Malicious Text Identification: Deep Learning from Public Comments and Emails



Abstract
1. Introduction
2. Background
2.1. Security Information
2.2. Text Classification and Malicious Text Filtering
2.3. Neural Networks for Text Filtering
2.4. Multi-Domain Learning
3. Research Methods
3.1. Word Embeddings
3.2. Basic Text Classification Architectures
- The input of the hidden layer at time t: Wt
- The output of the step t: where f is the activation function such as sigmoid or ReLu
- Final output: where g is the output activation function such as softmax
4. Methodology and Experimental Setup
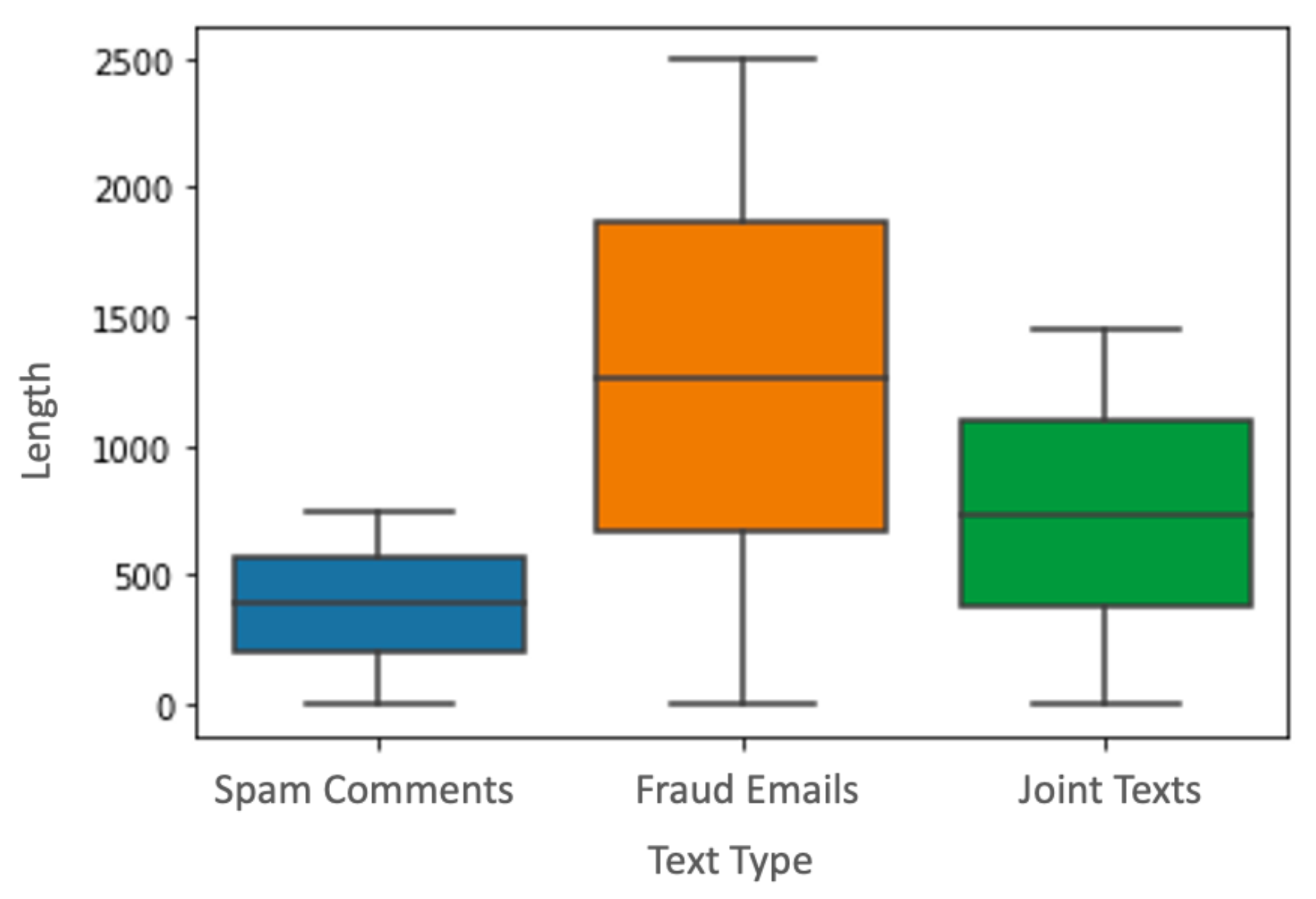
4.1. Datasets
4.2. Data Preparation
- Lower-casing all the words because our models are not case-sensitive
- Tokenizing the texts using NLTK Python Library
- Removing the stop words using an enhanced version of NLTK English corpus
- Removing URLs and links to websites that start with www.* or http://*
- Removing repeating characters from words
- Removing numbers and punctuation marks
- Removing strange characters that were utilized from the keyboard
- Word lemmatization, semantic reconstruction of misspelled words, mapping the Emojis to their expression, and replacing the slang by their original meaning
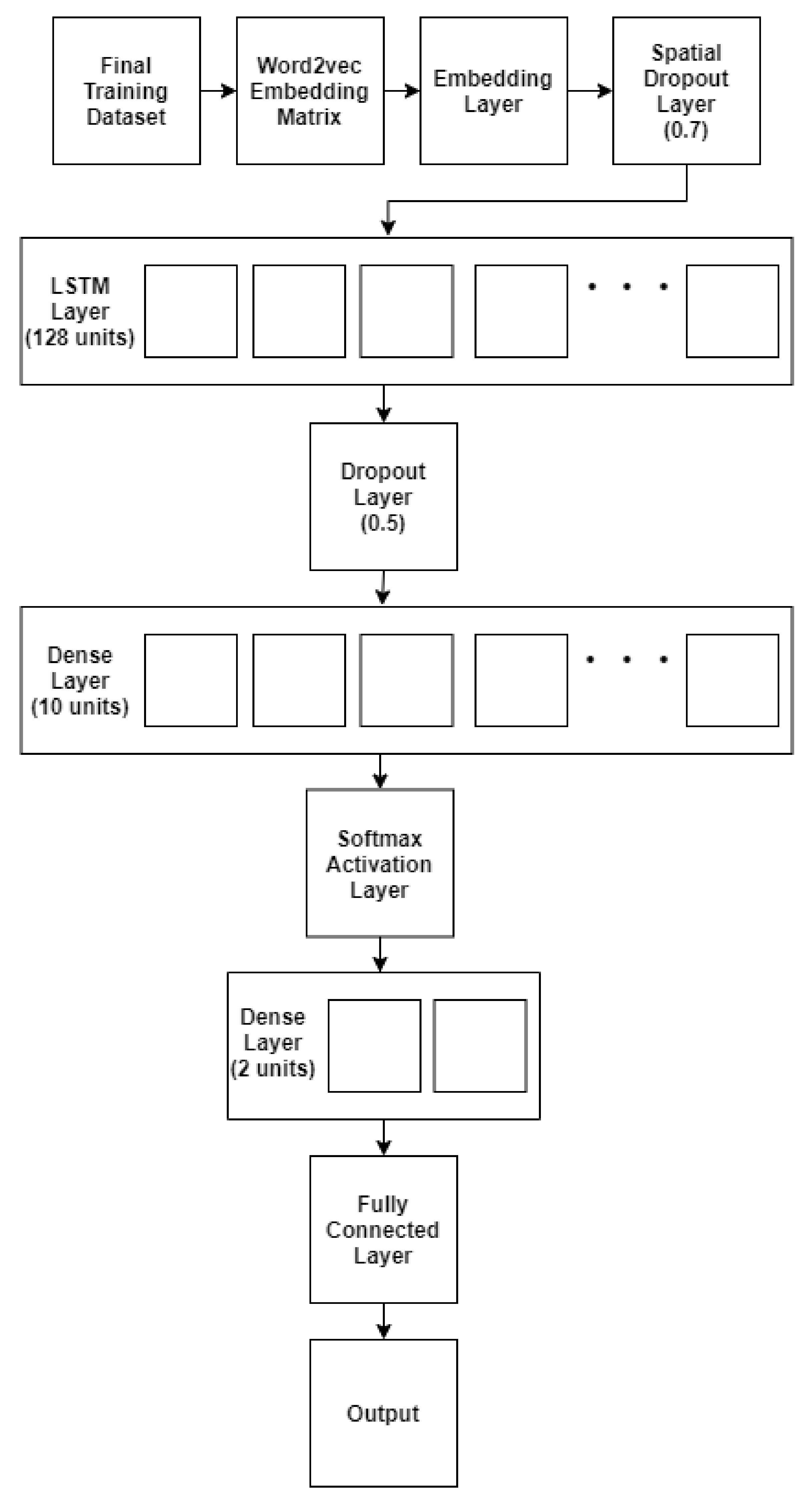
4.3. Models
4.3.1. Spam Model and Fraud Model Parameters
4.3.2. Joint Model Parameters
4.4. Word Representation: Word2vec
4.5. The Performance Evaluation Metrics
4.5.1. Accuracy
4.5.2. Precision
4.5.3. Recall
4.5.4. F1 Score
5. Results and Analysis
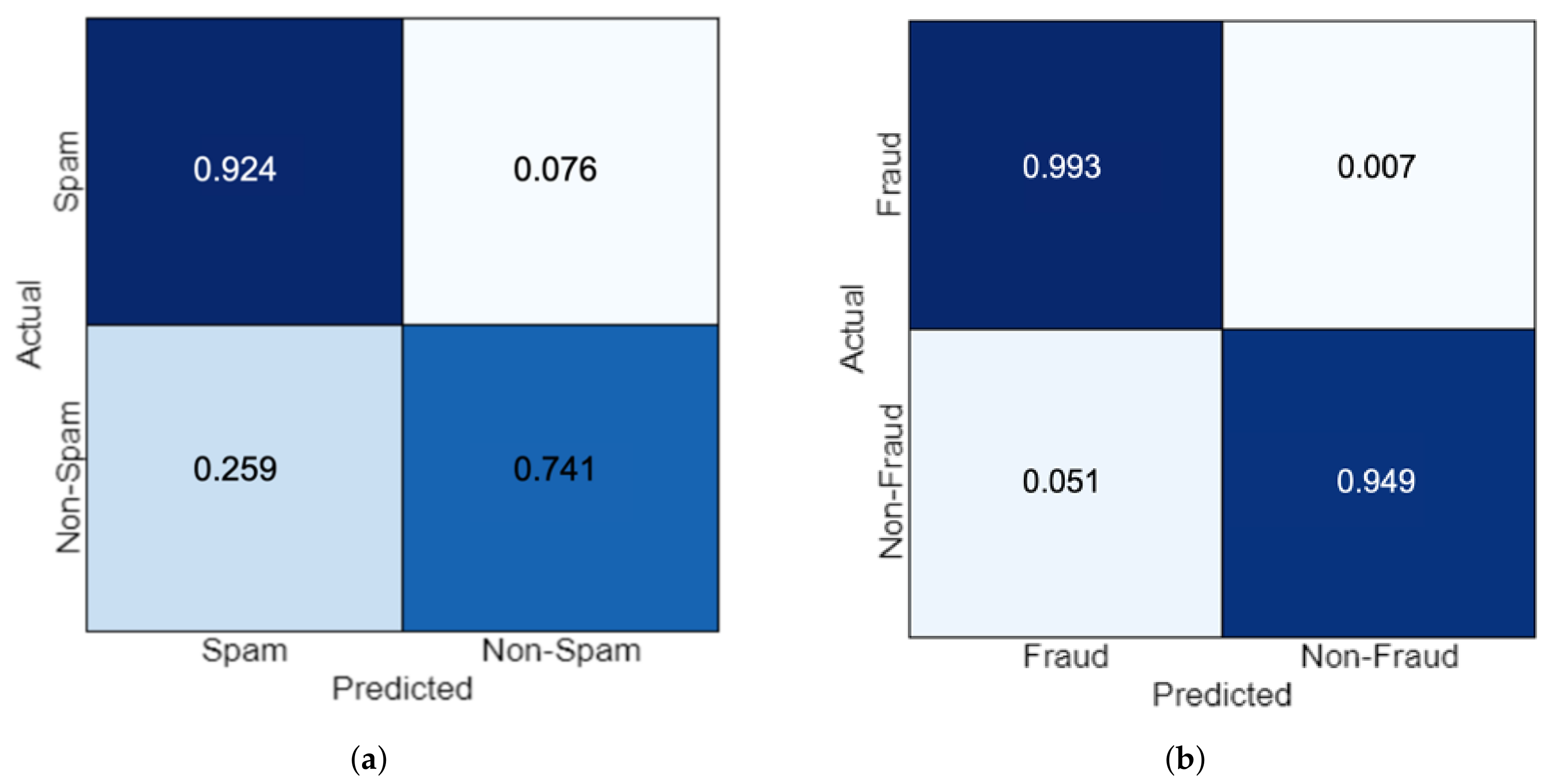
5.1. Spam Model Results
5.2. Fraud Model Results
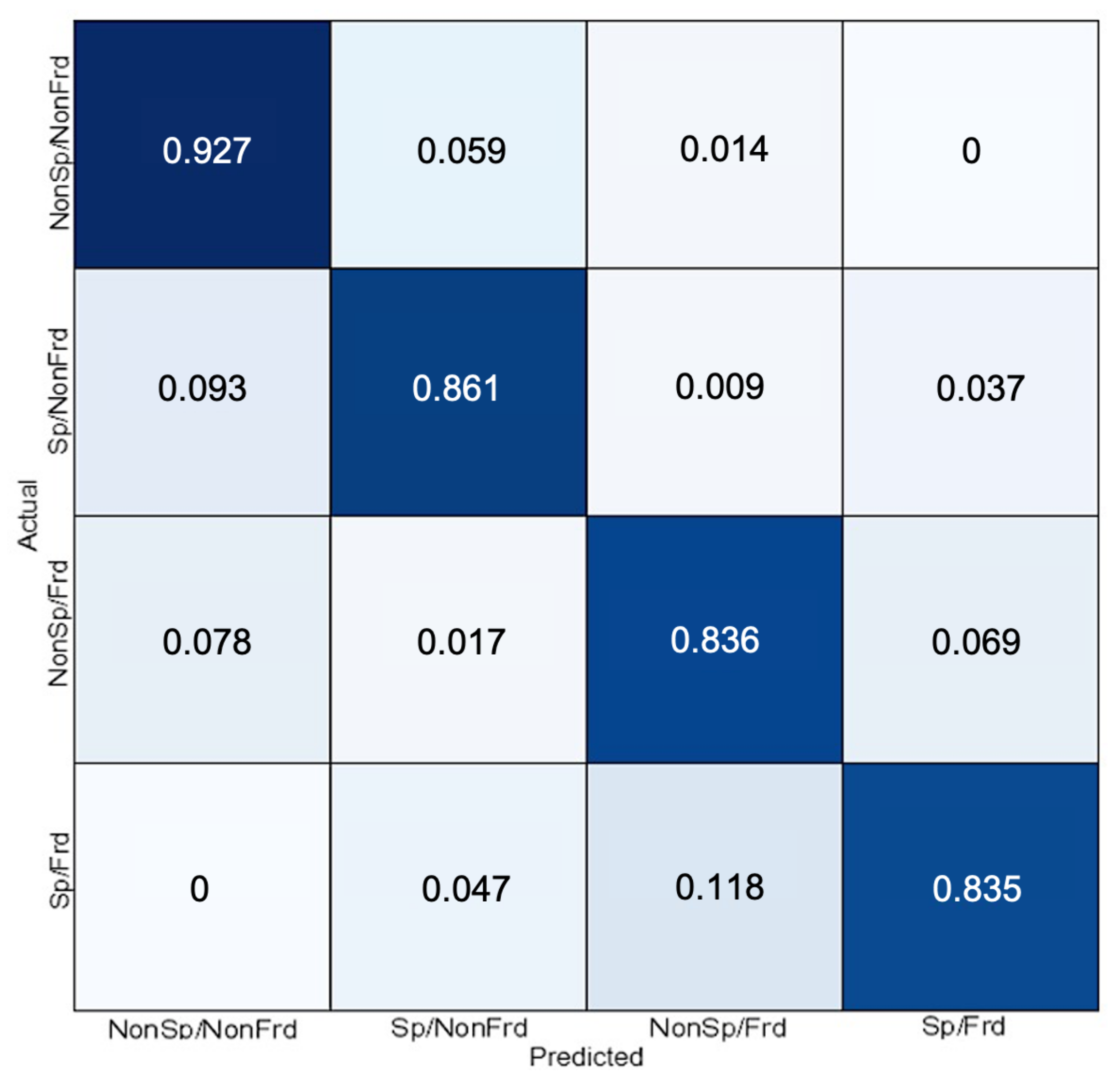
5.3. Joint Model Results
5.4. Cross-Datasets Evaluation of the Joint Model Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chiew, K.L.; Yong, K.S.C.; Tan, C.L. A survey of phishing attacks: Their types, vectors and technical approaches. Expert Syst. Appl. 2018, 106, 1–20. [Google Scholar] [CrossRef]
- Curtis, S.R.; Rajivan, P.; Jones, D.N.; Gonzalez, C. Phishing attempts among the dark triad: Patterns of attack and vulnerability. Comput. Hum. Behav. 2018, 87, 174–182. [Google Scholar] [CrossRef]
