
Multimatcher Model to Enhance Ontology Matching Using Background Knowledge



Abstract
1. Introduction
1.1. Background Knowledge (BK)
1.2. Contributions
- An algorithm to improve mapping correspondence quality using different matchers and several aggregation strategies;
- A matcher path confidence measure that indicates the generated path matchers, which will be exploited by final mapping judgment;
- An algorithm to select the final mapping from several paths based on the matcher path confidence measure and false mapping repository to enhance the direct matching performance.
1.3. Organization
2. Preliminaries
3. Related Work
3.1. GBKOM BK Based Ontology Matching
3.2. BK Based Ontology Matching
3.3. BK Ontology Selection
3.4. Aggregation Techniques
4. BK Ontology Matching: A Multimatcher Model
4.1. Overview of Our Approach
4.2. Matcher Aggregation Strategies
| Algorithm 1. Aggregation Strategies | |
| 1 | Input: ontology 1 (source ontology) and ontology 2 (target ontology) |
| 2 | matchers: matcher 1, matcher 2, matcher 3, and matcher n |
| 3 | Output: Aggregated alignment |
| 4 | if source and target ontologies exist then |
| 5 | for i:= 1 to matcher(n) do |
| 6 | set matcherName to matcher (i) |
| 7 | createAlignment (ontology 1, ontology 2, matcher (i)) |
| 8 | saveAlignmentToList (Matcher(i)) |
| 9 | end for |
| 10 | end if |
| 11 | for A:= 1 to AlignmentsList do |
| 12 | addAllMappingsMaster() |
| 13 | end for |
| 14 | for line:= 1 to allMappingsMaster do |
| 15 | for lineCompare: = 1 to allMappingsMaster do |
| 16 | if(masterLineCompare.equals(lineCompare)) then |
| 17 | addFinalMappings() |
| 18 | end if |
| 19 | end for |
| 20 | if FinalMappings greater than one then |
| 21 | for line:= 1 to FinalMappings do |
| 22 | scoresList = add(score); |
| 23 | if mappingAggregationStrategy = Min then |
| 24 | AggreagatedScore = Min (scoresList) |
| 25 | end if |
| 26 | if mappingAggregationStrategy = Max then |
| 27 | AggreagatedScore = Max (scoresList) |
| 28 | end if |
| 29 | if mappingAggregationStrategy = Avg then |
| 30 | AggreagatedScore = Avg (scoresList) |
| 31 | end if |
| 32 | if mappingAggregationStrategy = Vote then |
| 33 | AggreagatedScore = Vote (scoresList) |
| 34 | end if |
| 35 | end for |
| 36 | end if |
| 37 | end for |
| 38 | if AggreagatedScore > thresholdAggregationSelection then |
| 39 | return finalAggregatedAlignment (AggreagatedScore) |
| 40 | end if |
| 41 | end |
4.3. BK Path Driven Inferencing
4.4. Final Mapping Selection
| Algorithm 2. Final Mapping Selection | |
| 1 | Input: foundPaths, |
| 2 | sourceConcepts, targetConcepts |
| 3 | Output: Final alignment |
| 4 | for P:= 1 to foundPaths do |
| 5 | matcherslist = get matchers (linePath) |
| 6 | if matcherslist > 1 then |
| 7 | score:= 1.0 |
| 8 | end if |
| 9 | if refAlignFalseMapping > 0, then |
| 10 | if refAlignFalseMapping equal to |
| 11 | (sourceConcept, targetConcept) then |
| 12 | stopPathFlag=stop |
