A Syllable-Based Technique for Uyghur Text Compression

 ,
,
Abstract
1. Introduction
2. Related Research
3. Syllables of Uyghur
- Some loanwords from Chinese have two vowels, such as tüän and hua.
- No more than one consonant should appear in front of the vowel, but some loanwords from foreign languages have more than one consonant in front of a vowel, such as Stalin and Strategiyä.
- When syllables are segmented, the syllabic structure of two vowels of certain loanwords from Chinese and the syllabic structure of multiple consonants of certain words from foreign languages are prone to making the segmentation algorithm ambiguous, such as syllabic type 11 (CVVC), which structurally is a combination of syllabic type 3 (CV) and type 2 (VC). When a character string that has the CVVC structure occurs in a word, identifying whether the string has one syllable or two is a key issue for the syllable segmentation.
4. Syllable Segmentation and Selection
4.1. Syllable Segmentation and Analysis
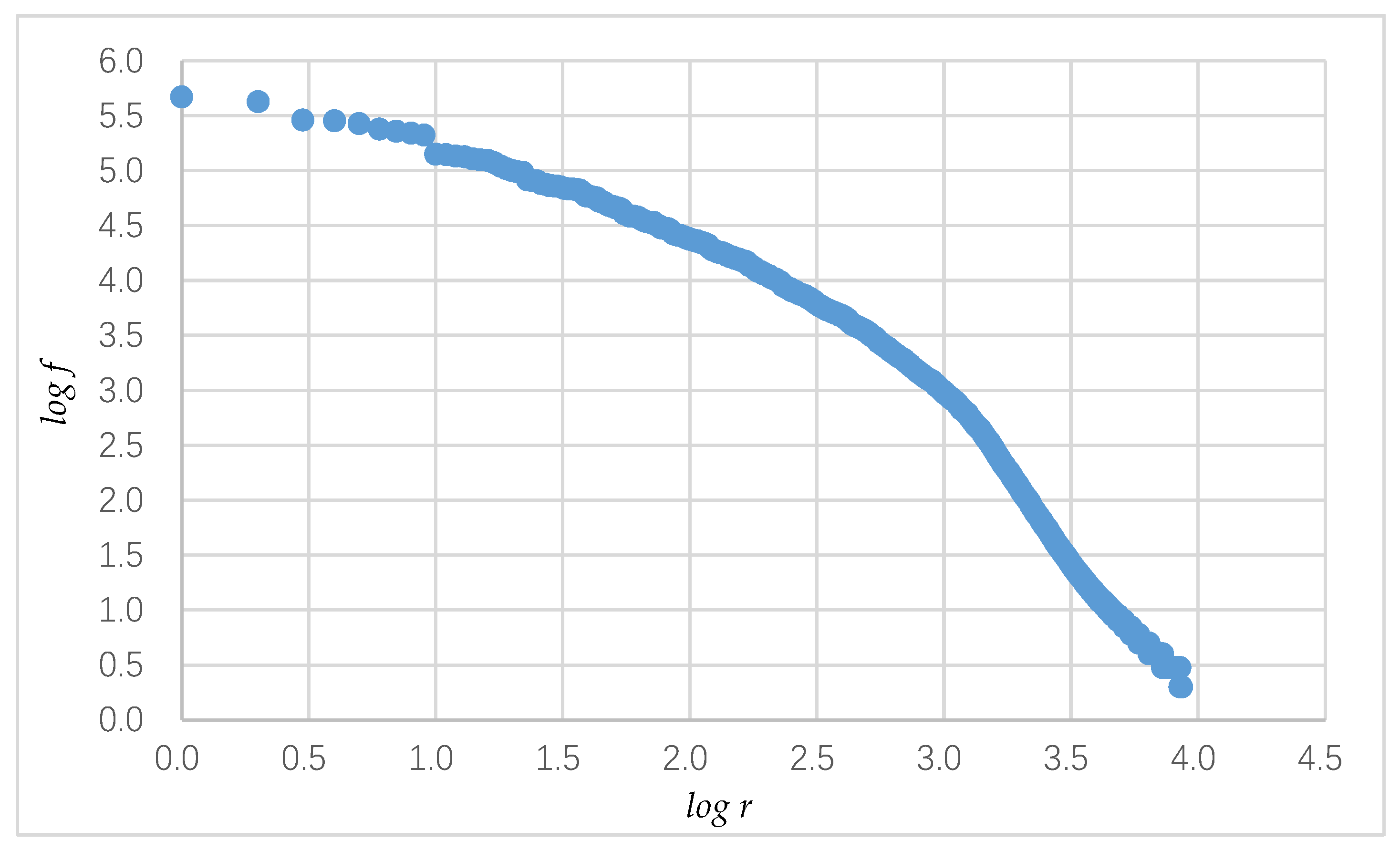
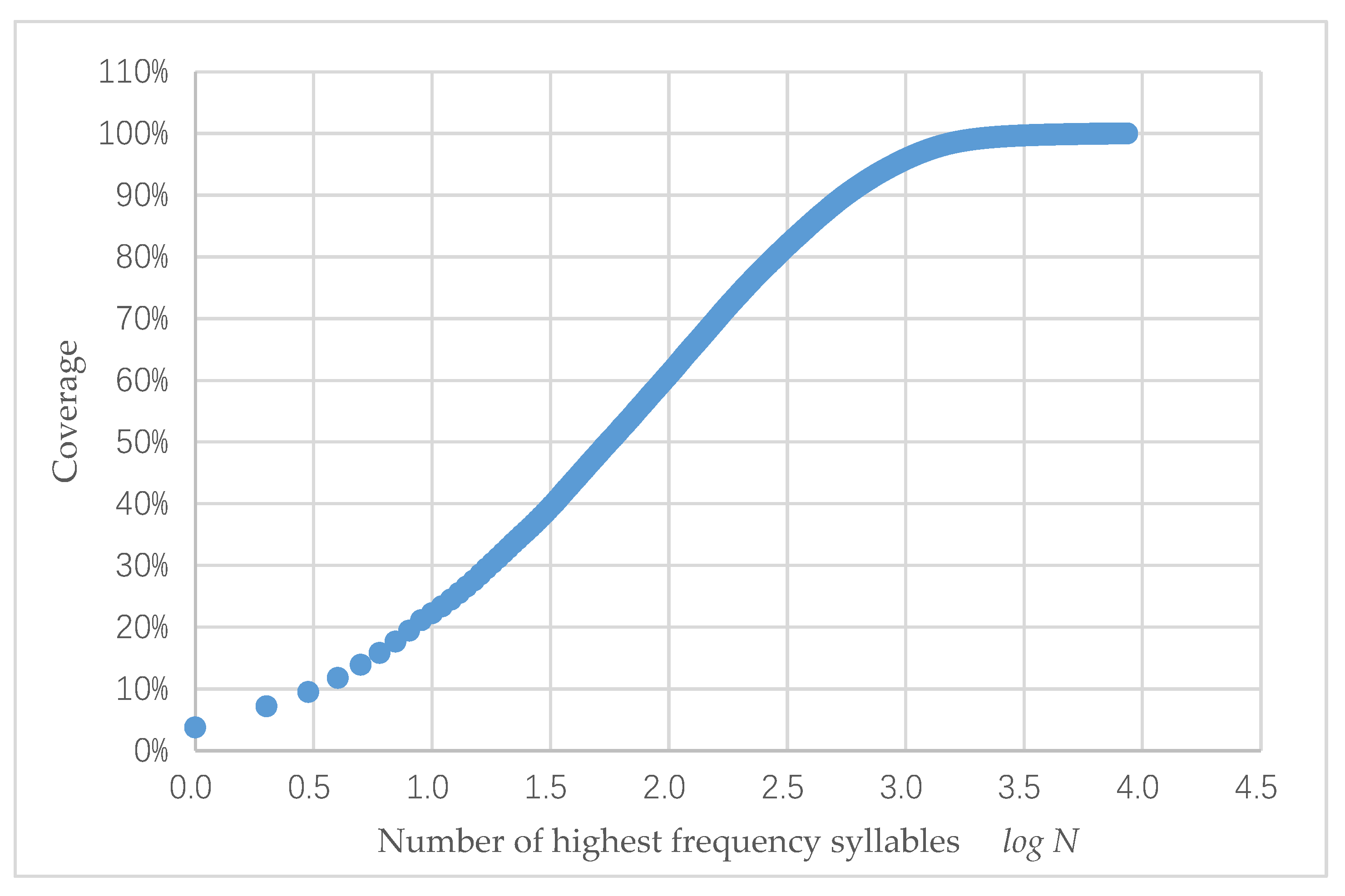
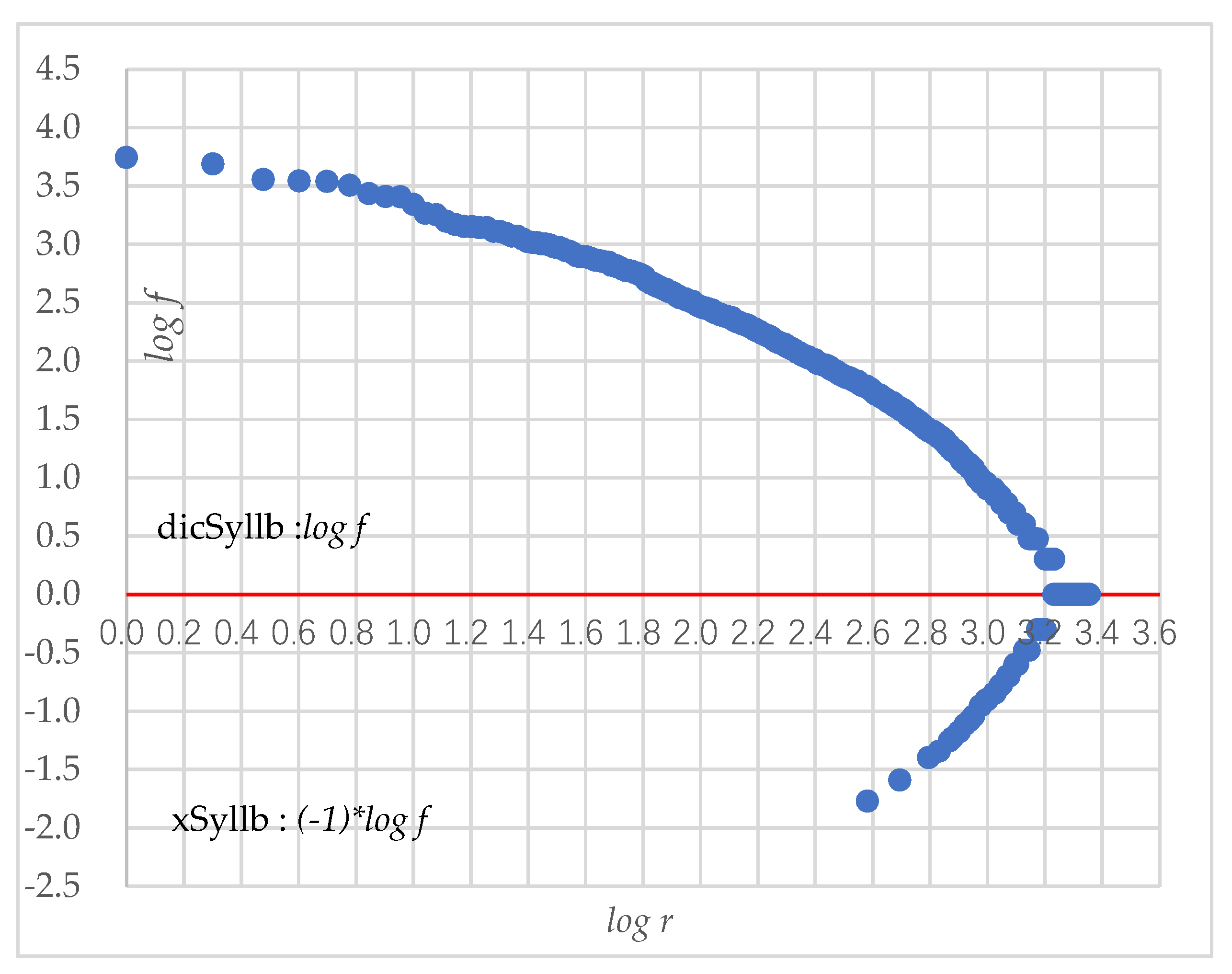
4.2. Selection of High-Frequency Syllables
5. Data Compression Coding
5.1. Syllable Coding
5.1.1. B12 Coding Scheme
- ASCII characters: The frequency of ASCII characters in Uyghur was higher than that of other symbols, such as Chinese characters, so we treated each ASCII character as a syllable, and thus we left the first 128 encoding positions for ASCII characters (0x00–0x7F).
