1. Introduction
Apple flowers have a high nutritional value and solid practical uses. During the apple planting stage, apple flower thinning can effectively regulate the nutrient supply of apple trees, which is closely related to fruit weight and quality [
1]. Moreover, apple flowers’ growing status, for instance, bloom intensity or flower numbers [
2], must be supervised since the flower is a relatively visual indicator for estimating fruit’s further growth states at an early stage. Therefore, apple flower detection plays a vital role in apple tree yield estimation and health status assessment of apple trees. However, nowadays, apple flower detection technology is inefficient, inaccurate, and labor-intensive. In addition, apple flower images are prone to have multiple flower objects in an individual image due to the natural shape characteristic of being dense; a bunch of apple flowers is liable to cause mutual shielding. Mutable illuminance causes diverse clarity of objects with varying resolutions in captured images. Thus, implementing an automatic apple flower detection to improve the efficiency of apple flower detection and increase farmers’ economic efficiency is necessary and urgent.
In recent years, machine learning has been widely applied to several agricultural studies, and some results have been achieved [
3]. Researchers have applied computer vision techniques in apple quality inspection [
4,
5,
6], apple pesticide residues [
7], apple size assessment [
8,
9], and apple detection [
10]. Nahina Islam et al. explored the potential of machine learning algorithms for weed and crop classification in UAV images. They discovered that conventional RF and SVM algorithms are efficient and practical to use [
11]. Jie Xu et al. proposed a multi-class classification model based on SVM and ANNs to estimate the occurrence of frost disasters towards tea [
12]. Some traditional machine learning methods used above have high speed for real-time reference due to their relatively straightforward computation, whereas, since being trained on chosen features, they typically share with low accuracy. Especially in this paper’s research field, these techniques do not perform well if previously unseen datasets occur, consisting of different flower species acquired under different conditions.
Additionally, some scholars have proposed various methods and recently made progress in research concerning apple flower detection. To build a pollination robot system, Lim et al. [
13] proposed a novel method based on Faster R-CNN and Single Shot Detector (SSD) Net and achieved an accuracy of 91.9%. To detect and count tomato flowers from images effectively, Afonso et al. [
14] first applied a set of grayscale transformations and then threshold and combined them by a logical binary AND operation with a recall of 79% and precision of 77%. To recognize and detect flower images accurately, Tian et al. [
15] introduced SSD deep learning techniques into this field and achieved an accuracy of 87.4% based on the evaluation standard of Pascal VOC2012. Balvant V. Biradar et al. [
16] proposed a method that uses Gaussian low-pass filter and morphological operations for pre-processing the flower images and a global thresholding technique using OTSU’s algorithm to segment flower regions. Results have shown that the accuracy is over 92% to detect and count the number of flowers from flower images. Dihua Wu et al. [
1] proposed a channel pruning-based deep learning algorithm for apple flower detection. The mAP using the proposed method was 97.31%; the detection speed was 72.33 f/s. Kaiqiong Sun et al. [
17] proposed an automated apple, peach, and pear flower detection method, achieving an F1 score at pixel-level up to 89.6% on one of the apple datasets and an average F1 score of 80.9% on the peach, pear, and another apple datasets. Guy Farjon et al. [
18] presented a visual flower detector based on a deep convolutional neural network, followed by a blooming level estimator and a peak blooming day finding algorithm. The trained detector detected flowers on trees with an Average Precision (AP) score of 0.68.
Therefore, inspired by the previous scholars’ research and the issues mentioned above in apple flower detection, we propose an optimization method based on the generative module and pruning inference and apply it to the mainstream detection network. The effectiveness of this method is verified experimentally. GM-EfficientDet-D5 can achieve 90.01% precision, 98.79% recall, and 97.43% mAP, compared to the not optimized EfficientDet-D5 with 3.98%, 7.46%, and 7.48% improvement in these three indexes. Moreover, considerable variations in apple flower images are considered based on maturity, light, genotype, and orientation. We also test the detection performance on various sizes of apple flowers, and experimental results are satisfactory and outperform those of other models.
The rest of this paper is divided into four parts: the Materials and Methods section introduces the dataset and design details of the generative module and pruning inference; the Results section shows the experimental process and results as well as their analysis; the Discussion section conducts numerous ablation experiments verifying the effectiveness of the optimized method; and the Conclusion section summarizes the whole paper.
