2. Previous Literature
Previous work studying user privacy on SMNs have focused on multiparty privacy conflicts [
5,
6], images or text content from users [
1,
7,
8,
9,
10,
11,
12,
13,
14], third-party applications that supervise privacy [
11,
13,
14,
15], cultures in university settings/communities [
1], the users’ SMNs privacy settings [
1,
3,
16,
17], studies on users’ attitudes, intention, or behaviors [
7,
17], and children/teenagers’ interactions with SMNs [
18,
19].
Online privacy is important to the growth of technology and the expansion of communication. Since social media has become a popular social forum, our private lives will continually be lived out in a public domain. To many, privacy on social media networks is user-dependent. People tend to share different content, have different privacy settings, and different perspectives of privacy. There are several papers that examine privacy settings of users’ accounts in correlation to their privacy leakage [
1,
16,
17]; moreover, there are privacy concerns that go beyond privacy settings [
1]. Through the exploration of users’ attitudes and intentions on social media platforms, upcoming developments consider the fact that privacy settings of social networks are failing the users [
17]. To help the user customize their privacy settings, authors [
20] suggests six privacy profiles: privacy maximizers, selective shares, privacy balancers, time savers, self-censors, and privacy minimalists. Investigating privacy settings of users on social media is important, but it is also important to explore the disclosed information from users [
1,
21]. The intersection of privacy settings and third-party applications on these platforms create opportunity for more risks [
16]. Social networks need to take meaningful action to decrease the exposure of personal information. The risks of engaging on social media could outweigh the benefits. The exploration of these risks was investigated by [
3]. Studies have provided third-party applications that will help reduce the amount of visual privacy leaks until social media platforms employ further action [
11,
15,
22,
23].
The perception of privacy is highly subjective and user-dependent [
10], which is shown by literature focusing on users’ attitudes towards privacy [
17]. As people engage on social media, the images posted can contain potential privacy leaks for users [
10]. In several studies it has been found that images on social media can pose danger [
1,
3,
5,
8]. With visual content on social media someone can uncover personal identifying information that can be collected from them [
8]. Visual content can also become a gateway for multiparty conflicts among users [
5]. These conflicts can arise due to feelings of ownership, privacy boundaries, and privacy perspectives of the individuals in the content. Looking further into self-censoring and reduction of multiparty conflict, users can implement privacy preserving procedures to reduce identity, association, and content disclosure [
24].
Researchers have developed mitigation techniques for visual privacy that range between intervention methods and data hiding [
25]. To protect visual privacy, these methods can be implemented before posting the content or after identifying private objects. Most privacy technology uses one or more of these five protection techniques: intervention [
23,
26], blind vision [
2,
4,
12], secure processing [
12,
15], redaction [
27,
28,
29,
30], and data hiding [
12,
15,
31].
Beyond protecting ourselves from dangers, there are also minors at risk. Studies exploring teenager attitudes towards privacy note that teenagers tend to be more open about their lives on social media when compared to older users [
18,
19]. On social media, teenagers and children are exposed to potential dangers like stalking and sexual predators because of this openness. Studies emphasize the importance of stranger danger and insider threat for minors on SMNs because the real threat lies within the users’ friends because of interpersonal sharing [
32]. The collection of personal information through social engineering and other techniques could affect national security and government officials on these platforms [
7]. With the use of surveys, researchers [
7,
9,
17] can understand what information they share and gauge their understanding of privacy in respect to their ethnicity.
From this literature, we can begin to uncover the importance of privacy and the growing need for evolving technologies to combat online threats. Previous works have discussed concerns with visual content focusing on multiparty conflicts, third-party applications, privacy settings, and the danger of this content. The current state of this field shows the importance to continue investigation and development of visual privacy and mitigation techniques to protect SMNs users. The future of this field is in the development of mitigation techniques, understanding the pervasiveness of visual privacy leaks, and helping users understand the correlation of privacy to threats and dangers on these networks. Our research investigates based on the foundation of these works. With this foundation, we explore the future of privacy on SMNs through participant surveys, data collection from Twitter, and analysis of these results. This work details the attitudes and perspectives toward visual privacy, and the data collection results from Twitter.
