1. Introduction
In recent years, considerable terrorism-related activity, including propaganda dissemination, recruitment and training, finance raising, and hate spreading towards specific social groups, has been observed in various online platforms [
1]. At the same time, several advanced methods have been developed that can analyze online textual content and extract information of interest, such as affiliations towards terrorist groups and information related to terrorist events [
2,
3]. Such analysis can lead to the identification of key information in the fight against crime and terrorism; for instance, the early detection and analysis of crime- and terrorism-related information exchanged in online communities can promote the efficient resource allocation towards mitigating serious incidents.
The first step in this process is the detection of content of interest, and, thus far, several works have focused on developing effective classification frameworks suitable for distinguishing between terrorism vs. non-terrorism [
3] or extremism vs. non-extremism content [
2], among others. These methods are more oriented towards detecting suspicious content, but without focusing on the significant changes that take place over time. Such an assessment can be performed using change point detection (CPD) methods applied on suitably constructed time series which can serve as indicators of terrorism or crime activity. More specifically, one can detect significant changes in the time series of posts related to terrorism and hate speech; the position of these changes may reflect changes in the attitude towards and/or engagement with terrorism-related activities and events that trigger users of social media platforms/forums to display a more intense online activity in the vicinity of these time points. Overall, the idea of using a CPD method in time series of terrorism- or hate speech-related posts can be seen as an alternative way to identify links between online activity and terrorism.
Towards this direction, this paper proposes a terrorism-related change point detection framework which builds on univariate and multivariate time series. Specifically, this framework facilitates the identification of points in time where statistically significant changes occur regarding the underlying data. By exploiting the temporal evolution of several indicators, such points constitute structural breaks in the behavior of the time series and may indicate the occurrence of important events where attention should be paid to. Moreover, in the case of multivariate CPD, possible correlations existing between the time series of different indicators could also be exploited.
In general, CPD methods are divided into two main categories:
online methods [
4] that aim to detect changes in real-time and
offline methods [
5] that retrospectively detect changes when considering historical data. For example, if data consisting of terrorism-related content or hate speech are considered as underlying data for the CPD algorithms, then the estimated change points based on the offline methods could offer a useful statistical analysis of such data to identify patterns and maximize the trade off between correctly identified change points and false alarms, whereas, in the case of online methods, the estimated time locations of structural breaks could enable interested parties (e.g., law enforcement) to respond in a timely manner with the aim of preventing possible radicalization, terrorist or criminal activities. In this work, our interest lies on the offline methods.
Overall, the main contribution of this work is the adoption of a change point detection method to estimate the time locations of statistically significant changes in terrorism-related time series based on a set of indicators for an effective analysis of trends and changes in a criminal context. Specifically, the detection of change points is performed in univariate as well as multivariate time series attempting to exploit possible correlations that may exist between the time series of different indicators. The presence of terrorism-related content and the expression of hate speech are detected on the basis of state-of-the-art deep learning methods (namely, Convolutional Neural Networks (CNNs)) and are used as inputs in the CPD algorithm. The evaluation carried out on data collected from a jihadist forum showcases the appropriateness of the proposed terrorism-related change point detection framework to identify changes at time locations where more attention could possibly be given. The satisfactory performance can be attributed to its ability to detect structural breaks in the time series—either univariate or multivariate—based on the time evolution of their statistical properties. To the best of our knowledge, this is the first time that change point detection algorithms are combined with the frequencies of online textual data classified as related to terrorism and/or hate speech based on well-established classification models.
The remainder of the paper is structured as follows. In
Section 2, we present a brief overview of the classification and change point detection methods. In
Section 3, we detail the specific setup of the proposed pipeline, whereas, in
Section 4, we exhibit its applicability. In
Section 5, we discuss the results. Finally, in
Section 6, we summarize our main findings, argue on possible limitations of the proposed framework and provide future directions.
2. Related Work
This section reviews related work, focusing first on change point detection methods and then presenting commonly used text classification methods whose output can be the basis for effectively detecting statistically significant changes in the behavior of a time series.
Change Point Detection (CPD). Regarding the application of CPD methods in online sources (e.g., social media and Surface/Dark Web), most existing works consider Twitter data. Change point algorithms applied to time series related to Twitter posts typically aim to discover the occurrence of events of interest that could be associated with changes in the structural behavior of the time series. For example, a nonparametric method for change point detection via density ratio estimation has been developed for tracking the degree of popularity of a given topic by monitoring the frequency of selected words [
6]. Moreover, change points have been detected in Twitter streams using temporal clusters of hashtags in online conversations related to specific events [
7]. CPD methods have also been combined with the outcomes of sentiment analysis in Twitter posts where the estimation of change points includes the detection of changes related to significant events [
8]. Additionally, three time series produced based on tweets with positive, negative and neutral sentiment, respectively, have been used as input to change point detection towards estimating correlations among the different sentiments [
9].
Concerning the use of CPD methods in terrorism-related data, the Noordin Top terrorist network data from 2001 to 2010 have been analyzed to detect significant changes in the evolution of their structure using a social network change detection method [
10]. Moreover, a method for multiple change point detection in multivariate time series has been applied in a time series produced by the counts of terrorism events across twelve global regions [
11]. Finally, a marked point process framework has been proposed to model the frequency and the impact of terrorist incidents based on change point analysis to search for timestamps where the process undergoes significant changes [
12].
In this work, change point detection is identified as a tool to detect changes in the behavior of the time series that may indicate the occurrence of events where attention should be paid to. It is applied to terrorism-related online content, by also considering the presence of hate speech. This is achieved building upon well-established deep learning-based classification models.
Text Classification. The detection of deviant content (such as terrorism-related, extremist or abusive content) in online platforms is often addressed as a classification problem. For example, a content analysis framework has been developed in order to identify extremist-related conversations on Twitter [
2]. In a similar direction, focusing on the Islamic State of Iraq and al-Sham (ISIS), content collected from social media sources has been utilized for the automatic detection of extremism propaganda [
13]. Finally, a lot of effort has been placed in detecting abusive behaviors in general, such as racist and sexist content [
14] or hate speech from content extracted from the white supremacist Stormfront forum [
15].
