
An Approach for Realizing Hybrid Digital Twins Using Asset Administration Shells and Apache StreamPipes




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Challenges and Requirements
- Interoperability with external systems: A DT should be easily integrated with other software systems. This requires standards for the DT metamodel as well as standardized interfaces to not only exchange messages with the external systems but also to understand their meaning.
- Interoperability within a DT: DT models should be made interoperable wherever it makes sense. There are no predefined pipelines; i.e., the way models are combined is application specific.
- Extensibility: A DT should be able to handle different types of models. These models could be developed with different technologies, in different programming languages, and using different protocols and require different environments to run them. New models for DT behavior can be created, and new types of models can be considered.
- Reusability: A DT should not be developed from scratch, but reusing existing models/components should be considered.
3. Background Technologies
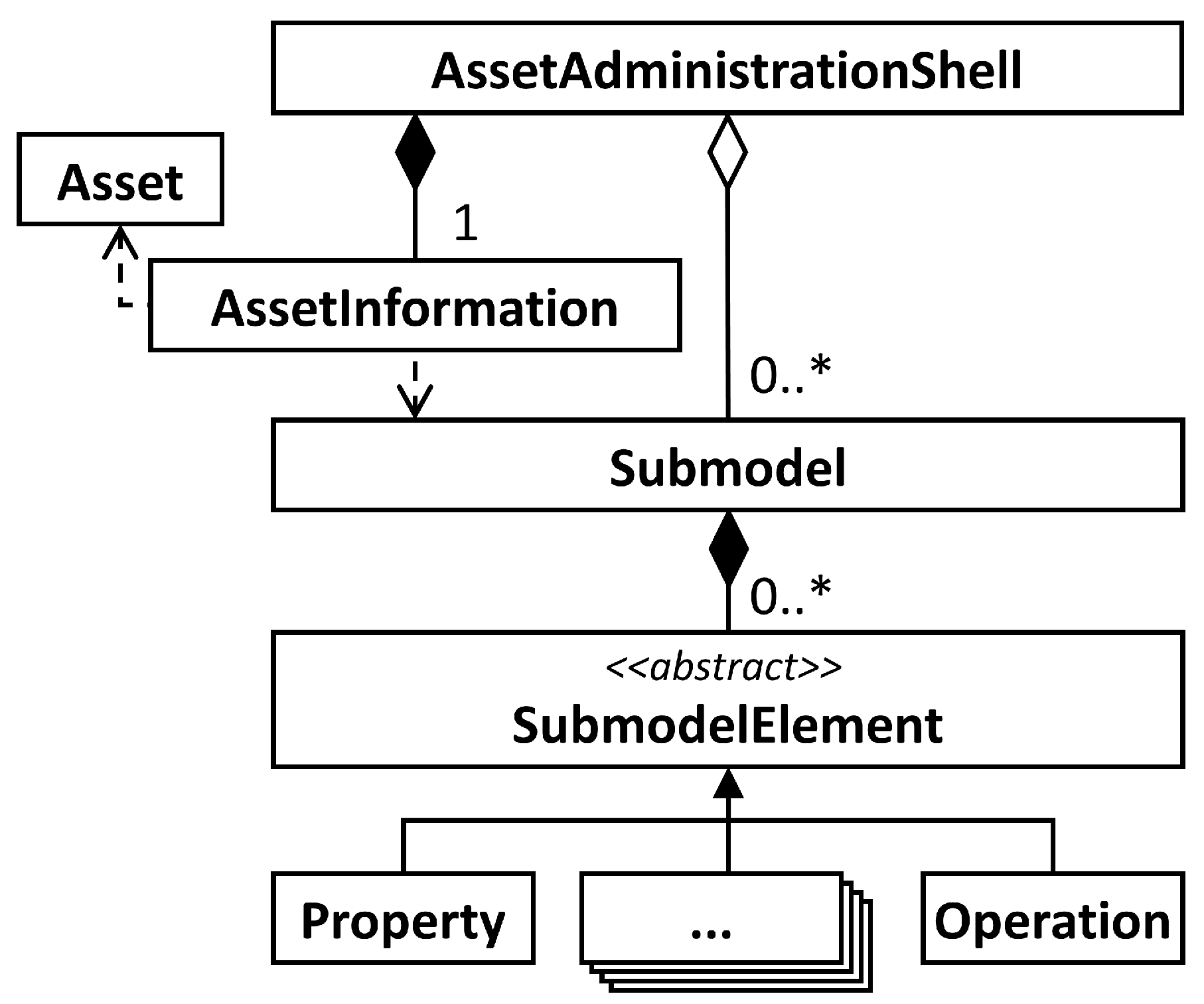
3.1. Asset Administration Shell Specification
3.2. Apache StreamPipes
- Data Sets/Streams—They represent the start of a pipeline and cover data acquisition from an external data source, such as sensors, databases, etc. In essence, they are responsible for data fetching and forwarding data to other elements within the pipeline. They can either be implemented as concrete data sets/streams allowing no further configuration, or instantiated with generic templates, called adapters, that offer further configuration options.