- Parsons, K.; Butavicius, M.; Delfabbro, P.; Lillie, M. Predicting susceptibility to social influence in phishing emails. Int. J. Hum. Comput. Stud. 2019, 128, 17–26. [Google Scholar] [CrossRef]
- Laorden, C.; Ugarte-Pedrero, X.; Santos, I.; Sanz, B.; Nieves, J.; Bringas, P.G. Study on the effectiveness of anomaly detection for spam filtering. Inf. Sci. 2014, 277, 421–444. [Google Scholar] [CrossRef]
- Ding, Y.; Luktarhan, N.; Li, K.; Slamu, W. A keyword-based combination approach for detecting phishing webpages. Comput. Secur. 2019, 84, 256–275. [Google Scholar] [CrossRef]
- Chiew, K.L.; Tan, C.L.; Wong, K.; Yong, K.S.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Gao, L.; Zhou, S.; Guan, J. Effectively classifying short texts by structured sparse representation with dictionary filtering. Inf. Sci. 2015, 323, 130–142. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, R.; Ji, D. A topic-enhanced word embedding for Twitter sentiment classification. Inf. Sci. 2016, 369, 188–198. [Google Scholar] [CrossRef]
- Stein, R.A.; Jaques, P.A.; Valiati, J.F. An analysis of hierarchical text classification using word embeddings. Inf. Sci. 2019, 471, 216–232. [Google Scholar] [CrossRef]
- Nalisnick, E.; Mitra, B.; Craswell, N.; Caruana, R. Improving document ranking with dual word embeddings. In Proceedings of the 25th International Conference Companion on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 83–84. [Google Scholar]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, Lille, France, 12 July 2015; pp. 957–966. [Google Scholar]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Dada, E.G.; Bassi, J.S.; Chiroma, H.; Adetunmbi, A.O.; Ajibuwa, O.E. Machine learning for email spam filtering: Review, approaches and open research problems. Heliyon 2019, 5, e01802. [Google Scholar] [CrossRef] [PubMed]
- Jain, G.; Sharma, M.; Agarwal, B. Spam detection in social media using convolutional and long short term memory neural network. Ann. Math. Artif. Intell. 2019, 85, 21–44. [Google Scholar] [CrossRef]