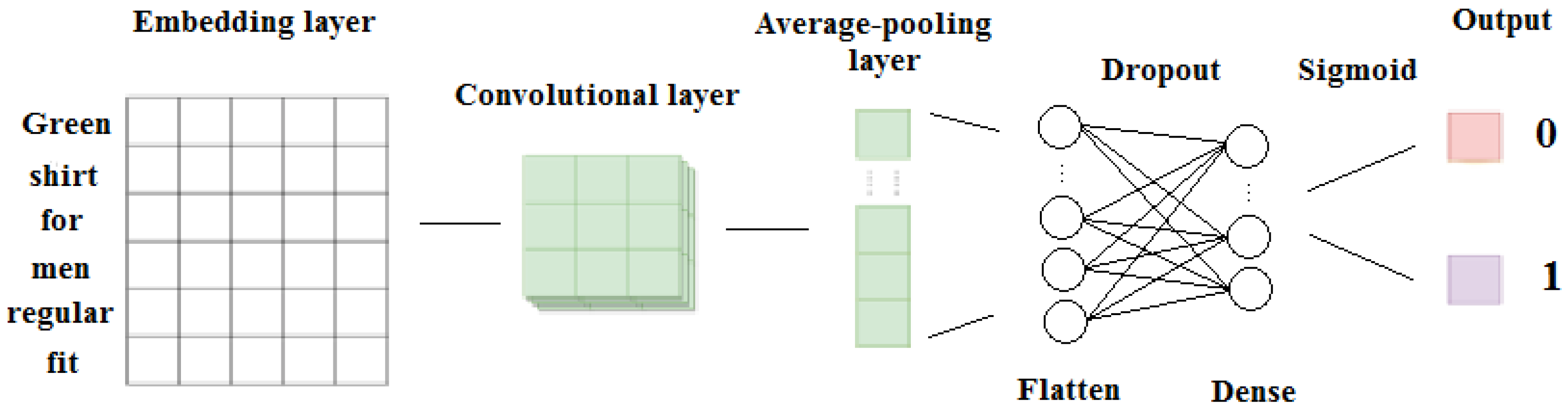
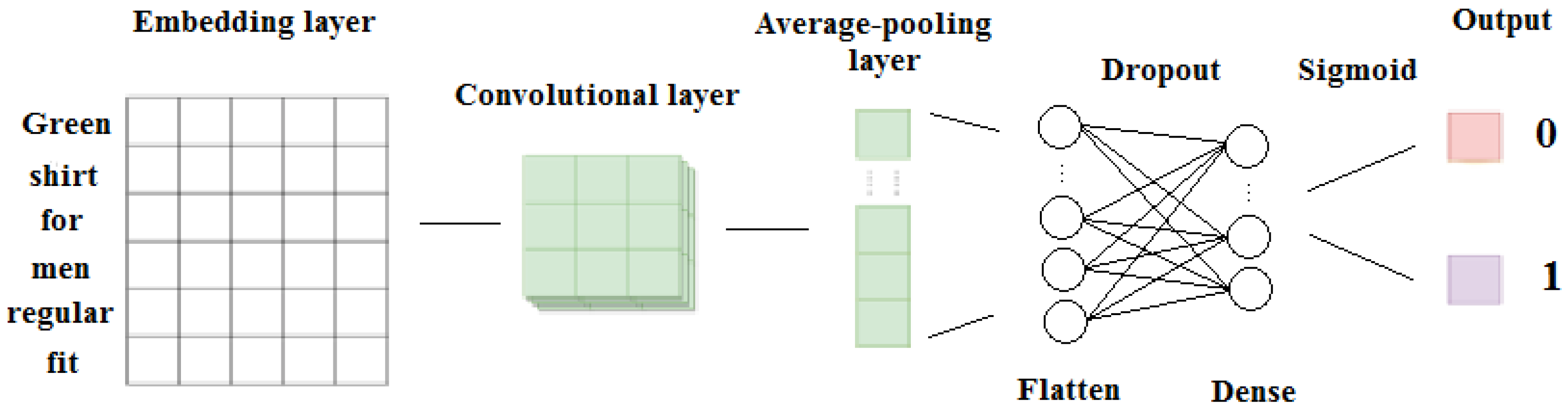
Towards the development of effective classification methods, deep learning has been extensively used, with Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) methods being among the most popular ones. CNNs were originally developed to further improve image processing, resulting in groundbreaking results in recognizing objects from a pre-defined list [
16]. Due to their performance in image processing tasks, CNNs gained a lot of attention and were thus subsequently applied in various Natural Language Processing (NLP) tasks, such as text classification or categorization [
17], sentiment analysis [
18] and machine translation [
19]. In addition to CNNs, RNNs have been particularly used in NLP tasks [
20]. The main difference between the two lies in the ability of RNNs to process data that come in sequences, e.g., sentences. Specifically, they analyze a text word by word and store the semantics of all the previous text in a fixed-size hidden layer [
21]. Detecting terrorism-related content or the expression of hate speech in the online world can constitute an important source of knowledge for early detection of threatening situations (such as manifestation of terrorist attacks). To this end, in this work, commonly used deep learning methods are considered to develop effective text classification models, with particular focus on distinguishing between: (i) crime- and terrorism-related activities (
terrorism-related classification model); and (ii) the expression of hate speech (
hate speech classification model) that constitutes an indirect way of expressing violence towards a group of people (e.g., minorities). The valuable knowledge that is extracted from both the terrorist and hate speech classification models is used then as the basis of the proposed terrorism-related change point detection framework.
4. Results
This section illustrates the applicability and performance of the proposed terrorism-related change point detection framework, when applied to the Ansar1 dataset.
Extraction of indicators based on the constructed classification models. As already mentioned, both terrorism- and hate speech-related indicators are used as input to the proposed terrorism-related change point detection framework. To this end, we first exploit the classification models presented in
Section 3.1, i.e., the terrorism and hate speech ones, to characterize texts as belonging to the terrorism or non-terrorism class and containing hate speech or not. The output is then exploited by the change point detection algorithm to ultimately detect previously unknown change points in the related time series that probably signify the occurrence of events of interest.
