On the Randomness of Compressed Data



Abstract
1. Introduction
2. Randomness of Compression Methods
2.1. Huffman Coding
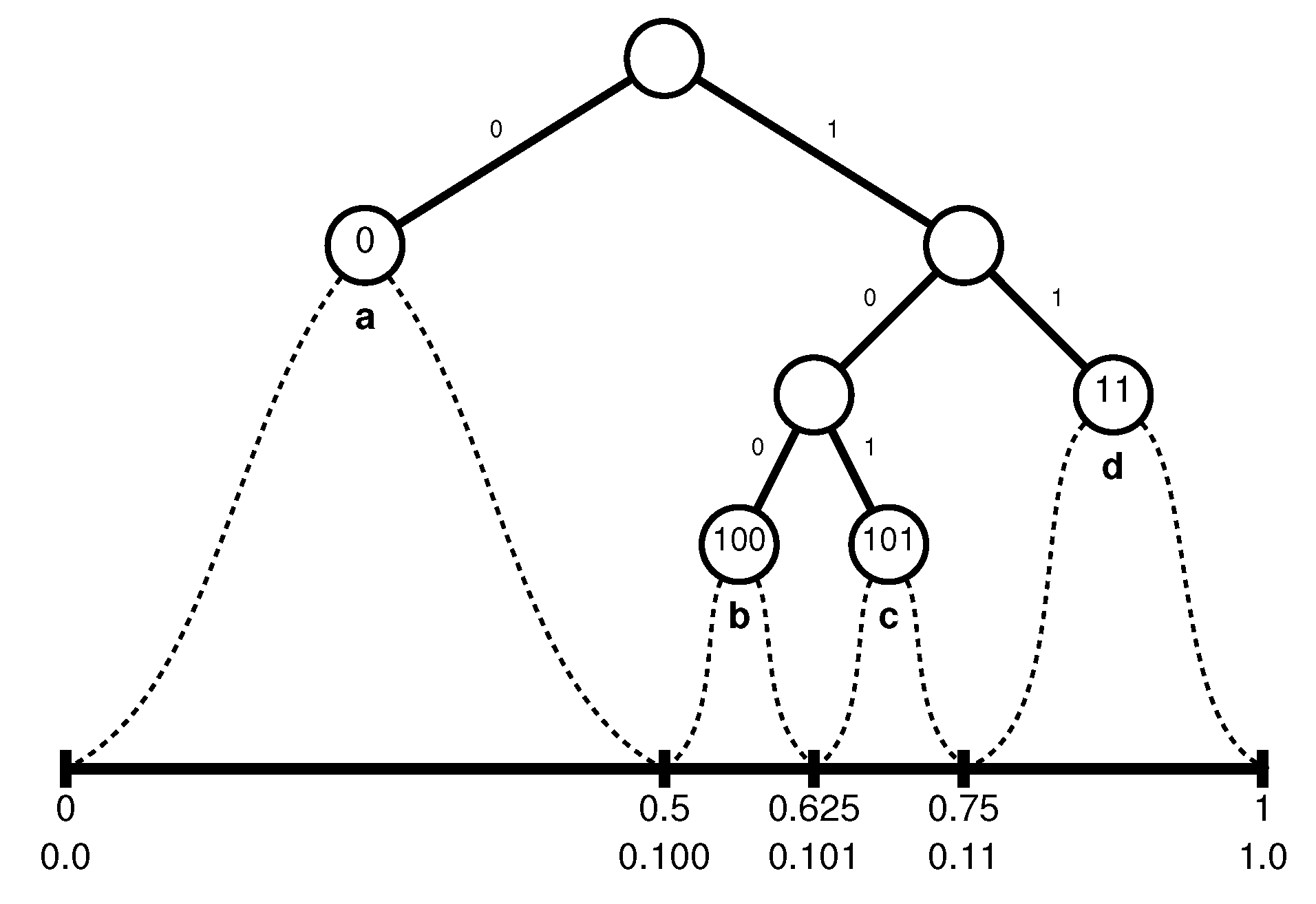
2.2. Arithmetic Coding
- If the first letter to be encoded is a, the interval will be narrowed to , and whatever the final interval will be, we know already that it is included in , so that the first bit of the encoding string must be a zero.