| 13 | end if |
| 14 | end if |
| 15 | if stopPathFlag not equal to stop, then |
| 16 | if allCandidates (sourceConcept) do not exist then |
| 17 | addCandidate (sourceConcept, score, matcher, pathNo) |
| 18 | else |
| 19 | if allCandidates (targetConcept) not exsit then |
| 20 | addCandidate (targetConcept, score, matcher, pathNo) |
| 21 | else |
| 22 | updateCandidate (maxScore, matcher, pathNo) |
| 23 | end if |
| 24 | end if |
| 25 | end if |
| 26 | end for |
| 27 | for S:= 1 to allCandidates (sourceConcept) do |
| 28 | for T:= 1 to allCandidates (targetConcept) do |
| 29 | if S.pathNo greater than one then |
| 30 | addFinalAlignment(mapping) |
| 31 | stopFlag = true |
| 32 | end if |
| 33 | if (S.maxScore > maxCandidateScore) then |
| 34 | maxCandidateScore = S.maxScore |
| 35 | maxCandidate = sourceConcept |
| 36 | uriCandidate = targetConcept |
| 37 | end if |
| 38 | end for |
| 39 | if stopFlag not true then |
| 40 | addFinalAlignment(mapping) |
| 41 | end if |
| 42 | end for |
| 43 | return (finalAlignment) |
| 44 | end |
5. Experimental and Result Analysis
5.1. Experimental Setup and Datasets
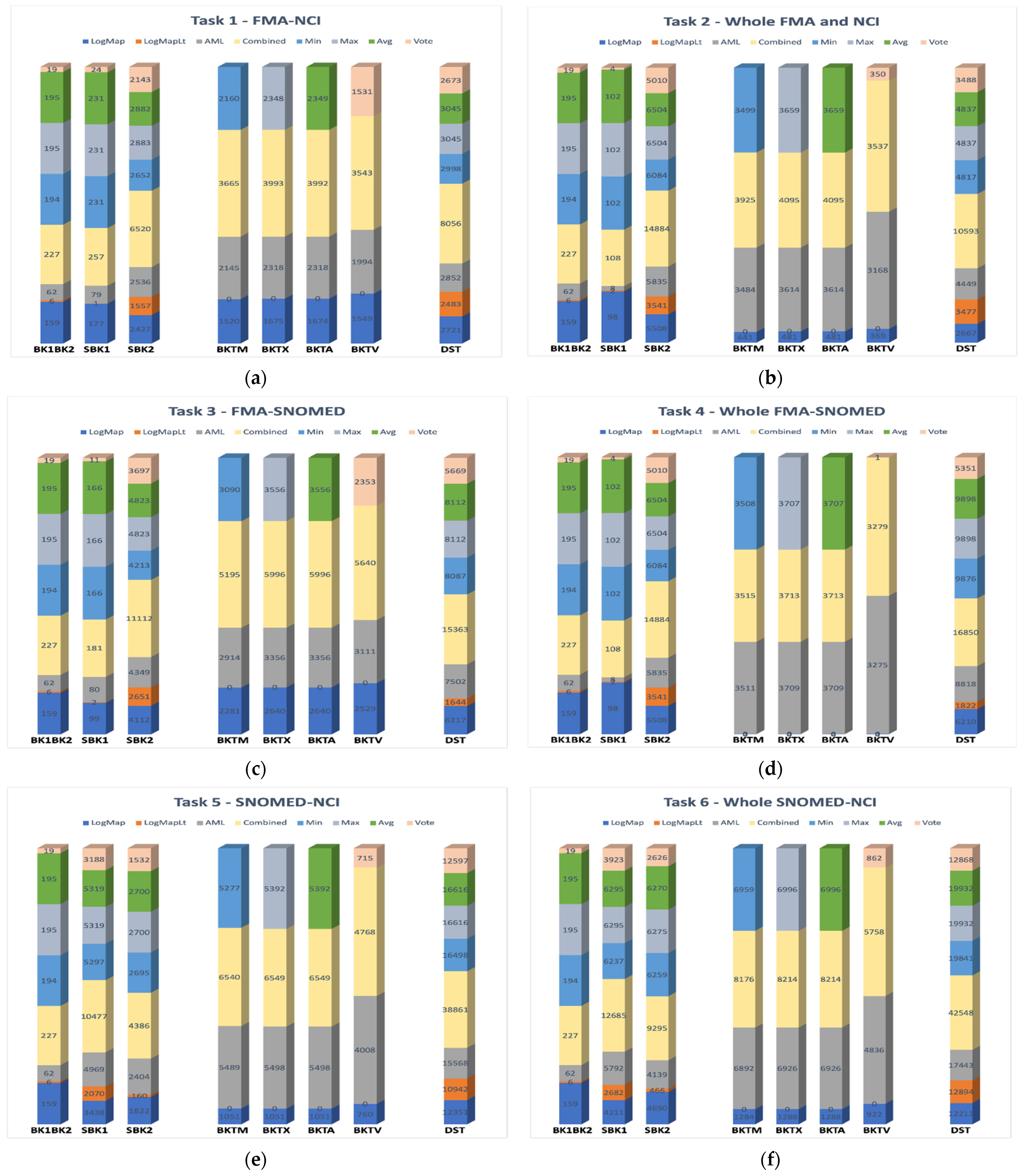
5.2. Experimental Results and Analysis
5.2.1. Building the Graphs Using Multi Matchers
5.2.2. BK Path-Driven Inferencing
5.2.3. Our Model with Different Direct Matchers and GBKOM
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AMA | Adult Mouse Anatomy |
| AML | AgreementMakerLight |
| BK | Background Knowledge |
| COMA | Combination of Schema Matching Approaches |
| DOID | Human Disease Ontology |
| FMA | Foundational Model of Anatomy |
| GBKOM | A Generic framework for BK Based Ontology Matching |
| GOMMA | Generic Ontology Matching and Mapping Management |
| LogMap | Logic Based and Scalable Ontology Matching |
| LogMapBio | LogMap BioPortal |
| LogMapLt | LogMap Lightweight |
| MA | Mouse Anatomy |
| NCI | National Cancer Institute Thesaurus |
| NCBO | The National Center for Biomedical Ontology |
| OAEI | Ontology Alignment Evaluation Initiative |
| SNOMED CT | SNOMED Clinical Terms |
| UBERON | The Uber Anatomy Ontology |
| UMLS | The Unified Medical Language System |
| YAM++ | Yet Another Matcher for Ontology Matching |
References
- Al-Yadumi, S.; Xion, T.E.; Wei, S.G.W.; Boursier, P. Review on Integrating Geospatial Big Datasets and Open Research Issues. IEEE Access 2021, 9, 10604–10620. [Google Scholar] [CrossRef]
- El Hajjamy, O.; Alaoui, L.; Bahaj, M. Semantic integration of heterogeneous classical data sources in ontological data warehouse. In Proceedings of the International Conference on Learning and Optimization Algorithms: Theory and Applications, Rabat, Morocco, 2–5 May 2018; pp. 1–8. [Google Scholar]
- Euzenat, J.; Shvaiko, P. Ontology Matching, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013; Available online: http://book.ontologymatching.org/ (accessed on 3 February 2021).
