
Explainable AI for Psychological Profiling from Behavioral Data: An Application to Big Five Personality Predictions from Financial Transaction Records


Abstract
:1. Introduction
1.1. AI as a Black Box
1.2. Why the Interpretability of AI Matters
1.2.1. Trust and Compliance
1.2.2. Improved Insights
1.2.3. Model Improvement
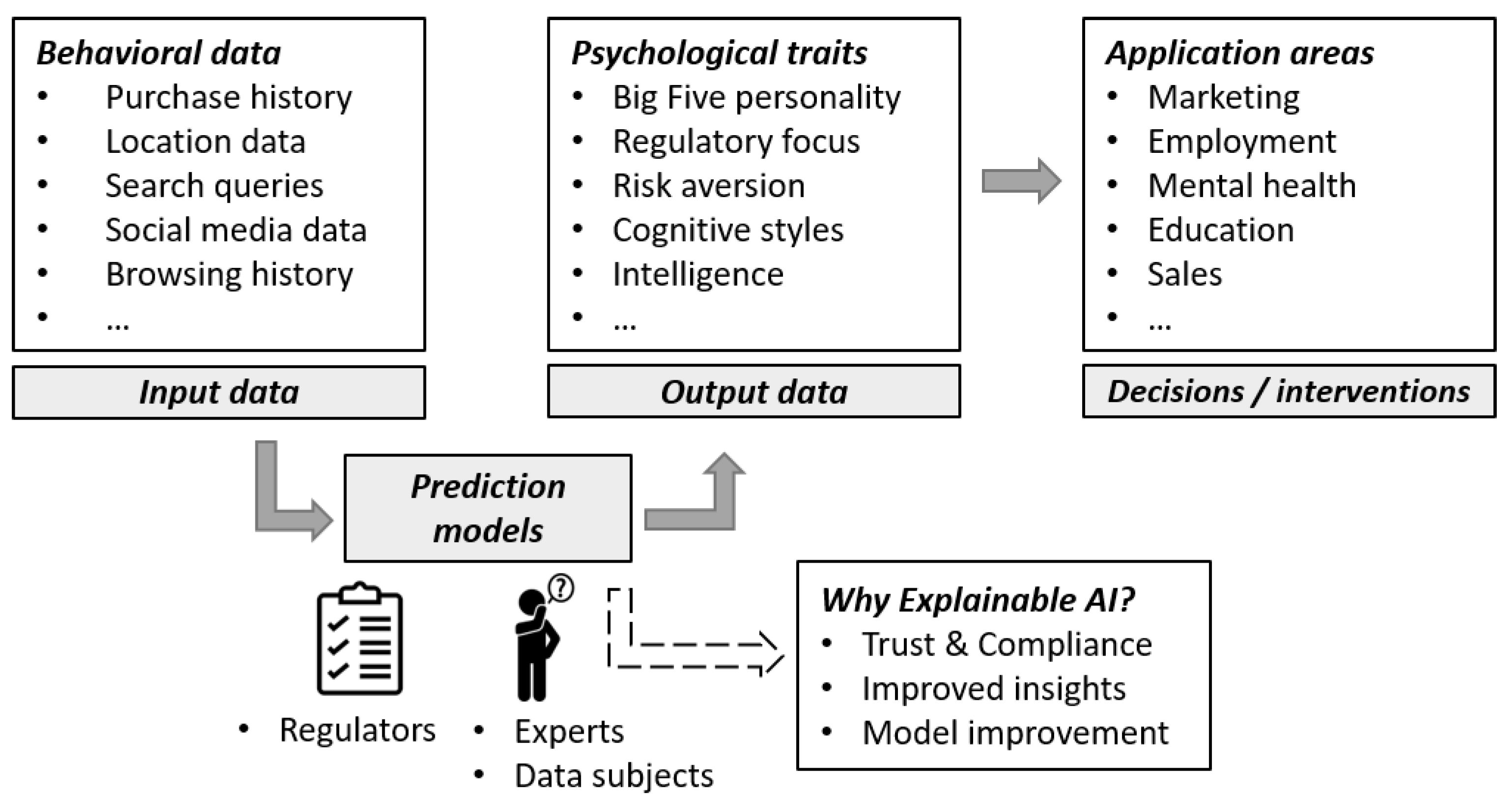
1.3. Using Explainable AI to Overcome Black Box Approaches: Research Overview
2. Introduction to the Field of Explainable AI (XAI)
2.1. Rules as Global Explanations
2.2. Counterfactual Rules as Local Explanations
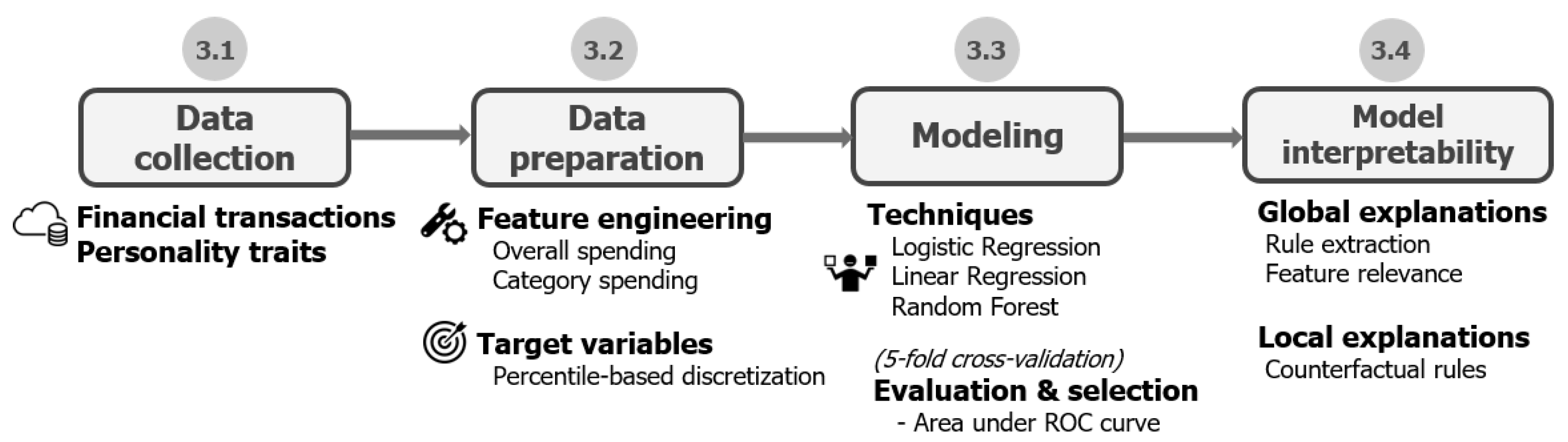
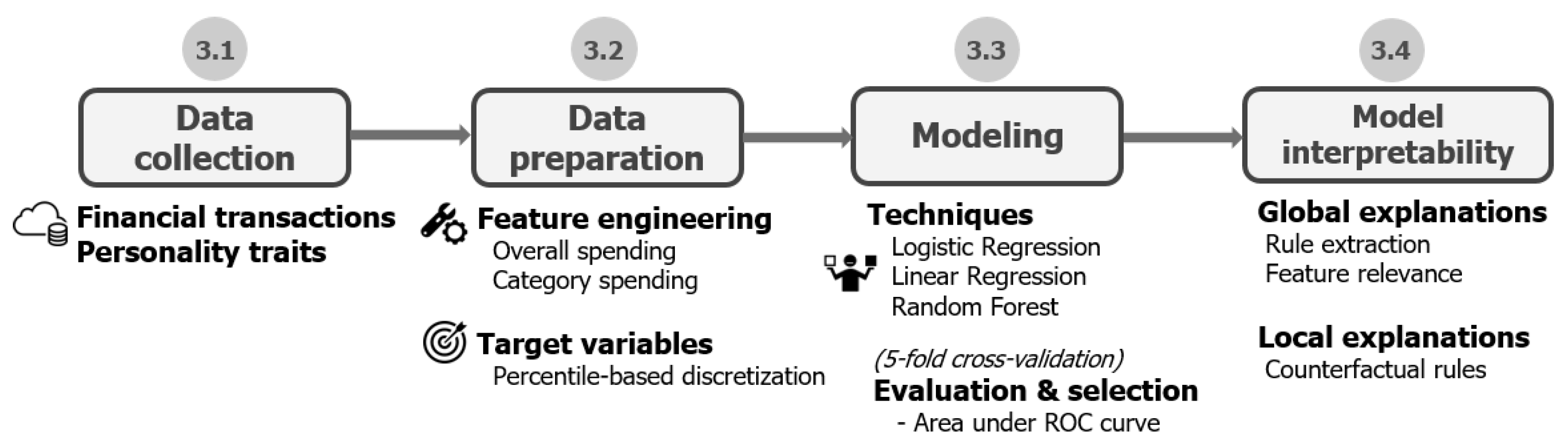
3. Case Study: Predicting Personality Traits from Financial Transaction Records
3.1. Data Collection
3.1.1. Financial Transactions
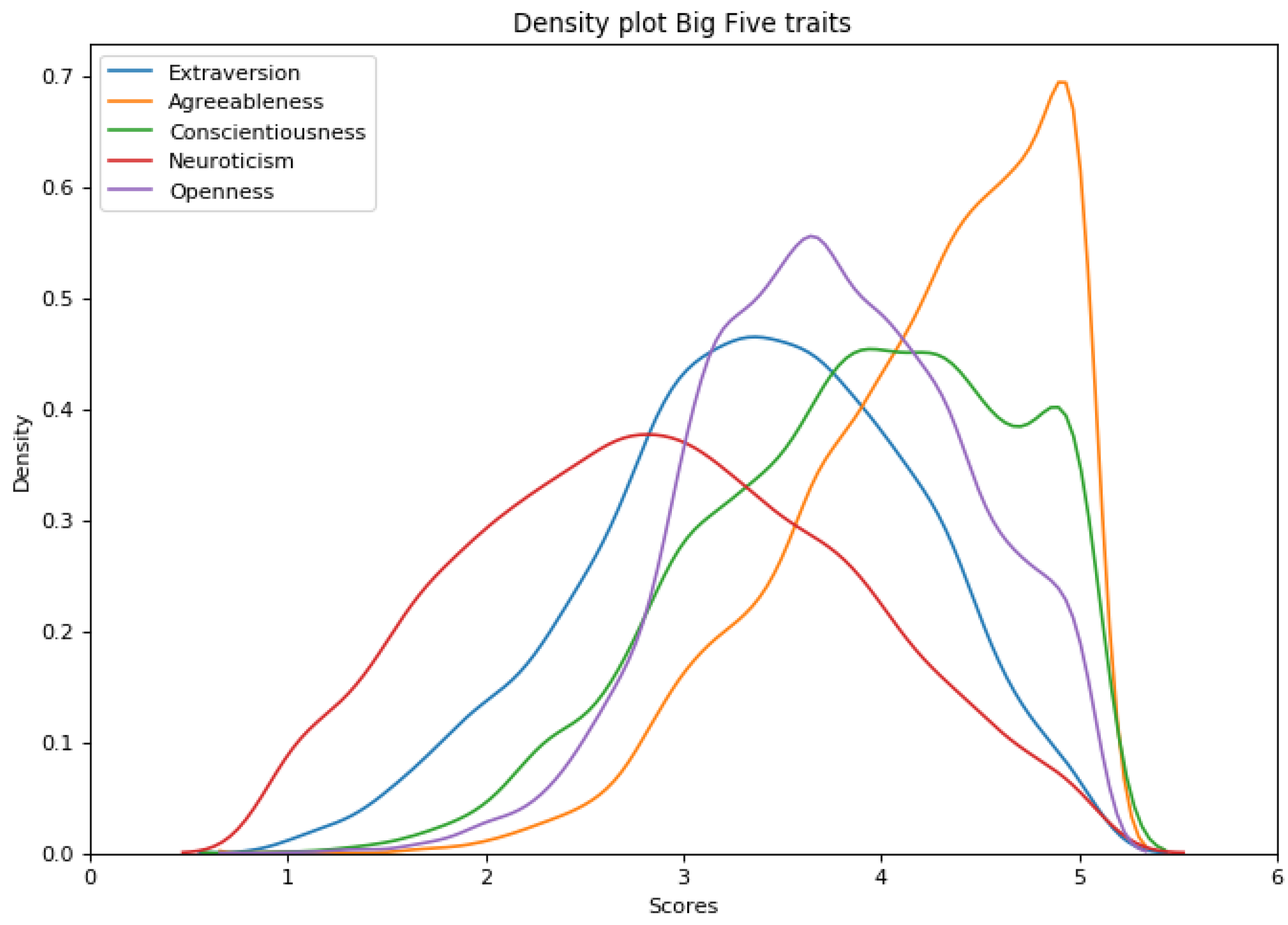
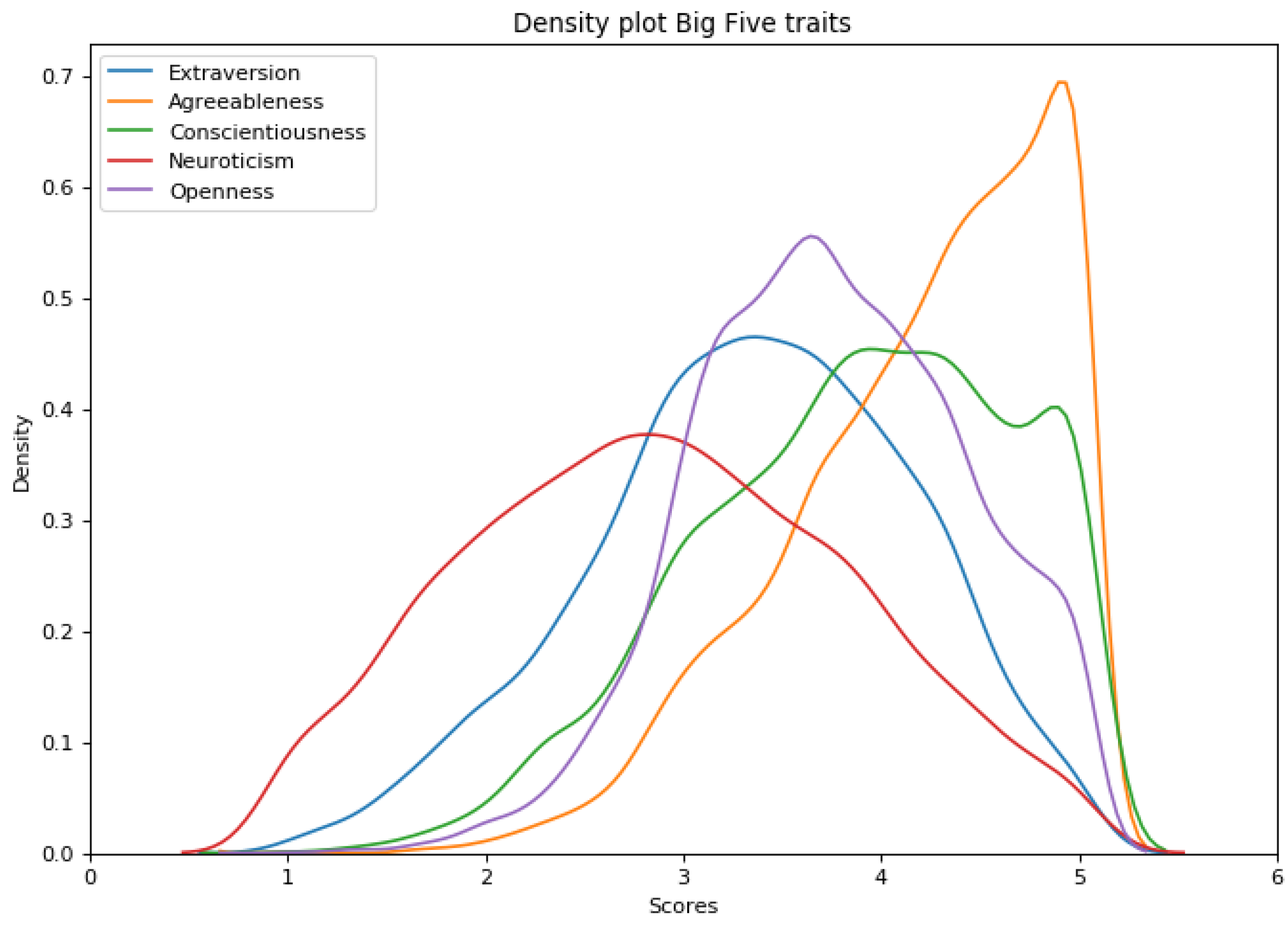
3.1.2. Personality Traits
- Extraversion: Sociability, Assertiveness, Energy
- Agreeableness: Compassion, Respectfulness, Trust
- Conscientiousness: Organization, Productivity, Responsibility
- Neuroticism: Anxiety, Depression, Emotional Volatility
- Openness: Intellectual Curiosity, Aesthetic Sensitivity, Creative Imagination
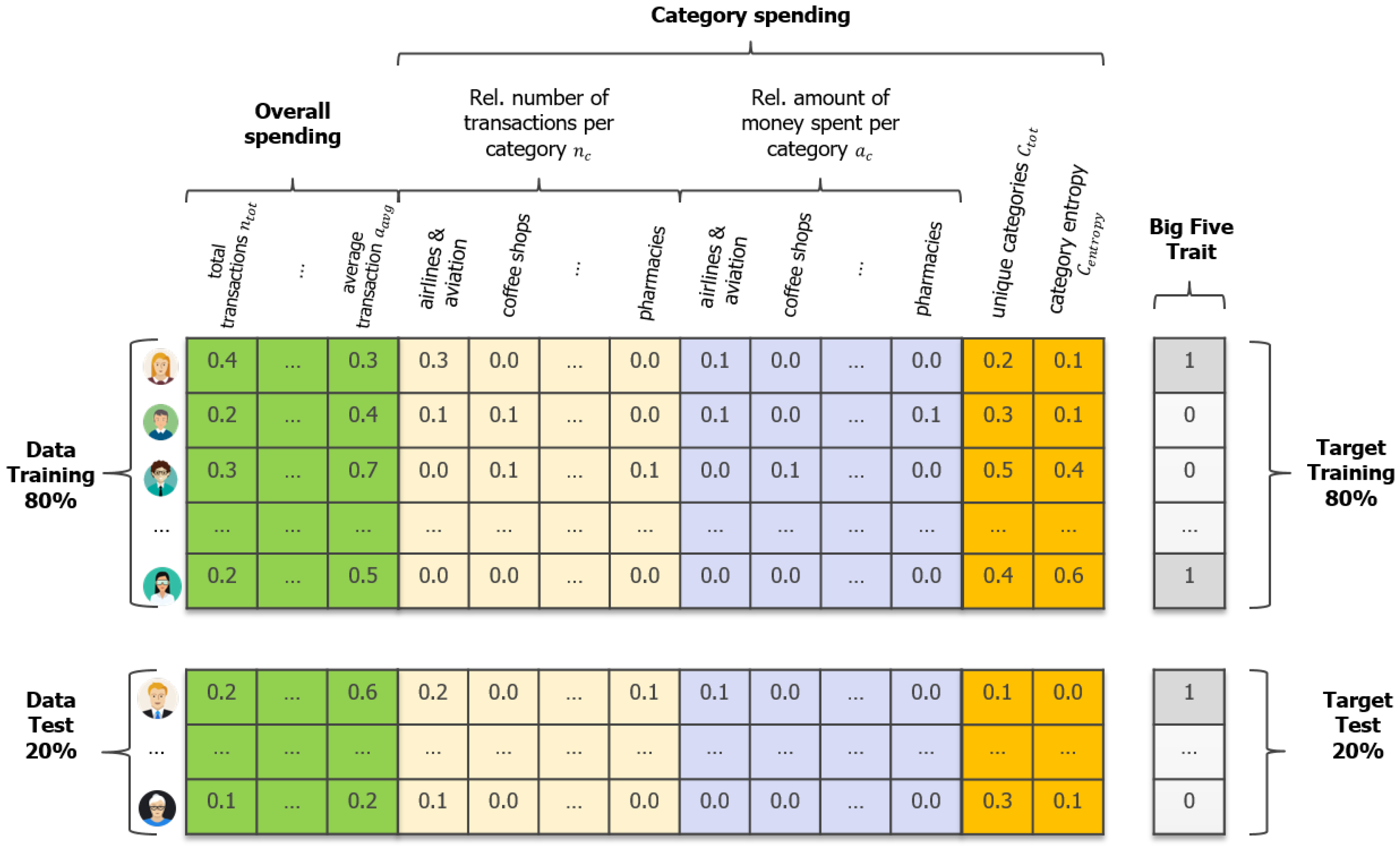
3.2. Data Preparation
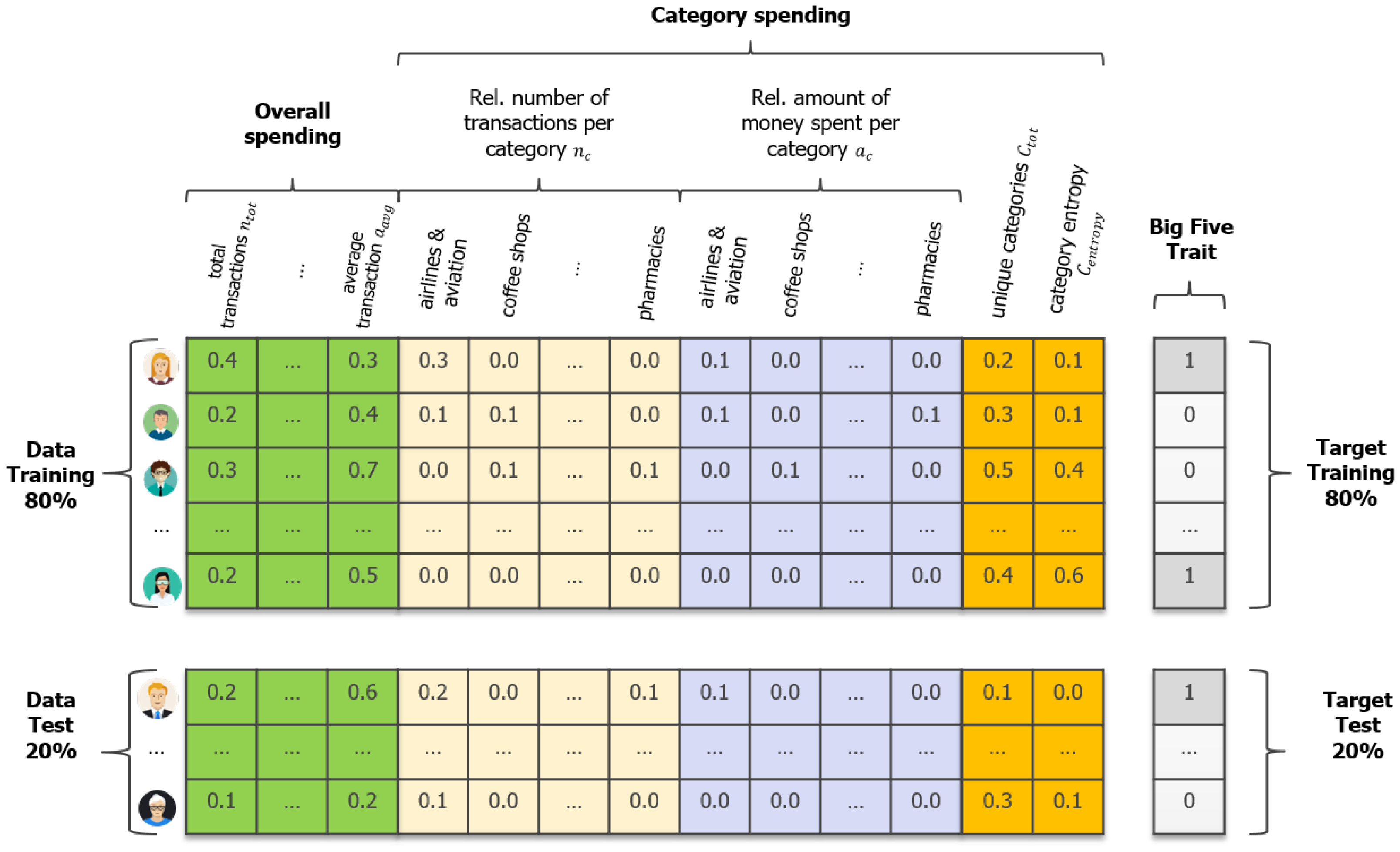
