1. Introduction
The sudden climate change, which has taken place in recent years, has generated calamitous phenomena linked to hydrogeological instability in many areas of the world. The main existing rainfall level measurement methods employ rain gauges, weather radars and satellites [
1,
2,
3]. The rain gauge is probably the most common rainfall measurement device, as it is able to provide an average accurate estimate of the rainfall with a precise temporal resolution; in fact, rain gauges continuously record the level of precipitation even within short time intervals. Modern tilt rain gauges consist of a plastic manifold balanced on a pin. When it tips, it actuates a switch which is then electronically recorded or transmitted to a remote collection station. Unfortunately, tipping buckets tend to underestimate the amount of rainfall, particularly in snowfall and heavy rainfall events. Moreover, they are also sensitive to the inclination of the receiver and different types of dirt that may clog the water collection point.
Many studies have been carried out regarding the classification of rainfall levels using alternative methods, parameters, and signals such as video, audio, and radio signals [
4,
5,
6].
In [
7], rain is estimated through acoustic sensors and Android smartphones. Using this system has several advantages: access to the data collected via the device’s microphone or camera; data can be sent via radio functions (WI-FI, GSM, LTE, etc.); and the cost-effectiveness of Android devices compared to high-precision meteorological instruments.
The audio data collected by the smartphone microphone are then processed to extract the fundamental parameters to be compared with the critical thresholds, and exceeding these thresholds, translates into sending an “alarm”. In addition, historical data are stored on a web server allowing remote access to information. From the audio sequence sampled at 22.05 KHz the calculation of the signal strength (dB) is performed every 5 s. To verify the validity of the results obtained with this method, measurements were carried out simultaneously with the aid of a tilting rain gauge so that the data of the two solutions can be compared.
The study carried out in [
8], aims at the digital representation of rain scenes as a function of the real sounds produced by the precipitation. The research is based on the study of rainfall phenomena proposed by Marshall and Palmer, providing the frame for describing the probability distribution of the number and size of raindrops in a space of known volume, evaluating the intensity of the event, and the fact that the speed of a water drop is only related to its size.
Based on these considerations, it is possible to extract parameters relating to raindrops, useful for creating an animated digital scene. A rainy phenomenon can be modelled according to the Marshall–Palmer distribution which allows determining the relationship between the number and size of the drops in a volume as a function of the level of intensity (mm/h) obtainable from the audio recordings of actual rainfall. These were obtained using a smartphone and employing the same previously described procedure [
7], but with sampling at a frequency of 44.10 KHz and, simultaneously, carrying out measurements using a rain gauge. In order to extract the frequency characteristics, various rainfall recordings of different intensity were taken and, for each, the Fourier transform was performed. One of the most evident results is that the samples in the spectrum present a high level of correlation and the high frequency components increase as the intensity of the precipitation increases. This can be interpreted by the Marshall–Palmer distribution, in fact, the number of occurring raindrops per unit of volume increases as the intensity of the rain increases, the average landing time of the drop is reduced and, consequently, the frequency of sounds increases.
The input sounds were taken from a data set, randomly selecting eight 1-s sound segments for each data, with 15 types of rainfall intensity. Once the level of rainfall has been determined, it is possible to trace the following parameters: size of the rain particles, number of drops, and falling speed.
In [
9], a technique of automated learning was studied through machine learning, employing a series of functions for the classification of acoustic recordings, in order to improve the performance of the rain classification system. The classification was implemented using a ‘decision tree’ classifier and comparing this with other classifiers.
Another technique used, was a machine learning approach of analysis and classification in which the sound classes to be analyzed are defined in advance [
10]. Another study carried out in [
11], involved the use of frequency domain functions to represent audio input and multilabel neural networks to detect multiple and simultaneous sound events in a real recording.
Aiming to overcome some limitations present in traditional techniques to signal classification, in [
12] we proposed an acoustic rain gauge based on convolutional neural network (CNN), in order to obtain accurate classification of rainfall levels. The paper presents a classification algorithm for the acoustic timbre produced by the rain in four intensities, i.e., “Weak rain”, “Moderate rain”, “Heavy rain”, and “Very heavy rain”; also the paper studies and compares the performance of an acoustic rain gauge in four different types of materials used to cover the microphone. In this study, the sound of rain was derived from the impact of water drops on a material covering the microphone. As in previous studies carried out in audio biometrics [
13,
14], the audio signal was analyzed using statistical variables (mean, variance and first coefficient of autocorrelation), whereas the MFCC parameters were used for the characterization of the audio spectrum.
This paper extends the previous study to a wider set of rain levels, including the “No rain” class and adding the “Shower” and “Cloudburst” rain classes. In places without a power grid (e.g., agriculture and smart roads), this system can be powered by a low-power photovoltaic panel, enabling recording at a rate proportional to the rain level, thus preserving the average lifetime of the electronic and microphone sensor components. Statistics on the average weather that characterizes a rainfall event in the territory allow us to state that the reliability and average duration of an audio rain gauge is comparable to that of a mobile terminal. The operating temperatures of an acoustic rain gauge, in fact, are the same as those of a mobile terminal. Furthermore, the microphones are designed for large temperature and humidity levels. The introduction of an acoustic rain gauge is, thus, justified, particularly, in contexts where it may be necessary to reduce the risks caused by sudden “showers” or “cloudbursts” with low operational investment, management and maintenance costs. Some application contexts concern smart cities for which is foreseen the integration of an audio sensor inside the luminaire of a street lamp, precision agriculture [
15], with the advantage of being able to adapt the irrigation flows in a complementary way to different rain levels, as well as highway safety, by minimizing the risks of aquaplaning [
16,
17].