- Data Processors—Used for defining a pipeline’s main logic, i.e., defining what a pipeline does with the data fetched from the external source. Processing steps include filtering, aggregating, trend detection, image manipulation, deep and machine learning, and many more.
- Data Sinks—They represent an ending point of a pipeline and, as such, are used to store data, send data to visualization systems, send notifications/alerts, forward data to third-party systems for further processing, etc.
3.3. Comparing StreamPipes and Node-RED
4. Approach to Hybrid Twins
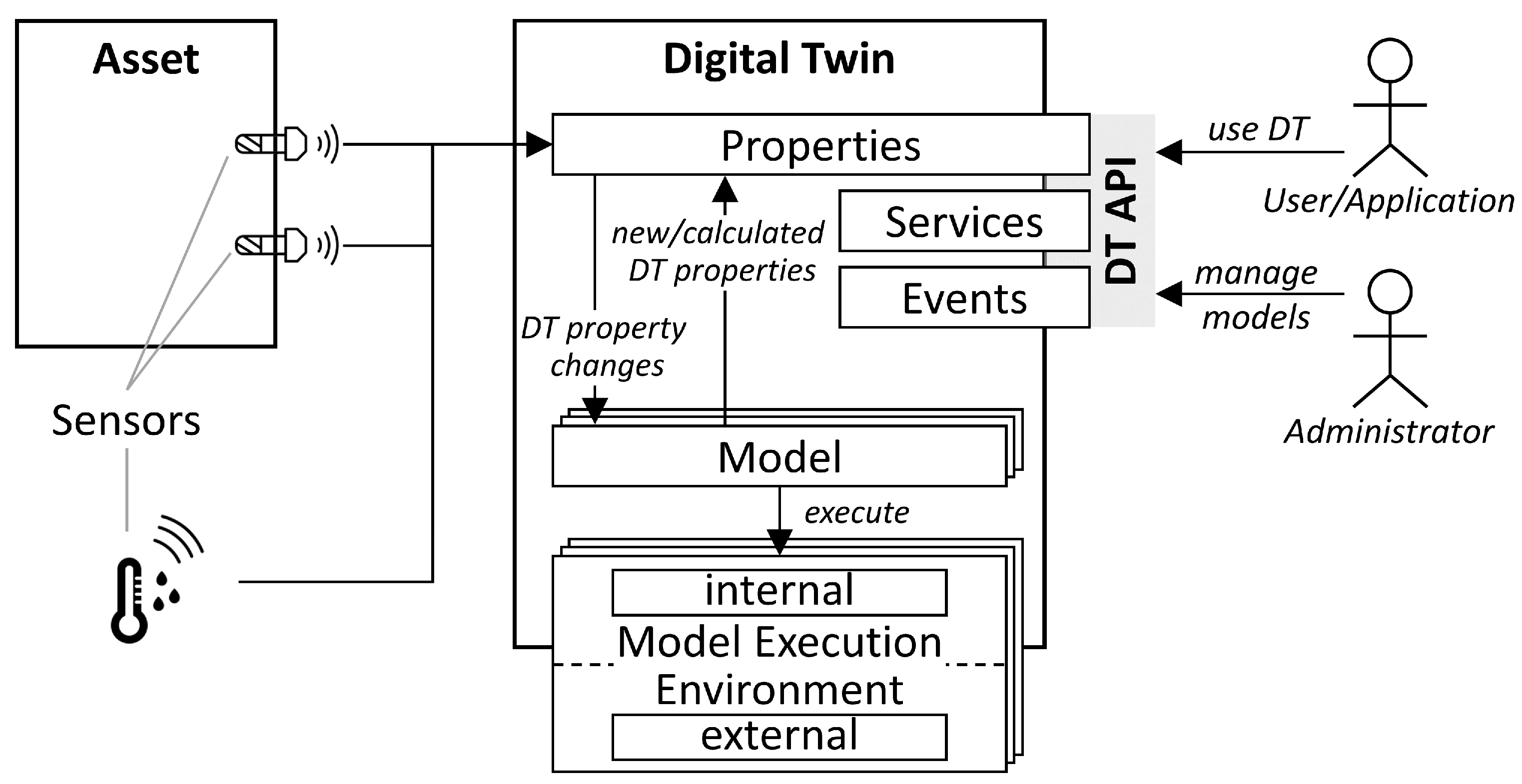
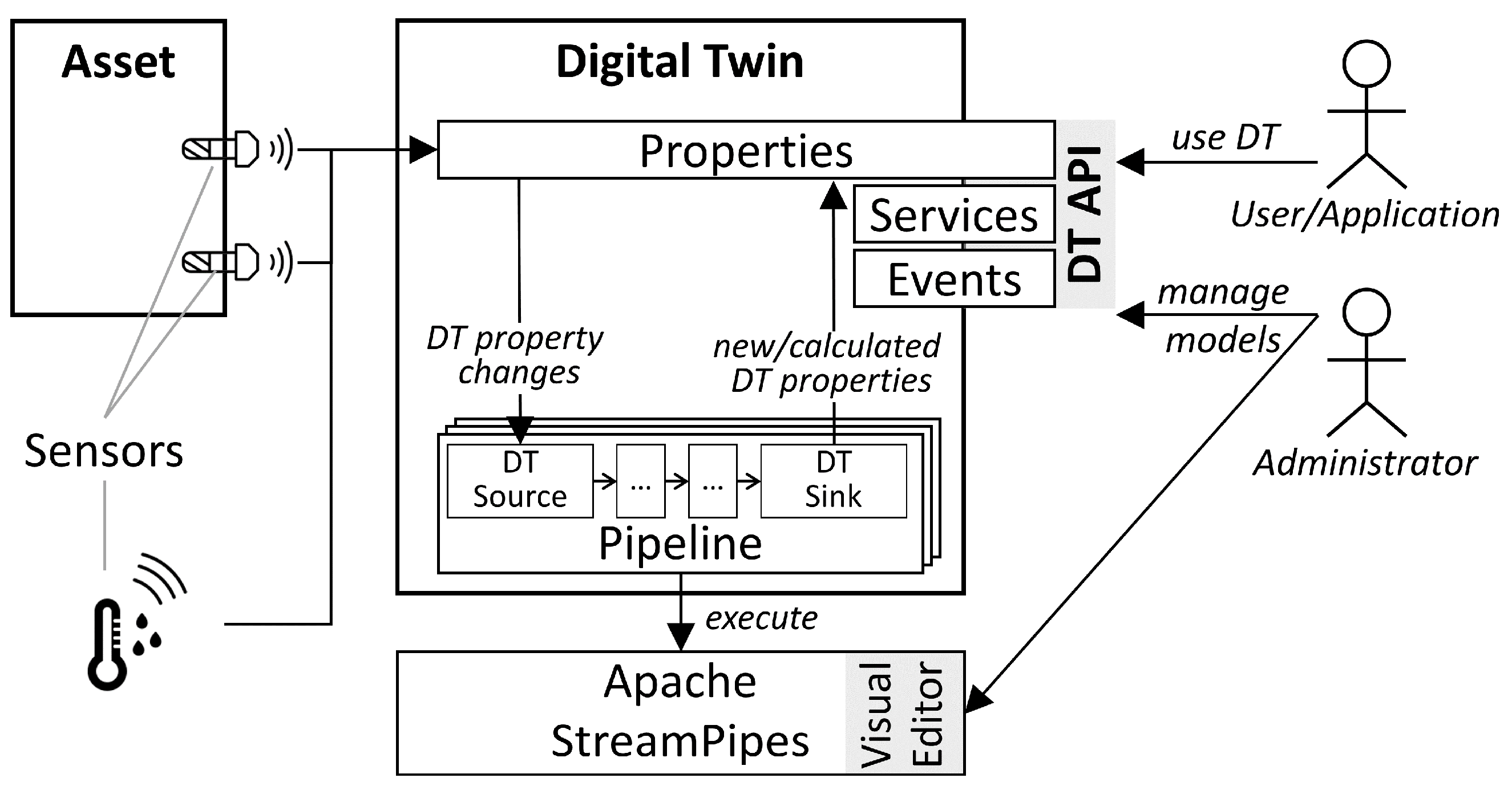
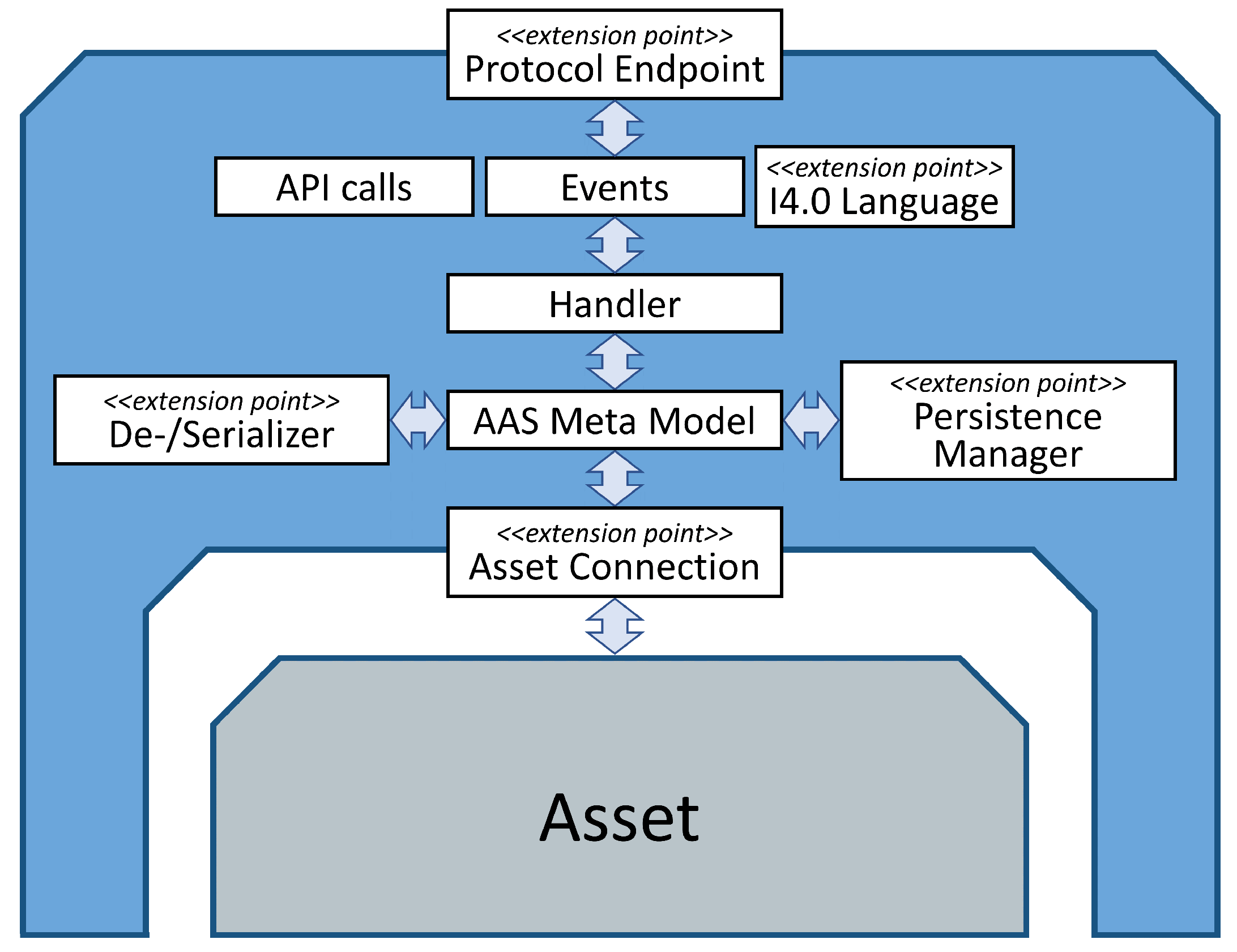
4.1. Architecture
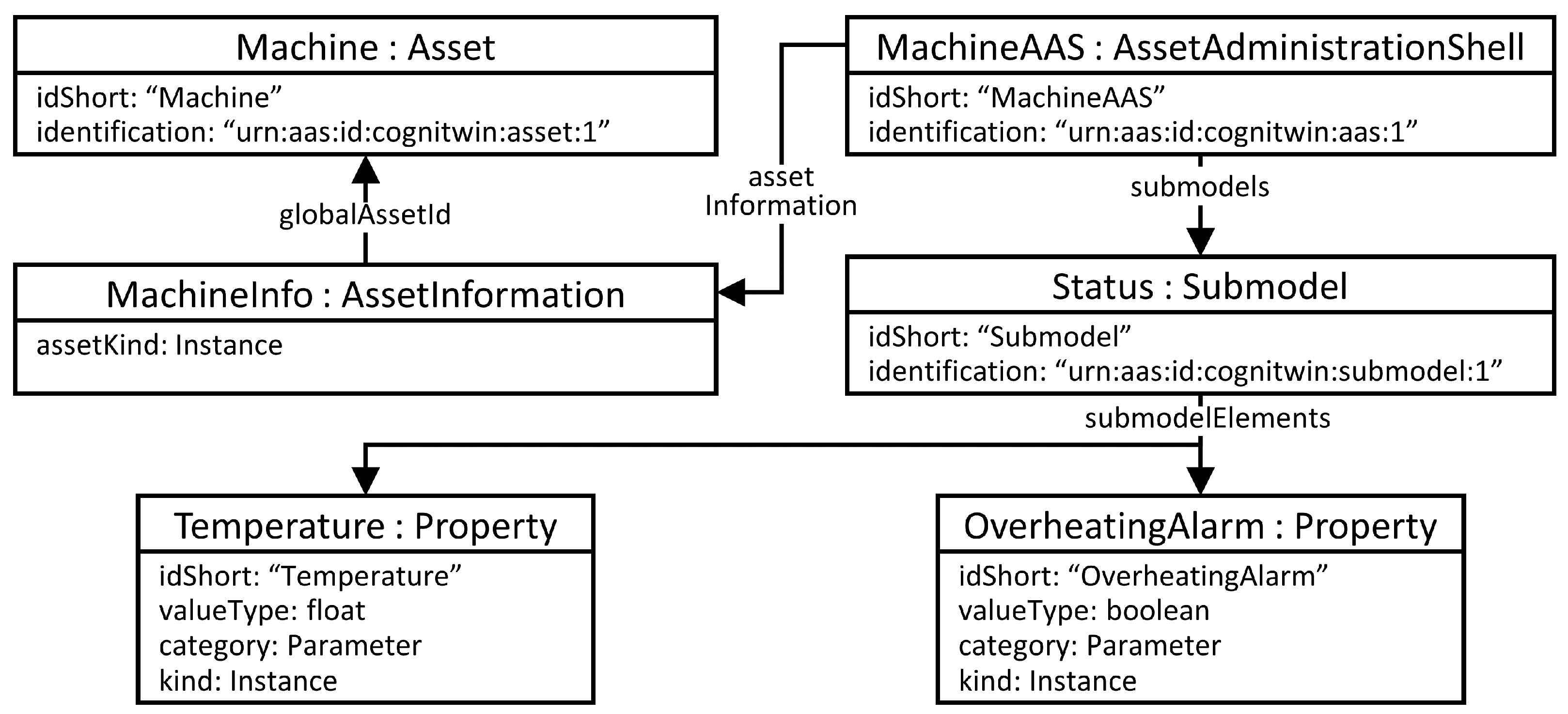
4.2. AAS Model Example
