Applying the ETL Process to Blockchain Data. Prospect and Findings




Abstract
1. Introduction
2. Related Works
2.1. Background
2.1.1. ETL Process
2.1.2. Lambda Architecture
- The need for a robust system that is fault-tolerant, both against hardware failures and human mistakes.
- To serve a wide range of workloads and use cases, in which low latency reads and updates are required. Related to this point, the system should support ad hoc queries.
- The system should be linearly scalable, and it should scale out rather than up, meaning that throwing more machines at the problem will do the job.
- The system should be extensible so that features can be added easily, and it should be easily debuggable and require minimal maintenance.
3. Method
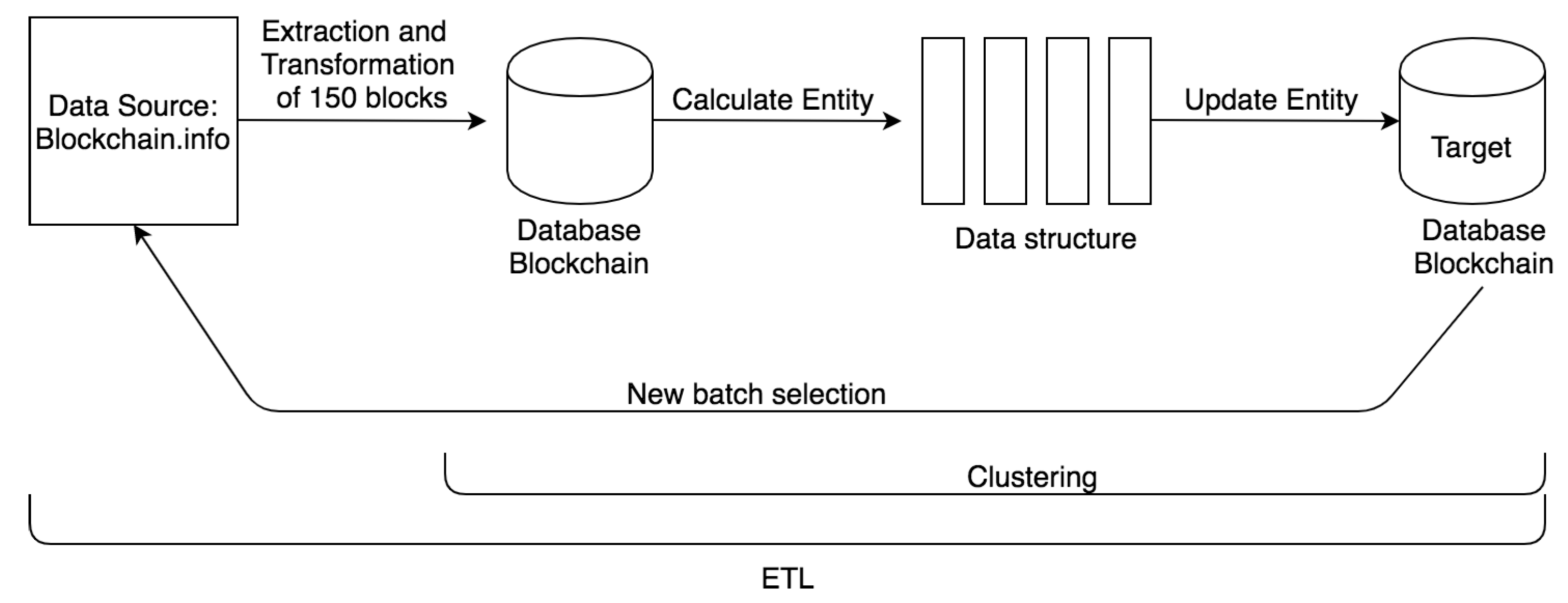
3.1. ETL Process Design
- blockchair.com: 0.5 requests per second;
- blockcyper.com: 3 requests per second;
- blockchain.info: 5 requests per second;
- chain.so: 5 requests per second.
