Machine Learning Based Sentiment Text Classification for Evaluating Treatment Quality of Discharge Summary


Abstract
1. Introduction
- A deep learning model with a combination of features consisting of word-embeddings, sentiment-shifter rules, sentiment based extracted knowledge, linguistic and statistical based extracted knowledge that has not been used before based on our literature review on the relevant studies.
- Meanwhile, we experimented with multiple strategies like statistical models, weighted principal component analysis (W-PCA), Chi-squared statistics (CSS), and weighted-support vector machine SVM that help us generate the specific lexicon.
- We have adopted an ELM as a multi-classification problem (positive, negative, and natural), by using multi-level of features with discharge summaries.
2. Related Work
2.1. Quality Evaluation for Discharge Summary
2.2. Sentiment Analysis
2.3. Deep Learning
3. The Challenge of the Text Classification Task
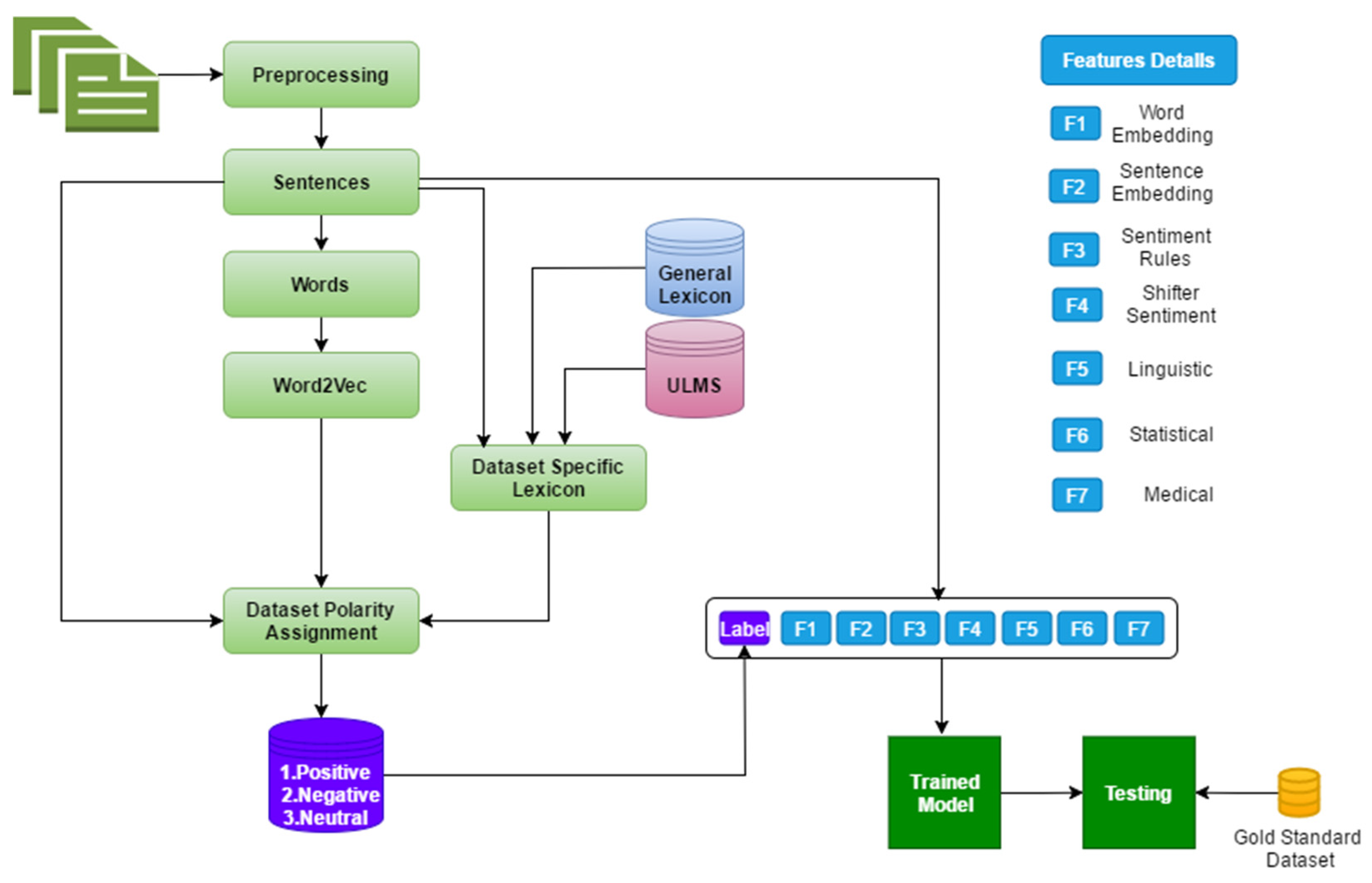
4. Proposed System
5. Experimental Results
5.1. Data Collection
5.2. Text Presentation and Feature Extraction
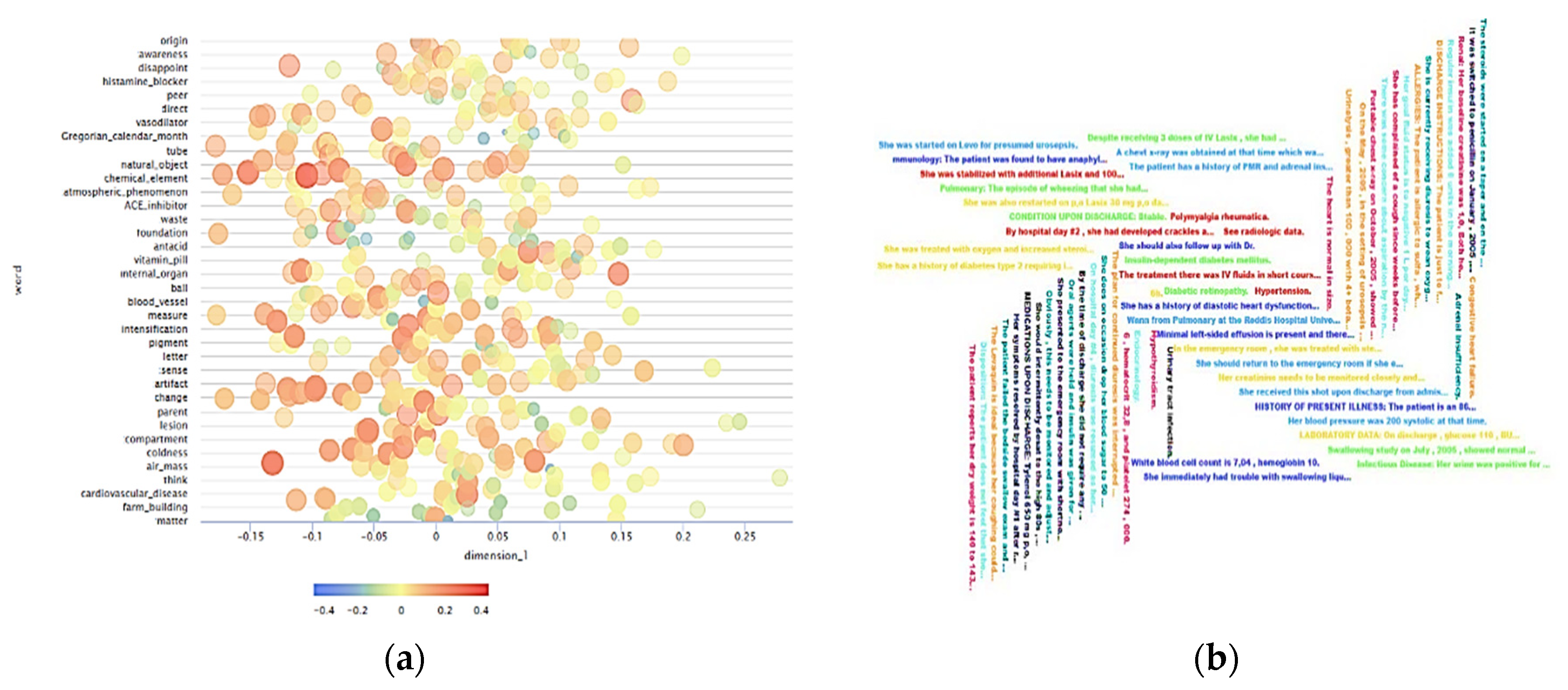
