Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network

Abstract
1. Introduction
- The recency–frequency–monetary lifetime (RFML) model is used for feature extraction of customer loyalty, and the k-means algorithm is used to cluster the features of customer loyalty, thereby distinguishing customers with different loyalty levels.
- A recommender system based on the bipartite graph is constructed, and the PageRank method is used for random walks (BGPR). After adding the exogenous variable of customer loyalty, the system compares the recommendation accuracy rate of customers with different loyalty levels and of the overall customers.
- A recommender system based on a single vertex set network and DeepWalk (SVDW) is constructed and the accuracy of adding the exogenous variable of customer loyalty is analyzed.
2. Related Works
2.1. Customer Loyalty
2.1.1. Expert Experience Scoring
2.1.2. Long-Term Forecasting
2.1.3. Short-Term Forecasting
2.2. Recommender System
2.2.1. Content-Based Filtering Recommender Systems
2.2.2. Collaborative Filtering Recommender Systems
2.2.3. Hybrid Recommender Systems
2.2.4. Complex Network Recommender Systems
3. Proposed Method
3.1. K-Means Clustering Method Based on the RFML Model: Designed for Customer Loyalty
3.1.1. The RFML Model
3.1.2. K-Means Clustering
3.2. Recommender System Based on Bipartite Graph and Personal Rank (BGPR)
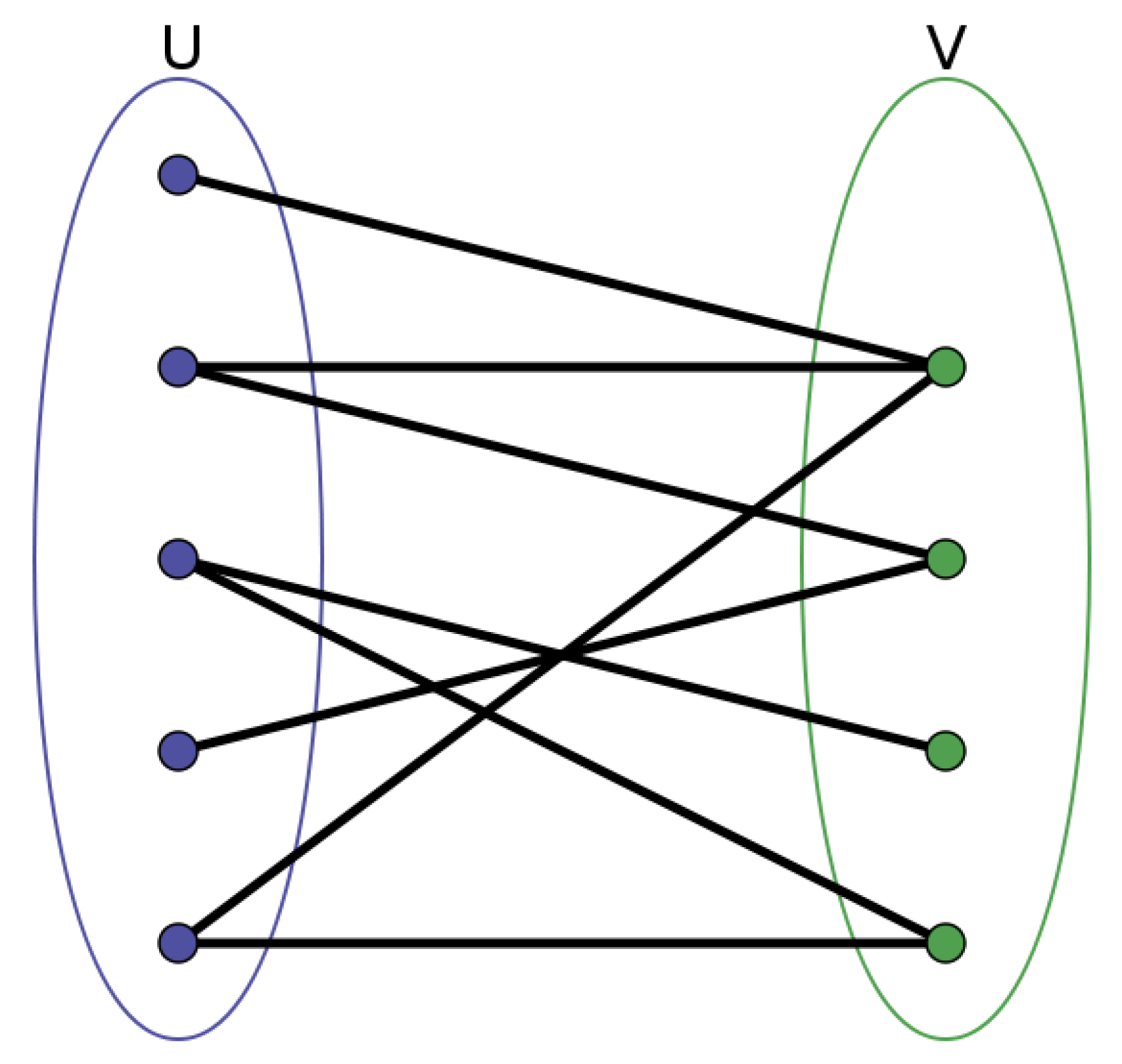
3.2.1. ‘Customer–Shop’ Bipartite Graph Network
3.2.2. PersonalRank for Recommender System
| Algorithm 1 BGPR |
|
3.3. Recommender System Based on Single Vertex Set and DeepWalk (SVDW)
3.3.1. ‘Shop–Shop’ Single Vertex Set Network
3.3.2. DeepWalk for Recommender System
| Algorithm 2 SVDW |
|
3.4. Evaluation Index
4. Experiment and Analysis
4.1. Data Set Description
4.2. K-Means Clustering Based on the RFML Model
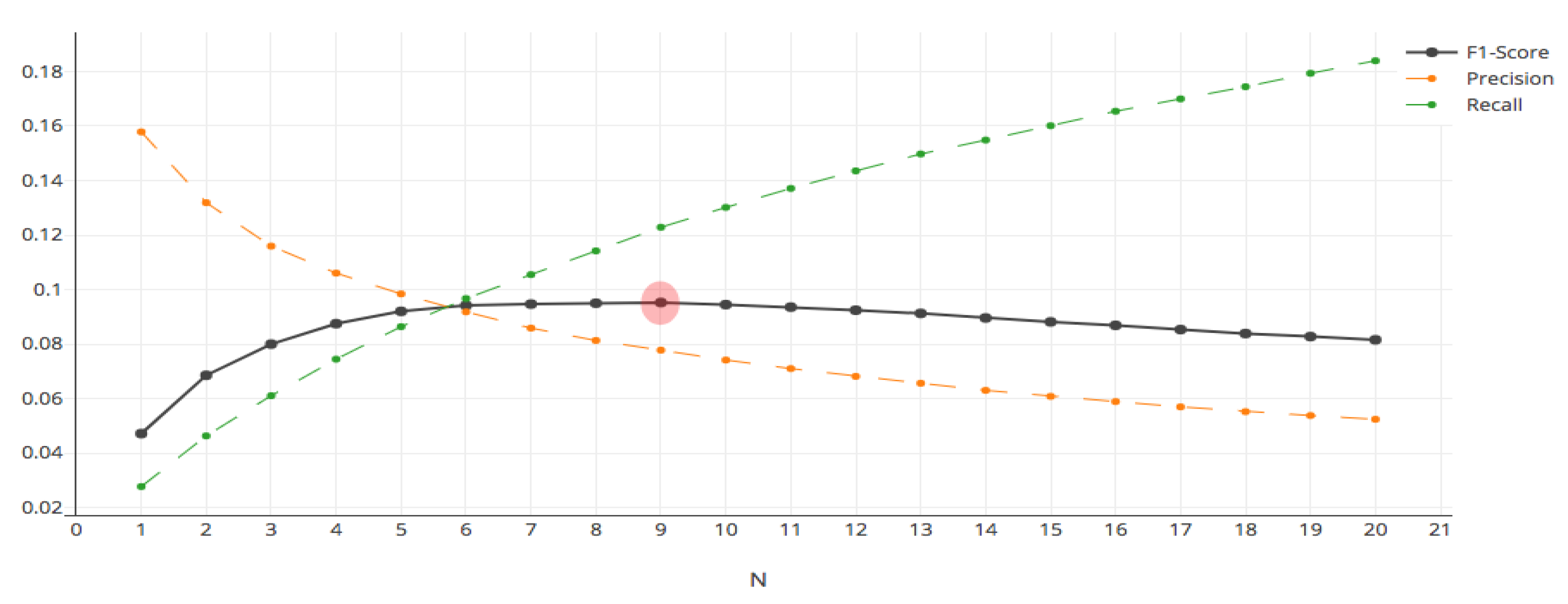
4.3. Impact of Customer Loyalty on BGPR
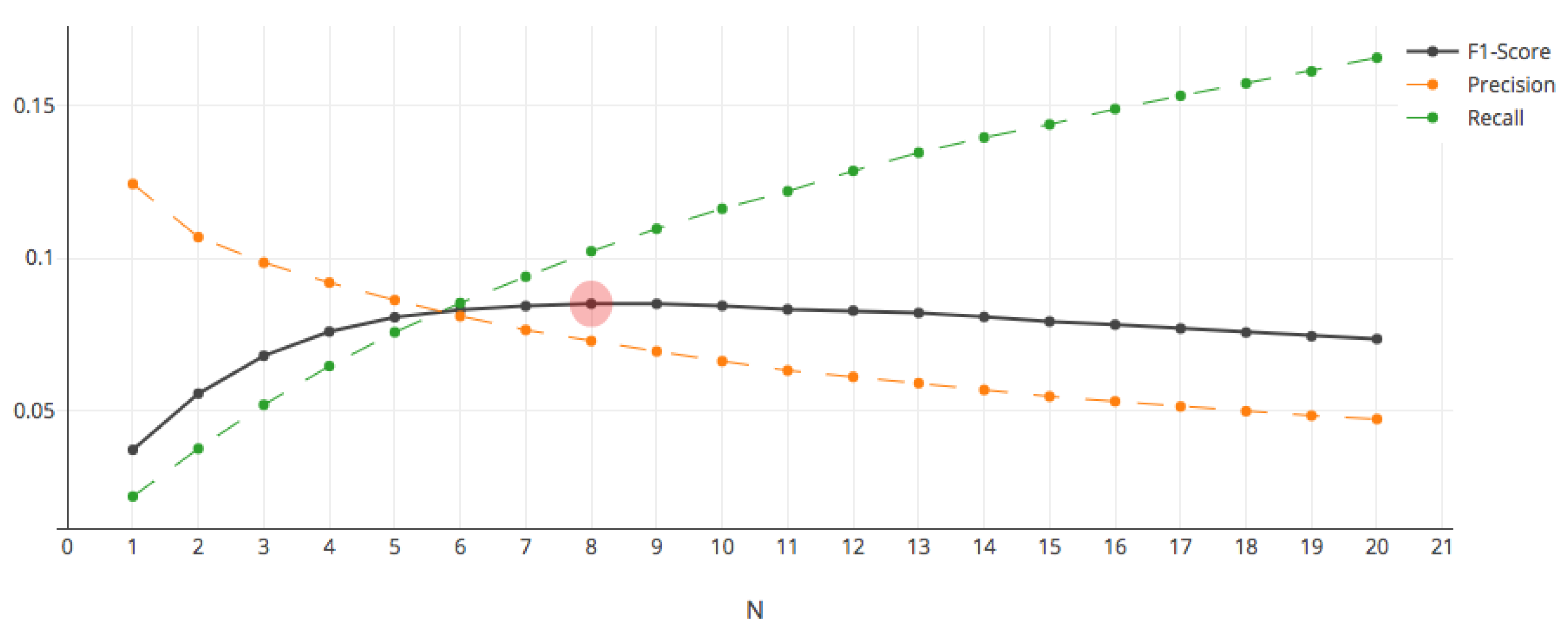
4.4. Impact of Customer Loyalty on SVDW
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Oliver, R.L. Whence consumer loyalty? J. Mark. 1999, 63 (Suppl. S1), 33–44. [Google Scholar] [CrossRef]
- Butcher, H. Information overload in management and business. In Proceedings of the IEE Colloquium on Information Overload, London, UK, 20 November 1995. [Google Scholar]
