A Distributed Approach to Speaker Count Problem in an Open-Set Scenario by Clustering Pitch Features


Abstract
1. Introduction
- Crowd++ combines Pitch with MFCC (a general-purpose feature in speech processing) for estimating the speaker count. Whereas in the proposed algorithm, we extract features only from the Pitch to estimate the speaker count. Thus, minimizing the computational overheads in terms of real-time factors.
- Crowd++ states it is an entirely distributed approach as it does not have any infrastructural requirements, at the same time, it simply adds the results of the multiple microphones (in-case of multi-group scenarios) to estimate the speaker count, overlooking the proximity of a speaker to multiple microphones (as shown in the Figure 1), which may result to over-count. As a solution to the problem, the proposed distributed approach performs a periodic exchange of extracted statistical features, which results in a more accurate approximation of speaker count.
- In Crowd++, each SD runs the application individually, which may result in variable results due to various challenges like the phone’s location (in or out pocket), SD’s hardware. While in the proposed distributed approach, all the participating SD’s will generate the same result.
- The proposed distributed approach provides a setup enhancing the system’s scalability, while there is no such discussion about it in Crowd++.
- Location of phone: The position of the phone (e.g., inside a pocket or a bag) affects the sensitivity of the microphone, which may result in an over-count or under-count of speakers.
- Background Noise: In real-world scenarios, other sources of interference are voice generated by TV or radio equipment which can cause over-count.
- Real-time speaker count: Speaker count in a real-time scenario is a challenging task, as the cluster identification time depends on the distances between the feature vector of an unknown speaker and dataset.
- Proximity to Microphones: As we are considering multiple microphones in the region of interest, the proximity of a speaker to multiple phones should not affect the overall speaker count.
- Open-set speaker count: In a large-scale real-time environment, the system should not consider any prior knowledge of the speakers in the audio sample.
- Scalability: The system must handle dynamic and crowded environments.
2. Related Works
3. Distributed Speaker Count
3.1. System Architecture
3.2. System Modules
3.2.1. Data Acquisition Module
3.2.2. Feature Extraction Module
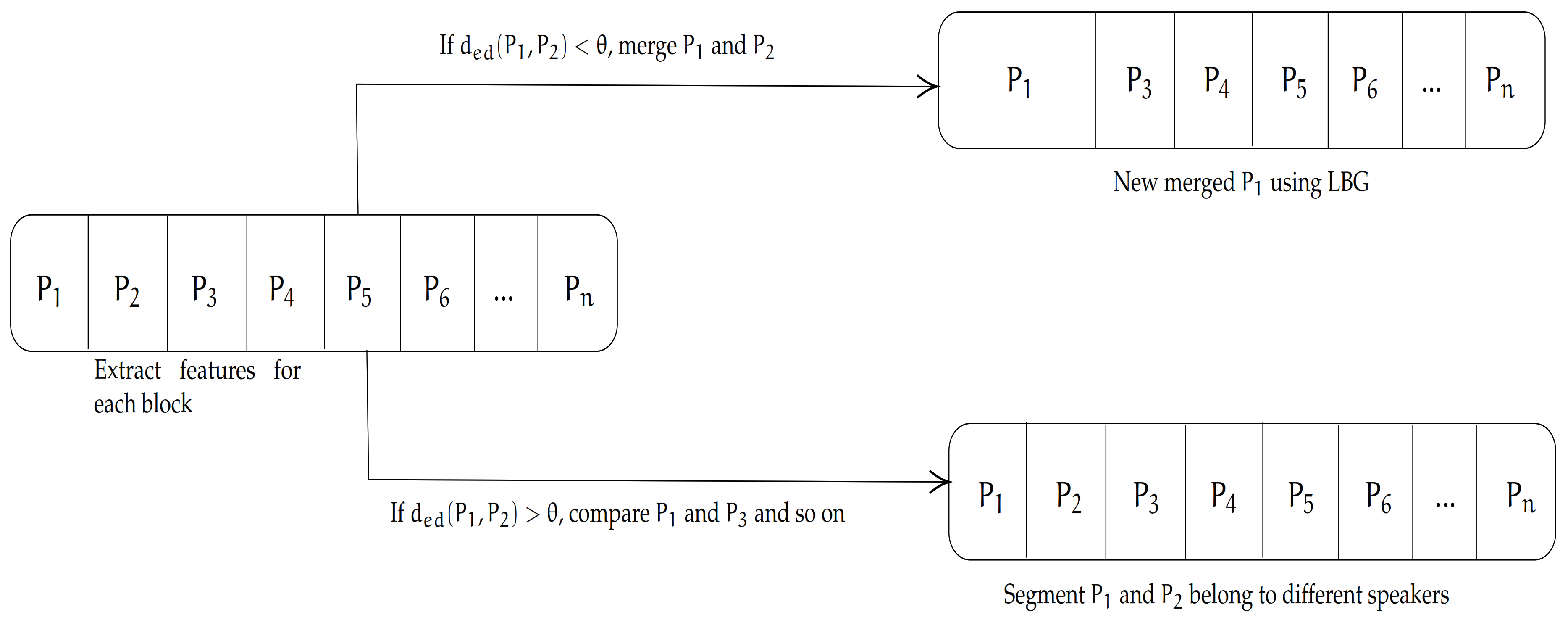
3.2.3. Feature Clustering Module
3.3. Proposed Algorithm
| Algorithm 1: System Modules of the Proposed Distributed Speaker Count Algorithm. |
 |
| Algorithm 2: Distributed Speaker Count Algorithm. |
 |
4. Experimental Results
4.1. Evaluation of the Threshold ()
