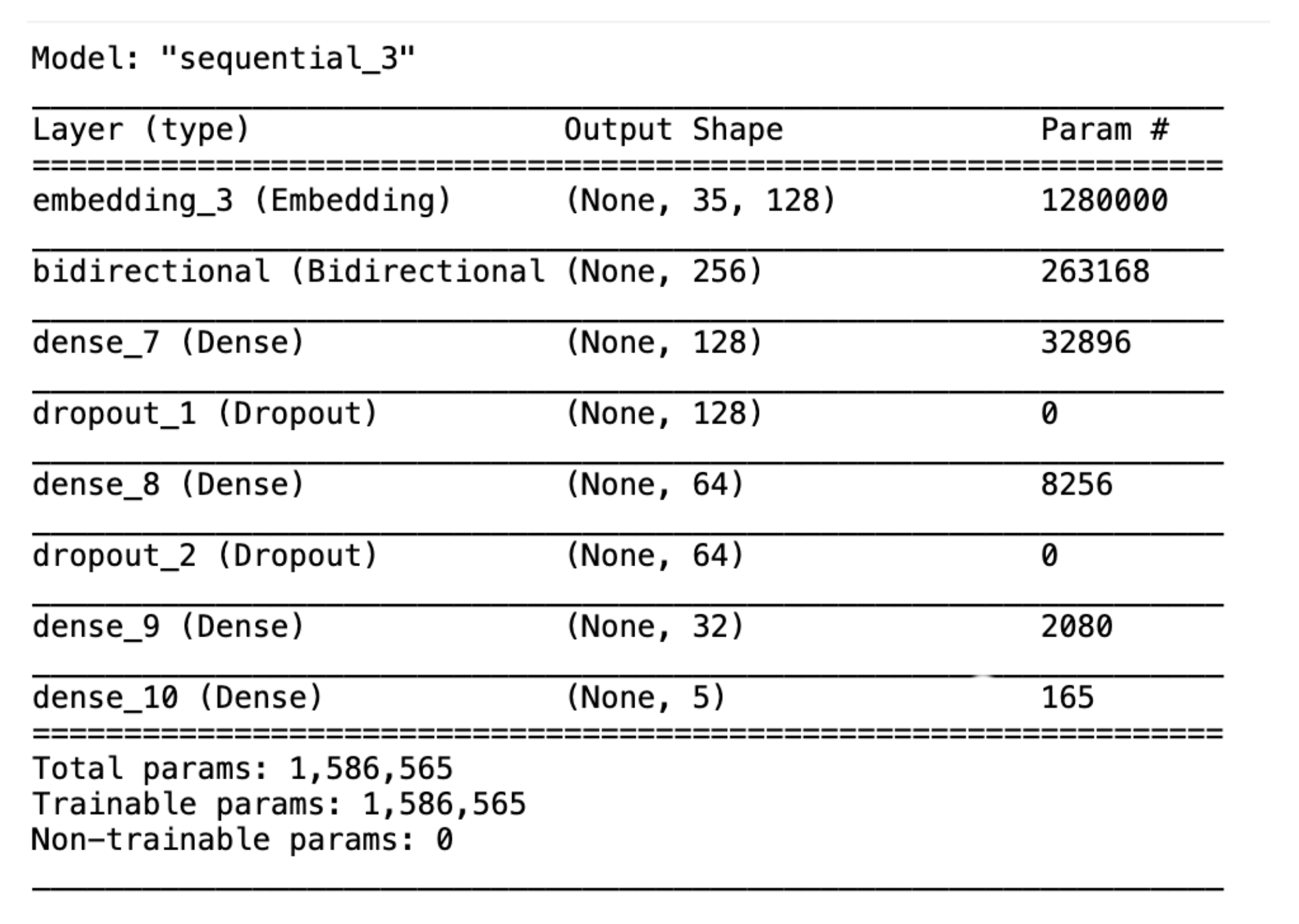
3.2. Results
Table 2 shows a summary of the macro-average results and the accuracy of all the models. At first glance, it is easy to observe that the deep learning models all performed better than the classical machine learning ones. The BERT model obtained the highest scores, with an F1 of 71%, which is more than double that of the Gaussian Naive Bayes model.
