Big Picture on Privacy Enhancing Technologies in e-Health: A Holistic Personal Privacy Workflow


Abstract
:1. Introduction
- The definition of a holistic ’big picture’ of the personal privacy workflow in context of health care
- A broad state-of-the-art analysis of technologies for each sub-sector of the personal privacy workflow which is relevant for health data
- Highlighting open research gaps in existing approaches motivating future research opportunities
2. Related Work
3. Personal Privacy Workflow
4. Controller Environment
4.1. Access Control
4.2. Privacy Language
4.3. Accountability
4.4. Privacy-Preserving Processing
Inference Detection and Prevention
5. User Environment
5.1. Preference Language
5.2. Preference User Interfaces
6. C2C Environment
6.1. Technical and Organisational Measures
6.2. Data Subject Rights
6.3. Trading
6.4. Multi-Party Privacy
7. Discussion and Future Research Directions
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Arcelus, A.; Jones, M.H.; Goubran, R.; Knoefel, F. Integration of Smart Home Technologies in a Health Monitoring System for the Elderly. In Proceedings of the 21st International Conference on Advanced Information Networking and Applications Workshops (AINAW’07), Niagara Fa-lls, ON, Canada, 21–23 May 2007; Volume 2, pp. 820–825. [Google Scholar]
- Parliament, E.; The Council of the European Union. General Data Protection Regulation, 2016. Regulation (EU) 2016 of the European Parliament and of the Council of on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC. OJ L 2016, 119. [Google Scholar]
- Epidemiology Working Group for NCIP Epidemic Response, Chinese Center for Disease Control and Prevention. The Epidemiological Characteristics of an Outbreak of 2019 Novel Coronavirus Diseases (COVID-19) in China. Zhonghua Liu Xing Bing Xue Za Zhi 2020, 41, 145. [Google Scholar]
- World Health Organization. Coronavirus Disease (COVID-19) Situation Report—135; Technical Report; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Berke, A.; Bakker, M.; Vepakomma, P.; Raskar, R.; Larson, K.; Pentland, A. Assessing disease exposure risk with location histories and protecting privacy: A cryptographic approach in response to a global pandemic. arXiv 2020, arXiv:2003.14412. [Google Scholar]
- Wu, Y.C.; Chen, C.S.; Chan, Y.J. The outbreak of COVID-19: An overview. J. Chin. Med Assoc. 2020, 83, 217. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Protocol for Assessment of Potential Risk Factors for Coronavirus Disease 2019 (COVID-19) among Health Workers in a Health Care Setting, 23 March 2020; Technical Report; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Wu, Z.; McGoogan, J.M. Characteristics of and important lessons from the coronavirus disease 2019 (COVID-19) outbreak in China: Summary of a report of 72 314 cases from the Chinese Center for Disease Control and Prevention. JAMA 2020, 323, 1239–1242. [Google Scholar] [CrossRef] [PubMed]
- Allam, Z.; Jones, D.S. On the coronavirus (COVID-19) outbreak and the smart city network: Universal data sharing standards coupled with artificial intelligence (AI) to benefit urban health monitoring and management. In Healthcare; Multidisciplinary Digital Publishing Institute: Basel, Switzerland, 2020; Volume 8, p. 46. [Google Scholar]
- Li, J.; Guo, X. COVID-19 Contact-tracing Apps: A Survey on the Global Deployment and Challenges. arXiv 2020, arXiv:2005.03599. [Google Scholar]
- Annas, G.J. HIPAA regulations-a new era of medical-record privacy? N. Engl. J. Med. 2003, 348, 1486–1490. [Google Scholar] [CrossRef] [Green Version]
- Jaigirdar, F.T.; Rudolph, C.; Bain, C. Can I Trust the Data I See? A Physician’s Concern on Medical Data in IoT Health Architectures. In Proceedings of the Australasian Computer Science Week Multiconference (ACSW 2019), Sydney, NSW, Australia, 29–31 January 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Dilmaghani, S.; Brust, M.R.; Danoy, G.; Cassagnes, N.; Pecero, J.; Bouvry, P. Privacy and Security of Big Data in AI Systems: A Research and Standards Perspective. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 5737–5743. [Google Scholar]
- Taeihagh, A.; Lim, H.S.M. Governing autonomous vehicles: Emerging responses for safety, liability, privacy, cybersecurity, and industry risks. Transp. Rev. 2019, 39, 103–128. [Google Scholar] [CrossRef] [Green Version]
- Lowry, P.B.; Dinev, T.; Willison, R. Why security and privacy research lies at the centre of the information systems (IS) artefact: Proposing a bold research agenda. Eur. J. Inf. Syst. 2017, 26, 546–563. [Google Scholar] [CrossRef]
- Xiao, Z.; Xiao, Y. Security and Privacy in Cloud Computing. IEEE Commun. Surv. Tutor. 2013, 15, 843–859. [Google Scholar] [CrossRef]
- Henze, M.; Inaba, R.; Fink, I.B.; Ziegeldorf, J.H. Privacy-Preserving Comparison of Cloud Exposure Induced by Mobile Apps. In Proceedings of the 14th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services (MobiQuitous 2017), Melbourne, Australia, 7–10 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 543–544. [Google Scholar] [CrossRef]
- Dahlmanns, M.; Dax, C.; Matzutt, R.; Pennekamp, J.; Hiller, J.; Wehrle, K. Privacy-Preserving Remote Knowledge System. In Proceedings of the 2019 IEEE 27th International Conference on Network Protocols (ICNP), Chicago, IL, USA, 8–10 October 2019; pp. 1–2. [Google Scholar]
- Hathaliya, J.J.; Tanwar, S. An exhaustive survey on security and privacy issues in Healthcare 4.0. Comput. Commun. 2020, 153, 311–335. [Google Scholar] [CrossRef]