4.2. Performance in Single Group Scenario
4.3. Performance in Multiple Groups Scenario
4.3.1. Performance of Two Group Scenario
4.3.2. Performance of Three Group Scenario
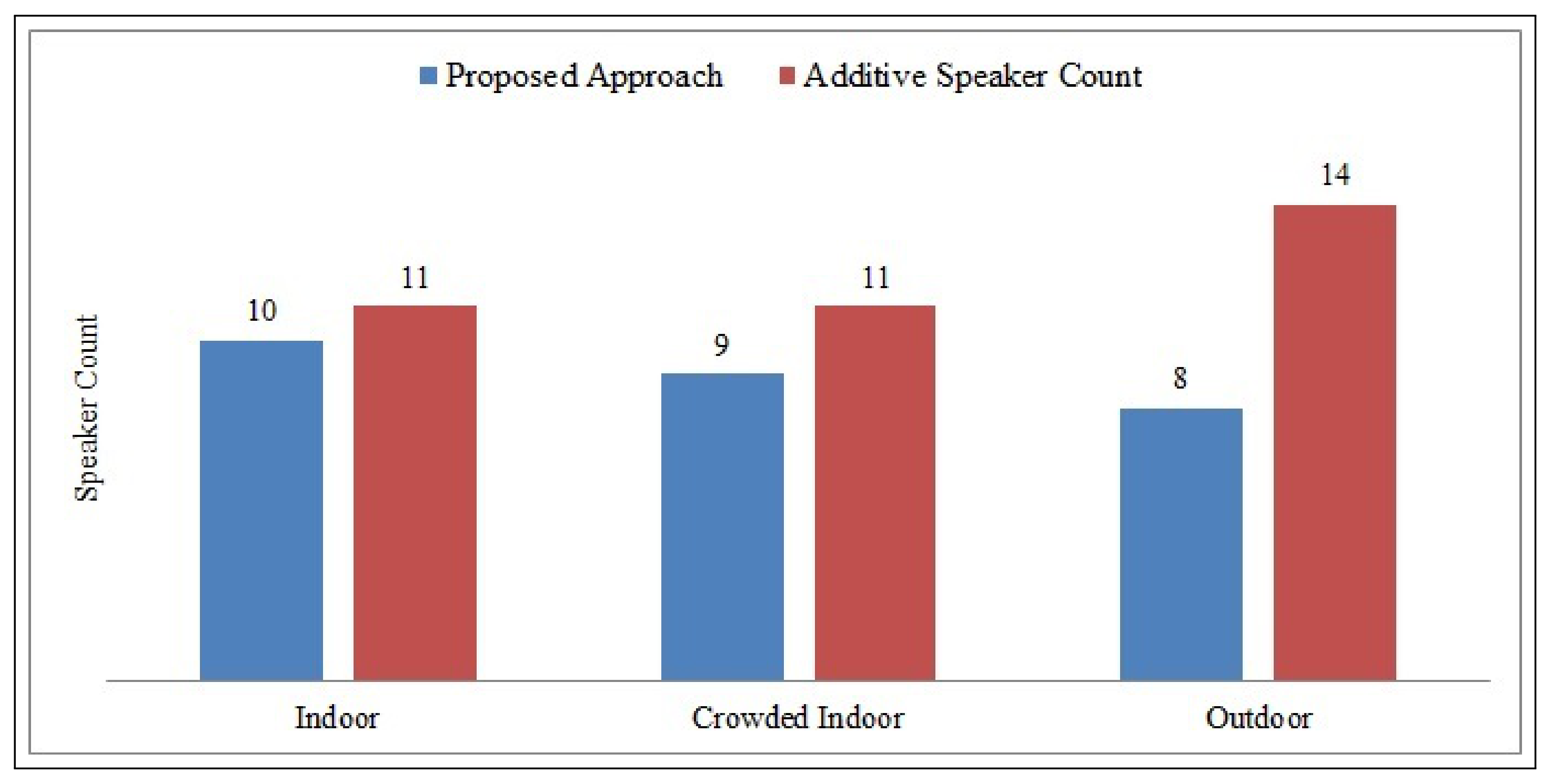
4.4. Performance in Indoor and Outdoor Environment
5. Discussion
- Applications: The real-time distributed speaker count architecture can be used in a restaurant, movie theater, or shopping mall to rank the popularity of an event, object, or place. This is based on the assumption that a place’s popularity is directly related to the number of people present nearby. Real-time ranking can help consumers make suitable choices. One can also use the methodology for determining audience participation in a lecture room for analyzing the popularity of lectures in the university.
- Complexity: The complexity of the DataAcquisition() and FeatureExtraction() modules discussed in Algorithm 2 is , where n is the number of pitch samples collected. Similarly the complexity of the FeatureClustering() module in worst case i.e., no two blocks merge, while on an average the complexity of FeatureClustering() module is . Thus, the overall complexity of the proposed algorithm (i.e., Algorithm 1) in worst case is and in average case .
- Scalability: The proposed algorithm groups the SDs into disjoint clusters to increase the scalability of the system. Researchers have proposed various distributed approaches for clustering the nodes in a dynamic environment, which plays a role in handling a large number of nodes in a geographic area. The system’s scalability can be further improved by using hierarchical clustering [22].
- Improvements: To improve the accuracy of the proposed methodology, we can include other statistical parameters, like median and average velocity of f0 change. Additionally, filtering the background noise can improve the accuracy in outdoor environments.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Suresh, V.; Roohi, S.; Eirinaki, M. Aspect-based opinion mining and recommendationsystem for restaurant reviews. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, CA, USA, 6–10 October 2014; pp. 361–362. [Google Scholar]
- Fu, Y.; Ge, Y.; Zheng, Y.; Yao, Z.; Liu, Y.; Xiong, H.; Yuan, J. Sparse real estate ranking with online user reviews and offline moving behaviors. In Proceedings of the 2014 IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 120–129. [Google Scholar]
- Sun, M.; Lebanon, G.; Kidwell, P. Estimating probabilities in recommendation systems. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11 April 2011; pp. 734–742. [Google Scholar]
- Agneessens, A.; Bisio, I.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Speaker count application for smartphone platforms. In Proceedings of the 2010 5th IEEE International Symposium on Wireless Pervasive Computing (ISWPC), Modena, Italy, 5–7 May 2010; pp. 361–366. [Google Scholar]