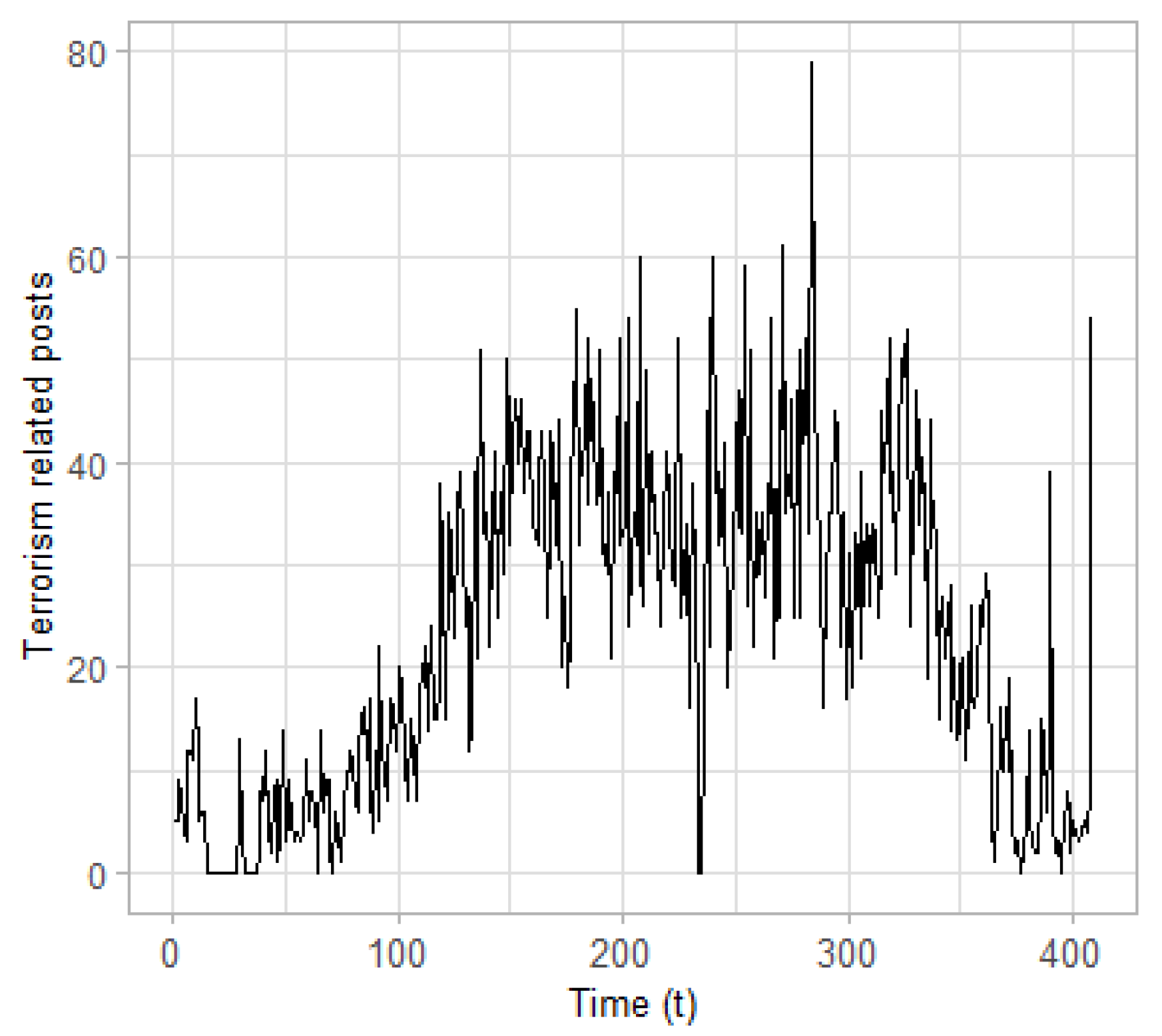
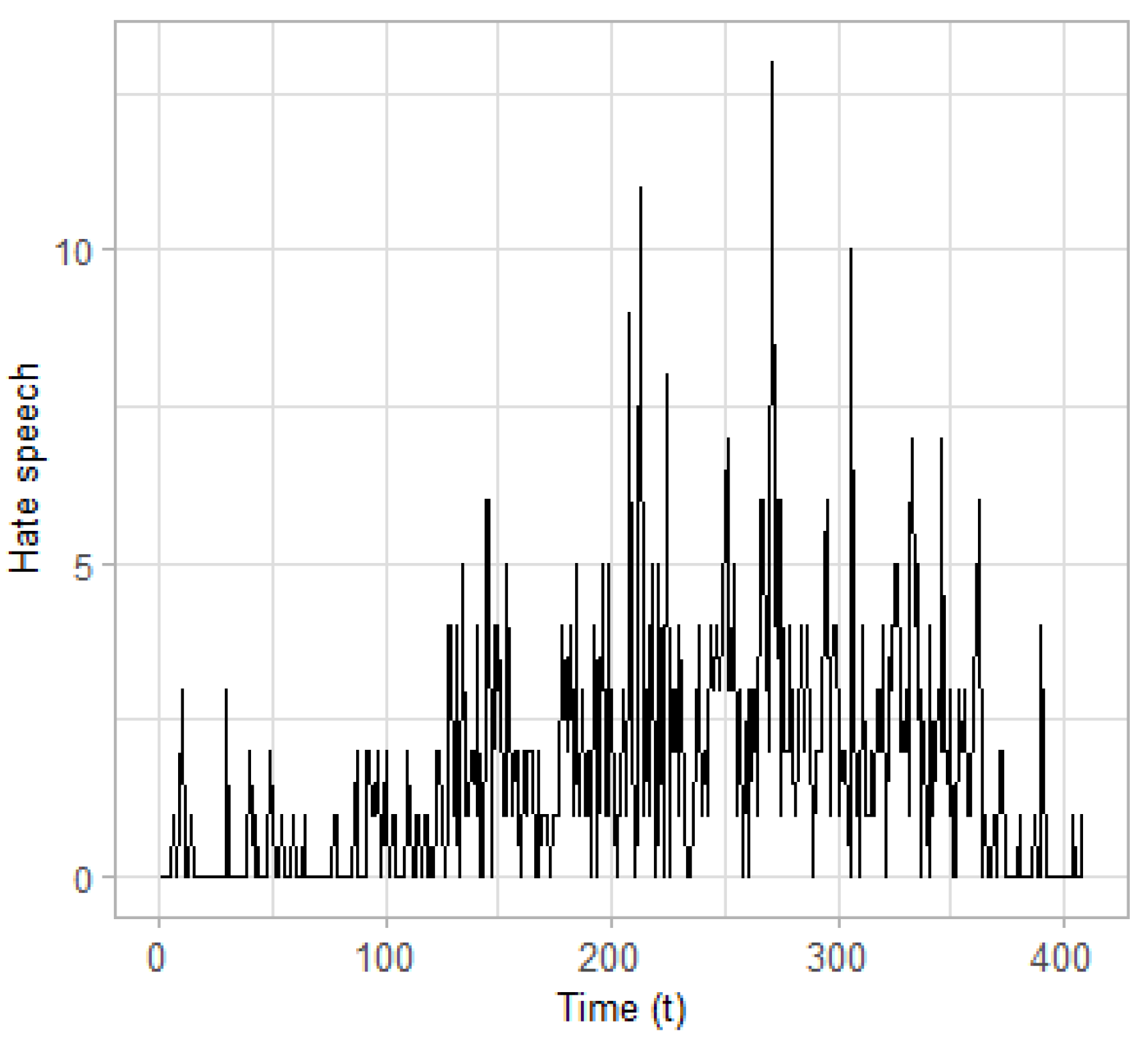
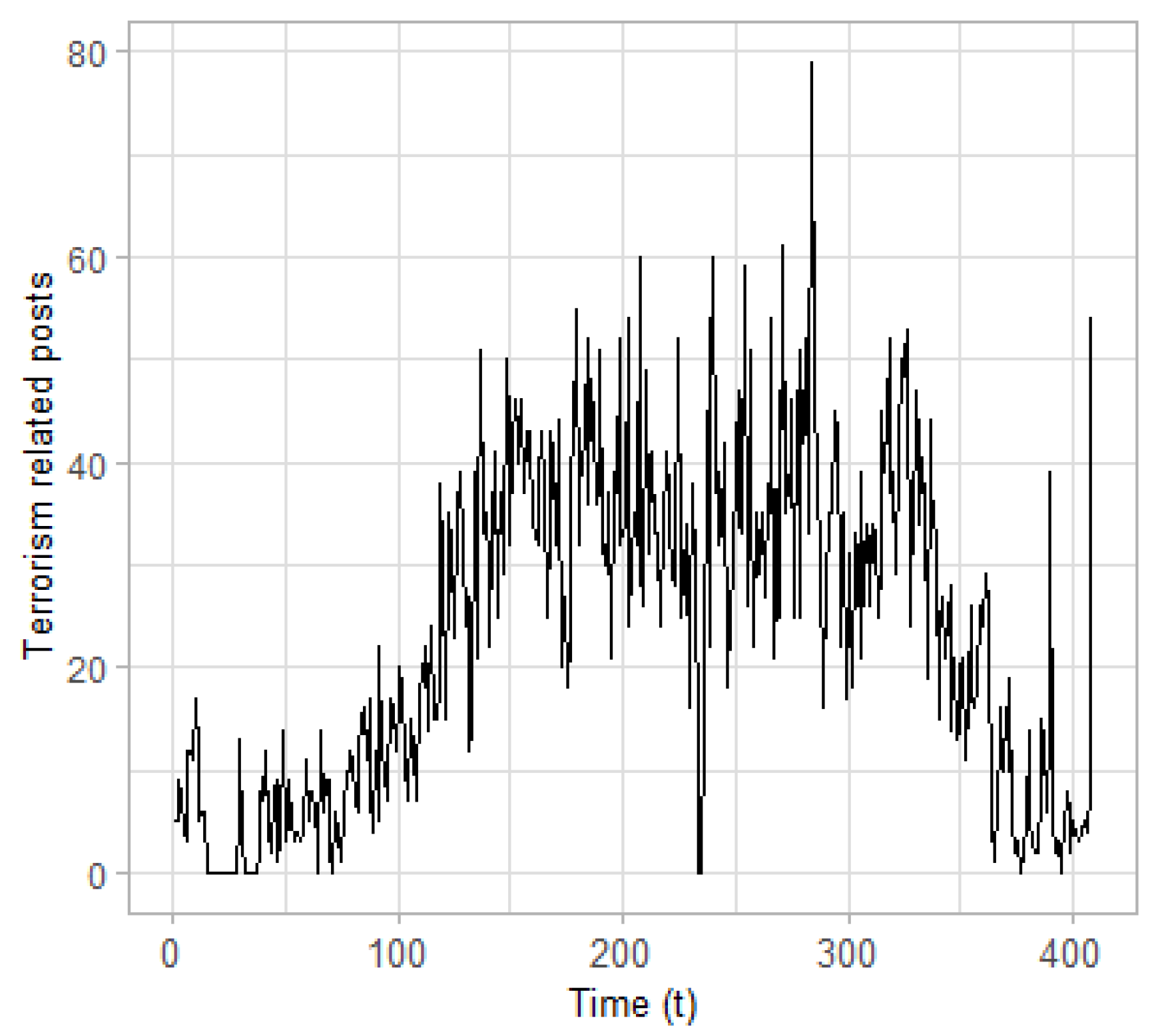
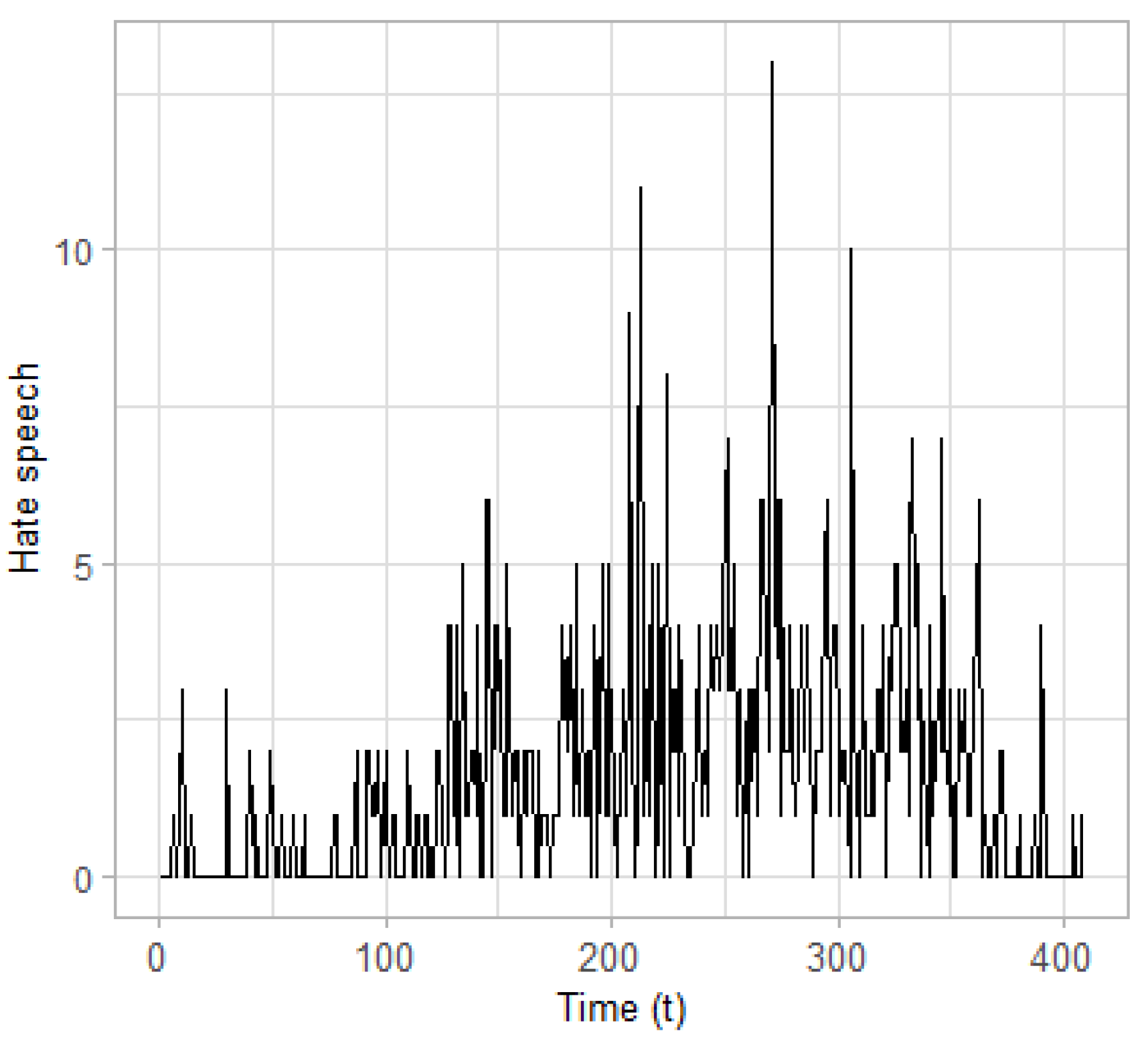
Time series. Overall, two time series are constructed and used as input to the CPD algorithm: (a) the time series of posts classified as terrorism related; and (b) those identified as containing hate speech. The posts are aggregated on a daily basis resulting in two time series with length
(days), which are presented in
Figure 4 and