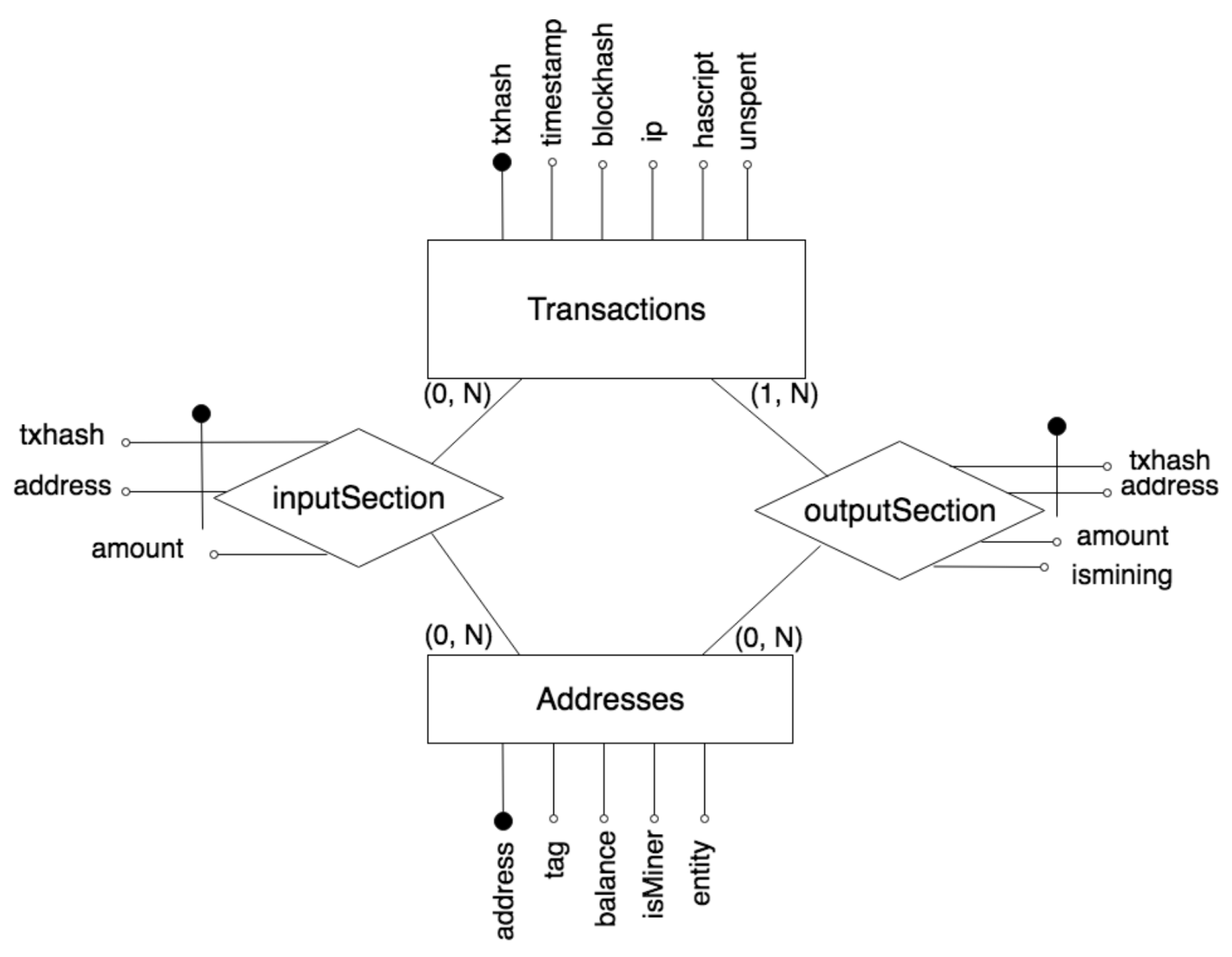
- Transactions (txhash (primary key), timestamp, block, IP, hasScript, unspent). Each tuple of this table is a blockchain transaction. Attributes of this table include: the transaction hash, the transaction date, the hash of the block which contains the transaction, the IP address of the miner, and two Boolean to represents if the transaction contains a script in its body, and if the transaction was unspent in the moment of the extraction.
- Addresses (address (primary key), tag, balance, IsMiner, entity). Each tuple of this table represents a blockchain address. Attributes include: the address, a tag (a short description, if available), the balance in Satoshi (1 Satoshi = Bitcoin. It is the smallest amount of cryptocurrency to transfer with a transaction.) (which is computed as the sum of the total value of the unspent transactions received by the address), a Boolean to specify if it is was a miner at least one time, and the ID of the entity we computed in the clustering process (initially empty).
- InputSection (address (external key), txhash (external key), amount). Each tuple of this table represents one element of the input section of a given transaction. For instance, if one transaction contains three input, three entries will be recorded in this table. Attributes include: the address (which references to the table addresses), the transaction hash (which references to the table transactions), and the amount of Bitcoin in Satoshi.