- Iqridar Newaz, A.; Sikder, A.K.; Ashiqur Rahman, M.; Selcuk Uluagac, A. A Survey on Security and Privacy Issues in Modern Healthcare Systems: Attacks and Defenses. arXiv 2020, arXiv:2005.07359. [Google Scholar]
- El Majdoubi, D.; El Bakkali, H. Towards a Holistic Privacy Preserving Approach in a Smart City Environment. In Innovations in Smart Cities Applications, 3rd ed.; Ben Ahmed, M., Boudhir, A.A., Santos, D., El Aroussi, M., Karas, İ.R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 947–960. [Google Scholar]
- Deep, S.; Zheng, X.; Jolfaei, A.; Yu, D.; Ostovari, P.; Kashif Bashir, A. A survey of security and privacy issues in the Internet of Things from the layered context. Trans. Emerg. Telecommun. Technol. 2020, e3935. [Google Scholar] [CrossRef] [Green Version]
- Ferrag, M.A.; Shu, L.; Yang, X.; Derhab, A.; Maglaras, L. Security and Privacy for Green IoT-Based Agriculture: Review, Blockchain Solutions, and Challenges. IEEE Access 2020, 8, 32031–32053. [Google Scholar] [CrossRef]
- Weixiong, Y.; Lee, R.; Seng, A.K.S.; tuz Zahra, F. Security and Privacy Concerns in Wireless Networks—A Survey. TechRxiv 2020. [Google Scholar] [CrossRef]
- Linden, T.; Khandelwal, R.; Harkous, H.; Fawaz, K. The Privacy Policy Landscape After the GDPR. Proc. Priv. Enhancing Technol. 2020, 2020, 47–64. [Google Scholar] [CrossRef] [Green Version]
- Ebert, N.; Ackermann, K.A.; Heinrich, P. Does Context in Privacy Communication Really Matter? A Survey on Consumer Concerns and Preferences. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20), Island of Oahu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–11. [Google Scholar] [CrossRef]
- Esmaeilzadeh, P. The effect of the privacy policy of Health Information Exchange (HIE) on patients’ information disclosure intention. Comput. Secur. 2020, 95, 101819. [Google Scholar] [CrossRef]
- Johnson, G.A.; Shriver, S.K.; Du, S. Consumer Privacy Choice in Online Advertising: Who Opts Out and at What Cost to Industry? Mark. Sci. 2020, 39, 33–51. [Google Scholar] [CrossRef]
- Leicht, J.; Heisel, M. A Survey on Privacy Policy Languages: Expressiveness Concerning Data Protection Regulations. In Proceedings of the 12th CMI Conference on Cybersecurity and Privacy (CMI), Copenhagen, Denmark, 28–29 November 2019; pp. 1–6. [Google Scholar]
- Kumaraguru, P.; Cranor, L.; Lobo, J.; Calo, S. A Survey of Privacy Policy Languages. In Workshop on Usable IT Security Management (USM ’07) at Symposium On Usable Privacy and Security ’07; ACM: New York, NY, USA, 2007. [Google Scholar]
- Kasem-Madani, S.; Meier, M. Security and Privacy Policy Languages: A Survey, Categorization and Gap Identification. arXiv 2015, arXiv:1512.00201. [Google Scholar]
- Morel, V.; Pardo, R. Three Dimensions of Privacy Policies. arXiv 2019, arXiv:1908.06814. [Google Scholar]
- Gerl, A.; Meier, B. Privacy in the Future of Integrated Health Care Services—Are Privacy Languages the Key? In Proceedings of the 2019 International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Barcelona, Spain, 21–23 October 2019; pp. 312–317. [Google Scholar]
- Ding, D.; Cooper, R.A.; Pasquina, P.F.; Fici-Pasquina, L. Sensor technology for smart homes. Maturitas 2011, 69, 131–136. [Google Scholar] [CrossRef] [PubMed]
- Walter, M.; Eilebrecht, B.; Wartzek, T.; Leonhardt, S. The Smart Car Seat: Personalized Monitoring of Vital Signs in Automotive Applications. Pers. Ubiquitous Comput. 2011, 15, 707–715. [Google Scholar] [CrossRef]
- Wu, Q.; Sum, K.; Nathan-Roberts, D. How Fitness Trackers Facilitate Health Behavior Change. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2016, 60, 1068–1072. [Google Scholar] [CrossRef]
- Kayes, A.S.M.; Kalaria, R.; Sarker, I.; Islam, M.; Watters, P.; Ng, A.; Hammoudeh, M.; Badsha, S.; Kumara, I. A Survey of Context-Aware Access Control Mechanisms for Cloud and Fog Networks: Taxonomy and Open Research Issues. Sensors 2020, 20, 2464. [Google Scholar] [CrossRef] [PubMed]
- Sandhu, R.S.; Coyne, E.J.; Feinstein, H.L.; Youman, C.E. Role-Based Access Control Models. Computer 1996, 29, 38–47. [Google Scholar] [CrossRef] [Green Version]
- Motta, G.H.M.B.; Furuie, S.S. A contextual role-based access control authorization model for electronic patient record. IEEE Trans. Inf. Technol. Biomed. 2003, 7, 202–207. [Google Scholar] [CrossRef]
- Wang, L.; Wijesekera, D.; Jajodia, S. A Logic-Based Framework for Attribute Based Access Control. In Proceedings of the 2004 ACM Workshop on Formal Methods in Security Engineering (FMSE ’04), Washington, DC, USA, 25–29 October 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 45–55. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zheng, D.; Deng, R.H. Security and Privacy in Smart Health: Efficient Policy-Hiding Attribute-Based Access Control. IEEE Internet Things J. 2018, 5, 2130–2145. [Google Scholar] [CrossRef]
- Kayes, A.S.M.; Han, J.; Colman, A. ICAF: A Context-Aware Framework for Access Control. In Australasian Conference on Information Security and Privacy; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef] [Green Version]
- Kayes, A.S.M.; Han, J.; Colman, A.; Islam, M. RelBOSS: A Relationship-Aware Access Control Framework for Software Services; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef] [Green Version]
- Kayes, A.S.M.; Rahayu, W.; Dillon, T.; Chang, E.; Han, J. Context-Aware Access Control with Imprecise Context Characterization Through a Combined Fuzzy Logic and Ontology-Based Approach. In OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”; Springer: Berlin/Heidelberg, Germany, 2017; pp. 132–153. [Google Scholar] [CrossRef]