Figure 5, respectively. These time series seem to evolve in a similar way, although the frequencies observed at the time series of the terrorism-related posts are much higher.
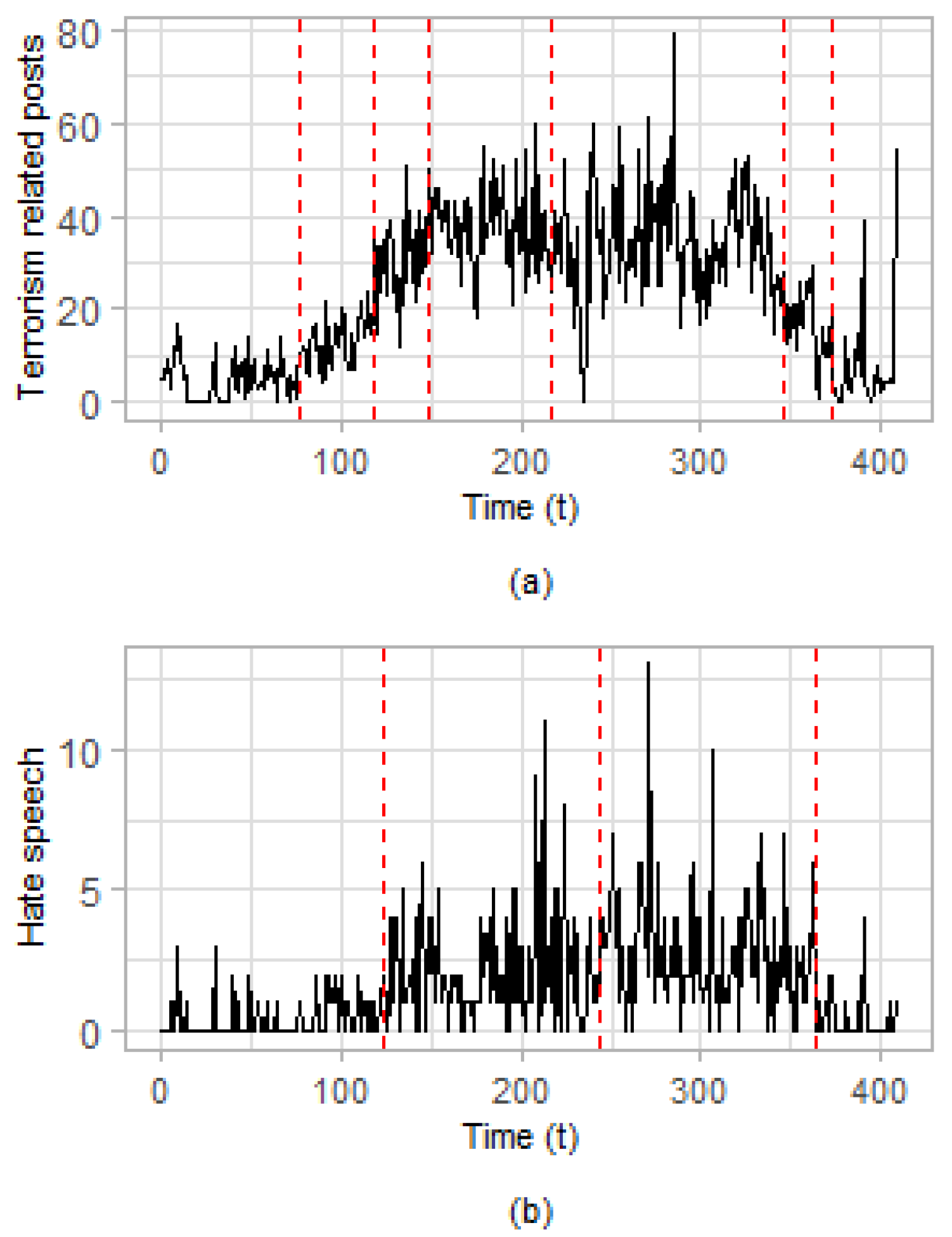
Change Point Detection in the Univariate Case. The CPD method presented in
Section 3.2 is applied to each of the two above mentioned time series and estimates changes in the mean value of the considered data. For the implementation of the method, we set
and use