- Alberto, T.C.; Lochter, J.V.; Almeida, T.A. Tubespam: Comment spam filtering on youtube. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 138–143. [Google Scholar]
- Nizamani, S.; Memon, N.; Glasdam, M.; Nguyen, D.D. Detection of fraudulent emails by employing advanced feature abundance. Egypt. Inform. J. 2014, 15, 169–174. [Google Scholar] [CrossRef]
- Guan, W.; Gao, H.; Yang, M.; Li, Y.; Ma, H.; Qian, W.; Yang, X. Analyzing user behavior of the micro-blogging website Sina Weibo during hot social events. Phys. A Stat. Mech. Its Appl. 2014, 395, 340–351. [Google Scholar] [CrossRef]
- Serrano-Guerrero, J.; Olivas, J.A.; Romero, F.P.; Herrera-Viedma, E. Sentiment analysis: A review and comparative analysis of web services. Inf. Sci. 2015, 311, 18–38. [Google Scholar] [CrossRef]
- Zhao, Y.; Kou, G.; Peng, Y.; Chen, Y. Understanding influence power of opinion leaders in e-commerce networks: An opinion dynamics theory perspective. Inf. Sci. 2018, 426, 131–147. [Google Scholar] [CrossRef]
- Rathore, S.; Sharma, P.K.; Loia, V.; Jeong, Y.S.; Park, J.H. Social network security: Issues, challenges, threats, and solutions. Inf. Sci. 2017, 421, 43–69. [Google Scholar] [CrossRef]
- Urena, R.; Kou, G.; Dong, Y.; Chiclana, F.; Herrera-Viedma, E. A review on trust propagation and opinion dynamics in social networks and group decision making frameworks. Inf. Sci. 2019, 478, 461–475. [Google Scholar] [CrossRef]
- Yu, W.D.; Nargundkar, S.; Tiruthani, N. Phishcatch-a phishing detection tool. In Proceedings of the 2009 33rd Annual IEEE International Computer Software and Applications Conference, Washington, DC, USA, 20–24 July 2009; pp. 451–456. [Google Scholar]
- Sun, X.X.; Dai, S.; Wang, Y.X. A platform for automatic identification of phishing URLs in mobile text messages. J. Phys. Conf. Ser. 2018, 1087, 042009. [Google Scholar] [CrossRef]
- Hu, W.; Du, J.; Xing, Y. Spam filtering by semantics-based text classification. In Proceedings of the 2016 Eighth International Conference on Advanced Computational Intelligence (ICACI), Chiang Mai, Thailand, 14–16 February 2016; pp. 89–94. [Google Scholar]