- Kayes, A.S.M.; Rahayu, W.; Watters, P.; Alazab, M.; Dillon, T.; Chang, E. Achieving security scalability and flexibility using Fog-Based Context-Aware Access Control. Future Gener. Comput. Syst. 2020, 107. [Google Scholar] [CrossRef]
- Kayes, A.S.M.; Rahayu, W.; Dillon, T.; Chang, E. Accessing Data from Multiple Sources Through Context-Aware Access Control. In Proceedings of the 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018. [Google Scholar] [CrossRef]
- Damianou, N.; Dulay, N.; Lupu, E.; Sloman, M. The Ponder Policy Specification Language. In Proceedings of the International Workshop on Policies for Distributed Systems and Networks (POLICY ’01), Bristol, UK, 29–31 January 2001; Springer: London, UK, 2001; pp. 18–38. [Google Scholar]
- Kagal, L. Rei: APolicy Language for the Me-Centric Project; Technical Report; HP Labs: Palo Alto, CA, USA, 2002. [Google Scholar]
- Becker, M.; Fournet, C.; Gordon, A. SecPAL: Design and semantics of a decentralized authorization language. J. Comput. Secur. 2010, 18, 619–665. [Google Scholar] [CrossRef] [Green Version]
- Rissanen, E.; Bill Parducci, H.L. eXtensible Access Control Markup Language (XACML) Version 3.0; Technical Report; OASIS: Burlington, MA, USA, 2013. [Google Scholar]
- Ardagna, C.; Bussard, L.; De Capitani Di Vimercati, S.; Neven, G.; Pedrini, E.; Paraboschi, S.; Preiss, F.; Samarati, P.; Trabelsi, S.; Verdicchio, M.; et al. Primelife policy language. In W3C Workshop on Access Control Application Scenarios; W3C: Cambridge, MA, USA, 2009. [Google Scholar]
- Wenning, R.; Schunter, M.; Cranor, L.; Dobbs, B.; Egelman, S.; Hogben, G.; Humphrey, J.; Langheinrich, M.; Marchiori, M.; Presler-Marshall, M.; et al. The Platform for Privacy Preferences 1.1 (P3P1.1) Specification; Technical Report; W3C: Cambridge, MA, USA, 2006. [Google Scholar]
- Bohrer, K.; Holland, B. Customer Profile Exchange (CPExchange) Specification; Version 1.0; OASIS: Burlington, MA, USA, 2000. [Google Scholar]
- Cranor, L.; Langheinrich, M.; Marchiori, M. A P3P Preference Exchange Language 1.0 (APPEL1.0); Technical Report; W3C: Cambridge, MA, USA, 2002. [Google Scholar]
- Agrawal, R.; Kiernan, J.; Srikant, R.; Xu, Y. XPref: A preference language for P3P. Comput. Netw. 2005, 48, 809–827. [Google Scholar] [CrossRef]
- Yu, T.; Li, N.; Antón, A.I. A Formal Semantics for P3P. In Proceedings of the 2004 Workshop on Secure Web Service (SWS ’04), Fairfax, VA, USA, 29 October 2004; ACM: New York, NY, USA, 2004; pp. 1–8. [Google Scholar] [CrossRef]
- Ashley, P.; Hada, S.; Karjoth, G.; Powers, C.; Schunter, M. Enterprice Privacy Authorization Language (EPAL 1.2); Technical Report; IBM: Armonk, NY, USA, 2003; Available online: https://www.w3.org/Submission/2003/SUBM-EPAL-20031110/ (accessed on 2 June 2020).
- Iyilade, J.; Vassileva, J. P2U: A Privacy Policy Specification Language for Secondary Data Sharing and Usage. In IEEE Security and Privacy Workshops; Technical Report; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Bonatti, P.A.; Kirrane, S.; Petrova, I.; Schlehahn, E.; Sauro, L. Deliverable D2.1-Policy Language V1; Technical Report; Scalable Policy-Aware Linked Data Architecture for Privacy, Transparency and Compliance-SPECIAL; Zenodo: Geneva, Switzerland, 2017. [Google Scholar]
- Gerl, A.; Bennani, N.; Kosch, H.; Brunie, L. LPL, Towards a GDPR-Compliant Privacy Language: Formal Definition and Usage. In Transactions on Large-Scale Databases and Knowledge-Centered Systems (TLDKS); Lecture Notes in Computer Science (LNCS) 10940; Springer: Berlin/Heidelberg, Germany, 2018; Chapter 2; pp. 1–40. [Google Scholar] [CrossRef]
- Benghabrit, W.; Grall, H.; Royer, J.C.; Sellami, M.; Azraoui, M.; Elkhiyaoui, K.; Önen, M.; De Oliveira, A.S.; Bernsmed, K. A Cloud Accountability Policy Representation Framework. In Proceedings of the 4th International Conference on Cloud Computing and Services Science (CLOSER 2014), Barcelona, Spain, 3–5 April 2014; SCITEPRESS-Science and Technology Publications, Lda: Setubal, Portugal, 2014; pp. 489–498. [Google Scholar] [CrossRef] [Green Version]
- Azraoui, M.; Elkhiyaoui, K.; Önen, M.; Bernsmed, K.; De Oliveira, A.S.; Sendor, J. A-PPL: An Accountability Policy Language. In Data Privacy Management, Autonomous Spontaneous Security, and Security Assurance: 9th International Workshop, DPM 2014, 7th International Workshop, SETOP 2014, and 3rd International Workshop, QASA 2014, Wroclaw, Poland, 10–11 September 2014. Revised Selected Papers; Springer International Publishing: Cham, Switzerland, 2015; pp. 319–326. [Google Scholar] [CrossRef]
- Camilo, J. Blockchain-based consent manager for GDPR compliance. In Open Identity Summit 2019; Roßnagel, H., Wagner, S., Hühnlein, D., Eds.; Gesellschaft für Informatik: Bonn, Germany, 2019; pp. 165–170. [Google Scholar]
- Dorri, A.; Kanhere, S.S.; Jurdak, R.; Gauravaram, P. Blockchain for IoT security and privacy: The case study of a smart home. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 618–623. [Google Scholar]
- Angraal, S.; Krumholz, H.M.; Schulz, W.L. Blockchain Technology. Circ. Cardiovasc. Qual. Outcomes 2017, 10, e003800. [Google Scholar] [CrossRef]
- Sicherman, G.L.; De Jonge, W.; Van de Riet, R.P. Answering Queries Without Revealing Secrets. ACM Trans. Database Syst. 1983, 8, 41–59. [Google Scholar] [CrossRef]
- Biskup, J.; Bonatti, P.A. Lying versus refusal for known potential secrets. Data Knowl. Eng. 2001, 38, 199–222. [Google Scholar] [CrossRef]
