Kernel-Based Ensemble Learning in Python


Abstract
1. Introduction
2. Related Work
3. KernelCobra: A Kernelized Version of COBRA
3.1. The Unsupervised Setting
3.2. Classification
4. Implementation
| Algorithm 1: General KernelCobra |
 |
| Algorithm 2:KernelCobra in the unsupervised setting |
 |
| Algorithm 3:KernelCobra for classification |
 |
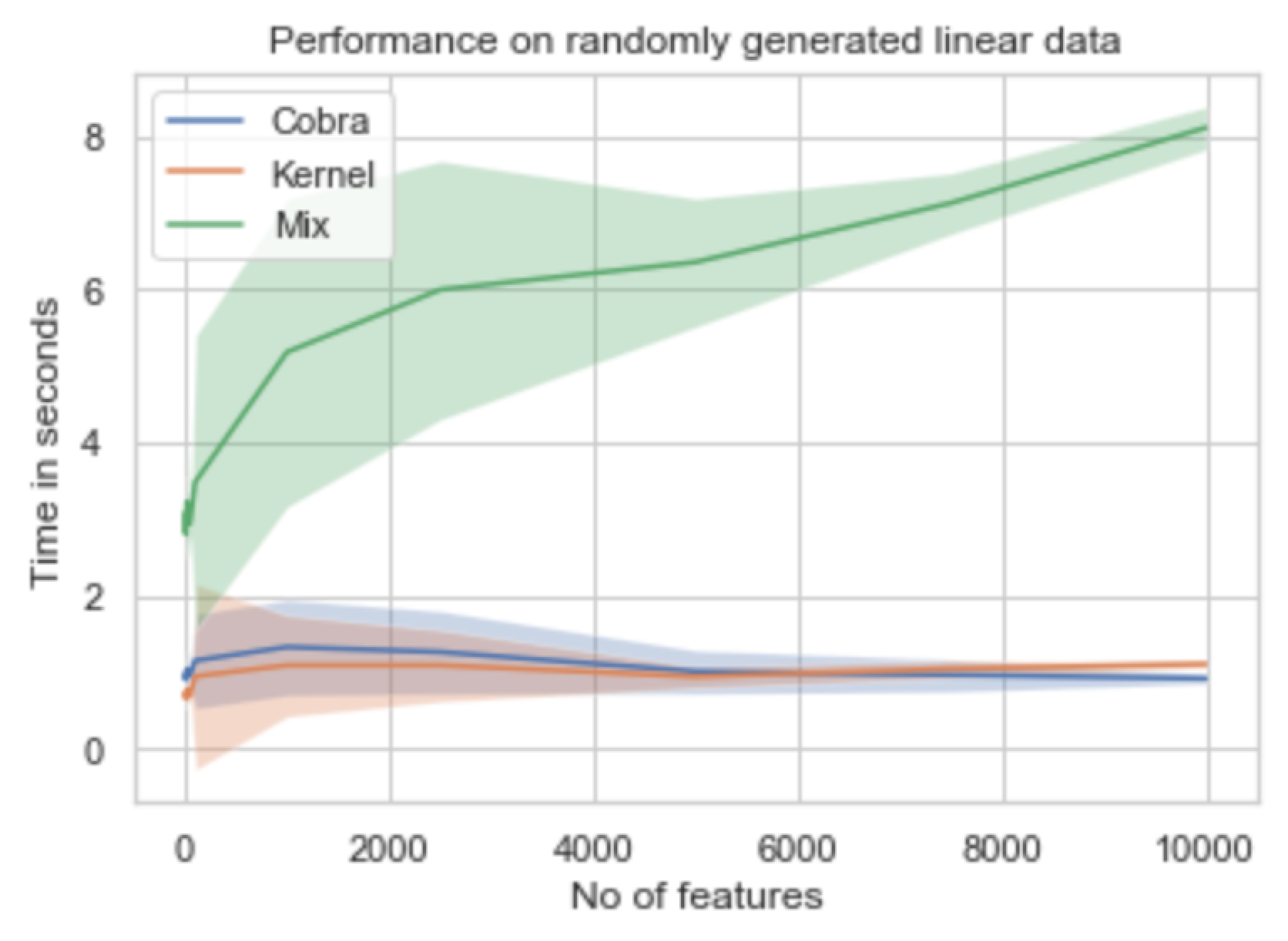
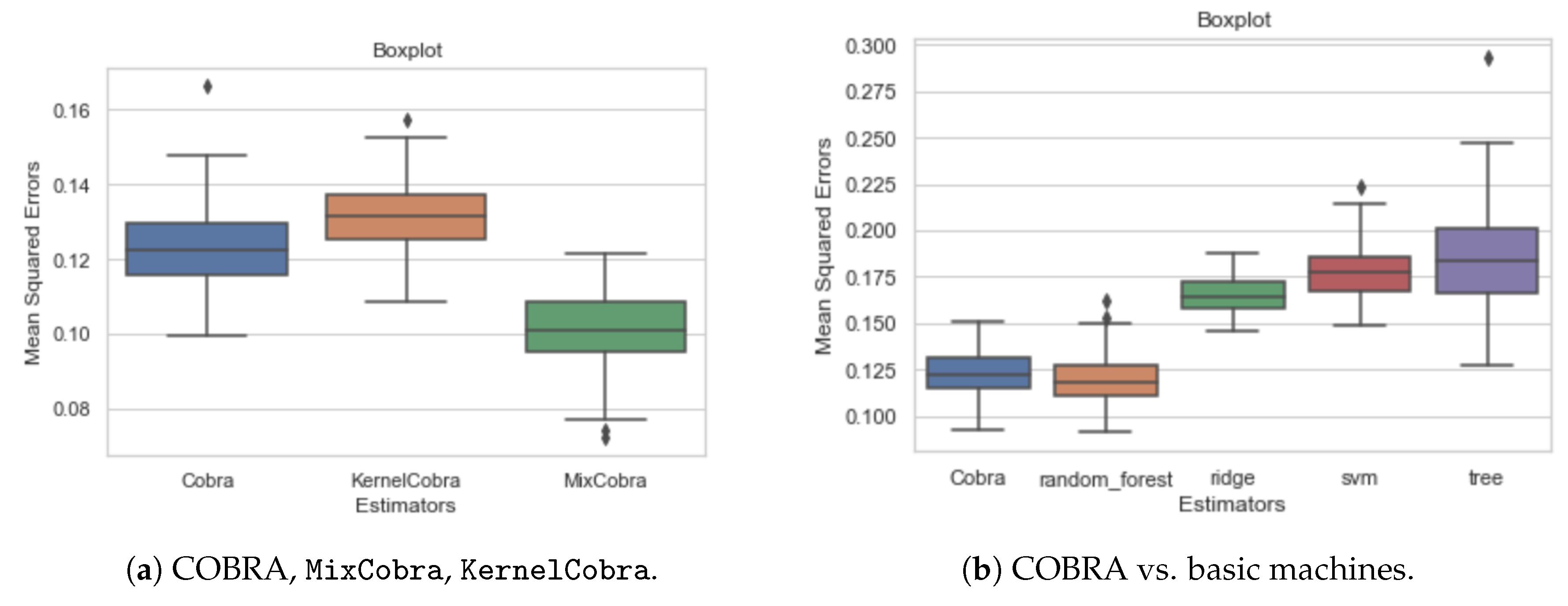
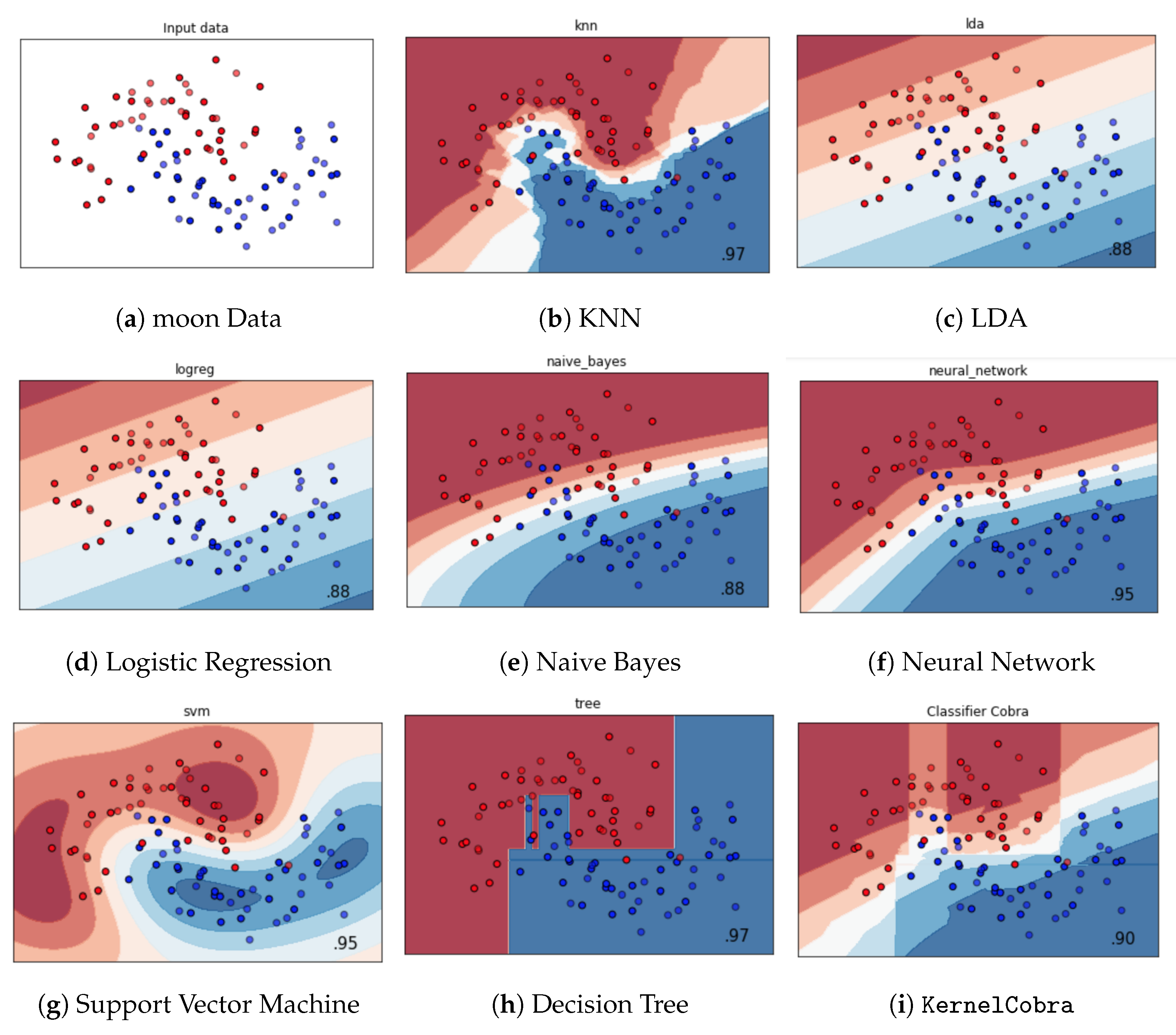
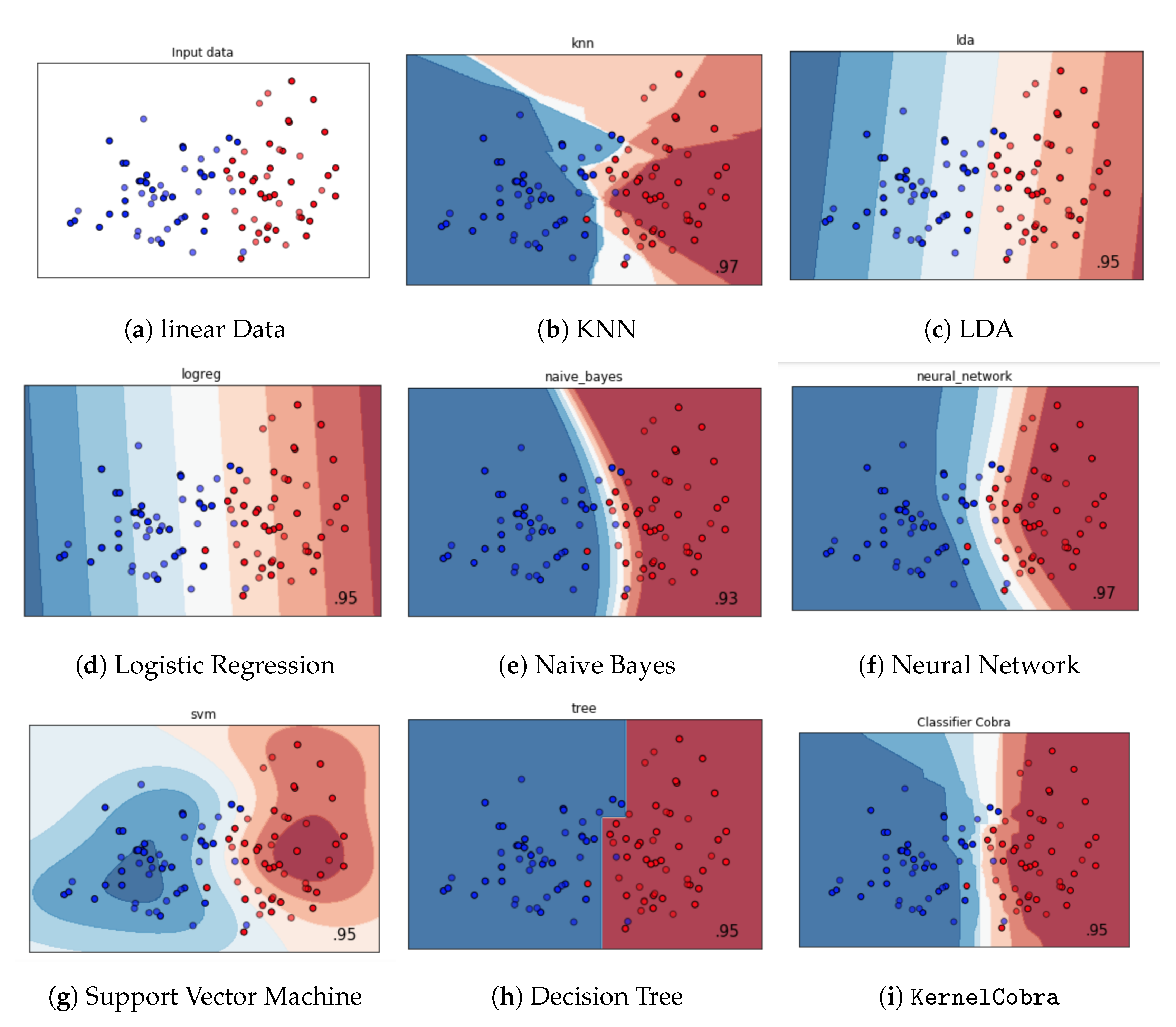
5. Numerical Experiments
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bell, R.M.; Koren, Y. Lessons from the Netflix prize challenge. ACM SIGKDD Explor. Newsl. 2007, 9, 75–79. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin, Germany, 2000; pp. 1–15. [Google Scholar]