- Xu, C.; Li, S.; Liu, G.; Zhang, Y.; Miluzzo, E.; Chen, Y.F.; Li, J.; Firner, B. Crowd++: Unsupervised speaker count with smartphones. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 43–52. [Google Scholar]
- Li, Y.; Narayanan, S.S.; Kuo, C.C.J. Adaptive speaker identification with audiovisual cues for movie content analysis. Pattern Recognit. Lett. 2004, 25, 777–791. [Google Scholar] [CrossRef]
- Sanchez-Riera, J.; Alameda-Pineda, X.; Wienke, J.; Deleforge, A.; Arias, S.; Čech, J.; Wrede, S.; Horaud, R. Online multimodal speaker detection for humanoid robots. In Proceedings of the 2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012), Osaka, Japan, 29 November–1 December 2012; pp. 126–133. [Google Scholar]
- Stöter, F.R.; Chakrabarty, S.; Edler, B.; Habets, E.A. Classification vs. regression in supervised learning for single channel speaker count estimation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 436–440. [Google Scholar]
- Stöter, F.R.; Chakrabarty, S.; Edler, B.; Habets, E.A. CountNet: Estimating the number of concurrent speakers using supervised learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 268–282. [Google Scholar] [CrossRef]
- Tharp, A.L.; Middleton, E.A. A quasi-distributed architecture for database management systems. In Proceedings of the 17th Conference on ACM Annual Computer Science Conference, Louisville, KY, USA, 21–23 February 1989; pp. 344–347. [Google Scholar]
- Banerjee, A.; Pandey, S.; Hussainy, M.A. Separability of Human Voices by Clustering Statistical Pitch Parameters. In Proceedings of the 2018 3rd International Conference for Convergence in Technology (I2CT), Pune, India, 6–8 April 2018; pp. 1–5. [Google Scholar]
- Singh, N.; Khan, R.; Shree, R. Mfcc and prosodic feature extraction techniques: A comparative study. Int. J. Comput. Appl. 2012, 54, 9–13. [Google Scholar] [CrossRef]
- Bartkova, K.; Gac, D.L.; Charlet, D.; Jouvet, D. Prosodic parameter for speaker identification. In Proceedings of the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, 12–20 September 2002. [Google Scholar]
- de Abreu Campos, V.; Pedronette, D.C.G. A framework for speaker retrieval and identification through unsupervised learning. Comput. Speech Lang. 2019, 58, 153–174. [Google Scholar] [CrossRef]
- Andrei, V.; Cucu, H.; Burileanu, C. Overlapped Speech Detection and Competing Speaker Counting—Humans Versus Deep Learning. IEEE J. Sel. Top. Signal Process. 2019, 13, 850–862. [Google Scholar] [CrossRef]
- Wang, W.; Seraj, F.; Meratnia, N.; Havinga, P.J. Speaker Counting Model based on Transfer Learning from SincNet Bottleneck Layer. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications (PerCom), Austin, TX, USA, 23–27 March 2020; pp. 1–8. [Google Scholar]