- Tudorache, T. Ontology engineering: Current state, challenges, and future directions. Semant. Web 2020, 11, 125–138. [Google Scholar] [CrossRef]
- Pesquita, C. Towards Semantic Integration for Explainable Artificial Intelligence in the Biomedical Domain. In Proceedings of the ACM SIGMOD International Conference on Management of Data, 14 June 2005; Baltimore, MD, USA; pp. 906–908. [Google Scholar] [CrossRef]
- Faria, D.; Pesquita, C.; Mott, I.; Martins, C.; Couto, F.M.; Cruz, I.F. Tackling the challenges of matching biomedical ontologies. J. Biomed. Semant. 2018, 9, 4. [Google Scholar] [CrossRef] [PubMed]
- Sun, K.; Zhu, Y.; Song, J. Progress and Challenges on Entity Alignment of Geographic Knowledge Bases. ISPRS Int. J. Geo-Inf. 2019, 8, 77. [Google Scholar] [CrossRef]
- Portisch, J.P. Towards Matching of Domain-Specific Schemas Using General-Purpose External Background Knowledge. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 31 May–4 June 2020; 12124 LNCS. pp. 270–279. [Google Scholar] [CrossRef]
- Nkisi-Orji, I.; Wiratunga, N.; Massie, S.; Hui, K.-Y.; Heaven, R. Ontology alignment based on word embedding and random forest classification. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10 September 2018; pp. 557–572. [Google Scholar] [CrossRef]
- Karimi, H.; Kamandi, A. Ontology alignment using inductive logic programming. In Proceedings of the 2018 4th International Conference on Web Research, ICWR 2018, Tehran, Iran, 25 April 2018; pp. 118–127. [Google Scholar] [CrossRef]
- Pesquita, C.; Santos, E.; Palmonari, M.; Cruz, I.F.; Couto, F.M. The AgreementMakerLight ontology matching system. In Proceedings of the On the Move to Meaningful Internet Systems (OTM 2013), Graz, Austria, 9–13 September 2013; pp. 527–541. [Google Scholar] [CrossRef]
- Aumueller, D.; Do, H.-H.; Massmann, S.; Rahm, E. Schema and ontology matching with COMA++. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14 June 2005; pp. 906–908. [Google Scholar] [CrossRef]
- Ren, F.; Deng, J. Background Knowledge Based Multi-Stream Neural Network for Text Classification. Appl. Sci. 2018, 8, 2472. [Google Scholar] [CrossRef]
- Annane, A.; Bellahsene, Z. GBKOM: A generic framework for BK-based ontology matching. J. Web Semant. 2020, 63, 100563. [Google Scholar] [CrossRef]
- Locoro, A.; David, J.; Euzenat, J. Context-Based Matching: Design of a Flexible Framework and Experiment. J. Data Semant. 2013, 3, 25–46. [Google Scholar] [CrossRef][Green Version]
- Annane, A.; Bellahsene, Z.; Azouaou, F.; Jonquet, C. Selection and combination of heterogeneous mappings to enhance biomedical ontology matching. In Proceedings of the European Knowledge Acquisition Workshop, Bologna, Italy, 19–23 November 2016; pp. 19–33. [Google Scholar] [CrossRef]
- Portisch, J.; Hladik, M.; Paulheim, H. Background Knowledge in Schema Matching. Semant. Web J. 2020, 1, 1–5. Available online: http://www.semantic-web-journal.net/system/files/swj2645.pdf (accessed on 10 January 2021).
