1. Introduction
Newspapers have been a privileged form of communication over the past hundred years or so. Over the course of its long and complex history, it has undergone many transformations. Although the first newspapers can be credited to the ancient Romans, only when printing techniques became more advanced, during the Industrial Revolution, newspapers turned into a more widely circulated means of communication. A second revolution took place with the technology advances in the Information and Communication Technologies, which transformed the newspaper industry into a digital, online news industry.
This novel paradigm has also been boosted by the requirements and expectations of a new generation of young adults, the Digital Natives, who grew up with the Internet and ubiquitous digital technology and devices. This part of the population has quite a different approach on learning, experiencing the world and reading habits. Digital Natives do not usually read traditional print newspapers, but yet, they can be remarkably informed and eager for information. It may be through browsing the headlines of online newspapers, reading the Web-links posted in social networks (Facebook, Twitter, etc.) or through headlines fed to their mobile phones. For these consumers, digital news introduce a number of powerful advantages that are traditionally absent in the printed environment: interactivity, non-linearity, immediacy in accessing information, and the convergence of text, images and video [
1].
In this evolving scenario, mobile devices are the latest to challenge traditional news-delivering methods. As they become more powerful, with larger screens and ubiquitous Internet access, major media companies are investing more resources into creating new ways of reaching larger audiences via mobile platforms. The International Telecommunication Union (ITU)’s statistics (
https://www.itu.int/en/ITU-D/Statistics/Pages/stat/default.aspx) show that there are more mobile device subscriptions in the developed world than there are people. This widespread use of smartphones and the different features offered, such as web browsing, gaming, video-messaging capabilities, allow keeping users up to date with the latest news, anywhere and at any time. As a consequence, the development of mobile news solutions has a significant impact on reader’s news consumption patterns. Publico (
http://www.publico.pt) a Portuguese newspaper, is a concrete example of this new scenario. Internal figures show that since the beginning of 2014, the number of visits coming from mobile devices experienced an increase of 130%, while in the same period the number of visits from desktop devices suffered a decrease of 36%. This scenario is confirmed by larger worldwide studies that show that, in 2019, two-thirds (66%) of the online readers used the smartphone to access news (+4 pp) [
2]. Comparing with a previous report, the growth trend is visible: in 2014, a fifth (20%) of online news users across all countries identified the mobile phone as their primary access point [
3].
Predictions show that the news industry should consider new ways of producing, consuming, and linking content, the integration of traditional journalism and social networks, the use of new navigation paradigms and the personalization of the services [
4]. Some of these ideas are not pure speculation. For example, Publico reports that in some of its sections, more than 70% of the accesses come from Facebook while, in others, Google is the source used to find an article. The use of a responsive design is also coincident with the growth of mobile accesses.
One of the main open challenges is on providing users personalized access to the huge amount of information produced daily and on avoiding information overload that might contribute to a bad quality of the reading experience. Recommender systems can contribute to customer loyalty by creating a trust-added relationship between the brand and the customer and consequently to increase economic revenue, by providing readers what they would like to find. Personalized functionalities play an important role in building a successful business model for highly rated Internet sites such as Amazon, YouTube, Netflix, or Yahoo and those who cannot deploy them are at profound competitive disadvantage [
5].
In this study we question different factors that may contribute to an effective personalization of news services. More precisely, the impact of recommended items, screen layout, and history of consumption on the users’ satisfaction and profiling has been investigated. Conclusions were validated by a prototype built with a specific news’ provider and a user testbed.
The remaining of the paper is organized as follows.
Section 2 provides an overview on recommendation systems, their application in the domain of news and approaches to create user profiles.
Section 3 presents the main research questions to be addressed in this study. The used recommendation and profile-building approaches are presented in
Section 4.
Section 5 goes into details on the experiment setup, including the characterization of the participants and the implementation of the methodology, namely the description of the tasks the users were asked to perform. Results are presented and analyzed in
Section 6 while
Section 7 provides an additional discussion on the findings and points out some guidelines for future work. Finally,
Section 8 presents the main conclusions of the experiment.
3. Research Questions
In the current scenario of moving news services into a digital business, requirements to assure the best navigation experience include graphical elements, language, and organization of the information. Information is usually organized in sections, each containing a number of topic links for the reader to choose from. The purpose is to provide a lot of options up-front, so as to attract a wide variety of audiences and direct them to the information of interest [
36]. The question raised, in such scenario, is whether cataloguing some news with labels such as “What to read next” or “Recommended for you,” may or may not compel the user to select those news, even unconsciously. What is expected is that, because of time constraints or unwillingness to search for content, users may tend to click the news catalogued as recommended, expecting that these articles match their personal interests. This theory is also supported by the principle of least effort which states that each individual adopts the course of action that minimizes his/her energy expenditure, even if it means accepting information with a lower quality [
37]. Considering this predisposed stimulus, would the user notice and click on these same news even if they did not have any description or were not included explicitly in one special sections?
Our research aims at analyzing several aspects of online news consumption, namely: (1) Evaluate the role of recommendation strategies on the user perceived importance of the information; (2) estimate the impact that editorial decisions (e.g., the position or layout used to present the information) might have on the consumption; (3) understand how the previous points depend on the degree of the reader’s loyalty toward the newspaper.
Reference [
38] takes the subject of examining users’ attitudes toward news personalization by presenting participants with different personalized news editions and compared them with a non-personalized edition composed by randomly chosen articles. Participants tended to prefer the personalized editions, but this tendency was small. According to the authors, these results are probably due to the relatively small differences between the personalized and no personalized editions and the possibility of users not having considered these differences or even failed to notice them. Reference [
39] provides valuable insight to examine whether personalization would influence behavior toward a news website. In this study, one group of participants was told the news website had been personalized to its interests. The other group served as a control and participants were given no such direction, and recommended stories were labelled as “Most viewed.” Although the findings of this study corroborate earlier research suggesting that readers prefer news sites customized to their interests [
40], the results indicate that the fact that the users are made aware of the recommendations does not affect their clicking behavior. This work tried to understand how much customization and what type is needed in order to have an effect, by analyzing user attitudes when using a Web portal with different degrees (low, medium, high) of customization. The question was whether a greater degree of customization engenders more positive attitudes toward a portal that delivers personalized content. The results suggest that with customization, users’ attitudes toward the site become more positive, and that a higher level of customization translates into more returns visits to the site’s homepage and fewer visits to other competing services.