5.3. Lexicon Generation
- The first step begins by comparing our bag-of-words method with UMLS and SentWordNet lexicon based on semantic sentiment approach, which suffers from a drawback that it neglects a neutral score. To remedy this, we used part of speech (PENN) tagging system (JJ.* |NN.* |RB.* |VB.*) (https://cs.nyu.edu/grishman/jet/guide/PennPOS.html). Then constructed two lists of the words, the first one was our BOW, the second one is SentWordNet that was based on hypernyms technique.
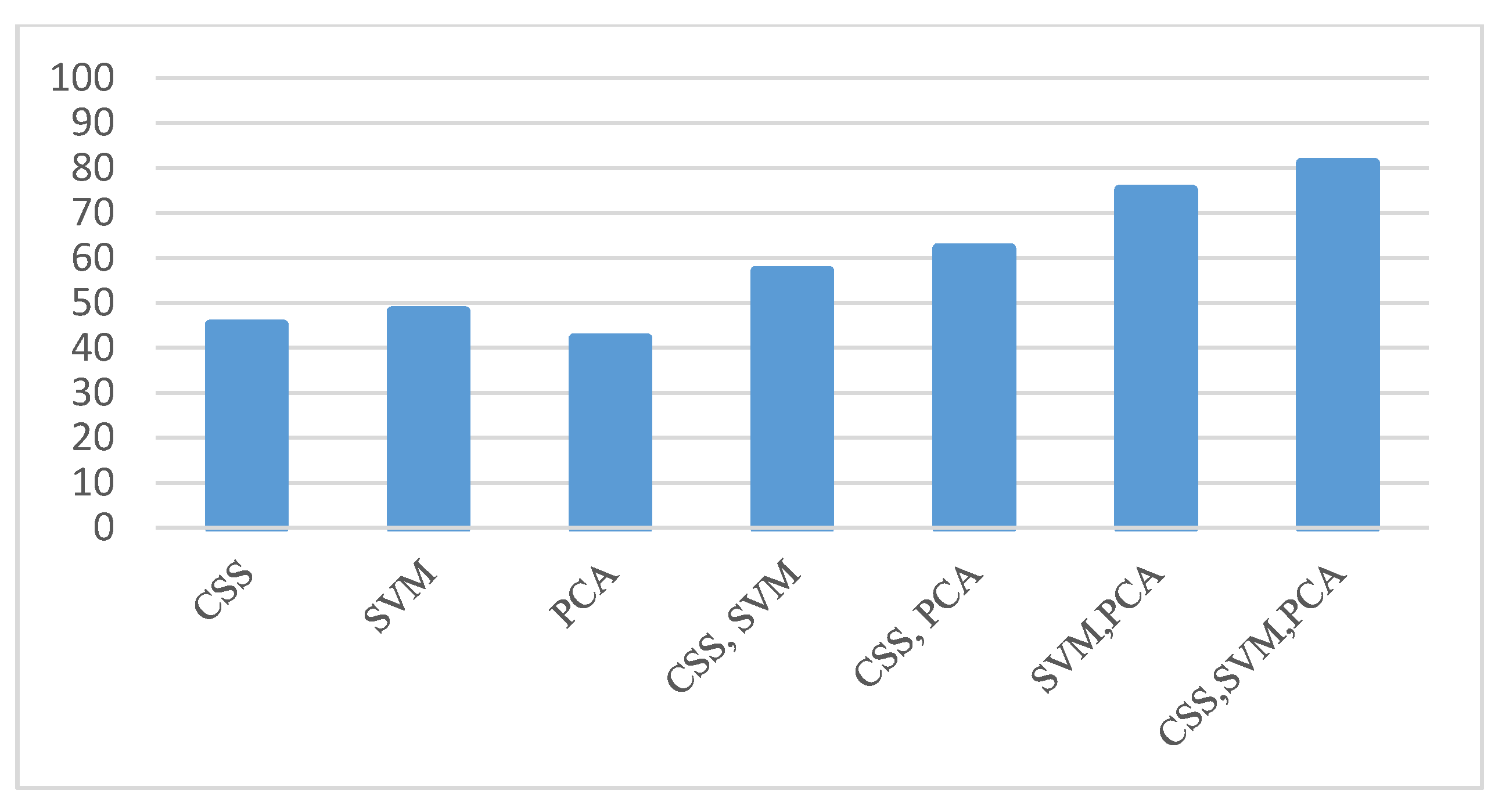
- The second step is to transfer both lists with weights 1, 0, −1 pos, neu, neg respectively, based on the feature weights approaches like Chi-squared statistic (CSS), weighted by (SVM), and (PCA) [39]. These three different schemes offer us more flexibility to select the best weights for each term. Then, we used cosine similarity as a numerical measure to extract the similarity weights between these methods and both the lists. Based on the discussion above, the experiment was implemented on these three weight approaches to get better accuracy. The output of this phase will be used for assigning the training dataset based on document.