Author Contributions
Conceptualization, Y.Z.; methodology, Y.Z.; validation, Y.Z.; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z., S.W., S.H. and Z.Z.; visualization, Z.Z. and S.H.; supervision, Y.Z.; project administration, Y.Z.; funding acquisition, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Modern Agricultural Industrial Technology System of China (No. CARS-28-20).
Acknowledgments
We are grateful to the Edison Coding Club of CIEE in China Agricultural University for their strong support during our thesis writing.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple flower detection using deep convolutional networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef] [Green Version]
- Pathan, M.; Patel, N.; Yagnik, H.; Shah, M. Artificial cognition for applications in smart agriculture: A comprehensive review. Artif. Intell. Agric. 2020, 4, 81–95. [Google Scholar] [CrossRef]
- Weng, S.; Zhu, W.; Zhang, X.; Yuan, H.; Zheng, L.; Zhao, J.; Huang, L.; Han, P. Recent advances in Raman technology with applications in agriculture, food and biosystems: A review. Artif. Intell. Agric. 2019, 3, 1–10. [Google Scholar] [CrossRef]
- Zhang, W.; Hu, J.; Zhou, G.; He, M. Detection of Apple Defects Based on the FCM-NPGA and a Multivariate Image Analysis. IEEE Access 2020, 8, 38833–38845. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, M.; Agyekum, A.A.; Wu, J.; Chen, Q.; Zuo, M.; El-Seedi, H.R.; Tao, F.; Shi, J.; Ouyang, Q.; et al. Quantitative detection of apple watercore and soluble solids content by near infrared transmittance spectroscopy. J. Food Eng. 2020, 279, 109955. [Google Scholar] [CrossRef]
- Jiang, B.; He, J.; Yang, S.; Fu, H.; Li, T.; Song, H.; He, D. Fusion of machine vision technology and AlexNet-CNNs deep learning network for the detection of postharvest apple pesticide residues. Artif. Intell. Agric. 2019, 1, 1–8. [Google Scholar] [CrossRef]
- Abbas, H.M.T.; Shakoor, U.; Khan, M.J.; Ahmed, M.; Khurshid, K. Automated Sorting and Grading of Agricultural Products based on Image Processing. In Proceedings of the 2019 8th International Conference on Information and Communication Technologies (ICICT), Karachi, Pakistan, 16–17 November 2019; pp. 78–81. [Google Scholar] [CrossRef]
- Sun, S.; Jiang, M.; He, D.; Long, Y.; Song, H. Recognition of green apples in an orchard environment by combining the GrabCut model and Ncut algorithm. Biosyst. Eng. 2019, 187, 201–213. [Google Scholar] [CrossRef]
- Mazzia, V.; Khaliq, A.; Salvetti, F.; Chiaberge, M. Real-Time Apple Detection System Using Embedded Systems With Hardware Accelerators: An Edge AI Application. IEEE Access 2020, 8, 9102–9114. [Google Scholar] [CrossRef]
- Islam, N.; Rashid, M.M.; Wibowo, S.; Xu, C.Y.; Morshed, A.; Wasimi, S.A.; Moore, S.; Rahman, S.M. Early Weed Detection Using Image Processing and Machine Learning Techniques in an Australian Chilli Farm. Agriculture 2021, 11, 387. [Google Scholar] [CrossRef]
- Xu, J.; Guga, S.; Rong, G.; Riao, D.; Liu, X.; Li, K.; Zhang, J. Estimation of Frost Hazard for Tea Tree in Zhejiang Province Based on Machine Learning. Agriculture 2021, 11, 607. [Google Scholar] [CrossRef]
- Lim, J.; Ahn, H.S.; Nejati, M.; Bell, J.; Williams, H.; MacDonald, B.A. Deep Neural Network Based Real-time Kiwi Fruit Flower Detection in an Orchard Environment. arXiv 2020, arXiv:2006.04343. [Google Scholar]
- Afonso, M.; Mencarelli, A.; Polder, G.; Wehrens, R.; Lensink, D.; Faber, N. Detection of Tomato Flowers from Greenhouse Images Using Colorspace Transformations. In Progress in Artificial Intelligence; Moura Oliveira, P., Novais, P., Reis, L.P., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 146–155. [Google Scholar]
- Tian, M.; Chen, H.; Wang, Q. Detection and Recognition of Flower Image Based on SSD network in Video Stream. J. Phys. Conf. Ser. 2019, 1237, 032045. [Google Scholar] [CrossRef]
- Biradar, B.V.; Shrikhande, S.P. Flower detection and counting using morphological and segmentation technique. Int. J. Comput. Sci. Inform. Technol 2015, 6, 2498–2501. [Google Scholar]
- Sun, K.; Wang, X.; Liu, S.; Liu, C. Apple, peach, and pear flower detection using semantic segmentation network and shape constraint level set. Comput. Electron. Agric. 2021, 185, 106150. [Google Scholar] [CrossRef]
- Farjon, G.; Krikeb, O.; Hillel, A.B.; Alchanatis, V. Detection and counting of flowers on apple trees for better chemical thinning decisions. Precis. Agric. 2020, 21, 503–521. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Huang, S.; Wang, X.; Tao, D. SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data. arXiv 2020, arXiv:2012.04846. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Du, L.; Ding, X.; Liu, T.; Li, Z. Modeling event background for if-then commonsense reasoning using context-aware variational autoencoder. arXiv 2019, arXiv:1909.08824. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G. yolov5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 26 October 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
Figure 1.