The use of simple methods (most popular, most recent, random, etc.) to provide a news personalization solution has also been analyzed [
41,
42]. The conclusions of these studies suggest that in these simple personalization methodologies the recommendation quality could depend on the context and specific news domain. For instance, the most popular algorithm can reach a good performance in pick hours. Our study intends also to analyze the impact of news personalization on user’s satisfaction and behavior but goes further ahead by comparing different aspects and approaches. This includes not only variations in the algorithm used but also the influence of the layout over users having very distinct history of usage. The first aim of our study is to examine, from a set of randomly disposed and unlabeled news, which percentage of users will show a preference for the recommended news over other presented news.
RQ1: What percentage of readers specifically select recommended news from a set of alternatives (popularity based, random) presented?
The next question is related to the way the information is presented on the screen. Most online newspapers take into attention several usability aspects, including content organization, navigational links, interface design, etc., that may have a major effect on how information is presented to and accessed by the end-user [
43]. Reference [
44] describes a qualitative study of online news reading and browsing behavior. In this study, the author explores how the layout impacts the users’ engagement with online news. Its outcomes demonstrate that the use of images and headlines lead people to the content of the articles. As the interactions with the news website continued, usability and the presentation of the information continued to contribute to users’ experiences, but the novelty or personal relevance of the articles also influenced engagement. In order to better identify the elements mostly attracting the users’ attention, the authors in [
45] describe an eye-tracking experiment on users when reading an online newspaper. Four metrics of ocular behavior were considered: (a) number of fixations overall, (b) fixation duration, (c) gaze time, and (d) saccade rate. These measures were especially useful for identifying fixation areas as well as variability in participants’ scan paths.
Although these studies are all concerned with layout questions, such as the position of various graphical elements on a page, the role of photographs versus text, or the role of color in the layout, it is not yet clear how it shapes the way users approach news information. Furthermore, these studies consider the newspaper homepage at the global level and failed in exploring interaction with a specific section, such as popular, recent or recommended news.
In order to study whether the position where the recommended items are displayed in the screen layout, for example at the top or at the bottom of the page, has a significant impact on the user selections, the following question is proposed.
RQ2: Does the position where the recommended news are displayed in the screen layout influence the user’s preferences?
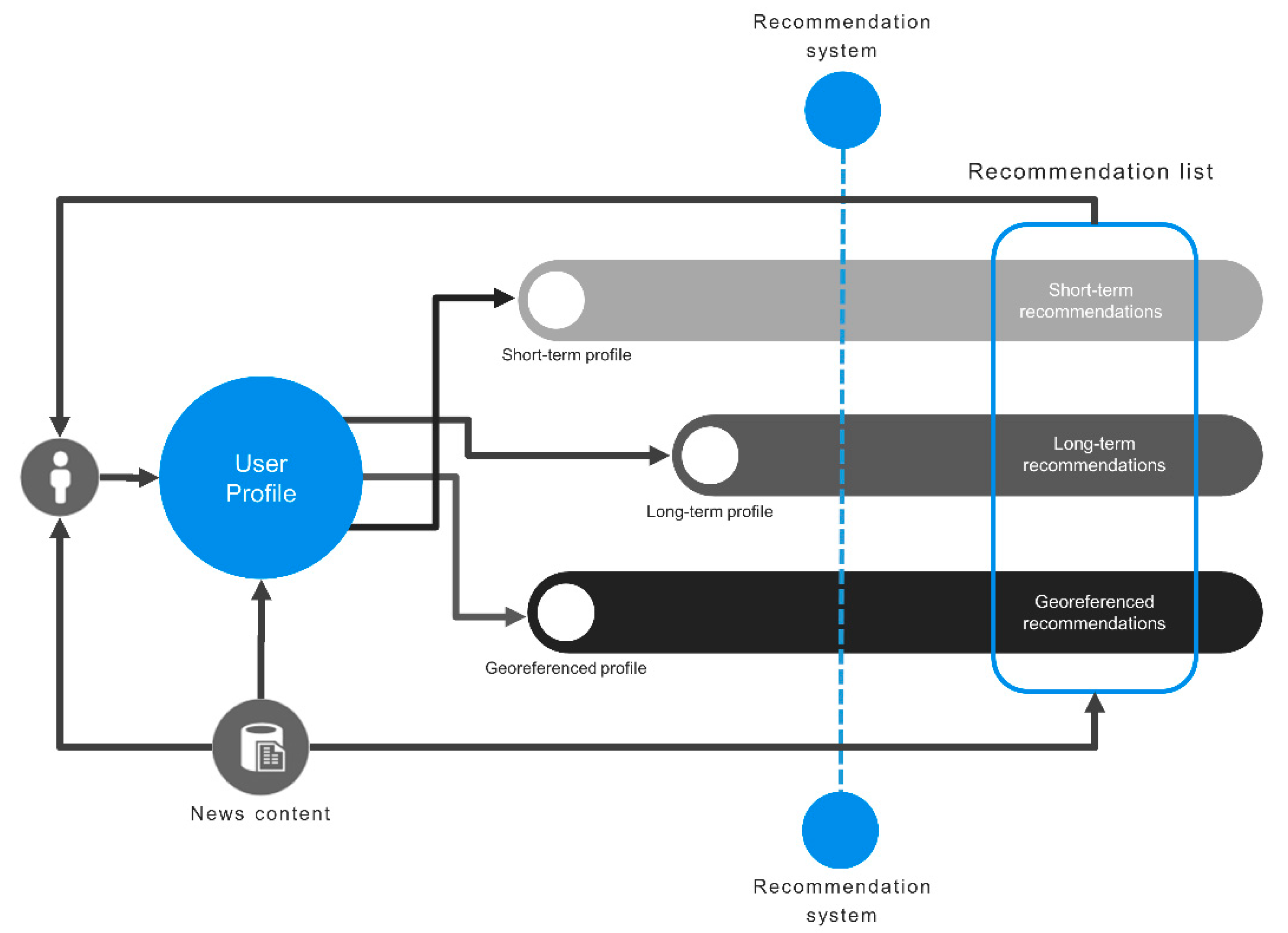
One of the key technical issues in developing applications for news personalization is the problem of how to construct accurate profiles of individual users and how these can be used to identify a user and describe his/her reading behavior.
Short and long-term profiles provide key information to a correct understanding of users’ interests. If we look into football-related news, we may discover that a user has a short-term interest in the topic if he/she only reads news during the World Cup, or a long-term interest if he/she is an assiduous reader of this topic.
To understand how a user’s interests change over time, the authors in [
46] conducted a large-scale analysis of anonymized Google news click logs. Based on the log analysis, this study concluded that clicks in old histories became much less useful in predicting future interests. It also showed that interests are also influenced by the user location and traveling users may show interest in nearby events or happenings. Although some studies addressed the evaluation of both short and long-term recommendation algorithms [
47,
48], the analysis of users’ preferences on time based or on geo located recommendation approaches is still a largely open question.