- Biskup, J.; Bonatti, P. Controlled query evaluation for enforcing confidentiality in complete information systems. Int. J. Inf. Secur. 2004, 3, 14–27. [Google Scholar] [CrossRef]
- Biskup, J.; Bonatti, P.A. Controlled Query Evaluation for Known Policies by Combining Lying and Refusal. Ann. Math. Artif. Intell. 2004, 40, 37–62. [Google Scholar] [CrossRef]
- Biskup, J.; Bonatti, P. Controlled query evaluation with open queries for a decidable relational submodel. Ann. Math. Artif. Intell. 2007, 50, 39–77. [Google Scholar] [CrossRef]
- Sweeney, L. k-Anonymity: A model for protecting privacy. Int. J. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C. Differential Privacy. In Automata, Languages and Programming; Bugliesi, M., Preneel, B., Sassone, V., Wegener, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Dankar, F.K.; El Emam, K. The Application of Differential Privacy to Health Data. In EDBT-ICDT ’12, Proceedings of the 2012 Joint EDBT/ICDT Workshops; Association for Computing Machinery: New York, NY, USA, 2012; pp. 158–166. [Google Scholar] [CrossRef]
- Andrés, M.E.; Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Geo-Indistinguishability: Differential Privacy for Location-Based Systems. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security (CCS ’13), Berlin, Germany, 4–8 November 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 901–914. [Google Scholar] [CrossRef] [Green Version]
- Lablans, M.; Borg, A.; Ückert, F. A RESTful interface to pseudonymization services in modern web applications. BMC Med. Inform. Decis. Mak. 2015, 15, 2. [Google Scholar] [CrossRef] [PubMed]
- Noumeir, R.; Lemay, A.; Lina, J.M. Pseudonymization of radiology data for research purposes. J. Digit. Imaging 2007, 20, 284–295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brekne, T.; Årnes, A.; Øslebø, A. Anonymization of ip traffic monitoring data: Attacks on two prefix-preserving anonymization schemes and some proposed remedies. In International Workshop on Privacy Enhancing Technologies; Springer: Berlin/Heidelberg, Germany, 2005; pp. 179–196. [Google Scholar]
- Fan, J.; Xu, J.; Ammar, M.H.; Moon, S.B. Prefix-preserving IP address anonymization: Measurement-based security evaluation and a new cryptography-based scheme. Comput. Netw. 2004, 46, 253–272. [Google Scholar] [CrossRef]
- Kerschbaum, F. Distance-preserving pseudonymization for timestamps and spatial data. In Proceedings of the 2007 ACM workshop on Privacy in electronic society, Alexandria, VA, USA, 29 October 2007; pp. 68–71. [Google Scholar]
- Jawurek, M.; Johns, M.; Rieck, K. Smart metering de-pseudonymization. In Proceedings of the 27th Annual Computer Security Applications Conference, Orlando, FL, USA, 5–9 December 2011; pp. 227–236. [Google Scholar]
- Guarnieri, M.; Marinovic, S.; Basin, D. Securing Databases from Probabilistic Inference. In Proceedings of the 2017 IEEE 30th Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 343–359. [Google Scholar]
- Chen, Y.; Chu, W.W. Protection of Database Security via Collaborative Inference Detection. IEEE Trans. Knowl. Data Eng. 2008, 20, 1013–1027. [Google Scholar] [CrossRef] [Green Version]
- Qian, X.; Stickel, M.E.; Karp, P.D.; Lunt, T.F.; Garvey, T.D. Detection and elimination of inference channels in multilevel relational database systems. In Proceedings of the 1993 IEEE Computer Society Symposium on Research in Security and Privacy, Oakland, CA, USA, 24–26 May 1993; pp. 196–205. [Google Scholar]
- Yip, R.W.; Levitt, E.N. Data level inference detection in database systems. In Proceedings of the 11th IEEE Computer Security Foundations Workshop (Cat. No.98TB100238), Rockport, MA, USA, 11 June 1998; pp. 179–189. [Google Scholar]
- Li, N.; Yu, T.; Antón, A. A semantics-base approach to privacy languages. Comput. Syst. Sci. Eng. CSSE 2006, 21, 339. [Google Scholar]
- Becker, M.Y.; Malkis, A.; Bussard, L. A Framework for Privacy Preferences and Data-Handling Policies. In Microsoft Research Cambridge Technical Report, MSR-TR-2009-128; Microsoft Research Cambridge: Cambridge, UK, 2009. [Google Scholar]
- Kapitsaki, G.M. Reflecting User Privacy Preferences in Context-Aware Web Services. In Proceedings of the 2013 IEEE 20th International Conference on Web Services, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 123–130. [Google Scholar] [CrossRef]
- Ulbricht, M.R.; Pallas, F. YaPPL-A Lightweight Privacy Preference Language for Legally Sufficient and Automated Consent Provision in IoT Scenarios. In Data Privacy Management, Cryptocurrencies and Blockchain Technology; Springer: Cham, Switzerland, 2018; pp. 329–344. [Google Scholar] [CrossRef]
- Kokolakis, S. Privacy attitudes and privacy behaviour: A review of current research on the privacy paradox phenomenon. Comput. Secur. 2015. [Google Scholar] [CrossRef]
- Cranor, L.F.; Guduru, P.; Arjula, M. User Interfaces for Privacy Agents. ACM Trans. Comput.-Hum. Interact. 2006, 13, 135–178. [Google Scholar] [CrossRef]
- Kolter, J.; Netter, M.; Pernul, G. Visualizing past personal data disclosures. In Proceedings of the ARES’10 International Conference on Availability, Reliability, and Security, Krakow, Poland, 15–18 February 2010; pp. 131–139. [Google Scholar]
- Angulo, J.; Fischer-Hübner, S.; Pulls, T.; Wästlund, E. Towards Usable Privacy Policy Display & Management—The PrimeLife Approach; HAISA: Coron, Philippines, 2011. [Google Scholar]
- PrimeLife. PrimeLife-Bringing Sustainable Privacy and Identity Management to Future Networks and Services. 2008–2011. Available online: http://primelife.ercim.eu/ (accessed on 13 January 2020).