- Cano, P.; Celma, O.; Koppenberger, M. Topology of music recommendation networks. Chaos Interdiscip. J. Nonlinear Sci. 2006, 16, 013107. [Google Scholar] [CrossRef] [PubMed]
- Naruchitparames, J.; Güneş, M.H.; Louis, S.J. Friend recommendations in social networks using genetic algorithms and network topology. In Proceedings of the 2011 IEEE Congress of Evolutionary Computation (CEC), New Orleans, LA, USA, 5–8 June 2011. [Google Scholar]
- Li, J.; Ma, S.; Hong, S. Recommendation on social network based on graph model. In Proceedings of the 31st Chinese Control Conference, Hefei, China, 25–27 July 2012. [Google Scholar]
- Wang, Q.; Li, W.; Zhang, X.; Lu, S. Academic paper recommendation based on community detection in citation-collaboration networks. In Lecture Notes in Computer Science, Proceedings of the Asia-Pacific Web Conference, Suzhou, China, 23–25 September 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Reichheld, F.F.; Markey, R.; Hopton, C. The loyalty effect. Eur. Bus. J. 2000, 12, 134–139. [Google Scholar]
- Han, S.H.; Lu, S.X.; Leung, S.C. Segmentation of telecom customers based on customer value by decision tree model. Expert Syst. Appl. 2012, 39, 3964–3973. [Google Scholar] [CrossRef]
- Kressmann, F.; Sirgy, M.J.; Herrmann, A.; Huber, F.; Huber, S.; Lee, D.-J. Direct and indirect effects of self-image congruence on brand loyalty. J. Bus. Res. 2006, 59, 955–964. [Google Scholar] [CrossRef]
- Hwang, H.; Jung, T.; Suh, E. An LTV model and customer segmentation based on customer value: A case study on the wireless telecommunication industry. Expert Syst. Appl. 2004, 26, 181–188. [Google Scholar] [CrossRef]
- Jackson, B.B. Build Customer Relationships That Last; Harvard Business Review: Boston, MA, USA, 1985; Volume 11. [Google Scholar]
- Qi, J.-Y.; Zhou, Y.P.; Chen, W.J.; Qu, Q.X. Are customer satisfaction and customer loyalty drivers of customer lifetime value in mobile data services: A comparative cross-country study. Inf. Technol. Manag. 2012, 13, 281–296. [Google Scholar] [CrossRef]
- Zhang, J.Q.; Dixit, A.; Friedmann, R. Customer loyalty and lifetime value: An empirical investigation of consumer packaged goods. J. Mark. Theory Pract. 2010, 18, 127–140. [Google Scholar] [CrossRef]