In our study, user preferences on short-term, long-term and georeferenced news recommendations are also investigated.
RQ3: Which of the two recommendation approaches, short-term or long-term, better matches user preferences?
RQ4: What is the degree of preference for news related to the country where the user is located when compared with user preferences analyzed in RQ3?
With the abundance of news sources, there is evidence that some segments of the population rely on multiple sources of news that are not limited to the ones provided by news agencies: information can be made available in social networks or through news aggregators [
49]. This fragmentation means that a significant portion of the population is no longer concentrated in a few providers but is spread across a large number of channels, making it harder for news providers to monitor consumption patterns. However, there are still users who read news regularly and are loyal to a specific source, for example through some kind of subscription, or simply because they found that source trustful. Typically, these users have a rather high consumption history. Given this highly differentiated set of consumption patterns in an online newspaper, can different types of consumption profiles be considered?
RQ5: Does the consumption frequency behavior influence significantly the preferences identified by RQ1, RQ3 and RQ4?
RQ6: Can the set of users that have not selected the list of recommended news, show similar preferences on short/long/geo approaches as identified by RQ3 and RQ4?
6. Results
For descriptive purposes, categorical variables were summarized by absolute (relative) frequencies and continuous variables by the mean (standard deviation). Chi-squared or Fisher test evaluated the independence between two categorical variables, depending on the situation. The existence of significant differences between the mean rating from experiment 2 was investigated by mixed-effects regression models. Data were grouped by individual and the variability introduced by the (non-fixed) position of the articles in the list was captured by a random effect. An autoregressive correlation of order 1 was found to best fit the data, as the model presented the lowest Akaike Information Criterion. Multiple comparisons between the three groups used Tukey contrasts. The significance level was set at 0.05.
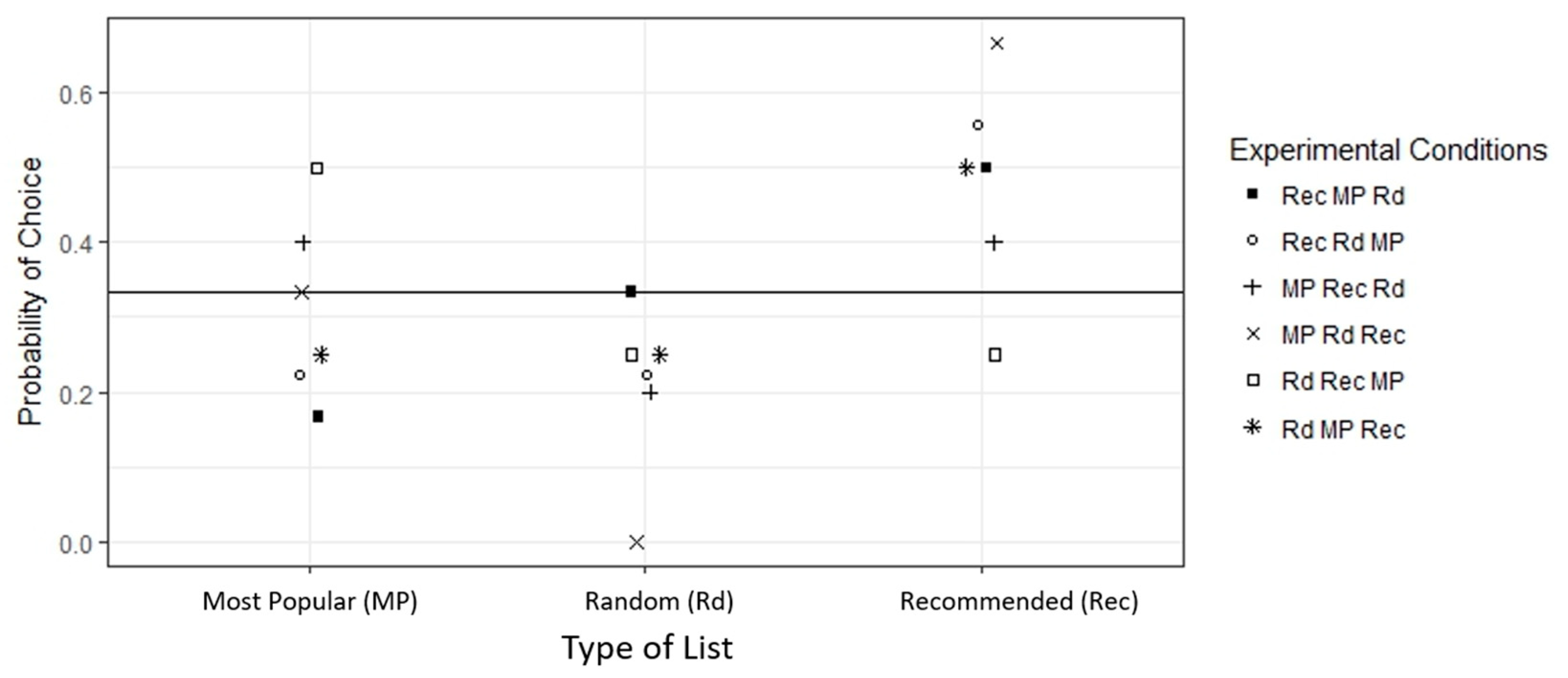
RQ1 asked about the percentage of readers selecting the recommended news from a set of several alternatives. The list including news from the recommendation algorithm was chosen most often, with 48.6% of the total number of selections, followed by the list corresponding to the most popular news (27.0%) and the list with news chosen at random (24.3%).
Figure 2 pictures the dependence of the choice probability on the type of list for each experimental condition. For example, the list with the recommended news was mostly chosen whenever the screen display presented that list in the last (cross, in the figure) or first (open circle, in the figure) position.
Regardless of the order of the alternatives on the screen display, the recommended list was, on average, more often chosen than the other alternatives once it obtained the highest values for the choice probabilities (
Figure 2). The chi-squared test marginally rejected (
p = 0.052) the null hypothesis of a uniform distribution for the choice probabilities, represented by a horizontal line in the figure.
RQ2 assesses whether the position where the information is displayed, in the screen layout, influences user selections.