- Real, F.J.Q.; Bella, G.; McNeill, F.; Bundy, A. Using domain lexicon and grammar for ontology matching. In Proceedings of the 15th International Workshop on Ontology Matching, Online. Athens, Greece, 2–3 November 2020; Volume 2788, pp. 1–12. [Google Scholar]
- Annane, A.; Bellahsene, Z.; Azouaou, F.; Jonquet, C. Building an effective and efficient background knowledge resource to enhance ontology matching. J. Web Semant. 2018, 51, 51–68. [Google Scholar] [CrossRef]
- Gherbi, S.; Khadir, M.T. Inferred Ontology Concepts Alignment Using Instances and an External Dictionary. Procedia Comput. Sci. 2016, 83, 648–652. [Google Scholar] [CrossRef]
- Yousfi, A.; Hafid, M.; Zellou, A. xMatcher: Matching Extensible Markup Language Schemas using Semantic-based Techniques. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 655–665. [Google Scholar] [CrossRef]
- Destro, J.M.; Vargas, J.A.; dos Reis, J.C.; Torres, R.D.S. EVOCROS: Results for OAEI 2019. CEUR Workshop Proc. 2019, 2536, 131–137. [Google Scholar]
- Schmidt, D.; Trojahn, C.; Vieira, R.; Kamel, M. Validating Top-Level and Domain Ontology Alignments Using WordNet. In Proceedings of the Brazilian Seminar Ontology (ONTOBRAS 2016), Curitiba, Brazil, 3–6 October 2016. [Google Scholar]
- Jiménez-Ruiz, E. LogMap family participation in the OAEI 2020. In Proceedings of the 15th International Workshop on Ontology Matching (OM 2020), Athens, Greece, 2–6 November 2020; Volume 2788, pp. 201–203. [Google Scholar]
- Kachroudi, M.; Diallo, G.; Ben Yahia, S. On the composition of large biomedical ontologies alignment. In Proceedings of the 7th International Conference on Web Intelligence, Mining and Semantics, Amantea, Italy, 19–22 June 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Nikooie Pour, M.A.; Algergawy, A.; Amini, R.; Faria, D.; Fundulaki, I.; Harrow, I.; Hertling, S.; Jimenez-Ruiz, E.; Jonquet, C.; Karam, N.; et al. Results of the ontology alignment evaluation initiative 2020. City Res. Online 2020, 37, 1591–1601. [Google Scholar]
- Kirsten, T.; Gross, A.; Hartung, M.; Rahm, E. GOMMA: A component-based infrastructure for managing and analyzing life science ontologies and their evolution. J. Biomed. Semant. 2011, 2, 6. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Ruiz, E.; Cuenca Grau, B. LogMap: Logic-based and scalable ontology matching. In Proceedings of the 10th International Semantic Web Conference, Bonn, Germany, 23–27 October 2011; pp. 273–288. [Google Scholar] [CrossRef]
- Groß, A.; Hartung, M.; Kirsten, T.; Rahm, E. Mapping composition for matching large life science ontologies. In Proceedings of the International Conference on Biomedical Ontology: ICBO 2011, Buffalo, NY, USA, 26 July 2011; Volume 833, pp. 109–116. [Google Scholar]
- Hartung, M.; Groß, A.; Rahm, E. Composition methods for link discovery. In Proceedings of the Datenbanksysteme für Business, Technologie und Web (BTW), Magdeburg, Germany, 11–15 March 2013; pp. 261–277. [Google Scholar]