- Disterer, G. ISO/IEC 27000, 27001 and 27002 for Information Security Management. J. Inf. Secur. 2013, 2013, 92–100. [Google Scholar] [CrossRef] [Green Version]
- Ludwig, H.; Keller, A.; Dan, A.; King, R.P.; Franck, R. Web Service Level Agreement (WSLA) Language Specification; Ibm Corporation: Endicott, NY, USA, 2003; pp. 815–824. [Google Scholar]
- Oldham, N.; Verma, K.; Sheth, A.; Hakimpour, F. Semantic WS-agreement partner selection. In Proceedings of the 15th international conference on World Wide Web, Montreal, QC, Canada; 2006; pp. 697–706. [Google Scholar]
- Dobson, G.; Lock, R.; Sommerville, I. QoSOnt: A QoS ontology for service-centric systems. In Proceedings of the 31st EUROMICRO Conference on Software Engineering and Advanced Applications, Porto, Portugal, 30 August–3 September 2005; pp. 80–87. [Google Scholar]
- Lamanna, D.D.; Skene, J.; Emmerich, W. SLAng: A language for defining service level agreements. In Proceedings of the Ninth IEEE Workshop on Future Trends of Distributed Computing Systems, San Juan, Philippines, 28–30 May 2003; pp. 100–106. [Google Scholar] [CrossRef] [Green Version]
- Meland, P.H.; Bernsmed, K.; Jaatun, M.G.; Castejón, H.N.; Undheim, A. Expressing cloud security requirements for SLAs in deontic contract languages for cloud brokers. Int. J. Cloud Comput. 2014, 3, 69–93. [Google Scholar] [CrossRef]
- Oberle, D.; Barros, A.; Kylau, U.; Heinzl, S. A Unified Description Language for Human to Automated Services. Inf. Syst. 2013, 38, 155–181. [Google Scholar] [CrossRef]
- Kennedy, J. Towards Standardised SLAs. In Euro-Par 2013: Parallel Processing Workshops; an Mey, D., Alexander, M., Bientinesi, P., Cannataro, M., Clauss, C., Costan, A., Kecskemeti, G., Morin, C., Ricci, L., Sahuquillo, J., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 105–113. [Google Scholar]
- Gerl, A.; Meier, B. The Layered Privacy Language Art. 12–14 GDPR Extension–Privacy Enhancing User Interfaces. Datenschutz Und Datensicherheit-DuD 2019, 43, 747–752. [Google Scholar] [CrossRef]
- Data Transfer Project. Data Transfer Project Overview and Fundamentals. 2018. Available online: https://www.zurich.ibm.com/security/enterprise-privacy/epal/Specification/ (accessed on 2 June 2020).
- Facebook. Facebook Reports First Quarter 2020 Results. 2020. Available online: https://investor.fb.com/investor-news/default.aspx (accessed on 2 June 2020).