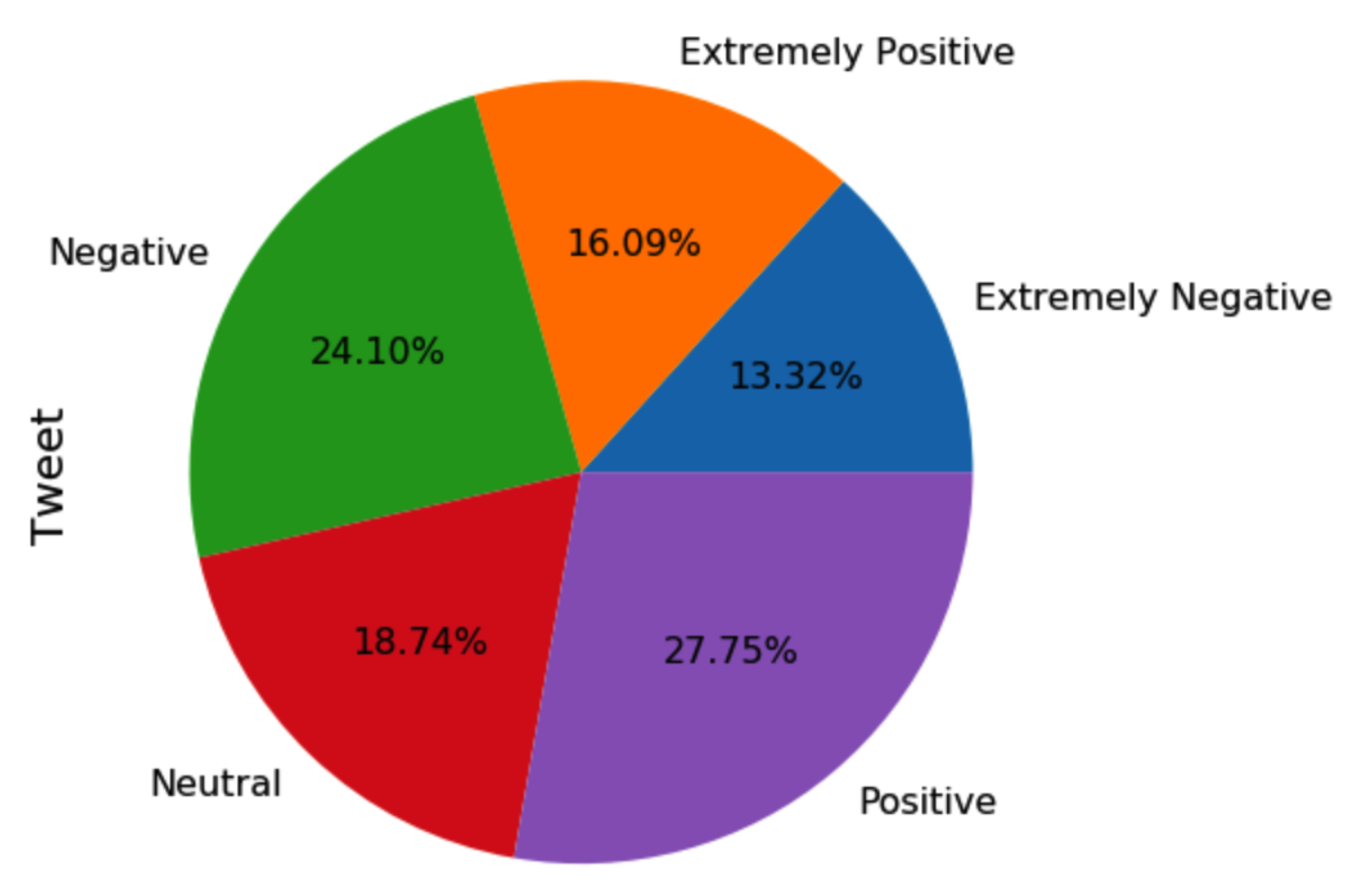
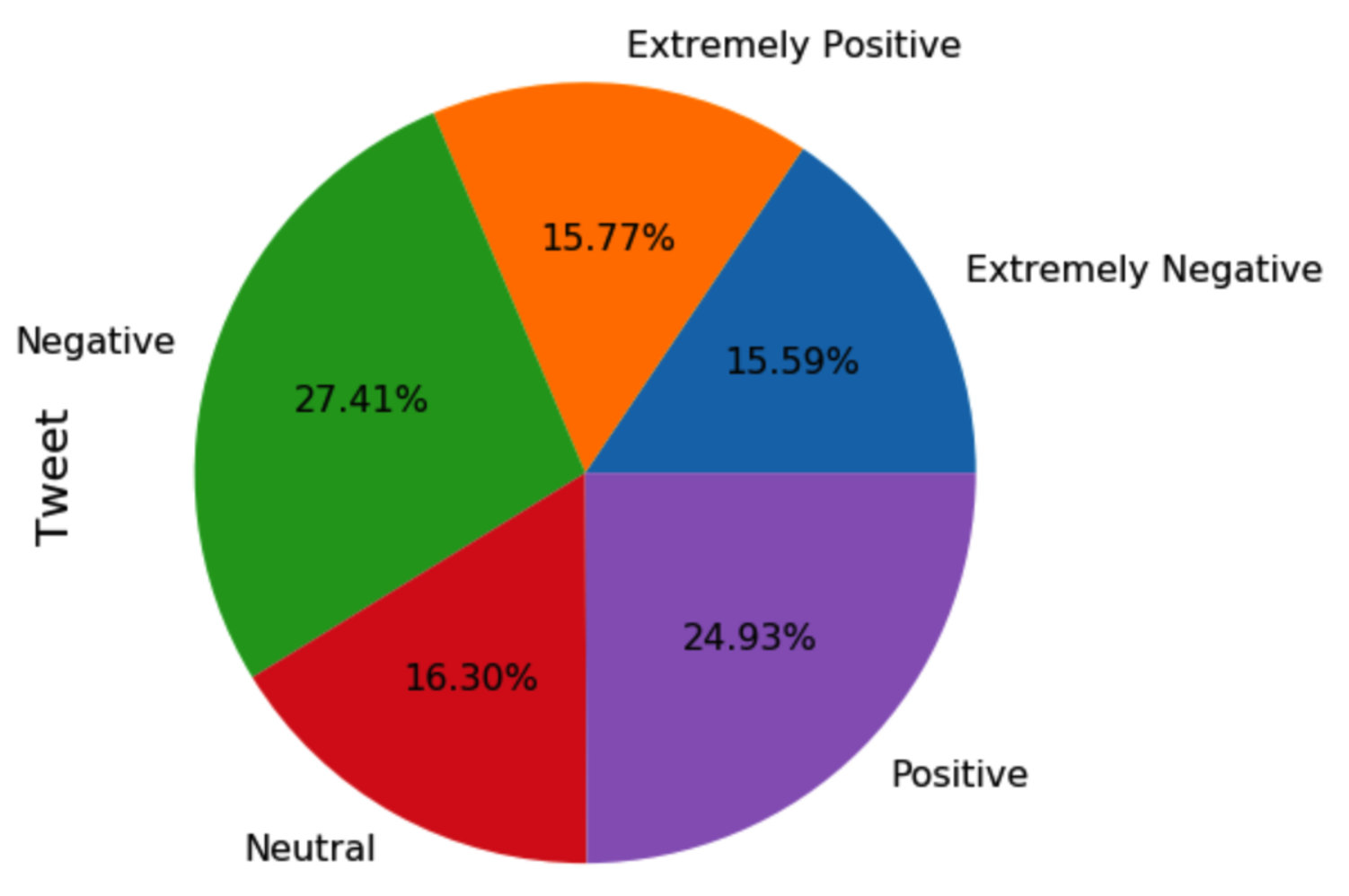
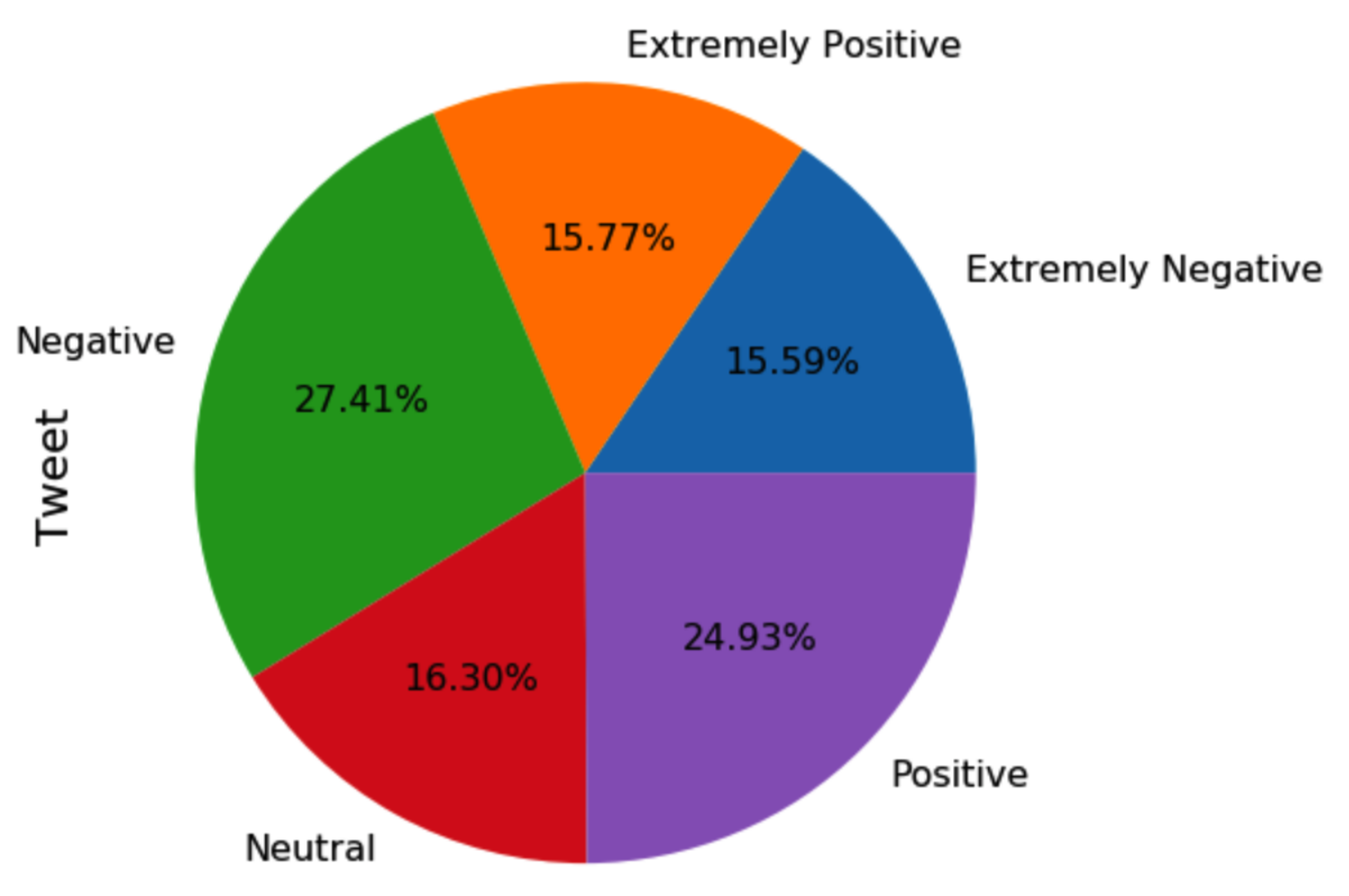
As there were five different classes in the study, a dummy classifier, which would assign all predictions to the greater class, would achieve a baseline score of 20% if the dataset was perfectly balanced. In our case, it would be closer to 25%. Thus, this must be taken into account as the lowest possible accuracy rate. A model with an accuracy value lower than this would perform very poorly. Therefore, it was necessary to use this as the lowest possible benchmark that we could achieve.