- Uyghur characters: The code range of Uyghur characters was in the Unicode basic block (U0600–U06FF). This block occupied 33 code positions in the syllable coding, including 24 consonant characters “[ل], [ڭ], [گ], [ك], [ق], [ف], [غ], [ش], [س], [ژ], [ز], [ر], [د], [خ], [چ], [ج], [ت], [پ], [ب], [ي], [ۋ], [ھ], [ن], [م] “ and eight vowel characters “[ۈ],[ۇ],[ۆ], [و], [ى], [ې],[ە],[ا]“ and special character HAMZE [ئ] (U0626).
- Uyghur commonly used punctuation marks: Common punctuation marks included “،” (U060C), “؛” (U061B), “؟” (U061F), and “-” (U0640). They occupied four code positions.
- Other commonly used punctuation marks in Uyghur: “«“ (U00AB), “»“ (U00BB), “…” (U2026), four-per-em space (U2005), left-to-right mark (U200E), and right-to-left mark (U200F). They occupied six code positions.
- We reserved 15 positions to flags, for describing various situations in the data stream.
- High-frequency Uyghur syllables: Excluding the previously mentioned syllable codes, 1862 code positions remained. As shown in Figure 1, the coverage of 1862 syllable codes was around 98%, which contained the more commonly used high-frequency syllables.
5.1.2. B16 Coding Scheme
5.1.3. Code Block Division
5.2. Design of Flag Coding
5.2.1. B12 Scheme Flags
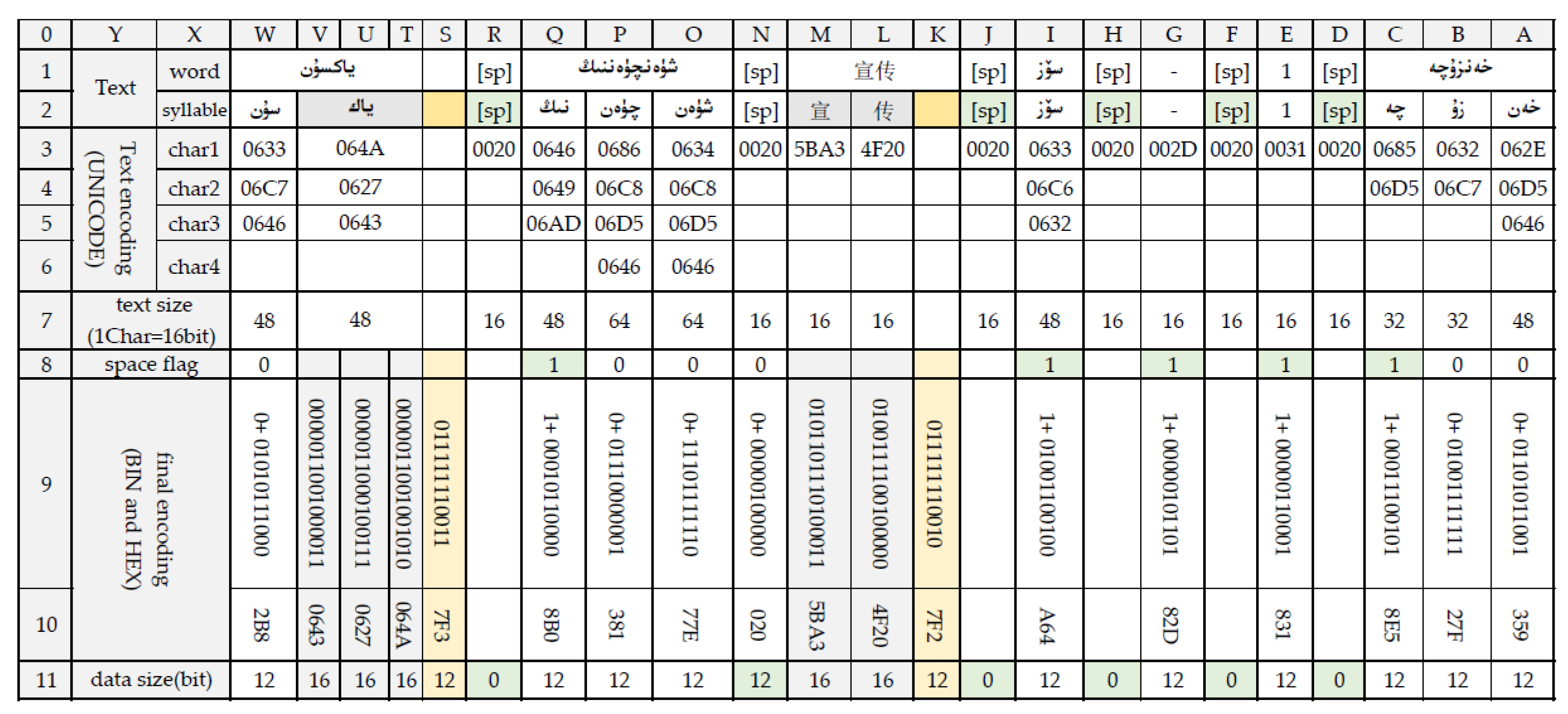
Sencoding = SDB + A1A2 + fXC (0x7F2) + R1R2 + fXBB (0x7FA) C1–C10fxBE(0xE002) + S1 +
fXC(0x7F3) U3U4U5 + fxC(0x7F3)E1E2E3.
