Deep Learning for Facial Beauty Prediction


Abstract
1. Introduction
- We propose a network for the facial beauty prediction (FBP) problem. Specifically, residual-in-residual (RIR) groups are designed for building a deeper network. To devise a better gradient transmission flow, multi-level skip connections are introduced.
- To find the inherent correlations among features, a joint spatial-wise and channel-wise attention mechanism is introduced for better feature comprehension.
- Experimental results demonstrate our network can achieve a better performance than other CNN-based methods and make the assessment more consistent with human opinion.
2. Related Works
2.1. Facial Beauty Prediction
2.2. Convolutional Neural Networks
3. Method
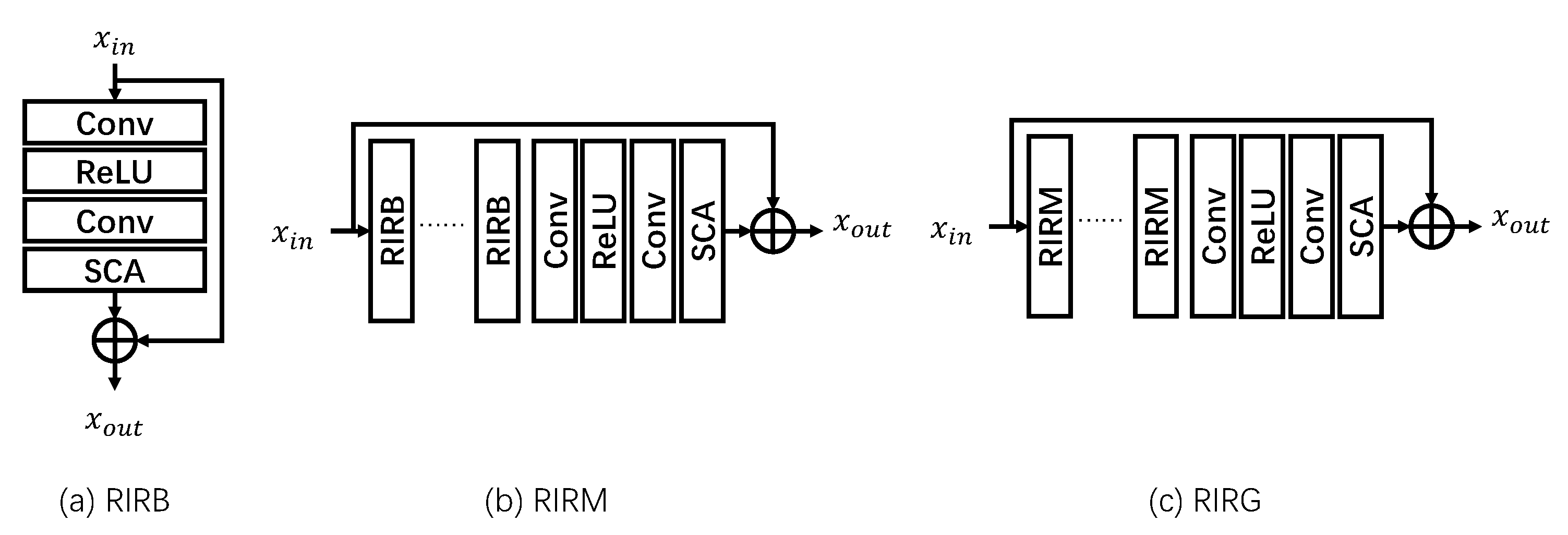
3.1. Residual-In-Residual Group
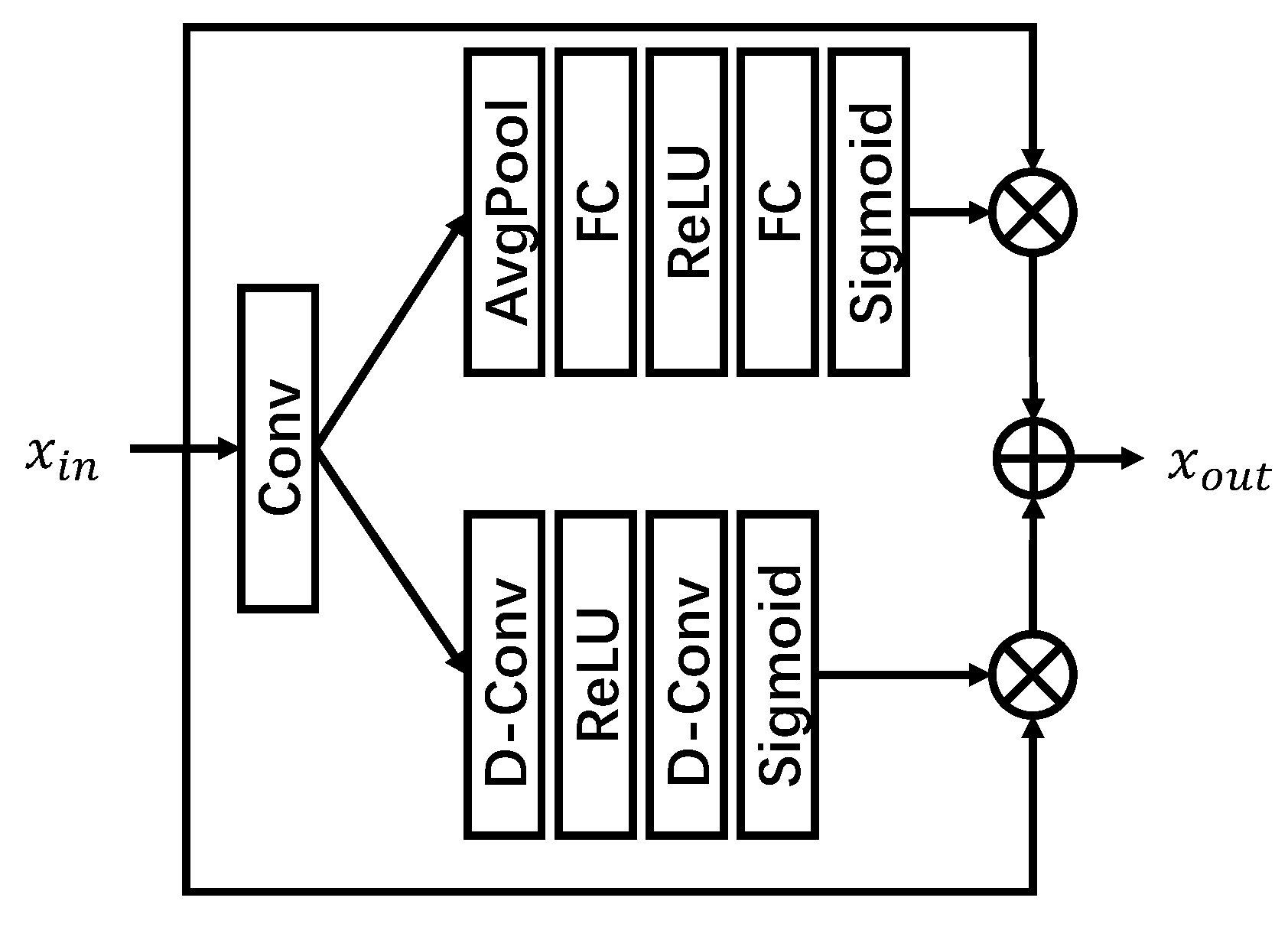
3.2. Spatial-Wise and Channel-Wise Attention
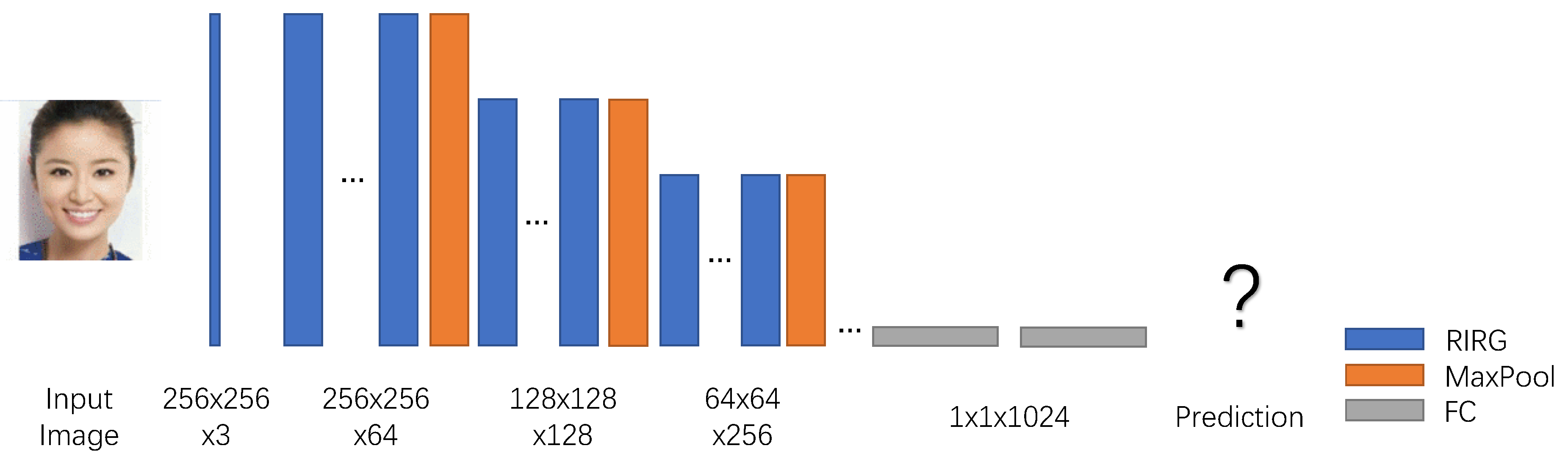
3.3. Network Design
4. Experiment
4.1. Results
4.2. Ablation Study
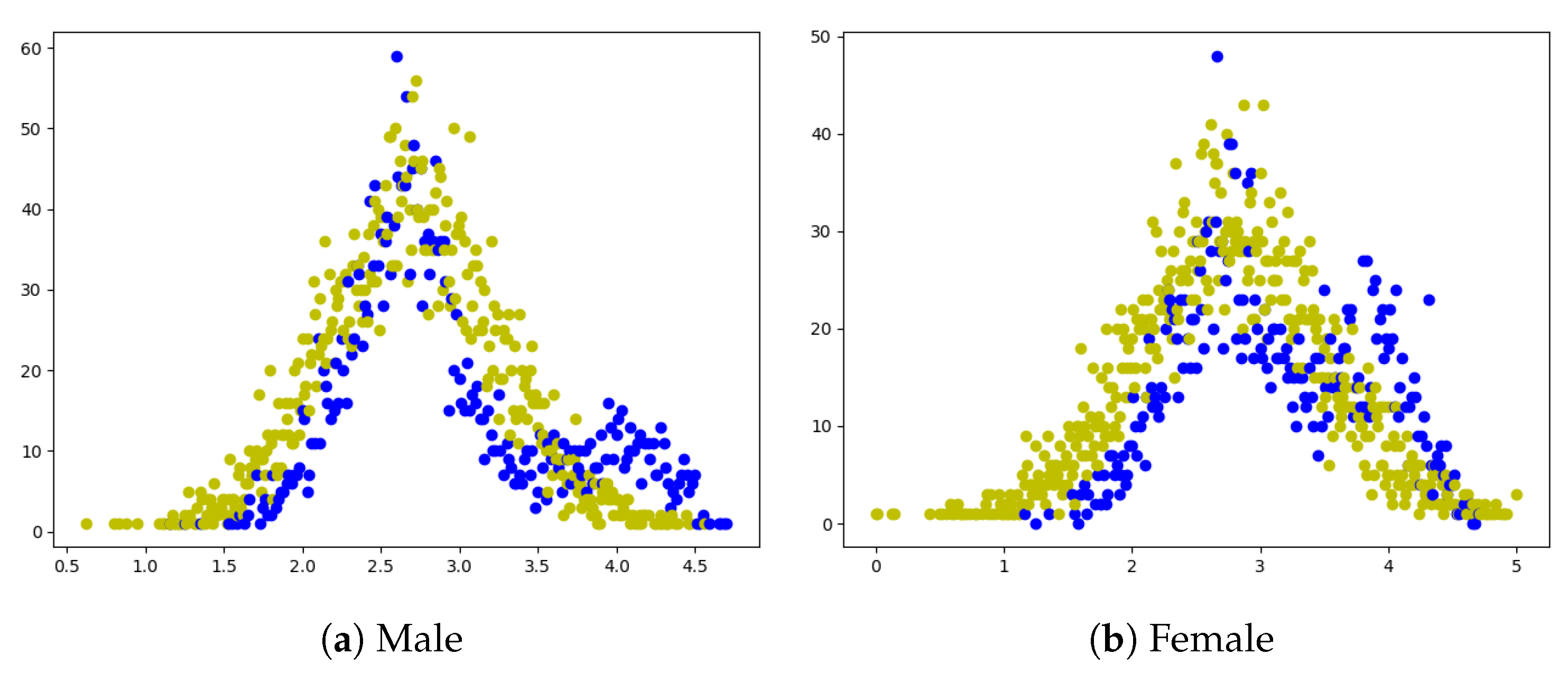
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gan, J.; Jiang, K.; Tan, H.; He, G. Facial Beauty Prediction Based on Lighted Deep Convolution Neural Network with Feature Extraction Strengthened. Chin. J. Electron. 2020, 29, 312–321. [Google Scholar] [CrossRef]
- Gan, J.; Zhai, Y.; Wang, B. Unconstrained Facial Beauty Prediction Based on Multi-scale K-Means. Chin. J. Electron. 2017, 26, 548–556. [Google Scholar] [CrossRef]
- Gunes, H.; Piccardi, M.; Jan, T. Comparative beauty classification for pre-surgery planning. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; Volume 3, pp. 2168–2174. [Google Scholar]
- Wassermann, S.; Seufert, M.; Casas, P.; Gang, L.; Li, K. Let me Decrypt your Beauty: Real-time Prediction of Video Resolution and Bitrate for Encrypted Video Streaming. In Proceedings of the 2019 Network Traffic Measurement and Analysis Conference (TMA), Paris, France, 19–21 June 2019; pp. 199–200. [Google Scholar]