4.3. I4.0 Conform Digital Twins
4.4. Apache StreamPipes Extensions for Digital Twins
| Listing 1 Example code showing how to start an AAS with an HTTP endpoint from a *.json file |
|
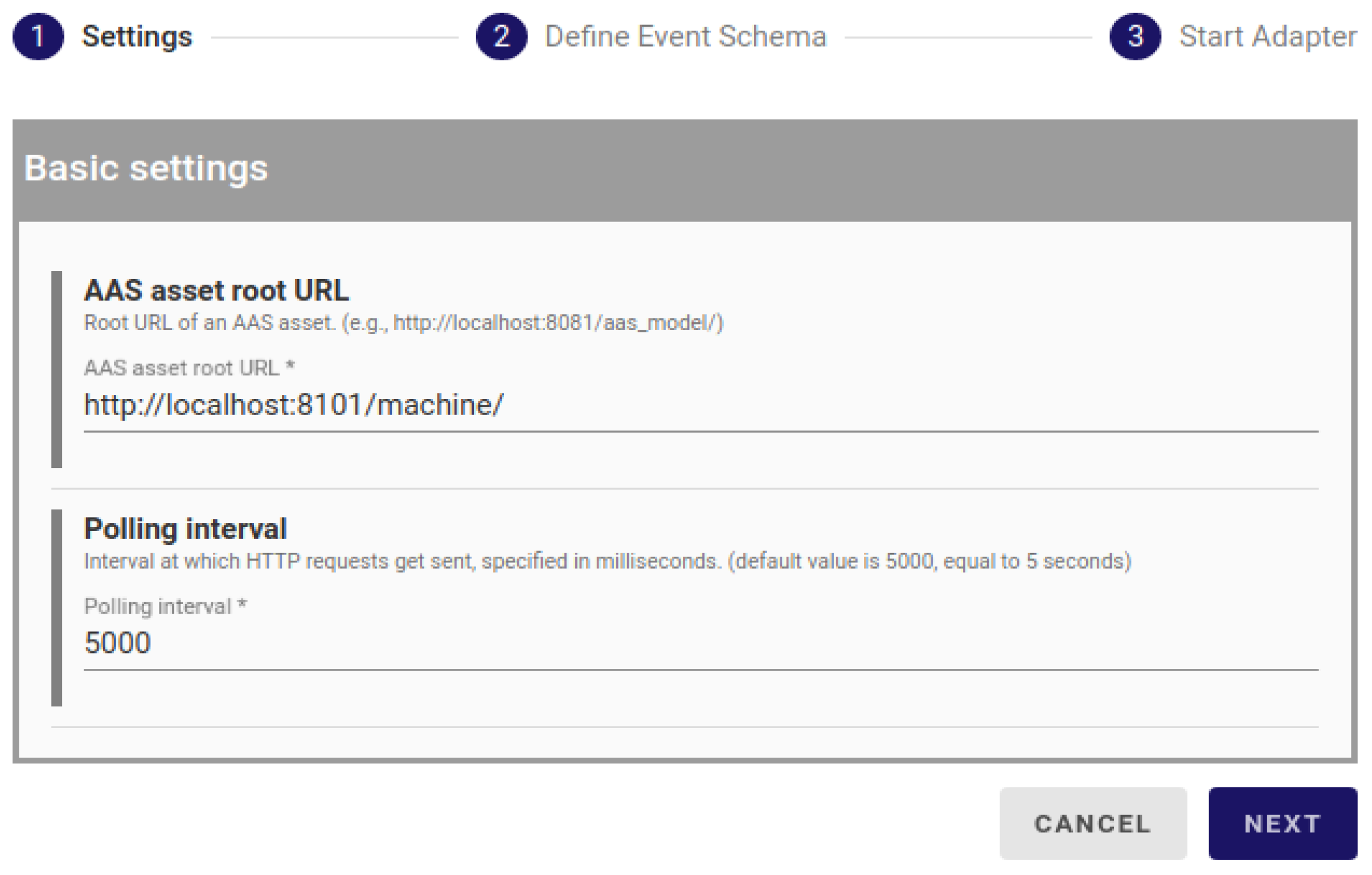
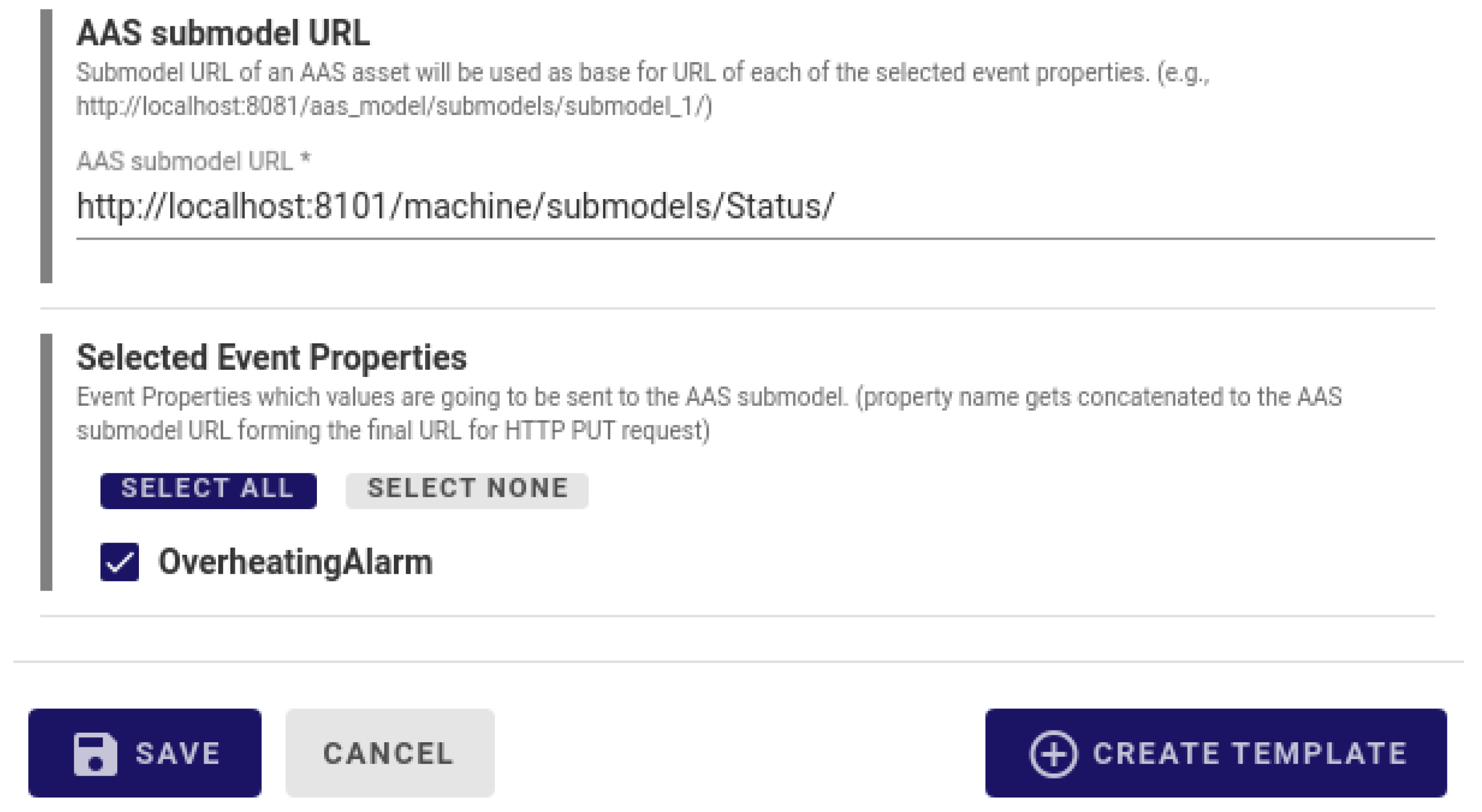
4.4.1. DT Source
4.4.2. DT Sink
4.4.3. Future Extensions
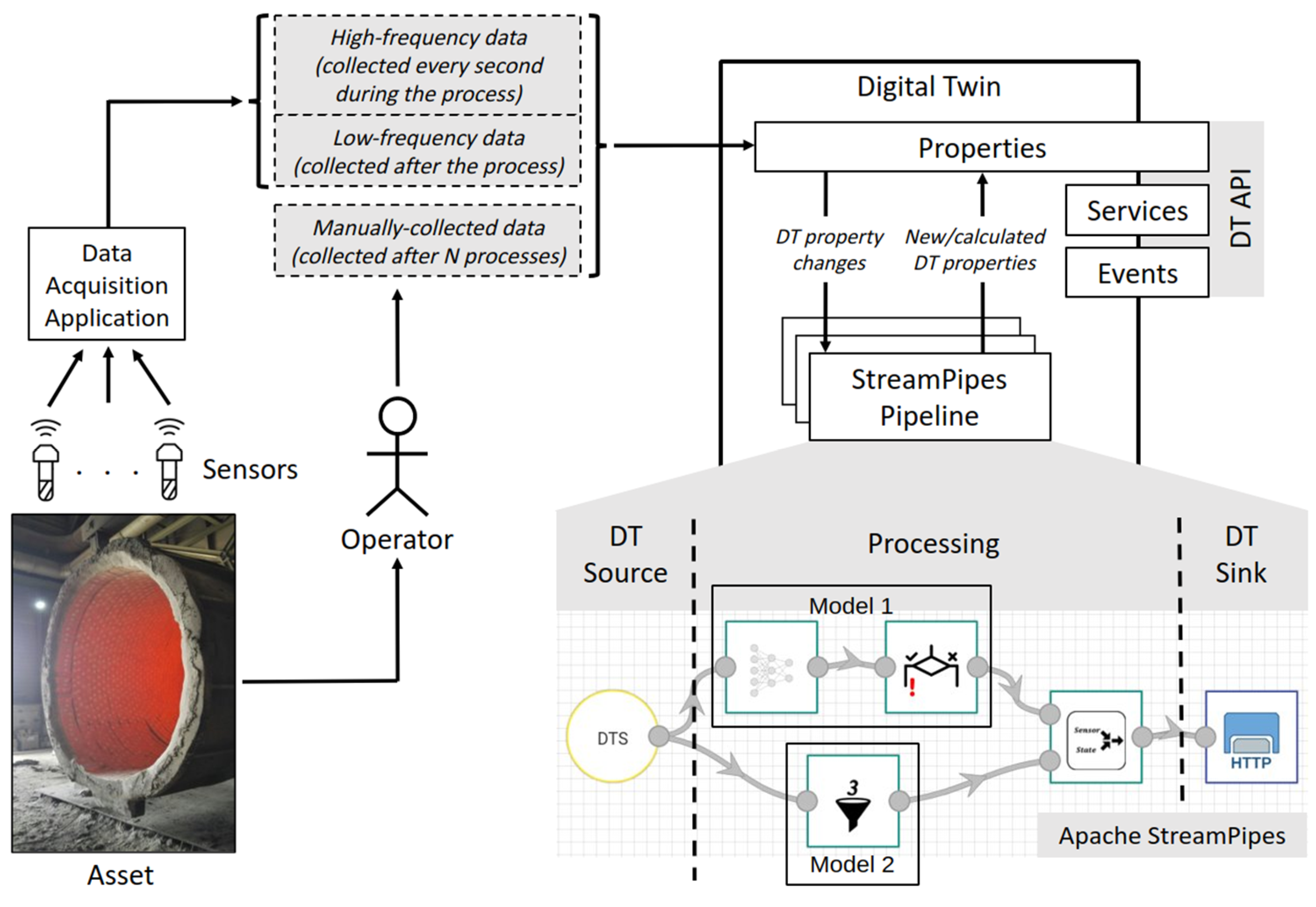
5. Steel Production Use Case
5.1. Description of Available Data
- Low-frequency data—Single measurement per parameter, collected at the end of each ladle usage. Monitored parameters include the percentage of sulfur after vacuum, total electrical consumption, total amount of lime added, amount of time of steel being in the ladle, amount of alumina added, percentage of sulfur at tapping, whether