5.2.2. B16 Scheme Flags
Sencoding = SDB + A1A2 + R1R2 + C1–C10 + S3(0xE003) + S5(0xE005) + U3U4U5 +
fxC(0xE001) E3 + fxC(0xE001)E5 + fxC(0xE001)E3 + fxC(0xE001)E5.
5.2.3. Datagram and File Format
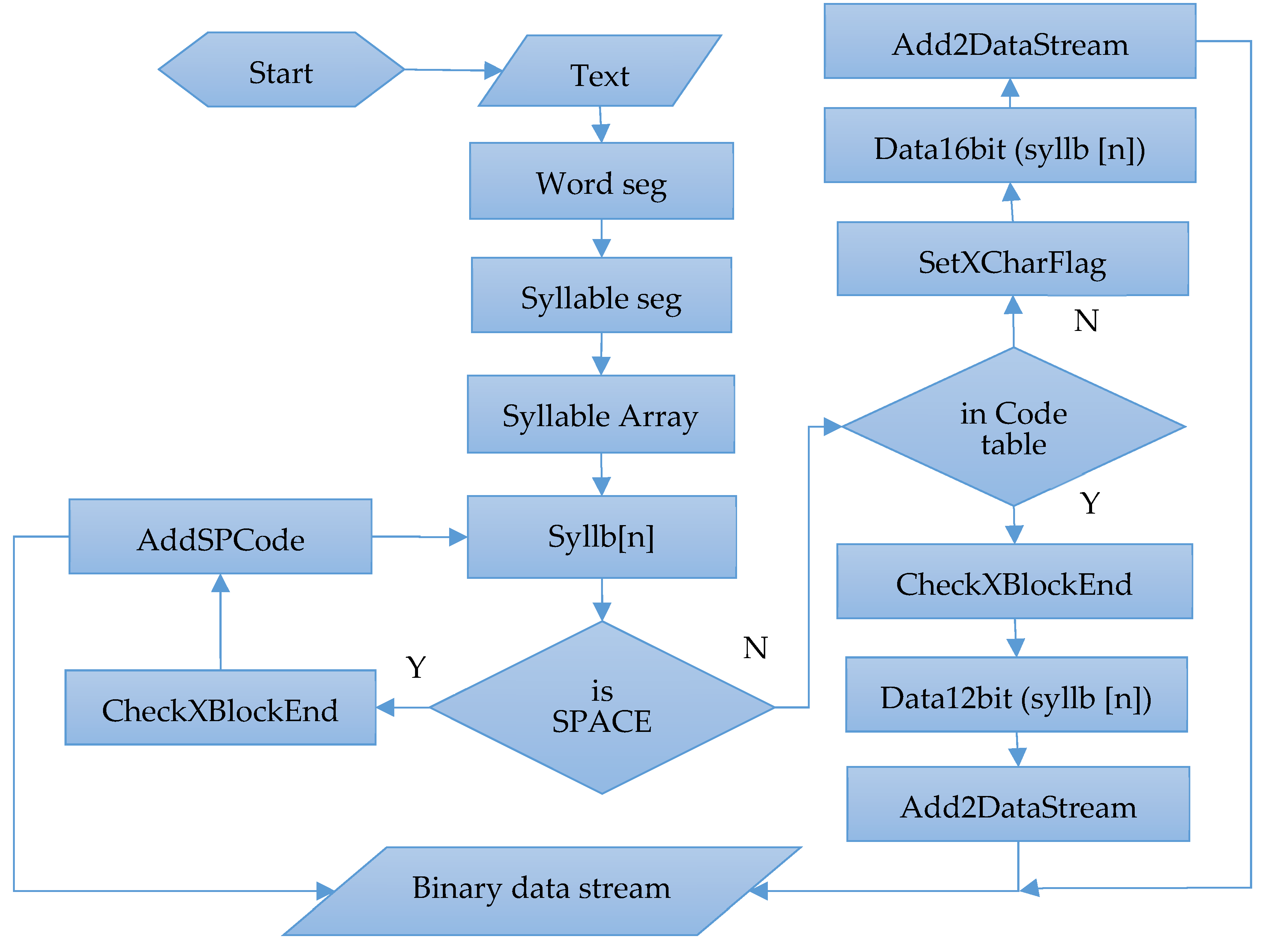
5.3. Data Compression Process
5.4. Data Compression Process
5.4.1. Compression Ratio
5.4.2. Average Coding Length
5.5. Data Decompression
5.5.1. Decompression of B12 Scheme
- Intercept 12 bit; if it was dicSyllb, read the next 12 bits.
- If the decoding result was fXC, n Unicode characters would be intercepted continuously, where n = fXC-0x7F0, and each character was 16 bits in length.
- If the decoding result was fXBB, then the Unicode characters would be intercepted continuously until fXBE was read.
- If there was no remaining bit data stream, the decompression was completed; otherwise, repeat Step 1. The decoding algorithm is shown in Algorithm 1:
| Algorithm 1 B12 scheme decoding algorithm | |
| Input: Binary data stream Output: Decoded text stream | |
| while start_position < Binary_data_length do data12bit = get12bitData (start_position); if data12bit is a syllable in the dictionary then //one syllable text = text + Decode_with_dictionary (data12bit); start_position = start_position + 12 bit; continue; end if if xChar_Flag < data12bit < xChar_Block_Begin_Flag then //xChars count < 10 xChars_number = code12bit - xChar_Flag; text = text + Get_Unicode_characters (xChars_number); start_position = start_position + xChars_number *16 bit; continue; end if if data12bit == xChar_Block_Begin_Flag then //xChars count > 9 xChars_block_length = Find_next_xChar_block_end_flag (start_position); text= text + Get_Unicode_characters (xChars_block_length/16bit); start_position = start_position + xChars_block_length; end if end while |
5.5.2. Decompression of B16 Scheme
- Read the original text in Unicode characters.
- Intercept 1 character (2 bytes); if the encoding range is in the range 0xE003-0xF8FF, then use the dictionary encoding table to decode.
- Intercept 1 character (2 bytes); if the encoding is equal to fXC (0xE001), then read the next Unicode character directly. Repeat Step 2. If no character data stream remains, the decompression is complete.
6. Experiment and Analysis
6.1. Experimental Corpus and Comparison Methods
- In this study, we randomly selected 15 texts according to size as the experimental corpus. We based the corpus on Unicode encoding.