- Workman, S.; Souvenir, R.; Jacobs, N. Understanding and Mapping Natural Beauty. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5590–5599. [Google Scholar]
- Chen, F.; Xiao, X.; Zhang, D. Data-Driven Facial Beauty Analysis: Prediction, Retrieval and Manipulation. IEEE Trans. Affect. Comput. 2018, 9, 205–216. [Google Scholar] [CrossRef]
- Shi, S.; Gao, F.; Meng, X.; Xu, X.; Zhu, J. Improving Facial Attractiveness Prediction via Co-attention Learning. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4045–4049. [Google Scholar]
- Gan, J.; Xiang, L.; Zhai, Y.; Mai, C.; He, G.; Zeng, J.; Bai, Z.; Donida Labati, R.; Piuri, V.; Scotti, F. 2M BeautyNet: Facial Beauty Prediction Based on Multi-Task Transfer Learning. IEEE Access 2020, 8, 20245–20256. [Google Scholar] [CrossRef]
- Liang, L.; Lin, L.; Jin, L.; Xie, D.; Li, M. SCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1598–1603. [Google Scholar]
- Yu, Z.; Raschka, S. Looking Back to Lower-Level Information in Few-Shot Learning. Information 2020, 11, 345. [Google Scholar] [CrossRef]
- Gibson, J.; Oh, H. Mutual Information Loss in Pyramidal Image Processing. Information 2020, 11, 322. [Google Scholar] [CrossRef]
- Susilo, B.; Sari, R. Intrusion Detection in IoT Networks Using Deep Learning Algorithm. Information 2020, 11, 279. [Google Scholar] [CrossRef]
- Zhang, Y.; Ding, W.; Liu, C. Summary of Convolutional Neural Network Compression Technology. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019; pp. 480–483. [Google Scholar]
- Devi, N.; Borah, B. Cascaded pooling for Convolutional Neural Networks. In Proceedings of the 2018 Fourteenth International Conference on Information Processing (ICINPRO), Bangalore, India, 21–23 December 2018; pp. 1–5. [Google Scholar]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. Facial Expression Recognition Based on Random Forest and Convolutional Neural Network. Information 2019, 10, 375. [Google Scholar] [CrossRef]