- Safari, K.M.; Safari, K.Z. An empirical analysis to design enhanced customer lifetime value based on customer loyalty: Evidences from Iranian banking sector. Iranian J. Manag. Studies 2012, 5, 145–167. [Google Scholar]
- Andon, P.; Baxter, J.; Bradley, G. Calculating Customer Lifetime Value (CLV): Theory and Practice, in Kundenwert; Springer: New York, NY, USA, 2003; pp. 299–315. [Google Scholar]
- Fader, P.S.; Hardie, B.G.; Jerath, K. Estimating CLV using aggregated data: The Tuscan lifestyles case revisited. J. Interact. Mark. 2007, 21, 55–71. [Google Scholar] [CrossRef]
- Karvanen, J.; Rantanen, A.; Luoma, L. Survey data and Bayesian analysis: A cost-efficient way to estimate customer equity. Quant. Mark. Econ. 2014, 12, 305–329. [Google Scholar] [CrossRef]
- Yeh, I.-C.; Yang, K.-J.; Ting, T.-M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Miglautsch, J.R. Thoughts on RFM scoring. J. Database Mark. Cust. Strategy Manag. 2000, 8, 67–72. [Google Scholar] [CrossRef]
- Khajvand, M.; Zolfaghar, K.; Ashoori, S.; Alizadeh, S. Estimating customer lifetime value based on RFM analysis of customer purchase behavior: Case study. Procedia Comput. Sci. 2011, 3, 57–63. [Google Scholar] [CrossRef]
- Safari, F.; Safari, N.; Montazer, G.A. Customer lifetime value determination based on RFM model. Mark. Intell. Plan. 2016. [Google Scholar] [CrossRef]
- Ha, S.H.; Park, S.C. Application of data mining tools to hotel data mart on the Intranet for database marketing. Expert Syst. Appl. 1998, 15, 1–31. [Google Scholar] [CrossRef]
- Hosseini, S.M.S.; Maleki, A.; Gholamian, M.R. Cluster analysis using data mining approach to develop CRM methodology to assess the customer loyalty. Expert Syst. Appl. 2010, 37, 5259–5264. [Google Scholar] [CrossRef]
- Schafer, J.B.; Konstan, J.A.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Riyahi, M.; Sohrabi, M.K. Providing effective recommendations in discussion groups using a new hybrid recommender system based on implicit ratings and semantic similarity. Electron. Commer. Res. Appl. 2020, 40, 100938. [Google Scholar] [CrossRef]
- Yeung, K.F.; Yang, Y. A proactive personalized mobile news recommendation system. In Proceedings of the 2010 Developments in E-Systems Engineering, London, UK, 6–8 September 2010. [Google Scholar]