- Chen, X.; Xia, W.; Jiménez-Ruiz, E.; Cross, V.V. Extending an ontology alignment system with BIOPORTAL: A preliminary analysis. In Proceedings of the ISWC 2014 Posters & Demonstrations Track a Track within the 13th International Semantic Web Conference, Riva del Garda, Italy, 21 October 2014; Volume 1272, pp. 313–316. [Google Scholar]
- Geometry, R.; Analysis, G. Automatic Background Knowledge Selection for Matching Biomedical Ontologies. PLoS ONE 2014, 11, e111226. [Google Scholar]
- Hartung, M.; Gross, A.; Kirsten, T.; Rahm, E. Effective composition of mappings for matching biomedical ontologies. In Proceedings of the Extended Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; Volume 7540, pp. 176–190. [Google Scholar] [CrossRef]
- Tigrine, A.N.; Bellahsene, Z.; Todorov, K. Selecting optimal background knowledge sources for the ontology matching task. In Proceedings of the European Knowledge Acquisition Workshop, Bologna, Italy, 19–23 November 2016; pp. 651–665. [Google Scholar] [CrossRef]
- Quix, C.; Roy, P.; Kensche, D. Automatic selection of background knowledge for ontology matching. In Proceedings of the International Workshop on Semantic Web Information Management, SWIM 2011, Athens, Greece, 12–16 June 2011; Volume 5, pp. 1–7. [Google Scholar] [CrossRef]
- Rahm, E. Towards Large-Scale Schema and Ontology Matching. In Schema Matching and Mapping; Bellahsene, Z., Bonifati, A., Rahm, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 3–27. [Google Scholar] [CrossRef]
- Gulić, M.; Vrdoljak, B.; Banek, M. CroMatcher: An ontology matching system based on automated weighted aggregation and iterative final alignment. J. Web Semant. 2016, 41, 50–71. [Google Scholar] [CrossRef]
- Duchateau, F.; Bellahsene, Z. YAM: A step forward for generating a dedicated schema matcher. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XXV; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9620, pp. 150–185. [Google Scholar] [CrossRef]
- Cardoso, S.D.; Da Silveira, M.; Lin, Y.-C.; Christen, V.; Rahm, E.; Reynaud-Delaître, C.; Pruski, C. Combining semantic and lexical measures to evaluate medical terms similarity. In Proceedings of the International Conference on Data Integration in the Life Sciences, Hannover, Germany, 20–21 November 2018; pp. 17–32. [Google Scholar] [CrossRef]
- Gulić, M.; Vrdoljak, B.; Vuković, M. An Iterative Automatic Final Alignment Method in the Ontology Matching System. J. Inf. Organ. Sci. 2018, 42, 39–61. [Google Scholar] [CrossRef]
- Gross, A.; Hartung, M.; Kirsten, T.; Rahm, E. On matching large life science ontologies in parallel. In Proceedings of the International Conference on Data Integration in the Life Sciences, Gothenburg, Sweden, 25–27 August 2010; pp. 35–49. [Google Scholar] [CrossRef]
- Wang, S.; Schlobach, S.; Takens, J.; Van Atteveldt, W. Mapping-chains for studying concept shift in political ontologies. In Proceedings of the 4th International Workshop on Ontology Matching (OM-2009), Fairfax, VA, USA, 25 October 2009; Volume 551, pp. 13–24. [Google Scholar]