- Niu, C.; Zheng, Z.; Wu, F.; Gao, X.; Chen, G. Trading Data in Good Faith: Integrating Truthfulness and Privacy Preservation in Data Markets. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 223–226. [Google Scholar]
- Bataineh, A.S.; Mizouni, R.; Barachi, M.E.; Bentahar, J. Monetizing Personal Data: A Two-Sided Market Approach. Procedia Comput. Sci. 2016, 83, 472–479. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Liu, A.; Li, Z.; Zhang, X.; Li, Q.; Zhou, X. Protecting multi-party privacy in location-aware social point-of-interest recommendation. World Wide Web 2019, 22, 863–883. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.J.; Ng, C.Y.; Brook, R.H. Response to COVID-19 in Taiwan: Big data analytics, new technology, and proactive testing. JAMA 2020, 323, 1341–1342. [Google Scholar] [CrossRef] [PubMed]
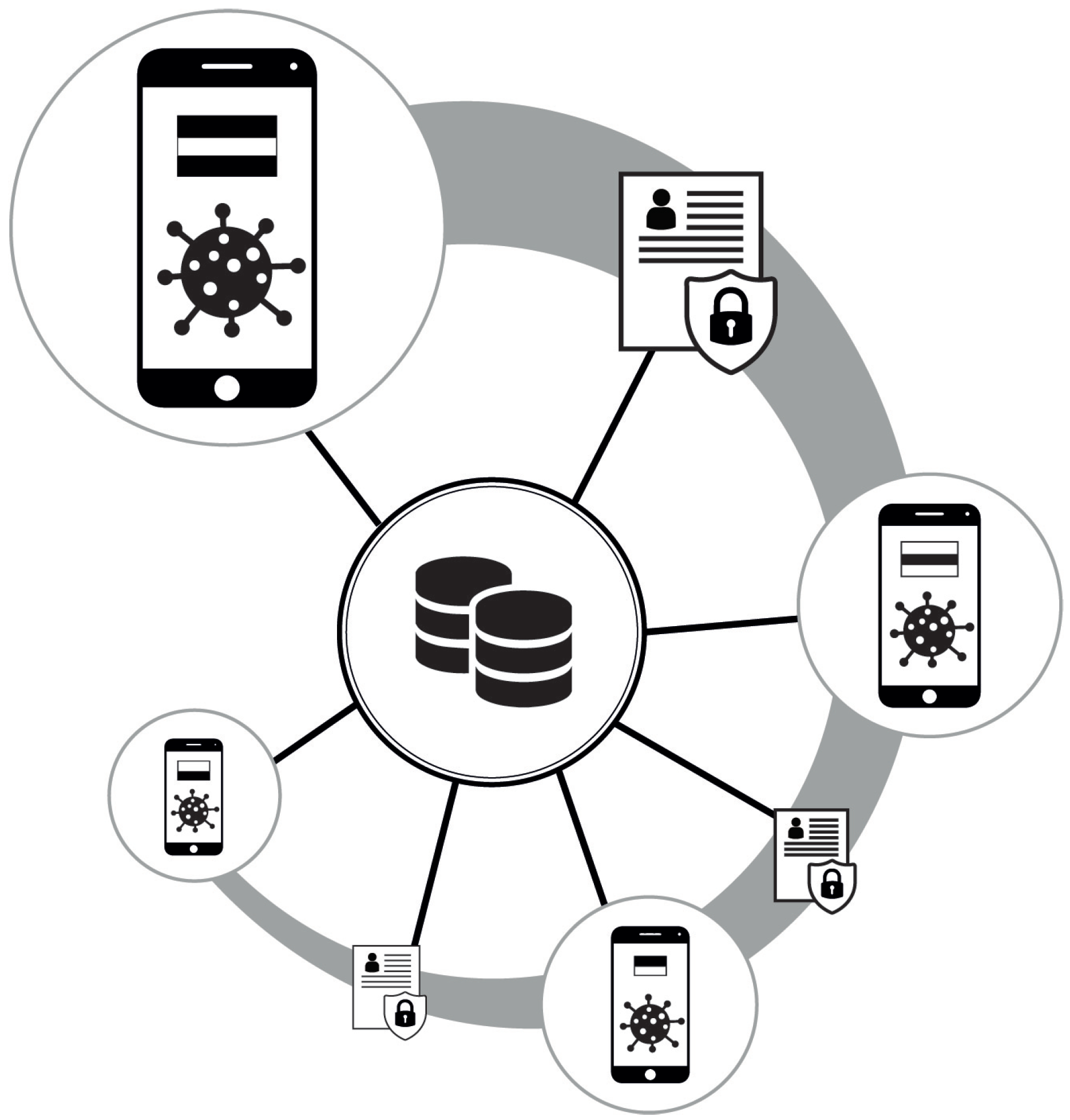

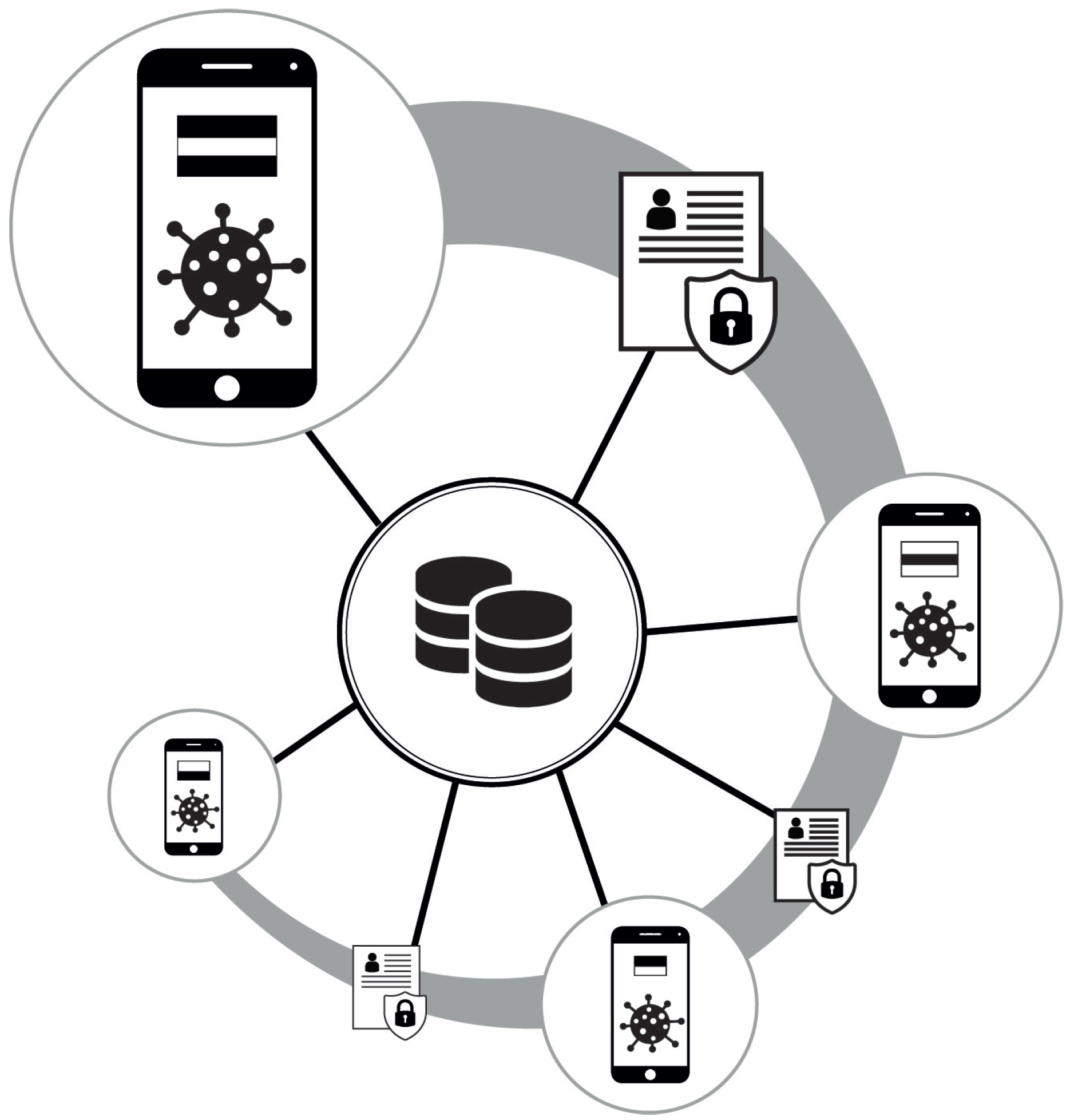{kind=link}
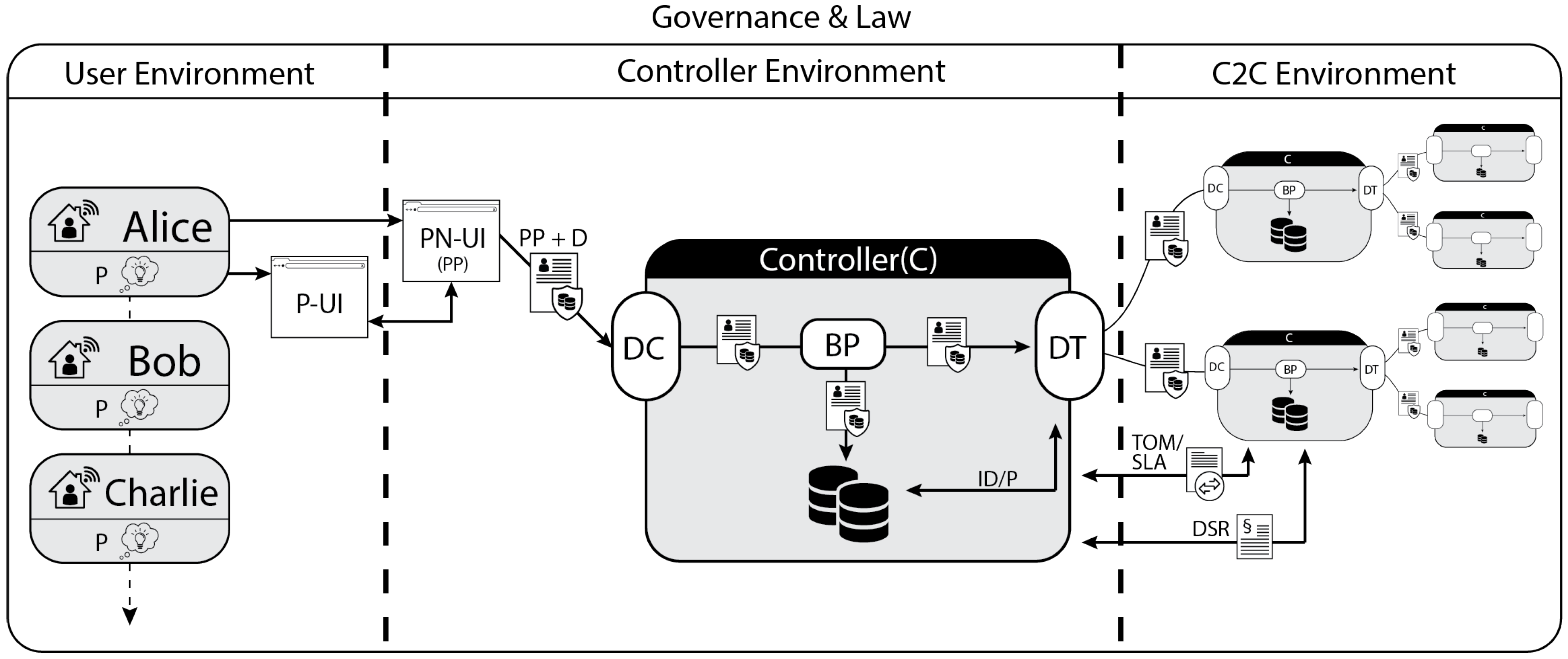
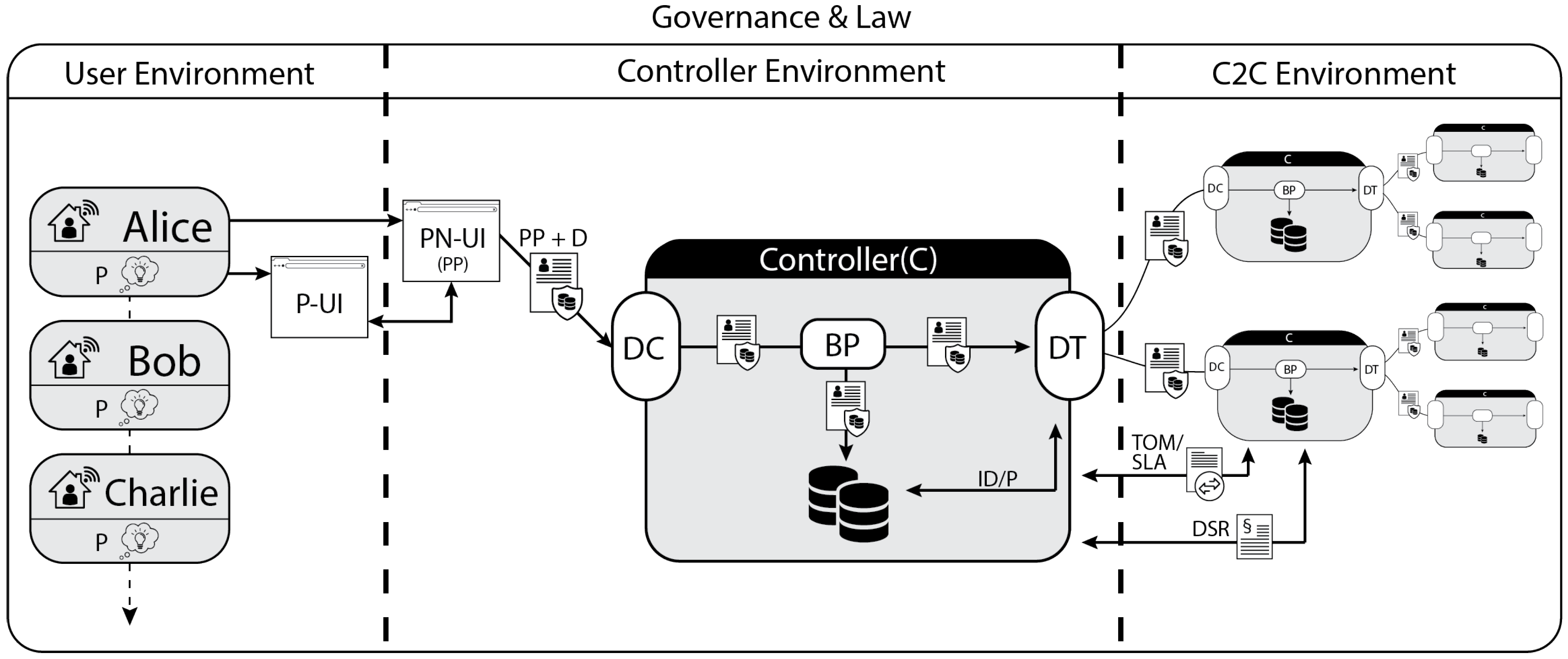{kind=link}
| Category | Approach / Framework | |||
|---|---|---|---|---|
| Role-Based Access Control | Motta and Furuie [40] | |||
| Attribute-Based Access Control | PASH [42] | |||
| Context-Aware Access Control | ICAF [43] | RelBOSS [44] | FCAAC [45] | FB-CAAC [46] |
| Category | Privacy Languages | ||||
|---|---|---|---|---|---|
| Access control privacy languages | Ponder | Rei | SecPAL | XACML | PPL |
| Transparency privacy languages | P3P | CPExchange | |||
| De-identification privacy languages | LPL | ||||
| Category | Preference Languages | |||||
|---|---|---|---|---|---|---|