- Van Meteren, R.; Van Someren, M. Using content-based filtering for recommendation. In Proceedings of the Machine Learning in the New Information Age: MLnet/ECML2000 Workshop, Barcelona, Catalonia, Spain, 30 May 2000. [Google Scholar]
- Blanco-Fernandez, Y.; Pazos-arias, J.J.; Gil-Solla, A.; Ramos-Cabrer, M.; Lopez-Nores, M. Providing entertainment by content-based filtering and semantic reasoning in intelligent recommender systems. IEEE Trans. Consum. Electron. 2008, 54, 727–735. [Google Scholar] [CrossRef]
- Barragáns-Martínez, A.B.; Costa-Montenegro, E.; Burguillo, J.C.; Rey-López, M.; Mikic-Fonte, F.A.; Peleteiro, A. A hybrid content-based and item-based collaborative filtering approach to recommend TV programs enhanced with singular value decomposition. Inf. Sci. 2010, 180, 4290–4311. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Das, A.S.; Datar, M.; Garg, A.; Rajaram, S. Google news personalization: Scalable online collaborative filtering. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007. [Google Scholar]
- Chen, J.; Zhang, H.; He, X.; Nie, L.; Liu, W. Attentive collaborative filtering: Multimedia recommendation with item-and component-level attention. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Subramaniyaswamy, V.; Logesh, R.; Chandrashekhar, M.; Challa, A.; Vijayakumar, V. A personalised movie recommendation system based on collaborative filtering. Int. J. High Perform. Comput. Netw. 2017, 10, 54–63. [Google Scholar] [CrossRef]
- Ghazanfar, M.A.; Prügel-Bennett, A. Leveraging clustering approaches to solve the gray-sheep users problem in recommender systems. Expert Syst. Appl. 2014, 41, 3261–3275. [Google Scholar] [CrossRef]
- Golbandi, N.; Koren, Y.; Lempel, R. Adaptive bootstrapping of recommender systems using decision trees. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011. [Google Scholar]
- Burke, R. Hybrid recommender systems: Survey and experiments. User Model. User Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Kermany, N.R.; Alizadeh, S.H. A hybrid multi-criteria recommender system using ontology and neuro-fuzzy techniques. Electron. Commer. Res. Appl. 2017, 21, 50–64. [Google Scholar] [CrossRef]