3.2.1. Feature Engineering
3.2.2. Target Variables
3.3. Modeling
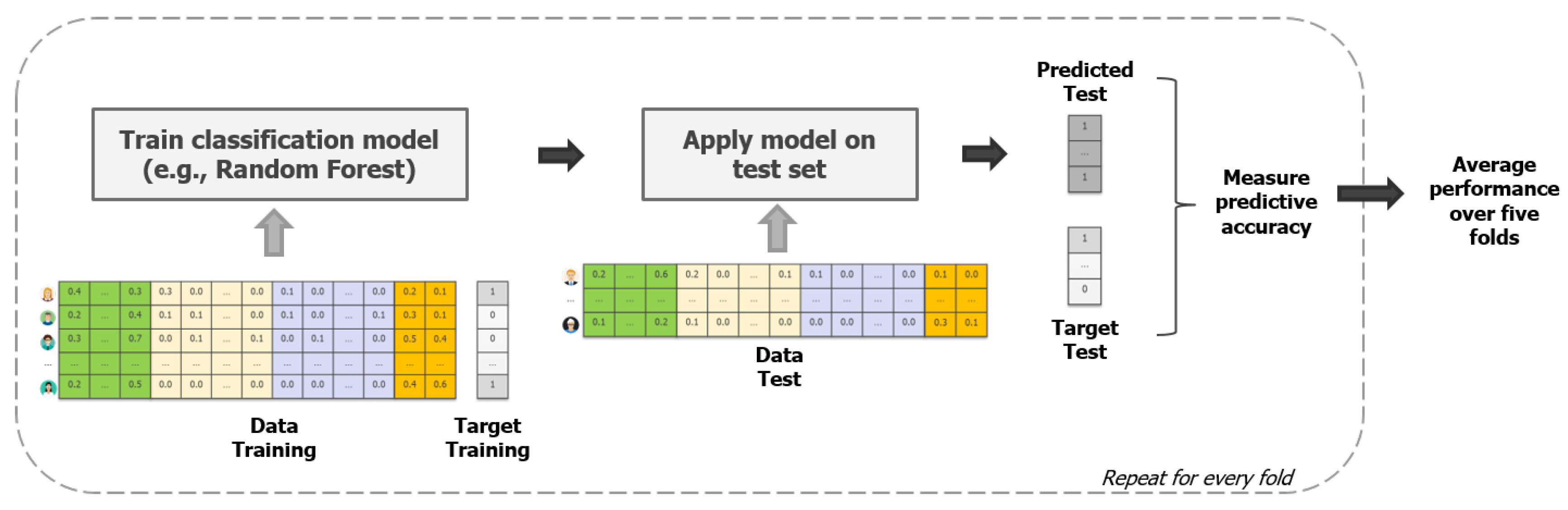
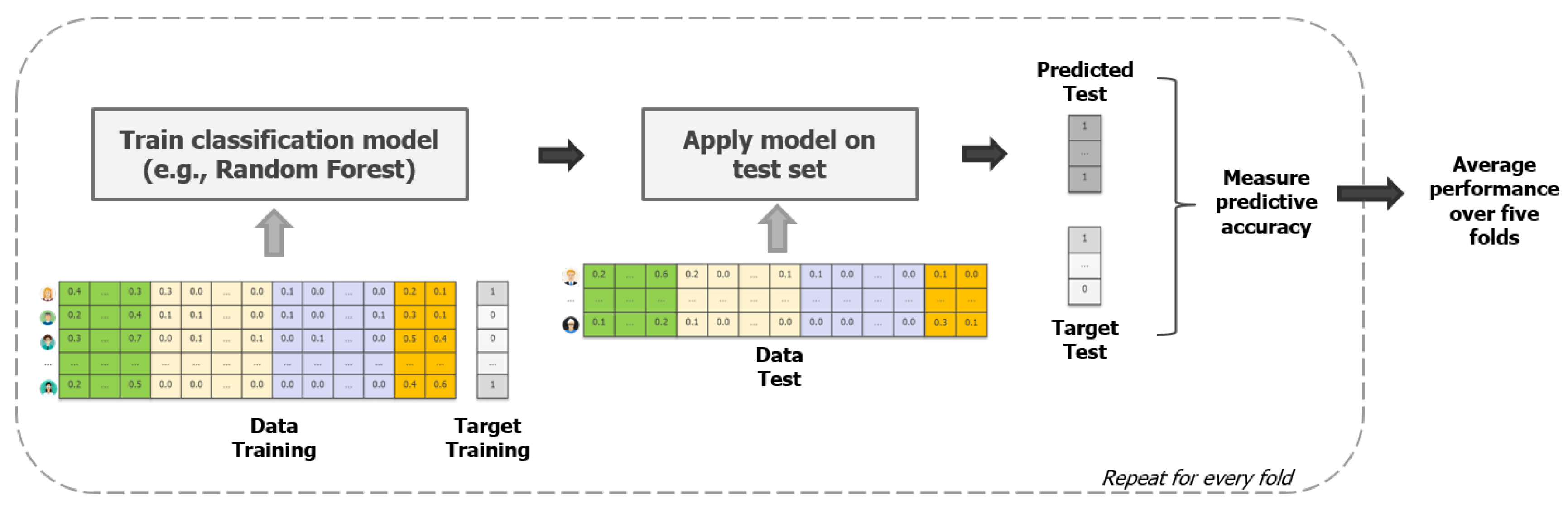
3.3.1. Modeling Techniques
3.3.2. Evaluation & Selection
3.4. Model Interpretability
3.4.1. Global Explanations: CART to Extract Rules
3.4.2. Local Explanations: SEDC to Compute Counterfactual Explanations
3.5. Results
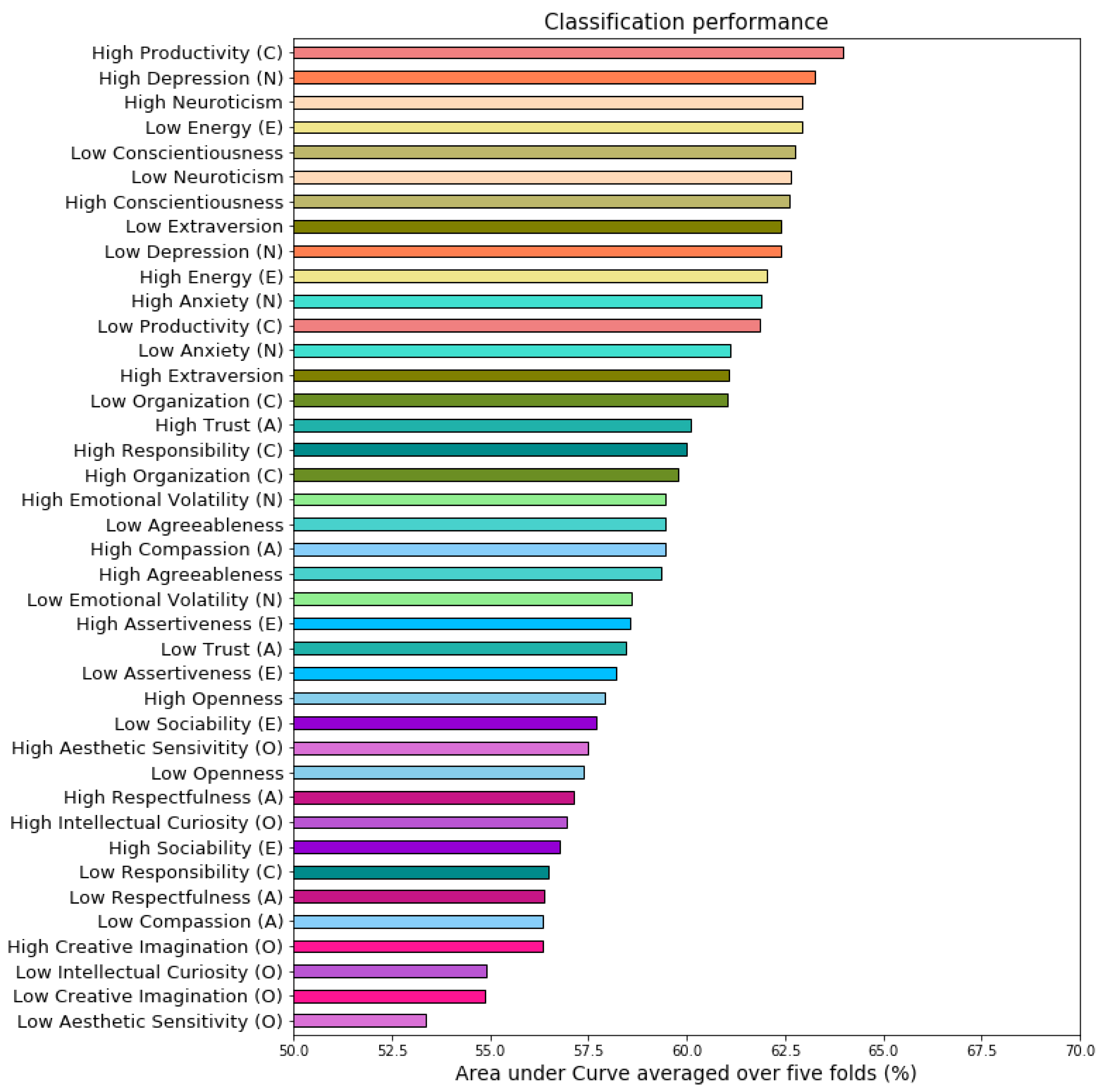
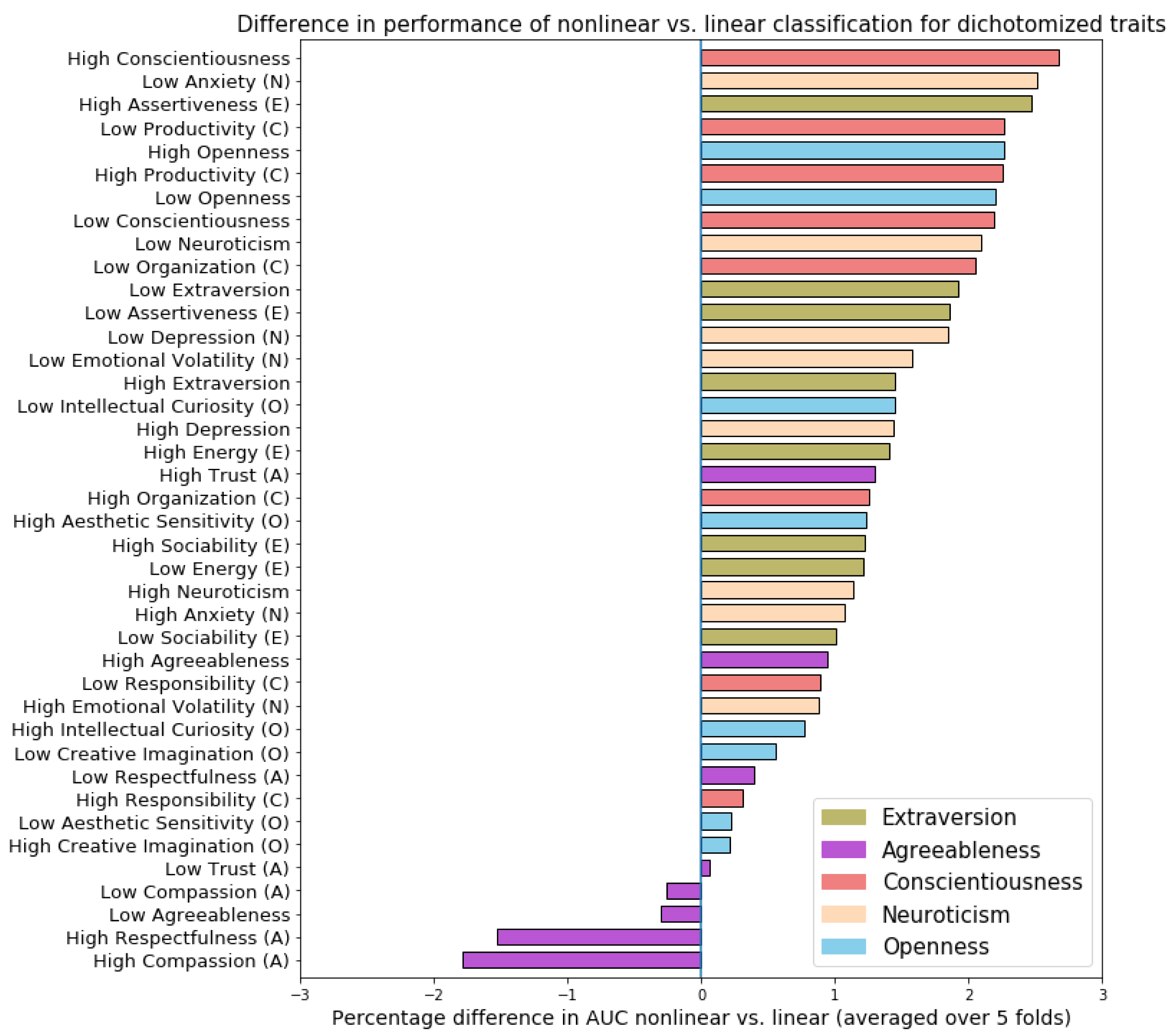
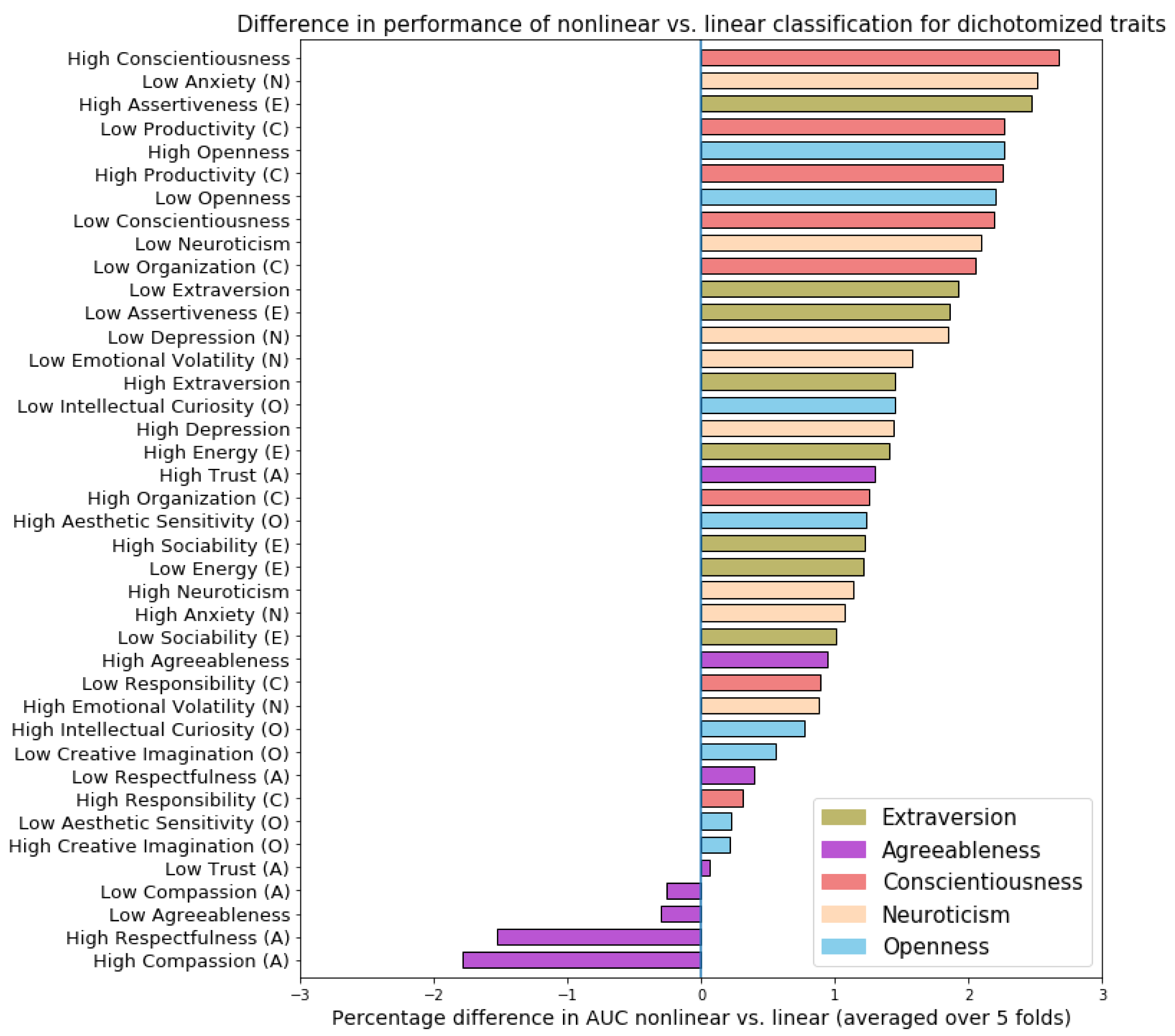
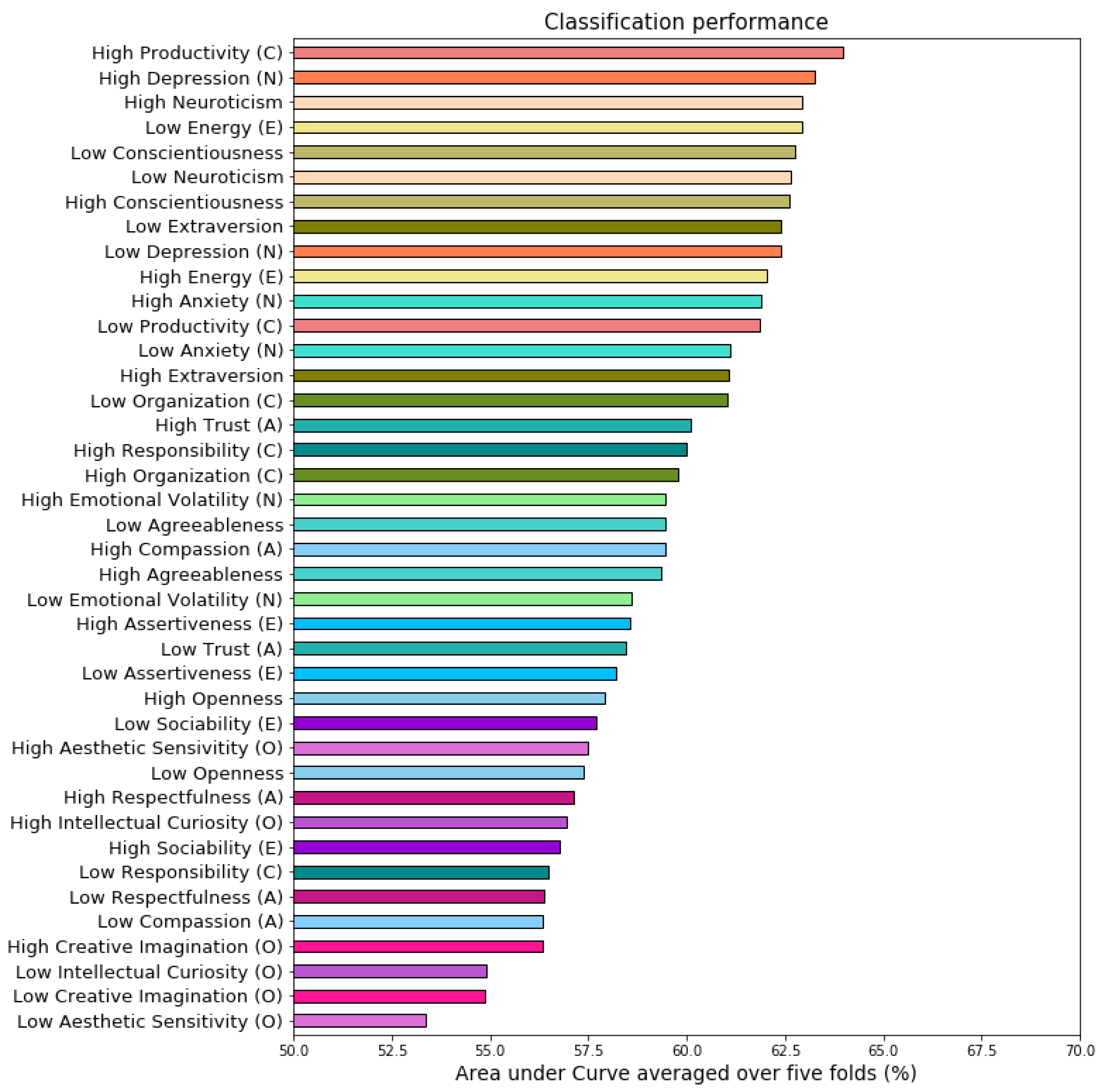
3.5.1. Classification Performance Analysis
Linear vs. Nonlinear Techniques
Predictability of Personality Traits and Underlying Facets
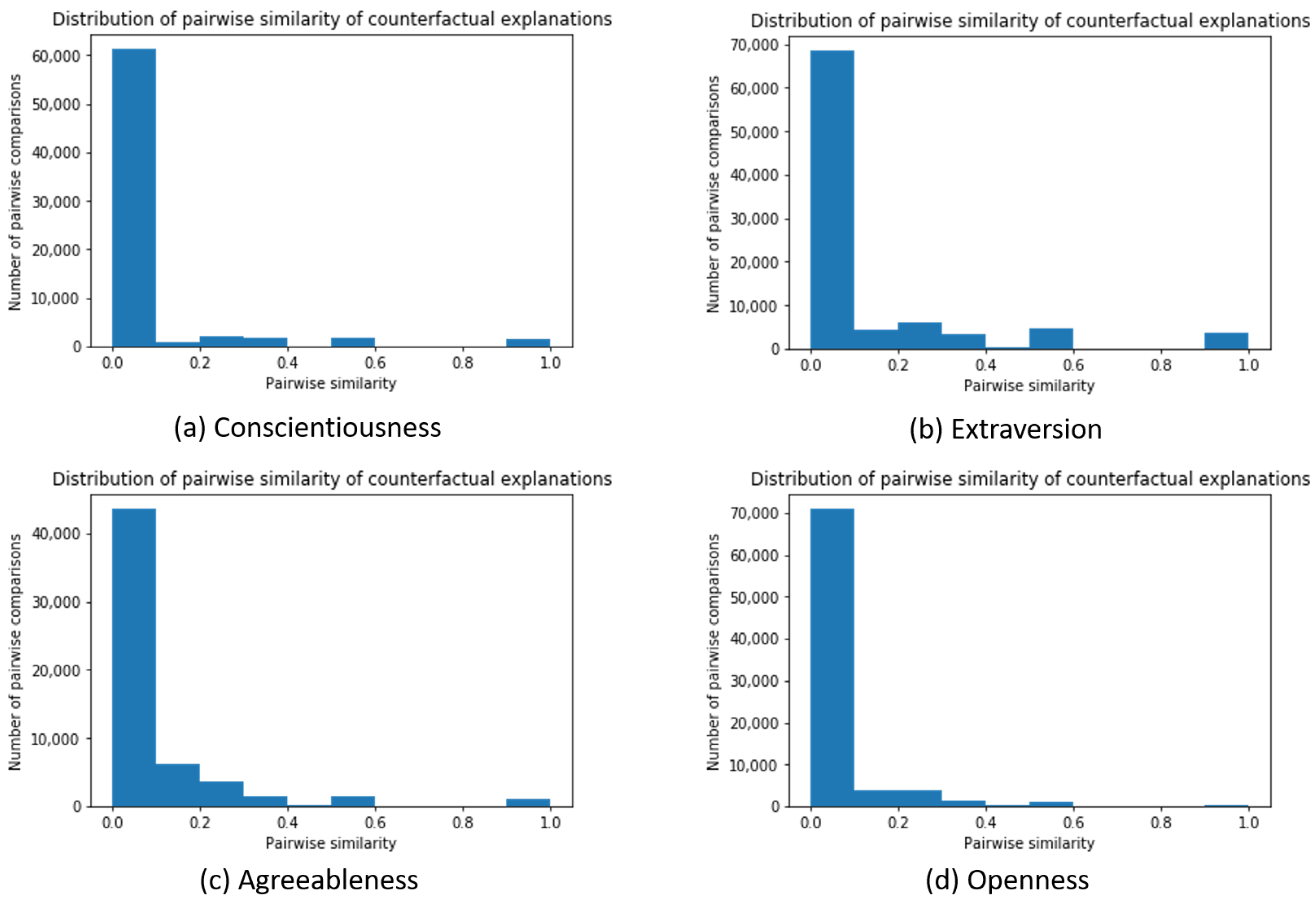
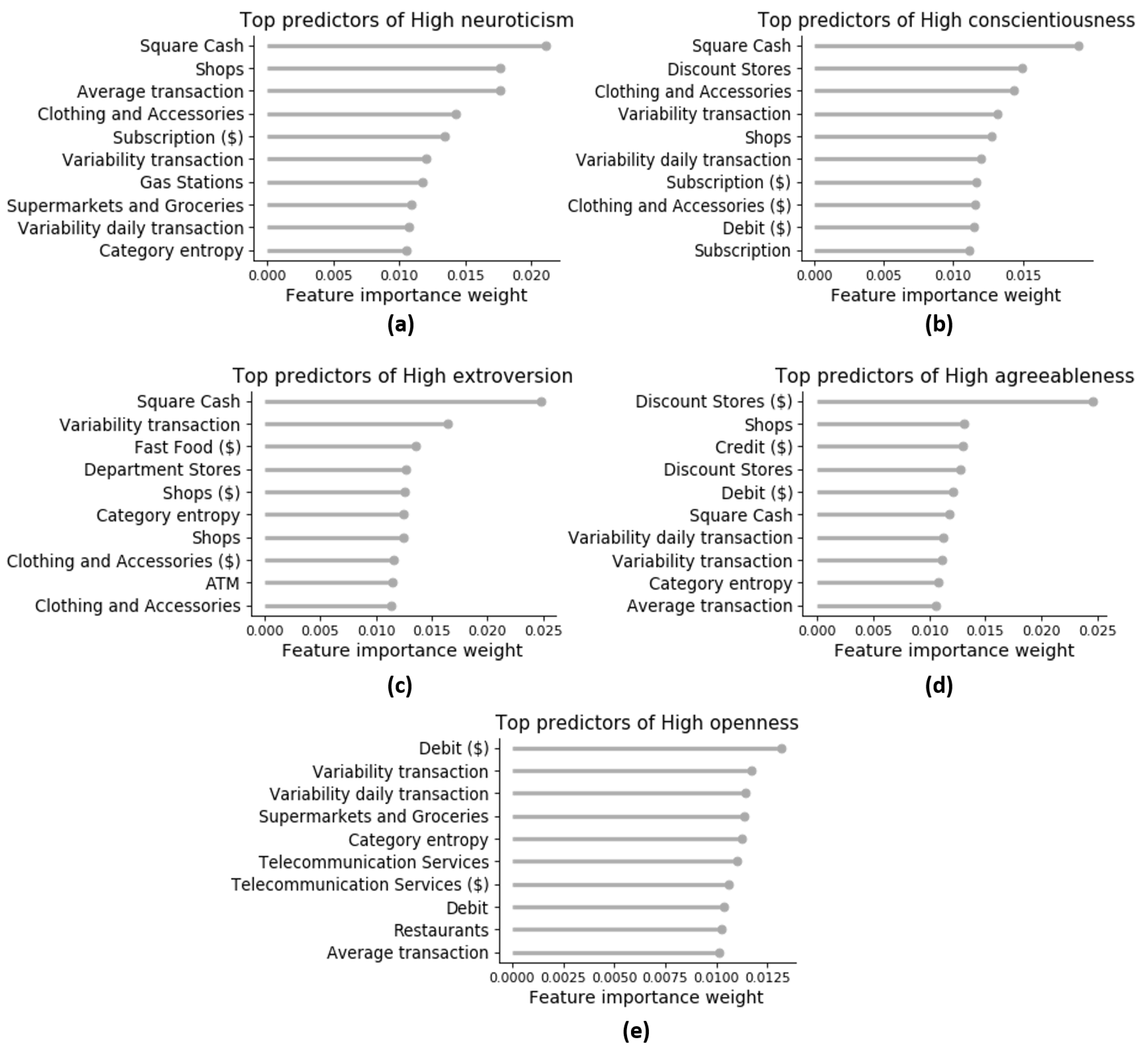
3.5.2. Model Interpretability Analysis
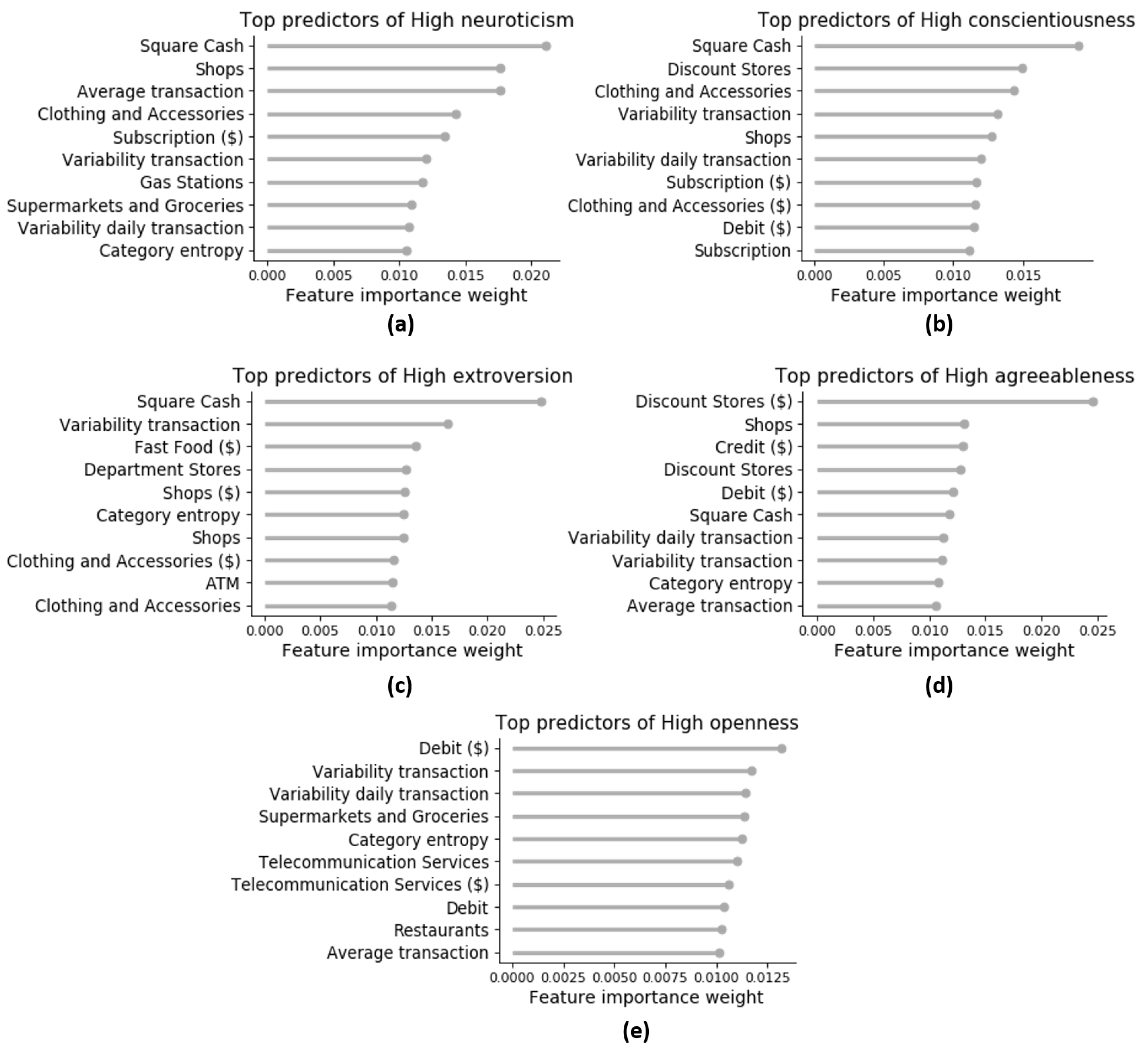
Global Explanations: Rule Extraction
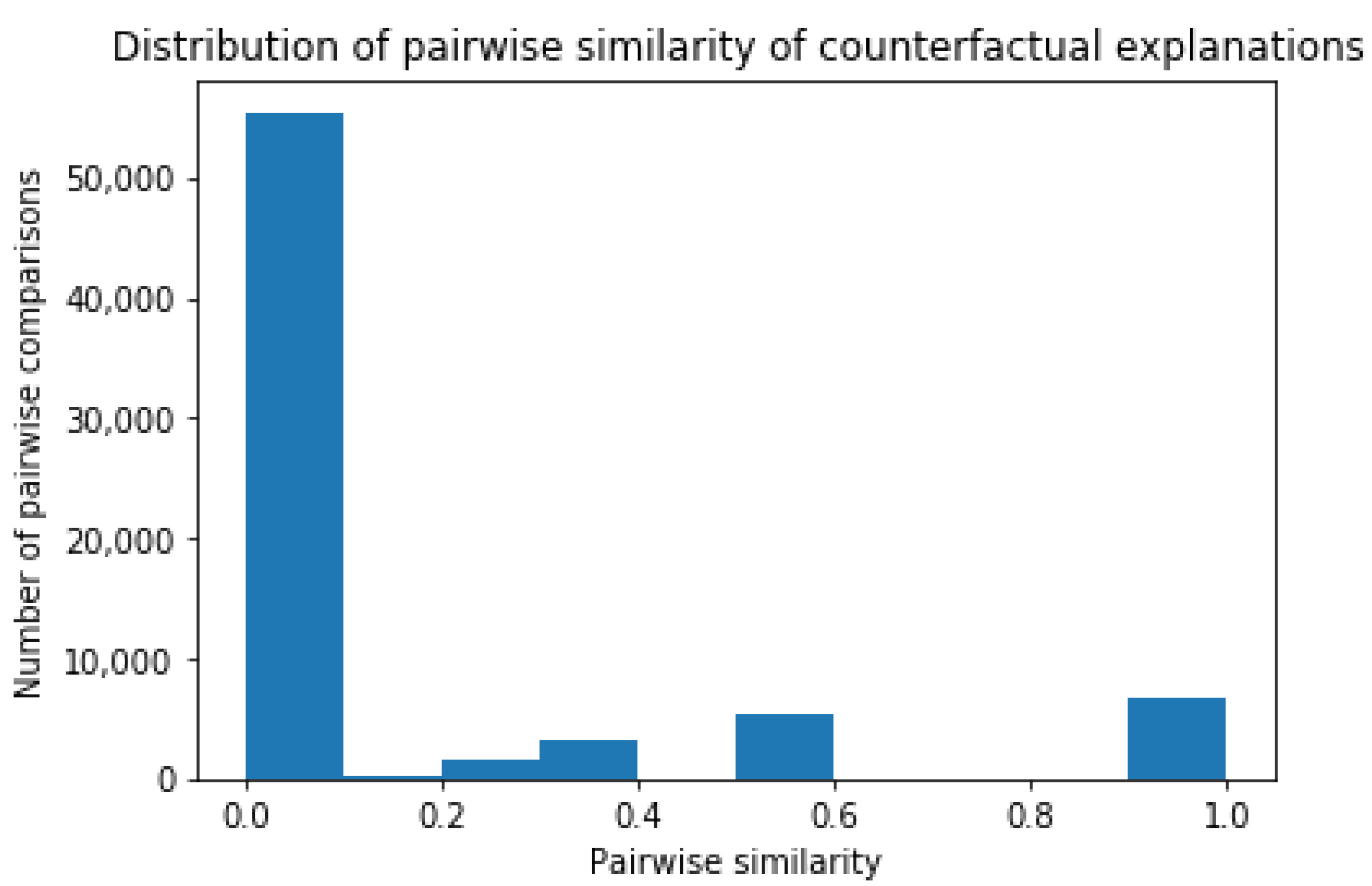
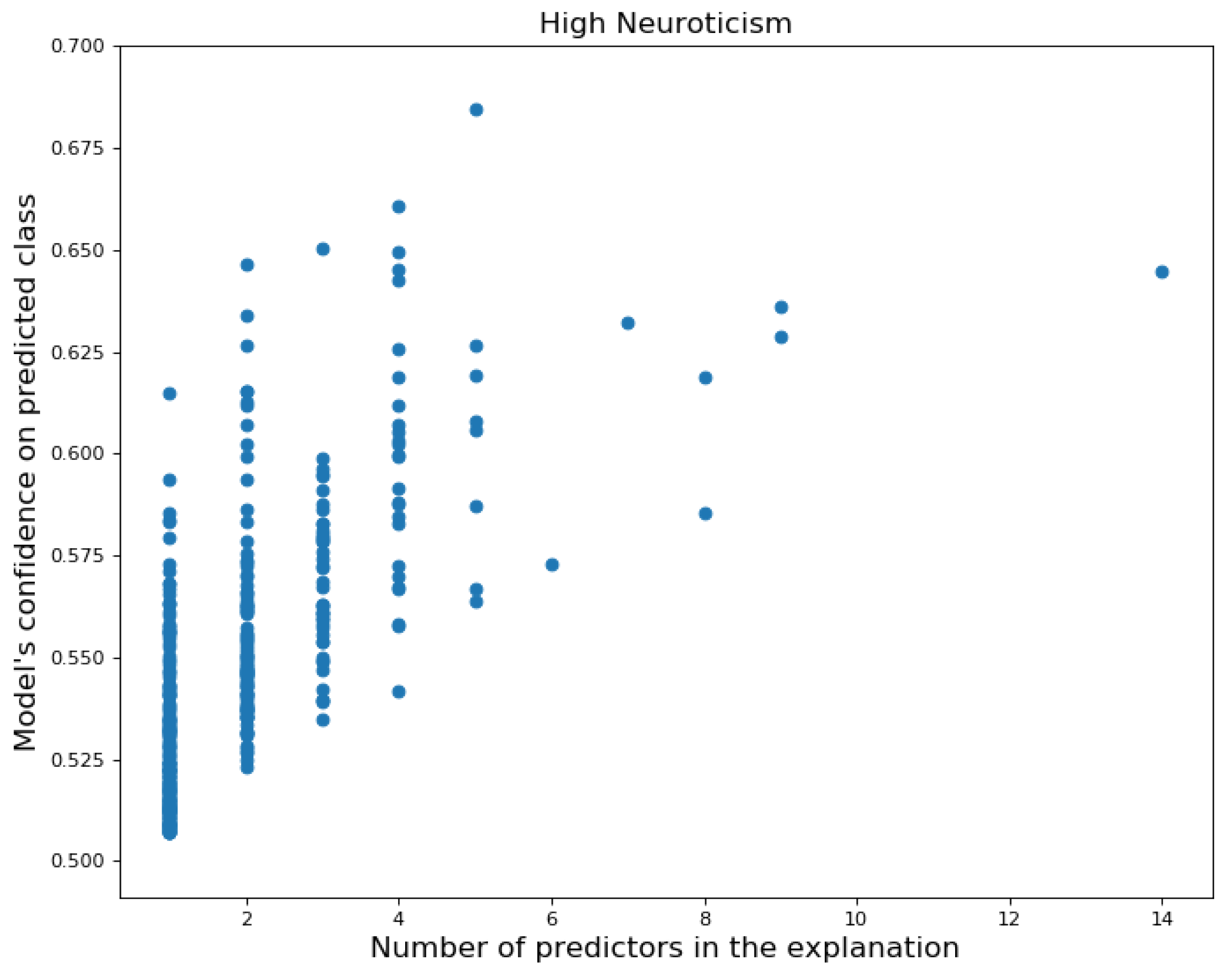
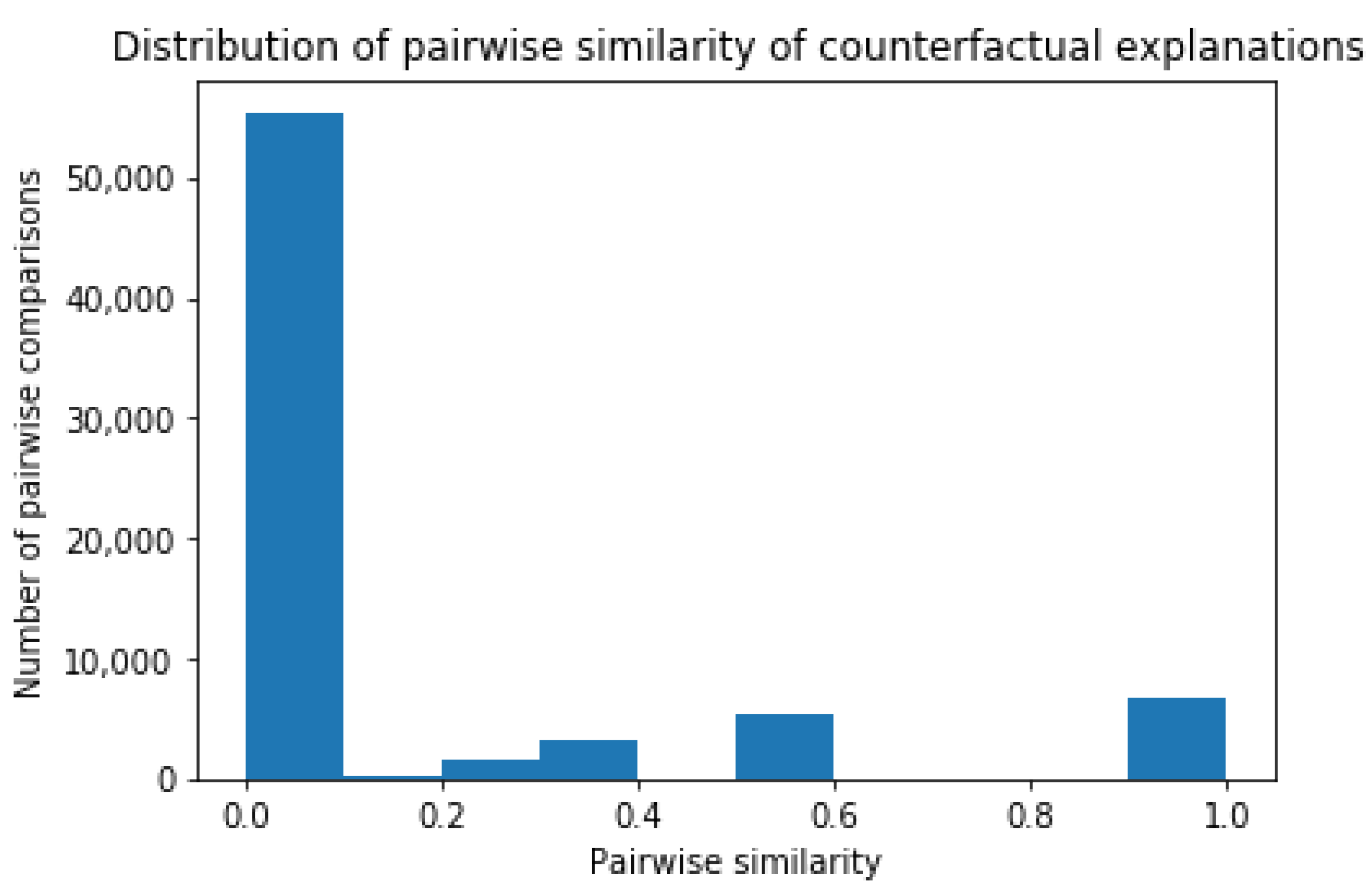
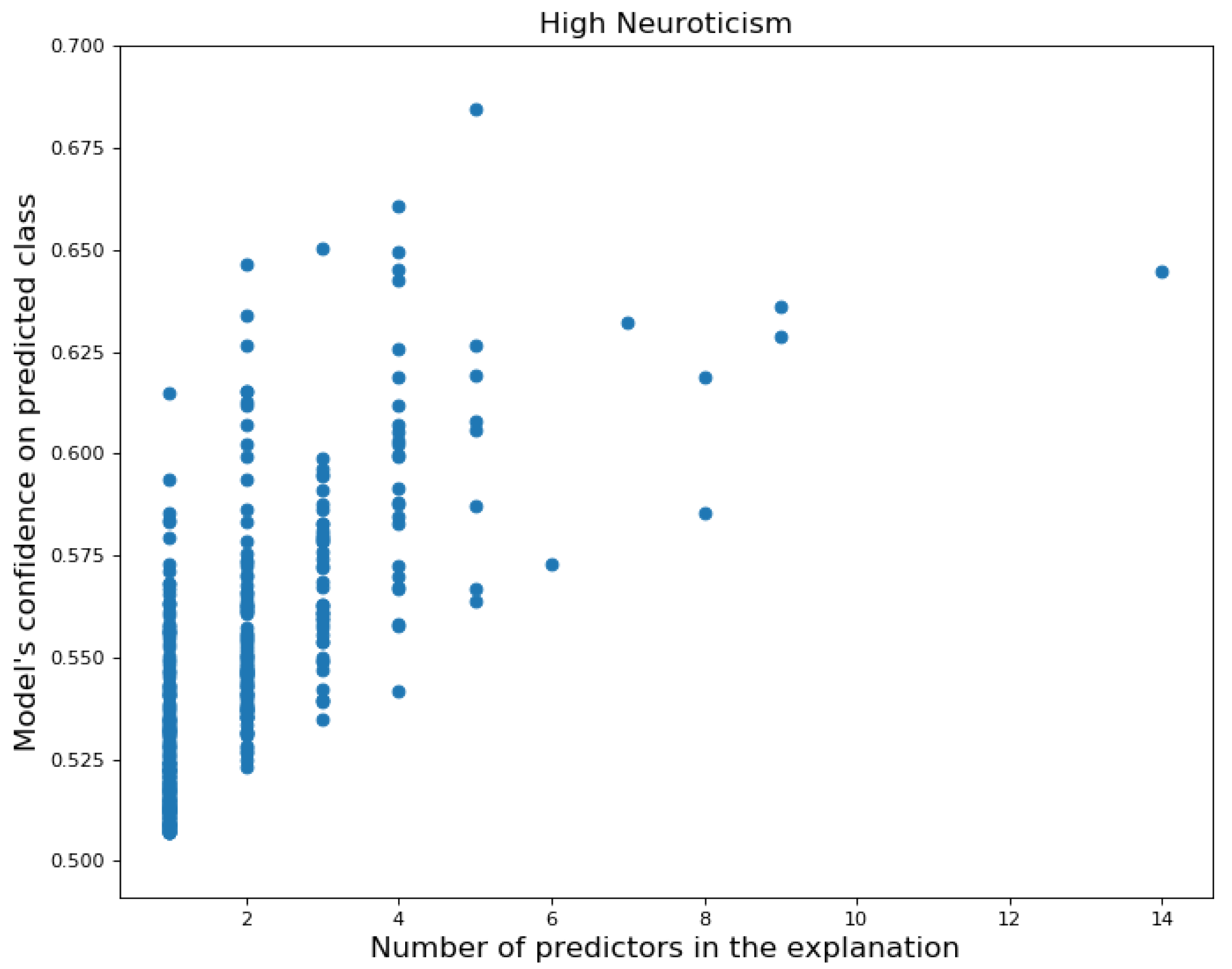
Local Explanations: Counterfactual Explanations
4. Discussion
4.1. Importance of Global Explanations and Implications
4.2. Importance of Local Explanations and Implications
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BB | black box |
