Abstract
This article numerically analyzes the distribution of the zeros of Riemann’s zeta function along the critical line (CL). The zeros are distributed according to a hierarchical two-layered model, one deterministic, the other stochastic. Following a complex plane anamorphosis involving the Lambert function, the distribution of zeros along the transformed CL follows the realization of a stochastic process of regularly spaced independent Gaussian random variables, each linked to a zero. The value of the standard deviation allows the possible overlapping of adjacent realizations of the random variables, over a narrow confidence interval. The hierarchical model splits the function into sequential equivalence classes, with the range of probability densities of realizations coinciding with the spectrum of behavioral styles of the classes. The model aims to express, on the CL, the coordinates of the alternating cancellations of the real and imaginary parts of the function, to dissect the formula for the number of zeros below a threshold, to estimate the statistical laws of two consecutive zeros, of function maxima and moments. This also helps explain the absence of multiple roots.
1. Introduction
This article presents a distribution model of the non-trivial zeros of the zeta function on the critical line (CL). The Riemann Hypothesis (RH) [1] places them exclusively on this line, but this article focuses on the CL zeros, regardless of the RH.
We first explored the global behavior of the function on the CL, and the role of the Lambert function [2] on the folds of the function in the critical strip (CS). A close relationship exists, on the CL, between Riemann’s function and Lambert’s function, after an anamorphosis of the ordinate of the complex plane.
This article also shows that, on the CL, there is a relationship between both the real and imaginary components of the function. This ratio, only valid on the CL, takes into account an angle tied to the fractional part of the anamorphosed ordinate, which makes it possible to anchor the common zeros of these two components in an equivalence relation, where the classes are intervals of unit length. Thus, both surfaces, alternatingly zero, with period one on the anamorphosed ordinate of the complex plane, locally generate an additional common zero which is the th non-trivial zero.
The article then investigates, on the anamorphosed axis, the local “random” character of the th non-trivial zero, in the form of the realization of a Gaussian random variable (RV) with a mean and standard deviation increasing very slowly with , of order for , all these RVs being pairwise independent. The magnitude of the standard deviation leads to the possible permutation of some realizations of adjacent RVs, justifying the uncertainty in the formula for the number of zeros below a given threshold, and explaining the corresponding difficulty for algorithms to compute these zeros.
Finally, this article presents a taxonomy of the local behaviors of the function in the CS, according to the probability density of the RV relevant to the th zero. The model still allows a number of derivations which reaffirm some classical formulas of the Riemann function. This also helps explain the absence of multiple roots.
By consulting the abundant scientific literature on the zeros of the Riemann function, including certain pioneering articles [3,4,5,6,7,8], one can distinguish three broad families of publications, with the first two having the underlying ambition to provide proof of the RH.
The first family consists in circumscribing the perimeter of the region where the zeros are located. As early as 1896, Hadamard [3] and La Vallée Poussin [4] restricted the “fertile region” of zeros to the CS . Then, during the twentieth century, the region was reduced in two ways. On the one hand, by further limiting the perimeter, and on the other hand by increasing the percentage of potential zeros on or around the CL [9,10], in an increasingly restricted perimeter.
The second family consists in analyzing only CL zeros [11,12], by estimating the number of zeros less than a value of the ordinate of [13], by calculating the number of zero crossings on the CL, by studying the adjacent zeros, or by estimating other characteristics of the function, always with the aim of apprehending the RH, according to various points of view.
The third family, more concretely, consists in effectively calculating the CL zeros with a numerical algorithm [14,15]. Currently, the exercise, which thrived between 1985 and 2005, has seen a loss of momentum, as the number of known zeros is substantial. Extending these calculations has become superfluous with silicon computers, although searches for zeros beyond about over an interval of the order of , would provide interesting additional knowledge on the function.
The aim of this article belongs to the second family, by taking advantage of numerical results of the third family. Indeed, the goal here is not to investigate questions about the RH, nor to determine an algorithm to effectively calculate zeros. The goal is mainly to define, on the CL, a distribution model with two layers, one deterministic and the other stochastic, to specify the local characteristics of the function around the zeros and to discuss the evolution of local behavior of rare events with increasing .
Despite its age, Edward Charles Titchmarsh’s book [16] is the most comprehensive book on function theory. It covers almost everything anyone would want to know about the function. Aleksandar Ivić’s book (Александар Ивић) [17] offers an easier approach for anyone who wants to understand all of the questions about the function, including the theory but also its applications.
After this introduction, the notations, methodology, data, computer science and mathematical tools are presented in Section 2. Section 3 presents the results. A discussion of the assumptions and results is expressed in Section 4, before the conclusion. The whole article is based on numerical calculations performed by computer programs in the Python language, designed and implemented by the author. Some calculations are supported by power series, which were validated by computer.
2. Materials and Methods
2.1. Mathematical Notations
Where possible, classical mathematical notations have been selected (Table 1): to lighten the writing, some original notations are defined.

Table 1.
Notations.
2.2. Numerical and Graphical Observation as a Tool for Reflection
It is fruitful to numerically represent and visualize the catalog of formulas, well known to all, to verify some exact formulas with infinite sums and to validate approximations or inequalities, demonstrated mathematically, to testify to their robustness, speed of convergence and power of truth. Graphical visualization is a powerful tool for analysis and reflection, which amply guides intuition to take paths that are difficult, if not impossible, to take with the traditional manipulation of mathematical formulas. However, the function calculations become complicated, even impractical, on a computer, when takes large values (). The window of practicable computer calculations ignores large numbers.
2.3. The Gap between Observation and Demonstration
Numerical processing and observation allow for the quashing of a formula, approximation or inequality, with a single representation, when this representation does not conform to the postulate or original intuition. However, the numerical calculation and graphical visualization on the first few million zeros do not demonstrate anything. We know the fallacy of the hasty general conclusions drawn from premature examinations of a phenomenon observed over too small an interval, while the results change or reverse over a wider interval. The well-known example is the Skewes number on the difference , where the sign swaps for huge values (a current upper bound where this occurs is ). For the function, the profile of the real and imaginary surfaces has more and more tightly packed folds, with increasingly strong amplitudes. The mixing of RVs and the rules for the appearance of zeros undergo very slow evolutions, so that the observations for risk masking new landscapes of the function for higher values, beyond . A (perhaps daring) extrapolation will nevertheless help to predict the behavior beyond .
The methodology here consists in first presenting the graphs and statistics on the raw variables. An analysis then allows these variables to undergo geometric transformations, in order to obtain more abstract calculated variables but with classic statistics that can be manipulated, mathematically.
Observation is also a good complementary tool, preceding a demonstration. This is what we will expose by presenting the graphical evolution of the local distribution of consecutive zeros and the evidence for the presence of only single roots in the CS.
2.4. Data and Computer Science Tools Used
This study was performed using the set , which represents the first 6 million zeros, as well as a few other sets of higher values. On the interval , we observe, without exception, that the zeros are located on the CL () according to the two-layered model (Lambert function and stochastic Laplace–Gauss process) described below. To obtain the list of zeros on the CL, one can consult several websites on the Internet [14,15], but one can also recalculate some of them. The computer used by the author is a personal computer, and therefore certain calculations sometimes take an exorbitant processing time: the calculation of certain zeros takes days of calculation time to obtain.
All the programs were written in Python, with the graphics library matplotlib and the mathematical library mpmath to allow for calculations with a number of adjustable significant figures (in the order of 15, 30 or 50, depending on the case) for floating point numbers.
2.5. Mathematical Tools Used
2.5.1. Stochastic Processes
is a random variable (an RV). The RVs are pairwise independent RVs.
is a Gaussian RV . The RVs are pairwise independent.