6.2. Experimental Results
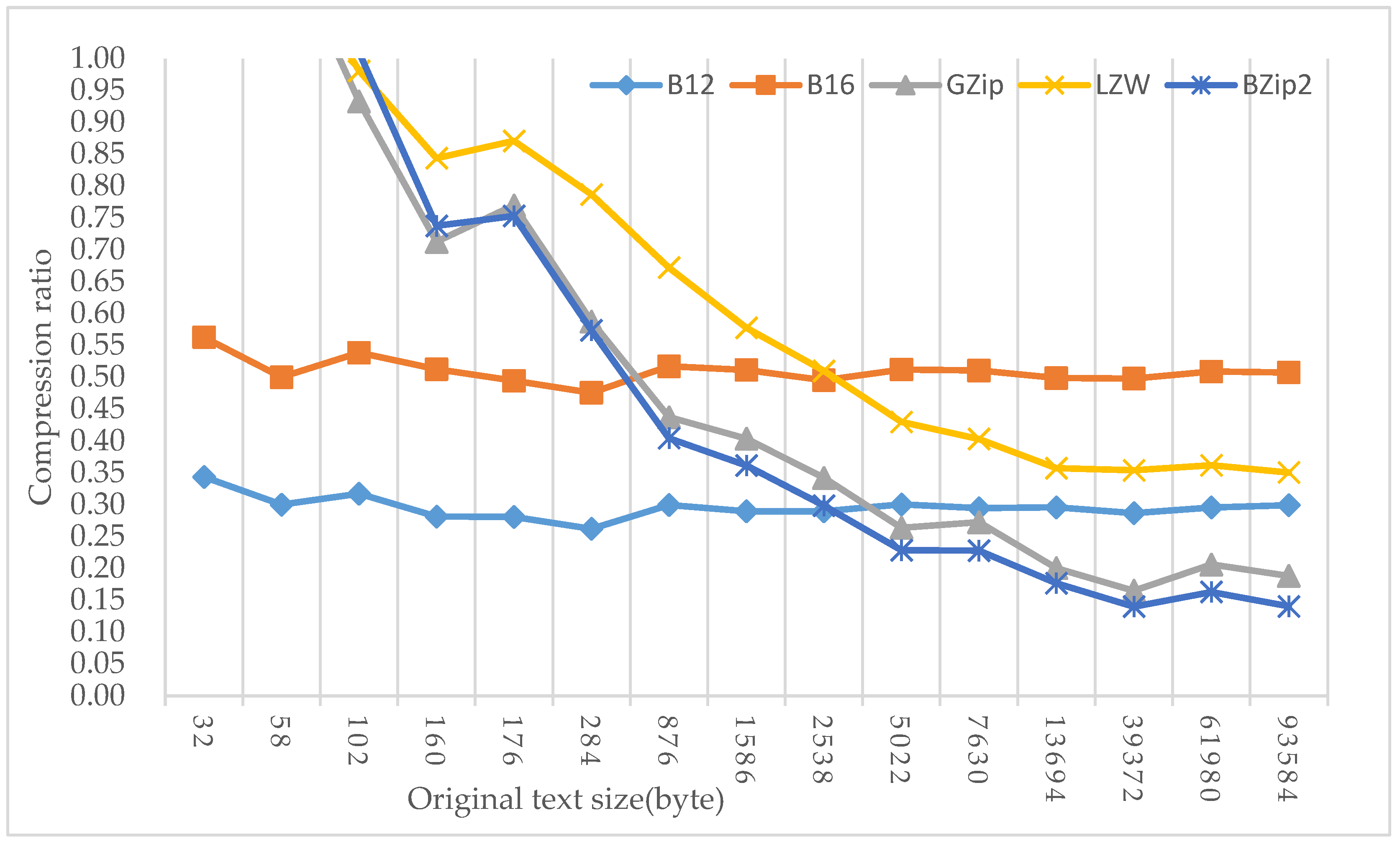
6.2.1. Compression of Text of Different Sizes
6.2.2. Short-Text Compression
6.3. Experimental Analysis
6.4. CRbest and CRworst of the B12 Scheme
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- David, S.; Le-Nan, W. Data Compression, 2nd ed.; Publishing House of Electronics Industry: Beijing, China, 2003; pp. 9–163. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Labs Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Resonance 2006, 11, 91–99. [Google Scholar] [CrossRef]
- Ziv, J.; Abraham, L. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Ziv, J.; Abraham, L. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Akman, K.I. A new text compression technique based on language structure. J. Inf. Sci. 1995, 21, 87–94. [Google Scholar] [CrossRef]
- Moffat, A. Word-based text compression. Softw. Pract. Exp. 1989, 19, 185–198. [Google Scholar] [CrossRef]
- Moffat, A.; Isal, R.Y. Word-based text compression using the Burrows-Wheeler transform. Inf. Process. Manag. 2005, 41, 1175–1192. [Google Scholar] [CrossRef]
- Crochemore, M.; Langiu, A.; Mignosi, F. Note on the greedy parsing optimality for dictionary-based text compression. Theor. Comput. Sci. 2014, 525, 55–59. [Google Scholar] [CrossRef]
- Gardner-Stephen, P.; Bettison, A.; Challans, R.; Hampton, J.; Lakeman, J.; Wallis, C. Improving Compression of Short Messages. Int. J. Commun. Netw. Syst. Sci. 2013, 6, 497–504. [Google Scholar] [CrossRef][Green Version]
- Platos, J.; Snasel, V.; Elqawasmeh, E. Compression of small text files. Adv. Eng. Inform. 2008, 22, 410–417. [Google Scholar] [CrossRef]
- Rein, S.; Guhmann, C.; Fitzek, F.H. Compression of Short Text on Embedded Systems. J. Comput. 2006, 1, 1–10. [Google Scholar] [CrossRef]
- Kalajdzic, K.; Ali, S.H.; Patel, A. Rapid lossless compression of short text messages. Comput. Stand. Interfaces 2015, 37, 53–59. [Google Scholar] [CrossRef]
- Adubi, S.A.; Misra, S. Syllable-Based Text Compression: A Language Case Study. Arab. J. Sci. Eng. 2016, 41, 3089–3097. [Google Scholar] [CrossRef]
- Nguyen, V.H.; Nguyen, H.T.; Duong, H.N.; Snasel, V. A Syllable-Based Method for Vietnamese Text Compression. International Conference on Ubiquitous Information Management and Communication; ACM: Danang, Vietnam, 2016. [Google Scholar]
- Akman, I.; Bayindir, H.; Ozleme, S. A lossless text compression technique using syllable based morphology. Int. Arab J. Inf. Technol. 2011, 8, 66–74. [Google Scholar]
- Oswald, C.; Ajith, K.J.; Avinash, J. A Graph-Based Frequent Sequence Mining Approach to Text Compression. In Mining Intelligence and Knowledge Exploration, Proceedings of the International Conference on Mining Intelligence and Knowledge Exploration, Hyderabad, India, 13–15 December 2017; Springer: Hyderabad, India, 2017. [Google Scholar]
- Bharathi, K.; Kumar, H.; Fairouz, A. A Plain-Text Incremental Compression (PIC) Technique with Fast Lookup Ability. In Proceedings of the 2018 IEEE 36th International Conference on Computer Design (ICCD), Orlando, FL, USA, 7–10 October 2018; IEEE: Orlando, FL, USA, 2018. [Google Scholar]
