Dew Computing and Asymmetric Security Framework for Big Data File Sharing



Abstract
1. Introduction
- We introduce dew computing for significant data sharing. The multi-cloud application requires a middleware to cooperate with each cloud service. A dew server can act as a middleware in this scheme. The dew server controls access control from users and monitors the availability of each file fragments (Section 4.2).
- We encrypt data as necessary, which would save processing costs and time. All data fragments are not encrypted. It depends on the data owner’s choice as to whether data is encrypted or not. Only sensitive fragments with standard encryption are encrypted. Additionally, we apply the fuzzy identity-based encryption as a security mechanism for sharing encryption keys among authorize users in the group. This method guarantees that even the attacker retrieves the risk items or data fragments. He or she cannot perform the decryption process efficiently (Section 4.3.2).
- We analyze the security in two scenarios: when the attacker knows the storage path of the file fragments and when the attacker does not know the storage path. The probability shows that, in both cases, our scheme has less opportunity for the attacker to retrieve all fragments on storage clouds (Section 5).
2. Related Works
3. Background
3.1. Multi-Cloud Storage
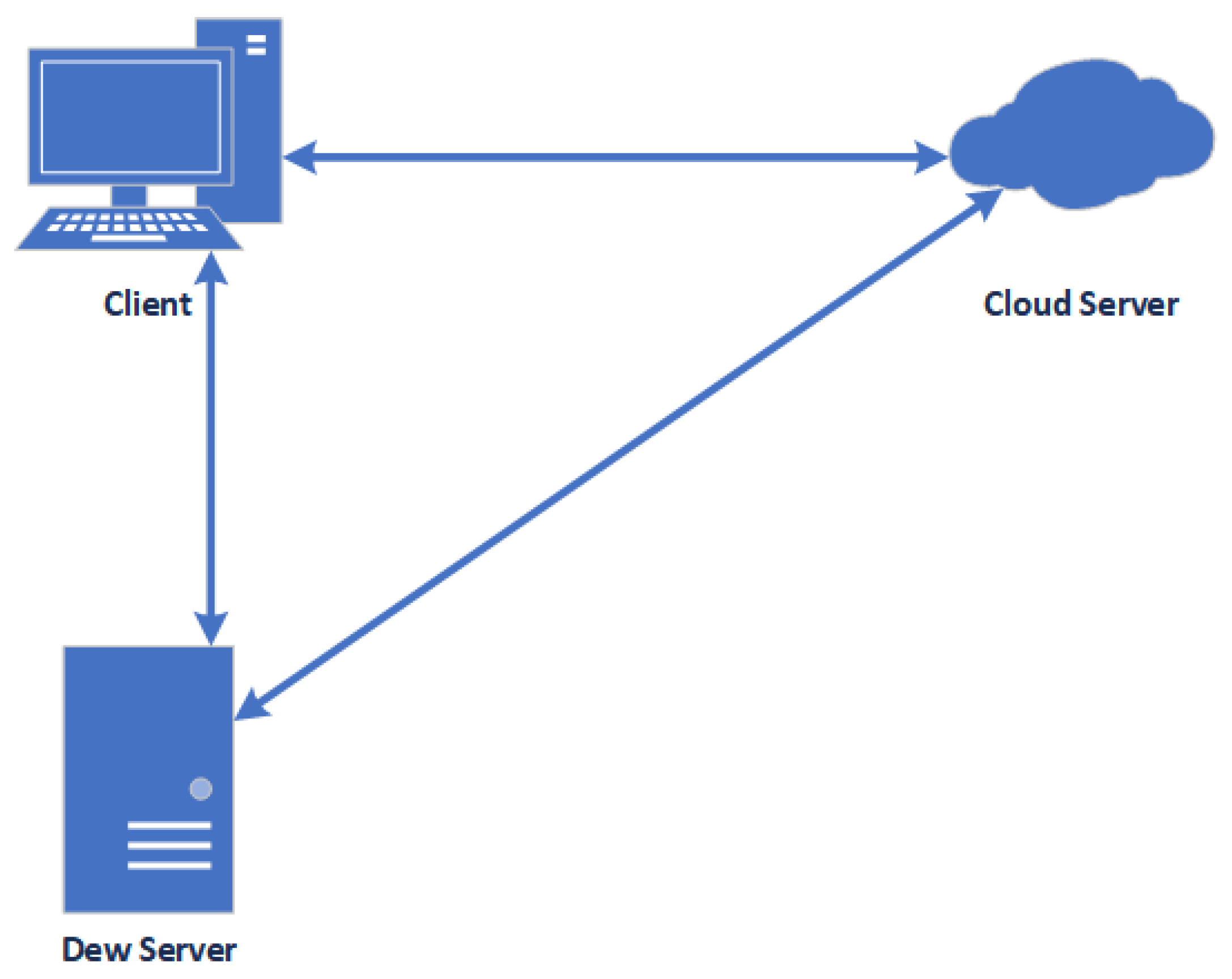
3.2. Dew Computing
3.2.1. Definition
3.2.2. Comparative Analysis of Fog and Dew Computing
3.2.3. Dew Computing Components
- A dew server is a lightweight web server. It provides service to only one client or user. Therefore, it does not require a high-performance machine.
- The storage capacity of the dew server is smaller than the storage capacity of the cloud storage provider. The data, stored on a dew server, belongs to a particular user.
- A dew server may die out immediately. The reason for disappearance may be caused by hardware failure or software virus infections.
- A vanished or damaged dew server can be restored quickly because all dew server data has a back up in the cloud servers.
- A dew server can be accessed although the internet connection is lost because it is operating on the local computer.
- The dewsite operates with a light load. Therefore, the dewsite is less complicated than the website.
- The dewsite uses open technology in its implementation rather than scripts that the website wants to conceal.
- A dewsite database content and capacity are limited.
- A new function will be added on both websites and dewsites synchronously.
3.3. Distance Base Encryption
- : The private key generator is the trusted third party that computes the private keys of biometrics for users. Users have to register their biometrics and are verified by the PKG. The PKG will generate private keys for users. The PKG receives the registered biometric and a master secret key as input. It then creates a vector from the recognition algorithm and a private key for the user from the key generation algorithm.
- : The encryptor is a message sender who wants to send a sensitive message to a receiver, where the message is encrypted with the receiver’s biometrics. First, the recognition algorithm is called to extract vector of this biometric. The encryption algorithm then encrypts the message using and a threshold value . The encryptor set , which means the encryptor wants the decryptor to have a private key vector close to under the official recognition. If , the encryptor wishes the decryptor to have a private key on a vector close to .
- : The decryptor receives a ciphertext sent from the encryptor and private key as input. If the distance between and is less than or equal to t, the decryptor can decrypt the given ciphertext. It is necessary to process further biometrics because both biometrics are transformed into vectors already.
- for all ,
- is a generator of
- It is efficient to compute for all .