The two-layer hierarchical model is:
An anamorphosis from to :
Two stochastic processes and are adjoined by independent RVs on associated with independent Gaussian RVs on , representing the nth zero.
The pair forms real RVs on the probability space , measurable functions of on :
We can consider that the stochastic processes are Markov processes (at least for ):
With this assumption, there is here a dependence between two adjacent RVs.
2.5.2. The Truncated Gaussian Distribution Density
The first two moments of an RV are the expectation and the variance, the centered second order moment: . The RV which follows a normal distribution is denoted by: .
The Gaussian probability density is: standard law:
A real RV is said to have density if there exists a positive and integrable function on , called a density function, such that for all .
For an RV , of distribution function , of density , the conditioning at the interval gives:
The associated density is: . The truncated normal distribution that we constrain to belong to the interval has the density:
2.5.3. The Error Function
The error function is used to estimate the percentage of the population which finds itself inside and outside of a given interval. For the normal distribution, the interval is: . On Table 2, we show, for each interval, the percentage of the concerned population.
Table 2.
Confidence interval and % of the population.
The proportion of the population in the interval is:
2.5.4. Lambert’s Function
Lambert introduced his eponymous function in 1758 [2]. In general, this function is outstanding for compressing the values of mathematical functions that increase even more rapidly than the exponential, and that of functions of related physical phenomena (Figure 1).
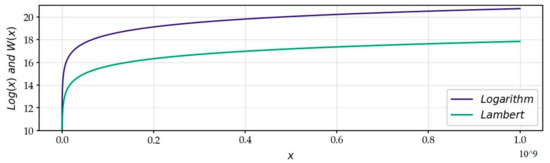
Figure 1.
Comparison between the Lambert and Logarithm functions: Lambert’s function compresses high values more than the Logarithm function.
Lambert’s function enables us to examine the behavior of functions with large numbers, such as and . The Lambert function overwrites high values with a more powerful mechanism than that of the logarithm function, by abrogating the exponential component of the function: . In the use we are going to make of it, it will remove the exponential component from the function , applied to : . In this article, it allows us to present the distribution of non-trivial zeros on the CL. Lambert’s function is the reciprocal of the complex variable function defined by :
For high values of : .
2.5.5. Hadamard’s Product Formula
Hadamard’s product formula contains in its expression, on the one hand, the non-trivial zeros and on the other hand, the functional Riemann equation. It therefore has a remarkable strength to characterize the zeta function and its deep relationship with neighborhoods of zeros. We know the formula:
Moreover, we know that:
The formula becomes:
Using a CL point of and the zeros on the CL , which assumes the RH to be true, the infinite sum is written:
We finally obtain, taking into account the pairs of zeros on the CL ( and ):
This formula converges slowly on the imaginary component, because of the terms in .
When is very large, we can do the approximation: .
The sum can then be broken down into two sums if :
We can then choose to obtain a good approximation, but the convergence is always slow.
If was always very small compared to , which is never the case since sweeps the entire range of ordinates, we could have an estimate of the infinite sum:
is the Glaisher–Kinkelin constant: .
This calculation only fixes orders of magnitude for the terms far from :
2.6. The CL Zeros within the Bibliography
There are many publications on the existence and properties of the zeros of the Riemann function [18]. As early as 1896, Hadamard made subtle use of the properties of the holomorphic function. As early as 1914, authors used the powerful tools of functional analysis and Fourier transforms to deduce inequalities that led to increasingly refined results. It should be noted that in these papers, the functional Riemann equation is used more qualitatively for its symmetry in compared to , rather than quantitatively for the value of the factor .
The main classic formulas are the following:
- Number of zeros:If denotes the number of zeros (counting multiplicities) of in the rectangle , Riemann proposed the estimate , Backlund [19] obtained the specific estimate: .In 2020, the number of zeros in the rectangle is considered asAn asymptotic estimate for the zero of rank , is .
- Consecutive zeros [20]:Assuming the RH, Feng and Wu [21] showed that the average size of the gaps is: and infinitely often: .Montgomery [22] suggested that there were arbitrarily large and small gaps between consecutive zeros of , which is to say and .
- Moment of order 2:
- High moments of the Riemann zeta-function [23,24], moments of order :
3. Results
The results are presented in progression, over graphic illustrations, for educational purposes.
3.1. The Global Distribution Model: The Density of Zeros and the Lambert Function
Figure 2 illustrates the raw frequency of occurrence of the first 6 million zeros, adjusted to a theoretical frequency. The calculation is carried out on intervals of 200 points. The law of appearance of zeros obeys a theoretical density of probability of appearance of , a formula which was already known to B. Riemann.
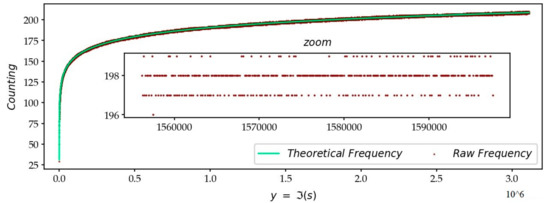
Figure 2.
Density of non-trivial zeros on the CL for the first 6 million zeros. The density of the appearance of zeros, on the axis from to , is calculated on segments of length . It is verified, on the zoom, that the experimental law remarkably follows the theoretical curve, by observing that the number of zeros in a sliding window, at this location ( to ), ranges from 196 to 199.
Figure 3 illustrates the error between the raw density and the theoretical density.

Figure 3.
Error between the theoretical and experimental distribution densities. This error varies for the set between and for segments of length .
If the probability density is , the rank of a particular zero within the sequence is and the number of zeros less than or equal to is the integral . We highlight here the status of the variable of the ordinate of which comes into play in the zeroing mechanism of the function via the anamorphosed variable . Thus, the Lambert function appears through the product present in the integral formula and in many formulas of the function. The Lambert function thus makes it possible to exhibit the anamorphic space by the transformation of the coordinates of :
The passage into a transformed space via this function makes it possible to simplify the study of the function. After the anamorphosis of the axis, in Figure 4, we determine the constant , by fitting the line .
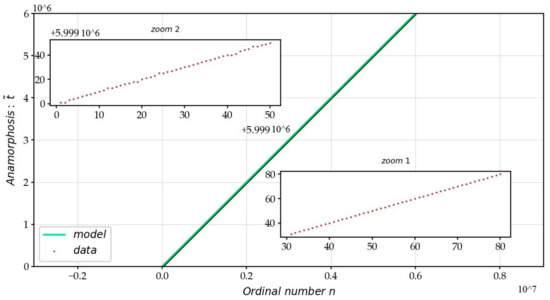
Figure 4.
Curve of the first 6 million zeros after the anamorphosis of the ordinate of the complex plane by the Lambert function. The adjustment of the line from after the anamorphosis allows us to calculate the constant .
The value identifies the nth non-trivial zero, with which is given a geometric interpretation below in the form of an angle. However, this formula succeeds in identifying of zeros but fails by or to qualify zeros, either ahead or behind.
In Figure 5, we represent the histogram of which has a maximum at ⅝ and a minimum at ⅛. We can conclude that in order to recover an integer for more often, it is judicious to subtract ⅛ from the real value of , in order to best estimate the integer number . Therefore, the formula is hence more correct.
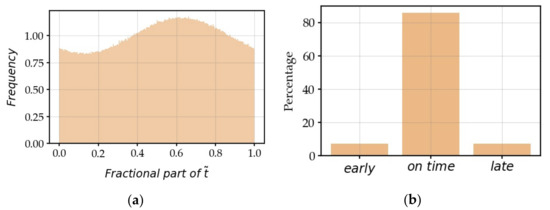
Figure 5.
(a) Histogram of with 500 intervals: frequency minimum is at ⅛, maximum is at ⅝. We recognize a histogram made up of several random variables folded on themselves and with an average of ⅝; (b) histogram .