- Vijayalakshmi, B. Lossless Text Compression Technique Based on Static Dictionary for Unicode Tamil Document. Int. J. Pure Appl. Math. 2018, 118, 85–91. [Google Scholar]
- Sinaga, A.; Adiwijaya Nugroho, H. Development of word-based text compression algorithm for Indonesian language document. In Proceedings of the 2015 3rd International Conference on Information and Communication Technology, ICoICT, Nusa Dua, Indonesia, 27–29 May 2015; IEEE: Bali, Indonesia, 2015. [Google Scholar]
- Farhad Mokter, M.; Akter, S.; Palash Uddin, M.; Ibn Afjal, M.; Al Mamun, M.; Abu Marjan, M. An Efficient Technique for Representation and Compression of Bengali Text. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing, ICBSLP, Sylhet, Bangladesh, 21–22 September 2018; IEEE: Sylhet, Bangladesh, 2018. [Google Scholar]
- Hilal, T.A.; Hilal, H.A. Arabic text lossless compression by characters encoding. Procedia Comput. Sci. 2019, 155, 618–623. [Google Scholar] [CrossRef]
- Chen, Q.; Chen, X.; Han, D. Compression algorithm LZW on Chinese text. Comput. Eng. Appl. 2014, 50, 112–116. [Google Scholar]
- Satoh, N.; Morihara, T.; Okada, Y.; Yoshida, S. Study of Japanese text compression. In Proceedings of the Data Compression Conference, DCC ’97, Snowbird, UT, USA, 25–27 March 1997; IEEE: Snowbird, UT, USA, 1997. [Google Scholar]
- Zhong-Qi, X.; Winira, M. Uyghur text compression technique research. J. Xinjiang Univ. 2012, 29, 9–12. [Google Scholar]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional long short-term memory network with a conditional random field layer for Uyghur part-of-speech tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef]
- Osman, T.; Yang, Y.; Tursun, E.; Cheng, L. Collaborative Analysis of Uyghur Morphology Based on Character Level. Acta Sci. Nat. Univ. Pekin. 2019, 55, 47–54. [Google Scholar]
- Nurmemet, Y.; Wushour, S.; Reyiman, T. Syllable based language model for large vocabulary continuous speech recognition of Uyghur. J. Tsinghua Univ. 2013, 53, 741–744. [Google Scholar]
- Wayit, A.; Jamila, W.; Turgun, I. Modern Uyghur automatic syllable segmentation method and its implementation. China Sci. 2015, 10, 957–961. [Google Scholar]
- LZW Data Compression. Available online: http://dogma.net/markn/articles/lzw/lzw.htm/ (accessed on 10 January 2020).
- GZipStream Class (System.IO.Compression). Available online: https://docs.microsoft.com/zh-cn/dotnet/api/system.io.compression.gzipstream?view=netframework-4.8/ (accessed on 10 January 2020).
- Tuergen, I.; Kahaerjiang, A.; Aishan, W.; Maihemuti, M. A Survey of Central Asian Language Processing. Chin. Inf. Process 2018, 32, 1–13, 21. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Syllabic Structure | Example | No. | Syllabic Structure | Example |
|---|---|---|---|---|---|
| 1 | V | ئا/A | 7 | CCV | ستالىن/Stalin |
| 2 | VC | ئات/At | 8 | CCVC | فرانكا/Franka |
| 3 | CV | كالا/Kala | 9 | CCVCC | تىرانسپورت/Tiransport |
| 4 | CVC | نان/Nan | 10 | CVV | خۇا/Hua |
| 5 | VCC | ئەرز/Ärz | 11 | CVVC | تۈەن/Tüän |
| 6 | CVCC | خەلق/Hälq | 12 | CCCV | سترومېتىر/Strometir |
| Structure | Number of | Frequency | Structure | Number of | Frequency | ||
|---|---|---|---|---|---|---|---|