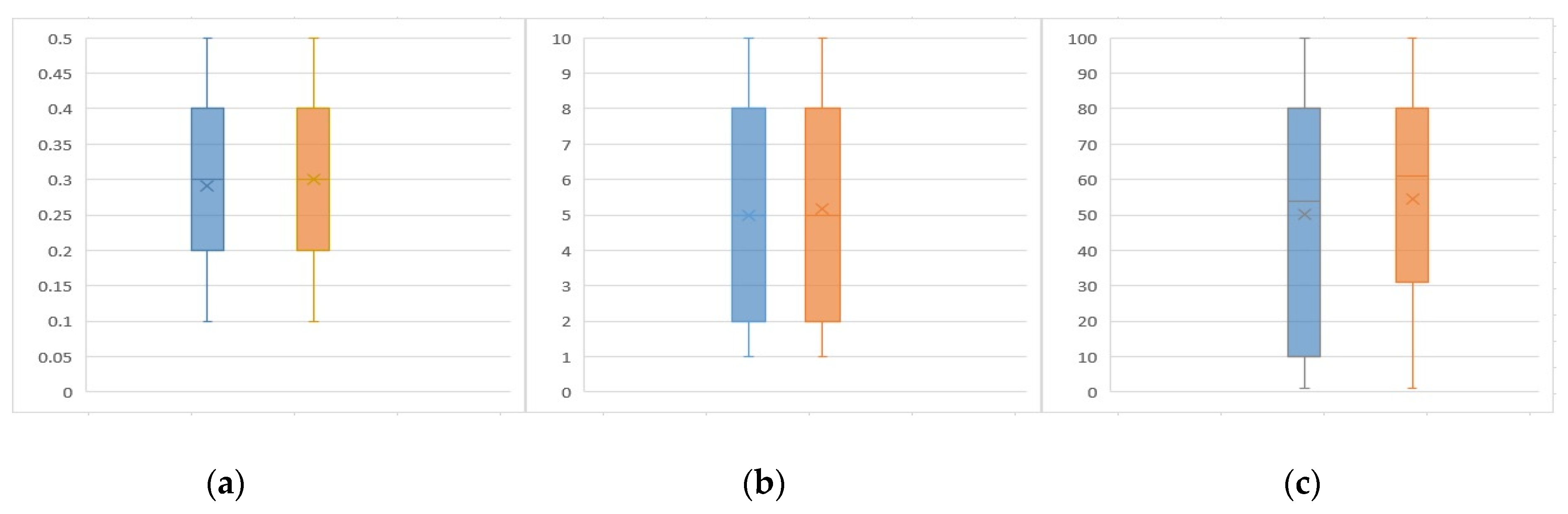
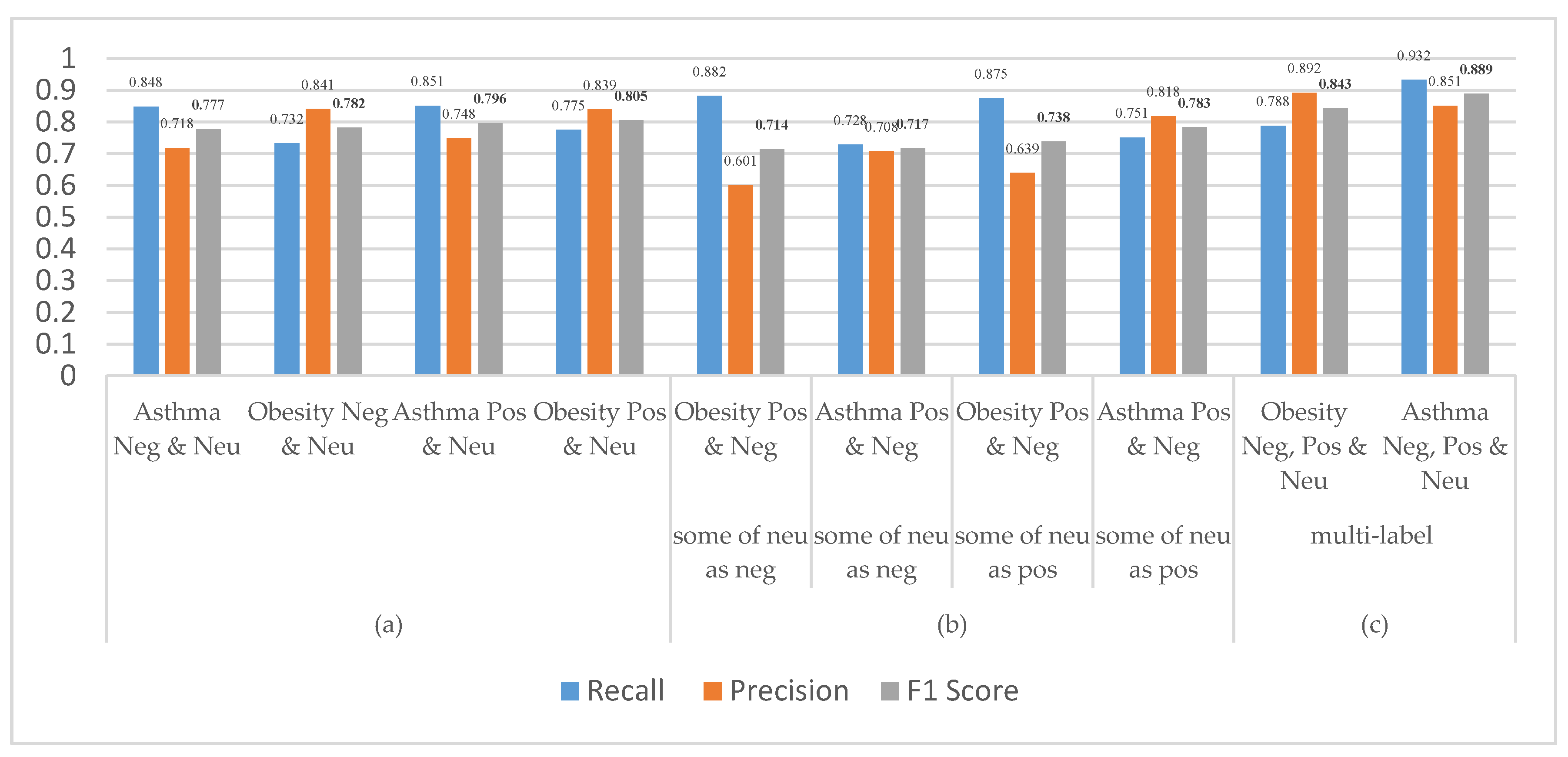
- sentiment polarity as in Equation (1). For more details see the (Supplementary file S1) which includes a full picture for each method and the main idea for the second and fourth phases present as workflow. Table 3 shows the samples from our dictionary list. Figure 3 shows the compared results based on seven cases.
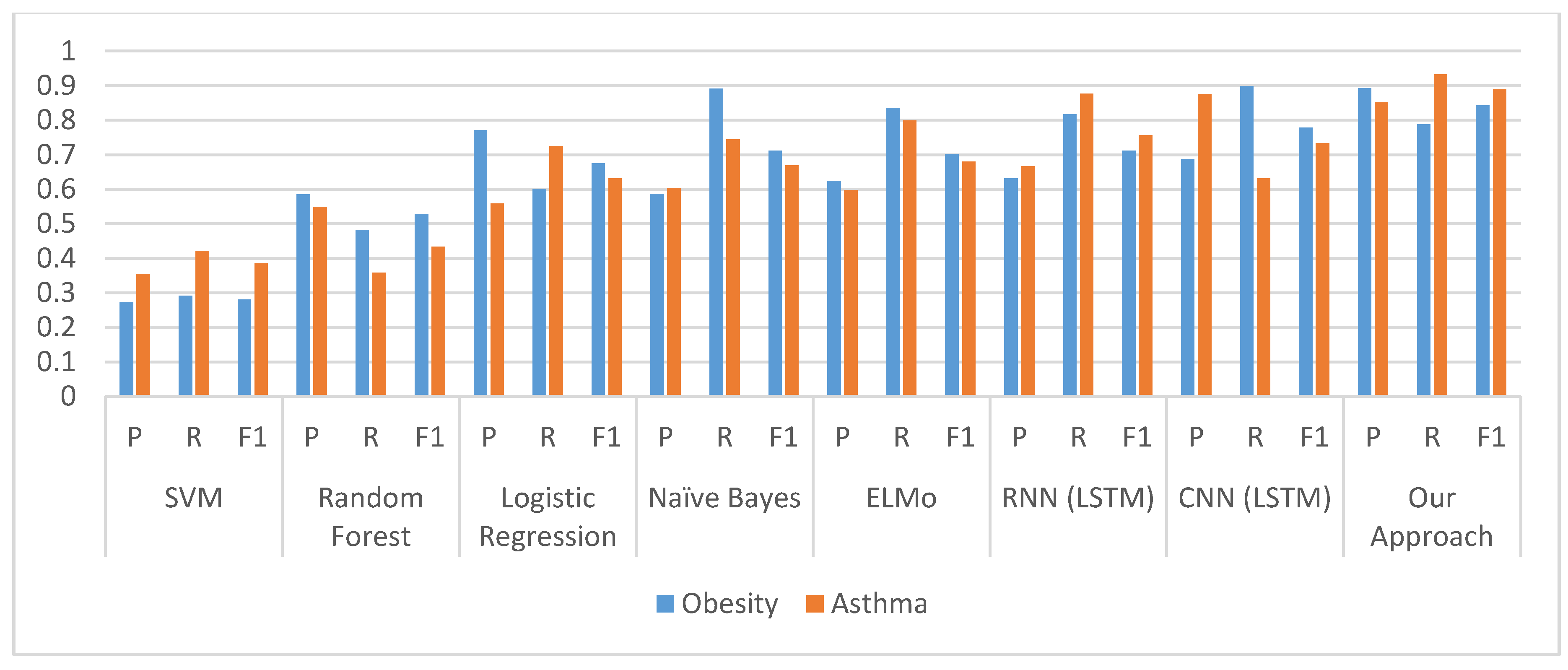
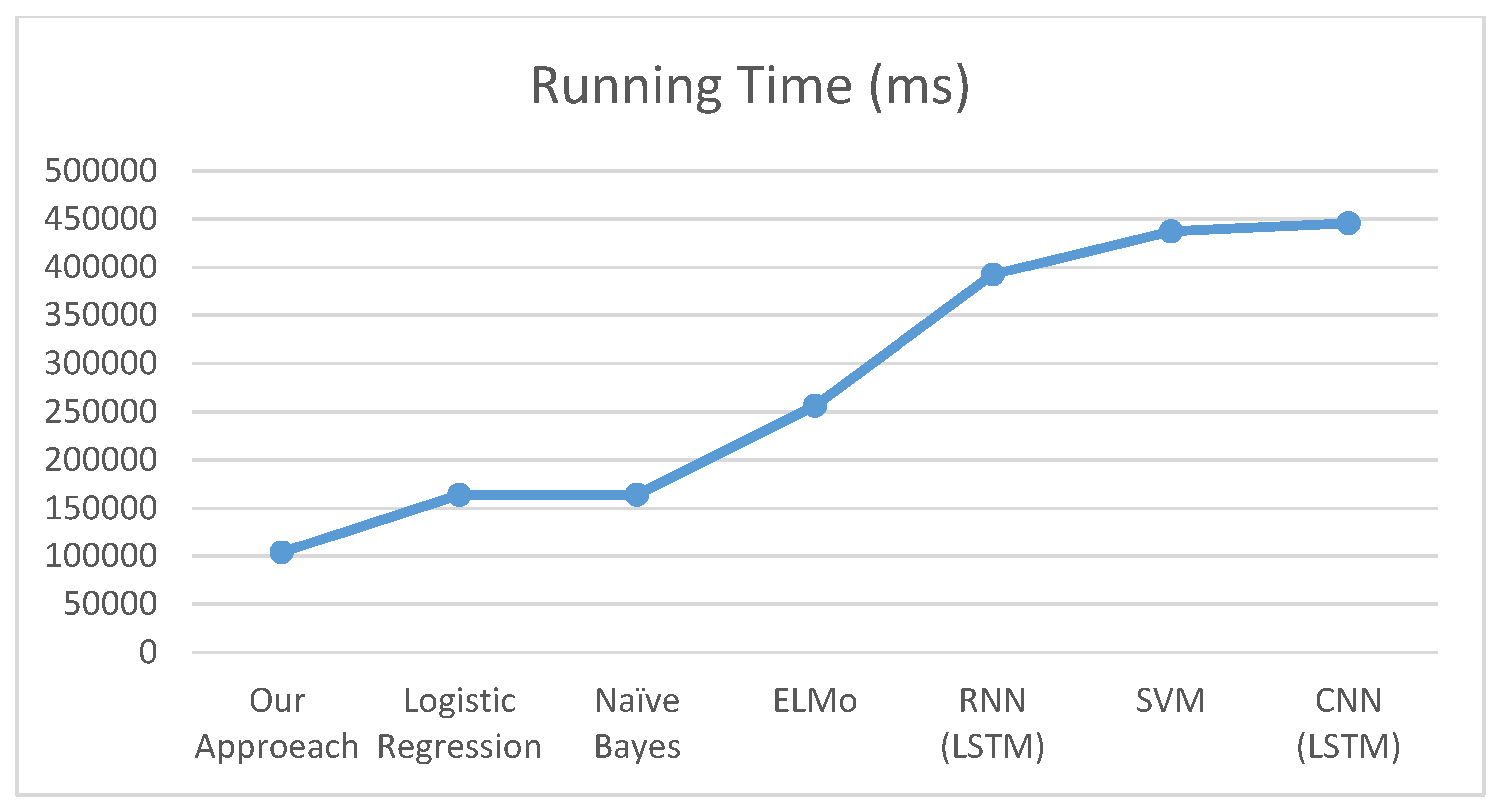
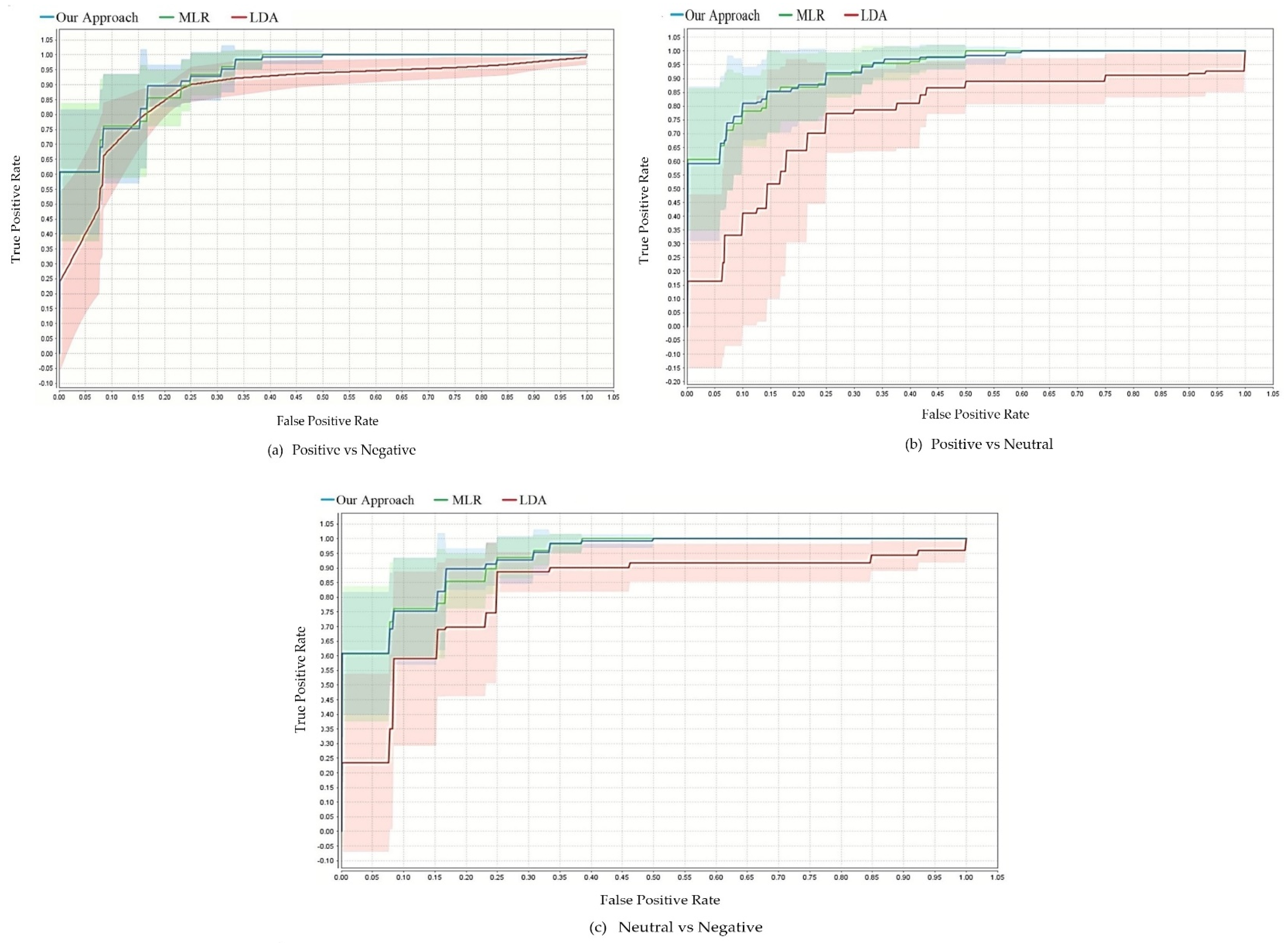
5.4. Evaluation and Comparison
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kilgour, C.; Bogossian, F.; Callaway, L.; Gallois, C.J.D.R. Experiences of women, hospital clinicians and general practitioners with gestational diabetes mellitus postnatal follow-up: A mixed methods approach. Diabetes Res. Clin. Pract. 2019, 148, 32–42. [Google Scholar] [CrossRef] [PubMed]
- O’Connor, R.; O’Callaghan, C.; McNamara, R.; Salim, U.J.I.J.O.M.S. An audit of discharge summaries from secondary to primary care. Ir. J. Med. Sci. 2019, 188, 537–540. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Cai, Z.; Li, Y.; Liu, F.; Fang, S.; Wang, G.J.J.O.H.E. Data processing and text mining technologies on electronic medical records: A review. J. Healthc. Eng. 2018, 2018, 4302425. [Google Scholar] [CrossRef] [PubMed]
- Hanauer, D.A.; Mei, Q.; Law, J.; Khanna, R.; Zheng, K.J.J.O.B.I. Supporting information retrieval from electronic health records: A report of University of Michigan’s nine-year experience in developing and using the Electronic Medical Record Search Engine (EMERSE). J. Biomed. Inform. 2015, 55, 290–300. [Google Scholar] [CrossRef] [PubMed]
- Rumshisky, A.; Ghassemi, M.; Naumann, T.; Szolovits, P.; Castro, V.; McCoy, T.; Perlis, R.J.T.P. Predicting early psychiatric readmission with natural language processing of narrative discharge summaries. Nat. Transl. Psychiatry 2016, 6, e921. [Google Scholar] [CrossRef] [PubMed]
- Tsopra, R.; Wyatt, J.C.; Beirne, P.; Rodger, K.; Callister, M.; Ghosh, D.; Clifton, I.J.; Whitaker, P.; Peckham, D.J.J.O.E.I.C.P. Level of accuracy of diagnoses recorded in discharge summaries: A cohort study in three respiratory wards. J. Eval. Clin. Pract. Wiley Online Libr. 2019, 25, 36–43. [Google Scholar] [CrossRef]
