| around | 15 | there | 5 |
| about | 7 | here | 5 |
| down | 10 | up | 10 |
| in | 5 | below | 10 |
| on | 10 | east | 10 |
| over | 10 | inside | 5 |
| under | 10 | outside | 15 |
| away | 15 | - | - |
| Statistic | Quantity | Statistic | Quantity |
|---|---|---|---|
| Total Images | 165 | Images with turbidity | 47 |
| Annotated images | 159 | Turbidity phenomena | 3791 |
| Total triples | 103,673 | Avg. turbidity phenomena per image | 80 |
| Avg. triples per image | 628 | Images with oil spills | 67 |
| Total Phenomena | 29,099 | Oil spill phenomena | 17,981 |
| Avg. phenomena per image | 176 | Avg. oil spill phenomena per image | 268 |
| Distinct image dates | 20 | Images with algal bloom | 45 |
| Algal bloom phenomena | 7327 | ||
| Avg. algal bloom phenomena per image | 162 |
| SN | Results (#) | Time (s) | ||
|---|---|---|---|---|
| 1 | Q | Find all the available images | 165 | 4 |
| S | SELECT DISTINCT ?s WHERE { GRAPH <http://seodwarf.eu/triples> { ?s seo:hasIdentifier ?o }} | |||
| 2 | Q | Get the phenomena found in the image with the identifier seo:S2A_MSI_2019_11_21_09_43_11_ T33SWB_t_dogliotti | 223 | 3 |
| S | SELECT DISTINCT ?s ?p ?o WHERE { GRAPH <http://seodwarf.eu/triples>{ <seo:S2A_MSI_2019_11_21_09_43_11_ T33SWB_t_dogliotti> seo:hasPhenomenon ?s. ?s ?p ?o }} | |||
| 3 | Q | Get all the images that contain turbidity phenomena | 47 | 5 |
| S | SELECT DISTINCT ?s WHERE { GRAPH <http://seodwarf.eu/triples>{ ?s seo:hasPhenomenon ?o . ?o a seo:Turbidity .}} | |||
| 4 | Q | Get images that contain turbidity phenomena in Bari | 10 | 7 |
| S | SELECT distinct ?s WHERE{ GRAPH <http://seodwarf.eu/triples>{ ?s seo:hasPhenomenon ?o. ?s seo:hasBoundingBox ?g . FILTER (geof:sfOverlaps(?g,"POLYGON(( 15.08... 39.77..., 15.08... 42.46... , 18.65... 42.46..., 18.65... 39.77... , 15.08... 39.77...))" ^^<http://www.opengis.net/ont/geosparql#wktLiteral>)) ?o rdf:type seo:Turbidity. }} | |||
| 5 | Q | Find images that contain turbidity phenomena happened after 22 November 2019 | 25 | 5 |
| S | SELECT DISTINCT ?s WHERE { GRAPH <http://seodwarf.eu/triples> { ?s seo:hasTimestamp ?d. ?s seo:hasPhenomenon ?o. ?o a seo:Turbidity. FILTER(str(?d) >"2019-11-22")}} | |||
| 6 | Q | Get turbidity phenomena near Bari happened after 01 November 2019 | 6 | 35 |
| S | SELECT DISTINCT ?s ?p ?o ?o1 WHERE{ GRAPH <http://seodwarf.eu/triples> { ?s seo:hasTimestamp ?d. ?s seo:hasPhenomenon ?o. ?o a seo:Turbidity. ?o seo:hasPhenomenoCoverage ?g. ?o ?p ?o1. FILTER (str(?d) >"22019-11-01"&& geof:sfIntersects(?g,"POLYGON((15.08... 39.77... , 15.08... 42.46... , 18.65.. 42.46.. , 18.65... 39.77... ,15.08... 39.77...))"^^<http://www.opengis.net/ont/geosparql#wktLiteral>))}} | |||
| 7 | Q | Get the turbidity phenomena areas with value ’50-100 FNU’ | 47 | 4 |
| S | SELECT DISTINCT ?o WHERE { GRAPH <http://seodwarf.eu/triples>{ ?s seo:hasClass "50-100 FNU". ?s seo:hasPhenomenonCoverage ?o.}} |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopsachilis, V.; Siciliani, L.; Polignano, M.; Kolokoussis, P.; Vaitis, M.; de Gemmis, M.; Topouzelis, K. Semantically-Aware Retrieval of Oceanographic Phenomena Annotated on Satellite Images. Information 2021, 12, 321. https://doi.org/10.3390/info12080321
Kopsachilis V, Siciliani L, Polignano M, Kolokoussis P, Vaitis M, de Gemmis M, Topouzelis K. Semantically-Aware Retrieval of Oceanographic Phenomena Annotated on Satellite Images. Information. 2021; 12(8):321. https://doi.org/10.3390/info12080321
Chicago/Turabian StyleKopsachilis, Vasilis, Lucia Siciliani, Marco Polignano, Pol Kolokoussis, Michail Vaitis, Marco de Gemmis, and Konstantinos Topouzelis. 2021. "Semantically-Aware Retrieval of Oceanographic Phenomena Annotated on Satellite Images" Information 12, no. 8: 321. https://doi.org/10.3390/info12080321
APA StyleKopsachilis, V., Siciliani, L., Polignano, M., Kolokoussis, P., Vaitis, M., de Gemmis, M., & Topouzelis, K. (2021). Semantically-Aware Retrieval of Oceanographic Phenomena Annotated on Satellite Images. Information, 12(8), 321. https://doi.org/10.3390/info12080321