1. Introduction
In Internet of Things (IoT) networks, data are collected at sensors and transmitted over a wireless channel to remote decision centers, which decide on one or multiple hypotheses based on the collected information. In this paper, we study simple binary hypothesis testing with a single sensor but two decision centers. The results can be combined with previous studies focusing on multiple sensors and a single decision center to tackle the practically relevant case of multiple sensors and multiple decision centers. We consider a single sensor for simplicity and because our main focus is on studying the tradeoff between the performances at the two decision centers that can arise because the single sensor has to send information over the channel that can be used by both decision centers. A simple, but highly suboptimal, approach would be to time-share communication and serve each of the two decision centers only during a part of the transmission. As we will see, better schemes are possible, and, in some cases, it is even possible to serve each of the two decision centers as if the other center was not present in the system.
In this paper, we follow the information-theoretic framework introduced in [
1,
2]. That means each terminal observes a memoryless sequence, and depending on the underlying hypothesis
, all sequences follow one of two possible joint distributions, which are known to all involved terminals. A priori, the transmitter, however, ignores the correct hypothesis and has to compute its transmit signal as a function of the observed source symbols only. Decision centers observe outputs of the channel, and, combined with their local observations, they have to make a decision on whether
or
. The performance of the decision center is measured by its
type-II error exponent, i.e., the expontial decay in the length of the observations of the probability of deciding on
when the true hypothesis is
. As a constraint on the decision center, we impose that the
type-I error probability, i.e., the probability of deciding
when the true hypothesis is
, vanishes (at any desired speed) with increasing observation lengths. The motivation for studying such asymmetric requirements on the two error probabilities stems, for example, from alert systems, where the
miss-detection event is much more harmful than the
false-alarm event, and, as a consequence, in our systems we require the miss-detection probability to decay much faster than the false-alarm probability.
This problem setting has first been considered for the setup with a single sensor and a single decision center when communication is over a noiseless link of given capacity [
1,
2]. For this canonical problem, the optimal error exponent has been identified in the special cases of
testing against independence [
1] and
testing against conditional independence [
3,
4].
The scheme proposed by Shimokawa–Han–Amari in [
3,
4] yields an achievable error exponent for all distributed hypothesis testing problems (not only testing against conditional independence) [
3,
4], but it might not be optimal in general [
5]. The Shimokawa–Han–Amari (SHA) scheme has been extended to various more involved setups such as noiseless networks with multiple sensors and a single decision center [
2,
6,
7]; networks where the sensor and the decision center can communicate interactively [
8,
9]; multi-hop networks [
10]; networks with multiple decision centers [
10,
11,
12,
13].
The works most closely related to the current paper are [
10,
12,
13,
14,
15,
16]. Specifically, Refs [
10,
12,
13,
14] consider a single-sensor multi-detector system where communication is over a common noiseless link from the sensor to all decision centers. Focusing on two decision centers, two scenarios can be encountered here: (1) the two decision centers have the same null and alternate hypotheses, and as a consequence, both aim at maximizing the error exponent under the same hypothesis
; or (2) the two decision centers have opposite null and alternate hypotheses and thus one decision center wishes to maximize the error exponent under hypothesis
and the other under hypothesis
. The second scenario is motivated by applications where the decision centers have different goals. Hypothesis testing for scenario 1) was studied in [
10,
12,
13,
14], and the results showed a tradeoff between the exponents achieved at the two decision centers. Intuitively, the tradeoff comes from the fact that communication from the sensor is serving both decision centers at the same time. Scenario 2) was considered in [
12,
13]. In this case, a tradeoff only occurs when the sensor’s observation alone provides no advantage in guessing the hypothesis. Otherwise, a tradeoff-free exponent region can be achieved by the following simple scheme: the sensor takes a tentative guess on the hypothesis based only on its local observations. It communicates this tentative guess to both decision centers using a single bit and then dedicates the rest of the communication using a dedicated SHA scheme only to the decision center that wishes to maximize the error exponent under the hypothesis that does
not correspond to its guess. The other decision center simply keeps the transmitter’s tentative guess and ignores the rest of the communication.
In this paper, we extend these previous works to memoryless broadcast channels (BC). Hypothesis testing over BCs was already considered in [
10], however, only for above scenario 1 where both decision centers have the same null and alternate hypothesis and in the special case of testing against conditional independence, in which case the derived error exponents were proved to be optimal. Interestingly, when testing against conditional independence over noisy channels, only the capacity of the channel matters but not the properties, see [
15,
16]. General hypothesis testing over noisy channels is much more challenging and requires additional tools, such as joint source-channel coding and
unequal error protection (UEP) coding [
17]. The latter can, in particular, be used to specially protect the communication of the sensor’s tentative guess, which allows one to avoid a degradation of the performance of classical hypothesis testing schemes.