- rojahn, C.; Moraes, M.; Quaresma, P.; Vieira, R. A cooperative approach for composite ontology mapping. In Journal on Data Semantics X; Springer: Berlin, Germany, 2008; pp. 237–263. [Google Scholar] [CrossRef]
- Peukert, E.; Maßmann, S.; König, K. Comparing similarity combination methods for schema matching. INFORMATIK 2010. Serv. Sci. Neue Perspekt. Für Die Inform. 2020, 1, 692–701. [Google Scholar]
- Euzenat, J. Algebras of ontology alignment relations. In Proceedings of the International Semantic Web Conference, Karlsruhe, Germany, 26–30 October 2008; pp. 387–402. [Google Scholar] [CrossRef]
- Nunes, B.P.; Dietze, S.; Casanova, M.A.; Kawase, R.; Fetahu, B.; Nejdl, W. Combining a co-occurrence-based and a semantic measure for entity linking. In Proceedings of the Extended Semantic Web Conference, Montpellier, France, 26–30 May 2013; pp. 548–562. [Google Scholar] [CrossRef]
- Mascardi, V.; Locoro, A.; Rosso, P. Automatic Ontology Matching via Upper Ontologies: A Systematic Evaluation. IEEE Trans. Knowl. Data Eng. 2009, 22, 609–623. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity 1 | Entity 2 | Score |
|---|---|---|
| MA_0002215 | UBERON_0007318 | 0.80 |
| MA_0002110 | UBERON_0008783 | 0.79 |
| MA_0000462 | UBERON_0001528 | 0.89 |
| MA_0002358 | UBERON_0001298 | 0.83 |
| MA_0002107 | UBERON_0006656 | 0.62 |
| MA_0000004 | UBERON_0000468 | 0.50 |
| Entity 1 | Entity 2 | Score |
|---|---|---|
| MA_0002215 | UBERON_0007318 | 1.0 |
| MA_0002110 | UBERON_0008783 | 1.0 |
| MA_0000462 | UBERON_0001528 | 1.0 |
| MA_0000599 | UBERON_0004268 | 1.0 |
| MA_0000744 | UBERON_0009039 | 1.0 |
| Entity 1 | Entity 2 | Score |
|---|---|---|
| MA_0002215 | UBERON_0007318 | 0.99 |
| MA_0002110 | UBERON_0008783 | 0.99 |
| MA_0000462 | UBERON_0001528 | 0.88 |
| MA_0002358 | UBERON_0001298 | 0.99 |
| MA_0002107 | UBERON_0006656 | 0.62 |
| MA_0000599 | UBERON_0004268 | 0.99 |
| MA_0000001 | UBERON_0001062 | 0.99 |
| Entity 1 | Entity 2 | Score | Matcher |
|---|---|---|---|
| MA_0002215 | UBERON_0007318 | 0.80 | LogMap, LogMapLt, AML |
| MA_0002110 | UBERON_0008783 | 0.79 | LogMap, LogMapLt, AML |
| MA_0000462 | UBERON_0001528 | 0.88 | LogMap, LogMapLt, AML |
| MA_0002358 | UBERON_0001298 | 0.83 | LogMap, AML |
| MA_0002107 | UBERON_0006656 | 0.62 | LogMap, AML |
| MA_0000599 | UBERON_0004268 | 0.99 | LogMapLt, AML |
| MA_0000004 | UBERON_0000468 | 0.50 | LogMap |
| MA_0000744 | UBERON_0009039 | 1.0 | LogMapLt |
| MA_0000001 | UBERON_0001062 | 0.99 | AML |
| Entity 1 | Entity 2 | Score | Matcher |
|---|---|---|---|
| MA_0002215 | UBERON_0007318 | 1.0 | LogMap, LogMapLt, AML |
| MA_0002110 | UBERON_0008783 | 1.0 | LogMap, LogMapLt, AML |
| MA_0000462 | UBERON_0001528 | 1.0 | LogMap, LogMapLt, AML |
| MA_0002358 | UBERON_0001298 | 0.99 | LogMap, AML |
| MA_0002107 | UBERON_0006656 | 0.62 | LogMap, AML |
| MA_0000599 | UBERON_0004268 | 1.0 | LogMapLt, AML |
| MA_0000004 | UBERON_0000468 | 0.50 | LogMap |
| MA_0000744 | UBERON_0009039 | 1.0 | LogMapLt |
| MA_0000001 | UBERON_0001062 | 0.99 | AML |
| Entity 1 | Entity 2 | Score | Matcher |
|---|---|---|---|