| Theoretical | Actual | Theoretical | Actual | ||||
| V | 8 | 8 | 31,653 | CCV | 4608 | 425 | 1358 |
| VC | 192 | 172 | 34,002 | CCVC | 110,592 | 688 | 2829 |
| CV | 192 | 184 | 593,850 | CCVCC | 2,654,208 | 151 | 287 |
| CVC | 4608 | 2992 | 441,376 | CVV | 1536 | 260 | 1358 |
| VCC | 4608 | 294 | 1319 | CVVC | 36,864 | 394 | 2194 |
| CVCC | 110,592 | 2956 | 11,667 | CCCV | 110,592 | 97 | 180 |
| No. | Encoding Entity | Encoding Range | ||
|---|---|---|---|---|
| Unicode | B12 | B16 | ||
| 1 | ASCII characters | U0000–U007F | 0x000–0x07F | Unchanged |
| 2 | Uyghur characters | U0600–U06FF | 0x080–0x0A0 | Unchanged |
| 3 | Uyghur punctuation marks | U0600–U06FF | 0x0A1–0x0A4 | Unchanged |
| 4 | Other punctuation marks | U00AB, U00BB, U2005, U200E, U200F, U2026 | 0x0A5–0x0AA | Unchanged |
| 5 | Selected syllables | NULL | 0x0AB–0x7F0 | UE003–UF8FF |
| 6 | Flags | NULL | 0x7F1–0x7FF | UE000–UE002 |
| No. | Type | Content | Size (MB) | No. | Type | Content | Size (MB) |
|---|---|---|---|---|---|---|---|
| 1 | Hot news | CCTV Focus Interview Program (2018/7 to 2018/12) | 8.36 | 7 | Book | Roosevelt Biography | 2.33 |
| 2 | Natural sciences | CCTV Human and Nature Program (2015 to 2018) | 5.57 | 8 | Novel | Farmer’s Son Wang Leyi | 1.43 |
| 3 | General news | CCTV News Hookup (2018/7 to 2018/12) | 19.8 | 9 | Other | Glossary of scientific terms | 1.6 |
| 4 | Agricultural technology | CCTV Get Rich Program (51st-94th, 2018) | 4.76 | 10 | Other | Name list of various institutions in Xinjiang | 0.6 9600 in total |
| 5 | Educational books | Elementary and Secondary Child Psychology | 1.6 | 11 | Short text (mobile terminal) | Web message, comment, SMS, WeChat chat data | 1 2908 in total |
| 6 | Popular science books | The World’s Most | 0.6 | Corpus total size 46.8 MB; unique words 136,523; and unique syllables 7434. | |||
| No. | Flag | Code | Meaning | Note |
|---|---|---|---|---|
| 1 | SDB | 0xE000 | Syllable Data Begin | Start decoding |
| 2 | fXC | 0x7F1–0x7F9 | xChar begin | Will encounter xChar sequences of length 0 < n < 10, each xChar encoding length is 16 bits, n = fXC-0x7F0 |
| 3 | fXBB | 0x7FA | xChar Block Begin | Will encounter xChar sequences with length n > 9, start to intercept 16bit data until fXBE is encountered |
| 5 | fXBE | 0xE002 | xChar Block End | The end of the xChar sequence, starting to intercept 12-bit data |
| 4 | ESD | 0x7FF | End of syllable data | Stop decoding |
| No. | Flag | Code | Meaning | Note |
|---|---|---|---|---|
| 1 | SDB | 0xE000 | Syllable data begin | Start decoding |
| 2 | fXC | 0xE001 | Private use area | Identifies that the next character is a private area character |
| 3 | ESD | 0xE002 | End of syllable data | Stop decoding |
| Size (Bytes) | File Count | dicChar | unique dicChar | 129 |
| <50 | 138 | average frequency | 3480 | |
| 50–100 | 315 | dicSyllb | unique dicSyllb | 1608 |
| 101–200 | 633 | average frequency | 94 | |
| 201–300 | 588 | xchar | unique xChar | 631 |
| 301–400 | 421 | average frequency | 3 | |
| 401–500 | 312 | xSyllb | unique xSyllb | 658 |
| 501–1000 | 466 | average frequency | 2 | |
| >1000 | 35 | words | unique word | 13,631 |