We present general distributed hypothesis testing schemes over memoryless BCs, and we analyze the performances of these schemes with a special focus on the tradeoff in exponents they achieve for the two decision centers. We propose two different schemes, depending on whether the sensor can distinguish with error probability
the two null hypotheses at the two decision centers. If a distinction is possible (because the decision centers have different null hypothesis and the sensor’s observations follow different marginal distributions under the two hypotheses), then we employ a similar scheme as proposed in [
12,
13] over a common noiseless link, but where the SHA scheme is replaced by the UEP-based scheme for DMCs in [
15]. That means, the sensor makes a tentative guess about the hypothesis and conveys this guess to both decision centers using an UEP mechanism. Moreover, the joint source-channel coding scheme in [
15] with dedicated codebooks is used to communicate to the decision center that aims to maximize the error exponent under the hypothesis that does
not correspond to the sensor’s tentative guess. This scheme shows no tradeoff between the exponents achieved at the two decision centers in various interesting cases. Sometimes, however, a tradeoff arises because even under UEP the specially protected messages can be in error and because the decision centers can confuse the codewords of the two different sets of codebooks. For the case where the sensor cannot reasonably distinguish the alternate hypotheses at the two decision centers (because both decision centers have the same alternate hypotheses or the sensor’s observations have the same marginal observations under both hypotheses), we present a scheme similar to [
10] but again including UEP. In this scheme, a tradeoff between the exponents achieved at the two decision centers naturally arises and mostly stems from the inherent tradeoff in distributed lossy compression systems with multiple decoders having different side informations.
Notation
We mostly follow the notation in [
18]. Random variables are denoted by capital letters, e.g.,
,
, and their realizations by lower-case letters, e.g.,
,
y. Script symbols such as
and
stand for alphabets of random variables, and
and
for the corresponding
n-fold Cartesian products. Sequences of random variables
and realizations
are abbreviated by
and
. When
, then we also use
and
instead of
and
.
We write the probability mass function (pmf) of a discrete random variable X as ; to indicate the pmf under hypothesis , we also use . The conditional pmf of X given Y is written as , or as when . The term stands for the Kullback–Leibler (KL) divergence between two pmfs P and Q over the same alphabet. We use to denote the joint type of the pair of sequences , and cond_tp for the conditional type of given . For a joint type over alphabet , we denote by the conditional ßmutual information assuming that the random triple has pmf ; similarly for the entropy and the conditional entropy . Sometimes we abbreviate by . In addition, when has been defined and is clear from the context, we write or for the corresponding subtypes. When the type coincides with the actual pmf of a triple , we omit the subscript and simply write , , and .
For a given
and a constant
, let
be the set of
μ-typical sequences in
as defined in [
8] (Section 2.4). Similarly,
stands for the set of
jointly μ-typical sequences. The expectation operator is written as
. We abbreviate
independent and identically distributed by
i.i.d. The log function is taken with base 2. Finally, in our justifications, we use (DP) and (CR) for “data processing inequality” and “chain rule”.