- Harikrishnan, N.B.; Vinayakumar, R.; Soman, K.P. A machine learning approach towards phishing Email detection. In Proceedings of the Anti-Phishing Pilot at ACM International Workshop on Security and Privacy Analytics (IWSPA AP), Tempe, AZ, USA, 21 March 2018; pp. 455–468. [Google Scholar]
- Sharmin, S.; Zaman, Z. Spam detection in social media employing machine learning tool for text mining. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 137–142. [Google Scholar]
- Varol, C.; Abdulhadi, H.M.T. Comparision of String Matching Algorithms on Spam Email Detection. In Proceedings of the 2018 International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT), Ankara, Turkey, 3–4 December 2018; pp. 6–11. [Google Scholar]
- Hassan, M.A.; Mtetwa, N. Feature Extraction and Classification of Spam Emails. In Proceedings of the 2018 5th International Conference on Soft Computing & Machine Intelligence (ISCMI), Nairobi, Kenya, 21–22 November 2018; pp. 93–98. [Google Scholar]
- Zareapoor, M.; Seeja, K.R. Feature extraction or feature selection for text classification: A case study on phishing email detection. Int. J. Inf. Eng. Electron. Bus. 2015, 7, 60. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Miao, D.; Wang, J. Three-way enhanced convolutional neural networks for sentence-level sentiment classification. Inf. Sci. 2019, 477, 55–64. [Google Scholar] [CrossRef]
- Yaghoobzadeh, Y.; Schutze, H. Multi-level representations for fine-grained typing of knowledge base entities. arXiv 2017, arXiv:1701.02025. Available online: www.arxiv.org/abs/1701.02025 (accessed on 10 January 2020).
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Advances in Neural information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NE, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Yih, W.T.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Ren, Y.; Ji, D. Neural networks for deceptive opinion spam detection: An empirical study. Inf. Sci. 2017, 385, 213–224. [Google Scholar] [CrossRef]
- Parwez, M.A.; Abulaish, M.; Jahiruddin, J. Multi-Label Classification of Microblogging Texts using Convolution Neural Network. IEEE Access 2019. [Google Scholar] [CrossRef]