| BF | Big Five |
| BFI | Big Five Inventory |
| DSA | Digital Services Act |
| EU | European Union |
| G20 | Group of Twenty |
| GDPR | General Data Protection Regulation |
| LIME | Local Interpretable Model-agnostic Explanations |
| OECD | Organisation for Economic Co-operation and Development |
| SHAP | SHapley Additive exPlanations |
| US | United States |
| XAI | Explainable Artificial Intelligence |
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain or Facet | This Study | Internet Sample [45] | d | Cronbach’s Alpha |
|---|---|---|---|---|
| Extraversion | () | () | ||
| Sociability | () | () | ||
| Assertiveness | () | () | ||
| Energy | () | () | ||
| Agreeableness | () | () | ||
| Compassion | () | () | ||
| Respectfulness | () | () | ||
| Trust | () | () | ||
| Conscientiousness | () | () | ||
| Organization | () | () | ||
| Productivity | () | () | ||
| Responsibility | () | () | ||
| Neuroticism | () | () | ||
| Anxiety | () | () | ||
| Depression | () | () | ||
| Emotional volatility | () | () | ||
| Openness | () | () | ||
| Intellectual curiosity | () | () | ||
| Aesthetic sensitivy | () | () | ||
| Creative imagination | () | () | ||
| N = 6408 | N = 1000 |
| Type | Feature Notation | Feature Name | Description |
|---|---|---|---|