The paper is organized as follows:
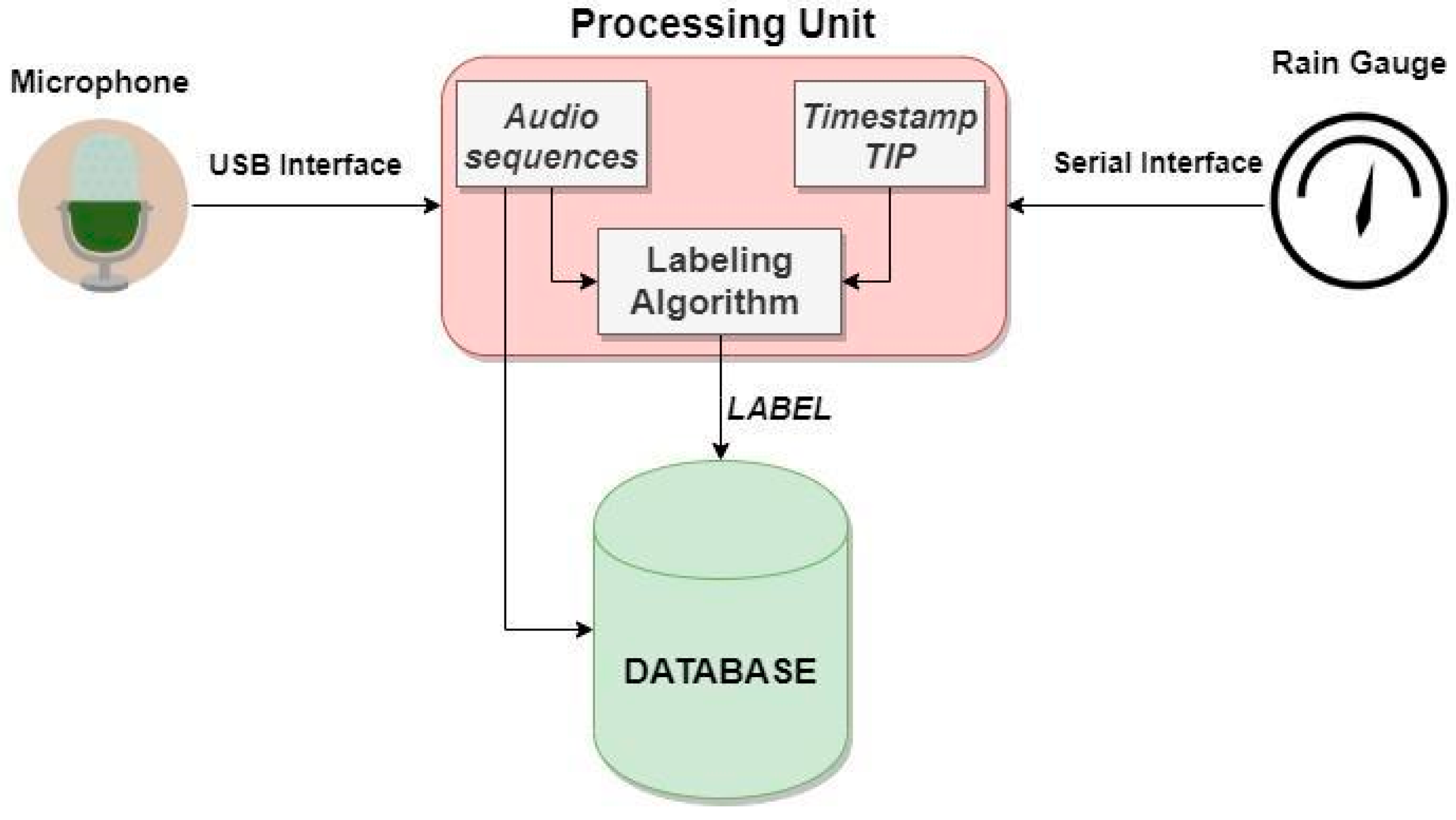
Section 2 illustrates the testbed scenario, i.e., database features, algorithm labeling and the types of tests carried out;