Image dataset was collected in Taolin Village in three scales.
Figure 2.
Dataset overall. (A) is the distribution of apple flowers’ number in each image; (B) is the distribution of different scales of apple flowers in each image; (C) shows four samples with different numbers of apple flowers.
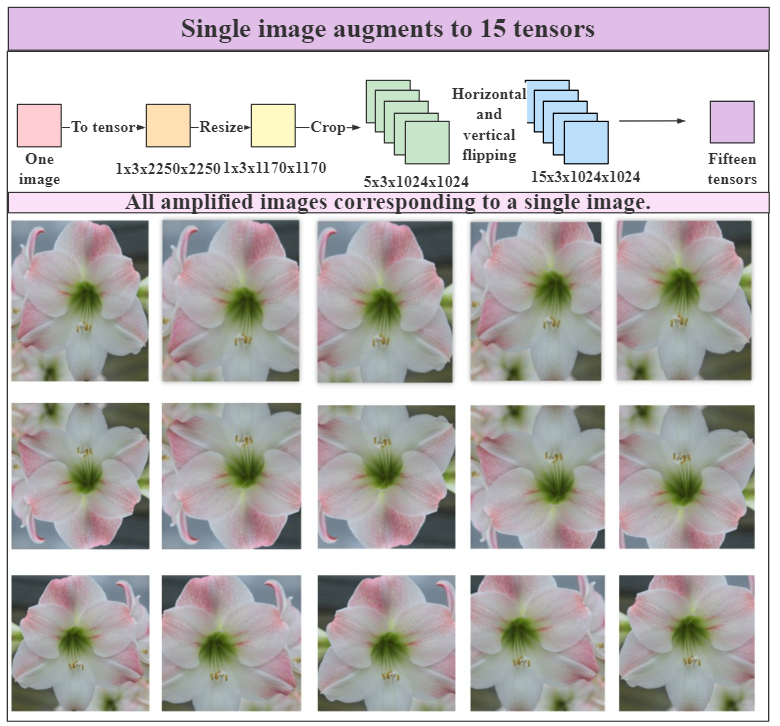
Figure 3.
Simple data augmentation.
Figure 4.
Illustration of five augmentation methods. (A) Mixup; (B) Cutout; (C) CutMix; (D) SnapMix; (E) Mosaic.
Figure 5.
Illustration of generative module on YOLO-v5 structure.
Figure 6.
Illustration of three implementations of generative module.
Figure 7.
Illustration of pruning process of feature pyramid network and UNet.
Figure 8.
The learning rate of two warm-up schemes.
Figure 9.
Training curves of accuracy and loss against number of iterations on YOLO series.
Figure 10.
Training curves of accuracy and loss against number of iterations on SSD series.
Figure 11.
Training curves of accuracy and loss against number of iterations on EfficientDet series, part I.
Figure 12.
Training curves of accuracy and loss against number of iterations on EfficientDet series, part II.
Figure 13.
Demonstration of GM-EfficientDet-D5’s effectiveness. (A) is large scale; (B) is medium scale; (C) is large scale.
Table 1.
Distribution of the dataset.
| | Large | Medium | Small | Total |
|---|
| Original dataset | 1044 | 1022 | 46 | 2158 |
| After data augmentation | 15,660 | 15,330 | 6900 | 37,890 |
| Training set | 14,094 | 13,797 | 6210 | 34,101 |
| Validation set | 1566 | 1533 | 690 | 3789 |
Table 2.