| Overall | Total transactions | Total number of transactions over 12 months | |
| Total amount transactions | Total amount of money spent over 12 months | ||
| Average transaction | Average amount of money spent per transaction | ||
| Variability transaction | Variability of amount of money spent per transaction | ||
| Average daily transaction | Average amount of money spent on a daily basis | ||
| Variability daily transaction | Variability of amount of money spent on a daily basis | ||
| Category | Category c | Relative number of transactions in category c (e.g., Fast Food) | |
| Category c ($) | Relative amount of money spent in category c (e.g., Fast Food ($)) | ||
| Unique categories | Number of distinct spending categories | ||
| Category entropy | Diversity of spending in different categories |
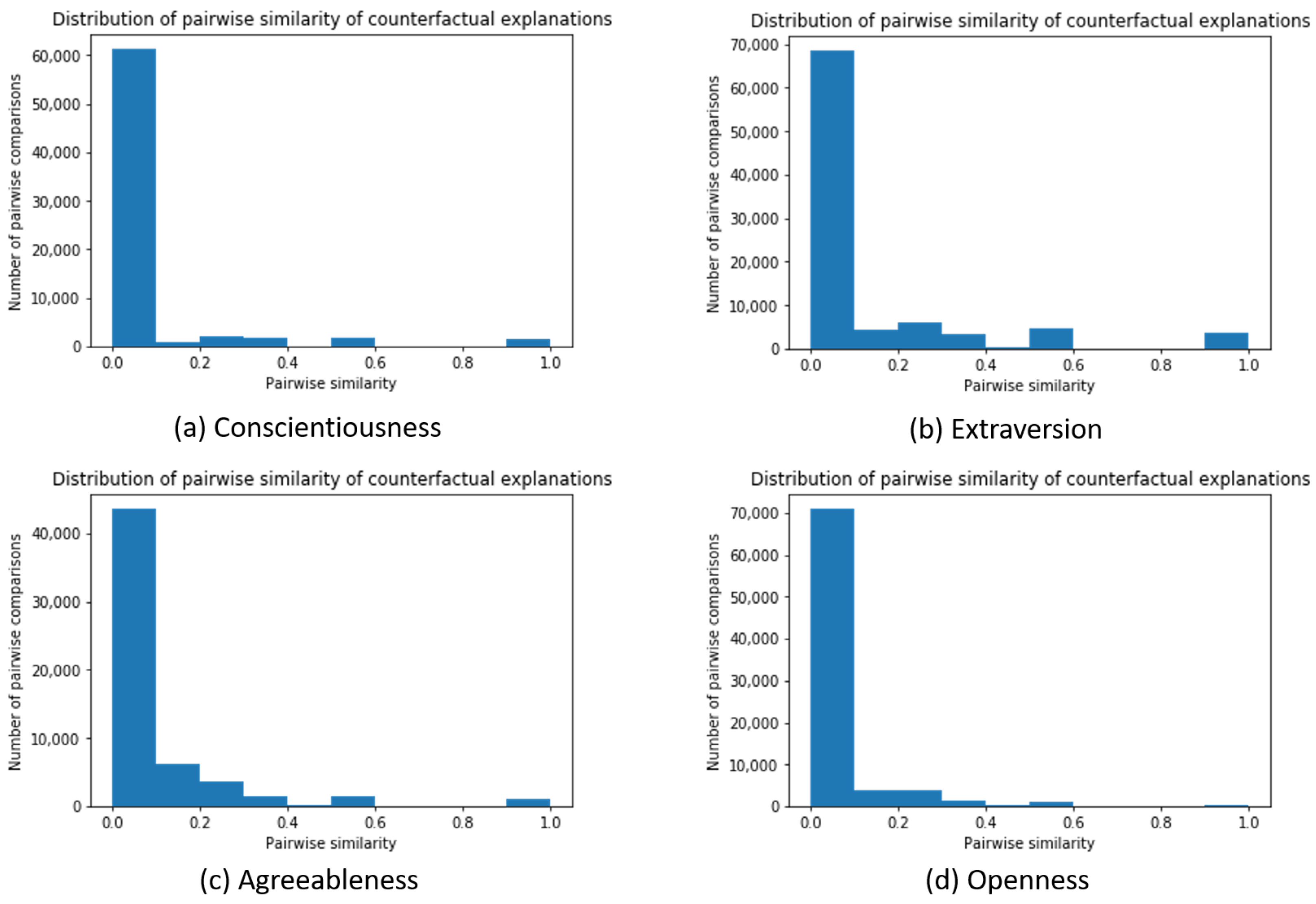
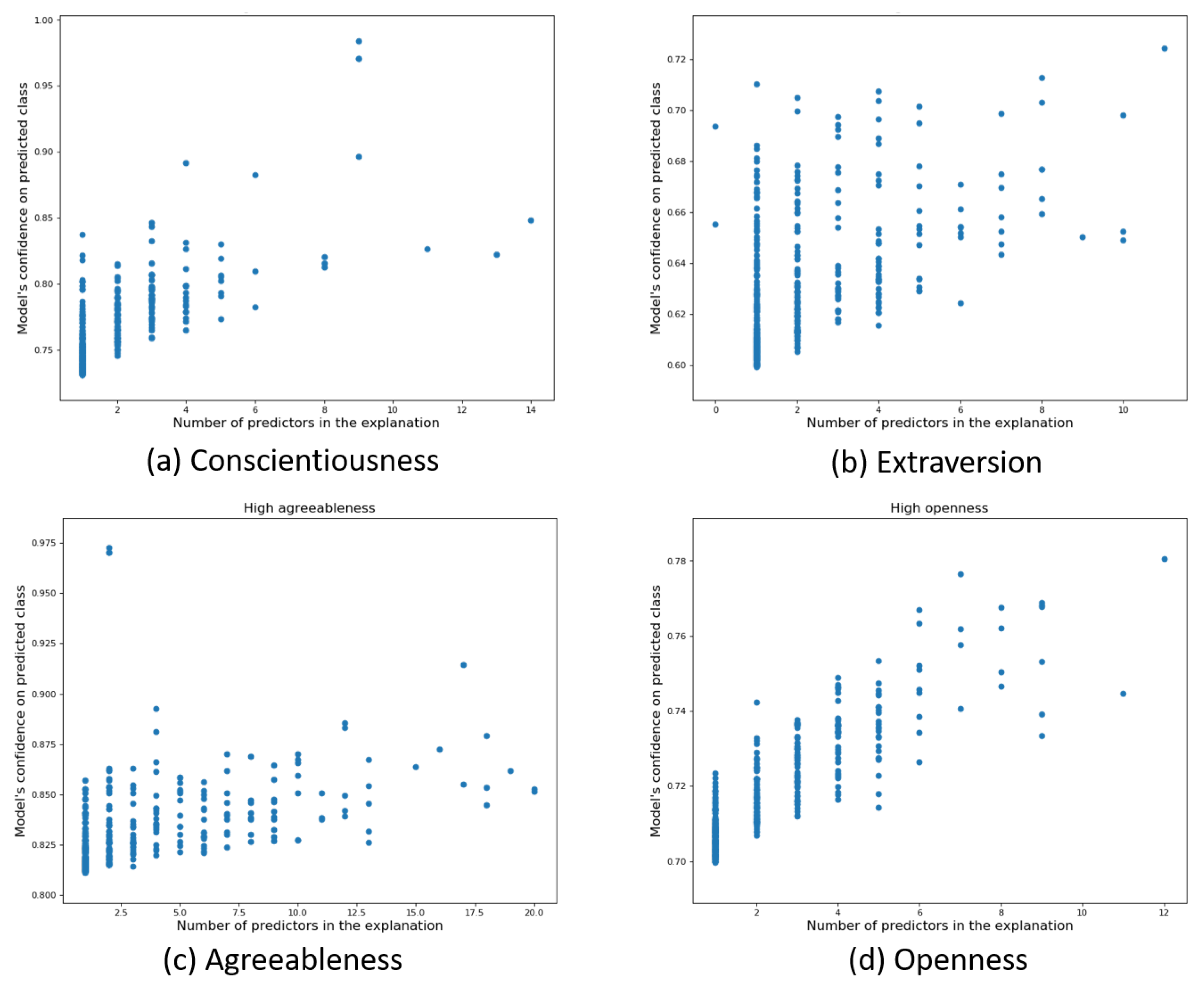
References
- Matz, S.C.; Netzer, O. Using Big Data as a window into consumers’ psychology. Curr. Opin. Behav. Sci. 2017, 18, 7–12. [Google Scholar] [CrossRef]
- Kosinski, M.; Stillwell, D.; Graepel, T. Private traits and attributes are predictable from digital records of human behavior. Proc. Natl. Acad. Sci. USA 2013, 110, 5802–5805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matz, S.C.; Kosinski, M.; Nave, G.; Stillwell, D. Psychological Targeting as an Effective Approach to Digital Mass Communication. Proc. Natl. Acad. Sci. USA 2017, 114, 12714–12719. [Google Scholar] [CrossRef] [Green Version]