In Figure 6, the error on is depending on whether the nth zero is ahead ( with a frequency of 6.5%) or behind (, with a probability of 6.5%), but the error is zero in the general case (87%). We will see in the following that the maximum error increases with when is greater ().
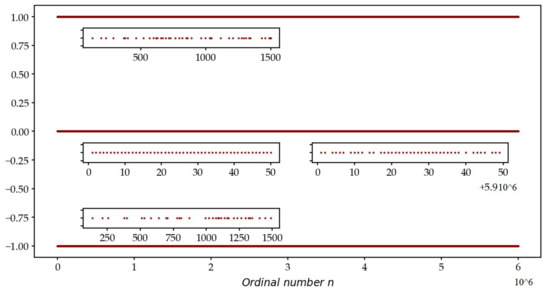
Figure 6.
Error versus ; .
In Table 3, we present the list of the 50 first zeros which are classified with an error of and an error of , i.e., the list of the first zeros which are, behind and ahead, respectively.
Table 3.
The 50 first early and late zero numbers.
When we know the ordinates of the zeros, we can therefore rectify the incorrectly estimated zeros in the formula and restore the residual which is greater than 1 in absolute value. Once this correction has been carried out, one can calculate the new histogram which is plotted on Figure 7. One deduces the second layer of the theoretical model from it. A zero is the realization of a Gaussian random variable . We can define the standard Gaussian variable such that: and estimate the probability density function (PDF) which turns out to be almost a perfect Gauss Law.
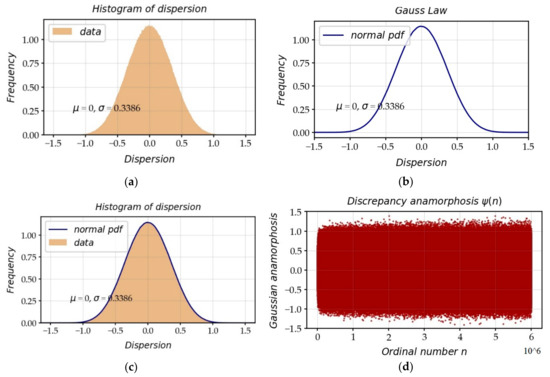
Figure 7.
(a) Histogram with 500 intervals; (b) theoretical fit of the Gaussian curve ; (c) we check that the frequency is a perfect Gaussian curve between (a) and (b); (d) scatterplot of the deviation of from the mean by , along . This interval, which varies from to , has extremes which deviate a little more, but in a very slow fashion, with respect to .
3.2. The Local Distribution Model: the Realization of Gaussian RVs
We thus obtain a hierarchical model with two layers (Figure 8). On the axis, we introduce pivots, which will be the averages of the RVs.
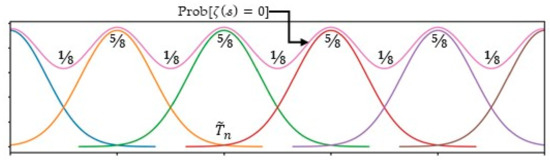
Figure 8.
Stochastic process of independent Gaussian random variable (RV), regularly spaced on the axis. The probability of obtaining a zero is not uniform on the anamorphic axis: the probability is maximum for and minimum for . The RVs overlap and the realizations of two adjacent RVs can permute: it is possible that the realization of the (n + 1)th zero precedes that of the zero.
The associated value with the value follows the realization of an associated RV with the Gaussian RV whose average is and whose standard deviation increases very slowly and is very roughly equal to for . The Gaussian RVs are independent:
.
The imaginary value of of the non-trivial zero is on average:
The error is:. See Figure 9.
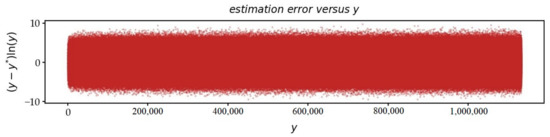
Figure 9.
Scatter plot versus . Errors become smaller and smaller as a function of .
Figure 10 shows a sequence of zeros, on the transformed axis, with the regularly spaced .
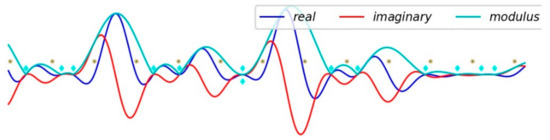
Figure 10.
The 2-layer model: in the middle of the figure, two zeros () and are very close ( ), one late, the other early, respectively. The random realization of these two zeros almost falls on , which may seem a paradox, since it is for this value ⅛, on this anamorphosed axis, that the probability of occurrence is the lowest to get a zero.
When is large, the formula becomes:
We undoubtedly find the similarity with the formula of the prime number theorem of Hadamard and La Vallée Poussin (1896): .
3.3. The Heteroscedasticity of Gaussian RVs
Figure 11 shows the adjustment of the variation of the standard deviation, calculated by an estimate on a sliding neighborhood of 1000 zeros. After a rapid increase in the first values, there is a slow increase in the variance. The experimental law is: .
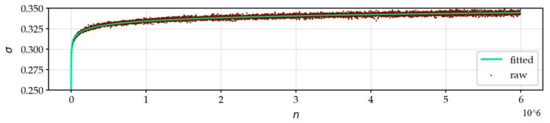
Figure 11.
Adjustment of the variation of the standard deviation according to .
3.4. The Equivalence Relation on the CL
The zeros of the real and imaginary parts of are close to the pivots and :
The alternating and regular setting to zero of the real and imaginary parts of the function on the CL in the neighborhoods of the pivot values for the real part and for the imaginary part, are at the origin of the production of the nth zero of the function, a zero which this time is common to both real and imaginary parts. These pivot values are not exactly the points of nullity for which a precise expression is later calculated. However, at pivotal values, there is the relation:
On the CL, there is a relationship between the real and imaginary parts of the function:
This relation (demonstrated later in Section 3.6.2) is only valid on the CL, and takes into account an angle related to the fractional part of the ordinate , which allows us to anchor the common zeros of these two components in an equivalence relation, :
The two alternately zero surfaces of period 1 on the anamorphic axis of the ordinate of the complex plane locally generate an additional common zero which is the nth non-trivial zero. For a non-trivial zero, the ratio becomes , and Hospital’s rule applies in :
This equivalence relation in , where the classes are intervals of length 1 (Figure 12), for the segments characterizes the silhouettes of the function on the CL, profiles which extend into the CS, and which allow us to estimate the maxima of in this CS. When one takes into account the raw values of the axis in , the equivalence relation is more difficult to manipulate and the underlying RVs are more convoluted. The -space distribution model removes the statistical bias caused by the strict axis support that hides the true mechanisms of the function.
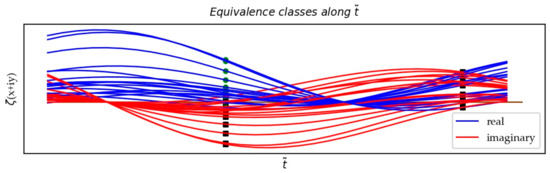
Figure 12.
The equivalence relation: a few segments of the curve (real and imaginary parts) along a few intervals of the anamorphic CL. The real (resp. imaginary) parts almost cancel each other out for the values , (resp. ). We almost also verified (resp. ) for the values .