- Almakky, I.; Palade, V.; Ruiz-Garcia, A. Deep Convolutional Neural Networks for Text Localisation in Figures From Biomedical Literature. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–5. [Google Scholar]
- Wan, S.; Gong, C.; Zhong, P.; Pan, S.; Li, G.; Yang, J. Hyperspectral Image Classification With Context-Aware Dynamic Graph Convolutional Network. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Lou, G.; Shi, H. Face image recognition based on convolutional neural network. China Commun. 2020, 17, 117–124. [Google Scholar] [CrossRef]
- Stephen, O.; Maduh, U.J.; Ibrokhimov, S.; Hui, K.L.; Abdulhakim Al-Absi, A.; Sain, M. A Multiple-Loss Dual-Output Convolutional Neural Network for Fashion Class Classification. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 17–20 February 2019; pp. 408–412. [Google Scholar]
- Yu, D.; Sun, S. A Systematic Exploration of Deep Neural Networks for EDA-Based Emotion Recognition. Information 2020, 11, 212. [Google Scholar] [CrossRef]
- Xiang, Z.; Dong, X.; Li, Y.; Yu, F.; Xu, X.; Wu, H. Bimodal Emotion Recognition Model for Minnan Songs. Information 2020, 11, 145. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, Z.; Morimoto, Y. Attention-Based SeriesNet: An Attention-Based Hybrid Neural Network Model for Conditional Time Series Forecasting. Information 2020, 11, 305. [Google Scholar] [CrossRef]
- Nascimento, J.C.; Carneiro, G. One shot segmentation: Unifying rigid detection and non-rigid segmentation using elastic regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2019; pp. 510–519. [Google Scholar]
- Wang, H.; Su, D.; Liu, C.; Jin, L.; Sun, X.; Peng, X. Deformable Non-Local Network for Video Super-Resolution. IEEE Access 2019, 7, 177734–177744. [Google Scholar] [CrossRef]