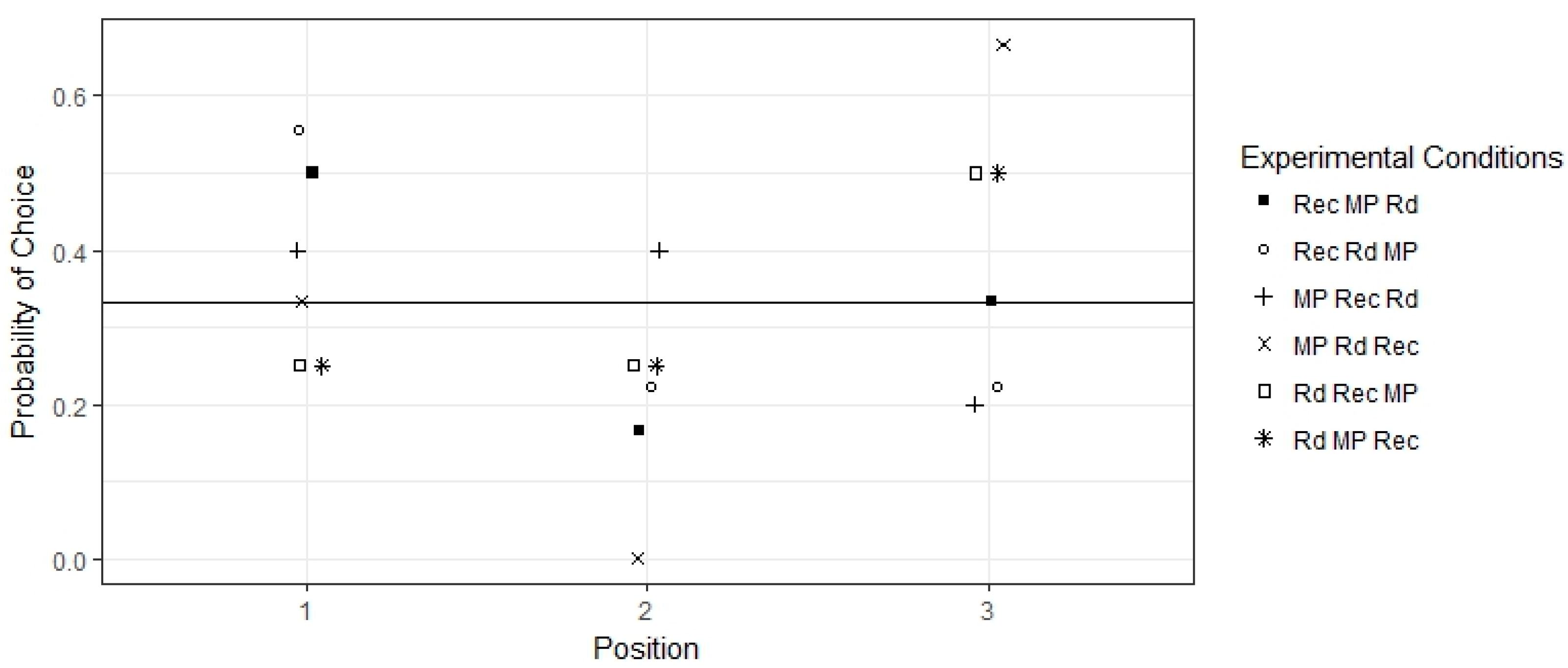
Figure 3 presents the observed probability of choosing the first, second, or third list on the screen display within each experimental condition.
The figure shows that the lists positioned first and third were most often picked than those positioned second. However, this preference was not statistically significant (p = 0.137, chi-squared test; the horizontal line in the plot represents the uniform distribution) meaning that, as a whole, each position is equally liked by the consumers. This answers RQ2 and it can be said that there was no significant position influence on the user selections.
It can be observed that the largest probability of choice for the first position happened when the recommended list was placed there, i.e., for the condition Rec Rd MP. The largest probabilities of choice in favor of the second and third positions have also occurred for the recommended list but the second largest probability also included a preference for the list with the most popular news.
The participants were then divided into three groups, depending on the number of stories already read in their profile: (1) Seasonal readers that read less than 10 news; (2) average readers that read 10 to 40 news; (3) intensive readers that read more than 40 news
As for the possible confounding effect of the readers’ consumption profile on the list choice,
Table 2 shows the preferences of each profile. It is seen that, regardless of the profile, most of the readers pick the list with the recommended items; even those with no regular reading habits. The Fisher test was not statistically significant (
p = 0.637) implying that we cannot reject the null hypothesis that states the independence of the two categorical variables. This answers the first part of RQ5 showing that conclusions obtained for RQ1 are not affected by the reading habits.
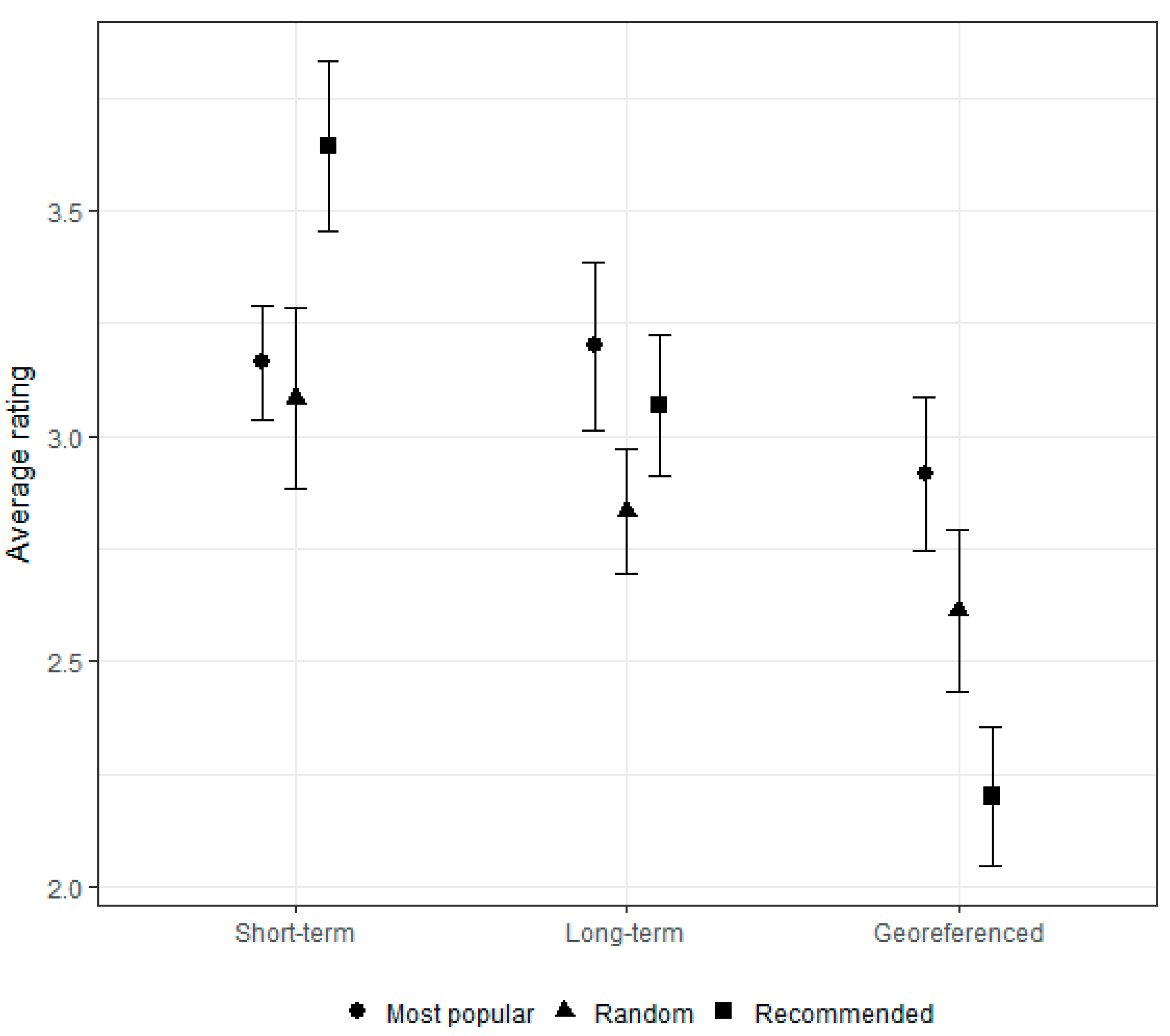
We now consider experiment 2, concerning a single list of 12 recommended newspaper news. RQ3 and RQ4 question which of the approaches, among short-term, long-term and georeferenced, show the highest preference.