Distribution of the dataset.
| Model Parameters | Values |
|---|
| Initial learning rate | 0.02 |
| Image input batch size | 2 |
| Gamma | 0.1 |
| Maximum iterations | 200,000 |
Table 3.
Comparisons of different detection network series’ performance (in %).
| Model | Precision | Recall | mAP | FPS |
|---|
| YOLO-v3 | 84.77 | 94.19 | 90.97 | 39 |
| YOLO-v4 | 85.12 | 89.27 | 89.13 | 36 |
| YOLO-v5 | 87.13 | 92.75 | 91.82 | 42 |
| SSD | 71.03 | 82.49 | 80.34 | 17 |
| FSSD | 81.61 | 93.37 | 91.47 | 21 |
| RefineDet | 84.95 | 93.39 | 91.77 | 23 |
| EfficientDet-D2 | 84.57 | 88.19 | 86.39 | 47 |
| EfficientDet-D3 | 86.22 | 89.81 | 87.22 | 41 |
| EfficientDet-D4 | 85.71 | 91.49 | 88.69 | 42 |
| EfficientDet-D5 | 86.03 | 91.33 | 89.91 | 35 |
| EfficientDet-D6 | 85.71 | 91.49 | 83.47 | 33 |
| EfficientDet-D7 | 85.24 | 90.98 | 84.14 | 29 |
Table 4.
Performance of different models (in %).
| Model | Precision | Recall | mAP | FPS |
|---|
| Faster RCNN | 79.87 | 87.93 | 84.18 | 37 |
| Mask RCNN | 81.99 | 91.03 | 87.26 | 39 |
| GM-Mask RCNN | 85.39 | 95.60 | 94.91 | 33 |
| YOLO-v5 | 87.13 | 92.75 | 91.82 | 42 |
| GM-YOLO-v5 | 89.77 | 96.48 | 93.90 | 38 |
| RefineDet | 84.95 | 93.39 | 91.77 | 23 |
| GM-RefineDet | 87.41 | 97.11 | 93.38 | 17 |
| EfficientDet-D5 | 86.03 | 91.33 | 89.91 | 35 |
| GM-EfficientDet-D5 | 90.01 | 98.79 | 97.43 | 29 |
Table 5.
Comparisons of detection performance for different sizes of apple flowers. (P): Precision, (R): Recall (in %).
| Object Size | Small | Medium | Large |
|---|
| YOLO-v5 (P) | 67.11 | 87.01 | 87.29 |
| YOLO-v5 (R) | 71.98 | 91.99 | 92.94 |
| YOLO-v5 (mAP) | 63.87 | 91.82 | 91.83 |
| GM-EfficientDet-D5 (P) | 78.18 | 89.93 | 90.25 |
| GM-EfficientDet-D5 (R) | 85.21 | 98.83 | 98.79 |
| GM-EfficientDet-D5 (mAP) | 83.94 | 97.42 | 97.45 |
Table 6.
Performance of different generative module implementation on different models.
| Model | GM | Precision | Recall | mAP | FPS |
|---|
| | CGAN | 90.01 | 98.79 | 97.43 | 29 |
| GM-EfficientDet-D5 | CVAE | 89.17 | 96.33 | 97.41 | 30 |
| | CVAE-GAN | 90.03 | 98.50 | 97.61 | 25 |
| | CGAN | 85.28 | 89.20 | 88.47 | 71 |
| GM-YOLO-v5-PI | CVAE | 84.71 | 89.31 | 89.02 | 76 |
| | CVAE-GAN | 91.27 | 94.12 | 93.18 | 47 |
Table 7.
Performance of different pruning strategy on different models.
| Model | Strategy | Precision | Recall | mAP | FPS |
|---|
| GM-EfficientDet-D5 | baseline | 90.01 | 98.79 | 97.43 | 29 |
| PI | 89.13 | 98.10 | 96.18 | 51 |
| EfficientDet-D5 | baseline | 86.03 | 91.33 | 89.91 | 35 |
| PI | 85.91 | 89.18 | 88.33 | 53 |
| GM-YOLO-v5 | baseline | 89.77 | 96.48 | 93.90 | 38 |
| PI | 89.14 | 96.27 | 93.15 | 63 |
| YOLO-v5 | baseline | 87.13 | 92.75 | 91.82 | 42 |
| PI | 85.28 | 89.20 | 88.47 | 71 |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}