- Giraud, C. Introduction to High-Dimensional Statistics; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Mojirsheibani, M. Combining classifiers via discretization. J. Am. Stat. Assoc. 1999, 94, 600–609. [Google Scholar] [CrossRef]
- Biau, G.; Fischer, A.; Guedj, B.; Malley, J.D. COBRA: A combined regression strategy. J. Multivar. Anal. 2016, 146, 18–28. [Google Scholar] [CrossRef]
- Guedj, B.; Srinivasa Desikan, B. Pycobra: A Python Toolbox for Ensemble Learning and Visualisation. J. Mach. Learn. Res. 2018, 18, 1–5. [Google Scholar]
- Fischer, A.; Mougeot, M. Aggregation using input–output trade-off. J. Stat. Plan. Inference 2019, 200, 1–19. [Google Scholar] [CrossRef]
- Steinbach, M.; Ertöz, L.; Kumar, V. The challenges of clustering high dimensional data. In New Directions in Statistical Physics; Springer: Berlin, Germany, 2004; pp. 273–309. [Google Scholar]
- Guedj, B.; Rengot, J. Non-linear aggregation of filters to improve image denoising. arXiv 2019, arXiv:1904.00865. [Google Scholar]
- Mojirsheibani, M. A kernel-based combined classification rule. Stat. Probab. Lett. 2000, 48, 411–419. [Google Scholar] [CrossRef]
- Mojirsheibani, M. An almost surely optimal combined classification rule. J. Multivar. Anal. 2002, 81, 28–46. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Mojirsheibani, M. A simple method for combining estimates to improve the overall error rates in classification. Comput. Stat. 2015, 30, 1033–1049. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gaussian | Sparse | Diabetes | Boston | Linear | Friedman | |
|---|---|---|---|---|---|---|
| random-forest | 12,266.640297 | 3.35474 | 2924.12121 | 18.47003 | 0.116743 | 5.862687 |