Table 3 indicates that the short-term recommendation algorithm collected the highest ratings—the average (standard deviation) rating for the short-term recommendations was 3.4 (1.1), while for the long-term recommendations the average rating was 3.0 (1.2) and for the georeferenced approach it was 2.5 (1.2).
The existence of significant differences between the mean ratings from the approaches was investigated by mixed-effects regression models. All pairs were found to have significantly different means (Short vs. Long: p = 0.044; Short vs. GeoReferenced: p < 0.001; Long vs. GeoReferenced: p = 0.003), with the highest mean rating for the short-term approach.
An additional effect of the readers’ consumption profile (seasonal/average/intensive) on the ratings was not statistically significant (p = 0.532, 0.282), nor its interaction. In particular, the lack of statistical significance for the interaction means that the ratings of the readers toward the three recommended approaches are essentially independent from their reading profiles.
RQ5 evaluates if news consumption frequency behavior influences significantly the preferences identified by RQ1, RQ3, and RQ4.
For the most popular and random list, no significant divergence between profiles was noticed: most popular news reached around 30% of the selections, while random news obtained around 15% of user selections. The results presented suggest that there is no significant influence of the length of the users’ interactions with the system in the past and the performance of the developed approach that always outperforms the simplest approaches of providing news.
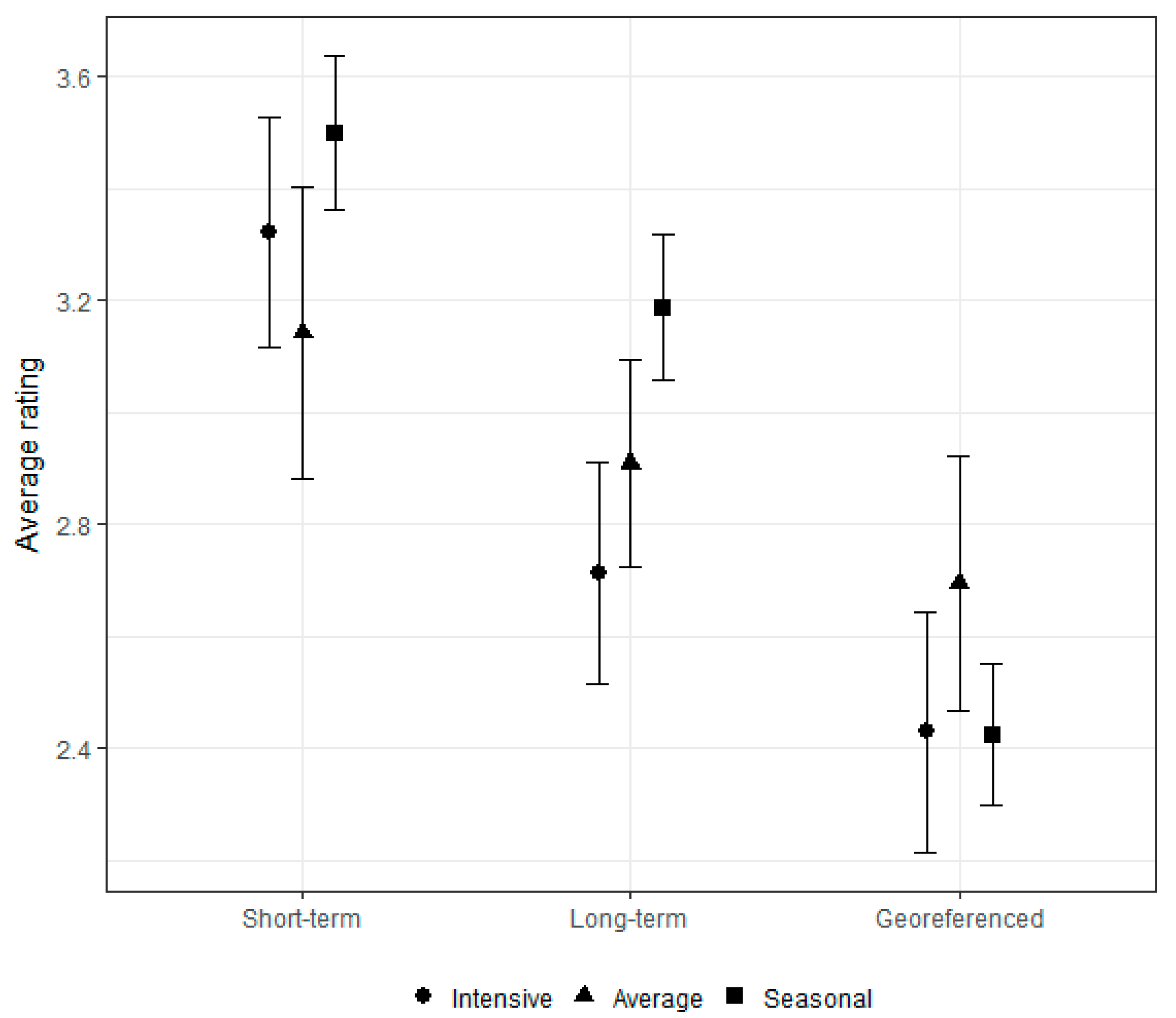
Figure 4 illustrates these results. The highest preferences were obtained for the short-term recommendation methodology, independently of the user profile, while the lowest value is associated with the georeferenced approach. However, it is noticeable that for intensive readers, the divergence between the rating average for the short-term approach and the other methodologies is larger than for seasonal or average reader profiles.