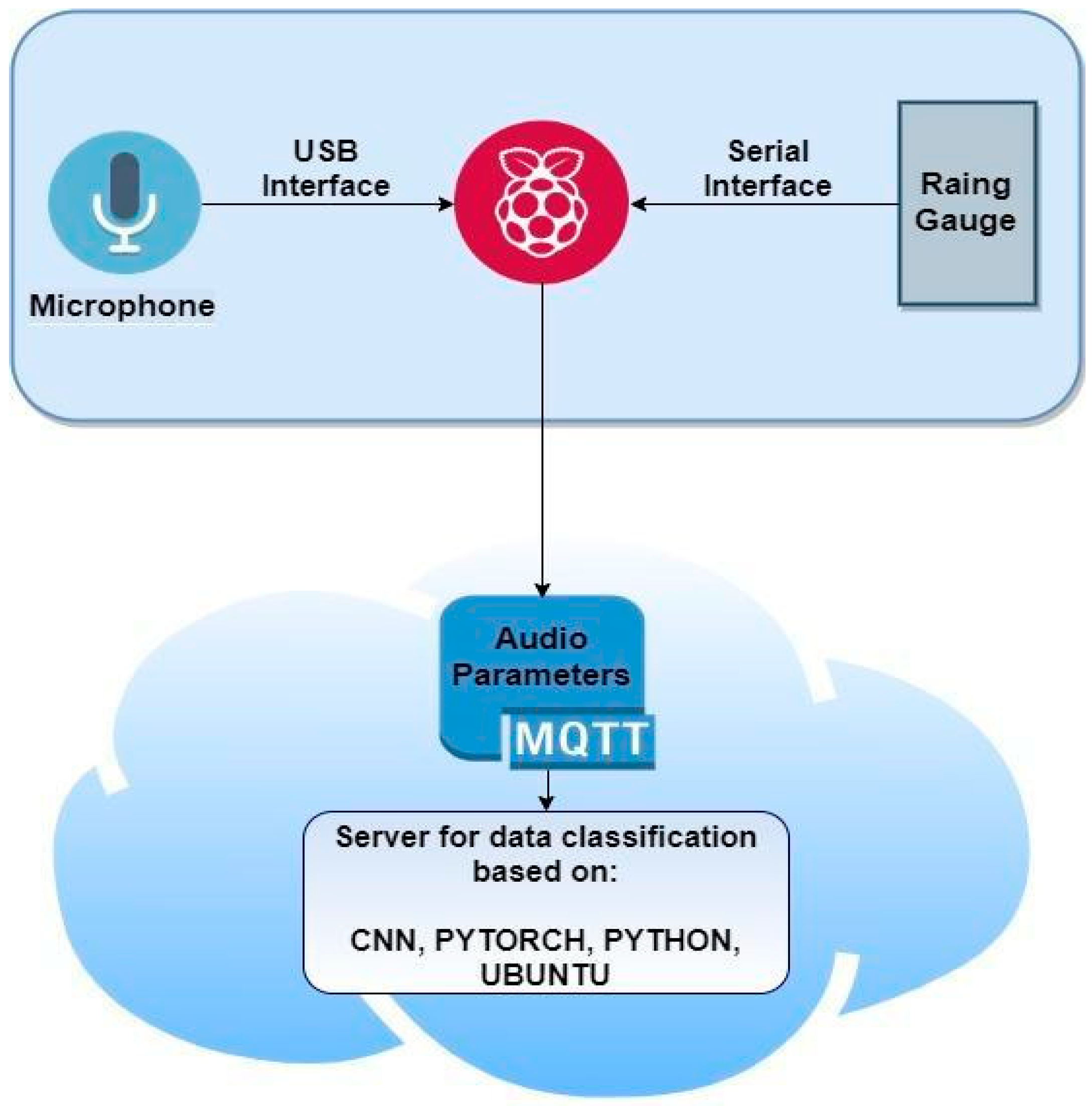
Section 3 describes the hardware and software components used;
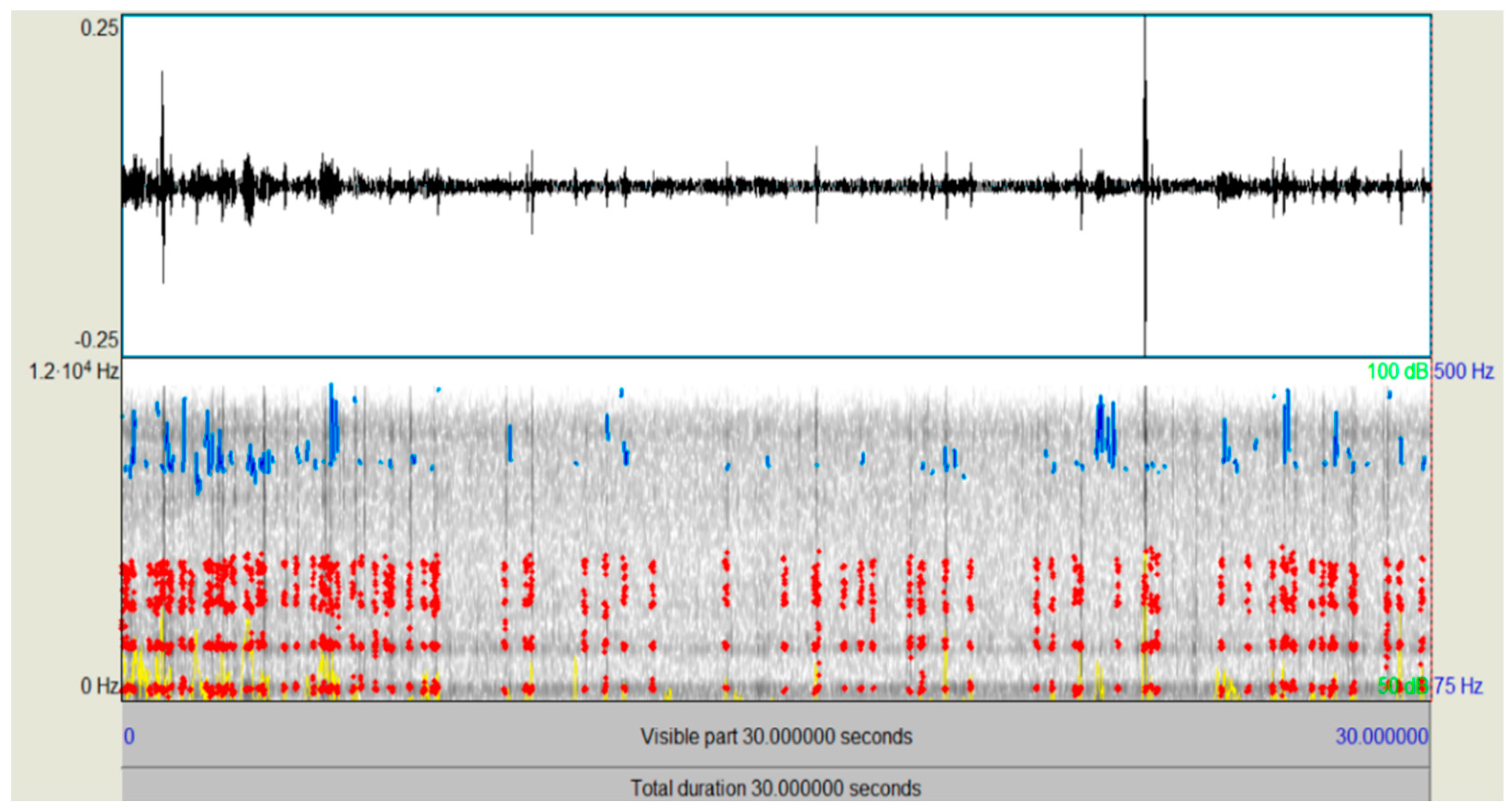
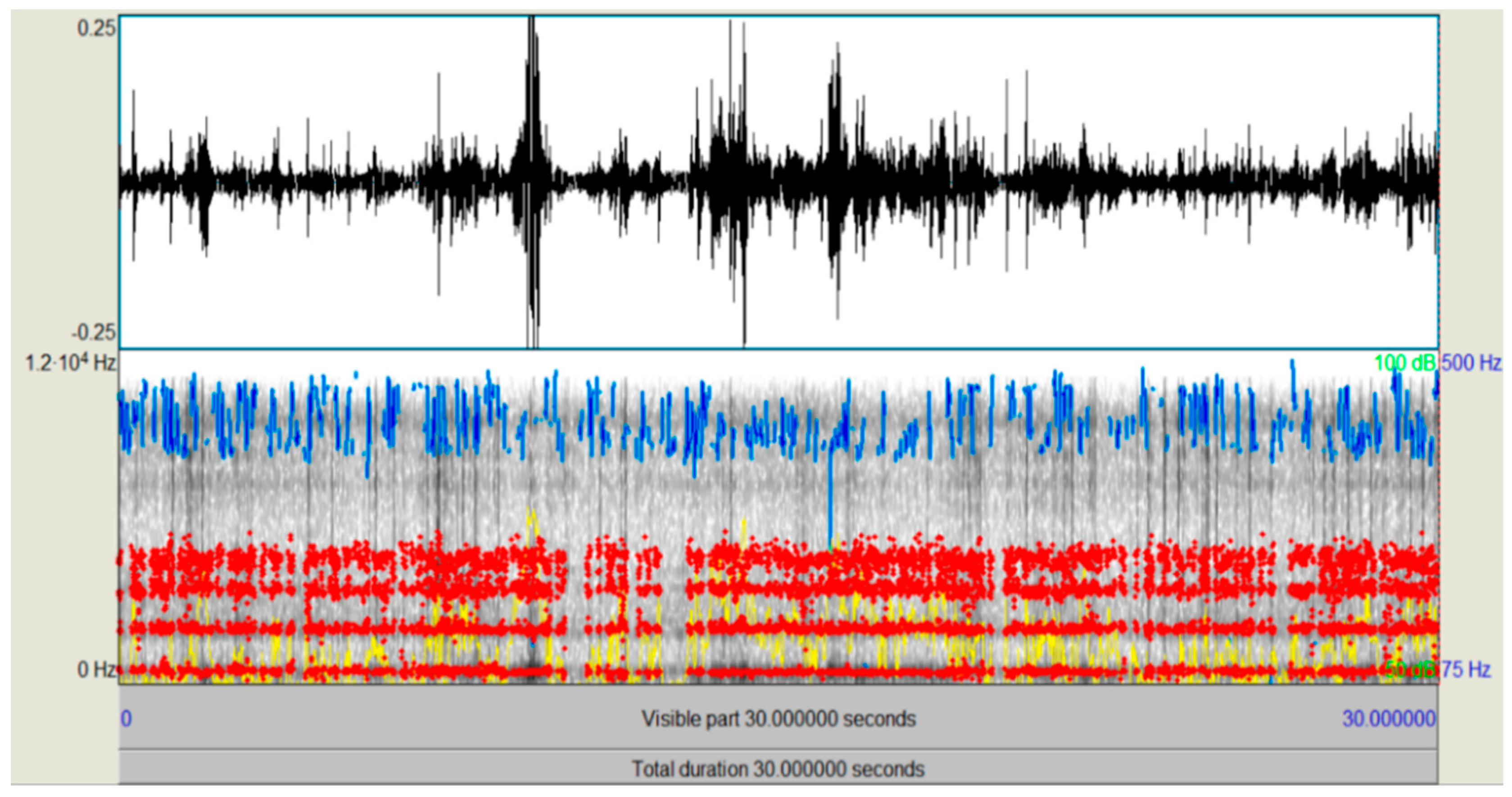