3.5. The Continuous Catalog of Fold Appearances of the Function in the CS
The stochastic process contributes to characterizing the local function landscapes. The classification of the function conformations simply takes its source in the effective “random” distribution of the zeros. The key to determining taxonomy is the value of the probability density of the nearby zero (Figure 13). We can thus extract some canonical patterns, at the origin of the production of a non-trivial zero, although the catalog of these patterns constitutes a continuous spectrum. These different families of patterns show more or less regular and more or less high wave configurations, according to the standard pattern: the higher the value of the probability density of a zero is, the more regular the neighboring undulations will be; the lower the value of the probability density of a zero is, the more irregular the nearby waves will be, in particular with weak waves and a strong wave which will appear in the vicinity (Figure 14). When the probability is very low, one can identify a particular archetype consisting of a rogue wave surrounded by dead calm. More frequently, the occurrence of small distances between two consecutive zeros arises with a similar configuration of the function: it is a high wave of the real part, located upstream or downstream, accompanied by wavelets of the real and the imaginary parts which graze the zero level of the plane : the corrugated sheet of both surfaces in the CS also gives rise to a kind of dead calm, any homothety of the Riemann functional equation apart.
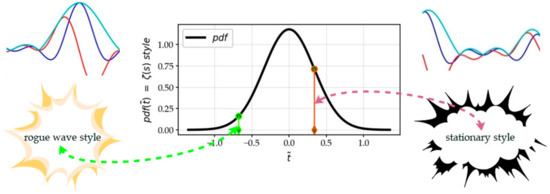
Figure 13.
Classification of the local behavior styles of the zeta function according to the value of the pdf of the local zero realization. Local styles of the zeta function (real, imaginary and module) are shown: rogue wave style on the left; stationary style on the right.
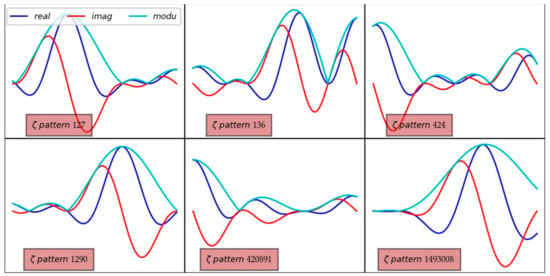
Figure 14.
Six different patterns depending on the pdf of the zero linked to the segment .
3.6. The Structural Characters of and from the Functional Equation
In this paragraph, we develop the function in the power series, by taking advantage of the power series expansion of the Gamma function. This operation uses the fact that is very small compared to . The calculations are geometrically interpreted in order to identify the structural features of the and functions which are expressed by this functional equation.
In the CS, the function is a composition of elementary geometric functions: a homothety and four rotations , and a series remainder function in :
The homothety is a function of and the four rotations are functions of . The remainder is the only factor that mixes the two coordinates and . The homothety plays its role of amplification in the region and contraction in the region. The four rotations, two of which are pure and the other two are digressive, that is to say a little falsified, ensure the functional equation between and .
On the CL, the homothety is neutral and only the first three rotations are effective: the function ensures the relation between and its conjugate, via a rotation of the angle , within an order of accuracy of :
3.6.1. The Functional Equation in the CS
The functional relationship is written:
The power series of the Gamma function is:
are the Bernoulli numbers.
In the CS, we can then develop the function in series, assuming :
When the point is on the CL, the expression is simplified:
The serial expansion of is interpreted as a function composed of a homothety and four rotations, the first two being pure rotations.
- The homothety supports the effect of the power of the terms of the function, with the symmetry at . The CL is a neutral element of the homothety.
- The rotation comes from the offset of the real surface which is, in probability, above the imaginary surface, due to the imbalance of the first term of the series of . This rotation restores, on average, the two surfaces to the same level.
- The major rotation erases the sinuousness of the function. This rotation, dependent on , shears by continuous torsions, in order to make the undulations disappear.
- The rotation is numerically and graphically barely perceptible. It is impure because the series contains higher order terms which alter the rotation. This rotation has a decisive influence in the genesis of the zeros of the two surfaces, and consequently in the materialization of non-trivial zeros.
- The impure rotation is not perceptible on the CL. It has an intrinsic role in the CS, because it is the impurity of this digressive rotation which breaks the symmetry at the level of each term of the series in and which does not make it possible to manufacture the two pairs of zeros () outside the CL (for and ).
The third and fourth rotations are impure (or digressive) rotations: the symmetry in and is thus not respected by the series from the term in in the CS, except on the CL, which geometrically explains the RH.
3.6.2. The Functional Equation on the CL
In this paragraph, we show, using the properties of the functional equation, that the real and imaginary curves of the function regularly and alternately cancel each other out, thanks to which nearly instantiates in two perfect sinusoids on the CL. It is this alternation that generates a non-trivial zero in a restricted interval. On the CL, the calculations are extremely simplified:
By multiplying by if is not a zero:
If is zero, Hospital’s rule gives:
The non-trivial zeros are at the breaking point of the two functions and .
Using the power series expansion of , we serially expand to find :
We can therefore extract the rotation from this expansion:
We can deduce an approximate value of on the CL:
The functional equation on the CL does not represent a pure rotation, but this equation allows to define an equivalence relation, within the order of . With this equivalence relation, the CL is a concatenation of equivalence class instantiations of unit length along the anamorphic axis .
Now, we will be able to determine the alternating zeros of the real and imaginary curves, by taking advantage of this evaluation via an approximate calculation of the derivative.
3.6.3. The Zeros of the Real and Imaginary Parts of the Function
In this paragraph, we perform the calculations assuming the approximation: .
On the CL, we can calculate the derivative of at constant , as a function of :
The values of for which cancel each other out for the real part (resp. the imaginary part), correspond to the values for which (resp. ). They coincide with the values close to (resp. ), that is to say the values , (resp. ).
We assume in the calculations: .
Case where
It follows then that:
To improve the estimation of such that , we must take into account the derivative of . Hence, we can calculate the difference with the pivot value :
The approximate value of for which has a null imaginary value is therefore:
Case where
It follows then that:
Case where
It follows that:
Case where
It follows that:
3.7. The Consecutive Zeros on the CL
Figure 15a shows the rather asymmetrical histogram of the raw distances between two consecutive zeros from . The tail of the histogram has not been represented for values greater than : these are some large differences of the first zeros (). Figure 15b represents the scatterplot of these distances along the ordinate. We observe that these distances, on average, tend to decrease with , and we understand from this figure that the raw axis is not the most appropriate variable to study the statistics of gaps between zeros. It is preferable to analyze the population of the gaps between zeros, after anamorphosis, along the axis.
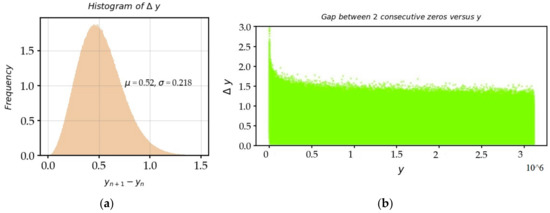
Figure 15.
(a) Histogram of the gaps between two consecutive zeros, calculated on the raw axis, . Indeed, the first is an outlier at 6.887; (b) the scatterplot of the gaps between two zeros as a function of the ordinate.
Figure 16a,b show the graphs, after the transformation of the axis into the axis. We greatly reduced the influence of the bias of the use of the variable . There is only a slight asymmetry, which can be interpreted as follows. We selected the zeros in the order of appearance on the axis, so that the difference between and is always positive, as is the difference . It goes without saying that there are possible underlying permutations between the indices and . If there was a way to identify these permutations of indices of consecutive zeros, especially when the zeros are relatively close, the gaps between some adjacent zeros could be negative, and in this case, the left part of the histogram would have a branch which would overflow towards negative values, still with mean 1. We would then obtain a much more symmetrical and Gaussian histogram.
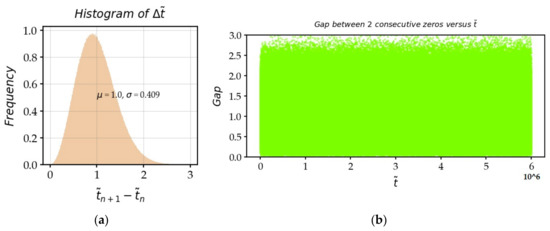
Figure 16.