- Choi, K.; Yoo, D.; Kim, G.; Suh, Y. A hybrid online-product recommendation system: Combining implicit rating-based collaborative filtering and sequential pattern analysis. Electron. Commer. Res. Appl. 2012, 11, 309–317. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Zeng, D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 116–142. [Google Scholar] [CrossRef]
- Schering, A.-C.; Dueffer, M.; Finger, A.; Bruder, I. A mobile tourist assistance and recommendation system based on complex networks. In Proceedings of the 1st ACM International Workshop on Complex Networks Meet Information & Knowledge Management, Hong Kong, China, 6 November 2009. [Google Scholar]
- Fields, B.; Jacobson, K.; Rhodes, C.; d’Inverno, M.; Sandler, M.; Casey, M. Analysis and exploitation of musician social networks for recommendation and discovery. IEEE Trans. Multimed. 2011, 13, 674–686. [Google Scholar] [CrossRef]
- Hughes, A.M. Strategic Database Marketing: The Masterplan for Starting and Managing a Profitable, Customer-Based Marketing Program; McGraw-Hill: New York, NY, USA, 2000; Volume 12. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 224–227. [Google Scholar] [CrossRef]
- Chartrand, G.; Zhang, P. Chromatic Graph Theory; Chapman and Hall/CRC: London, UK, 2008. [Google Scholar]
- Haveliwala, T.H. Topic-sensitive pagerank: A context-sensitive ranking algorithm for web search. IEEE Trans. Knowl. Data Eng. 2003, 15, 784–796. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The Pagerank Citation Ranking: Bringing Order to the Web; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Guillaume, J.-L.; Latapy, M. Bipartite graphs as models of complex networks. Phys. A Stat. Mech. Appl. 2006, 371, 795–813. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.-M.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Andersen, R.; Chung, F.; Lang, K. Local graph partitioning using pagerank vectors. In Proceedings of the 2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS’06), Berkeley, CA, USA, 21–24 October 2006. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Test Set | |
|---|---|---|
| Time span | 2010.07.26–2015.06.20 | 2015.06.21–2016.09.20 |
| Number of customers | 21,187 | 18,986 |
| Number of online shops | 2418 | 1753 |