- Liu, Q.; Yao, M.; Xu, H.; Wang, F. Research on different feature parameters in speaker recognition. J. Signal Inf. Process. 2013, 4, 106. [Google Scholar] [CrossRef]
- Ng, R.W.; Lee, T.; Leung, C.C.; Ma, B.; Li, H. Analysis and selection of prosodic features for language identification. In Proceedings of the 2009 International Conference on Asian Language Processing (IALP’09), Singapore, 7–9 December 2009; pp. 123–128. [Google Scholar]
- Ofoegbu, U.O.; Iyer, A.N.; Yantorno, R.E.; Smolenski, B.Y. A speaker count system for telephone conversations. In Proceedings of the 2006 International Symposium on Intelligent Signal Processing and Communications, Yonago, Japan, 12–15 December 2006; pp. 331–334. [Google Scholar]
- Anguera, X.; Bozonnet, S.; Evans, N.; Fredouille, C.; Friedland, G.; Vinyals, O. Speaker diarization: A review of recent research. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 356–370. [Google Scholar] [CrossRef]
- Farnstrom, F.; Lewis, J.; Elkan, C. Scalability for clustering algorithms revisited. ACM SIGKDD Explor. Newsl. 2000, 2, 51–57. [Google Scholar] [CrossRef]
- Banerjee, S.; Khuller, S. A clustering scheme for hierarchical control in multi-hop wireless networks. In Proceedings of the IEEE INFOCOM 2001, Conference on Computer Communications, Twentieth Annual Joint Conference of the IEEE Computer and Communications Society (Cat. No. 01CH37213), Anchorage, AK, USA, 22–26 April 2001; Volume 2, pp. 1028–1037. [Google Scholar]
- Agarwal, R.; Motwani, D. Survey of clustering algorithms for MANET. arXiv 2009, arXiv:0912.2303. [Google Scholar]
- Wan, P.J.; Alzoubi, K.M.; Frieder, O. Distributed construction of connected dominating set in wireless ad hoc networks. In Proceedings of the Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 23–27 June 2002; Volume 3, pp. 1597–1604. [Google Scholar]
- Bechler, M.; Hof, H.J.; Kraft, D.; Pahlke, F.; Wolf, L. A cluster-based security architecture for ad hoc networks. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; Volume 4, pp. 2393–2403. [Google Scholar]
- Gielow, F.; Jakllari, G.; Nogueira, M.; Santos, A. Data similarity aware dynamic node clustering in wireless sensor networks. Ad Hoc Netw. 2015, 24, 29–45. [Google Scholar] [CrossRef]
- Younis, O.; Fahmy, S. HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans. Mob. Comput. 2004, 3, 366–379. [Google Scholar] [CrossRef]
- Younis, O.; Fahmy, S. Distributed clustering in ad-hoc sensor networks: A hybrid, energy-efficient approach. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; Volume 1. [Google Scholar]
- De Cheveigné, A.; Kawahara, H. YIN, a fundamental frequency estimator for speech and music. J. Acoust. Soc. Am. 2002, 111, 1917–1930. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Bernheim Brush, A.; Priyantha, B.; Karlson, A.; Liu, J. Speakersense: Energy efficient unobtrusive speaker identification on mobile phones. Pervasive Comput. 2011, 6696, 188–205. [Google Scholar]