- Moshe, I.; Terhorst, Y.; Opoku Asare, K.; Sander, L.B.; Ferreira, D.; Baumeister, H.; Mohr, D.C.; Pulkki-Råback, L. Predicting Symptoms of Depression and Anxiety Using Smartphone and Wearable Data. Front. Psychiatry 2020, 12, 625247. [Google Scholar] [CrossRef]
- Praet, S.; Van Aelst, P.; Martens, D. Predictive modeling to study lifestyle politics with Facebook likes. EPJ Data Sci. 2021, 10, 50. [Google Scholar] [CrossRef]
- Matz, S.C.; Appel, R.; Kosinski, M. Privacy in the Age of Psychological Targeting. Curr. Opin. Psychol. 2020, 31, 116–121. [Google Scholar] [CrossRef] [PubMed]
- Youyou, W.; Kosinski, M.; Stillwell, D. Computer-based personality judgements are more accurate than those made by humans. Proc. Natl. Acad. Sci. USA 2015, 112, 1–5. [Google Scholar] [CrossRef] [Green Version]
- de Montjoye, Y.-A.; Quoidbach, J.; Robic, F.; Pentland, A.S. Predicting people personality using novel mobile phone-based metrics. In Proceedings of the Social Computing, Behavioral-Cultural Modeling and Prediction, SBP 2013, Lecture Notes in Computer Science, Washington, DC, USA, 2–5 April 2013; Volume 7812, pp. 48–55. [Google Scholar]