- Lin, K.; Jia, C.; Zhao, Z.; Wang, L.; Wang, S.; Ma, S.; Gao, W. Residual in Residual Based Convolutional Neural Network In-loop Filter for AVS3. In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; pp. 1–5. [Google Scholar]
- Xie, W.; Zhang, J.; Lu, Z.; Cao, M.; Zhao, Y. Non-Local Nested Residual Attention Network for Stereo Image Super-Resolution. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2643–2647. [Google Scholar]
- Okaishi, W.A.; Zaarzne, A.; Slimani, I.; Atouf, I.; Benrabh, M. A Traffic Surveillance System in Real-Time to Detect and Classify Vehicles by Using Convolutional Neural Network. In Proceedings of the 2019 International Conference on Systems of Collaboration Big Data, Internet of Things Security (SysCoBIoTS), Casablanca, Morocco, 12–13 December 2019; pp. 1–5. [Google Scholar]
- Pak, J.; Kim, M. Convolutional Neural Network Approach for Aircraft Noise Detection. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 430–434. [Google Scholar]
- Lu, S.; Feng, J.; Wu, J. A Time Weight Convolutional Neural Network for Positioning Internal Detector. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 4666–4669. [Google Scholar]
- Sun, G.; Wang, Y.; Sun, C. Fault Diagnosis of Planetary Gearbox Based on Signal Denoising and Convolutional Neural Network. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Paris), Paris, France, 2–5 May 2019; pp. 96–99. [Google Scholar]
- Lee, K.; Chae, S.; Park, H. Optimal Time-Window Derivation for Human-Activity Recognition Based on Convolutional Neural Networks of Repeated Rehabilitation Motions. In Proceedings of the 2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019; pp. 583–586. [Google Scholar]