Section 4 outlines the statistical and spectral analysis of the audio sequences related to different rainfall levels;
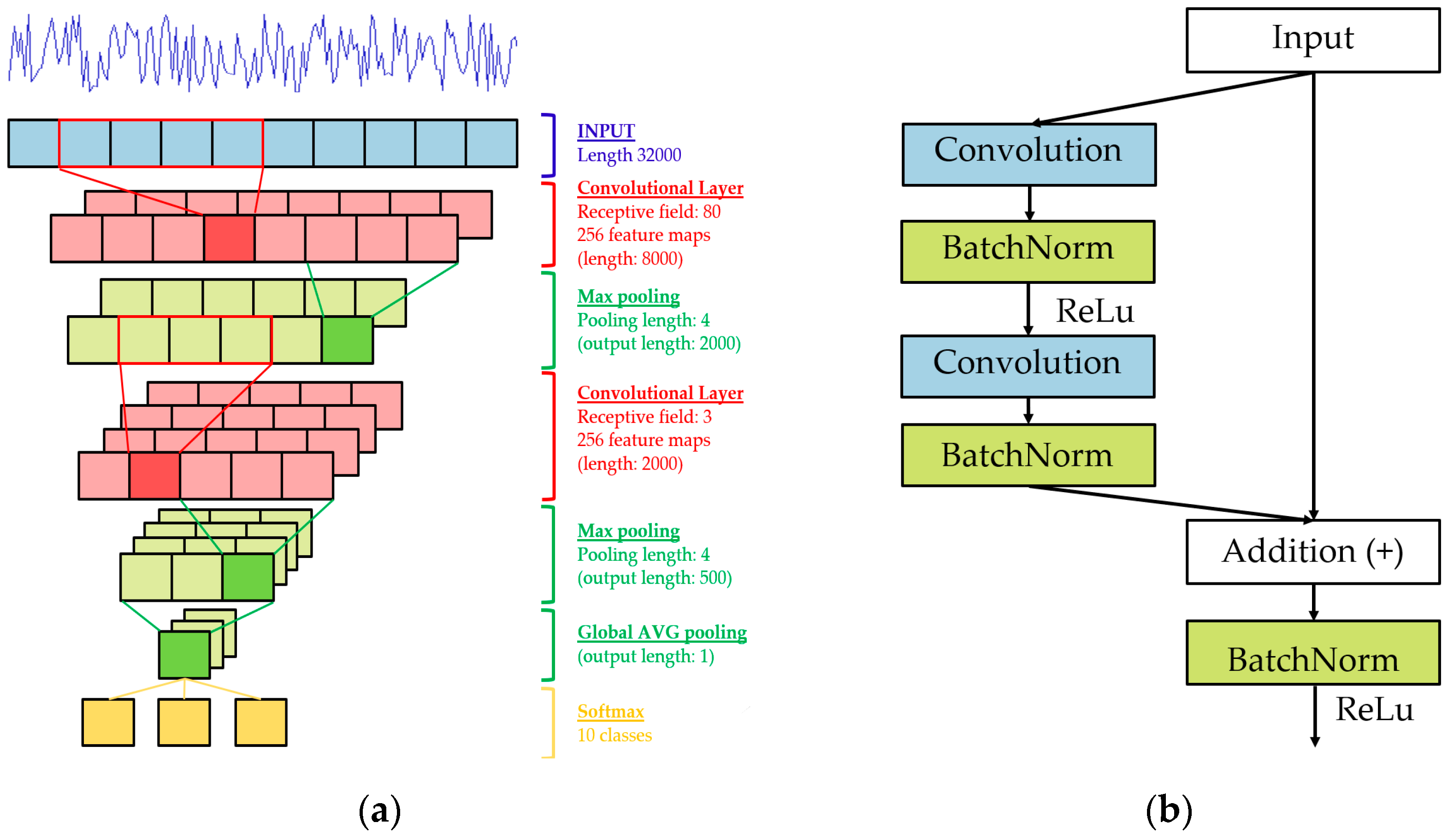