burners are used, amount of time for vacuum, amount of gas used for stirring, amount of fluorspar added, amount of steel, continuous casting format, desulfurization speed, amount of time the ladle was powered on, percentage of EAF slag at tapping, and percentage of manganese at tapping. Historical acyclic data are used for the training of machine learning and deep learning models, while real-time acyclic data are used for inference.
- High-frequency data—Time-series measurements per parameter, collected every second during each ladle usage. Monitored parameters are nitrogen or argon pressure, gas flow rate, back pressure, type of used gas, gas instruction, vacuum pressure, temperature, and electrical consumption. Real-time cyclic data are used for outlier detection.
- Manually collected data—Measurements of brick thickness after each cycle of ladle usage. The ladle is vertically split in half, and for each half and for each layer of bricks in it, the minimum value of brick thickness is recorded. This type of data is not relevant for real-time processing. It is used for deep learning model training instead.
5.2. Implemented Pipelines
- Deep Learning—Fully connected neural network model that takes low-frequency data as input and outputs the predicted tool state. Input data pass through a preprocessing step that is integrated into separate pipeline elements and is executed before the neural network.
- Statistical Analysis—Model that applies change point detection and a multivariate exponentially weighted moving average control chart on high-frequency data, detecting possible outliers and their root causes.
- Complex Event Processing—Model that applies complex event processing using Siddhi [20].
- Machine Learning—Partial least squares regression model that uses low-frequency data to infer whether or not the tool can be used without any incidents. This model requires a preprocessing step that should be integrated into a separate pipeline element.
- Physics based—Model that uses the laws of physics to calculate the values of parameters that are not being monitored, thus providing other models with additional information about the process.
- The physics-based model calculates the thickness of the brick walls in each heat. We note here that there is no such value in the original dataset.
- The deep learning model uses this new information provided by the physics-based model as an additional input for the training process and generates more accurate predictions on whether the ladle can be used in the next run. It should be emphasized that without this additional data, the algorithm was not able to make an accurate generalization of the prediction model, since the model was under-fitted.
6. Conclusions and Outlook
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Industrial Internet Consortium, Digital Twins for Industrial Application, an Industrial Internet Consortium White Paper. Available online: https://www.iiconsortium.org/pdf/IIC_Digital_Twins_Industrial_Apps_White_Paper_2020-02-18.pdf (accessed on 20 March 2021).