| (1386.2011) | (0.3062) | (415.4779) | (4.0244) | (0.0142) | (0.706) | |
| ridge | 491.466644 | 1.23882 | 2058.08145 | 13.907375 | 0.165907 | 6.631595 |
| (201.110142) | (0.0311) | (127.6948) | (2.2957) | (0.0101) | (0.2399) | |
| svm | 1699.722724 | 1.129673 | 8984.301249 | 74.682848 | 0.178525 | 7.099232 |
| (441.8619) | (0.0421) | (236.8372) | (114.9571) | (0.0155) | (0.3586) | |
| tree | 22,324.209936 | 6.304297 | 5795.58075 | 32.505575 | 0.185554 | 11.136161 |
| (3309.8819) | (0.9771) | (1251.3533) | (14.2624) | (0.0246) | (1.73) | |
| Cobra | 1606.830549 | 1.951787 | 2506.113231 | 16.590891 | 0.12352 | 5.681025 |
| (651.2418) | (0.5274) | (440.1539) | (8.0838) | (0.0109) | (1.3613) | |
| KernelCobra | 488.141132 | 1.11758 | 2238.88967 | 12.789762 | 0.113702 | 4.844789 |
| (189.9921) | (0.1324) | (1046.0271) | (9.3802) | (0.0089) | (0.5911) | |
| MixCobra | 683.645028 | 1.419663 | 2762.95792 | 16.228564 | 0.104243 | 5.068543 |
| (196.7856) | (0.1292) | (512.6755) | (12.7125) | (0.0104) | (0.6058) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guedj, B.; Srinivasa Desikan, B. Kernel-Based Ensemble Learning in Python. Information 2020, 11, 63. https://doi.org/10.3390/info11020063
Guedj B, Srinivasa Desikan B. Kernel-Based Ensemble Learning in Python. Information. 2020; 11(2):63. https://doi.org/10.3390/info11020063
Chicago/Turabian StyleGuedj, Benjamin, and Bhargav Srinivasa Desikan. 2020. "Kernel-Based Ensemble Learning in Python" Information 11, no. 2: 63. https://doi.org/10.3390/info11020063
APA StyleGuedj, B., & Srinivasa Desikan, B. (2020). Kernel-Based Ensemble Learning in Python. Information, 11(2), 63. https://doi.org/10.3390/info11020063