- Rentfrow, P.J.; Gosling, S.D. The do re mi’s of everyday life: The structure and personality correlates of music preferences. J. Personal. Soc. Psychol. 2003, 84, 1236–1256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nave, G.; Minxha, J.; Greenberg, D.M.; Kosinski, M.; Stillwell, D.; Rentfrow, J. Musical Preferences Predict Personality: Evidence from Active Listening and Facebook Likes. Psychol. Sci. 2018, 29, 1145–1158. [Google Scholar] [CrossRef] [Green Version]
- Müller, S.R.; Peters, H.; Matz, S.C.; Wang, W. Investigating the Relationships Between Mobility Behaviours and Indicators of Subjective Well-Being Using Smartphone-Based Experience Sampling and GPS Tracking. Eur. J. Personal. 2020, 34, 714–732. [Google Scholar] [CrossRef]
- Gladstone, J.J.; Matz, S.C. Can Psychological Traits be Inferred from Spending? Evidence from Transaction Data. Psychol. Sci. 2019, 30, 1087–1096. [Google Scholar] [CrossRef] [Green Version]
- Tovanich, N.; Centellegher, S.; Seghouani, N.B.; Gladstone, J.; Matz, S.; Lepri, B. Inferring Psychological Traits from Spending Categories and Dynamic Consumption Patterns. EPJ Data Sci. 2021, 10, 1–30. [Google Scholar] [CrossRef]