Author Contributions
Conceptualization, J.D. and C.G.; methodology, J.D., M.S. and C.G.; validation, J.D., M.S. and C.G.; formal analysis, J.D.; investigation, J.D., M.S. and C.G.; resources, C.G.; data curation, J.D.; writing–original draft preparation, J.D.; writing–review and editing, M.S. and C.G.; visualization, J.D.; supervision, C.G.; project administration, J.D. and C.G.; funding acquisition, J.D. All authors have read and agreed to the published version of the manuscript.
Funding
Jasmine DeHart is supported by the National GEM Consortium and the DoD SMART Scholarship for Service. Makya Stell is supported by the National Science Foundation Oklahoma Louis Stokes Alliance for Minority Participation. Financial support was provided from the University Libraries of the University of Oklahoma.
Acknowledgments
The authors would like to thank Kingsley Pinder Jr. of the University of Arkansas for providing statistical insight of the manuscript; and John Alberse for his initial work on the open source Twitter and Instagram scraper that supported this research:
https://github.com/oudalab/viper_scraper.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| SMN | Social Media Network |
| PL | Privacy Leak |
References
- Gross, R.; Acquisti, A. Information revelation and privacy in online social networks. In Proceedings of the 2005 ACM workshop on Privacy in the electronic society, Alexandria, VA, USA, 7 November 2005; pp. 71–80. [Google Scholar]
- DeHart, J.; Grant, C. Visual content privacy leaks on social media networks. arXiv 2018, arXiv:1806.08471. [Google Scholar]
- Rosenblum, D. What anyone can know: The privacy risks of social networking sites. IEEE Secur. Priv. 2007, 5, 40–49. [Google Scholar] [CrossRef]
- Li, Y.; Vishwamitra, N.; Knijnenburg, B.P.; Hu, H.; Caine, K. Effectiveness and users’ experience of obfuscation as a privacy-enhancing technology for sharing photos. Proc. ACM Hum.-Comput. Interact. 2017, 1, 67. [Google Scholar] [CrossRef]
- Such, J.M.; Porter, J.; Preibusch, S.; Joinson, A. Photo privacy conflicts in social media: A large-scale empirical study. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3821–3832. [Google Scholar]
- Zhong, H.; Squicciarini, A.; Miller, D. Toward automated multiparty privacy conflict detection. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Lingotto, Italy, 22–26 October 2018; pp. 1811–1814. [Google Scholar]
- Abdulhamid, S.M.; Ahmad, S.; Waziri, V.O.; Jibril, F.N. Privacy and national security issues in social networks: The challenges. arXiv 2014, arXiv:1402.3301. [Google Scholar]
- Squicciarini, A.C.; Caragea, C.; Balakavi, R. Analyzing images’ privacy for the modern web. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiago, Chile, 1–4 September 2014; pp. 136–147. [Google Scholar]
- Srivastava, A.; Geethakumari, G. Measuring privacy leaks in online social networks. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 2095–2100. [Google Scholar]
- Zerr, S.; Siersdorfer, S.; Hare, J.; Demidova, E. Privacy-aware image classification and search. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 35–44. [Google Scholar]
- Buschek, D.; Bader, M.; von Zezschwitz, E.; De Luca, A. Automatic privacy classification of personal photos. In Proceedings of the IFIP Conference on Human-Computer Interaction, Bamberg, Germany, 14–18 September 2015; pp. 428–435. [Google Scholar]
- Tierney, M.; Spiro, I.; Bregler, C.; Subramanian, L. Cryptagram: Photo privacy for online social media. In Proceedings of the First ACM Conference on Online Social Networks, Boston, MA, USA, 7–8 October 2013; pp. 75–88. [Google Scholar]
- Gurari, D.; Li, Q.; Lin, C.; Zhao, Y.; Guo, A.; Stangl, A.; Bigham, J.P. VizWiz-Priv: A Dataset for Recognizing the Presence and Purpose of Private Visual Information in Images Taken by Blind People. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Kuang, Z.; Li, Z.; Lin, D.; Fan, J. Automatic Privacy Prediction to Accelerate Social Image Sharing. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 197–200. [Google Scholar]
- Zerr, S.; Siersdorfer, S.; Hare, J. Picalert!: A system for privacy-aware image classification and retrieval. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 2710–2712. [Google Scholar]
- Krishnamurthy, B.; Wills, C.E. Characterizing privacy in online social networks. In Proceedings of the First Workshop on Online Social Networks, Seattle, WA, USA, 17–22 August 2008; pp. 37–42. [Google Scholar]
- Madejski, M.; Johnson, M.L.; Bellovin, S.M. Failure of Online Social Network Privacy Settings; Technical Report CUCS-010-11; Department of Computer Science, Columbia University: New York, NY, USA, July 2011. [Google Scholar]
- Boyd, D. It’s Complicated: The Social Lives of Networked Teens; Yale University Press: New Haven, CT, USA, 2014. [Google Scholar]
- Boyd, D.; Marwick, A.E. Social Privacy in Networked Publics: Teens’ Attitudes, Practices, and Strategies. 2011. Available online: https://osf.io/2gec4/ (accessed on 20 January 2020).