Section 5 provides an overview of the Convolutional Neural Networks (CNN) used for this study;
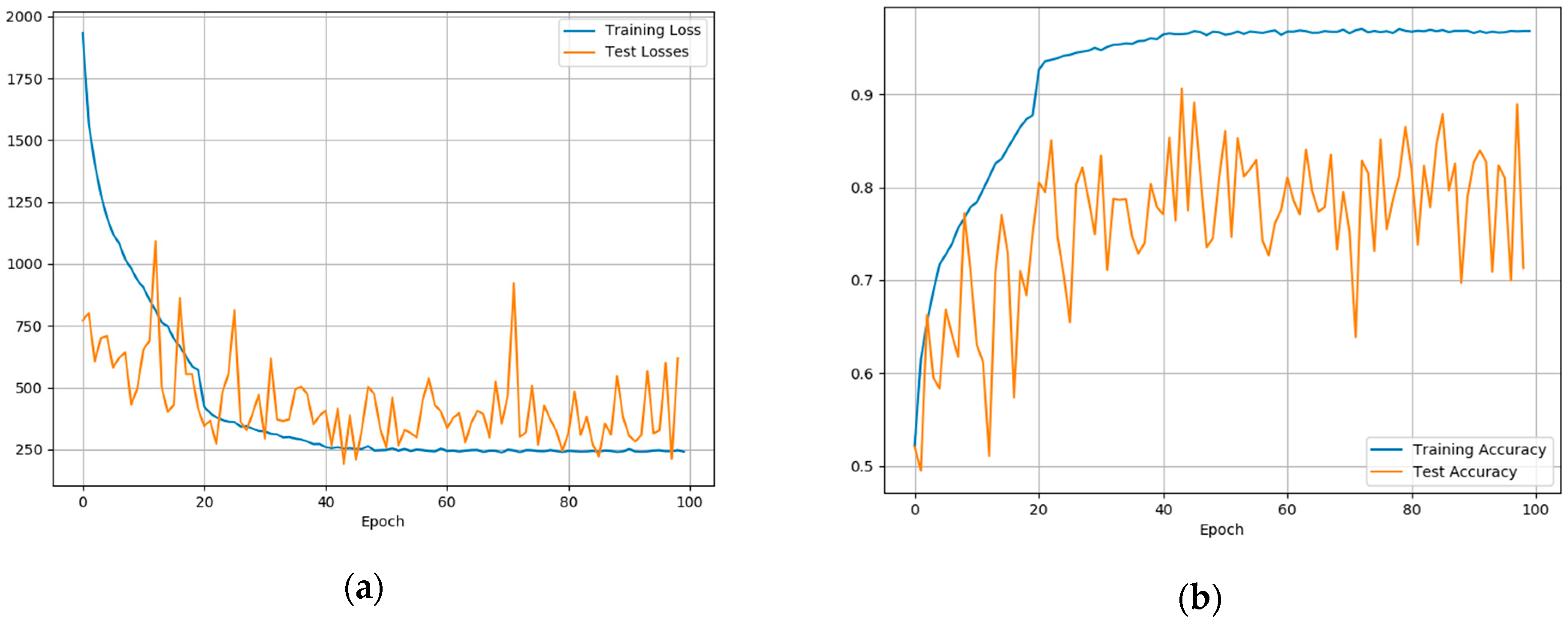
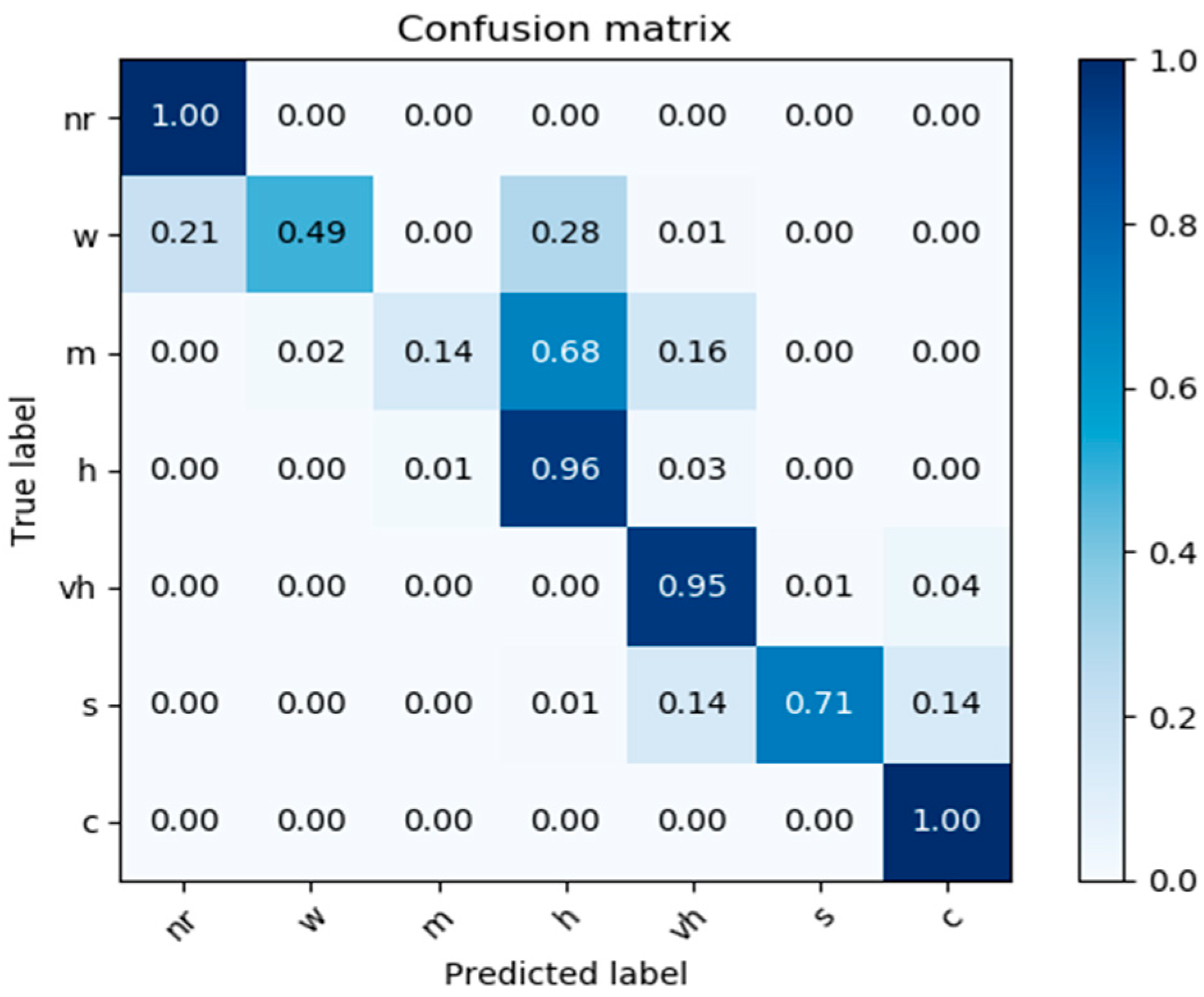
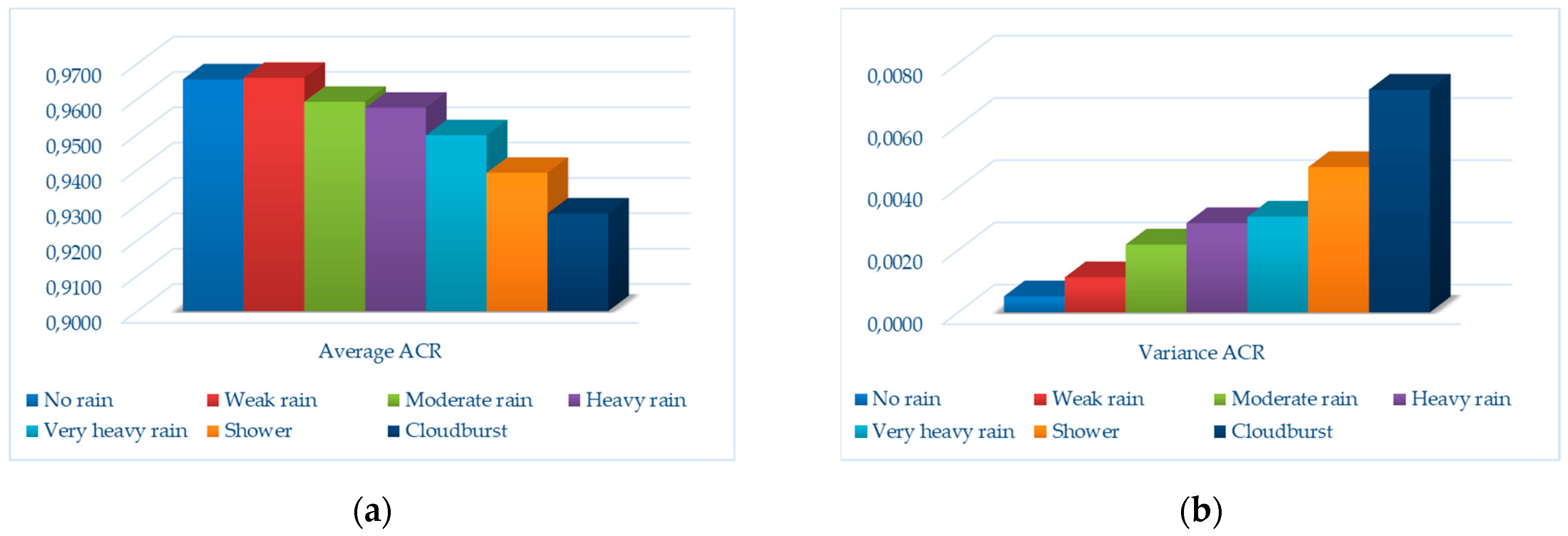
Section 6 depicts the testbed and the various performance tests and results;
Section 7 suggests some ideas for future developments, whereas the last section is devoted to conclusions.