| Number of purchasing records | 694,176 | 459,962 |
| Proportion of data | 3/5 | 2/5 |
| Cluster Number | Cluster Scale | Cluster Center | RFML Value | |||
|---|---|---|---|---|---|---|
| R | F | M | L | |||
| 7 | 1 | 0.99776 | 0.00470 | 1.00000 | 0.72909 | 2.73155 |
| 6 | 3 | 0.97668 | 0.71829 | 0.04344 | 0.41103 | 2.14944 |
| 5 | 3749 | 0.95915 | 0.00241 | 0.00066 | 0.65454 | 1.61676 |
| 4 | 7133 | 0.92724 | 0.00235 | 0.00035 | 0.38307 | 1.31301 |
| 3 | 8875 | 0.95269 | 0.00029 | 0.00005 | 0.04897 | 1.00245 |
| 2 | 5645 | 0.62550 | 0.00036 | 0.00005 | 0.10530 | 0.73121 |
| 1 | 3992 | 0.32104 | 0.00014 | 0.00004 | 0.03593 | 0.35715 |
| Customer Loyalty Levels | Number of Customer | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | 0 | 0.000 | 0.000 | 0.000 |
| 2 | 24 | 0.032 | 0.233 | 0.057 |
| 3 | 360 | 0.056 | 0.160 | 0.083 |
| 4 | 4769 | 0.086 | 0.148 | 0.109 |
| 5 | 3165 | 0.067 | 0.091 | 0.077 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Without customer loyalty | 0.078 | 0.123 | 0.095 |
| With customer loyalty | 0.086 | 0.148 | 0.109 |
| Customer Loyalty Levels | Number of Customer | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | 0 | 0.000 | 0.000 | 0.000 |
| 2 | 24 | 0.042 | 0.267 | 0.072 |
| 3 | 360 | 0.054 | 0.138 | 0.078 |
| 4 | 4769 | 0.082 | 0.126 | 0.099 |
| 5 | 3165 | 0.061 | 0.073 | 0.066 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Without customer loyalty | 0.072 | 0.102 | 0.085 |
| With customer loyalty | 0.082 | 0.126 | 0.099 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.; Jia, S.; Wang, S.; Tan, B. Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network. Information 2020, 11, 171. https://doi.org/10.3390/info11030171
Bai Y, Jia S, Wang S, Tan B. Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network. Information. 2020; 11(3):171. https://doi.org/10.3390/info11030171
Chicago/Turabian StyleBai, Yun, Suling Jia, Shuangzhe Wang, and Binkai Tan. 2020. "Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network" Information 11, no. 3: 171. https://doi.org/10.3390/info11030171
APA StyleBai, Y., Jia, S., Wang, S., & Tan, B. (2020). Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network. Information, 11(3), 171. https://doi.org/10.3390/info11030171