- OutputSection (address (external key), txhash (external key), amount, isMining). Each tuple of this table represents one element of the output section of each transaction. Attributes include: the address (which references to the table addresses), the hash of the transaction (which references to the table transactions), the amount of money in Satoshi, and a Boolean to represent if a given address is the receiver of the mining prize obtained with a given transaction.
3.2. Clustering
- Transaction search algorithm (Algorithm 2): it takes in input an unexplored address and searches all the transactions where the unexplored address is present, and once the transactions have been found, the address is removed from the list of addresses to be explored.
- Address search algorithm (Algorithm 3): takes in input an unexplored transaction and searches all the addresses present in the input section of the transaction under consideration, excluding those already explored. At the end of the process it marks the transaction as explored and adds the result of the search to the queue of addresses to be explored.
- Updating Algorithm (Algorithm 4): If the same address has been clustered into multiple entities, these clusters are joined into a single entity, identified by a new ID equal to the existing maximum ID incremented by one. Contextually, the algorithm updates the table addresses of the database which, for each address, writes the new entity ID.
| Algorithm 1: Clustering(inputSection) |
 |
| Algorithm 2: findTransactionsInexplored(addr, tr, exAddr) |
 |
| Algorithm 3: findAddressesInexplored(addr, tr, exTr) |
 |
| Algorithm 4: updateEntities(exAddr) |
 |
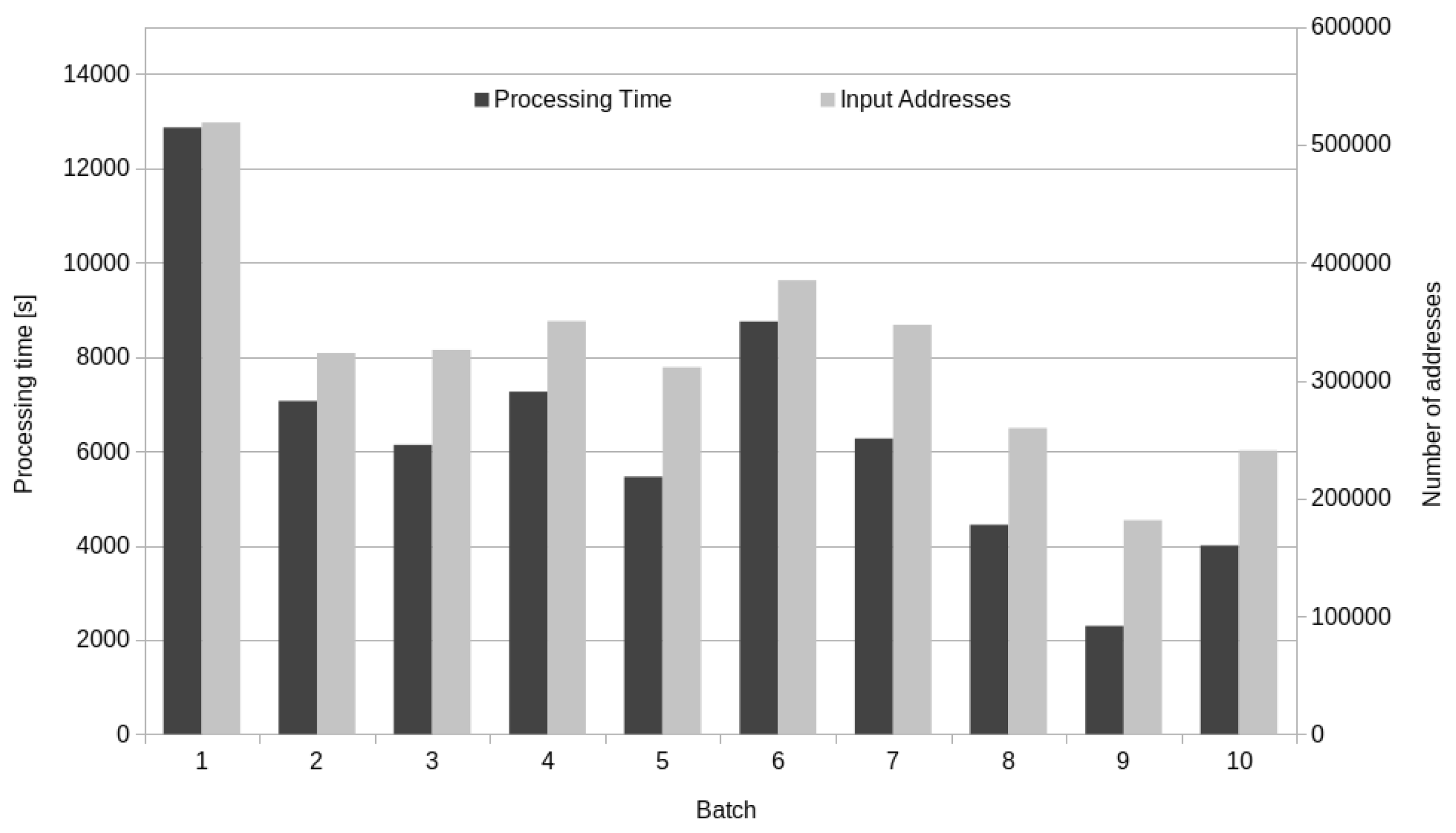
4. Results
5. Implications
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nakamoto, S. A Peer-to-Peer Electronic Cash System. Bitcoin.org. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 7 March 2020).