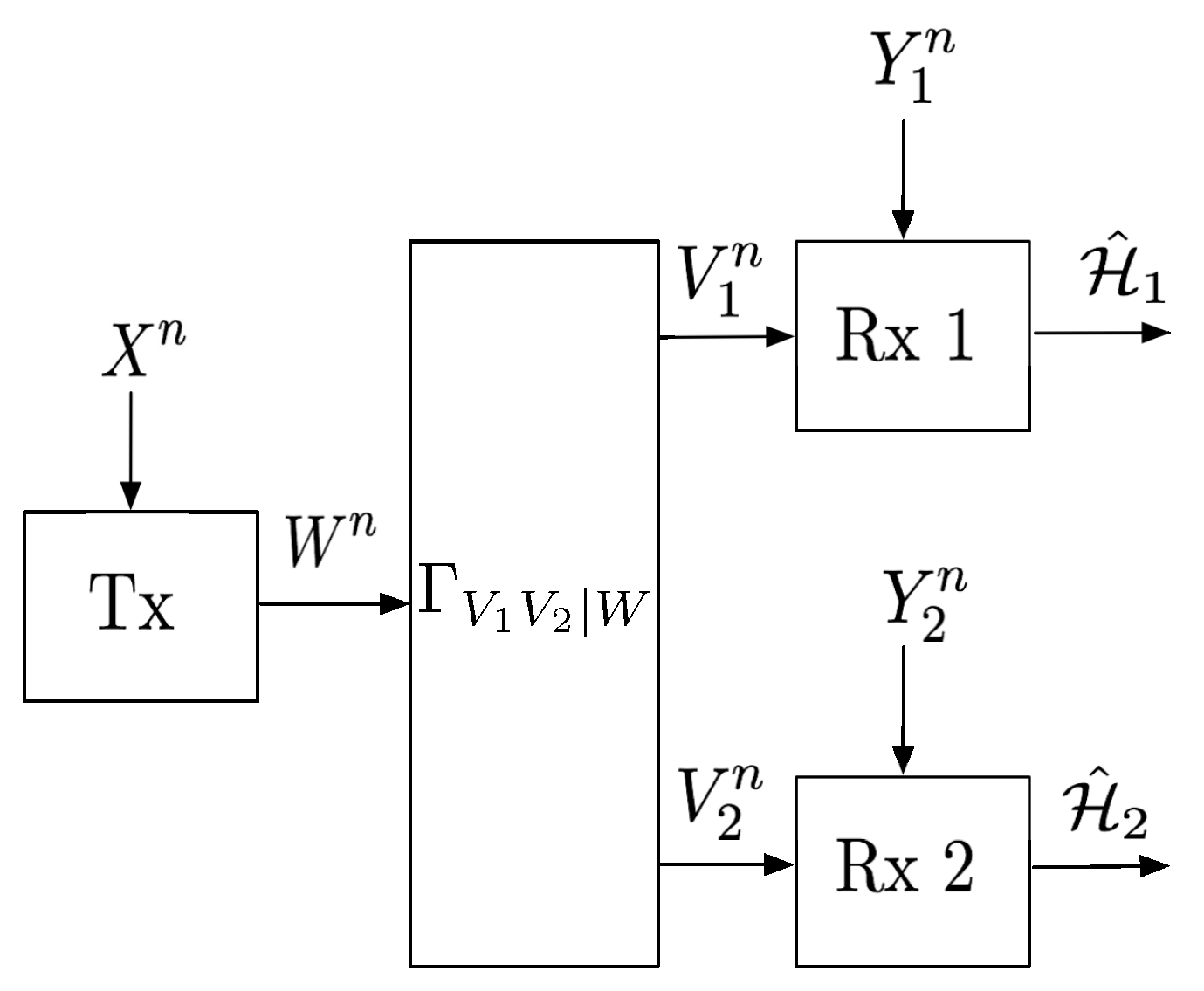
2. System Model
Consider the distributed hypothesis testing problem in
Figure 1, where a transmitter observes sequence
, Receiver 1 sequence
, and Receiver 2 sequence
. Under the null hypothesis:
and under the alternative hypothesis:
for two given pmfs
and
. The transmitter can communicate with the receivers over
n uses of a discrete memoryless broadcast channel
where
denotes the finite channel input alphabet and
and
the finite channel output alphabets. Specifically, the transmitter feeds inputs
to the channel, where
denotes the chosen (possibly stochastic) encoding function
Each Receiver
observes the BC ouputs
, where for a given input
,
Based on the sequence of channel outputs
and the source sequence
, Receiver
i decides on the hypothesis
. That means it produces the guess
for a chosen decoding function
There are different possible scenarios regarding the requirements on error probabilities. We assume that each receiver is interested in only one of the two exponents. For each , let be the hypothesis whose error exponent Receiver i wishes to maximize, and the other hypothesis, i.e., and . (The values of and are fixed and part of the problem statement.) We then have:
Definition 1. An exponent pair is said to be achievable over a BC, if for each and sufficiently large blocklengths n, there exist encoding and decoding functions such that:satisfyand Definition 2. The fundamental exponents regionis the set of all exponent pairsthat are achievable.
Remark 1. Notice that both and depend on the BC law only through the conditional marginal distribution . Similarly, and only depend on . As a consequence, also the fundamental exponents region depends on the joint laws and only through their marginal laws , , , and .
Remark 2. As a consequence to the preceding Remark 1, when , one can restrict attention to a scenario where both receivers aim at maximizing the error exponent under hypothesis , i.e., . In fact, under , the fundamental exponents region for arbitrary and coincides with the fundamental exponents region for and if one exchanges pmfs and in case and one exchanges pmfs and in case .
To simplify the notation in the sequel, we use the following shorthand notations for the pmfs and .
For each
:
and
We propose two coding schemes yielding two different exponent regions, depending on whether
or
Notice that (
13) always holds when
. In contrast, given (
14), then obviously
.