The model with the lowest accuracy was the Gaussian Naive Bayes. This model only reached an accuracy of 35%, with similar levels of precision and recall, but a very low F1-score of 35%. Then, we observed a significant jump in performance to reach the Multinomial Naive Bayes model, with an accuracy of 45% and similar values for the other metrics. It could be seen that the two probabilistic models were the lowest-performing models. This was because the size of the dataset, with the different classes and the non-normal distribution of the vectorized words, caused the probabilistic models to perform worse than the deterministic ones. The Random Forest model was next on the list, but not by a large margin, as its overall accuracy was only 47%.
SVM and Logistic Regression obtained accuracy values of 55% and 56%, respectively. Both classifiers provided the same F1-score of 55% over the test dataset. They were the best traditional machine learning classifiers for this task. In fact, previous works have proven that Logistic Regression usually achieves the best results in multiclass text classification tasks [
20]. As could be seen, their performances were not great, and only 5 out of 10 tweets would have been correctly classified in their sentiment.
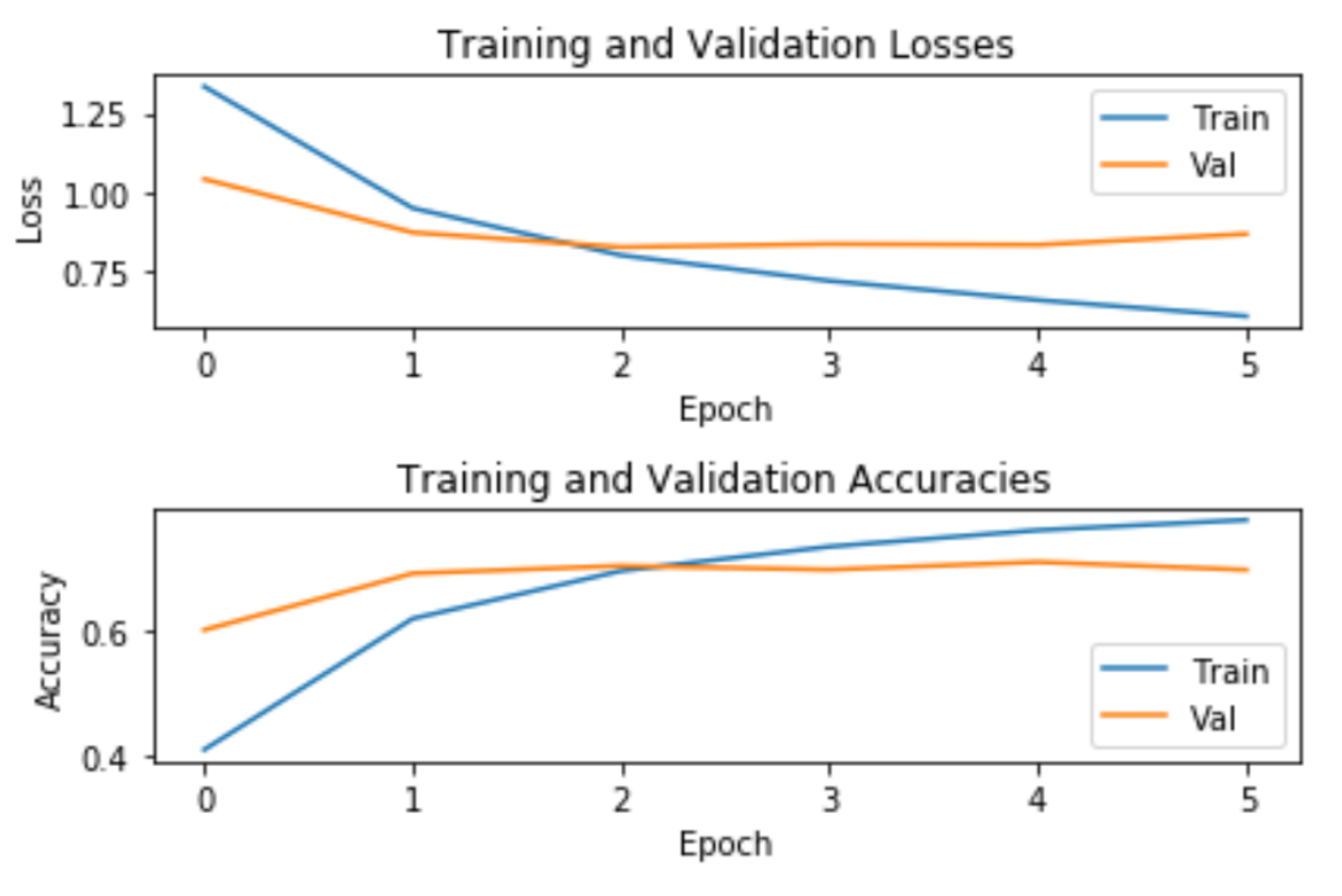
The top tier of models that were analysed in this study corresponded to the neural network models. Thus, MLP had an F1-score of 65%, 10 points greater than SVM and Logistic Regression. Its accuracy was also 10 points greater than Logistic Regression.