- Antunes do Carmo, J.S. Physical Modelling vs. Numerical Modelling: Complementarity and Learning; Preprints: Basel, Switzerland, 2020. [Google Scholar] [CrossRef]
- Hybrid Modeling in Process Industries; Glassey, J., von Stosch, M., Eds.; CRC Press: Boca Raton, FL, USA, 2020; ISBN 9780367572228. [Google Scholar]
- Lin, P.; Yuan, X.X.; Tovilla, E. Integrative modeling of performance deterioration and maintenance effectiveness for infrastructure assets with missing condition data. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 677–695. [Google Scholar] [CrossRef]
- Abburu, S.; Roman, D.; Berre, A.; Stojanovic, L.; Jacoby, M.; Stojanovic, N. COGNITWIN–Hybrid and Cognitive Digital Twins for the Process Industry. In Proceedings of the IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Cardiff, UK, 15–17 June 2020; Available online: https://doi.org/10.1109/ICE/ITMC49519.2020.9198403 (accessed on 20 March 2021).
- Hamilton, F.; Lloyd, A.L.; Flores, K.B. Hybrid modeling and prediction of dynamical systems. PLoS Comput. Biol. 2017, 13, e1005655. [Google Scholar] [CrossRef] [PubMed]
- Apache StreamPipes. Available online: https://streampipes.apache.org/ (accessed on 20 March 2021).
- Details of the Asset Administration Shell: From Idea to Implementation. Plattform Industrie 4.0, Ed. Available online: https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/vws-in-detail-presentation.pdf (accessed on 20 March 2020).
- Jacoby, M.; Usländer, T. Digital Twin and Internet of Things—Current Standards Landscape. Appl. Sci. 2020, 10, 6519. [Google Scholar] [CrossRef]
- Stojanovic, L.; Bader, S.R. Smart Services in the Physical World: Digital Twins. In Smart Service Management: Design Guidelines and Best Practices; Maleshkova, M., Kühl, N., Jussen, P., Eds.; Springer International Publishing: Cham, Germany, 2020; pp. 137–147. [Google Scholar] [CrossRef]
- Plattform Industrie 4.0—Digital Twin and Asset Administration Shell Concepts and Application in the Industrial Internet and Industrie 4.0 (Plattform-i40.de). Available online: https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/Digital-Twin-and-Asset-Administration-Shell-Concepts.html (accessed on 12 May 2021).
- Shohin, A.; Xun, X.; Ray, Y.; Zhong, Y.L. Digital Twin as a Service (DTaaS) in Industry 4.0: An Architecture Reference Model, Advanced Engineering Informatics. Adv. Eng. Inform. 2021, 47, 101225. [Google Scholar] [CrossRef]
- Sepasgozar, S.M.E. Differentiating Digital Twin from Digital Shadow: Elucidating a Paradigm Shift to Expedite a Smart, Sustainable Built Environment. Buildings 2021, 11, 151. [Google Scholar] [CrossRef]
- DIN SPEC 91345:2016-04, Reference Architecture Model Industrie 4.0 (RAMI4.0). Available online: https://www.beuth.de/en/technical-rule/din-spec-91345/250940128 (accessed on 20 March 2021).
- Platform Industrie 4.0, Details of the Asset Administration Shell—Part 1. Available online: https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/Details_of_the_Asset_Administration_Shell_Part1_V3.pdf?__blob=publicationFile&v=5 (accessed on 20 March 2021).
- Platform Industrie 4.0, Details of the Asset Administration Shell—Part 2. Available online: https://www.plattform-i40.de/PI40/Redaktion/EN/Downloads/Publikation/Details_of_the_Asset_Administration_Shell_Part2_V1.pdf?__blob=publicationFile&v=6 (accessed on 20 March 2021).
- Node Red. Available online: https://nodered.org/ (accessed on 8 April 2021).
- Introducing Node-RED 1.0. Available online: https://nodered.org/ (accessed on 26 April 2021).
- I4.0 Language. Available online: https://www.i40.ovgu.de/i40/en/I4_0+language-p-48.html (accessed on 8 April 2021).
- Siddhi—Cloud Native Stream Processor. Available online: https://siddhi.io/ (accessed on 26 April 2021).









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jacoby, M.; Jovicic, B.; Stojanovic, L.; Stojanović, N. An Approach for Realizing Hybrid Digital Twins Using Asset Administration Shells and Apache StreamPipes. Information 2021, 12, 217. https://doi.org/10.3390/info12060217
Jacoby M, Jovicic B, Stojanovic L, Stojanović N. An Approach for Realizing Hybrid Digital Twins Using Asset Administration Shells and Apache StreamPipes. Information. 2021; 12(6):217. https://doi.org/10.3390/info12060217
Chicago/Turabian StyleJacoby, Michael, Branislav Jovicic, Ljiljana Stojanovic, and Nenad Stojanović. 2021. "An Approach for Realizing Hybrid Digital Twins Using Asset Administration Shells and Apache StreamPipes" Information 12, no. 6: 217. https://doi.org/10.3390/info12060217
APA StyleJacoby, M., Jovicic, B., Stojanovic, L., & Stojanović, N. (2021). An Approach for Realizing Hybrid Digital Twins Using Asset Administration Shells and Apache StreamPipes. Information, 12(6), 217. https://doi.org/10.3390/info12060217