| Accountability not directly considered | P3P | EPAL | P2U | PPL | SPECIAL | LPL |
| Accountability by design | AAL | A-PPL | ||||
| Method | Approaches | ||
|---|---|---|---|
| Anonymisation | Suppression | Generalisation | Deletion |
| Privacy Model | k-Anonymity | Differential Privacy | |
| Pseudonymisation | Pseudo-random Seeds | Cryptographic Approaches | Hashing |
| Author | Approaches |
|---|---|
| Guarnieri et al. [82] | Query-time inference detection if adversary has external knowledge |
| Chen and Chu [83] | Query-time detection of semantic inferences based on query log for sensitive data |
| Qian et al. [84] | Multi-level database inference detection based on foreign key relations in the schema |
| Yip and Levitt [85] | Data-level inference detection based on analysing the stored data with inference rules |
| Category | Preference Languages | ||
|---|---|---|---|
| P3P based | APPEL | XPref | SemPref |
| Symmetric Approach | SecPAL4P | PPL | |
| Context Information | CPL | ||
| GDPR Requirements | YaPPL | ||
| Type | Solution | Description |
|---|---|---|
| WSLA | SLAs for Web Services | |
| SLA | WS-Agreement | Protocol and Scheme to define SLAs between Services |
| SLAng | SLAs for end-to-end QoS in Cloud Services | |
| USDL | SLAs with Legal Context for Business Services | |
| TOM | - | No electronic representation |
| Data Subject Right | Technical Solutions |
|---|---|
| Art. 12 Transparent information, communication and modalities for the exercise of the rights of the data subject | Privacy language, privacy icon |
| Art. 13 Information to be provided where personal data are collected from the data subject | Privacy language |