- If the first letter of the input is b, the interval will be narrowed to (in binary); any real number in that can be identified as belonging only to must start with , which contributes the bits 100 to the output file. Note that 0.1 or 0.10 also belong to , but there are also numbers in other subintervals starting with 0.1 or 0.10, so that the shortest representation of that can be used unambiguously to further sub-partition the interval is 0.100.
- Similarly, if the first letter to be encoded is c, will be narrowed to , which contributes the bits 101 to the output file, and for the last case,
- if the first letter is d, the new interval will be , contributing the bits 11.
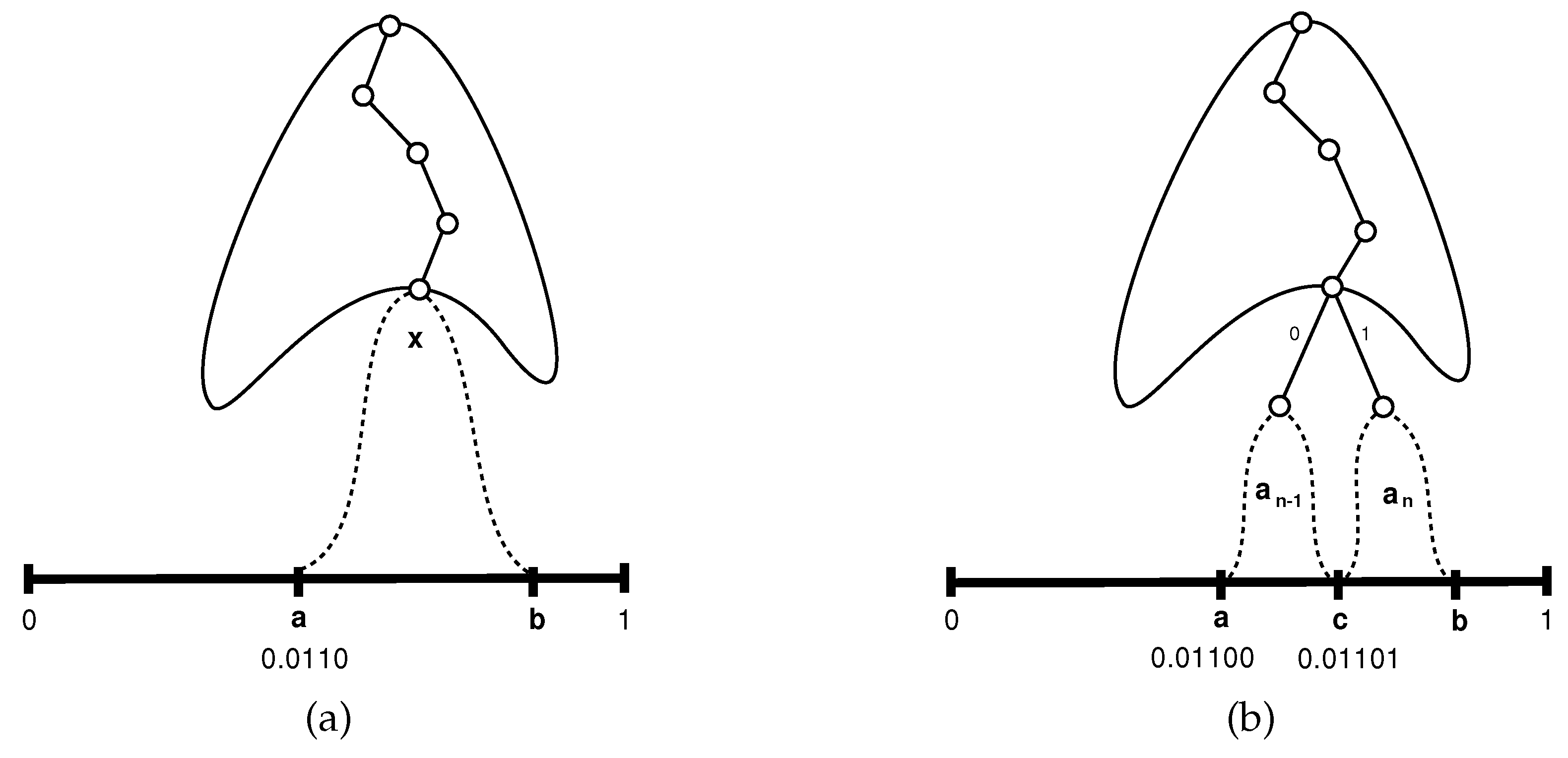
- If the current character y to be processed is one of , it follows from the inductive assumption that arithmetic coding will narrow the current interval so that the following bits of the output stream are equal to the Huffman codeword of y.