- Rao, G.; Huang, W.; Feng, Z.; Cong, Q. LSTM with sentence representations for document-level sentiment classification. Neurocomputing 2018, 308, 49–57. [Google Scholar] [CrossRef]
- Alghoul, A.; Al Ajrami, S.; Al Jarousha, G.; Harb, G.; Abu-Naser, S.S. Email Classification Using Artificial Neural Network. Int. J. Acad. Dev. 2018, 2, 8–14. [Google Scholar]
- Yawen, W.; Fan, Y.; Yanxi, W. Research of Email Classification based on Deep Neural Network. In Proceedings of the 2018 Second International Conference of Sensor Network and Computer Engineering (ICSNCE 2018), Xi’an, China, 27–29 April 2018. [Google Scholar]
- Dhingra, A.; Mittal, S. Content based spam classification in twitter using multi-layer perceptron learning. Int. J. Latest Trends Eng. Technol. 2015, 5, 9–19. [Google Scholar]
- Deshmukh, J.S.; Tripathy, A.K. Mining multi domain text reviews using semi-supervised approach. In Proceedings of the 2016 IEEE International Conference on Engineering and Technology (ICETECH), Coimbatore, India, 17–18 March 2016; pp. 788–791. [Google Scholar]
- Ding, X.; Shi, Q.; Cai, B.; Liu, T.; Zhao, Y.; Ye, Q. Learning Multi-Domain Adversarial Neural Networks for Text Classification. IEEE Access 2019, 7, 40323–40332. [Google Scholar] [CrossRef]
- Jiang, W.; Gao, H.; Lu, W.; Liu, W.; Chung, F.L.; Huang, H. Stacked Robust Adaptively Regularized Auto-Regressions for Domain Adaptation. IEEE Trans. Knowl. Data Eng. 2018, 31, 561–574. [Google Scholar] [CrossRef]
- Hua, Y. Understanding BERT performance in propaganda analysis. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, Hong Kong, China, 3–7 November 2019; pp. 135–138. [Google Scholar]
- Aggarwal, A.; Chauhan, A.; Kumar, D.; Mittal, M.; Verma, S. Classification of Fake News by Fine-tuning Deep Bidirectional Transformers based Language Model. In EAI Endorsed Transactions on Scalable Information Systems Online First; EAI: Ghent, Belgium, 2020. [Google Scholar]
- Rusk, N. Deep learning. Nat. Methods 2016, 13, 35. [Google Scholar] [CrossRef]