(a) Histogram of the gaps between two consecutive zeros calculated on the anamorphic axis; and (b) scatterplot of the gaps between two zeros as a function of the anamorphic ordinate .
The model expresses it clearly. The difference between two independent mixed RVs and is a new Gaussian RV of parameters . We can calculate the average distance between two consecutive zeros :
We can get, for , an estimation of the drift of extreme values of as a function of :
The passage from to makes it possible to better compare the differences in the list of non-trivial zeros from : some adjacent zeros are very close or far apart from each other (Figure 17).
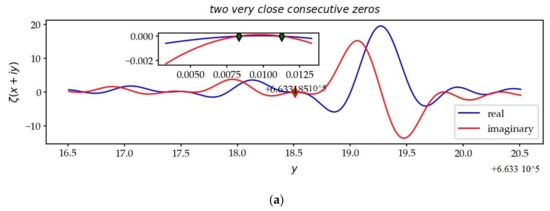
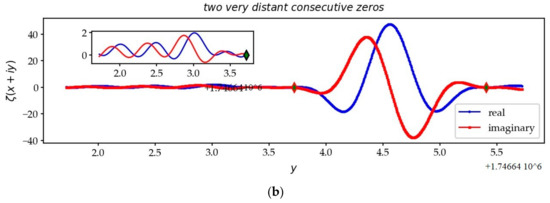
Figure 17.
Two very close zeros (a) and two very distant zeros (b). On the CL, the curves have configurations where the undulations are very weak, in the vicinity of a very large fold.
This is the case, without being exhaustive, in Table 4, for the following pairs of zeros.
Table 4.
(a) List of near consecutive zeros; and (b) the list of distant consecutive zeros.
3.8. The Multiplicity of Zeros
It follows from the numerical value of the standard deviation of the Gaussian RVs that the multiplicity of zeros is achievable thanks to the constant mixing of the close RVs and that the possibility of this configuration increases with the value of . It could be at the maximum of order 3 when : it would then be necessary that the th zero arrives late, the th arrives in advance, and that in addition, the th also occurs very early. This scenario never appears in the first few million zeros and its probability is also very low:
The possibility of a double root is more likely, although it is known that, among the trillion zeros calculated, no double roots have yet been identified. The probability is , for , knowing that the nearest zeros on are distant from . We know [15] that between the and the (n + 1)th, the gap is . Notwithstanding, the probability () for this rare event is “quite large”.
Hadamard’s product formula, dynamically interpreted via geometric analysis, provides a better understanding of the possibility of the multiple root phenomenon. We know that if is a simple root , is not null. Both members of Hadamard’s formula equilibrate by the term , present in the second member:
We study, below, the configuration of the function when two zeros are very close. We know that when the real part (resp. the imaginary part) of the derivative of is null, the imaginary part (resp. the real part) of the function is located on a local extremum:
on a local extremum for the curve on the axis.
on a local extremum for the curve on the axis.
We observe on the graphs (Figure 18), that for a double root to exist, it would be necessary that (both real and imaginary parts) be tangent to the CL . We would then be dealing with an extremum (local maximum or minimum) of the function for the two curves. We would therefore have in this case . If there is such a double root, the behavior of the two members of Hadamard’s formula is changed. In the rest of this paragraph, it is no longer assumed that the zeros are all on the CL. We recall that if is a zero of the CS, then are also zeros. Now, we examine the geometric configuration of two different zeros belonging to two neighboring quartets if they are both in the CS, in two pairs if they are both on the CL, or in a quartet and a duet if they are one in the CS and the other on the CL.
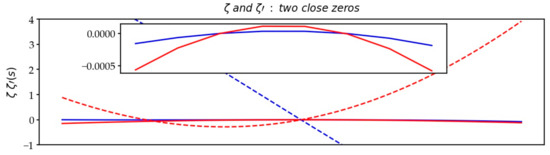
Figure 18.
Plot for two near zeros: function (solid lines) and derivative (dotted lines).
It is assumed that the points and of indices and are roots with very close coordinates and . We choose the point with coordinates in the middle of the segment : . The Hadamard formula applied to point becomes:
being the middle, we obtain: . The second member becomes a function of which takes finite real and imaginary values of :
The function is holomorphic; we can write at point :
The derived function is holomorphic; we can write at point :
In the configuration of close zeros, and . It follows that:
When and converge, the midpoint also converges and we obtain:
It goes without saying that if , we extend the expansion until we find a non-zero derivative , which is always feasible since the function is not uniformly null. In conclusion, the first member takes an infinite complex value, while the second member is finite, which justifies that the double root configuration is impossible. The holomorphic property that is included in Taylor’s formula accounts for the neighborhood very close to zero. It is essentially the analysis of the local extrema of the function in relation to the behavior of the derivative, i.e., the observation of the zeros of the derivative of the real and imaginary parts that triggers the justification.
3.9. The Approximation Formulas of the Extremes of and of the kth Order Moments on the CL
By efficiently using the relation , it is easier to numerically estimate the curves of the maxima on the CL, and to derive results from them in the CS. In addition, the maxima, being rare events, it is advisable to carry out a rotation of the function, in order to make the three surfaces (real, imaginary and modulus) of the function be at the same level, and to make the estimation of extremes more robust. The regular sampling of the function from , and not a regular sampling from , also allows us to calculate with better accuracy the kth-order moments of the function. We find the following formulas from the sample data:
Figure 19 shows the fitting of the maxima modulus of the zeta function:
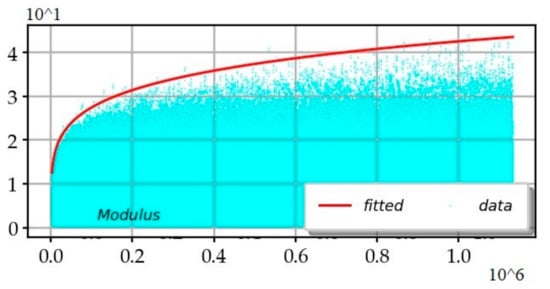
Figure 19.
Adjusted curve (in red) of the maximum of the modulus of the zeta function and data (in cyan) of the moduli of the values of the zeta moduli.
- Order 1 moment:
- Order 2 moment:
- Order 3 moment:
- Order 4 moment: .
Table 5 shows the estimations for higher even moments from 6 to 12.
Table 5.
for to 6.
Figure 20 shows the fitting of the first power moments. and the numerical values of the coefficients for the higher moments are significant for the Lindelöf conjecture which is equivalent to the statement: .
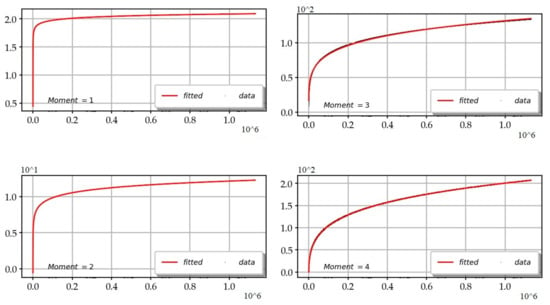
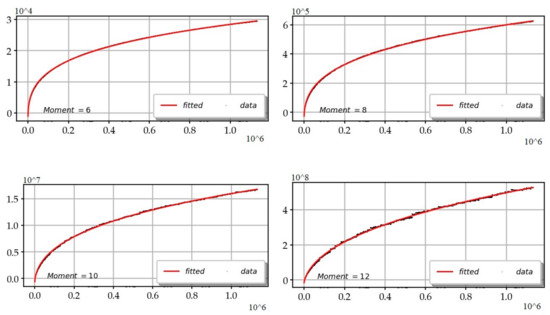
Figure 20.