- Knijnenburg, B.P. Privacy? I Can’t Even! making a case for user-tailored privacy. IEEE Secur. Priv. 2017, 15, 62–67. [Google Scholar] [CrossRef]
- Veiga, M.H.; Eickhoff, C. Privacy leakage through innocent content sharing in online social networks. arXiv 2016, arXiv:1607.02714. [Google Scholar]
- Ilia, P.; Polakis, I.; Athanasopoulos, E.; Maggi, F.; Ioannidis, S. Face/Off: Preventing Privacy Leakage From Photos in Social Networks. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 781–792. [Google Scholar] [CrossRef]
- Zezschwitz, E.; Ebbinghaus, S.; Hussmann, H.; De Luca, A. You Can’t Watch This!: Privacy-Respectful Photo Browsing on Smartphones. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 4320–4324. [Google Scholar] [CrossRef]
- Loukides, G.; Gkoulalas-Divanis, A. Privacy challenges and solutions in the social web. XRDS 2009, 16, 14–18. [Google Scholar] [CrossRef]
- Padilla-López, J.R.; Chaaraoui, A.A.; Flórez-Revuelta, F. Visual privacy protection methods: A survey. Expert Syst. Appl. 2015, 42, 4177–4195. [Google Scholar] [CrossRef]
- Mazzia, A.; LeFevre, K.; Adar, E. The PViz comprehension tool for social network privacy settings. In Proceedings of the Eighth Symposium on Usable Privacy and Security, Washington, DC, USA, 11–13 July 2012; p. 13. [Google Scholar]
- Li, X.; Li, D.; Yang, Z.; Chen, W. A patch-based saliency detection method for assessing the visual privacy levels of objects in photos. IEEE Access 2017, 5, 24332–24343. [Google Scholar] [CrossRef]
- Orekondy, T.; Fritz, M.; Schiele, B. Connecting pixels to privacy and utility: Automatic redaction of private information in images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8466–8475. [Google Scholar]
- Li, Y.; Vishwamitra, N.; Knijnenburg, B.P.; Hu, H.; Caine, K. Blur vs. block: Investigating the effectiveness of privacy-enhancing obfuscation for images. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1343–1351. [Google Scholar]
- Zhao, Q.A.; Stasko, J.T. The Awareness-Privacy Tradeoff in Video Supported Informal Awareness: A Study of Image-Filtering based Techniques; Technical Report; Georgia Institute of Technology: Atlanta, GA, USA, 1998. [Google Scholar]
- Boult, T.E. PICO: Privacy through invertible cryptographic obscuration. In Proceedings of the Computer Vision for Interactive and Intelligent Environment (CVIIE’05), Lexington, KY, USA, 17–18 November 2005; pp. 27–38. [Google Scholar]
- Johnson, M.; Egelman, S.; Bellovin, S.M. Facebook and privacy: It’s complicated. In Proceedings of the Eighth Symposium on Usable Privacy and Security, Washington, DC, USA, 11–13 July 2012; p. 9. [Google Scholar]
- Schaeffer, N.C.; Presser, S. The science of asking questions. Annu. Rev. Sociol. 2003, 29, 65–88. [Google Scholar] [CrossRef]
- Kalton, G.; Kasprzyk, D. The treatment of missing survey data. Surv. Methodol. 1986, 12, 1–16. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Loper, E.; Bird, S. NLTK: The natural language toolkit. arXiv 2002, arXiv:cs/0205028v1. [Google Scholar]
- Sarkar, D. Text Analytics with Python: A Practitioner’s Guide to Natural Language Processing; APress: Berkeley, CA, USA, 2019. [Google Scholar]
- Miller, G.A. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Bengfort, B.; Danielsen, N.; Bilbro, R.; Gray, L.; McIntyre, K.; Richardson, G.; Miller, T.; Mayfield, G.; Schafer, P.; Keung, J. Yellowbrick. 2018. Available online: https://zenodo.org/record/1206264#.XiVI1CMRVPY (accessed on 20 January 2020).