- Maxwell, G. CoinJoin: Bitcoin Privacy for the Real World. bitcointalk.org. 2013. Available online: https://bitcointalk.org/?topic=279249 (accessed on 7 March 2020).
- Ruffing, T.; Moreno-Sanchez, P. Valueshuffle: Mixing confidential transactions for comprehensive transaction privacy in bitcoin. In Proceedings of the International Conference on Financial Cryptography and Data Security, Sliema, Malta, 3–7 April 2017; pp. 133–154. [Google Scholar]
- Bistarelli, S.; Mercanti, I.; Santini, F. A suite of tools for the forensic analysis of bitcoin transactions: Preliminary report. In Proceedings of the European Conference on Parallel Processing, Turin, Italy, 27–31 August 2018; pp. 329–341. [Google Scholar]
- Wu, Y.; Luo, A.; Xu, D. Forensic Analysis of Bitcoin Transactions. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI), Shenzhen, China, 1–3 July 2019; pp. 167–169. [Google Scholar]
- Ron, D.; Shamir, A. Quantitative analysis of the full bitcoin transaction graph. In Proceedings of the International Conference on Financial Cryptography and Data Security, Okinawa, Japan, 1–5 April 2013; pp. 6–24. [Google Scholar]
- Meiklejohn, S.; Pomarole, M.; Jordan, G.; Levchenko, K.; McCoy, D.; Voelker, G.M.; Savage, S. A fistful of bitcoins: characterizing payments among men with no names. In Proceedings of the 2013 Conference on Internet Measurement Conference, Barcelona, Spain, 23–25 October 2013; pp. 127–140. [Google Scholar]
- Reid, F.; Harrigan, M. An Analysis of Anonymity in the Bitcoin System. In Security and Privacy in Social Networks; Altshuler, Y., Elovici, Y., Cremers, A.B., Aharony, N., Pentland, A., Eds.; Springer: New York, NY, USA, 2013; pp. 197–223. [Google Scholar] [CrossRef]
- Ober, M.; Katzenbeisser, S.; Hamacher, K. Structure and anonymity of the bitcoin transaction graph. Future Internet 2013, 5, 237–250. [Google Scholar] [CrossRef]
- McGinn, D.; Birch, D.; Akroyd, D.; Molina-Solana, M.; Guo, Y.; Knottenbelt, W.J. Visualizing dynamic bitcoin transaction patterns. Big Data 2016, 4, 109–119. [Google Scholar] [CrossRef] [PubMed]
- Harrigan, M.; Fretter, C. The unreasonable effectiveness of address clustering. In Proceedings of the 2016 Intl IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; pp. 368–373. [Google Scholar]
- McGinn, D.; McIlwraith, D.; Guo, Y. Towards open data blockchain analytics: a Bitcoin perspective. R. Soc. Open Sci. 2018, 5, 180298. [Google Scholar] [CrossRef] [PubMed]