Raw curves and theoretical fittings of the moments .
4. Discussion
4.1. The Rank (Position) of a Particular Zero and the Number of Zeros below a Threshold
On the distribution of zeros, the model answers two distinct questions:
- Finding the rank (position) of a particular zero in the sequence . Knowing a zero on the CL, what is the estimate of the order number of this zero? After processing the set of the first zeros, we found a law in order to estimate the rank of zero in the ordered sequence : .
- Finding . Given a value , what is the number of zeros less than ? The answer to this classic question on the Riemann function requires, according to the traditional formula, to compute the argument of .
This complementary term is easy to explain thanks to the model (Figure 21). Indeed, the argument (the phase of the complex number), on the transformed CL, is a sawtooth function, piecewise quasi-linear, whose value has been calculated by the model to the nearest , and whose indeterminacy can be removed if we obtain , the signs of . The almost linear aspect is within . On a interval of length 1, starting at ⅛, the argument is almost zero (in fact, ), then decreases, then goes back up by a jump of when a new zero is emerging, and finally decreases in order to rejoin the value. On this unit segment, there is the probable appearance of a new zero and the complementary term thus increases by 1. The break and the jump take place at the location of a non-trivial zero, hence the formula for the number of zeros . Unfortunately, there is sometimes an untimely earlier or later stall when the probability on a non-trivial zero is low and this zero is then far from the mean and outside the interval . Therefore, cannot account for this eccentric stall and there is then a local error on the estimated value. This situation happens around the following first zeros: .
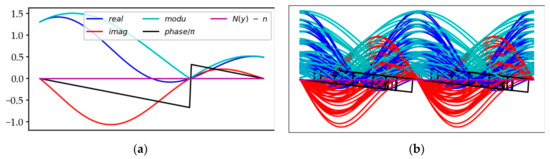
Figure 21.
(a) A segment of starting at ⅛ showing the break of the term at the zero location; (b) 50 plots of : we observe the properties of 2 adjacent equivalence classes.
The similarity between both general formulas therefore appears:
Knowing which is only dependent of and knowing in which quadrant is located , we can infer the last term :
4.2. Heteroscedasticity and the Evolution of the Hierarchical Model According to
The RVs are uniformly distributed along the axis , of mathematical expectation , and of slowly increasing standard deviation:
with for small : .
The difference between the minimum and maximum probability densities is of the order of:
The Gaussian RV is experimentally truncated at : . For , the numerical value of the standard deviation on the transformed axis allows the overlapping of two consecutive RVs on each interval . Thus, with the extension to in of the RV , the RVs and overlap and some realizations of two consecutive RVs are switched. The zero can lie in one of the three intervals . Therefore, it is possible that zeros can be ahead (in the interval , in of cases), that zeros are late (in the interval in of case), but in general ( of cases) the zeros are “on time” in the interval .
With such standard deviations for the RV, it often happens, including for small (for example ), that both the (n − 1)th and nth zeros or the nth and (n + 1)th zeros are in the same interval . The model then facilitates the calculation of the number of zeros less than a value with a possible error of . In this distribution model, the RVs are considered as independent. It is thus possible (and this happens theoretically in of cases for ) that the RV is located before the RV . Thus, the (n + 1)th zero attached to RV arrives ahead and the nth zero attached to the RV arrives late, so much so that a permutation in the arrival orders, to which the zeros in question are linked, is possible. With this assumption of independence of RVs , the (n + 1)th zero attached to the RV is in fact the nth according to the order of arrival on the axis. However, this assumption of independence does not identify where these permutations take place. Knowledge should be extracted from an additional phenomenon, resulting from the morphogenesis of the function, in order to pinpoint the permutations. In the absence of additional knowledge of the mechanism which produces zeros, we can avoid the obstacle of permutations in the arrival order, and be satisfied by considering a simpler interpretation: the RVs are Gaussian and all pairwise independent, except two successive Gaussian RVs and , which are dependent with the constraint . With this parameterization, the order of arrival is always compatible with the number of the RV .
When is very large , the Gaussian RV spreads more widely, so that the mixing of RVs becomes more and more frequent. The th zero might lie within the interval of zeros, and we would need to consider more than two consecutive RVs to be greater or smaller than the value of the previous RV. Any permutations are then more challenging to interpret.
4.3. The Limits of the Model
It is crucial to determine the limits of a theoretical model. The current model was inferred from values of . We cannot claim to generalize this model beyond this value without making some hypotheses or assumptions which must be justified. If the model seems robust in its architecture, we can discuss the legitimacy of the use of the full normal distribution, the independence of adjacent RVs and the heteroscedasticity of the sequence of normal laws, which proceeds from a more fragile induction. Calculations towards on a segment are essential to finally being able to confirm these properties.
4.3.1. Questioning the Legitimacy of Statistics: Observation versus Genesis
The second layer of the model implements RVs. However, the origin of zeros is concealed under experimental observation through a statistical filter. Needless to say, the successive zeros of the CL do not obey the morphogenetic assumptions of a random distribution, since the function is deterministic. The occurrence of a zero is generated by the nullity coincidence of both members of the infinite sum of trigonometric functions , and this simultaneity is not due to chance. The Laplace–Gauss law is one of the foundations of statistics, based on the law of large numbers summarizing the work of Laplace [25], Čebyšëv [26] and Paul Lévy [27]. Statistics which focus more on the analysis of the RV’s average behavior, rather than on rare events, should be used with caution when considering the extremes of mathematical functions. RVs are assumed to be independent, but the local layout is no accident (Figure 22). The Poisson model [28], which is the basis for the analysis of series of independent observations, is therefore not a suitable model for the appearance of zeros, because of the undeniable local dependence of the various sub-series of adjacent zeros.
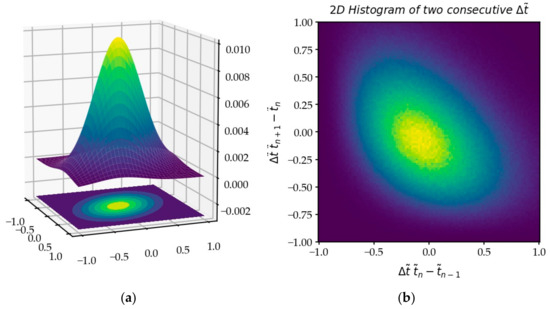
Figure 22.
(a) Gaussian 2D distribution; (b) the 2D histogram of successive increments is not fully a Gaussian distribution (see the upper right part): and are dependent: .
If we accept the systematic dependence of two successive RVs , the process can even be considered as Markovian since: , with the constraint .
4.3.2. Questioning a Normal Distribution or a Normal Distribution Truncated to
If the use of a normal distribution over an infinite interval is improper, then the normal distribution must be reduced to a truncated Gaussian distribution , again is it necessary to determine the value of the coefficient of the maximum spacing . According to the theory, the function erf admits that there should be, by probability, a 1 in 2 million chance of finding a zero beyond , which is not realized for , but this estimate must be weighted by the fact that evolves in this interval. The most extreme zero is for : it deviates by , if we consider that locally .
4.3.3. Questioning the Arrangement of Zeros According to, or Not, the Natural Order of Appearance on the Imaginary Axis
If we fully accept the model of the normal law, we must recognize that this law, which extends from to , will allow, undoubtedly, for very large values of , disturbing the configuration of some zeros’ sequences: for example, a zero could then be placed at the number , following the natural order, since a very low probability exists, that a zero reaches beyond the interval , for example. In this hypothesis of pure normal law, the natural order of appearance is an arbitrary order: it is then necessary to revise the concept of numbering of non-trivial zeros, and to deduce the consequences on the morphogenesis of the function and perhaps even the effects on the order or arrangement of prime numbers. However, it must be remembered that the continuous values of the function do not come from a random draw, and that therefore, if the zero is disturbed in its positioning, it is clear that the neighboring zeros are also concerned in a way that should be explored.