- If the current character is , the corresponding interval is . From the inductive assumption we know that if we would deal with and the following character would be x, the next generated bits would have been , so if we now restrict our attention to , the left half of , the next generated bits have to be . But is exactly the Huffman codeword of in A.
- Similarly, if the next character is , the restriction would be to and the next generated bits would have to be , which is the Huffman codeword of in A.
2.3. LZW
3. Empirical Tests
- A measure for the spread of values could be the standard deviation , which is generally of the order of magnitude of the average , so their ratio may serve as a measure of the skewness of the distribution.
- Given two probability distributions and , the Kullback–Leibler (KL) divergence [39], defined asgives a one-sided, asymmetric, distance from P to Q, which vanishes for .
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huffman, D.A. A Method for the Construction of Minimum-Redundancy Codes. Available online: http://compression.ru/download/articles/huff/huffman_1952_minimum-redundancy-codes.pdf (accessed on 5 April 2020).
- Elias, P. Universal codeword sets and representations of the integers. IEEE Trans. Inf. Theory 1975, 21, 194–203. [Google Scholar] [CrossRef]
- Vitter, J.S. Algorithm 673: Dynamic Huffman coding. ACM Trans. Math. Softw. 1989, 15, 158–167. [Google Scholar] [CrossRef]
- Cleary, J.; Witten, I. Data Compression Using Adaptive Coding and Partial String Matching. IEEE Trans. Commun. 1984, 32, 396–402. [Google Scholar] [CrossRef]
- Storer, J.A.; Szymanski, T.G. Data compression via textural substitution. J. ACM 1982, 29, 928–951. [Google Scholar] [CrossRef]
- Klein, S.T.; Shapira, D. Context Sensitive Rewriting Codes for Flash Memory. Comput. J. 2019, 62, 20–29. [Google Scholar] [CrossRef]
- Klein, S.T.; Shapira, D. On improving Tunstall codes. Inf. Process. Manag. 2011, 47, 777–785. [Google Scholar] [CrossRef][Green Version]
- Amir, A.; Benson, G. Efficient two-dimensional compressed matching. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 24–27 March 1992; pp. 279–288. [Google Scholar]
- Shapira, D.; Daptardar, A.H. Adapting the Knuth-Morris-Pratt algorithm for pattern matching in Huffman encoded texts. Inf. Process. Manag. 2006, 42, 429–439. [Google Scholar] [CrossRef][Green Version]
- Klein, S.T.; Shapira, D. Compressed Pattern Matching in jpeg Images. Int. J. Found. Comput. Sci. 2006, 17, 1297–1306. [Google Scholar] [CrossRef]
- Klein, S.T.; Shapira, D. Compressed matching for feature vectors. Theor. Comput. Sci. 2016, 638, 52–62. [Google Scholar] [CrossRef]
- Klein, S.T.; Shapira, D. Compressed Matching in Dictionaries. Algorithms 2011, 4, 61–74. [Google Scholar] [CrossRef]
- Baruch, G.; Klein, S.T.; Shapira, D. Applying Compression to Hierarchical Clustering. In Proceedings of the SISAP 2018: 11th International Conference on Similarity Search and Applications, Lima, Peru, 7–9 October 2018; pp. 151–162. [Google Scholar]
- Jacobson, G. Space efficient static trees and graphs. In Proceedings of the 30th Annual Symposium on Foundations of Computer Science, Research Triangle Park, NC, USA, 30 October–1 November 1989; pp. 549–554. [Google Scholar]
- Navarro, G. Compact Data Structures: A Practical Approach; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Klein, S.T.; Shapira, D. Random access to Fibonacci encoded files. Discret. Appl. Math. 2016, 212, 115–128. [Google Scholar] [CrossRef]