4. Approach
4.1. Problem Formulation
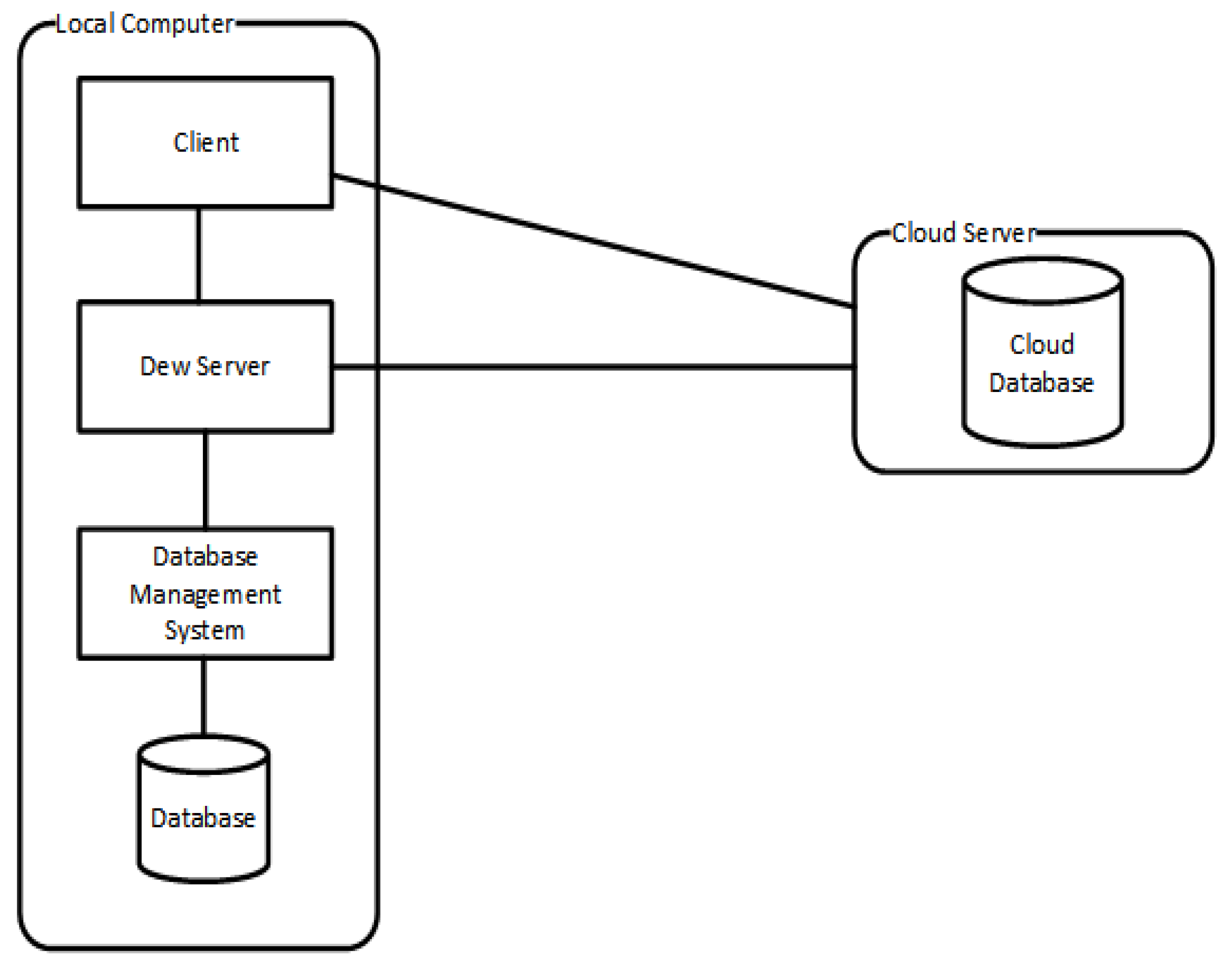
4.2. System Architecture
- Data owner: The data owner is the person who keeps the original data file and holds the authorization for users who want to access those fragments of a data file. The data owner sends an authorized token to the user. The token contains fragment information such as username, password, and location.
- Dew server: A dew server is a lightweight server that manages data fragments, accessing requests, and authorization token transfers, and temporarily stores some file pieces when CSPs are out off services.
- Cloud storage provider: The cloud storage provider offers storage service for customers. Each cloud storage provider has its policies, service offerings, costs, and connection methods.
- Key management unit: The secret key may be stored in the data owner’s local machine, a third party’s key management server, or a cloud provider data center. In our approach, the private key is on the owner’s premises so as to improve flexibility and enable file sharing.
- Data user: A data user is a person who needs to use the sharing file in multi-cloud storage. The user must be granted by data owner authorization from the data owner before accessing the file fragments in cloud storage.
- Data owner’s machine: All of the uploading operations are processed in this machine, including file slicing, fragments encryption, and fragment uploading. Additionally, the key management process is operated on the local machine.
- Data user’s machine: When all fragments are downloaded, the fragments are decrypted and merged in the user’s machine.
4.3. System Design
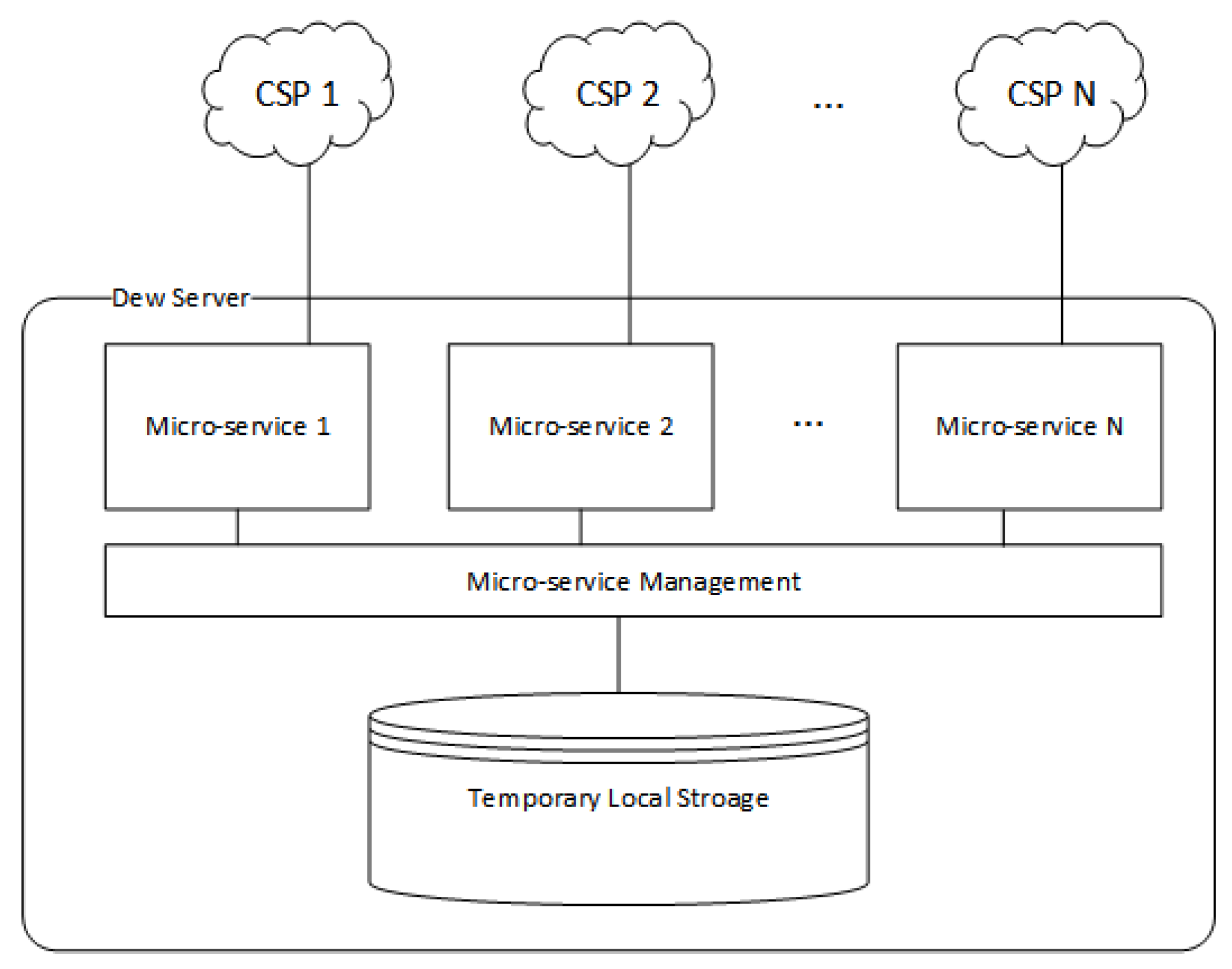
4.3.1. Dew Server
- User Management: The dew server monitors incoming requests whether they are from registered users or not. The dew server has a responsibility to register new users and create their private key.