4.3.4. Questioning Rare Events and the Emergence of Rogue Waves
In order to analyze the extreme behaviors of the function in the CS, we can use the statistical modeling of rare events, while knowing that the statistical approach is delicate (Figure 23). Only variables derived from the function which can be assimilated to the observation of small variations in a natural phenomenon can be the subject of such an examination. An analysis of the growth of the standard deviation of the RV along , based on the law of large numbers, allows us to obtain a law of evolution. For the study of maxima, it is more reasonable to use the results of the extreme value theory of Fisher and Tippett [29], which states that, under certain conditions, the distribution of the extremes (minima and maxima) of a large number of independent and identically distributed (i.i.d.) RVs converge to one of the following three distributions (Gumbel [30], Fréchet [31], Weibull [32]): the parametric generalized extreme value (GEV) distribution family is used here. The analysis of the rare values on the minima and maxima of the local standard deviations of the variations in the appearance of zeros, estimated on 10,000 successive samples, gives some lessons, without the underlying assumptions of the statistical theories being likely to be made in default.
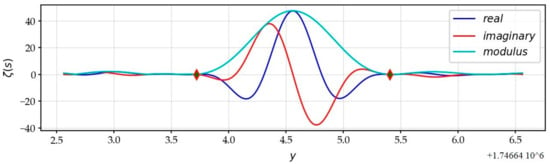
Figure 23.
Rogue wave, with very flat waves around: and .
4.4. Model Adherences
4.4.1. The Resemblance with Čebyšëv’s First Function
Čebyšëv’s first function is given by: prime.
We know several bounds for this function, for example:
The three-term asymptotic expansion of the Lambert function is as tends to :
The connection between the heteroscedasticity of normal distributions and the evolution of the distribution of prime numbers is immediate: .
We deduce for the primorial de :
4.4.2. The Rapprochement with the Erdös–Kac Theorem
Probabilistic number theory explicitly uses probabilities to state results on the distribution of properties of natural numbers. being the number of prime factors distinct from a non-zero natural number , we know the Hardy–Ramanujan theorem [33]: “The normal order of the number of prime factors distinct from a number is ”. We also know the more precise Erdös–Kac theorem [34]: .
This theorem expresses that the number of prime
factors distinct from a natural number for tends to a normal distribution with mean and variance as tends to infinity. When running the Eratosthenes sieve to identify prime numbers, which are checked only once, is the number of scores of each natural number. This number is maximum for primorials
(). Thus, we can generate the numbers with prime numbers which follow a more or less bell-shaped histogram: 3 on average, very often (2, 4), less frequently (1, 5), more rarely (6, 7) and only one occurrence for 8: . For example:
power of a prime number, :
primorial, :
To generate all the natural numbers , there is an economy principle with the parsimonious use of prime numbers drawn from the elements of the base . As increases, it is necessary to give more and more flexibility in this number of prime numbers of the corresponding base. The cardinal of the subset needs to increase. It seems natural to compare both the evolution of the mean of and that of the standard deviation in the of the RV . The RV needs more flexibility to sweep a larger subset.
4.4.3. The Similarity with the Twin Prime Issue
Twin prime pairs are two prime numbers [35] that differ only by 2. According to the twin primes conjecture, there is an infinity of twin primes and . The occurrence of twin primes can also be related to the Gaussian RV heteroscedasticity. The higher the standard deviation of the normal distribution, the more the prime numbers have the possibility of sweeping a wider range, so much so that two consecutive primes can be joined. Again, to formulate a theory, it might be daring to break away from the natural order of the emergence of prime numbers.
4.5. Pros and Cons of the Model and Numerical Applications
Finally, the model brings theoretical and practical advantages and disadvantages for computational applications:
- This offers an easy way to calculate the numerical value for the seed of the zero: the pivot is indeed very close to the result.
- The passage through the Fourier transform is clearly improved since the zeta function in the space is quasi-periodic, with period 1. It is a fairly regular corrugated sheet and the local Fourier coefficients are then crystallized on a few frequencies, thanks to the resemblance and the correspondence between the Gaussian pdf of a local zero and the local morphology of the zeta function.
- The model has the drawback of being statistical.
- It does not provide answers on questions about the ordering and the numbering of these zeros: it is necessary to deepen the morphological engine of the zeta function and the genesis of the folds of this function.
- The model is valid over a large interval , but must be validated for much higher values.
5. Conclusions
The article analyzes numerically the global and local distribution of the non-trivial zeros of Riemann’s zeta function along the CL of the complex plane. The behavior of the function in the CS (in fact, its analytical extension, since the function diverges in the CS) is governed in particular by the fractional part of the variable .
The non-trivial zeros on obey the partition of the variable as follows:
This article shows that the zeros are distributed on the CL according to a two-layered hierarchical model .
The first, deterministic layer defines two pivots and , linked to the zero, close to the cancellation of the imaginary and real parts of the function, and involves the Lambert function, via an anamorphosis : .
is the main branch of the Lambert function: .
The pivot turns out to be a good estimate of the ordinate of the zero:
An asymptotic estimate for the zero of rank , is .
The second, stochastic layer precisely allocates the zeros and involves a sequence of RVs . To express the features of the RVs , it is wiser to work in the anamorphic plane . In this space , after a change of variable from to , the distribution of zeros along the transformed CL follows the realization of a stochastic process of independent Gaussian RVs, regularly spaced: . The location of the nth zero then obeys the probabilistic formula being the realization of the nth RV , of probability density:
The model shows that, along the CL, the realizations of adjacent normal distributions overlap, causing irregularities in places, so that the order of neighboring zeros can be swapped. In addition, the distributions undergo a slow heteroscedasticity since the standard deviation of the distributions increases in .
The model makes it possible to calculate the respective zeros of the real and imaginary parts:
The model reveals the direct relation between the two components on the whole CL :
This two-layer distribution model helps to deduce the known results or to specify laws already studied in the literature:
- The sequence number of zero is: , the error is , according to the probabilities , when .
- The law of the number of zeros : . The last term depends on , i.e., on which quadrant is .
- The law of the differences of the ordinates of consecutive zeros is a law, associated with the normal law . The mean is valued:We use here the natural order of zeros, that is to say that we admit, in this formula, the dependence between two consecutive RVs ().
- The common law of the maximum of the absolute value of in its real and imaginary components, and in absolute value:The rotation of restores the balance between the two components.
- The moments :
- The moments :
The model also makes it possible to spot a family of local profiles of the function on the CL, around the RVs, according to the realization of the neighboring Gaussian RV. This family can be extended to the entire CS, thanks to the homothety of the morphologies of the function in the CS. If the value deviates a little from the mean of the RV , the function profile is regular around this neighborhood: the real and imaginary waves are almost stationary with sinusoids of similar amplitudes. On the other hand, if the value is significantly different from the mean of the RV , a “rogue wave” emerges, in the vicinity of the value , worthy of the Roaring Forties, which contributes to the development of local maxima of on the CL and in the CS (for ). This very high wave is then accompanied by waves of tiny amplitudes, in dead calm, which cause the emergence of close consecutive zeros.
Finally, the hierarchical model allows us to explain the absence of multiple roots, by dissecting Hadamard’s product formula, with two close zeros.
The numerical study of the Gaussian RV . must be continued, in particular the slow evolution of its heteroscedasticity, which must be validated for high values of . Indeed, the very slow growth of the standard deviation would be a major property of the second layer of the model, which would reflect the local disorder of non-trivial zeros, notably in their distributions for very low probability densities () of , analyzable by the theory of extremes, and in relation to the distribution of prime numbers for very high values.