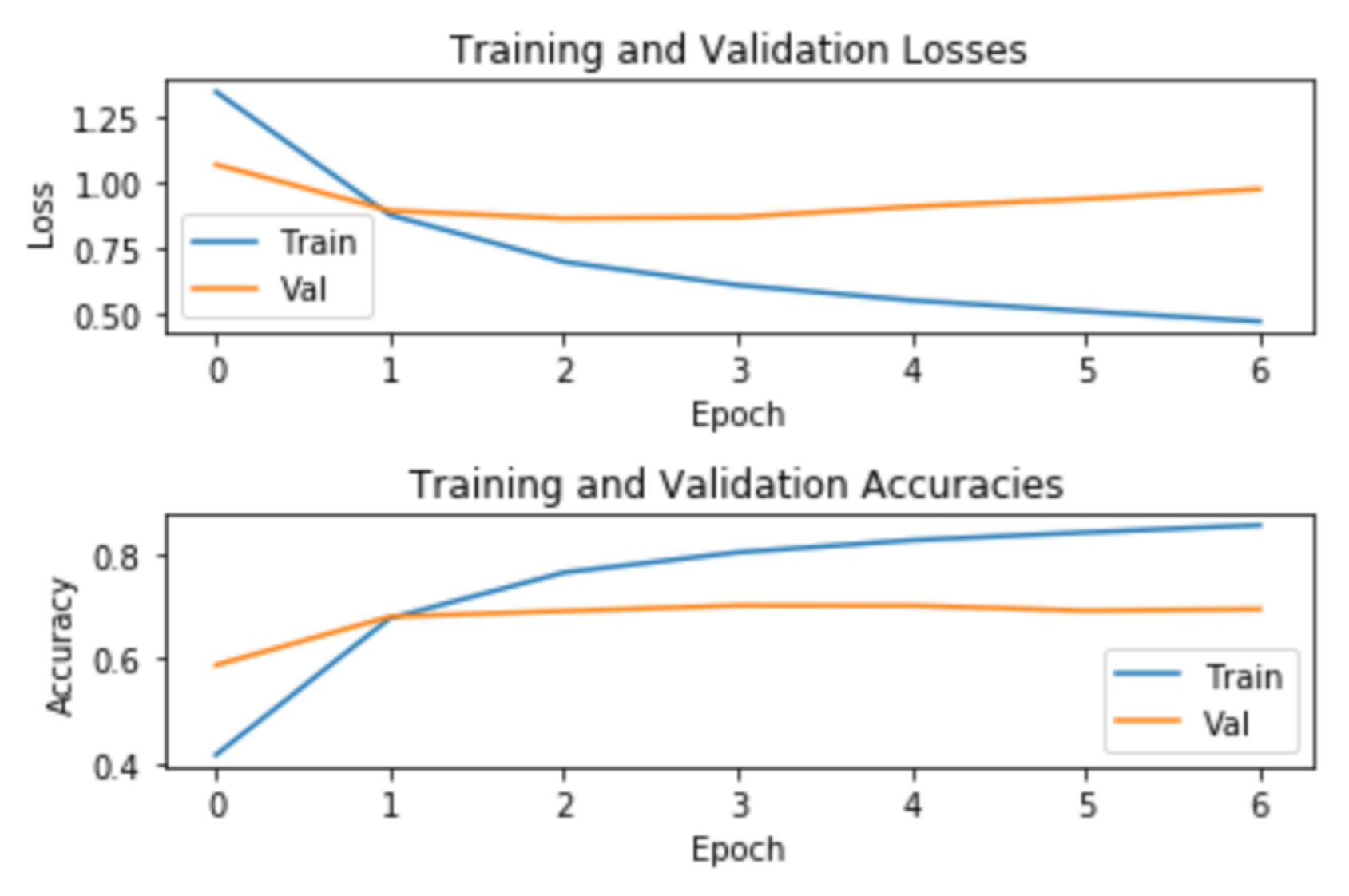
We now focus on the deep learning models. The LSTM model obtained an accuracy and an F1-score of 67%. In other words, LSTM provided slightly better results than MLP and significantly overcame the traditional machine learning classifiers. Finally, BERT achieved the best results, reaching an accuracy and an F1-score of 71%. BERT obtained improvements of 16% in accuracy and 15% in the F1-score over Logistic Regression, the best of the traditional machine learning models. BERT’s scores were also significantly better than those obtained by the MLP, with a difference of 6 points above the accuracy of MLP (65%). When comparing the deep learning methods, it can be said that BERT showed an improvement of 4 points in terms of accuracy and F1-score.
Table 3 shows the classification scores of the logistic model divided by the sentiment classes. Both the negative and the positive class were the ones with the lowest F1-scores, with 45% and 53%, respectively. These instances might have been wrongly classified in the extremely negative or positive categories, since they could be difficult to distinguish.