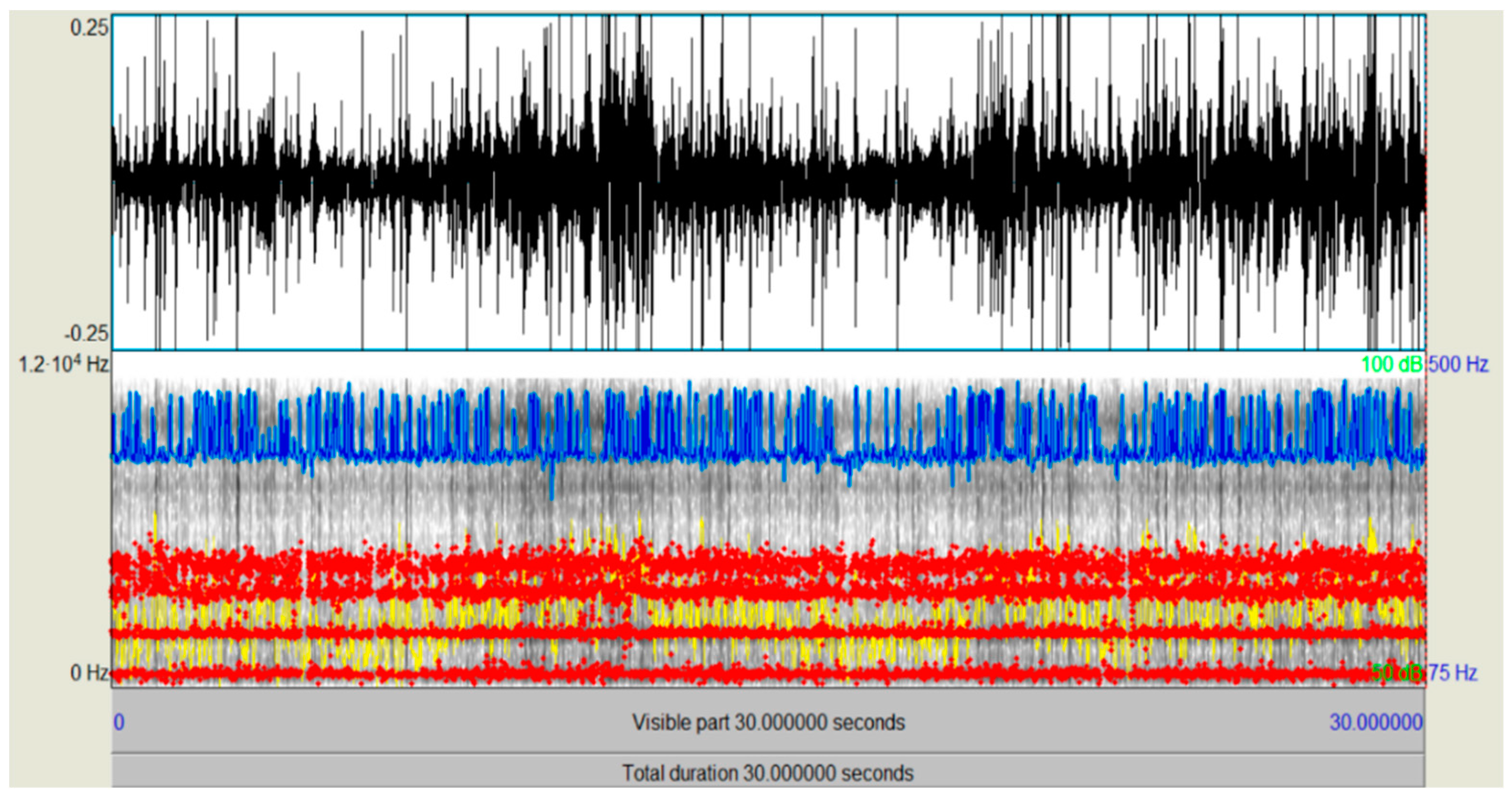
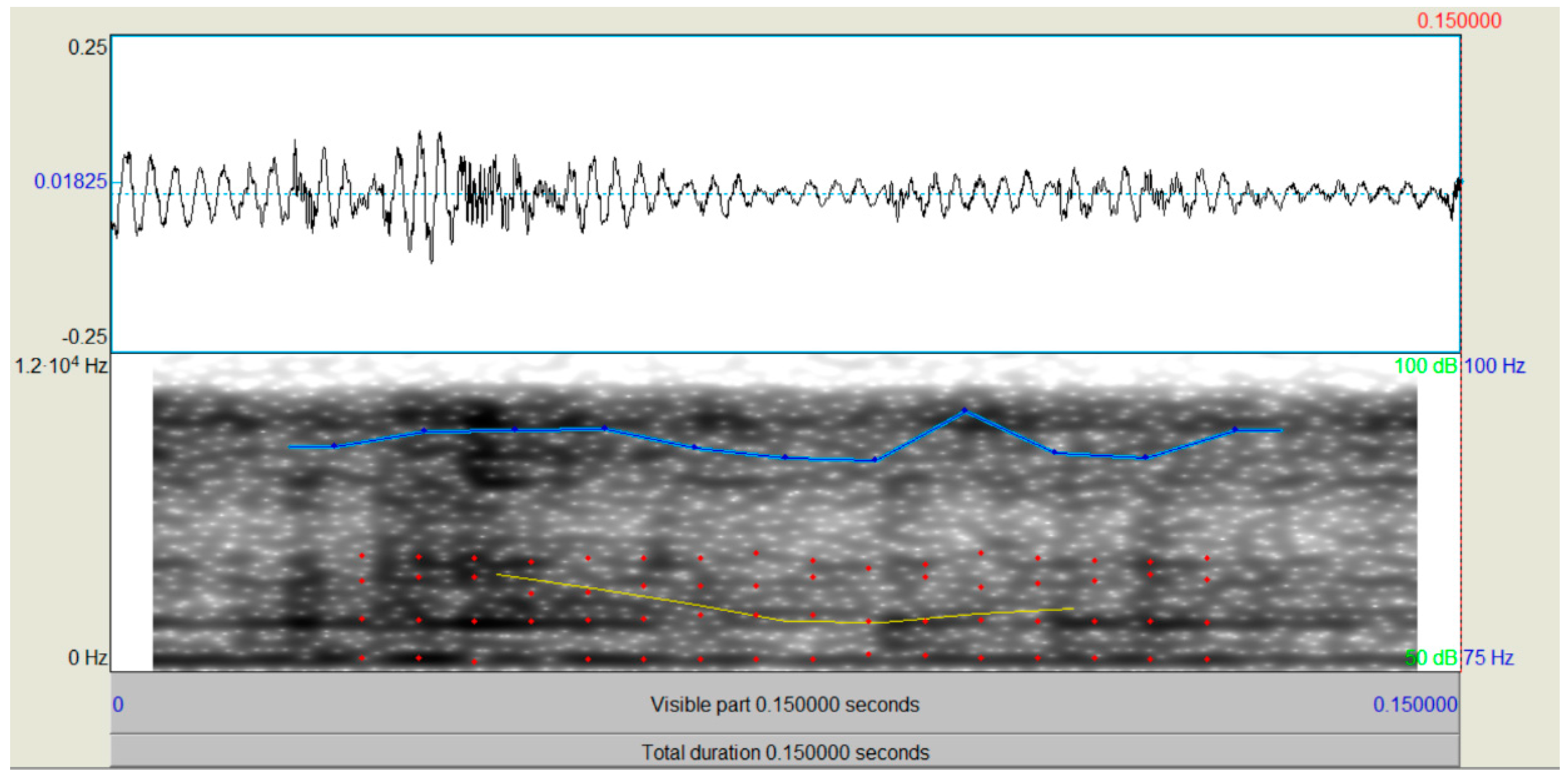
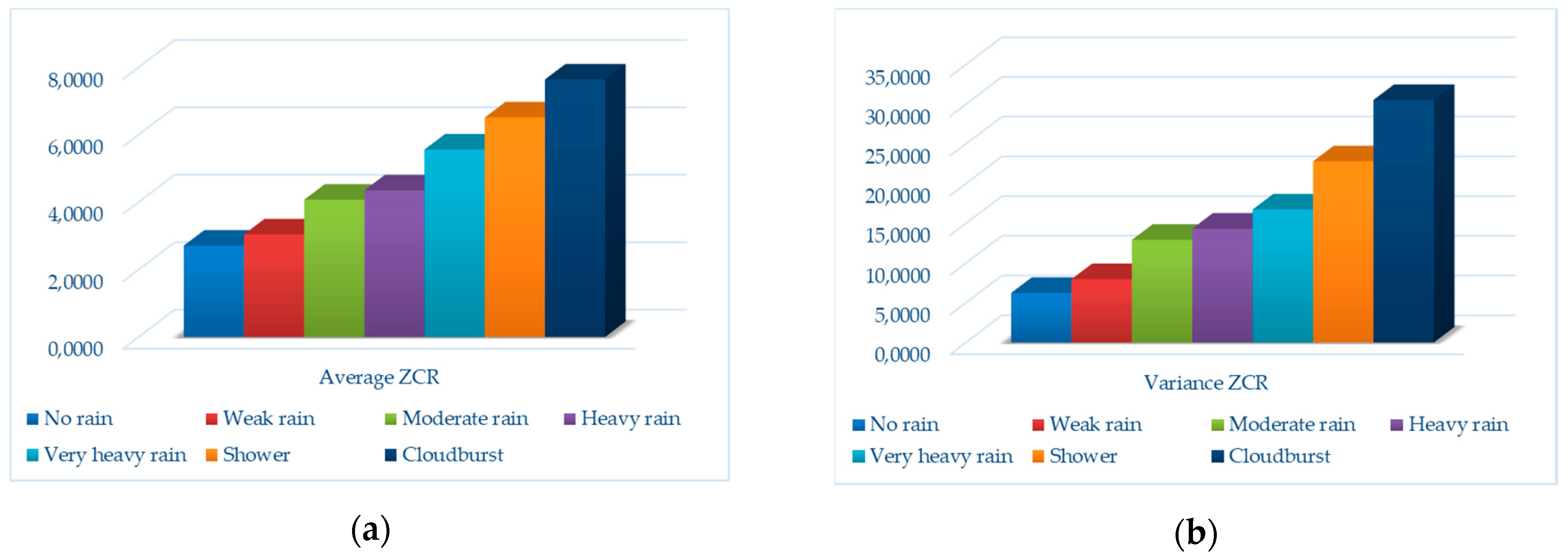