| Art. 14 Information to be provided where personal data have not been obtained from the data subject | Privacy language |
| Art. 15 Right of access by the data subject | |
| Art. 16 Right to rectification | |
| Art. 17 Right to erasure (‘right to be forgotten’) | |
| Art. 18 Right to restriction of processing | |
| Art. 19 Notification obligation regarding rectification or erasure of personal data or restriction of processing | |
| Art. 20 Right to data portability | Data Transfer Project [104] |
| Art. 21 Right to object | |
| Art. 22 Automated individual decision-making, including profiling | |
| Art. 23 Restrictions |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Becher, S.; Gerl, A.; Meier, B.; Bölz, F. Big Picture on Privacy Enhancing Technologies in e-Health: A Holistic Personal Privacy Workflow. Information 2020, 11, 356. https://doi.org/10.3390/info11070356
Becher S, Gerl A, Meier B, Bölz F. Big Picture on Privacy Enhancing Technologies in e-Health: A Holistic Personal Privacy Workflow. Information. 2020; 11(7):356. https://doi.org/10.3390/info11070356
Chicago/Turabian StyleBecher, Stefan, Armin Gerl, Bianca Meier, and Felix Bölz. 2020. "Big Picture on Privacy Enhancing Technologies in e-Health: A Holistic Personal Privacy Workflow" Information 11, no. 7: 356. https://doi.org/10.3390/info11070356
APA StyleBecher, S., Gerl, A., Meier, B., & Bölz, F. (2020). Big Picture on Privacy Enhancing Technologies in e-Health: A Holistic Personal Privacy Workflow. Information, 11(7), 356. https://doi.org/10.3390/info11070356