- Fragment Monitoring: The dew server monitors file fragments’ availability. If some fragments do not appear in cloud storage, the dew server will notify the data owner about these missing fragments. The data owner then uploads the missing fragments to the corresponding cloud storage.
- Temporary Fragment Hosting: When cloud storage services are offline, the file fragment hosted on those cloud storage providers cannot be accessed. The data owner may upload the missing fragments to the dew server. The users are switched to download from temporary storage until the CSPs are online again. However, the dew server does not contain complete fragments due to the size of the whole file is more extensive than the dew server storage space. It just temporarily host some file fragments.
4.3.2. Fragment Deployment
| Algorithm 1 File Splitting and Fragment Encryption |
| Input: Original file (F), owner’s secret key () |
| Output: File fragments () or Encrypted file fragments () |
| procedure FileSplitEncrypt |
| if then |
| Estimate file size |
| Divide file into fragments to an equal number of cloud storage providers (N) |
| Give fragments a file name based on the order of fragments on the owner’s machine |
| Encrypt each fragment by the AES algorithm with the owner’s secret key |
| return |
| else |
| Estimate file size |
| Divide file into fragments to an equal number of cloud storage providers |
| Give fragments a file name based on the order of fragments on the owner’s machine |
| return |
| end if |
| Upload each fragment to multi-cloud storage. |
| end procedure |
4.4. Cloud Selection
| Algorithm 2 File Merging and Reconstructing |
| Input: File Fragments () or Encrypted File Fragments (), Encrypted Secret key () |
| Output: Decrypted file fragments and merged to original File(F) |
| procedure FileMergeReconst |
| Get the fragment details and encrypted secret key () from the file owner |
| Decrypted to obtain |
| if then (Algorithm 3.) |
| Get secret key, |
| else |
| End procedure |
| end if |
| for each cloud storage i do |
| Search file fragment |
| Download file fragment ( or ) |
| end for |
| if then |
| for each fragment i do |