- Graham, A.J.; Ocampo, W.; Southern, D.A.; Falvi, A.; Sotiropoulos, D.; Wang, B.; Lonergan, K.; Vito, B.; Ghali, W.A.; McFadden, S.D.P.J.B.Q.S. Evaluation of an electronic health record structured discharge summary to provide real time adverse event reporting in thoracic surgery. BMJ Qual. Saf. 2019, 28, 310–316. [Google Scholar] [CrossRef]
- Goldgrab, D.; Balakumaran, K.; Kim, M.J.; Tabtabai, S.R.J.H.F.R. Updates in heart failure 30-day readmission prevention. Heart Fail. Rev. 2019, 24, 177–187. [Google Scholar] [CrossRef]
- Gilbert, A.V.; Patel, B.K.; Roberts, M.S.; Williams, D.B.; Crofton, J.H.; Morris, N.M.; Wallace, J.; Gilbert, A.L.J.J.O.P.P. An audit of medicines information quality in electronically generated discharge summaries–evidence to meet the Australian National Safety and Quality Health Service Standards. J. Pharm. Wiley Online Libr. 2017, 47, 355–364. [Google Scholar] [CrossRef]
- Schwarz, C.M.; Hoffmann, M.; Schwarz, P.; Kamolz, L.P.; Brunner, G.; Sendlhofer, G.J.B.H.S.R. A systematic literature review and narrative synthesis on the risks of medical discharge letters for patients’ safety. BMC Health Servres 2019, 19, 158. [Google Scholar] [CrossRef]
- Liang, H.; Tsui, B.Y.; Ni, H.; Valentim, C.C.; Baxter, S.L.; Liu, G.; Cai, W.; Kermany, D.S.; Sun, X.; Chen, J.J.N.M. Evaluation and accurate diagnoses of pediatric diseases using artificial intelligence. Nat. Med. 2019, 25, 433. [Google Scholar] [CrossRef] [PubMed]
- Reátegui, R.; Ratté, S.J.B.M.I.; Making, D. Comparison of MetaMap and cTAKES for entity extraction in clinical notes. BMC Med. Inform. Decis. Mak. 2018, 18, 74. [Google Scholar] [CrossRef] [PubMed]
- Servid, S.A.; Noble, B.N.; Fromme, E.K.; Furuno, J.P.J.J.O.T.A.G.S. Clinical intentions of antibiotics prescribed upon discharge to hospice care. J. Am. Heart Assoc. Wiley Online Libr. 2018, 66, 565–569. [Google Scholar] [CrossRef]
- Xu, J.; Gan, L.; Cheng, M.; Wu, Q.J.J.O.H.E. Unsupervised medical entity recognition and linking in Chinese online medical text. J. Healthc. Eng. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Zafra, S.M.; Martín-Valdivia, M.T.; Molina-González, M.D.; Ureña-López, L.A.J.A.I.I.M. How do we talk about doctors and drugs? Sentiment analysis in forums expressing opinions for medical domain. Artif. Intell. Med. 2019, 93, 50–57. [Google Scholar] [CrossRef] [PubMed]