- Clark, J.; Provost, F. Unsupervised dimensionality reduction versus supervised regularization for classification from sparse data. Data Min. Knowl. Discov. 2019, 33, 871–916. [Google Scholar] [CrossRef] [Green Version]
- Ramon, Y.; Martens, D.; Evgeniou, T.; Praet, S. Can metafeatures help improve explanations of prediction models when using behavioral and textual data? Mach. Learn. 2021, 1–40. [Google Scholar] [CrossRef]
- Martens, D.; Provost, F. Explaining data-driven document classifications. MIS Q. 2014, 38, 73–99. [Google Scholar] [CrossRef]
- Ramon, Y.; Martens, D.; Provost, F.; Evgeniou, T. A Comparison of Instance-level Counterfactual Explanation Algorithms for Behavioral and Textual Data: SEDC, LIME-C and SHAP-C. Adv. Data Anal. Classif. 2020, 14, 801–819. [Google Scholar] [CrossRef]
- De Cnudde, S.; Martens, D.; Evgeniou, T.; Provost, F. A benchmarking study of classification techniques for behavioral data. Int. J. Data Sci. Anal. 2020, 9, 131–173. [Google Scholar] [CrossRef] [Green Version]
- Junqué de Fortuny, E.; Martens, D.; Provost, F. Predictive Modeling With Big Data: Is Bigger Really Better? Big Data 2014, 1, 215–226. [Google Scholar] [CrossRef]
- PwC. 22nd Annual Global CEO Survey. Available online: https://www.pwc.com/gx/en/ceo-survey/2019/report/pwc-22nd-annual-global-ceo-survey.pdf (accessed on 27 September 2021).