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
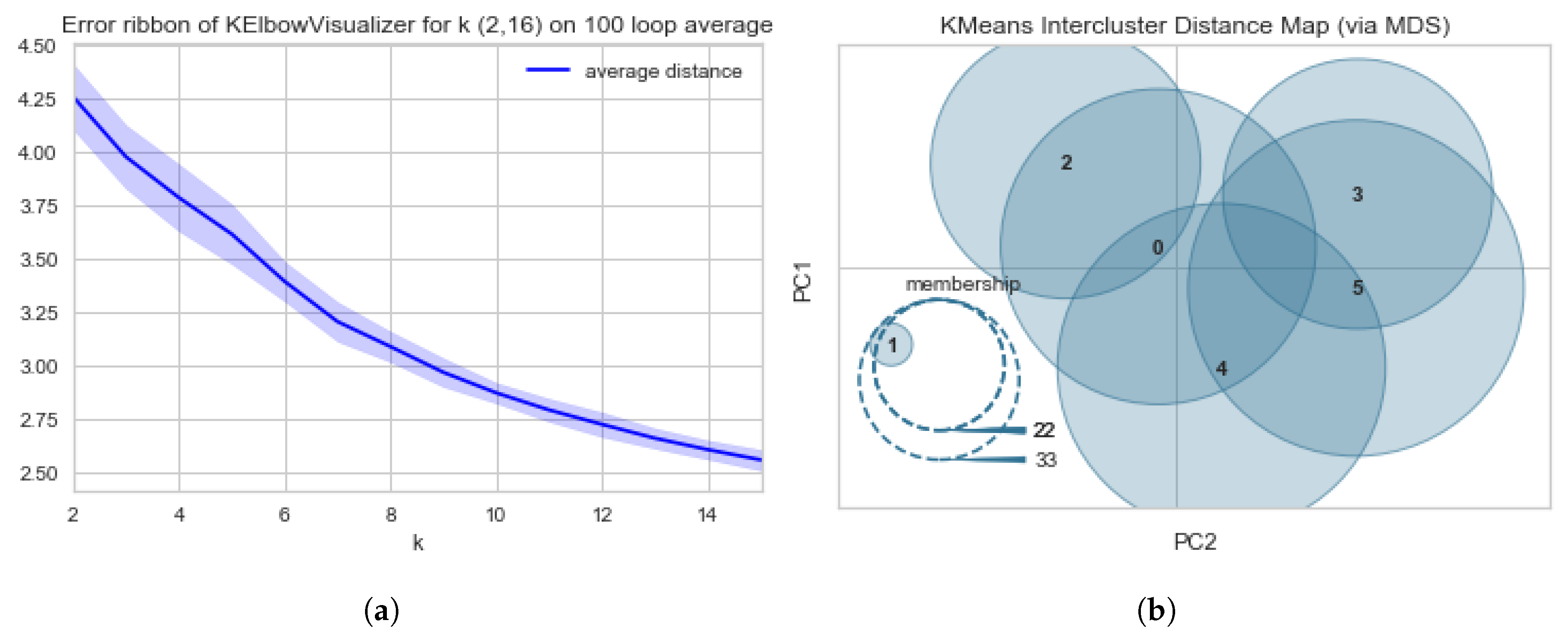
Figure 1.
Diagrams of the Elbow–Knee scores and errors using Calinski Harabasz method. (a) Diagram of the Error Ribbon for the Elbow–Knee Plots using Calinski Harabasz method with cluster size (k) ranging from 2 to 16. (b) Diagram of Intercluster Distance Map using YellowBricks Calinski Harabasz method with cluster size (k) = 6.