permutations for the estimation of the statistical significance of each change point with a level of
in our significance testing. The results regarding the time series of terrorism-related posts are presented in
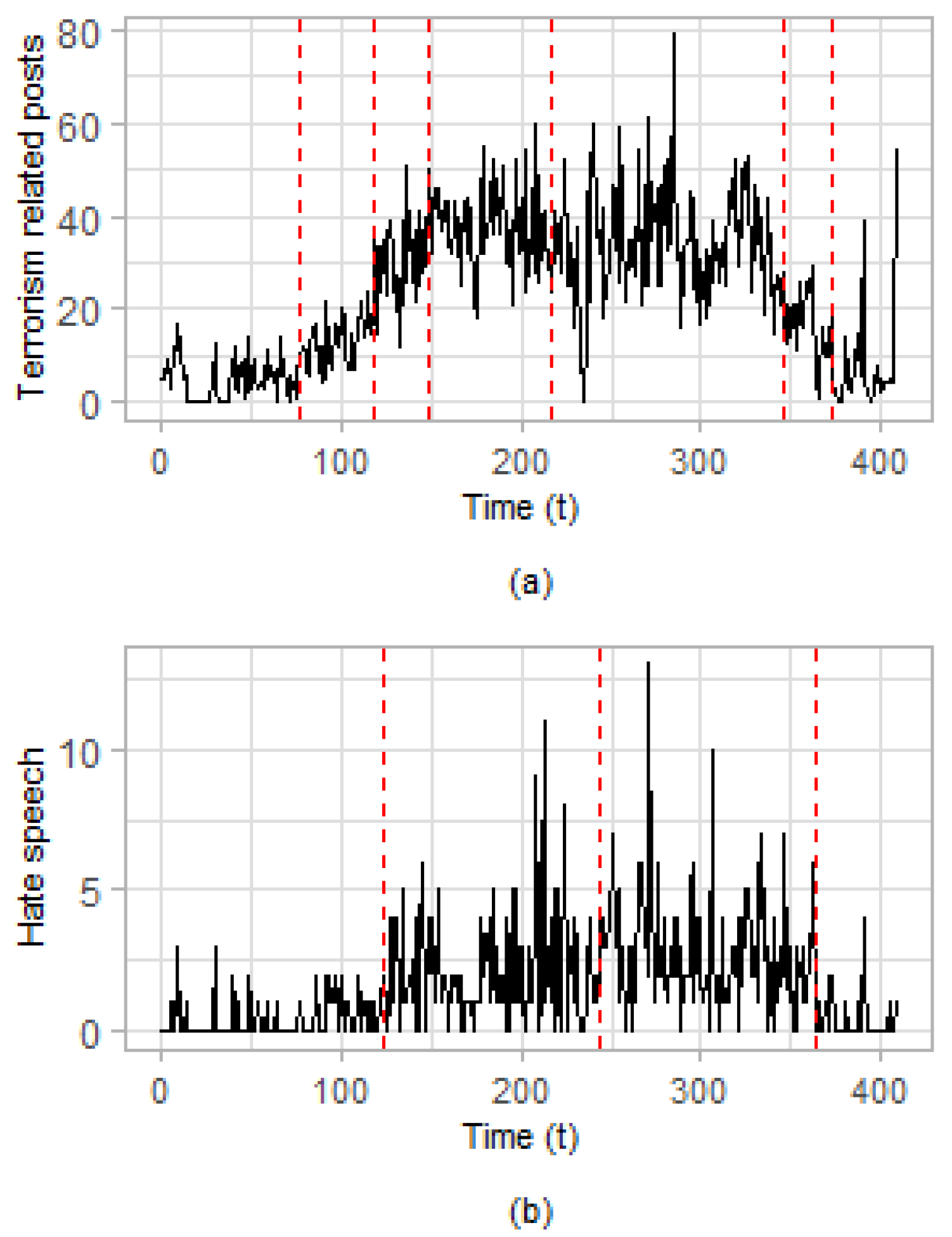
Table 3 and graphically depicted in
Figure 6a, whereas for the time series of hate speech, the results are presented in
Table 4 and
Figure 6b.
Considering the time series of terrorism-related posts, six change points are estimated as statistically significant (see
Table 3), whereas, when the time series of posts including hate speech is considered, there are three estimated change points (see
Table 4). The first estimated change point of the time series of posts related to hate speech (
) is very close to the second estimated change point in the time series of terrorism-related posts (
). Moreover, the third estimated change point in the time series of posts containing hate speech (
) is close to the sixth estimated change point of the terrorism-related time series (
).