| Decrypt fragment by and obtain |
| end for |
| end if |
| Merge fragments to obtain original file F |
| Automatically remove file fragments and the secret key from the user’s machine |
| return Original file (F) |
| end procedure |
4.5. Fragment Retrieval and File Reconstruction
4.6. Secret Key Encryption and Decryption
| Algorithm 3 Key Communication. |
| procedure KeyCommunicate [30] |
| Setup: The setup algorithm takes as input the security parameter and distance parameters (). It returns a master public/secret key pair (). |
| KeyGen: The key generation algorithm takes as input the data owner secret key and a user’s biometric n-length vector . The alogirthm then returns a private key for . |
| Encryption: The encryption algorithm uses , an n-length vector , a threshold value t, and a message M. The result is ciphertext, En[]. |
| Decryption: The input of decryption are ciphertext (), the master public key (), and the private key . |
| if then |
| The decryption is successful: return message M. |
| else |
| The decryption fails, and the procedure stops. |
| end procedure |
5. Analysis
5.1. Security Analysis
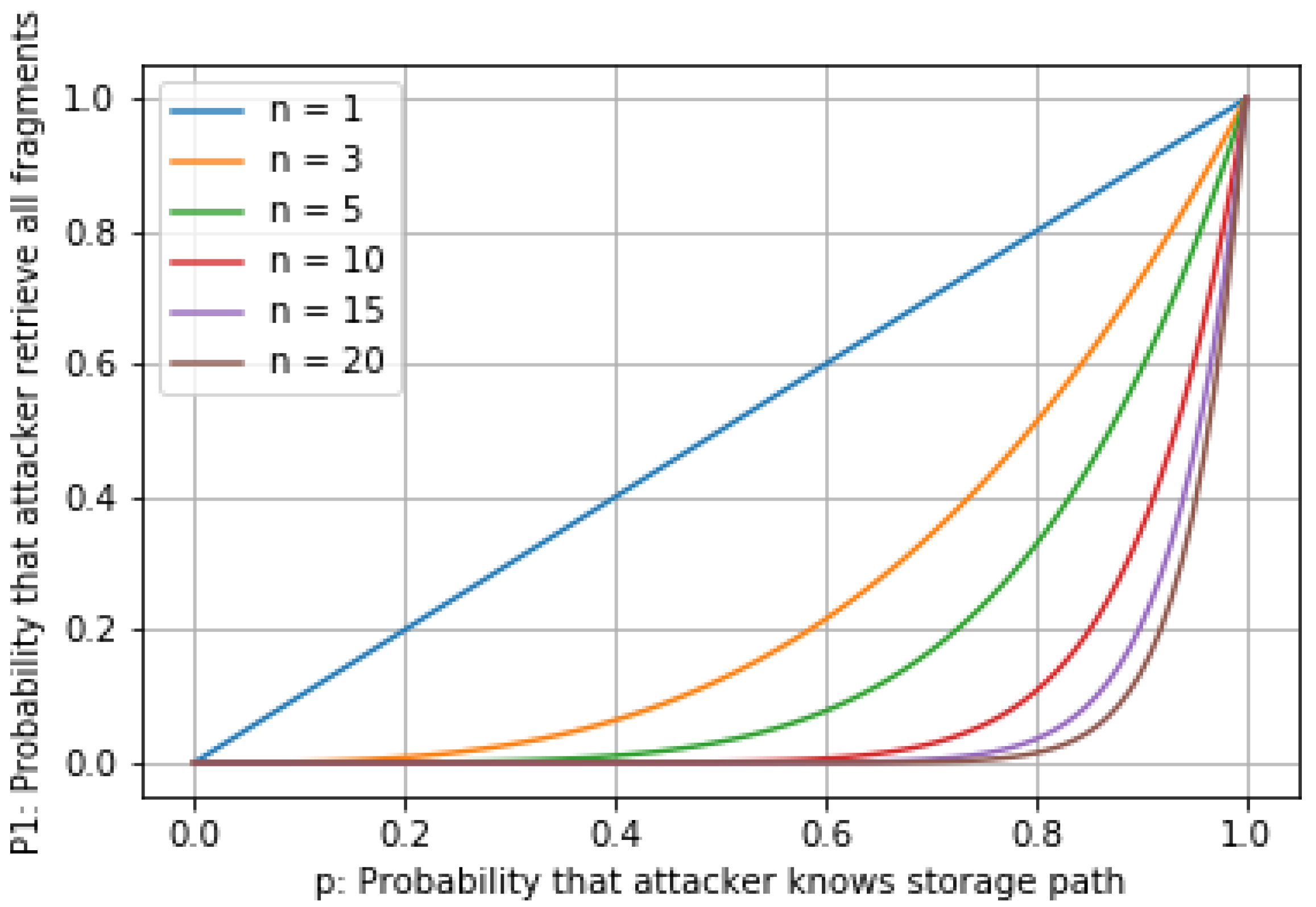
5.1.1. Attacker Knows the Storage Path
5.1.2. Attacker Does Not Know the Storage Path
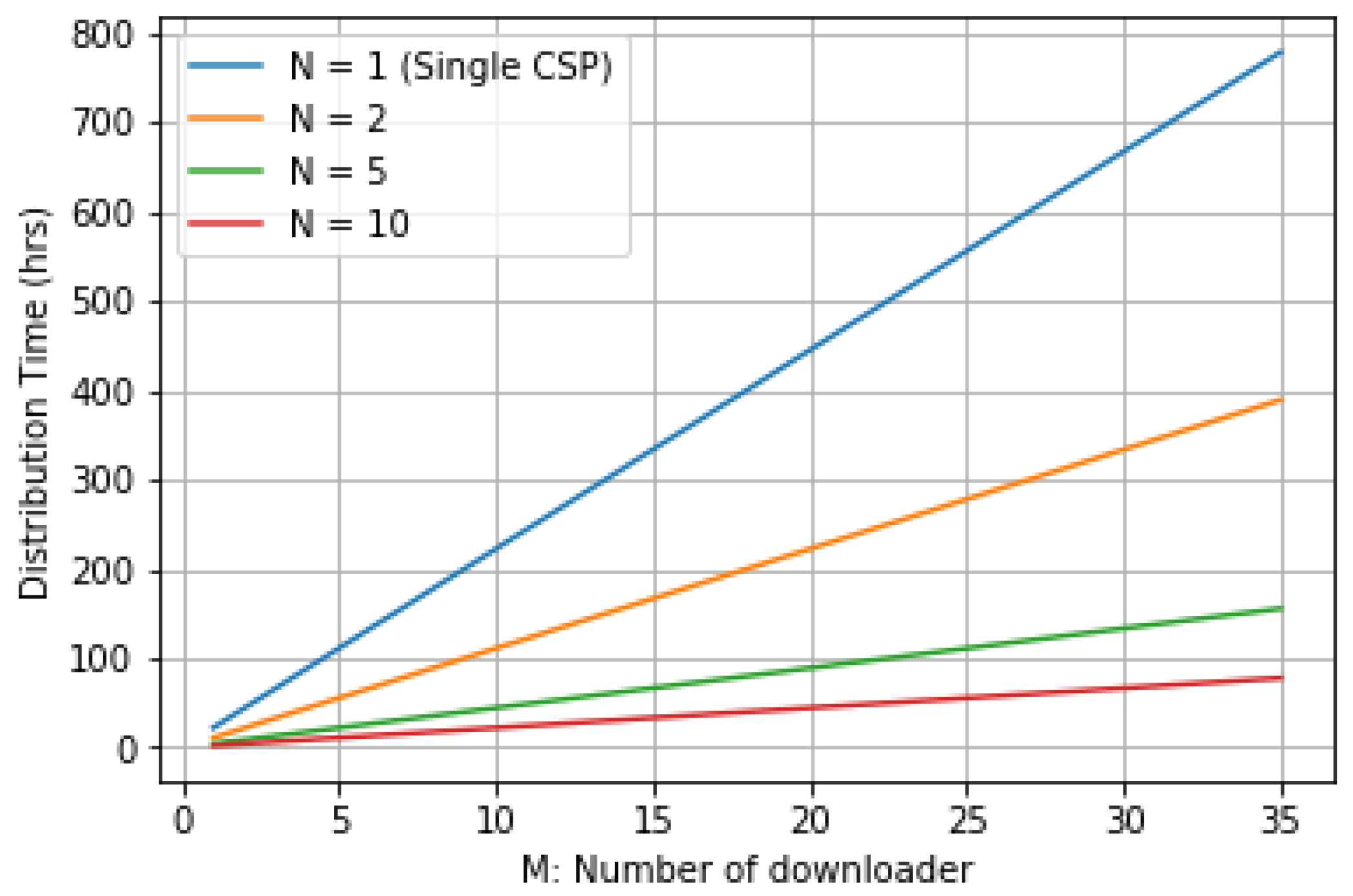
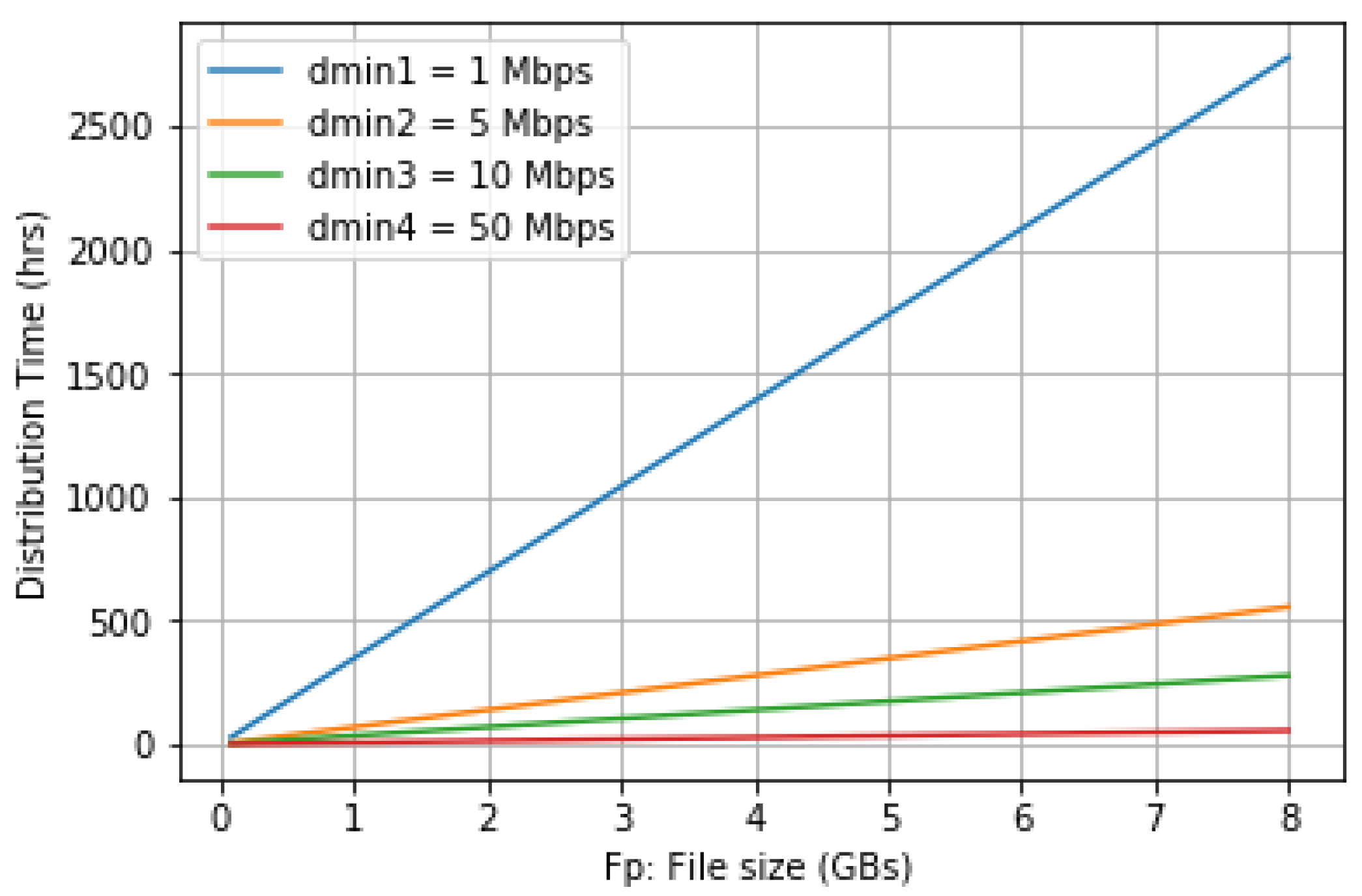
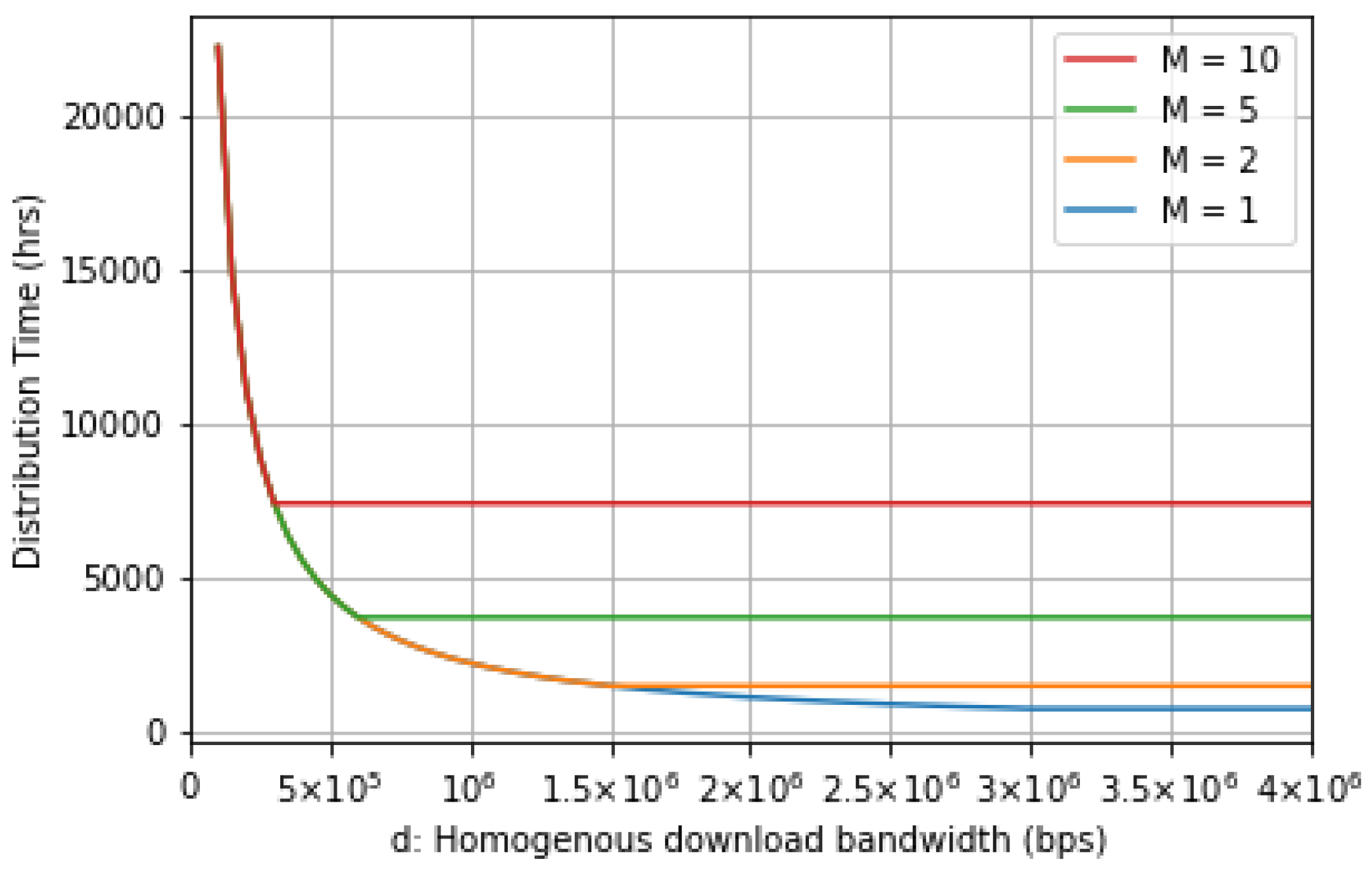
5.2. Performance Analysis
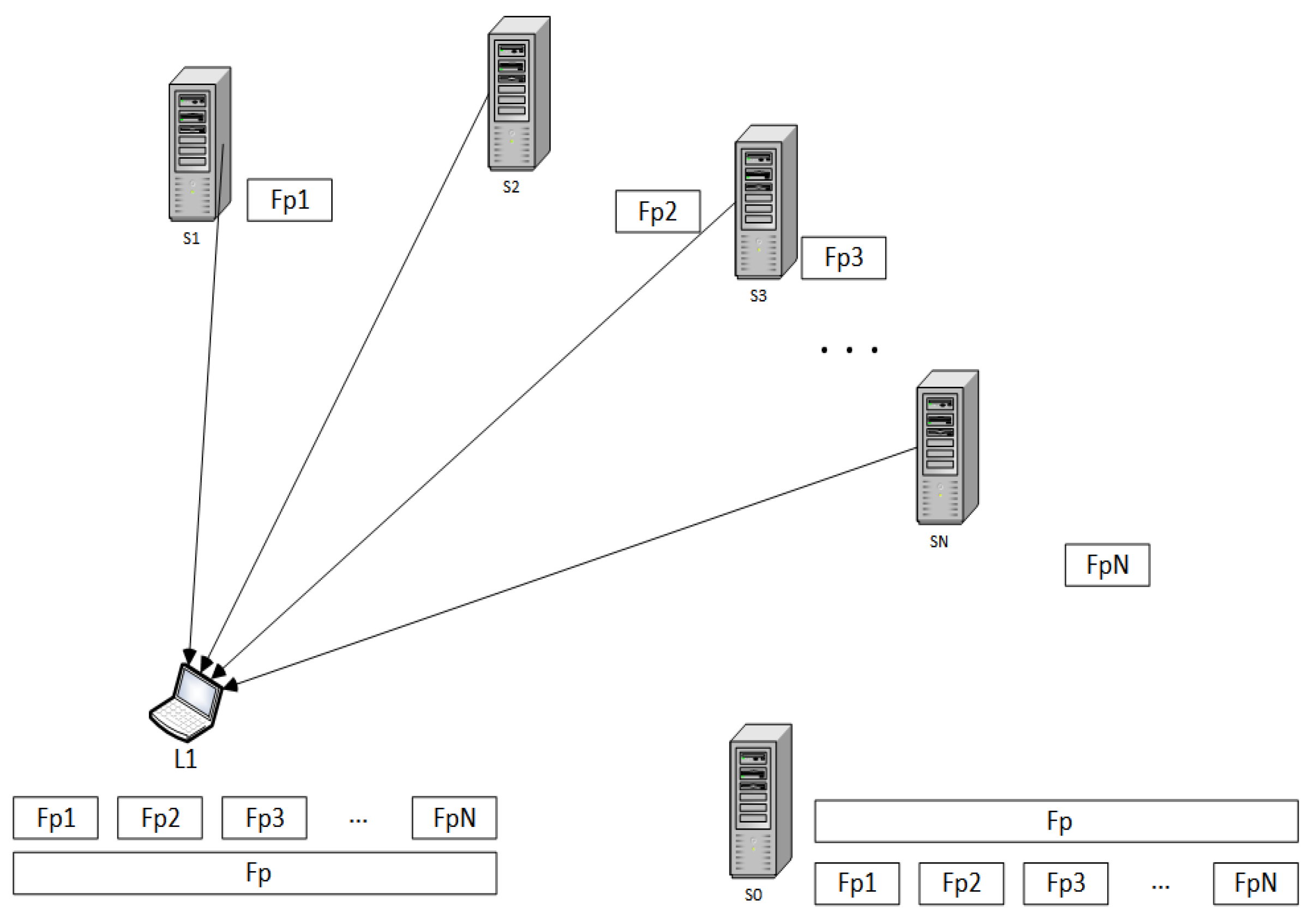
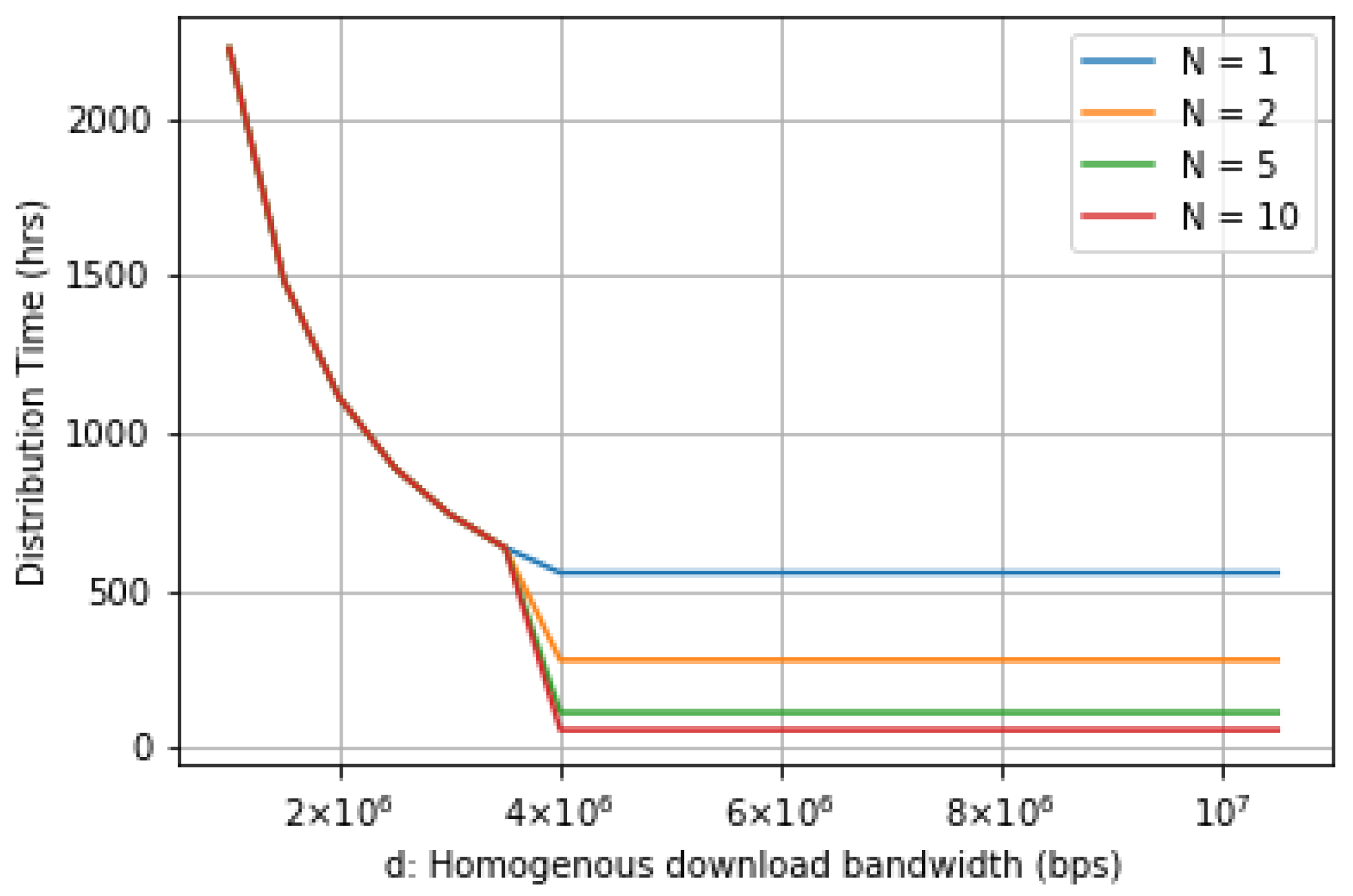
- The bandwidth bottlenecks are not in the internet heart. They are only at the access end of the Internet, which is uploading and downloading points.
- Both sets of seeders and leechers participate in file transferring until they completely retrieve all file fragments. There is no extra join or leaving companions between the process.
- Seeders have a constant upload capacity. In addition, leechers have a constant download capacity.
- At the first step, all seeders save all file fragments, while the leechers contain none of them.
- Leechers focus only on downloading interested file fragments during the file transfer. Leechers do not cooperate in downloading other irrelevant files.