- Zheng, B.; Zhu, L.; Shen, M.; Du, X.; Guizani, M. Identifying the vulnerabilities of bitcoin anonymous mechanism based on address clustering. Sci. China Inf. Sci. 2020, 63, 1–15. [Google Scholar] [CrossRef]
- Zheng, B.; Zhu, L.; Shen, M.; Du, X.; Yang, J.; Gao, F.; Li, Y.; Zhang, C.; Liu, S.; Yin, S. Malicious bitcoin transaction tracing using incidence relation clustering. In Proceedings of the International Conference on Mobile Networks and Management, Melbourne, Australia, 13–15 December 2017; pp. 313–323. [Google Scholar]
- Ermilov, D.; Panov, M.; Yanovich, Y. Automatic bitcoin address clustering. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 461–466. [Google Scholar]
- Shin, M.G.; Baek, U.J.; Shim, K.S.; Park, J.T.; Yoon, S.H.; Kim, M.S. Block Analysis in Bitcoin System Using Clustering with Dimension Reduction. In Proceedings of the 2019 20th Asia-Pacific Network Operations and Management Symposium (APNOMS), Matsue, Japan, 18–20 September 2019; pp. 1–4. [Google Scholar]
- Neudecker, T.; Hartenstein, H. Could network information facilitate address clustering in Bitcoin? In Proceedings of the International Conference on Financial Cryptography and Data Security, Sliema, Malta, 3–7 April 2017; pp. 155–169. [Google Scholar]
- Maesa, D.D.F.; Marino, A.; Ricci, L. Data-driven analysis of Bitcoin properties: exploiting the users graph. Int. J. Data Sci. Anal. 2018, 6, 63–80. [Google Scholar] [CrossRef]
- Pinna, A.; Tonelli, R.; Orrú, M.; Marchesi, M. A Petri Nets model for blockchain analysis. Comput. J. 2018, 61, 1374–1388. [Google Scholar] [CrossRef]
- Bartoletti, M.; Lande, S.; Pompianu, L.; Bracciali, A. A general framework for blockchain analytics. In Proceedings of the 1st Workshop on Scalable and Resilient Infrastructures for Distributed Ledgers, Las Vegas, NV, USA, 11–15 December 2017; pp. 1–6. [Google Scholar]
- Yue, K.B.; Chandrasekar, K.; Gullapalli, H. Storing and Querying Blockchain using SQL Databases. Inf. Syst. Educ. J. 2019, 17, 24. [Google Scholar]
- Trujillo, J.; Luján-Mora, S. A UML based approach for modeling ETL processes in data warehouses. In Proceedings of the International Conference on Conceptual Modeling, Chicago, IL, USA, 13–16 October 2003; pp. 307–320. [Google Scholar]
- Kiran, M.; Murphy, P.; Monga, I.; Dugan, J.; Baveja, S.S. Lambda architecture for cost-effective batch and speed big data processing. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2785–2792. [Google Scholar]