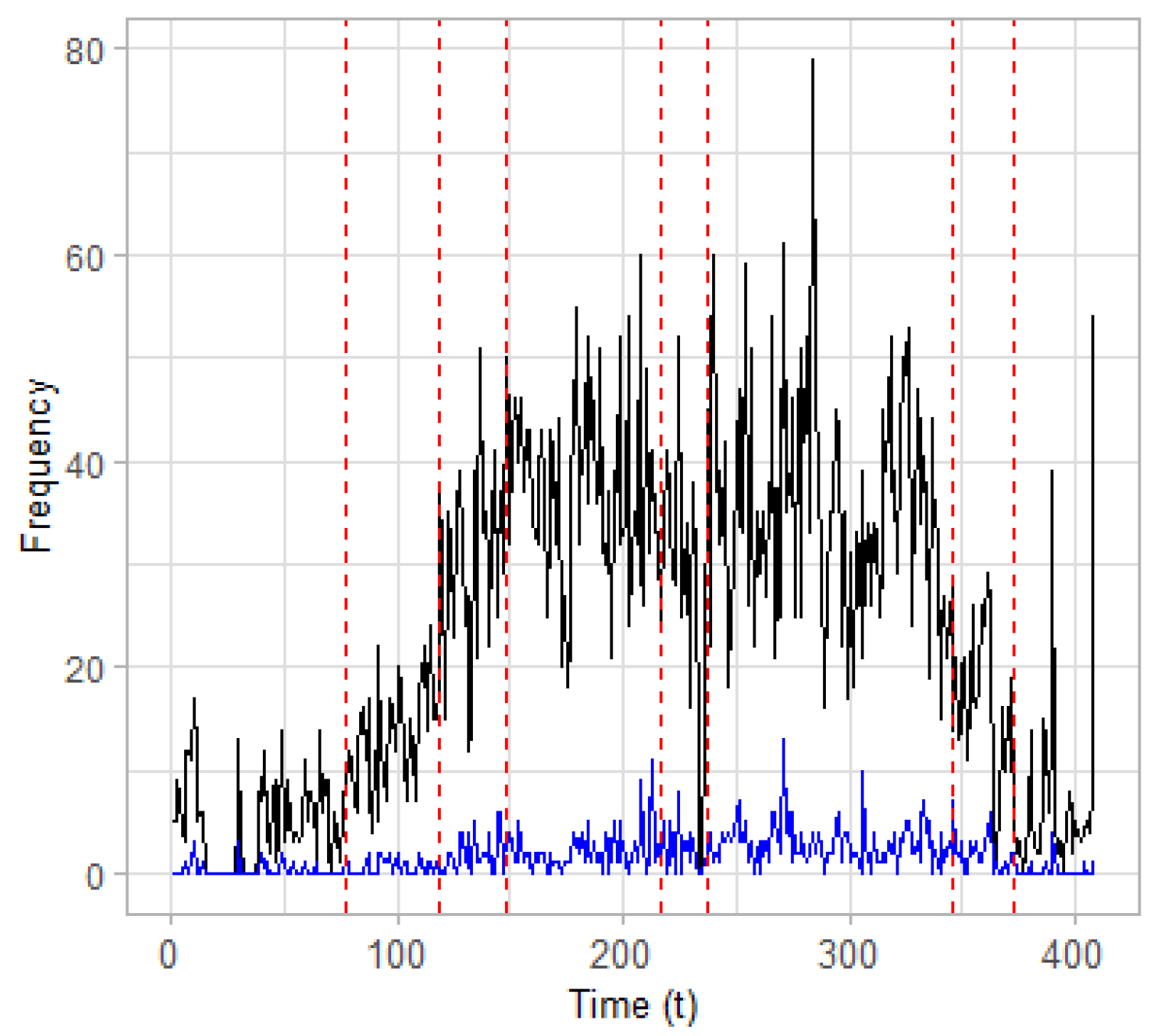
Change Point Detection in the Multivariate Case. Apart from applying CPD on the univariate case, as performed previously, we can also exploit possible correlations that may exist between the two time series using the multivariate CPD. To this end, we combine the two time series of the terrorism related posts and hate speech into a single two-dimensional time series
,
,
,
, where the first entry of the observation vector
(i.e.,
) is the frequency of the posts classified as terrorism-related and the second one (i.e.,
) denotes the frequency of the posts classified as containing hate speech. The attempt to combine terrorism-related posts with hate speech lies on the idea that hate speech, in the sense of expressing aggressive behaviors, may be related to terrorism and vice versa. This is especially true if we consider the fact that the underlying dataset is based on jihadist forums where terrorism-related topics of discussion and the expression of aggressive behaviors may be more often. The results of the two-dimensional CPD are presented in
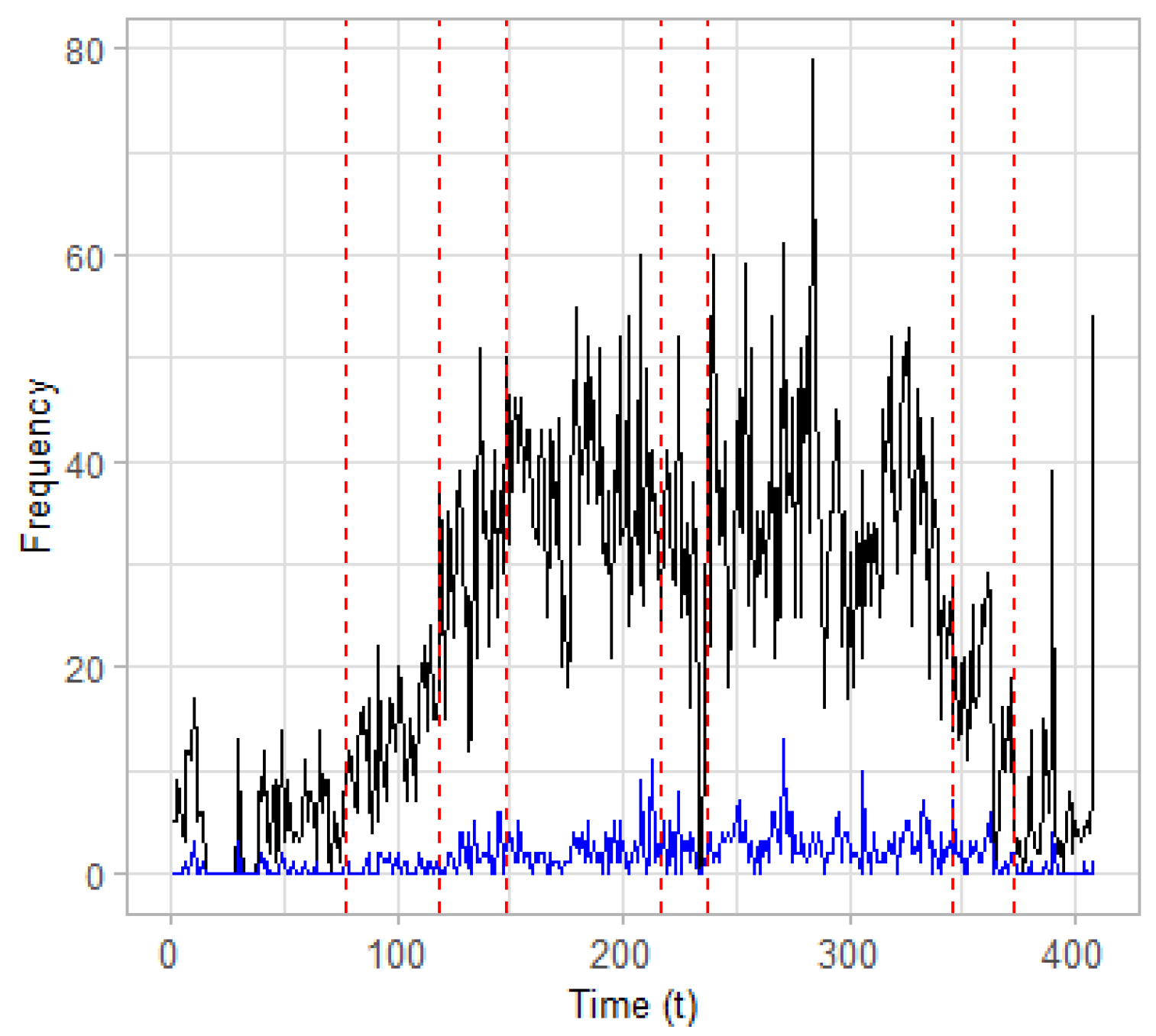
Table 5 and depicted graphically in
Figure 7. It is observed that the estimated change points in the two-dimensional case are the same with those estimated for the univariate time series of terrorism-related posts and presented in
Table 3, apart from the point at time
. The estimated change point at time location
is close enough to the second estimated change point regarding the time series of posts classified as hate speech (see
Table 4). Moreover, this point (i.e.,
) also appears to be a statistically significant change point for the time series of terrorism-related posts, if the value
is used for the level of our significance testing. Overall, it seems that the time series of terrorism-related posts have more impact on the two-dimensional model compared to the time series of posts related to hate speech.