- Baruch, G.; Klein, S.T.; Shapira, D. A space efficient direct access data structure. J. Discret. Algorithms 2017, 43, 26–37. [Google Scholar] [CrossRef]
- Fariña, A.; Navarro, G.; Paramá, J.R. Boosting Text Compression with Word-Based Statistical Encoding. Comput. J. 2012, 55, 111–131. [Google Scholar] [CrossRef]
- Manber, U.; Myers, G. Suffix Arrays: A New Method for On-Line String Searches. SIAM J. Comput. 1993, 22, 935–948. [Google Scholar] [CrossRef]
- Huo, H.; Sun, Z.; Li, S.; Vitter, J.S.; Wang, X.; Yu, Q.; Huan, J. CS2A: A Compressed Suffix Array-Based Method for Short Read Alignment. In Proceedings of the 2016 Data Compression Conference (DCC), Snowbird, SLC, USA, 30 March–1 April 1 2016; pp. 271–278. [Google Scholar]
- Benza, E.; Klein, S.T.; Shapira, D. Smaller Compressed Suffix Arrays. Comput. J. 2020, 63. [Google Scholar] [CrossRef]
- Rubin, F. Cryptographic Aspects of Data Compression Codes. Cryptologia 1979, 3, 202–205. [Google Scholar] [CrossRef]
- Klein, S.T.; Shapira, D. Integrated Encryption in Dynamic Arithmetic Compression. In Proceedings of the 11th International Conference on Language and Automata Theory and Applications, Umeå, Sweden, 6–9 March 2017; pp. 143–154. [Google Scholar]
- Gillman, D.W.; Mohtashemi, M.; Rivest, R.L. On breaking a Huffman code. IEEE Trans. Inf. Theory 1996, 42, 972–976. [Google Scholar] [CrossRef]
- Fraenkel, A.S.; Klein, S.T. Complexity Aspects of Guessing Prefix Codes. Algorithmica 1994, 12, 409–419. [Google Scholar] [CrossRef]
- L’Ecuyer, P.; Simard, R.J. TestU01: A C library for empirical testing of random number generators. ACM Trans. Math. Softw. 2007, 33, 22:1–22:40. [Google Scholar] [CrossRef]
- Chang, W.; Yun, X.; Li, N.; Bao, X. Investigating Randomness of the LZSS Compression Algorithm. In Proceedings of the 2012 International Conference on Computer Science and Service System, Nanjing, China, 11–13 August 2012. [Google Scholar]
- Chang, W.; Fang, B.; Yun, X.; Wang, S.; Yu, X. Randomness Testing of Compressed Data. arXiv 2010, arXiv:1001.3485. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming, Volume II: Seminumerical Algorithms; Addison-Wesley: Reading, MA, USA, 1969. [Google Scholar]
- Klein, S.T.; Bookstein, A.; Deerwester, S.C. Storing Text Retrieval Systems on CD-ROM: Compression and Encryption Considerations. ACM Trans. Inf. Syst. 1989, 7, 230–245. [Google Scholar] [CrossRef]
- Longo, G.; Galasso, G. An application of informational divergence to Huffman codes. IEEE Trans. Inf. Theory 1982, 28, 36–42. [Google Scholar] [CrossRef]
- Bookstein, A.; Klein, S.T. Is Huffman coding dead? Computing 1993, 50, 279–296. [Google Scholar] [CrossRef]
- Witten, I.H.; Neal, R.M.; Cleary, J.G. Arithmetic Coding for Data Compression. Commun. ACM 1987, 30, 520–540. [Google Scholar] [CrossRef]
- Klein, S.T. Basic Concepts in Data Structures; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Vitter, J.S. Design and analysis of dynamic Huffman codes. J. ACM 1987, 34, 825–845. [Google Scholar] [CrossRef]
- Welch, T.A. A Technique for High-Performance Data Compression. IEEE Comput. 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Burrows, M.; Wheeler, D.J. A Block Sorting Lossless Data Compression Algorithm. Available online: https://www.hpl.hp.com/techreports/Compaq-DEC/SRC-RR-124.pdf (accessed on 5 April 2020).