- Kulkarni, A.; Shivananda, A. Converting text to features. In Natural Language Processing Recipes; Apress: Berkeley, CA, USA, 2019; pp. 67–96. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. Available online: ww.arxiv.org/abs/1301.3781 (accessed on 10 January 2020).
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- YouTube Spam Collection. Available online: http://dcomp.sor.ufscar.br/talmeida/youtubespamcollection/ (accessed on 15 November 2019).
- Radev, D. CLAIR Collection of Fraud Email, ACL Data and Code Repository 2008, ADCR2008T001. Available online: http://aclweb.org/aclwiki (accessed on 21 March 2019).
- Jianqiang, Z.; Xiaolin, G. Comparison research on text pre-processing methods on twitter sentiment analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar] [CrossRef]
- She, X.; Zhang, D. Text Classification Based on Hybrid CNN-LSTM Hybrid Model. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 185–189. [Google Scholar]
- Li, C.; Zhan, G.; Li, Z. News Text Classification Based on Improved Bi-LSTM-CNN. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 890–893. [Google Scholar]
- Xiao, L.; Wang, G.; Zuo, Y. Research on Patent Text Classification Based on Word2Vec and LSTM. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 71–74. [Google Scholar]
- Trausan-Matu, S. Intertextuality detection in literary texts using Word2Vec models. In Proceedings of the 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 8–10 October 2017; pp. 262–265. [Google Scholar]
- Xu, J.; Cai, Y.; Wu, X.; Lei, X.; Huang, Q.; Leung, H.F.; Li, Q. Incorporating context-relevant concepts into convolutional neural networks for short text classification. In Neurocomputing; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Zheng, Y.; Haixun, W.; Xuemin, L.; Min, W. Understanding short texts through semantic enrichment and hashing. IEEE Trans. Knowl. Data Eng. 2015, 28, 566–579. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Applied Method | Task | Results | Application |
|---|---|---|---|---|
| Dhingra & Mittal [40] | Multi-Layer Perceptron | Spam classification in tweets from Twitter. MLP had not been applied to tweets for this purpose before | 82% accuracy, 75% precision, 81% recall | MLP outperformed Naïve Bayes in classification of tweets as spam |