- Guha, S.R.; Haque, S.R. Convolutional Neural Network Based Skin Lesion Analysis for Classifying Melanoma. In Proceedings of the 2019 International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 24–25 December 2019; pp. 1–5. [Google Scholar]
- Alani, A. Arabic Handwritten Digit Recognition Based on Restricted Boltzmann Machine and Convolutional Neural Networks. Information 2017, 8, 142. [Google Scholar] [CrossRef]
- Yu, Y.; Lin, H.; Meng, J.; Wei, X.; Zhao, Z. Assembling Deep Neural Networks for Medical Compound Figure Detection. Information 2017, 8, 91. [Google Scholar] [CrossRef]
- Peng, M.; Wang, C.; Chen, T.; Liu, G. NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification. Information 2016, 7, 61. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Lin, L.; Liang, L.; Jin, L. Regression Guided by Relative Ranking Using Convolutional Neural Network (R3CNN) for Facial Beauty Prediction. IEEE Trans. Affect. Comput. 2019, 1. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PC↑ | MAE↓ | RMSE↓ | Square Deviation↓ |
| LR [9] | 0.5948 | 0.4289 ± 1.50 | 0.5531 | 2.25 |
| GR [9] | 0.6738 | 0.3914 ± 1.42 | 0.5085 | 2.03 |
| SVR [9] | 0.6668 | 0.3898 ± 1.41 | 0.5152 | 1.99 |
| AlexNet [24] | 0.8298 | 0.2938 ± 1.23 | 0.3819 | 1.53 |
| ResNet-18 [26] | 0.8513 | 0.2818 ± 1.21 | 0.3703 | 1.48 |
| ResNeXt-50 [27] | 0.8777 | 0.2518 ± 1.20 | 0.3325 | 1.45 |
| Ours | 0.8780 | 0.2517 ± 0.65 | 0.3320 | 0.43 |
| PC↑ | 1 | 2 | 3 | 4 | 5 | Avg |
| AlexNet [24] | 0.8667 | 0.8645 | 0.8615 | 0.8678 | 0.8566 | 0.8634 |
| RCNN [45] | 0.8873 | 0.8741 | 0.8856 | 0.8906 | 0.8779 | 0.8831 |
| ResNet [26] | 0.8847 | 0.8792 | 0.8929 | 0.8932 | 0.9004 | 0.8900 |
| ResNeXt [27] | 0.8985 | 0.8932 | 0.9016 | 0.8990 | 0.9064 | 0.8997 |
| Ours | 0.8990 | 0.8939 | 0.9020 | 0.8999 | 0.9067 | 0.9003 |
| MAE↓ | 1 | 2 | 3 | 4 | 5 | Avg |
| AlexNet [24] | 0.2633 | 0.2605 | 0.2681 | 0.2609 | 0.2728 | 0.2651 |
| RCNN [45] | 0.2436 | 0.2456 | 0.2428 | 0.2409 | 0.2451 | 0.2436 |