Table 1.
This table displays the outline of the IRB #10299 survey that was completed by participants. The survey was compromised of multiple-choice questions and short answer.
| Item | Question |
|---|
| A | Of what Social Media Networks (SMNs) do you consider yourself a frequent user? |
| B | How many hours per week do you spend on social media networks? |
| C | What type of content do you usually post on social media? |
| D | Do you post any of these types of images or videos on your SMNs? |
| E | How would you define privacy? (in one sentence) |
| F | Would you define privacy the same for social media networks? |
| G | Personally identifying information is information that can be used to uniquely identify, contact, or locate a person. Agree or Disagree? |
| H | Privacy leaks include any instance in which a transfer of personal identifying visual content is shared on Social Media Networks. Private visual content exposes intimate information that can be detrimental to your finances, personal life, and reputation. Agree or Disagree? |
| I | Would you consider any of these images to have identifying information? |
| J | As a typical user of Social Media Networks (SMNs), if you were to post these items would you consider these items to be private? |
| K | Drag and drop the following dangers in order of most threatening (most threatening ranked 1 and so on). |
| L | Do you believe there are other dangers on Social Media Networks? If so, list them. |
| M | What type of threat would these items fall under? |
| N | Do you believe that conflict (e.g., bullying, domestic disputes) can increase the occurrence of privacy leaks? |
Table 2.
The weight for each term is computed by averaging the Term Frequency and the Inverse Document Frequency (TF-IDF) scores over all responses.
| Term | Avg. (TF-IDF) |
|---|
| information | 0.1418 |
| personal | 0.1254 |
| private | 0.0785 |
| share | 0.0655 |
Table 3.
Cluster breakdown of the top terms used to define privacy using average TF-IDF scores.
| Cluster (Total Size) | Keyword Score |
|---|
|
0 (36) | information | 0.1651 |
| share | 0.1086 |
| private | 0.0870 |
| want | 0.0770 |
|
1 (33) | social | 0.0984 |
| address | 0.0938 |
| security | 0.0883 |
| information | 0.8171 |
|
2 (27) | know | 0.1420 |
| want | 0.1315 |
| people | 0.1201 |
| information | 0.1075 |
|
3 (30) | information | 0.1813 |
| right | 0.1442 |
| ability | 0.0898 |
| control | 0.0874 |
|
4 (16) | personal | 0.3792 |
| information | 0.3785 |
| passwords | 0.1119 |
| control | 0.09364 |
|
5 (13) | personal | 0.2380 |
| private | 0.1271 |
| identify | 0.0769 |
| share | 0.0769 |
Table 4.
Top five terms used to define privacy using average TF-IDF scores for each by gender demographic.
| Gender Identity (Total Size) | Keyword Score |
|---|
|
Female (71) | information | 0.1361 |
| personal | 0.0985 |
| private | 0.0751 |
| share | 0.0705 |
| social | 0.0400 |
| Male (82) | information | 0.1346 |
| personal | 0.1038 |
| want | 0.0631 |
| control | 0.0545 |
| private | 0.0542 |
| Other (1) | birthdate | 0.3779 |
| blood | 0.3779 |
| date | 0.3779 |
| location | 0.3779 |
| security | 0.3779 |
Table 5.
Calculated ANOVA score for top words used among gender identities to define visual privacy.
| Gender Identity Comparison | f-Value | p-Value |
|---|
| Female vs. Male | 5.9749 | 0.0061 |
| Female vs. Other | 6.0464 | 0.0222 |
| Male vs. Other | 6.4194 | 0.0189 |
Table 6.
Top words used to define privacy using TF-IDF Scores for each document via age demographic. This table includes the cluster label and the top five words by the highest TF-IDF score.
| Age (Total Size) | Keyword Score |
|---|
| 18–25 (111) | information | 0.1167 |
| personal | 0.0777 |
| right | 0.0523 |
| control | 0.0512 |
| private | 0.0492 |
| 26 & over (43) | information | 0.1395 |
| personal | 0.1212 |
| anything | 0.0869 |
| private | 0.0805 |
| share | 0.0585 |
Table 7.