4. Coding and Testing Scheme When
Fix
, a sufficiently large blocklength
n, auxiliary distributions
,
and
over
, conditional channel input distributions
and
, and conditional pmfs
and
over a finite auxiliary alphabet
such that for each
:
The mutual information in (
33) is calculated according to the joint distribution:
For each
, if
, choose rates
If
, then choose rates
Again, all mutual informations in (
35)–(
38) are calculated with respect to the pmf in (
34).
Code Construction: Generate a sequence
by independently drawing each component
according to
. For each
, generate a sequence
by independently drawing each
according to
when
. In addition, construct a random codebook
superpositioned on
where the
k-th symbol
of codeword
is drawn independently of all codeword symbols according to
when
and
. Finally, construct a random codebook
by independently drawing the
k-th component
of codeword
according to the marginal pmf
.
Reveal all codebooks and the realizations of the sequences to all terminals.
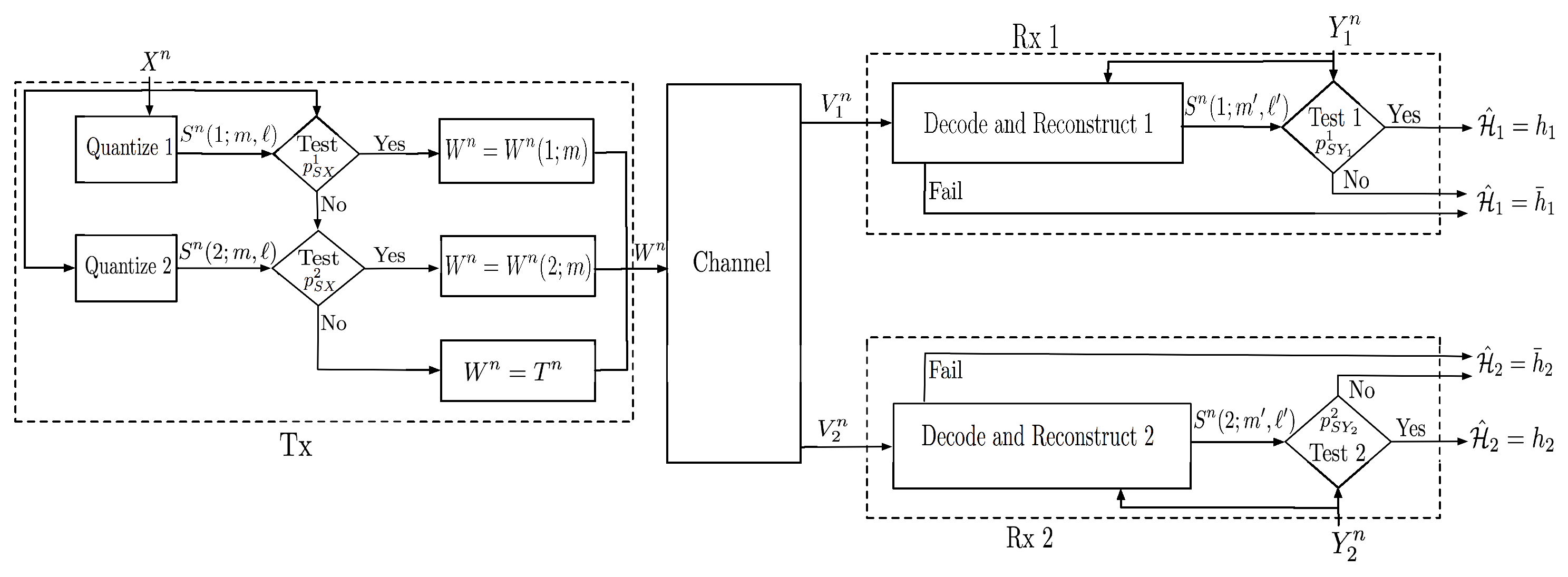
Transmitter: Given source sequence
, the transmitter looks for indices
such that codeword
from codebook
satisfies
and the corresponding codeword
from codebook
satisfies
(Notice that when
is sufficiently small, then Condition (
41) can be satisfied for at most one value
, because
.) If successful, the transmitter picks uniformly at random one of the triples
that satisfy (
41), and it sends the sequence
over the channel. If no triple satisfies Condition (
41), then the transmitter sends the sequence
over the channel.
Receiver : Receives and checks whether there exist indices such that the following three conditions are satisfied:
If successful, it declares . Otherwise, it declares .


{kind=link}
{kind=link}
{kind=link}