- Pernet, C.R.; Belin, P. The role of pitch and timbre in voice gender categorization. Front. Psychol. 2012, 3, 23. [Google Scholar] [CrossRef] [PubMed]
- Linde, Y.; Buzo, A.; Gray, R. An algorithm for vector quantizer design. IEEE Trans. Commun. 1980, 28, 84–95. [Google Scholar] [CrossRef]
- Gray, R.M. Vector quantization. Readings Speech Recognit. 1990, 1, 75–100. [Google Scholar]
- Lu, H.; Brush, A.B.; Priyantha, B.; Karlson, A.K.; Liu, J. Speakersense: Energy efficient unobtrusive speaker identification on mobile phones. In Proceedings of the International Conference on Pervasive Computing, San Francisco, CA, USA, 12–15 June 2011; pp. 188–205. [Google Scholar]
- Liu, G.; Zhang, C.; Hansen, J.H. A linguistic data acquisition front-end for language recognition evaluation. In Proceedings of the Odyssey 2012—The Speaker and Language Recognition Workshop, Singapore, 25–28 June 2012. [Google Scholar]
- Liu, G.; Dimitriadis, D.; Bocchieri, E. Robust speech enhancement techniques for ASR in non-stationary noise and dynamic environments. In Proceedings of the 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 3017–3021. [Google Scholar]
- Blue, L.; Vargas, L.; Traynor, P. Hello, is it me you’re looking for? differentiating between human and electronic speakers for voice interface security. In Proceedings of the 11th ACM Conference on Security & Privacy in Wireless and Mobile Networks, Stockholm, Sweden, 18–20 June 2018; pp. 123–133. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Clusters | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| Size | 25 | 33 | 32 |
| 118.4341 | 177.4756 | 118.334 | |
| 29.3108 | 51.5388 | 14.2691 | |
| −0.8291 | −0.9232 | −0.1311 | |
| 3.4473 | 3.4345 | 6.9116 | |
| Speaker | Inter Cluster | ||
|---|---|---|---|
| Average | Min | Max | |
| 4 | 45.9259 | 26.44 | 69.97 |
| 5 | 37.489 | 28.21 | 56.16 |
| 6 | 34.08 | 28.69 | 58.75 |
| 7 | 34.444 | 28.45 | 56.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pandey, S.; Banerjee, A. A Distributed Approach to Speaker Count Problem in an Open-Set Scenario by Clustering Pitch Features. Information 2021, 12, 157. https://doi.org/10.3390/info12040157
Pandey S, Banerjee A. A Distributed Approach to Speaker Count Problem in an Open-Set Scenario by Clustering Pitch Features. Information. 2021; 12(4):157. https://doi.org/10.3390/info12040157
Chicago/Turabian StylePandey, Sakshi, and Amit Banerjee. 2021. "A Distributed Approach to Speaker Count Problem in an Open-Set Scenario by Clustering Pitch Features" Information 12, no. 4: 157. https://doi.org/10.3390/info12040157
APA StylePandey, S., & Banerjee, A. (2021). A Distributed Approach to Speaker Count Problem in an Open-Set Scenario by Clustering Pitch Features. Information, 12(4), 157. https://doi.org/10.3390/info12040157