- the set of seeders is ;
- the set of leeachers is ;
- the number of seeder ;
- the number of leecher ;
- for the set of seeder set S, is the aggregate upload capacity, where ;
- for the set of leecher L, is the minimum download capacity, where
- for subset , is the minimum distribution time of leechers in subset
- Case 1:
- Case 2:
- Case 1:
- Case 2:
6. Evaluation
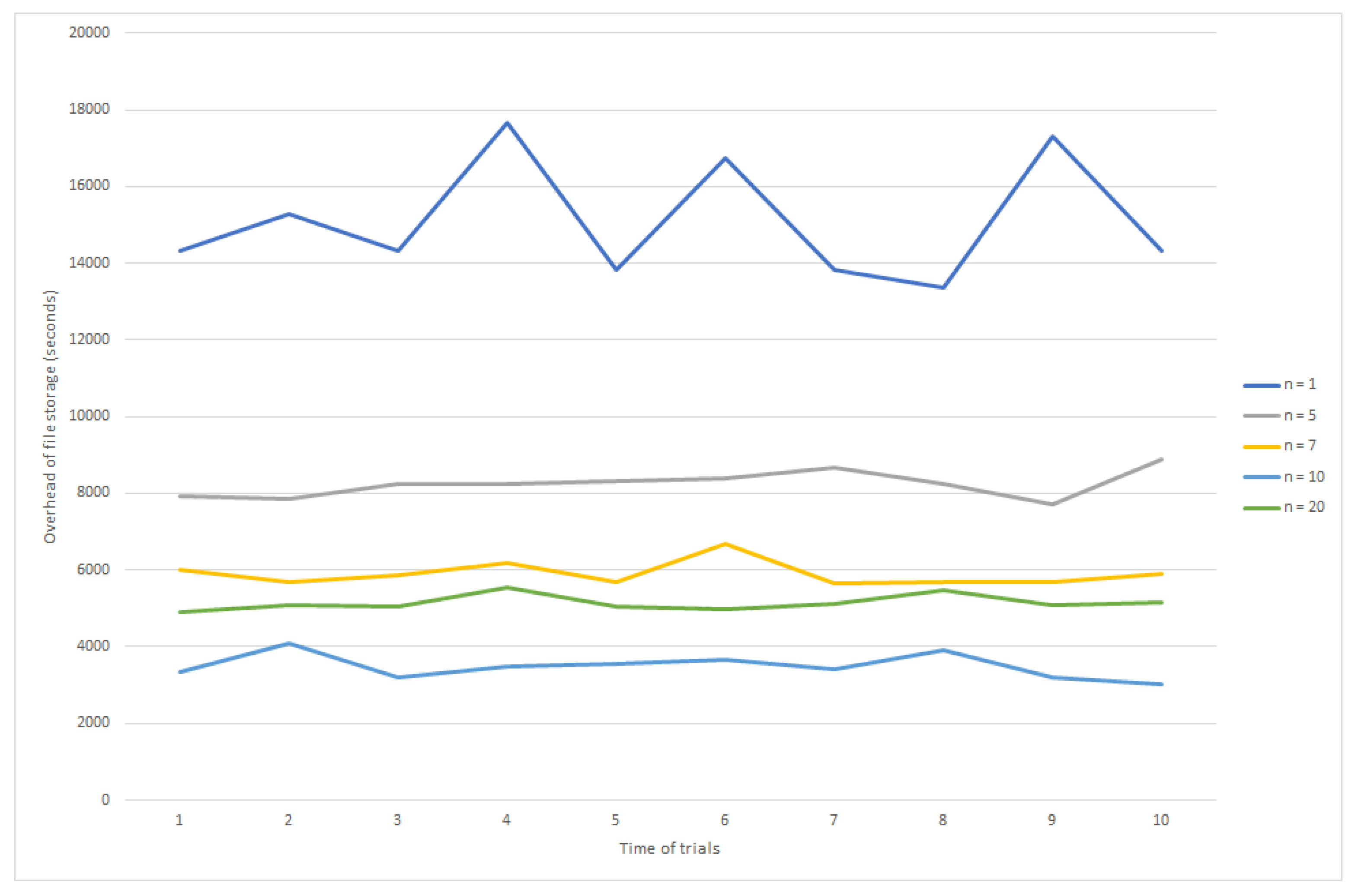
6.1. Security Evaluation
6.2. Distribution Time Evaluation
7. Simulation
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Subashini, S.; Veeraruna, K. A survey on security issues in service delivery models of cloud computing. J. Netw. Comput. Appl. 2011, 34, 1–11. [Google Scholar] [CrossRef]
- Saurabh, S.; Young Sik, J.; Jong Hyuk, P. A survey on cloud computing security: Issues, threats, and solutions. J. Netw. Comput. Appl. 2016, 75, 200–222. [Google Scholar]
- Hui Shyong, Y.; Xiao Shen, P.; Hoon Jae, L.; Hyotaek, L. Leveraging client-side storage techniques for enhanced use of multiple consumer cloud storage services on resource-constrained mobile devices. J. Netw. Comput. Appl. 2016, 43, 142–156. [Google Scholar]
- Subramanian, K.; Leo, J. Enhanced Security for Data Sharing in Multi Cloud Storage (SDSMC). Int. J. Adv. Comput. Sci. Appl. 2017, 8, 176–185. [Google Scholar]
- Abu-Libdeh, H.; Princehouse, L.; Weatherspoon, H. RACS: A case for cloud storage diversity. In Proceedings of the 1st ACM Symposium on Cloud Computing (SoCC 10), Indianapolis, IN, USA, 6–11 June 2010; pp. 229–240. [Google Scholar]
- Wang, Y. Definition and Categorization of Dew computing. Open J. Cloud Comput. 2016, 3, 1–7. [Google Scholar]
- Security Guidelines for Critical Areas of Focus in Cloud Computing v3.0. Available online: https://cloudsecurityalliance.org/artifacts/security-guidance-or-critical-areas-of-focus-in-cloud-computing-v3/ (accessed on 19 May 2020).
- Chen, D.; Li, X.; Wang, L.; Khan, S.U.; Wang, J.; Zeng, K.; Cai, C. Fast and Scalable Multi-Way Analysis of Massive Neural Data. IEEE Trans. Comput. 2015, 64, 707–719. [Google Scholar] [CrossRef]
- Ali, M.; Dhamotharan, R.; Khan, E.; Khan, S.U.; Vasilakos, A.V.; Li, K.; Zomay, A.Y. SeDaSC: Secure Data Sharing in Clouds. IEEE Syst. J. 2017, 11, 395–404. [Google Scholar] [CrossRef]
- Plantard, T.; Susilo, W.; Zhang, Z. Fully Homomorphic Encryption Using Hidden Ideal Lattice. IEEE Trans. Inf. Forensics Secur. 2013, 8, 2127–2137. [Google Scholar] [CrossRef]
- Li, M.; Yu, S.; Zheng, Y.; Ren, K.; Lou, W. Scalable and Secure Sharing of Personal Health Records in Cloud Computing Using Attribute-Based Encryption. IEEE Trans Parallel Distrib. Syst. 2013, 24, 131–143. [Google Scholar] [CrossRef]
- Zhou, S.; Du, R.; Chen, J.; Deng, H.; Shen, J.; Zhang, H. SSEM: Secure, scalable and efficient multi-owner data sharing in clouds. China Commun. 2016, 13, 231–243. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory 2014, 6, 1–36. [Google Scholar] [CrossRef]
- Bowers, K.D.; Juels, A.; Oprea, A. HAIL: A High-Availability and Integrity Layer for Cloud Storage. In Proceedings of the 16th ACM Conference on Computer and Communications Security (CCS 09), Chicago, IL, USA, 9–13 November 2009; pp. 187–198. [Google Scholar]
- Bessani, A.; Correia, M.; Quaresma, B.; André, F.; Sousa, P. DEPSKY: Dependable and Secure Storage in a Cloud-of-Clouds. ACM Trans. Storage 2013, 9, 1–33. [Google Scholar] [CrossRef]
- Su, M.; Zhang, L.; Wu, Y.; Chen, K.; Li, K. Systematic Data Placement Optimization in Multi-Cloud Storage for Complex Requirements. IEEE Trans. Comput. 2016, 65, 1964–1977. [Google Scholar] [CrossRef]
- Subramanian, K.; John, F.L. Dynamic and secure unstructured data sharing in multi-cloud storage using the hybrid crypto-system. Int. J. Adv. Appl. Sci. 2018, 5, 15–23. [Google Scholar] [CrossRef]
- Nehe, S.; Vaidya, M.B. Data security using data slicing over storage clouds. In Proceedings of the IEEE International Conference on Information Processing (ICIP 2015), Pune, Maharashtra, India, 16–19 December 2015; pp. 322–325. [Google Scholar]
- Bucur, V.; Dehelean, C.; Miclea, L. Object storage in the cloud and multi-cloud: State of the art and the research challenges. In Proceedings of the 2018 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR 2018), Cluj-Napoca, Romania, 24–26 May 2018; pp. 1–6. [Google Scholar]
- Sánchez, D.; Batet, M. Privacy-preserving data outsourcing in the cloud via semnatic data splitting. Comput. Commun. 2017, 110, 187–201. [Google Scholar] [CrossRef]
- The Initial Definition of Dew Computing. Available online: http://www.dewcomputing.org/index.php/2015/11/10/the-initial-definition-of-dew-computing/ (accessed on 12 January 2020).