| Total | 2908 | average frequency | 4 |
| So | CR | BPC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Bytes) | B12 | B16 | GZip | LZW | BZip2 | B12 | B16 | GZip | LZW | BZip2 |
| 32 | 0.34 | 0.56 | 1.50 | 1.31 | 2.09 | 5.50 | 9.00 | 24.00 | 21.00 | 33.50 |
| 58 | 0.30 | 0.50 | 1.20 | 1.18 | 1.50 | 4.80 | 8.00 | 19.20 | 18.93 | 24.00 |
| 102 | 0.32 | 0.54 | 0.93 | 0.98 | 1.01 | 5.08 | 8.62 | 14.92 | 15.69 | 16.15 |
| 160 | 0.28 | 0.51 | 0.71 | 0.84 | 0.74 | 4.50 | 8.20 | 11.40 | 13.50 | 11.80 |
| 176 | 0.28 | 0.49 | 0.77 | 0.87 | 0.75 | 4.49 | 7.91 | 12.31 | 13.93 | 12.04 |
| 284 | 0.26 | 0.48 | 0.59 | 0.79 | 0.57 | 4.20 | 7.61 | 9.40 | 12.59 | 9.17 |
| 876 | 0.30 | 0.52 | 0.44 | 0.67 | 0.40 | 4.79 | 8.27 | 7.00 | 10.75 | 6.47 |
| 1586 | 0.29 | 0.51 | 0.40 | 0.58 | 0.36 | 4.63 | 8.18 | 6.46 | 9.24 | 5.78 |
| 2538 | 0.29 | 0.50 | 0.34 | 0.51 | 0.30 | 4.64 | 7.92 | 5.47 | 8.16 | 4.77 |
| 5022 | 0.30 | 0.51 | 0.26 | 0.43 | 0.23 | 4.81 | 8.19 | 4.22 | 6.88 | 3.66 |
| 7630 | 0.29 | 0.51 | 0.27 | 0.40 | 0.23 | 4.71 | 8.17 | 4.36 | 6.45 | 3.65 |
| 13,694 | 0.30 | 0.50 | 0.20 | 0.36 | 0.18 | 4.73 | 7.98 | 3.21 | 5.72 | 2.83 |
| 39,372 | 0.29 | 0.50 | 0.16 | 0.35 | 0.14 | 4.59 | 7.97 | 2.64 | 5.66 | 2.24 |
| 61,980 | 0.30 | 0.51 | 0.21 | 0.36 | 0.16 | 4.73 | 8.14 | 3.30 | 5.79 | 2.61 |
| 93,584 | 0.30 | 0.51 | 0.19 | 0.35 | 0.14 | 4.79 | 8.12 | 3.01 | 5.61 | 2.25 |
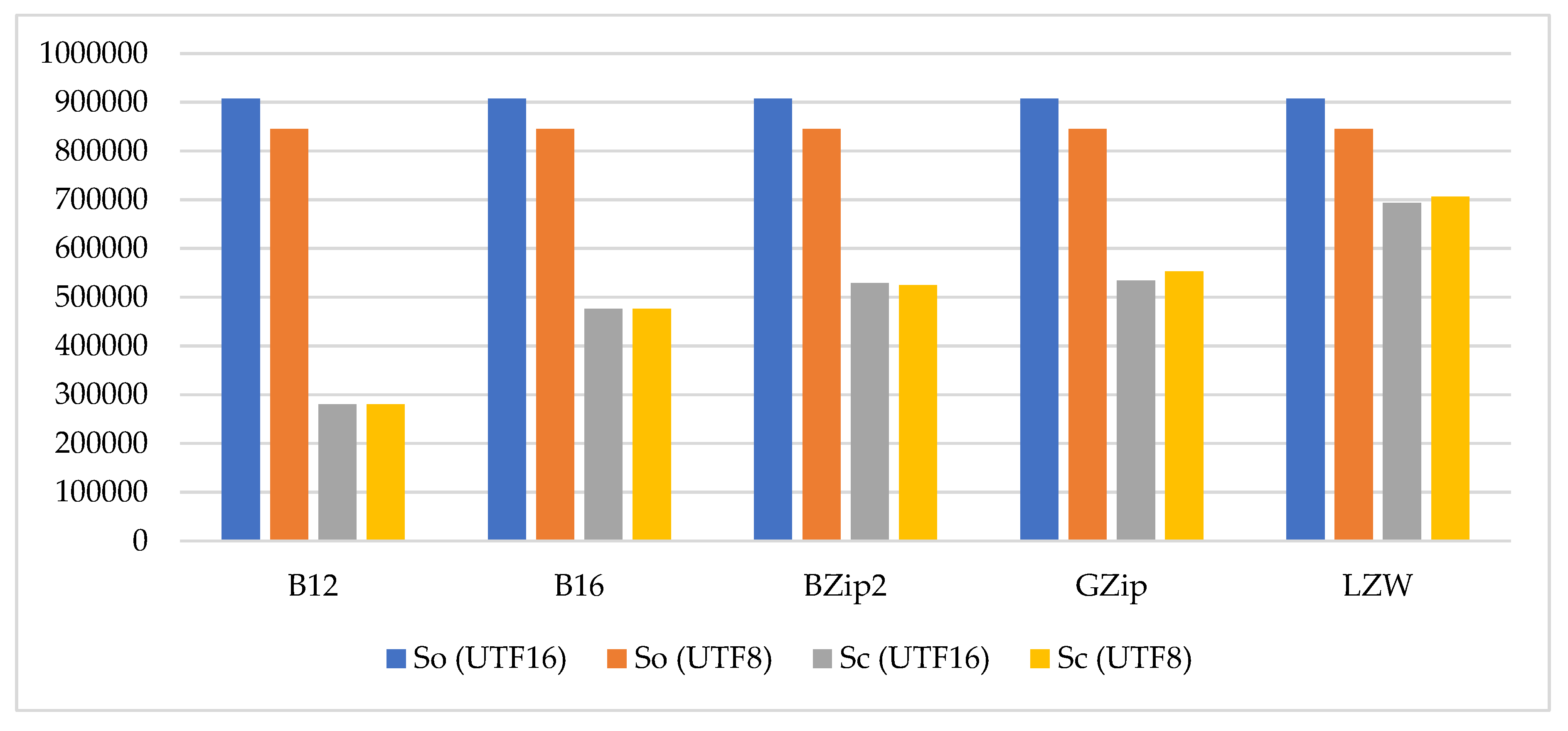
| Method | Text Code | Time (ms) | So (byte) | Sc (byte) | CR | BPC | |
|---|---|---|---|---|---|---|---|
| Compression | Decompression | ||||||
| B12 | UTF8 | 3595 | 14,511 | 845,127 | 280,261 | 0.33 | 4.94 |
| UTF16 | 3306 | 15,016 | 907,108 | 280,261 | 0.31 | 4.94 | |
| B16 | UTF8 | 2846 | 2909 | 845,127 | 475,984 | 0.56 | 8.40 |
| UTF16 | 2775 | 3096 | 907,108 | 475,984 | 0.52 | 8.40 | |
| BZip2 | UTF8 | 5646 | 2975 | 845,127 | 524,630 | 0.62 | 9.25 |
| UTF16 | 6364 | 2619 | 907,108 | 529,350 | 0.58 | 9.34 | |
| GZip | UTF | 2788 | 1889 | 845,127 | 553,315 | 0.65 | 9.76 |
| UTF16 | 4326 | 2185 | 907,108 | 534,337 | 0.59 | 9.42 | |
| LZW | UTF8 | 18,104 | 1580 | 845,127 | 705,984 | 0.84 | 12.45 |
| UTF16 | 16,737 | 1505 | 907,108 | 693,398 | 0.76 | 12.23 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abliz, W.; Wu, H.; Maimaiti, M.; Wushouer, J.; Abiderexiti, K.; Yibulayin, T.; Wumaier, A. A Syllable-Based Technique for Uyghur Text Compression. Information 2020, 11, 172. https://doi.org/10.3390/info11030172
Abliz W, Wu H, Maimaiti M, Wushouer J, Abiderexiti K, Yibulayin T, Wumaier A. A Syllable-Based Technique for Uyghur Text Compression. Information. 2020; 11(3):172. https://doi.org/10.3390/info11030172
Chicago/Turabian StyleAbliz, Wayit, Hao Wu, Maihemuti Maimaiti, Jiamila Wushouer, Kahaerjiang Abiderexiti, Tuergen Yibulayin, and Aishan Wumaier. 2020. "A Syllable-Based Technique for Uyghur Text Compression" Information 11, no. 3: 172. https://doi.org/10.3390/info11030172
APA StyleAbliz, W., Wu, H., Maimaiti, M., Wushouer, J., Abiderexiti, K., Yibulayin, T., & Wumaier, A. (2020). A Syllable-Based Technique for Uyghur Text Compression. Information, 11(3), 172. https://doi.org/10.3390/info11030172