- Abualigah, L.; Alfar, H.E.; Shehab, M.; Hussein, A.M.A. Sentiment Analysis in Healthcare: A Brief Review. In Recent Advances in NLP: The Case of Arabic Language; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–141. [Google Scholar]
- Melo, P.F.; Dalip, D.H.; Junior, M.M.; Gonçalves, M.A.; Benevenuto, F.J.J.O.T.A.F.I.S. 10SENT: A stable sentiment analysis method based on the combination of off-the-shelf approaches. J. Assoc. Inf. Sci. Technol. 2019, 70, 242–255. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Talafha, B.; Al-Ayyoub, M.; Jararweh, Y.J.I.J.O.M.L. Using long short-term memory deep neural networks for aspect-based sentiment analysis of Arabic reviews. Int. J. Mach. Learn. Cybern. 2019, 10, 2163–2175. [Google Scholar] [CrossRef]
- Ghasemaghaei, M.; Eslami, S.P.; Deal, K.; Hassanein, K. Consumers’ attitude toward insurance companies: A sentiment analysis of online consumer reviews. Decision Support and Analytics (SIGDSA). 2016. Available online: https://aisel.aisnet.org/amcis2016/Decision/Presentations/10/ (accessed on 21 May 2020).
- Rezaeinia, S.M.; Ghodsi, A.; Rahmani, R.J.A.P.A. Improving the accuracy of pre-trained word embeddings for sentiment analysis. arXiv 2017, arXiv:1711.08609. [Google Scholar]
- Sankar, H.; Subramaniyaswamy, V.; Vijayakumar, V.; Arun Kumar, S.; Logesh, R.; Umamakeswari, A.J.S.P. Intelligent sentiment analysis approach using edge computing-based deep learning technique. Softw. Pract. Exp. Wiley Online Libr. 2019. [Google Scholar] [CrossRef]
- Wang, Y.; Youn, H.J.A.S. Feature Weighting Based on Inter-Category and Intra-Category Strength for Twitter Sentiment Analysis. Appl. Sci. 2019, 9, 92. [Google Scholar] [CrossRef]
- Dehkharghani, R.; Saygin, Y.; Yanikoglu, B.; Oflazer, K.J.L.R. SentiTurkNet: A Turkish polarity lexicon for sentiment analysis. Lang. Resour. Eval. 2016, 50, 667–685. [Google Scholar] [CrossRef]
- Wang, Y.; Rao, Y.; Wu, L. A review of sentiment semantic analysis technology and progress. In Proceedings of the 2017 13th International Conference on Computational Intelligence and Security (CIS), Hong Kong, China, 15–18 December 2017; pp. 452–455. [Google Scholar]