The function contains secrets that we can unravel through new analysis grids. The digital way offers to openly illustrate drafts of research. In this article, the Lambert function, by its elongation, reveals the uniform description of folds of the Zeta function along the transformed imaginary axis and the normal distribution locally distributes the zeros around regularly spaced pivots. Lambert’s unfolding standardizes the global aspect of the Zeta function in equivalent paradigms of length 1, but the stress relief of Gauss’s law, along ,
expresses a progressive degree of freedom of the local position of the zeros, thanks to the increasing standard deviation in
, most certainly, in relation with the Erdös–Kac theorem and with the maximum elasticity (perceptible on twin prime numbers) of the distribution of prime numbers for very high values of .
Funding
This research received no external funding.
Informed Consent Statement
Not Applicable.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request. The data are not publicly available due to the fact that these data are the result of calculations carried out by a wide range of specific application programs, in Python language.
Acknowledgments
C Fagard-Jenkin, student of mathematics at St Andrews University, acted as an initial proofreader before submission.
Conflicts of Interest
The author declares no conflict of interest.
References
- Riemann, B. Über die Anzahl der Primzahlen unter Einer Gegebenen Größe. Ges. Math. Werke und Wissenschaftlicher Nachlaß 1859, 2, 145–155. [Google Scholar]
- Lambert, J.H. Observationes Variae in Mathesin Puram. Acta Helv. Phys. Math. Anat. Bot. Med. 1758, 3, 128–168. [Google Scholar]
- Hadamard, J. Sur les zéros de la fonction de Riemann. Comptes Rendus de l’Académie Sci. Paris 1896, 122, 1470–1473. [Google Scholar]
- De la Vallée Poussin, C.-J. Sur la fonction de Riemann et le nombre des nombres premiers inférieurs à une limite donnée. Sci. Lett. Beaux-Arts Belg. 1899, 49, 74. [Google Scholar]
- Gram, J.-P. Note sur les zéros de la fonction de Riemann. Acta Math. 1903, 27, 289–304. [Google Scholar] [CrossRef]
- Landau, E. Über die Nullstellen der Zeta-funktion. Math. Ann. 1912, 71, 548–564. [Google Scholar] [CrossRef]
- Hardy, G.H. Sur les zéros de la fonction de Riemann. C. R. Acad. Sci. Paris 1914, 158, 1012–1014. [Google Scholar]
- Littlewood, J.E. On the zeros of the Riemann zeta-function. Proc. Camb. Philos. Soc. 1924, 22, 295–318. [Google Scholar] [CrossRef]
- Levinson, N. More than one third of zeros of Riemann’s zeta-function are on σ = ½. Adv. Math. 1974, 13, 383–436. [Google Scholar]
- Conrey, J.B. More than two fifths of the zeros of the Riemann zeta function are on the critical line. J. Reine Angew. Math. 1989, 399, 1–26. [Google Scholar]
- Hardy, G.H.; Littlewood, J.E. The zeros of Riemann’s zeta function on the critical line. Math. Z. 1921, 10, 283–317. [Google Scholar] [CrossRef]
- Atkinson, F.V. The mean value of the zeta-function on the critical line. Proc. Lond. Math. Soc. 1941, 47, 174–200. [Google Scholar]
- Ingham, A.E. On the estimation of N(σ,T). Quart. J. Math. 1940, 11, 291–292. [Google Scholar] [CrossRef]
- Odlyzko, A. Tables of Zeros of the Riemann Zeta Function. 2002. Available online: http://www.dtc.umn.edu/~odlyzko/zeta_tables/index.html (accessed on 11 December 2020).
- Gourdon, X. The 1013 First Zeros of the Riemann Zeta Function, and Zeros Computation at Very Large Height. 2004. Available online: http://numbers.computation.free.fr/Constants/Miscellaneous/zetazeros1e13-1e24.pdf (accessed on 11 December 2020).
- Titchmarsh, E.C. The theory of the Riemann Zeta-Function, 1st ed.; Oxford Univ. Press: Oxford, UK, 1951; p. 346. [Google Scholar]
- Ivić, A. The Riemann Zeta-Function. The Theory of the Riemann Zeta-Function with Applications; John Wiley & Sons: New York, NY, USA, 1985; 517p. [Google Scholar]
- Selberg, A. On the zeros of Riemann’s zeta-function. Skr. Norske Vid. Akad. Oslo I 1942, 10, 1–59. [Google Scholar]
- Backlund, R.J. Sur les zéros de la fonction de Riemann. C. R. Acad. Sci. Paris 1914, 158, 1979–1981. [Google Scholar]
- Karatsuba, A.A. On the zeros of the Riemann zeta-function on short intervals of the critical line. Sov. Math. Dokl. 1983, 28, 533–535. [Google Scholar]
- Feng, S.; Wu, X. On gaps between zeros of the Riemann zeta-function. J. Number Theory 2012, 132, 1385–1397. [Google Scholar] [CrossRef][Green Version]
- Montgomery, H.L. The pair correlation of zeros of the zeta function. In Analytic Number Theory (Proc. Symp. Pure Math., Vol. 24); American Mathematical Society: Providence, RI, USA, 1973; pp. 181–193. [Google Scholar]
- Conrey, J.B.; Ghosh, A. A conjecture for the sixth power moment of the Riemann zeta function. In Proceedings of the Amalfi Conference on Analytic Number Theory, Maiori, Italy, 25–29 September 1989; pp. 35–59. [Google Scholar]
- Conrey, J.B.; Gonek, S.M. High moments of the Riemann zeta-function. Duke Math. J. 2001, 107, 577–604. [Google Scholar] [CrossRef]
- Laplace, P.S. Théorie Analytique des Probabilités; Œuvre Tome VII; Courcier: Paris, France, 1820; ISBN 978-2-87647-161-0. [Google Scholar]
- Čebyšëv, P.L. Mémoire sur les nombres premiers. J. Math. Pures Appl. 1852, 17, 366–390. [Google Scholar]
- Lévy, P. Théorie de L’addition des Variables Aléatoires; Gauthier-Villars: Paris, France, 1937; ISBN 978-2-87647-207-5. [Google Scholar]
- Poisson, S.D. Recherches sur la Probabilité des Jugements en Matière Criminelle et en Matière Civile, Précédée des Règles Générales du Calcul des Probabilités; Bachelier: Paris, France, 1837. [Google Scholar]
- Fisher, R.A.; Tippett, L.H.C. Limiting forms of the frequency distribution of the largest or smallest member of a sample. Proc. Camb. Philos. Soc. 1928, 24, 180–190. [Google Scholar] [CrossRef]
- Gumbel, E.J. Statistics of Extremes; Columbia University Press: New York, NY, USA, 1958. [Google Scholar]
- Fréchet, M. Sur la loi de probabilité de l’écart maximum. Ann. Soc. Polonaise Math. 1927, 6, 92–116. [Google Scholar]
- Weibull, W. A statistical distribution of wide applicability. J. Appl. Mech. 1951, 18, 293–297. [Google Scholar]
- Hardy, G.H.; Ramanujan, S. The normal number of prime factors of a number n. Quart. J. Math. 1917, 48, 76–92. [Google Scholar]
- Erdős, P.; Kac, M. The Gaussian law of errors in the theory of additive functions. Proc. Natl. Acad. Sci. USA 1939, 25, 206–207. [Google Scholar] [CrossRef] [PubMed]
- Korevaar, J. Prime pairs and the zeta function. J. Approx. Theory 2009, 158, 69–96. [Google Scholar] [CrossRef][Green Version]

























Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).