| MA_0002215 | UBERON_0007318 | 0.93 | LogMap, LogMapLt, AML |
| MA_0002110 | UBERON_0008783 | 0.93 | LogMap, LogMapLt, AML |
| MA_0000462 | UBERON_0001528 | 0.92 | LogMap, LogMapLt, AML |
| MA_0002358 | UBERON_0001298 | 0.91 | LogMap, AML |
| MA_0002107 | UBERON_0006656 | 0.62 | LogMap, AML |
| MA_0000599 | UBERON_0004268 | 0.99 | LogMapLt, AML |
| MA_0000004 | UBERON_0000468 | 0.50 | LogMap |
| MA_0000744 | UBERON_0009039 | 1.0 | LogMapLt |
| MA_0000001 | UBERON_0001062 | 0.99 | AML |
| Entity 1 | Entity 2 | Score | Matcher |
|---|---|---|---|
| MA_0002215 | UBERON_0007318 | 1.0 | LogMap, LogMapLt, AML |
| MA_0002110 | UBERON_0008783 | 1.0 | LogMap, LogMapLt, AML |
| MA_0000462 | UBERON_0001528 | 1.0 | LogMap, LogMapLt, AML |
| MA_0002358 | UBERON_0001298 | 0.99 | LogMap, AML |
| MA_0002107 | UBERON_0006656 | 0.62 | LogMap, AML |
| MA_0000599 | UBERON_0004268 | 1.0 | LogMapLt, AML |
| Parameter | Value | |
|---|---|---|
| Matcher | Single | Yes/No |
| Multiple | Yes/No | |
| Matchers | LogMap | Yes/No |
| LogMapLt | Yes/No | |
| AML | Yes/No | |
| YAM ++ | Yes/No | |
| Aggregation methods | Minimum | Yes/No |
| Maximum | Yes/No | |
| Average | Yes/No | |
| VOTE | Yes/No | |
| BK | DOID and UBERON ontologies | Yes |
| Existing Mapping | No | |
| Alignment repository | No | |
| Mapping selection | ML based | No |
| Rule based | Yes | |
| Maximum path length | 4 | |
| Internal exploration | Yes/No | |
| Threshold | 0.0 | |
| Semantic verification | Yes/No | |
| Track | All Paths | One Matcher | Two Matchers | Three Matchers | |
|---|---|---|---|---|---|
| Anatomy | Min | 0.777 | 0.519 | 0.652 | 0.903 |
| Max | 0.777 | 0.518 | 0.651 | 0.904 | |
| Avg | 0.778 | 0.518 | 0.650 | 0.904 | |
| Vote | 0.933 | - | 0.148 | 0.960 | |
| Task 1— FMA-NCI | Min | 0.839 | 0.624 | 0.664 | 0.940 |
| Max | 0.841 | 0.622 | 0.658 | 0.940 | |
| Avg | 0.841 | 0.619 | 0.658 | 0.941 | |
| Vote | 0.959 | 0.50 | 0.861 | 0.976 | |
| Task 2—Whole FMA and NCI | Min | 0.487 | 0.241 | 0.322 | 0.646 |
| Max | 0.485 | 0.241 | 0.321 | 0.638 | |
| Avg | 0.484 | 0.239 | 0.322 | 0.639 | |
| Vote | 0.725 | 1 | 0.578 | 0.739 | |
| Task 3— FMA-SNOMED | Min | 0.839 | 0.738 | 0.851 | 0.904 |
| Max | 0.842 | 0.737 | 0.852 | 0.902 | |
| Avg | 0.842 | 0.738 | 0.852 | 0.902 | |
| Vote | 0.964 | 1 | 0.959 | 0.970 | |
| Task 4—Whole FMA-SNOMED | Min | 0.680 | 0.457 | 0.777 | 0.859 |
| Max | 0.681 | 0.458 | 0.775 | 0.851 | |
| Avg | 0.681 | 0.457 | 0.774 | 0.853 | |
| Vote | 0.935 | 0.785 | 0.928 | 0.952 | |
| Task 5— SNOMED-NCI | Min | 0.787 | 0.599 | 0.677 | 0.941 |
| Max | 0.786 | 0.600 | 0.675 | 0.941 | |
| Avg | 0.786 | 0.599 | 0.675 | 0.942 | |
| Vote | 0.946 | 0.833 | 0.876 | 0.965 | |
| Task 6—Whole SNOMED-NCI | Min | 0.589 | 0.463 | 0.374 | 0.824 |
| Max | 0.590 | 0.462 | 0.375 | 0.824 | |
| Avg | 0.590 | 0.462 | 0.376 | 0.824 | |
| Vote | 0.843 | 0. | 0.690 | 0.873 | |
| Track | GBKOM (LogMap) | AML | LogMapLt | LogMap | Our Model | |||
|---|---|---|---|---|---|---|---|---|
| Min | Avg | Max | Vote | |||||