- Mohammad, S.M.; Kiritchenko, S.; Zhu, X.J.A.P.A. NRC-Canada: Building the state-of-the-art in sentiment analysis of tweets. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 6–7 August 2019; Volume 1. [Google Scholar]
- Gilmore-Bykovskyi, A.L.; Kennelty, K.A.; DuGoff, E.; Kind, A.J.J.B.H.S.R. Hospital discharge documentation of a designated clinician for follow-up care and 30-day outcomes in hip fracture and stroke patients discharged to sub-acute care. BMC Health Servres 2018, 18, 103. [Google Scholar] [CrossRef] [PubMed]
- Mehta, R.L.; Baxendale, B.; Roth, K.; Caswell, V.; Le Jeune, I.; Hawkins, J.; Zedan, H.; Avery, A.J.J.B.H.S.R. Assessing the impact of the introduction of an electronic hospital discharge system on the completeness and timeliness of discharge communication: A before and after study. BMC Health Servres 2017, 17, 624. [Google Scholar] [CrossRef] [PubMed]
- Ooi, C.E.; Rofe, O.; Vienet, M.; Elliott, R.A.J.I.J.O.C.P. Improving communication of medication changes using a pharmacist-prepared discharge medication management summary. Int. J. Clin. Pharm. 2017, 39, 394–402. [Google Scholar] [CrossRef] [PubMed]
- Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M.J.S. Detecting and Monitoring Hate Speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef]
- Flores, A.C.; Icoy, R.I.; Peña, C.F.; Gorro, K.D. An Evaluation of SVM and Naive Bayes with SMOTE on Sentiment Analysis Data Set. In Proceedings of the 2018 International Conference on Engineering, Applied Sciences, and Technology (ICEAST), Phuket, Thailand, 4–7 July 2018; pp. 1–4. [Google Scholar]
- Ahmad, M.; Aftab, S.; Bashir, M.S.; Hameed, N.; Ali, I.; Nawaz, Z.J.I.J.A.C.S.A. SVM optimization for sentiment analysis. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 393–938. [Google Scholar] [CrossRef]
- Gupta, S.; Jain, S.; Gupta, S.; Chauhan, A.J.I.J.O.A.R.I.C.S. Opinion Mining for Hotel Rating through Reviews Using Decision Tree Classification Method. Int. J. Adv. Res. Comput. Sci. 2018, 9, 180. [Google Scholar] [CrossRef]
- Ma, Y.; Peng, H.; Khan, T.; Cambria, E.; Hussain, A.J.C.C. Sentic LSTM: A hybrid network for targeted aspect-based sentiment analysis. Cogn. Comput. 2018, 10, 639–650. [Google Scholar] [CrossRef]
- Spinczyk, D.; Nabrdalik, K.; Rojewska, K.J.B.E.O. Computer aided sentiment analysis of anorexia nervosa patients’ vocabulary. Biomed. Eng. Online 2018, 17, 19. [Google Scholar] [CrossRef]