RQ6 questions if the set of users who do not select the recommended proposals have similar preferences to the ones identified by RQ3 and RQ4.
Figure 5 focuses on the average ratings obtained for the different recommendation approaches when seen from users that did not select the recommended list during the first experiment. The results show that, in contrast with those having selected personalized news, users who had opted for the most popular news do not show a clear preference for any of the recommendation approaches. Users who had selected the random list show a slight preference for the short-term approach, followed by the long-term and finally by the georeferenced approach, but the preference pattern is much less evident compared with those who prefer recommended news. Additionally, users who selected recommended news have the lowest average rating value for the news provided by the georeferenced methodology. These results provide some evidence that users who have a notorious preference for news related to their profile, do not show much interest in more general news, such as those generated by the georeferenced approach, which does not differentiate users but just their location.
7. Discussion
In this study, various research questions have been formulated in an attempt to analyze the newsreaders’ behaviors and preferences in the interaction with online personalized news.
The first results clearly suggested that, among a set of news to choose from, users will more likely read recommended news instead of popular news or other generic content that shows up on the screen. Results are consistent independently of the position of the recommendation list in the experiment. This can be interpreted as an indication that if there are recommendations available, information overload does not affect the user capability to locate his/her interests. It seems that, even if the personalized articles are presented in a basic and poor newspaper design, randomly arranged and without any kind of description, users will still feel motivated to choose those articles without knowing they are recommendations.
At the same time, findings show that generic recommendation techniques, as recommending the most popular items, cannot compete with recommendation approaches based on the user profile. The rationale is that a system that routinely recommends popular or common items, even when achieving high numerical accuracy values, can be of little value to users [
57]. However, recommending popular news still seems to be a better approach than suggesting news without any pre-selection, since the random news list scored worse. These findings provide some support to the hypothesis that the online newspapers that do not implement or only implement low-level personalization systems will not have as many readings as newspapers having more complex and personalized recommendation systems. This hypothesis is in line with the research of [
58] that demonstrated that online product recommendations greatly influence subjects’ product choices and could make a product to be selected twice as often if it is recommended.
Our study also shows that there is no significant change in the pattern of results for seasonal, average or intensive readers. This is highly encouraging, since it suggests that regardless of the number of interaction of a user with the system, or whatever his news consumption behavior is, recommendation systems can be effective in increasing the perceived attractiveness of online news services.
Table 4, summarizing results from experiment 2, shows that, regardless of the consumption history, there was no change in the user preferences pattern, indicating that the short-term recommendation methodology provides the highest preferences (rating average). These results demonstrate the users’ higher interest for news similar to those they have read recently when compared to personalized news based on their long-term profile. This conclusion is in line with [
46] that analyzed anonymized Google News click logs. It is noticeable that for intensive readers there is a more evident preference over short-term recommendations when compared with results from the other methodologies, showing a stronger preference for news that capture their recent interests. The potential explanation for these general findings is that users who read news intensively and with a regular frequency can have their preferences better defined. Since the profile of this class of readers is created from a larger amount of collected information, their long and short-term profiles can be better distinguished.
The low performance of the georeferenced algorithm may be due to the use of only generic information about the country where the user is located in. This is a current limitation that might be improved in the future if additional information is introduced by the news provider, including, for example, region-based or town-based locations. Given that, in the testbed, the users were located in the same country, this country-only-geolocation limitation may have had an impact on the evaluation. Having a broader representation of geo-locations among the testers will be considered in a future experiment
Considering the first evaluation experiment, an additional analysis associated with the question on whether the users who do not select the recommended list have the same recommendation approach preferences as those who selected the recommended list, demonstrated that different types of news selection reflect different preference patterns. The findings from this analysis suggest that there is an influence in the average rating assigned to the recommendation approaches in the second evaluation experiment depending on the list that was selected in the first experiment. In particular, users who had selected most popular news do not show a clear preference for any of the recommended approaches. This can be interpreted as an indication that, in some cases, the social influence represents a crucial role in user readings decisions [
59]. Popular news articles are usually the most commented, shared in social networks, and also most discussed with others. Users who matched their preferences only with the crowd will present a profile that is mainly dependent on the preferences of other newsreaders. In such cases, the users will be unable to demonstrate an evident interest by any of the recommender approaches, since none of them corresponds to their real interests.
Results also show that users who have selected recommended news are the ones less keen on the georeferenced methodology. This provides some evidence that users who have a notorious preference for news related to their profile do not show much interest in broader news, such as those generated by georeferenced approach.
Author Contributions
Conceptualization, P.V. and M.S.; methodology, P.V., M.S. and R.G.; software, M.S.; validation, P.V., M.S., and R.G.; formal analysis, P.V., M.S., and R.G.; investigation, P.V., M.S., and A.C.; resources, P.V., M.S., and A.C.; data curation, P.V., M.S., and A.C.; writing—original draft preparation, P.V. and M.S.; writing—review and editing, P.V. and R.G.; visualization, M.S.; supervision, P.V.; project administration, P.V.; funding acquisition, P.V. and A.C. All authors have read and agreed to the published version of the manuscript.
Funding
Paula Viana and Márcio Soares were partial supported by Project “TEC4Growth—Pervasive Intelligence, Enhancers and Proofs of Concept with Industrial Impact/NORTE-01-0145-FEDER-000020”, under Research Line FourEyes, financed by the North Portugal Regional Operational Programme (NORTE 2020), under the PORTUGAL 2020 Partnership Agreement, and through the European Regional Development Fund (ERDF). Paula Viana has also been supported by National Funds through the Portuguese funding agency, FCT—Fundação para a Ciência e a Tecnologia, within project UIDB/50014/2020. Rita Gaio was partially supported by CMUP, which is Financed by national funds through FCT—Fundação para a Ciência e a Tecnologia, I.P., under the project with the reference UIDB/00144/2020. Amílcar Correia was partially supported by the Project Pglobal (Nr. 2014/38592-Programa Operacional Temático Factores de Competitividade/Programa Operacional do Norte, Funded by ERDF).