- Martens, D. Data Science Ethics: Concepts, Techniques, and Cautionary Tales; Oxford University Press: Oxford, UK, 2022. [Google Scholar]
- Stachl, C.; Pargent, F.; Hilbert, S.; Harari, G.M.; Schoedel, R.; Vaid, S.; Gosling, S.D.; Bühner, M. Personality Research and Assessment in the Era of Machine Learning. Eur. J. Personal. 2020, 34, 613–631. [Google Scholar] [CrossRef]
- Dastin, J. Amazon Scraps Secret AI Recruiting Tool That Showed Bias against Women. Available online: https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G (accessed on 29 September 2021).
- Murgia, M. Algorithms Drive Online Discrimination, Academic Warns. Available online: https://www.ft.com/content/bc959e8c-1b67-11ea-97df-cc63de1d73f4 (accessed on 27 September 2021).
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Chen, D.; Fraiberger, S.P.; Moakler, R.; Provost, F. Enhancing Transparency and Control When Drawing Data-Driven Inferences About Individuals. Big Data 2017, 5, 197–212. [Google Scholar] [CrossRef] [Green Version]
- Dattner, B.; Chamorro-Premuzic, T.; Buchband, R.; Schettler, L. The Legal and Ethical Implications of Using AI in Hiring. Available online: https://hbr.org/2019/04/the-legal-and-ethical-implications-of-using-ai-in-hiring (accessed on 27 September 2021).
- Baker, S.R.; Farrokhnia, R.A.; Meyer, S.; Pagel, M.; Yannelis, C. How Does Household Spending Respond to an Epidemic? Consumption During the 2020 COVID-19 Pandemic. Natl. Bur. Econ. Res. Work. Pap. 2020, 10, 834–862. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef] [Green Version]
- Mittal, V.; Kashyap, I. Online Methods of Learning in Occurence of Concept Drift. Int. J. Comput. Appl. 2015, 117, 18–22. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges towards responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, D.; Pedreschi, A. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Molnar, C. Interpretable Machine Learning, 1st ed.; Lulu: Morrisville, NC, USA, 2019; Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 3 December 2021).
- Fernandez, C.; Provost, F.; Han, X. Explaining data-driven decisions made by AI systems: The counterfactual approach. arXiv 2020, arXiv:2001.07417. [Google Scholar]
- Settani, M.; Azucar, D.; Marengo, D. Predicting individual characteristics from digital traces on social media: A meta-analysis. Cyberpsychol. Behav. Soc. Netw. 2018, 21, 217–228. [Google Scholar] [CrossRef]
- Stachl, C.; Au, C.; Schoedel, R.; Buschek, D.; Völkel, S.; Schuwerk, T. Behavioral patterns in smartphone usage predict big five personality traits. OSF 2019, 1–24. [Google Scholar] [CrossRef]
- Andrews, R.; Diederich, J. Survey and critique of techniques for extracting rules from trained artificial neural networks. Knowl.-Based Syst. 1995, 8, 373–389. [Google Scholar] [CrossRef]
- Huysmans, J.; Baesens, B.; Vanthienen, J. Using Rule Extraction to Improve the Comprehensibility of Predictive Models. SSRN Electron. J. 2006. [Google Scholar] [CrossRef] [Green Version]
- Martens, D.; Baesens, B.; Van Gestel, T.; Vanthienen, J. Comprehensible credit scoring models using rule extraction from support vector machines. EJOR 2007, 183, 1466–1476. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR. Harv. J. Law Technol. 2018, 31, 841. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- US Bureau of Labor Statistics. Available online: https://www.bls.gov/cex/tables/calendar-year/mean-item-share-average-standard-error/cu-income-before-taxes-2019.pdf (accessed on 17 September 2021).
- Costa, P.; McCrae, R. Normal personality assessment in clinical practice: The NEO personality inventory. Psychol. Assess. 1992, 4, 5–13. [Google Scholar] [CrossRef]
- Soto, C.S.; John, O.P. Short and extra-short forms of the Big Five Inventory-2: The BFI-2-S and BFI-2-XS. J. Res. Personal. 2017, 68, 69–81. [Google Scholar] [CrossRef]
- Pianesi, F.; Mana, N.; Cappelletti, A.; Lepri, B.; Zancanaro, M. Multimodal recognition of personality traits in social interactions. In Proceedings of the International Conference on Multimodal Interfaces (ICMI), Chania, Greece, 20–22 October 2008. [Google Scholar]
- Phan, L.V.; Rauthmann, J.F. Personality Computing: New frontiers in personality assessment. Soc. Personal. Psychol. Compass 2021, 15, e12624. [Google Scholar] [CrossRef]
- Provost, F.; Fawcett, T. Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking, 1st ed.; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- Chittaranjan, G.; Blom, J.; Gatica-Perez, D. Who with Big-Five: Analyzing and Classifying Personality Traits with Smartphones. In Proceedings of the 15th Annual International Symposium on Wearable Computers, San Francisco, CA, USA, 12–15 June 2011; pp. 29–36. [Google Scholar]
- Aiken, L.R., Jr. The relationships of dress to selected measures of personality in undergraduate women. J. Soc. Psychol. 1963, 59, 119–128. [Google Scholar] [CrossRef]
- Darden, L.A. Personality Correlates of Clothing Interest for a Group of Non-Incarcerated and Incarcerated Women Ages 18 to 30. Ph.D. Thesis, University of North Carolina, Greensboro, NC, USA, 1975. [Google Scholar]
- Open Science Collaboration. Estimating the reproducibility of psychological science. Science 2015, 349, aac4716. [Google Scholar] [CrossRef] [Green Version]
- Aaker, J.L. Dimensions of Brand Personality. J. Mark. Res. 1997, 34, 347–356. [Google Scholar] [CrossRef]
- Tucker, C.E. Social Networks, Personalized Advertising, and Privacy Controls. J. Mark. Res. 2014, 51, 546–562. [Google Scholar] [CrossRef] [Green Version]
| Per Customer | Mean (Std) | Median |
|---|---|---|
| Total amount transactions | $ ($) | $ |
| Amount per transaction | $ ($) | $ |
| Number of transactions | () | 621 |
| Unique number of spending categories | () | 43 |
| Per Spending Category | Mean (Std) | Median |
| Total amount transactions | $ ($) | $ |
| Rel. total amount transactions | () | 9.7 |
| Number of transactions | () | 544 |
| Rel. number of transactions | () | 1.2 |
| Customer support | () | 240 |
| Rel. customer support | () |
| Trait | Explanation Rules |
|---|---|
| Neurotic | if (Square cash($) ≤ 0.3%) and (Average transaction ≤ $57.08) and (Clothing & Accessories ≤ 0.7%) → Model predicts High Neuroticism |
| if (Square cash($) > 0.3%) and (Subscription($) > 0.5%) and (Loans & Mortgages($) ≤ 3.9%) → Model predicts High Neuroticism | |
| else: Model predicts Default | |
| Conscientious | if (Square cash > 0.4%) and (Beauty Products > 0.3%) → Model predicts High Conscientiousness |
| if (Square cash > 0.4%) and (Beauty Products ≤ 0.3%) and (Clothing & Accessories($) > 0.8%) → Model predicts High Conscientiousness | |
| if (Square cash ≤ 0.4%) and (Discount Stores > 0.8%) and (Shops > 0.5%) → Model predicts High Conscientiousness | |
| else: Model predicts Default | |
| Extroverted | if (Square cash ≤ 0.7%) and (Clothing & Accessories ($) > 0.7%) and (Hotels & Motels > 0.1%) → Model predicts High Extraversion |
| if (Square cash > 0.7%) and (Variability transaction amount ≤ 0.31) → Model predicts High Extraversion | |
| if (Square cash > 0.7%) and (Variability transaction amount > 0.31) and (Service > 0.3%) → Model predicts High Extraversion | |
| else: Model predicts Default | |
| Agreeable | if (Square cash ≤ 0.5%) and (Discount Stores($) > 0.1%) and (Shops ≤ 0.6%) → Model predicts High Agreeableness |
| if (Square cash > 0.5%) and (Discount Stores > 0.7%) → Model predicts High Agreeableness | |
| if (Square cash > 0.5%) and (Discount Stores ≤ 0.7%) and (ATM > 5.7%) → Model predicts High Agreeableness | |
| else: Model predicts Default | |
| Open | if (Venmo($) > 0.1%) → Model predicts High Openness |
| if (Venmo($) ≤ 0.1%) and (Square cash($) > 0.5%) and (Digital purchase > 2.5%) → Model predicts High Openness | |
| if (Venmo($) ≤ 0.1%) and (Square cash($) ≤ 0.5%) and (Taxi($) > 0.4%) → Model predicts High Openness | |
| else: Model predicts Default |
| Personality Class | (%) | (%) | (%) | (%) |
|---|---|---|---|---|
| Neuroticism | () | () | () | () |
| Conscientiousness | () | () | () | () |
| Extraversion | () | () | () | () |
| Agreeableness | () | () | () | () |
| Openness | () | () | () | () |
| Instance i | Counterfactual Explanation for Instance i |
|---|---|
| Person a ( = 0.69) | If you had spent less frequently in Computers & Electronics, Insurance and Shops, |
| = 5 | and more frequently in Clothing & Accessories and Restaurants → then you would not |
| have been predicted as Neurotic | |
| Person b ( = 0.66) | If you had spent less frequently in Pets, Shops and Veterinarians, and spent less |
| = 4 | money on Subscription → you would not have been predicted as Neurotic |
| Person c ( = 0.65) | If you had spent less frequently in Shops, less money on Internal Account Transfer |
| = 3 | and Subscription → then you would not have been predicted as Neurotic |
| Person d ( = 0.65) | If you had spent less frequently in Shops, and less money on Subscription |
| = 2 | → then you would not have been predicted as Neurotic |
| Person e ( = 0.65) | If you had spent less frequently in Food & Beverage, PayPal and Shops, and less |
| = 4 | money on Subscription → then you would not have been predicted as Neurotic |
| Person f ( = 0.65) | If you had spent less frequently in Check, Department stores and Shops, and more |
| = 4 | frequently in Supermarkets & Groceries → then you would not have been predicted |
| as Neurotic | |
| Person g ( = 0.64) | If you had spent less frequently in Shops and Tobacco, and less money on |
| = 4 | Subscription and Tobacco → then you would not have been predicted as Neurotic |
| Person h ( = 0.64) | If you had spent less frequently in Food & Beverage, Vintage & Thrift, less money on |
| = 8 | Department stores, Shops, Tobacco and Vintage & Thrift, more frequently in Clothing & |
| Accessories, more money in Arts & Entertainment, and the variability of your spending | |
| amount was lower → then you would not have been predicted as Neurotic |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramon, Y.; Farrokhnia, R.A.; Matz, S.C.; Martens, D. Explainable AI for Psychological Profiling from Behavioral Data: An Application to Big Five Personality Predictions from Financial Transaction Records. Information 2021, 12, 518. https://doi.org/10.3390/info12120518
Ramon Y, Farrokhnia RA, Matz SC, Martens D. Explainable AI for Psychological Profiling from Behavioral Data: An Application to Big Five Personality Predictions from Financial Transaction Records. Information. 2021; 12(12):518. https://doi.org/10.3390/info12120518
Chicago/Turabian StyleRamon, Yanou, R.A. Farrokhnia, Sandra C. Matz, and David Martens. 2021. "Explainable AI for Psychological Profiling from Behavioral Data: An Application to Big Five Personality Predictions from Financial Transaction Records" Information 12, no. 12: 518. https://doi.org/10.3390/info12120518
APA StyleRamon, Y., Farrokhnia, R. A., Matz, S. C., & Martens, D. (2021). Explainable AI for Psychological Profiling from Behavioral Data: An Application to Big Five Personality Predictions from Financial Transaction Records. Information, 12(12), 518. https://doi.org/10.3390/info12120518