- Jiang, K.; Feng, S.; Song, Q.; Calix, R.A.; Gupta, M.; Bernard, G.R.J.B.B. Identifying tweets of personal health experience through word embedding and LSTM neural network. BMC Bioinform. 2018, 19, 210. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G.J.N. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sun, K.; Zhang, J.; Zhang, C.; Hu, J.J.N. Generalized extreme learning machine autoencoder and a new deep neural network. Neurocomputing 2017, 230, 374–381. [Google Scholar] [CrossRef]
- Waheeb, S.A.; Husni, H.J.I.J.O.A.I.S. Multi-Document Arabic Summarization Using Text Clustering to Reduce Redundancy. Int. J. Adv. Sci. Technol. 2014, 2, 194–199. [Google Scholar]
- Waheeb, S.A.K.N.A.; Chen, B.; Shang, X. Multidocument Arabic Text Summarization Based on Clustering and Word2Vec to Reduce Redundancy. Information 2020, 11, 59. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K.J.N. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Reese, R.M. Natural Language Processing with Java; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J.J.A.P.A. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Yao, L.; Ge, Z.J.I.T.O.I.E. Deep learning of semisupervised process data with hierarchical extreme learning machine and soft sensor application. IEEE Trans. Ind. Electron. 2017, 65, 1490–1498. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.B.; Song, S.; You, K.J.N.N. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease | Present | Unmentioned | Absent | Questionable | Total |
|---|---|---|---|---|---|
| Asthma | 75 | 529 | 1 | 1 | 606 |
| CAD | 331 | 240 | 16 | 4 | 591 |
| CHF | 239 | 344 | 7 | 0 | 589 |
| Depression | 90 | 519 | 0 | 0 | 609 |
| Diabetes | 396 | 181 | 12 | 6 | 595 |
| Gallstones | 93 | 513 | 3 | 0 | 609 |
| GERD | 98 | 500 | 1 | 3 | 602 |
| Gout | 73 | 534 | 0 | 2 | 609 |
| Hypercholesterolemia | 246 | 343 | 9 | 1 | 599 |
| Hypertension | 441 | 149 | 10 | 0 | 600 |
| Hypertriglyceridemia | 15 | 594 | 0 | 0 | 609 |
| OA | 89 | 513 | 0 | 0 | 602 |
| Obesity | 245 | 354 | 3 | 4 | 606 |
| OSA | 88 | 510 | 0 | 7 | 604 |
| PVD | 83 | 525 | 0 | 0 | 608 |
| Venous Insufficiency | 14 | 592 | 0 | 0 | 606 |
| Sum | 2616 | 6940 | 62 | 28 | 9644 |