| Jain et al. [14] | CNN-LSTM based architecture | Detecting spam in noisy and short-text messages such as those found in social media | 95% accuracy, 95% precision, 98% recall, 97% F1-score in tweet spam detection | High performing method for spam detection in short texts using machine learning |
| Ding et al. [5] | Heuristic Rule and Logistic Regression | Detecting phishing websites based on URLs | 98% accuracy, 98% recall, 98% F1-score, 97% precision | A method to detect phishing websites through obfuscation techniques processing |
| Chiew et al. [6] | Random Forest | Preprocessing data to perform spam classification in emails | 96.17% accuracy | Hybrid Ensemble Feature Selection for preprocessing data that works best with Random Forest classifier |
| Hua [44] | BERT ensemble | Classifying propaganda texts at the sentence level | 63% precision, 69% recall, 66% F1-score | A set of illustrative experiments to understand the performance of BERT on propaganda classification |
| Aggarwal et al. [45] | BERT | Classifying text articles as fake news | 97% accuracy | A method for classifying fake news for long-text articles (avg. 731 words) |
| Parameter | Value |
|---|---|
| Word embedding dimension | 300 |
| Number of LSTM units | 128 |
| Dropout probability at embedding layer | 0.5 and 0.7 |
| Dropout probability at the output layer | 0.5 |
| L2 regularization rate | 0.5 |
| Early stopping min delta | 0.0001 |
| Number of epochs | 10, 20 and 30 |
| Padding length | 150, 207 and 400 |
| True Class 1 | True Class 2 | |
|---|---|---|
| Predicted Class 1 | TP (True Positive) | FP (False Positive) |
| Predicted Class 2 | FN (False Negative) | TN (True Negative) |
| Model | Classifier | Dataset | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Spam Model | SVM | Spam Dataset | 0.67 | 0.69 | 0.61 | 0.64 |
| Naïve Bayes | 0.69 | 0.67 | 0.75 | 0.71 | ||
| SGD | 0.66 | 0.81 | 0.42 | 0.56 | ||
| Fraud Model | SVM | Fraud Dataset | 0.55 | 0.55 | 0.72 | 0.62 |