- Marz, N.; Warren, J. Big Data: Principles and Best Practices of Scalable Real-Time Data Systems; Manning Publications Co.: New York, NY, USA, 2015. [Google Scholar]
- Hasani, Z.; Kon-Popovska, M.; Velinov, G. Survey of technologies for real time big data streams analytic. In Proceedings of the 11th International Conference on Informatics and Information Technologies, Las Vegas, NV, USA, 7–9 April 2014; pp. 11–13. [Google Scholar]
- Androulaki, E.; Karame, G.O.; Roeschlin, M.; Scherer, T.; Capkun, S. Evaluating user privacy in bitcoin. In Proceedings of the International Conference on Financial Cryptography and Data Security, Okinawa, Japan, 1–5 April 2013; pp. 34–51. [Google Scholar]






{kind=link}
{kind=link}
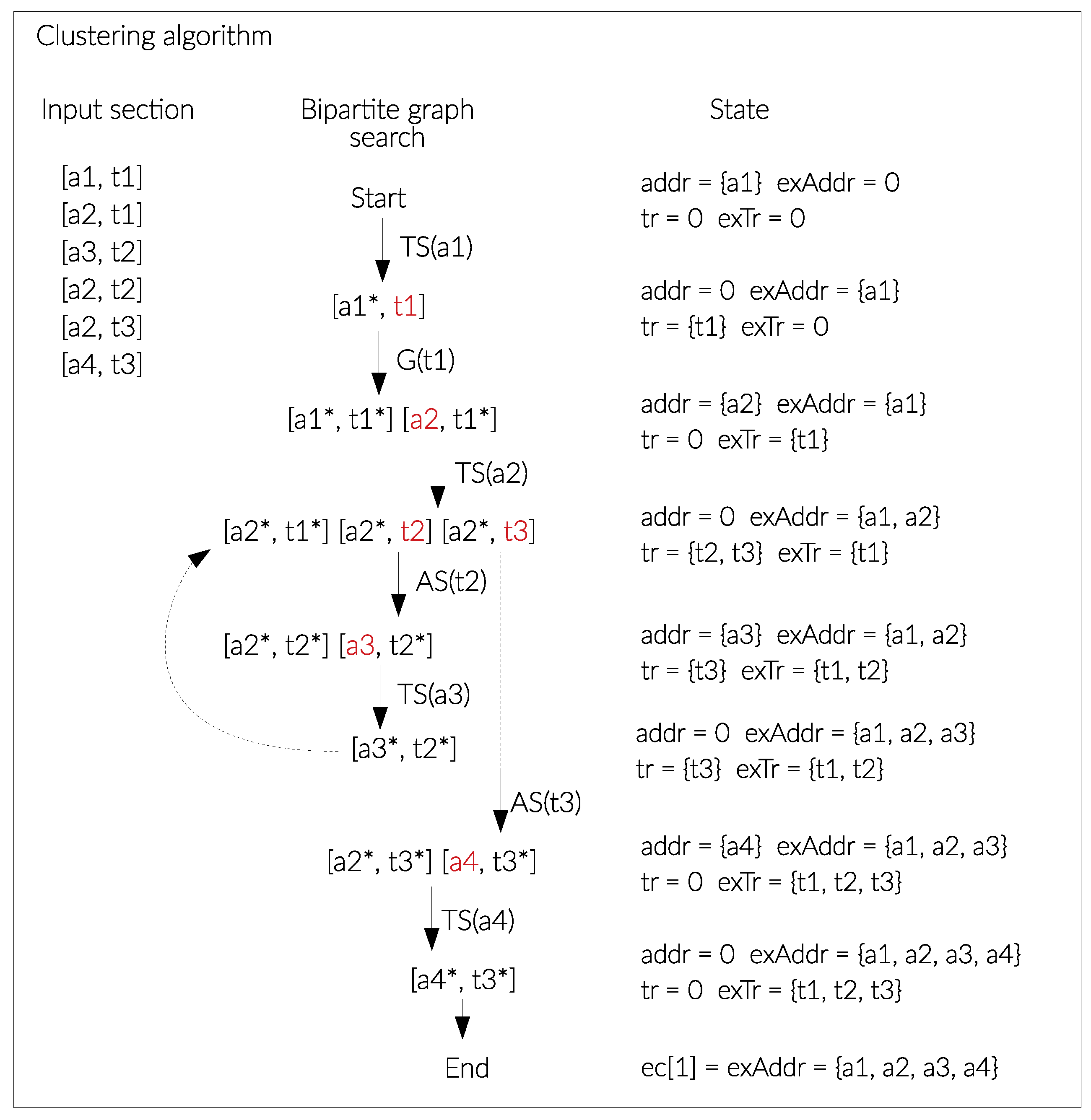{kind=link}
{kind=link}
{kind=link}
| 150 Blocks | 21,300 Blocks | 180,000 Blocks [19] | |
|---|---|---|---|
| Disk space | 449 MB | 54 GB | - |
| Number of Transactions | 163,442 | 30.99 × | 3.14 × |
| Number of Addresses | 547,553 | 56.50 × | 3.73 × |
| Average number of transactions sent by an address | 1.580 | 1.508 | 1.2266 |
| Total number of entries in the table inputSection | 584,409 | 48.7 × | 4.57 × |
| Average length of the input section per transaction | 3.5789 | 2.695 | 1.4564 |
| Average amount in Satoshi in the input sections | 169.7 × | 46.32 × | - |
| Number of Entities | 128,207 | 6.54 x | 2.46 × |
| Maximum number of addresses per entity | 177,768 | 4.072 × | 156,725 |
| Average number of addresses per entity | 4.270 | 4.1526 | 1.5158 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galici, R.; Ordile, L.; Marchesi, M.; Pinna, A.; Tonelli, R. Applying the ETL Process to Blockchain Data. Prospect and Findings. Information 2020, 11, 204. https://doi.org/10.3390/info11040204
Galici R, Ordile L, Marchesi M, Pinna A, Tonelli R. Applying the ETL Process to Blockchain Data. Prospect and Findings. Information. 2020; 11(4):204. https://doi.org/10.3390/info11040204
Chicago/Turabian StyleGalici, Roberta, Laura Ordile, Michele Marchesi, Andrea Pinna, and Roberto Tonelli. 2020. "Applying the ETL Process to Blockchain Data. Prospect and Findings" Information 11, no. 4: 204. https://doi.org/10.3390/info11040204
APA StyleGalici, R., Ordile, L., Marchesi, M., Pinna, A., & Tonelli, R. (2020). Applying the ETL Process to Blockchain Data. Prospect and Findings. Information, 11(4), 204. https://doi.org/10.3390/info11040204