| Anatomy | 0.900 | 0.950 | 0.962 | 0.918 | 0.903 | 0.903 | 0.903 | 0.987 |
| Task 1—FMA-NCI | 0.945 | 0.958 | 0.967 | 0.945 | 0.967 | 0.968 | 0.970 | 0.995 |
| Task 2—Whole FMA and NCI | 0.763 | 0.806 | 0.676 | 0.867 | 0.797 | 0.806 | 0.813 | 0.989 |
| Task 3—FMA-SNOMED | 0.924 | 0.923 | 0.968 | 0.947 | 0.954 | 0.954 | 0.954 | 0.988 |
| Task 4—Whole FMA-SNOMED | 0.798 | 0.685 | 0.851 | 0.811 | 0.885 | 0.888 | 0.890 | 0.998 |
| Task 5—SNOMED-NCI | 0.924 | 0.906 | 0.949 | 0.957 | 0.948 | 0.947 | 0.951 | 0.997 |
| Task 6—Whole SNOMED-NCI | 0.795 | 0.862 | 0.798 | 0.874 | 0.823 | 0.827 | 0.830 | 0.995 |
| Track | GBKOM (LogMap) | AML | LogMapLt | LogMap | Our Model | |||
|---|---|---|---|---|---|---|---|---|
| Min | Avg | Max | Vote | |||||
| Anatomy | 0.947 | 0.936 | 0.728 | 0.846 | 0.962 | 0.963 | 0.963 | 0.922 |
| Task 1—FMA-NCI | 0.896 | 0.910 | 0.819 | 0.902 | 0.928 | 0.937 | 0.938 | 0.884 |
| Task 2—Whole FMA and NCI | 0.851 | 0.881 | 0.819 | 0.805 | 0.895 | 0.915 | 0.922 | 0.834 |
| Task 3—FMA-SNOMED | 0.735 | 0.762 | 0.208 | 0.690 | 0.823 | 0.827 | 0.828 | 0.668 |
| Task 4—Whole FMA-SNOMED | 0.695 | 0.710 | 0.208 | 0.642 | 0.787 | 0.791 | 0.792 | 0.561 |
| Task 5—SNOMED-NCI | 0.705 | 0.746 | 0.566 | 0.666 | 0.779 | 0.783 | 0.786 | 0.653 |
| Task 6—Whole SNOMED-NCI | 0.683 | 0.687 | 0.566 | 0.650 | 0.760 | 0.767 | 0.771 | 0.594 |
| Track | GBKOM (LogMap) | AML | LogMapLt | LogMap | Our Model | |||
|---|---|---|---|---|---|---|---|---|
| Min | Avg | Max | Vote | |||||
| Anatomy | 0.923 | 0.943 | 0.828 | 0.880 | 0.931 | 0.932 | 0.932 | 0.954 |
| Task 1—FMA-NCI | 0.920 | 0.933 | 0.887 | 0.923 | 0.947 | 0.952 | 0.954 | 0.937 |
| Task 2—Whole FMA and NCI | 0.804 | 0.842 | 0.741 | 0.835 | 0.843 | 0.857 | 0.864 | 0.905 |
| Task 3—FMA-SNOMED | 0.819 | 0.835 | 0.342 | 0.798 | 0.884 | 0.886 | 0.886 | 0.797 |
| Task 4—Whole FMA-SNOMED | 0.743 | 0.697 | 0.334 | 0.717 | 0.833 | 0.836 | 0.838 | 0.718 |
| Task 5—SNOMED-NCI | 0.80 | 0.818 | 0.709 | 0.785 | 0.855 | 0.857 | 0.861 | 0.789 |
| Task 6—Whole SNOMED-NCI | 0.735 | 0.765 | 0.662 | 0.746 | 0.791 | 0.796 | 0.799 | 0.744 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Yadumi, S.; Goh, W.-W.; Tan, E.-X.; Jhanjhi, N.Z.; Boursier, P. Multimatcher Model to Enhance Ontology Matching Using Background Knowledge. Information 2021, 12, 487. https://doi.org/10.3390/info12110487
Al-Yadumi S, Goh W-W, Tan E-X, Jhanjhi NZ, Boursier P. Multimatcher Model to Enhance Ontology Matching Using Background Knowledge. Information. 2021; 12(11):487. https://doi.org/10.3390/info12110487
Chicago/Turabian StyleAl-Yadumi, Sohaib, Wei-Wei Goh, Ee-Xion Tan, Noor Zaman Jhanjhi, and Patrice Boursier. 2021. "Multimatcher Model to Enhance Ontology Matching Using Background Knowledge" Information 12, no. 11: 487. https://doi.org/10.3390/info12110487
APA StyleAl-Yadumi, S., Goh, W.-W., Tan, E.-X., Jhanjhi, N. Z., & Boursier, P. (2021). Multimatcher Model to Enhance Ontology Matching Using Background Knowledge. Information, 12(11), 487. https://doi.org/10.3390/info12110487