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Liu, Z. Reading behavior in the digital environment: Changes in reading behavior over the past ten years. J. Doc. 2005, 61, 700–712. [Google Scholar] [CrossRef]
- Reuters Institute for the Study of Journalism. Reuters Institute Digital News Report 2019; Newman, N., Fletcher, R., Kalogeropoulos, A., Nielsen, R.K., Eds.; Reuters Institute for the Study of Journalism: Oxford, UK, 2019; Available online: https://reutersinstitute.politics.ox.ac.uk/sites/default/files/2019-06/DNR_2019_FINAL_0.pdf (accessed on 29 June 2020).
- Reuters Institute for the Study of Journalism. Reuters Institute Digital News Report 2014: Tracking the Future of News; Newman, N., Levy, D.A.L., Eds.; Reuters Institute for the Study of Journalism: Oxford, UK, 2014; Available online: https://reutersinstitute.politics.ox.ac.uk/our-research/digital-news-report-2014 (accessed on 29 June 2020).
- Newman, N. Journalism, Media and Technology Predictions 2016. ORA Review Team. Available online: https://ora.ox.ac.uk/objects/uuid:f15fac34-bafb-4883-898c-a53ade027e32 (accessed on 12 December 2019).
- Zaier, Z.; Godin, R.; Faucher, L. Evaluating Recommender Systems. In Proceedings of the 2008 International Conference on Automated Solutions for Cross Media Content and Multi-Channel Distribution, Axmedis 2008, Florence, Italy, 17–19 November 2008; pp. 211–217. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. (Eds.) Recommender Systems Handbook; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Gena, C.; Grillo, P.; Lieto, A.; Mattutino, C.; Vernero, F. When Personalization Is Not an Option: An In-The-Wild Study on Persuasive News Recommendation. Information 2019, 10, 300. [Google Scholar] [CrossRef]
- Gunawardana, A.; Shani, G. A Survey of Accuracy Evaluation Metrics of Recommendation Tasks. J. Mach. Learn. Res. 2009, 10, 2935–2962. [Google Scholar]
- Chen, L.; Pu, P. Experiments on user experiences with recommender interfaces. Behav. Inf. Technol. 2014, 33, 372–394. [Google Scholar] [CrossRef]
- Kirchhoff, S.M. The U.S. Newspaper Industry in Transition; Congressional Research Service: Washington, DC, USA, 2010.
- Paliouras, G.; Alexandros, M.; Ntoutsis, C.; Alexopoulos, A.; Skourlas, C. PNS: Personalized Multi-source News Delivery. In Knowledge-Based Intelligent Information and Engineering Systems; Gabrys, B., Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1152–1161. [Google Scholar] [CrossRef]
- Zheng, L.; Li, L.; Hong, W.; Li, T. PENETRATE: Personalized news recommendation using ensemble hierarchical clustering. Expert Syst. Appl. 2013, 40, 2127–2136. [Google Scholar] [CrossRef]
- Borges, H.L.; Lorena, A.C. A Survey on Recommender Systems for News Data. In Smart Information and Knowledge Management; Szczerbicki, E., Nguyen, N.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 129–151. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; Association for Computing Machinery: New York, NY, USA, 1994; pp. 175–186. [Google Scholar] [CrossRef]
- Ahn, J.; Brusilovsky, P.; Grady, J.; He, D.; Syn, S.Y. Open User Profiles for Adaptive News Systems: Help or Harm? In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 11–20. [Google Scholar] [CrossRef]
- Ren, H.; Feng, W. CONCERT: A Concept-Centric Web News Recommendation System. In Web-Age Information Management; Wang, J., Xiong, H., Ishikawa, Y., Xu, J., Zhou, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 796–798. [Google Scholar] [CrossRef]
- IJntema, W.; Goossen, F.; Frasincar, F.; Hogenboom, F. Ontology-based News Recommendation. In Proceedings of the 2010 EDBT/ICDT Workshops, Lausanne, Switzerland, 23–25 March 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Ardissono, L.; Petrone, G.; Vigliaturo, F. News Recommender Based on Rich Feedback. In User Modeling, Adaptation and Personalization; Ricci, F., Bontcheva, K., Conlan, O., Lawless, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 331–336. [Google Scholar] [CrossRef]
- Jonnalagedda, N.; Gauch, S. Personalized News Recommendation Using Twitter. In Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Atlanta, GA, USA, 17–20 November 2013; Association for Computing Machinery: New York, NY, USA, 2013; Volume 3, pp. 21–25. [Google Scholar] [CrossRef]
- Viana., P.; Soares, M. A Hybrid Approach for Personalized News Recommendation in a Mobility Scenario Using Long-Short User Interest. Int J. Artif. Intell. Tools 2017, 26, 1760012. [Google Scholar] [CrossRef]
- Noh, Y.; Oh, Y.H.; Park, S.B. A Location-based Personalized News Recommendation. In Proceedings of the 2014 International Conference on Big Data and Smart Computing (BIGCOMP), Bangkok, Thailand, 15–17 January 2014; pp. 99–104. [Google Scholar] [CrossRef]
- Lee, H.J.; Park, S.J. MONERS: A news recommender for the mobile web. Expert Syst. Appl. 2007, 32, 143–150. [Google Scholar] [CrossRef]
- Tavakolifard, M.; Gulla, J.A.; Almeroth, K.C.; Ingvaldesn, J.E.; Nygreen, G.; Berg, E. Tailored News in the Palm of Your Hand: A Multi-perspective Transparent Approach to News Recommendation. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 305–308. [Google Scholar]
- Viana, P.; Soares, M. A Hybrid Recommendation System for News in a Mobile Environment. In Proceedings of the 6th International Conference of Web Intelligence, Mining and Semantics, Nîmes, France, 13–15 June 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Rich, E. User modeling via stereotypes. Cogn. Sci. 1979, 3, 329–354. [Google Scholar] [CrossRef]
- Fröschl, C. User Modeling and User Profiling in Adaptive E-learning Systems: An Approach for a Service-Based Personalization Solution for the Research Project AdeLE; VDM Verlag Dr. Müller: Saarbrücken, Germany, 2008. [Google Scholar]
- Stegmann, R. Improving Explicit Profile Acquisition by Means of Adaptive Natural Language Dialog. In User Modeling; Ardissono, L., Brna, P., Mitrovic, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 518–520. [Google Scholar] [CrossRef]
- Chen, J.J.; Gao, J.; Sheng, S.E. Non-violative User Profiling Approach for Website Design Improvement. In Proceedings of the 8th International Conference on Computer Supported Cooperative Work in Design, Xiamen, China, 26–28 May 2004; Springer: Berlin/Heidelberg, Germany, 2005; pp. 95–104. [Google Scholar] [CrossRef]