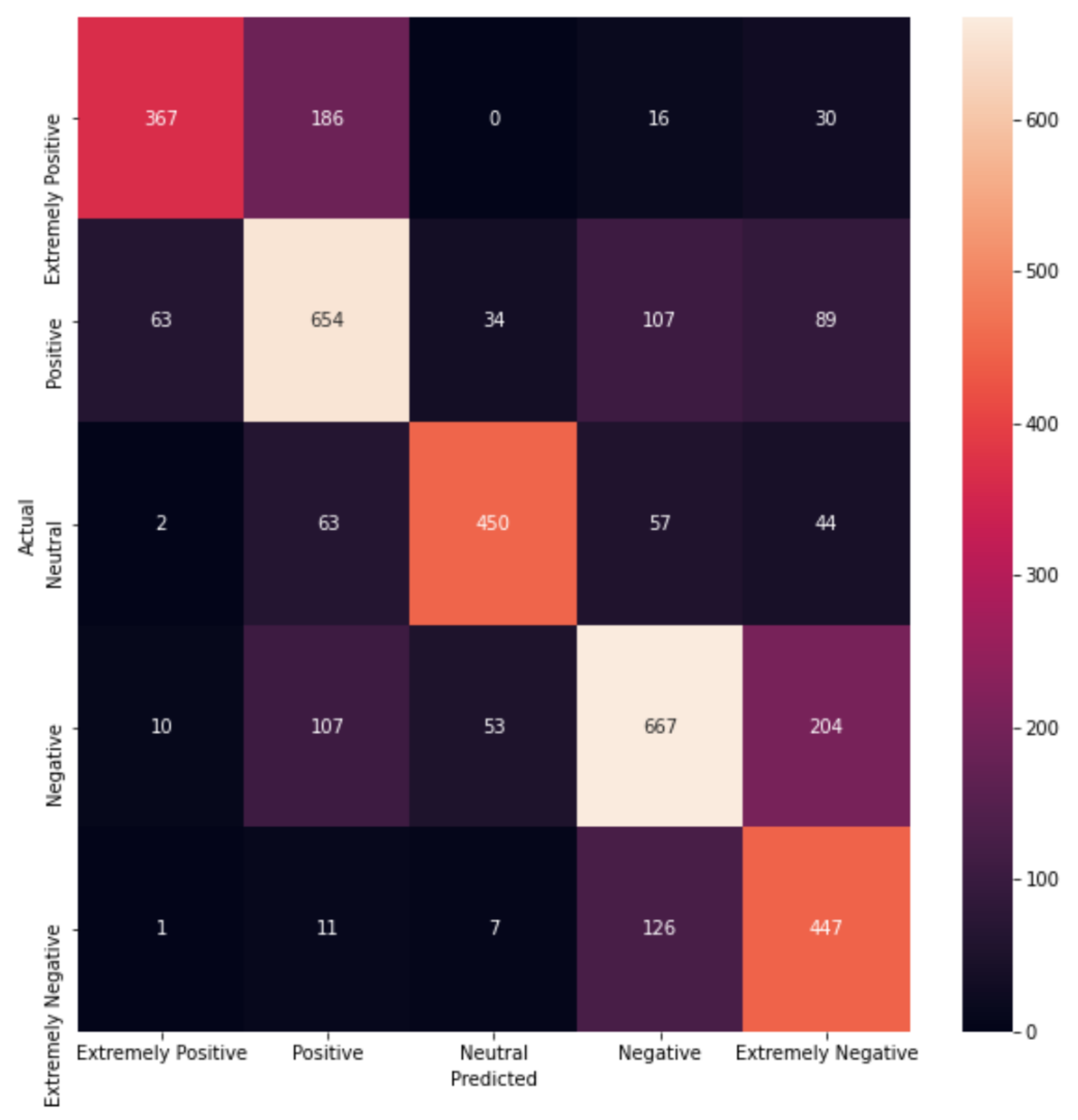
LSTM has a similar behaviour (see
Table 4), but the classes with the lowest performance were the negative and the extremely negative classes. A large increase in the neutral class was seen, and the positive class remained similar to the negative class in terms of F1-score.
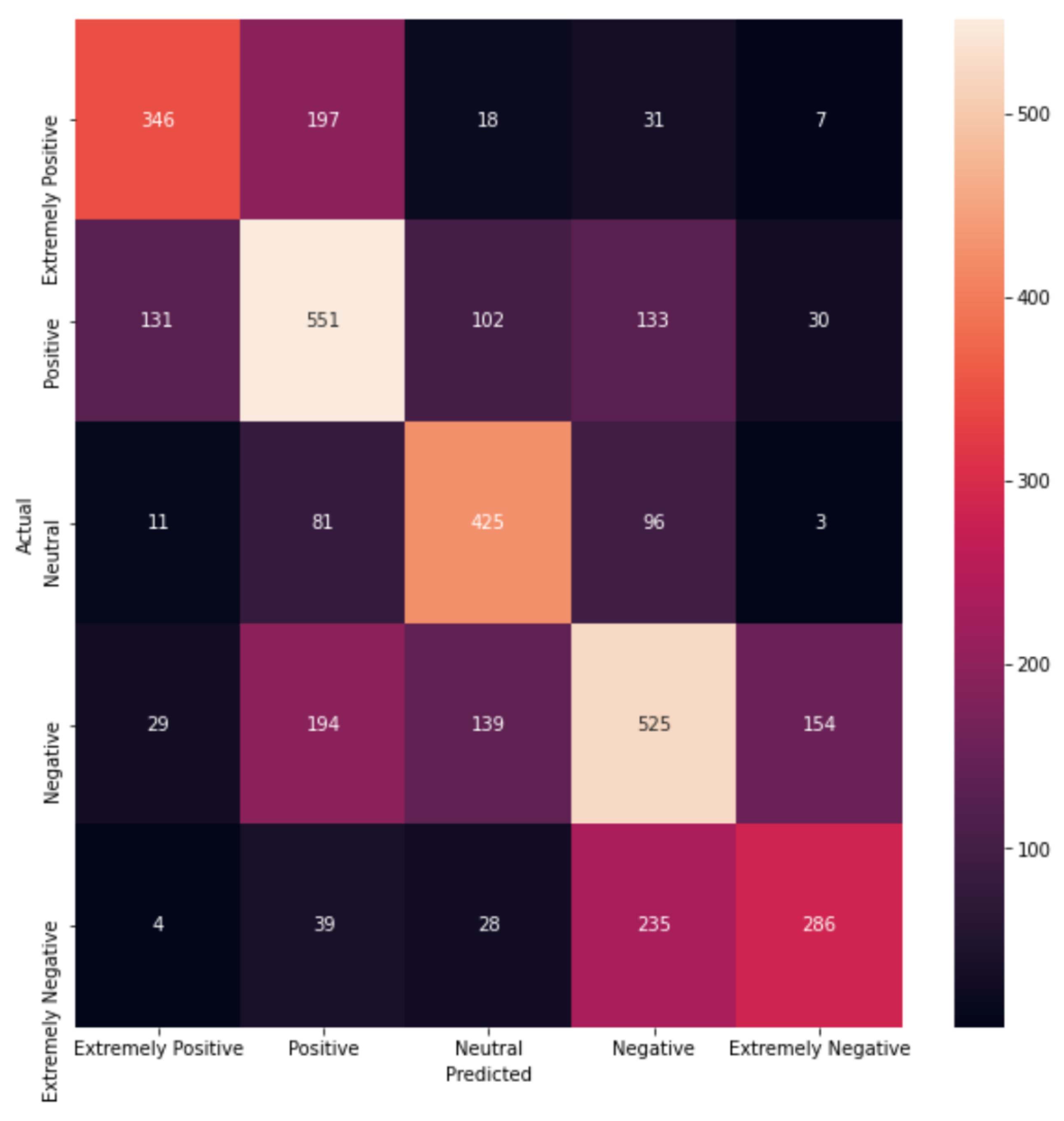
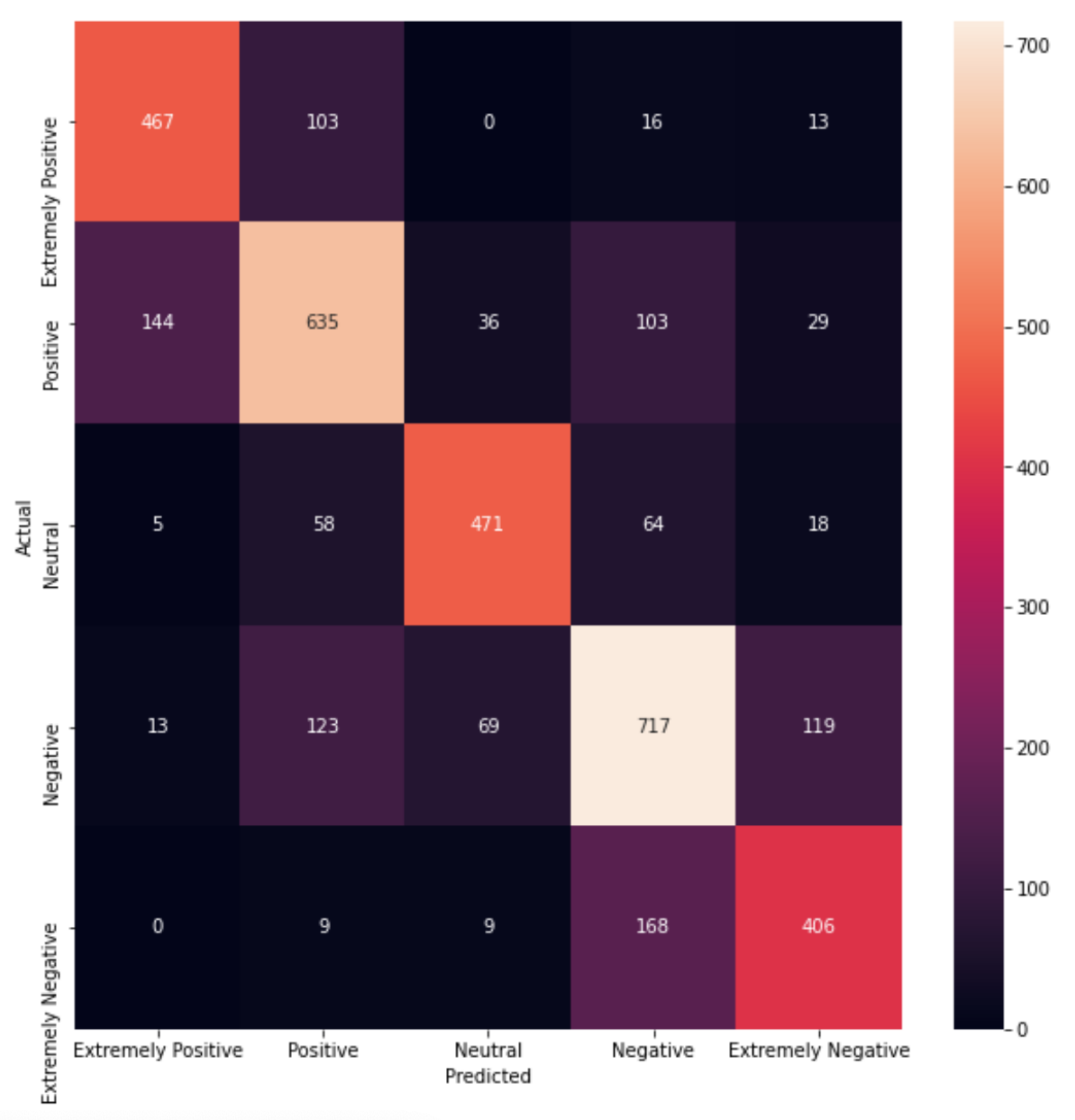
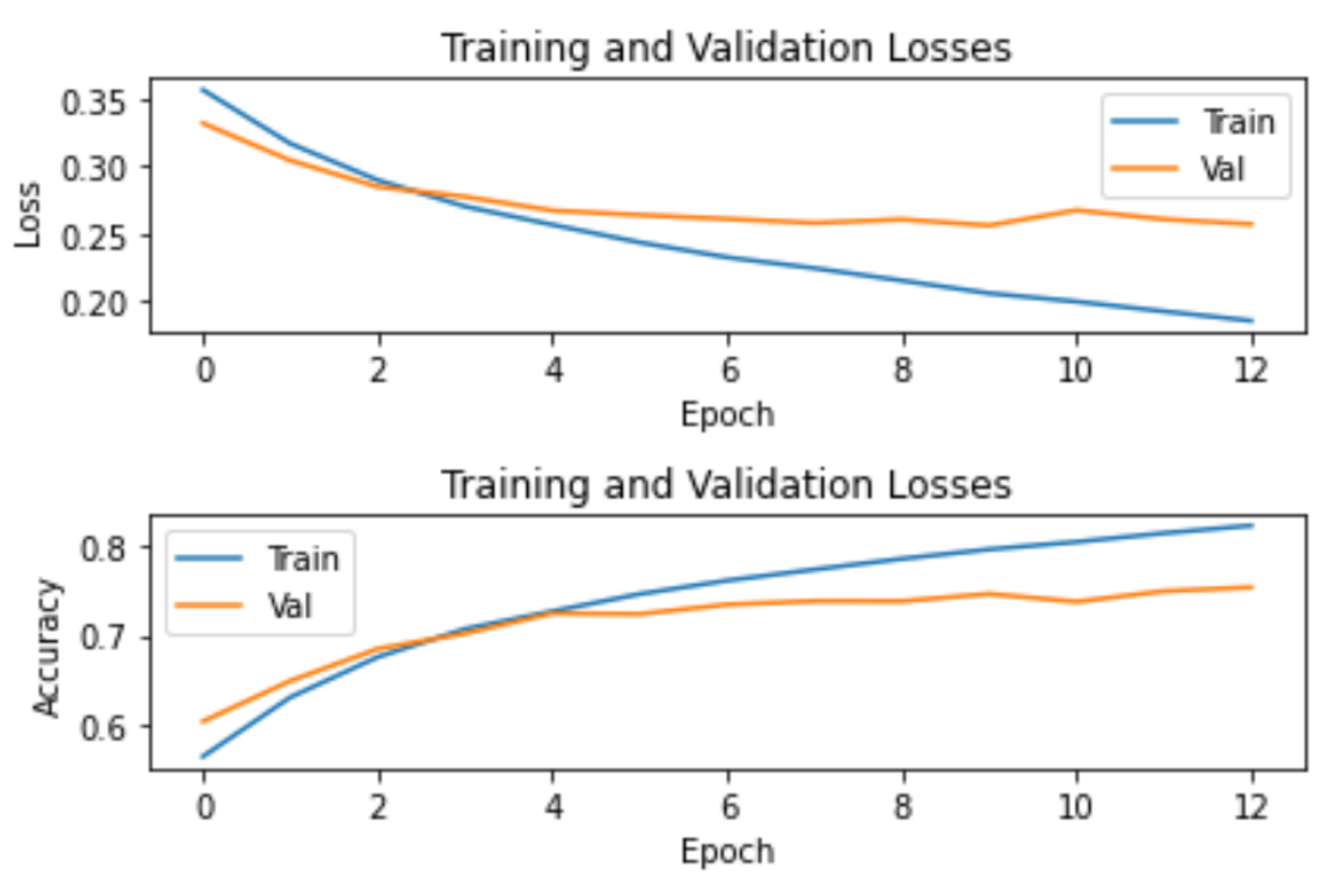
Table 5 shows a more detailed evaluation for the BERT model, providing scores for each class. It can be seen that the precision scores for the negative and the extremely negative classes were much lower than those of the positive or the neutral ones. In terms of the F1-score, the worst-performing classes were the positive and the negative, with a value of 68% each. Compared to the neutral class, this was very poor, since the neutral class had an F1-score of 78%, ten points higher. Overall, the accuracy of the model was 71%, which, at first glance, does not appear particularly high, but dealing with multiple classes is not as simple as the binary classification problem, where the benchmark is at 50%. As mentioned before, in this study, having five categories, a dummy classifier would obtain a 20% accuracy score. Therefore, achieving more than 70% shows very good performance indeed.
Finally, we can conclude that BERT showed its clear superiority in this task and was clearly the most accurate model to use in this sentiment classification task.
All the previous systems [
21,
22,
23] trained on the same Kaggle dataset [
3] only addressed the task of classifying negative, neutral and positive messages. In other words, they merged the instances from the extremely negative and negative classes, and they did the same for the extremely positive and positive classes. Therefore, a direct comparison to these systems’ models cannot be done. Similarly, the study presented in [
24] only detected negative, neutral and positive tweets, obtaining a very high F1-score (around 98%). However, its results cannot be directly compared to ours, because we performed a finer-grained sentiment analysis of tweets about the COVID-19 pandemic.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}