- Ray, P.P. An Introduction to Dew Computing: Definition, Concept and Implication. IEEE Access 2017, 6, 723–737. [Google Scholar] [CrossRef]
- Longo, M.; Hirsch, M.; Mateos, C.; Zunino, A. Towards Integrating Mobile Devices into Dew Computing: A Model for Hour-Wise Prediction of Energy Availability. Information 2019, 10, 86. [Google Scholar] [CrossRef]
- Vaquero, L.M.; Rodero-Merino, L. Finding your way in the fog: Towards a comprehensive definition of fog computing. ACM SIGCOMM Comput. Commu. Rev. 2014, 44, 27–32. [Google Scholar] [CrossRef]
- Alessio, B.; Luigi, G.; Giorgio, V. Cloud, fog, and dew robotics: Architectures for next generation applications. In Proceedings of the 7th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud 2019), Newark, CA, USA, 4–9 April 2019; pp. 16–23. [Google Scholar]
- Tushar, M.; Himanshu, A. Cloud-fog-dew architecture for refined driving assistance: The complete service computing ecosystem. In Proceedings of the IEEE 17th International Conference on Ubiquitous Wireless Broadband (ICUWB 2017), Salamanca, Spain, 12–15 September 2017; pp. 1–7. [Google Scholar]
- Skala, K.; Davidovic, D.; Afgan, E.; Sovic, I.; Sojat, Z. Scalable Distributed Computing Hierarchy: Cloud, Fog and Dew Computing. Open J. Cloud Comput. 2015, 2, 16–24. [Google Scholar]
- Wang, Y. The Relationships among Cloud Computing, Fog Computing, and Dew Computing. Available online: http://www.dewcomputing.org/index.php/2015/11/12/the-relationships-among-cloud-computing-fog-computing-and-dew-computing/ (accessed on 19 May 2020).
- Wang, Y.; Pan, Y. Cloud-dew architecture: Realizing the potential of distributed database systems in unreliable networks. In Proceedings of the International Conference on Parallel and Distributed Processing Techniques and Applications, Athens, Greece, 27–30 July 2015; pp. 85–89. [Google Scholar]
- Guo, F.; Susilo, W.; Mu, Y. Distance-based encryption: How to embed fuzziness in biometric-based encryption. IEEE Trans. Inf. Forensics Secur. 2016, 11, 247–257. [Google Scholar] [CrossRef]
- Li, Y.; Gai, K.; Qiu, L.; Qiu, M.; Zhao, H. Intelligent cryptography approach for secure distributed big data storage in cloud computing. Inf. Sci. 2017, 387, 103–115. [Google Scholar] [CrossRef]
- Gai, K.; Qiu, M.; Zhao, H. Security-Aware Efficient Mass Distributed Storage Approach for Cloud Systems in Big Data. In Proceedings of the IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 140–145. [Google Scholar]
- Edward, F.D.; Shuhui, Y. Doing More with the Dew: A New Approach to Cloud-Dew Architecture. Open J. Cloud Comput. 2016, 3, 8–19. [Google Scholar]
- Hongbing, C.; Chunming, R.; Kai, H.; Weihong, W.; Yanyan, L. Secure big data storage and sharing scheme for cloud tenants. China Commun. 2015, 12, 106–115. [Google Scholar]
- Suwansrikham, P.; She, K. Asymmetric Secure Storage Scheme for Big Data on Multiple Cloud Providers. In Proceedings of the 4th IEEE International Conference on Big Data Security on Cloud (BigDataSecurity 2018), Omaha, NE, USA, 3–5 May 2018; pp. 121–125. [Google Scholar]
- Kumar, R.; Ross, K. Peer-Assisted File Distribution: The Minimum Distribution Time. In Proceedings of the 1st IEEE Workshop on Hot Topics in Web Systems and Technologies, Boston, MA, USA, 13–14 November 2006; pp. 1–11. [Google Scholar]
- Meng, X.; Tsang, P.S.; Lui, K. Analysis of distribution time of multiple files in a P2P network. Comput. Netw. 2013, 57, 2900–2915. [Google Scholar] [CrossRef]
- Cristescu, G.; Dobrescu, R.; Chenaru, O.; Florea, G. Dew: A new edge computing component for distributed dynamic networks. In Proceedings of the 22nd International Conference on Control Systems and Computer Science (CSCS 2019), Bucharest, Romania, 28–30 May 2019; pp. 547–551. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computing Model | Origin | Features | Applications |
|---|---|---|---|
| Fog | Vice president of Cisco, in 2011 | Extends cloud computing to the edge of network | Latency-sensitive applications, large-scale distributed control systems, and geo-distributed applications |
| Dew | Wang in 2015 | Improve scalability [25] | Offline or local area computation [26] |
| Entity Name | Details |
|---|---|
| Username | For logging in to each cloud storage provider |
| Password | Authority code that corresponds to the username of a cloud storage provider |
| Directory | Location of each cloud that keeps file fragments |
| Integrity Value | Integrity value of each file fragment, e.g., MD5 |
| Configuration | No. of CSPs |
|---|---|
| Single CSP | 1 |
| Configuration 1 | 5 |
| Configuration 2 | 10 |
| Configuration 3 | 15 |
| Configuration 4 | 20 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suwansrikham, P.; Kun, S.; Hayat, S.; Jackson, J. Dew Computing and Asymmetric Security Framework for Big Data File Sharing. Information 2020, 11, 303. https://doi.org/10.3390/info11060303
Suwansrikham P, Kun S, Hayat S, Jackson J. Dew Computing and Asymmetric Security Framework for Big Data File Sharing. Information. 2020; 11(6):303. https://doi.org/10.3390/info11060303
Chicago/Turabian StyleSuwansrikham, Parinya, She Kun, Shaukat Hayat, and Jehoiada Jackson. 2020. "Dew Computing and Asymmetric Security Framework for Big Data File Sharing" Information 11, no. 6: 303. https://doi.org/10.3390/info11060303
APA StyleSuwansrikham, P., Kun, S., Hayat, S., & Jackson, J. (2020). Dew Computing and Asymmetric Security Framework for Big Data File Sharing. Information, 11(6), 303. https://doi.org/10.3390/info11060303