- Nelson, M.; Gailly, J.L. The Data Compression Book, 2nd ed.; M & T Books: New York, NY, USA, 1996. [Google Scholar]
- Moffat, A. Word-based Text Compression. Softw. Pract. Exp. 1989, 19, 185–198. [Google Scholar] [CrossRef]
- Cormack, G.V.; Horspool, R.N. Data Compression Using Dynamic Markov Modelling. Comput. J. 1987, 30, 541–550. [Google Scholar] [CrossRef]
- Willems, F.M.J.; Shtarkov, Y.M.; Tjalkens, T.J. The context-tree weighting method: basic properties. IEEE Trans. Inf. Theory 1995, 41, 653–664. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| alg | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | compr | |
|---|---|---|---|---|---|---|---|---|---|---|
| arith | 0.00004 | 0.0001 | 0.0007 | 0.0011 | 0.0017 | 0.0025 | 0.0036 | 0.0050 | 0.3 | 52.4 |
| random | 0.0015 | 0.0021 | 0.0029 | 0.0040 | 0.0054 | 0.0078 | 0.0108 | 0.0149 | 1 | – |
| gzip | 0.0072 | 0.0129 | 0.0168 | 0.0204 | 0.0234 | 0.0263 | 0.0290 | 0.0318 | 3.4 | 31.2 |
| newlzw | 0.0174 | 0.0251 | 0.0314 | 0.0367 | 0.0415 | 0.0459 | 0.0501 | 0.0541 | 6.1 | 30.2 |
| oldlzw | 0.0237 | 0.0341 | 0.0427 | 0.0504 | 0.0572 | 0.0633 | 0.0691 | 0.0746 | 8.4 | 30.3 |
| bwt | 0.0204 | 0.0326 | 0.0415 | 0.0544 | 0.0674 | 0.0825 | 0.1025 | 0.1236 | 10.6 | 23.3 |
| hufwrd | 0.0420 | 0.0595 | 0.0730 | 0.0851 | 0.0976 | 0.1130 | 0.1299 | 0.1500 | 15.2 | 21.7 |
| hufcar | 0.0834 | 0.1240 | 0.1609 | 0.2018 | 0.2661 | 0.3533 | 0.4488 | 0.5695 | 44.7 | 52.8 |
| ascii | 0.1227 | 0.1736 | 0.2506 | 0.3234 | 0.4457 | 0.5721 | 0.8007 | 1.1124 | 76.9 | 100 |
| alg | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| arith | 0.000000001 | 0.000000003 | 0.00000010 | 0.00000021 | 0.00000042 | 0.00000076 | 0.00000135 | 0.00000224 | 0.02 |
| random | 0.00000154 | 0.00000308 | 0.00000625 | 0.00001152 | 0.00002079 | 0.00004397 | 0.00008407 | 0.00015928 | 1 |
| gzip | 0.00004 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 2 |
| newlzw | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0003 | 0.0003 | 6 |
| oldlzw | 0.0004 | 0.0004 | 0.0004 | 0.0004 | 0.0005 | 0.0005 | 0.0005 | 0.0005 | 11 |
| bwt | 0.0003 | 0.0004 | 0.0004 | 0.0005 | 0.0007 | 0.0008 | 0.0011 | 0.0014 | 17 |
| hufwrd | 0.0013 | 0.0013 | 0.0013 | 0.0013 | 0.0014 | 0.0015 | 0.0017 | 0.0020 | 36 |
| hufcar | 0.0050 | 0.0058 | 0.0069 | 0.0087 | 0.0122 | 0.0173 | 0.0223 | 0.0289 | 324 |
| ascii | 0.0109 | 0.0109 | 0.0170 | 0.0228 | 0.0338 | 0.0452 | 0.0699 | 0.1014 | 944 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klein, S.T.; Shapira, D. On the Randomness of Compressed Data. Information 2020, 11, 196. https://doi.org/10.3390/info11040196
Klein ST, Shapira D. On the Randomness of Compressed Data. Information. 2020; 11(4):196. https://doi.org/10.3390/info11040196
Chicago/Turabian StyleKlein, Shmuel T., and Dana Shapira. 2020. "On the Randomness of Compressed Data" Information 11, no. 4: 196. https://doi.org/10.3390/info11040196
APA StyleKlein, S. T., & Shapira, D. (2020). On the Randomness of Compressed Data. Information, 11(4), 196. https://doi.org/10.3390/info11040196