| ResNet [26] | 0.2480 | 0.2459 | 0.2430 | 0.2383 | 0.2383 | 0.2419 |
| ResNeXt [27] | 0.2306 | 0.2285 | 0.2260 | 0.2349 | 0.2258 | 0.2291 |
| Ours | 0.2300 | 0.2284 | 0.2257 | 0.2345 | 0.2251 | 0.2287 |
| RMSE↓ | 1 | 2 | 3 | 4 | 5 | Avg |
| AlexNet [24] | 0.3408 | 0.3449 | 0.3583 | 0.3438 | 0.3576 | 0.3481 |
| RCNN [45] | 0.3155 | 0.3328 | 0.3227 | 0.3140 | 0.3294 | 0.3229 |
| ResNet [26] | 0.3258 | 0.3286 | 0.3184 | 0.3107 | 0.2994 | 0.3166 |
| ResNeXt [27] | 0.3025 | 0.3084 | 0.3016 | 0.3044 | 0.2918 | 0.3017 |
| Ours | 0.3020 | 0.3081 | 0.3013 | 0.3039 | 0.2916 | 0.3014 |
| Square Deviation↓ | 1 | 2 | 3 | 4 | 5 | Avg |
| AlexNet [24] | 1.5203 | 1.5255 | 1.5304 | 1.5225 | 1.5809 | 1.5359 |
| ResNet [26] | 1.4703 | 1.4731 | 1.4809 | 1.4720 | 1.4850 | 1.4762 |
| ResNeXt [27] | 1.4495 | 1.4506 | 1.4552 | 1.4533 | 1.4580 | 1.4533 |
| Ours | 1.4308 | 1.4350 | 1.4401 | 1.4420 | 1.4500 | 1.4395 |
| Method | PC↑ | MAE↓ | RMSE↓ |
|---|---|---|---|
| 0.8780 | 0.2517 | 0.3320 | |
| 0.8491 | 0.2905 | 0.3755 | |
| 0.8480 | 0.2892 | 0.3749 | |
| 0.8301 | 0.2929 | 0.3800 |
| SCA | PC↑ | MAE↓ | RMSE↓ |
|---|---|---|---|
| w | 0.8780 | 0.2517 | 0.3320 |
| w/o | 0.8778 | 0.2525 | 0.3322 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, K.; Choi, K.-n.; Jung, H.; Duan, L. Deep Learning for Facial Beauty Prediction. Information 2020, 11, 391. https://doi.org/10.3390/info11080391
Cao K, Choi K-n, Jung H, Duan L. Deep Learning for Facial Beauty Prediction. Information. 2020; 11(8):391. https://doi.org/10.3390/info11080391
Chicago/Turabian StyleCao, Kerang, Kwang-nam Choi, Hoekyung Jung, and Lini Duan. 2020. "Deep Learning for Facial Beauty Prediction" Information 11, no. 8: 391. https://doi.org/10.3390/info11080391
APA StyleCao, K., Choi, K.-n., Jung, H., & Duan, L. (2020). Deep Learning for Facial Beauty Prediction. Information, 11(8), 391. https://doi.org/10.3390/info11080391