| Naïve Bayes | 0.67 | 0.63 | 0.85 | 0.72 | ||
| SGD | 0.52 | 0.53 | 0.43 | 0.48 | ||
| Joint Model | SVM | Joint Dataset | 0.71 | 0.86 | 0.71 | 0.72 |
| Naïve Bayes | 0.77 | 0.85 | 0.75 | 0.78 | ||
| SGD | 0.73 | 0.80 | 0.72 | 0.74 |
| Model | Classifier | Dataset | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Spam Model | SVM | Spam test samples | 0.49 | 0.50 | 0.94 | 0.65 |
| Naïve Bayes | 0.56 | 0.52 | 0.82 | 0.67 | ||
| SGD | 0.45 | 0.52 | 0.76 | 0.59 | ||
| Joint Model | SVM | Spam test samples | 0.50 | 0.50 | 1.00 | 0.66 |
| Naïve Bayes | 0.58 | 0.52 | 0.88 | 0.67 | ||
| SGD | 0.47 | 0.55 | 0.79 | 0.60 | ||
| Fraud Model | SVM | Fraud test samples | 0.50 | 0.50 | 1.00 | 0.67 |
| Naïve Bayes | 0.53 | 0.52 | 0.89 | 0.70 | ||
| SGD | 0.50 | 0.52 | 0.89 | 0.69 | ||
| Joint Model | SVM | Fraud test samples | 0.54 | 0.50 | 1.00 | 0.68 |
| Naïve Bayes | 0.55 | 0.55 | 0.89 | 0.70 | ||
| SGD | 0.50 | 0.56 | 0.81 | 0.69 |
| Model | Dataset | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Spam Model | Spam test samples | 0.79 | 0.72 | 0.93 | 0.81 |
| Joint Model | 0.93 | 0.91 | 0.97 | 0.94 | |
| Fraud Model | Fraud test samples | 0.97 | 0.95 | 1.00 | 0.97 |
| Joint Model | 0.99 | 0.98 | 1.00 | 0.99 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baccouche, A.; Ahmed, S.; Sierra-Sosa, D.; Elmaghraby, A. Malicious Text Identification: Deep Learning from Public Comments and Emails. Information 2020, 11, 312. https://doi.org/10.3390/info11060312
Baccouche A, Ahmed S, Sierra-Sosa D, Elmaghraby A. Malicious Text Identification: Deep Learning from Public Comments and Emails. Information. 2020; 11(6):312. https://doi.org/10.3390/info11060312
Chicago/Turabian StyleBaccouche, Asma, Sadaf Ahmed, Daniel Sierra-Sosa, and Adel Elmaghraby. 2020. "Malicious Text Identification: Deep Learning from Public Comments and Emails" Information 11, no. 6: 312. https://doi.org/10.3390/info11060312
APA StyleBaccouche, A., Ahmed, S., Sierra-Sosa, D., & Elmaghraby, A. (2020). Malicious Text Identification: Deep Learning from Public Comments and Emails. Information, 11(6), 312. https://doi.org/10.3390/info11060312