Calculated ANOVA score for top words used among age groups to define visual privacy.
| Age Group Comparison | f-Value | p-Value |
|---|
| 18–25 v. 26+ | 0.3275 | 0.5776 |
Table 8.
Top words used to define visual privacy using TF-IDF Scores for each document.
| Keyword | Score |
|---|
| private | 0.1513 |
| information | 0.1280 |
| media | 0.1083 |
| social | 0.1083 |
| share | 0.0952 |
Table 9.
Threats are listed in their respective order based on survey results. In each ranking column shows each threat ranking for dangers and their associated vote percentage for that position; the highest vote for each item is highlighted.
| Threat | Rank 1 | Rank 2 | Rank 3 | Rank 4 | Rank 5 | Rank 6 |
|---|
| Kidnapping | 52.38% | 15.48% | 10.71% | 3.57% | 9.52% | 8.33% |
| Burglary | 20.24% | 35.71% | 17.86% | 10.71% | 7.14% | 8.33% |
| Stalking | 5.95% | 14.29% | 25.00% | 16.67% | 23.81% | 14.29% |
| Financial Threat | 4.76% | 14.29% | 23.81% | 30.95% | 17.86% | 8.33% |
| Identity Theft | 14.29% | 17.86% | 14.29% | 25.00% | 23.81% | 4.76% |
| Explicit Websites | 2.38% | 2.38% | 8.33% | 13.10% | 17.86% | 55.95% |
Table 10.
Statistical analysis of gender related differences of danger assessment results using the Analysis of variance (ANOVA) method. In the table we see the f-value and p-value for Female and Male genders.
| ANOVA analysis of danger distribution among gender identity |
|---|
| Statistic Value | Burglary | Kidnapping | Explicit Websites | Financial Theft | Identity Theft | Stalking |
| f-Value | 5.2662 | 2.8248 | 6.0343 | 1.8150 | 4.8928 | 2.9822 |
| p-Value | 0.0063 | 0.0629 | 0.0031 | 0.1668 | 0.0089 | 0.0541 |
Table 11.
Statistical analysis of gender related differences of danger assessment results using the Analysis of variance (ANOVA) method. In the table we see the f-value and p-value for the age groups: 18–25 & 26 and over.
| ANOVA analysis of danger distribution among age groups |
|---|
| Statistic Value | Burglary | Kidnapping | Explicit Websites | Financial Theft | Identity Theft | Stalking |
| f-Value | 0.3491 | 0.4125 | 4.1532 | 3.7922 | 3.5000 | 5.2348 |
| p-Value | 0.7059 | 0.6628 | 0.0178 | 0.0250 | 0.0330 | 0.0064 |
Table 12.
Results of keyword crawling on Twitter.
| Keywords or Phrases | # of Images Collected |
|---|
| Credit card | 364,825 |
| debit card | |
| job offer | |
| job acceptance | 107,470 |
| job letter | |
| key | |
| house key | 174,348 |
| car key | |
| license | |
| licensed to drive | 109,520 |
| driver’s license | |
| passport | 183,048 |
| password | 166,835 |
| passwords | |
| racist | 121,638 |
| #racisttwitter | |
| college acceptance |
| college bound | 100,199 |
| college letter | |
| #wikileaks | 137,208 |
| Total | 1,465,091 |
Table 13.
Risk Classification from keyword search with Twitter.
| Category | # of Images Collected |
|---|
| Severe | 160 |
| Moderate | 327 |
| No risk | 18,264 |
Table 14.
Distribution of Content for Risk Categories. This table includes the keyword and the content frequency.
| Category | Keyword (Count) |
|---|
| Severe (160) | Baby | 71 |
| Driver’s License | 12 |
| Financial Document | 2 |
| Hospital | 54 |
| Job | 4 |
| Keys | 1 |
| License Plate | 4 |
| Medication | 10 |
| Medical Records | 6 |
| Moderate (327) | Baby | 45 |
| College Letter | 6 |
| Driver’s License | 24 |
| Hospital | 123 |
| Job Promotion | 7 |
| Medical Information | 52 |
| Medication | 43 |
| Work Identification | 12 |
| Workplace | 15 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).






{kind=link}