Regarding the estimated change points in the two dimensional time series (
Figure 7), some conclusions could be inferred the time locations of the points and the terrorist incidents that occurred during 2009 (a list of widely known terrorist attacks can be found for example: (a) at
https://en.wikipedia.org/wiki/List_of_terrorist_incidents_in_2009; accessed on 22 April 2021, (b) at
https://www.dni.gov/nctc/index.html; accessed on 22 April 2021, or (c) in [
30]), which covers the main part of the
Ansar1 dataset. It can be argued that the time period between the estimated change points at time locations
(23 February 2009) and
(6 April 2009) appear to have an increasing trend, which is depicted more obviously in the frequency of posts which belong to the terrorism-related class. Therefore, the first estimated change point at
signals an upward change regarding the frequency of posts classified as terrorism-related and as containing hate speech, probably due to the terrorist incidents that occurred at that time.
Commenting on the period that is formulated between the second estimated change point at (6 April 2009) and the third one at (5 May 2009), it can be argued that even more intense online activity (i.e., the trend is even more increasing) is observed compared to the previous period. This may be partially interpreted based on two factors: (a) the terrorist incidents that occurred in the previous period (e.g., Bomb explosion in Afghanistan on 25 March 2009 and Suicide bombing in Pakistan on 27 March 2009) caused an increasing trend related to the aftermath of the attacks; and (b) other terrorist attacks took place in the period delimited by the second and third estimated change point, which enhanced the online activity. Therefore, the second estimated change point at signifies an upward (and sharper) change compared to the previous period.
Regarding the period which is bounded between the third and the fourth estimated change point at time locations (5 May 2009) and (12 July 2009), respectively, it can be argued that the frequency of posts appears to have a stable trend at a high level compared to the previous periods. This stable trend at high frequencies may be partially explained by the two factors that are also mentioned above, i.e., the terrorist incidents that occurred in the previous period triggered an online activity that lasts and is related to the aftermaths of the attacks, and the additional terrorist incidents that occurred in the period between the third and fourth estimated change points preserved the online activity related to terrorist topics and hate speech at a high frequency level. Therefore, the third estimated change point at time signals the beginning of a period with stable trend at high frequencies.
A similar interpretation of the results, as the one derived for the time period between the third and the fourth estimated change points, can also be used for the period between the fifth and sixth estimated change points at time locations (2 August 2009) and (19 Nvember 2009), respectively. In addition, the fourth estimated change point at time signals the beginning of a short period with a decreasing trend between the two periods of stable trend at high frequencies. Finally, the two last change points estimated at time locations (19 November 2009) and (16 December 2009) signal the beginning of two periods with decreasing trends regarding the frequency of terrorism-related posts and hate speech, indicating partially that the interest of users among the forum has been decreased regarding terrorism-related topics.
Topic Detection. To further evaluate the effectiveness of the proposed framework, we proceed with an analysis of the topics discussed within different time periods based on the detected change points, as listed in
Table 5. Specifically, we follow the Latent Dirichlet Allocation (LDA) topic detection process in each resulting time period. LDA is a generative statistical model that aims to find distinct topics in document collections [
31]; to this end, it models each document as a mixture of latent topics, where a topic is described by a distribution over words. We apply the gensim version of the LDA method (
https://radimrehurek.com/gensim/models/ldamodel.html; accessed on 5 May 2021). The specific parameters used for the LDA model are listed in
Table 6.
For the topic detection, we focused mainly on the time periods where a more intense online activity is observed either via the existence of an increasing trend (6 April–5 May 2009) or via the illustration of a stable trend at a consistently high level (5 May–12 July and 2 August–19 November 2009) regarding the frequencies. For each of the aforementioned time periods, we ran the LDA method for a range of topics between 2 and 10 in steps of 1 and concluded that at most five topics resulted in a clear set of distinct topics. The results are presented in
Table 7.
Regarding the first time period (6 April–5 May 2009), which signals the intensification of the posting activity, we observe that the attention is highly focused on destructions and deaths related to terrorist attacks. This is in line with a set of terrorist incidents that took place in the previous period and, as a result, they may have attracted the attention of people, leading to increased online activity and intense discussions around them.
Moving on to the next time period (5 May–12 July 2009), where online activity remains at consistently high rates, there is a continuation of the discussion regarding the aftermaths of the terrorist incidents, as well as new ones that took place during this period (e.g.,
20 June 2009 Taza bombing with at least 73 deaths and more than 200 injured (
https://en.wikipedia.org/wiki/2009_Taza_bombing; accessed on 22 April 2021). Now, the discussions are more oriented around the government and the military, as well as the arrests and evidence found. As expected, discussions about injuries and deaths continue with undiminished interest. Finally, there is an increased interest and discussion around issues of religion that have often been linked to terrorist attacks.
In the following short period (12 July–2 August 2009), although there is a decrease in the intensity of the discussions that take place, the attention remains on the same points with respect to the previous time period. During the last presented time period (2 August–19 November 2009), which indicates the final resurgence of interest, discussions are also beginning to focus on issues related to security, education and protection. As expected, there is insistence on discussions related to religion and god, as well as, clearly, to the deaths and killings that have occurred in the recent past.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}