| Disease | Positive | Negative | Neutral | Total |
|---|---|---|---|---|
| Asthma | 331 | 37 | 238 | 606 |
| Obesity | 320 | 43 | 243 | 606 |
| ID | Positive Keywords | Negative Keywords | Neutral Keywords |
|---|---|---|---|
| 1 | Positive, improve, increase | Failure, fatigue, weakness | Notify, totally, planned |
| 2 | Accept, strong | Disease, losing weight | Data, side, center |
| 3 | Effective, improve, clear, safe, good | Swollen, illness, loose, droop | Move, weigh, event |
| 4 | Bright, gain, stable, consistent, satisfactory | Itching, headache, smoker | Site, totally, tubes |
| 5 | Significant, thought, advanced, aspiration | Complained, work, deviation, upset | System, steadily, discussion |
| Our Method | F1 | F2 | F3 | F4 | F5 | F6 | F7 | Precision | Recall | F_measure |
|---|---|---|---|---|---|---|---|---|---|---|
| DS-SA-ELM-AE | + | + | + | + | + | + | + | 0.851 | 0.932 | 0.889 |
| DS-SA-ELM-AE | + | + | + | + | + | + | 0.8675 | 0.6571 | 0.7478 | |
| DS-SA-ELM-AE | + | + | + | + | + | 0.8176 | 0.6193 | 0.7048 | ||
| DS-SA-ELM-AE | + | + | + | + | 0.8404 | 0.6369 | 0.7246 | |||
| DS-SA-ELM-AE | + | + | + | 0.7869 | 0.5998 | 0.6807 | ||||
| DS-SA-ELM-AE | + | + | 0.7826 | 0.6004 | 0.6795 | |||||
| DS-SA-ELM-AE | + | 0.7469 | 0.5733 | 0.6487 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waheeb, S.A.; Ahmed Khan, N.; Chen, B.; Shang, X. Machine Learning Based Sentiment Text Classification for Evaluating Treatment Quality of Discharge Summary. Information 2020, 11, 281. https://doi.org/10.3390/info11050281
Waheeb SA, Ahmed Khan N, Chen B, Shang X. Machine Learning Based Sentiment Text Classification for Evaluating Treatment Quality of Discharge Summary. Information. 2020; 11(5):281. https://doi.org/10.3390/info11050281
Chicago/Turabian StyleWaheeb, Samer Abdulateef, Naseer Ahmed Khan, Bolin Chen, and Xuequn Shang. 2020. "Machine Learning Based Sentiment Text Classification for Evaluating Treatment Quality of Discharge Summary" Information 11, no. 5: 281. https://doi.org/10.3390/info11050281
APA StyleWaheeb, S. A., Ahmed Khan, N., Chen, B., & Shang, X. (2020). Machine Learning Based Sentiment Text Classification for Evaluating Treatment Quality of Discharge Summary. Information, 11(5), 281. https://doi.org/10.3390/info11050281