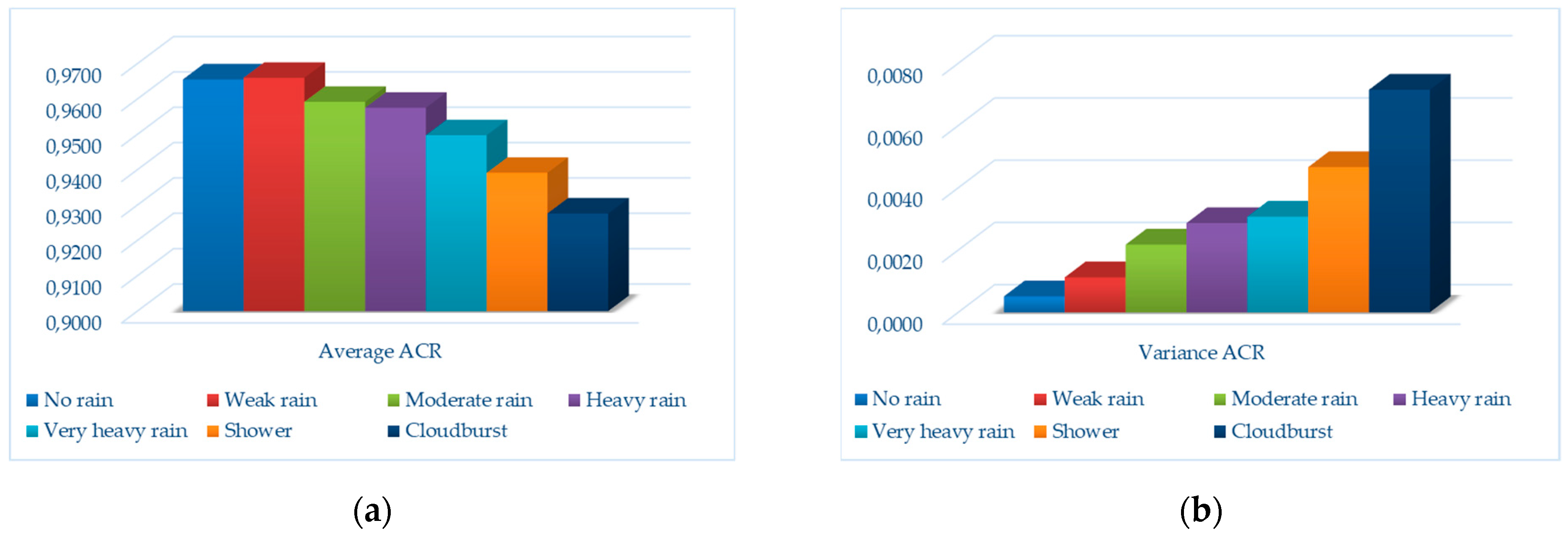

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}