- Schiaffino, S.; Amandi, A. Intelligent User Profiling. In Artificial Intelligence an International Perspective; Bramer, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 193–216. [Google Scholar] [CrossRef]
- Soares, M.; Viana, P. Tuning metadata for better movie content-based recommendation systems. Multimed. Tools Appl. 2014, 74, 7015–7036. [Google Scholar] [CrossRef]
- Gauch, S.; Speretta, M.; Chandramouli, A.; Micarelli, A. User Profiles for Personalized Information Access. In The Adaptive Web; Brusilovsky, P., Kobsa, A., Nejdl, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 54–89. [Google Scholar] [CrossRef]
- Ghorab, M.R.; Zhou, D.; O’Connor, A.; Wade, V. Personalised Information Retrieval: Survey and classification. User Modeling User-Adapt. Interact. 2012, 23, 381–443. [Google Scholar] [CrossRef]
- Soares, M.; Viana, P. TV Recommendation and Personalization Systems: Integrating Broadcast and Video On demand Services. Adv. Electr. Comput. Eng. 2014, 14, 115–120. [Google Scholar] [CrossRef]
- Mao, K.; Chen, G.; Hu, Y.; Zhang, L. Music recommendation using graph based quality model. Signal. Process. 2016, 120, 806–813. [Google Scholar] [CrossRef]
- Tewari, A.S.; Kumar, A.; Barman, A.G. Book Recommendation System Based on Combine Features of Content Based Filtering, Collaborative Filtering and Association Rule Mining. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), Haryana, India, 21–22 February 2014; pp. 500–503. [Google Scholar] [CrossRef]
- Busa, M.G. Introducing the Language of the News: A Student’s Guide; Routledge: London, UK, 2013. [Google Scholar]
- Zipf, G.K. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology; Addison-Wesley Press: Boston, MA, USA, 1949. [Google Scholar]
- Sela, M.; Lavie, T.; Inbar, O.; Oppenheim, I.; Meyer, J. Personalizing news content: An experimental study. J. Assoc. Inf. Sci. Technol. 2015, 66, 1–12. [Google Scholar] [CrossRef]
- Chen, G.M.; Chock, T.M.; Gozigian, H.; Rogers, R.; Sen, A.; Schweisberger, V.N.; Wang, Y. Personalizing News Websites Attracts Young Readers. Newsp. Res. J. 2011, 32, 22–38. [Google Scholar] [CrossRef]
- Kalyanaraman, S.; Sundar, S. The Psychological Appeal of Personalized Content in Web Portals: Does Customization Affect Attitudes and Behavior? J. Commun. 2006, 56, 110–132. [Google Scholar] [CrossRef]
- Gebremeskel, G.G. The Degree of Randomness in a Live Recommender Systems Evaluation; Linda, C., Nicola, F., Gareth, J., Eric, S.J., Eds.; CWI: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Lommatzsch, A.; Werner, S. Optimizing and Evaluating Stream-Based News Recommendation Algorithms. In Proceedings of the 6th CLEF International Conference on Experimental IR Meets Multilinguality, Multimodality, and Interaction, Toulouse, France, 8–11 September 2015; Springer Inc.: New York, NY, USA, 2015; Volume 9283, pp. 376–388. [Google Scholar] [CrossRef]
- Van Oostendorp, H.; van Nimwegen, C. Locating Information in an Online Newspaper. J. Comput. Med. Commun. 1998, 4. [Google Scholar] [CrossRef]
- O’Brien, H.L. Exploring user engagement in online news interactions. Proc. Am. Soc. Inf. Sci. Technol. 2011, 48, 1–10. [Google Scholar] [CrossRef]
- Bernas, R.S.; Gibbs, W.J. Visual Attention in Newspaper versus TV-Oriented News Websites. J. Usability Stud. 2009, 4, 147–165. [Google Scholar]
- Liu, J.; Dolan, P.; Pedersen, E.R. Personalized News Recommendation Based on Click Behavior. In Proceedings of the 15th International Conference on Intelligent User Interfaces, Hong Kong, China, 7–10 February 2010; ACM: New York, NY, USA, 2010; pp. 31–40. [Google Scholar] [CrossRef]
- Billsus, D.; Pazzani, M.J. User Modeling for Adaptive News Access. User Model. User Adapt. Interact. 2000, 10, 147–180. [Google Scholar] [CrossRef]
- Díaz, A.; Gervás, P. Dynamic User Modeling in a System for Personalization of Web Contents. In Current Topics in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 281–290. [Google Scholar] [CrossRef]
- Ksiazek, T.B.; Malthouse, E.C.; Webster, J.G. News-seekers and Avoiders: Exploring Patterns of Total News Consumption Across Media and the Relationship to Civic Participation. J. Broadcasting Electron. Media 2010, 54, 551–568. [Google Scholar] [CrossRef]
- Limam, L. Usage-Driven Unified Model for User Profile and Data Source Profile Extraction, Lyon, INSA. 2014. Available online: http://www.theses.fr/2014ISAL0058 (accessed on 3 July 2020).
- Li, L.; Zheng, L.; Yang, F.; Li, T. Modeling and broadening temporal user interest in personalized news recommendation. Expert Syst. Appl. 2014, 41, 3168–3177. [Google Scholar] [CrossRef]
- Aimeur, E.; Vézeau, M. Short-Term Profiling for a Case-Based Reasoning Recommendation System. In Machine Learning: ECML 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 23–30. [Google Scholar] [CrossRef]
- Kacem, A.; Boughanem, M.; Faiz, R. Time-Sensitive User Profile for Optimizing Search Personalization; Springer: Cham, Switzerland, 2014; pp. 111–121. [Google Scholar] [CrossRef]
- Osinski, S. An Algorithm for Clustering of Web Search Results. Master’s Thesis, Poznań University of Technology, Poznań, Poland, 2003. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2015, 17, 734–749. [Google Scholar] [CrossRef]
- Shani, G.; Gunawardana, A. Evaluating Recommendation Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: New York, NY, USA, 2011; pp. 257–297. [Google Scholar] [CrossRef]
- Pathak, B.; Garfinkel, R.; Gopal, R.; Venkatesan, R.; Yin, F. Empirical Analysis of the Impact of Recommender Systems on Sales. J. Manag. Inf. Syst. 2010, 27, 159–188. [Google Scholar] [CrossRef]
- Senecal, S.; Nantel, J. The influence of online product recommendations on consumers’ online choices. J. Retail. 2009, 80, 159–169. [Google Scholar] [CrossRef]
- Shang, S.; Hui, P.; Kulkarni, S.R.; Cuff, P.W. Wisdom of the Crowd: Incorporating Social Influence in Recommendation Models. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems, Tainan, Taiwan, 7–9 December 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 835–840. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}