Improving the Performance of Multiobjective Genetic Algorithms: An Elitism-Based Approach


Abstract
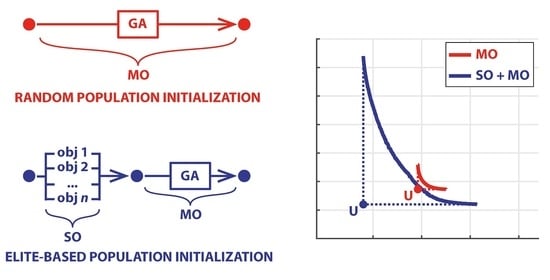
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
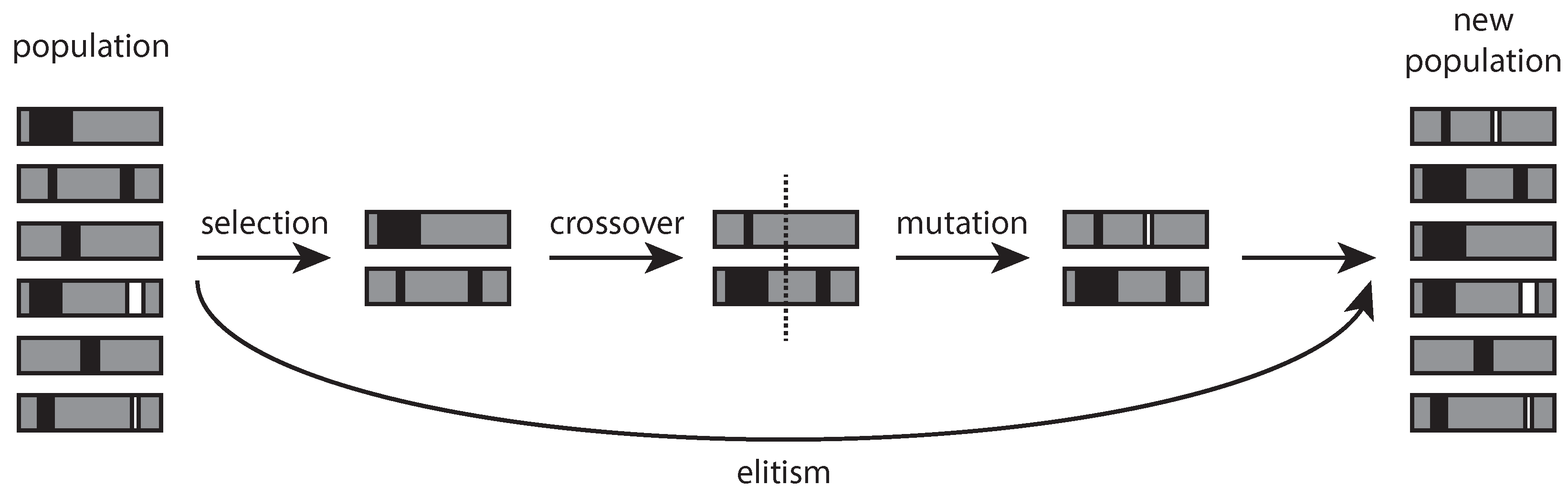
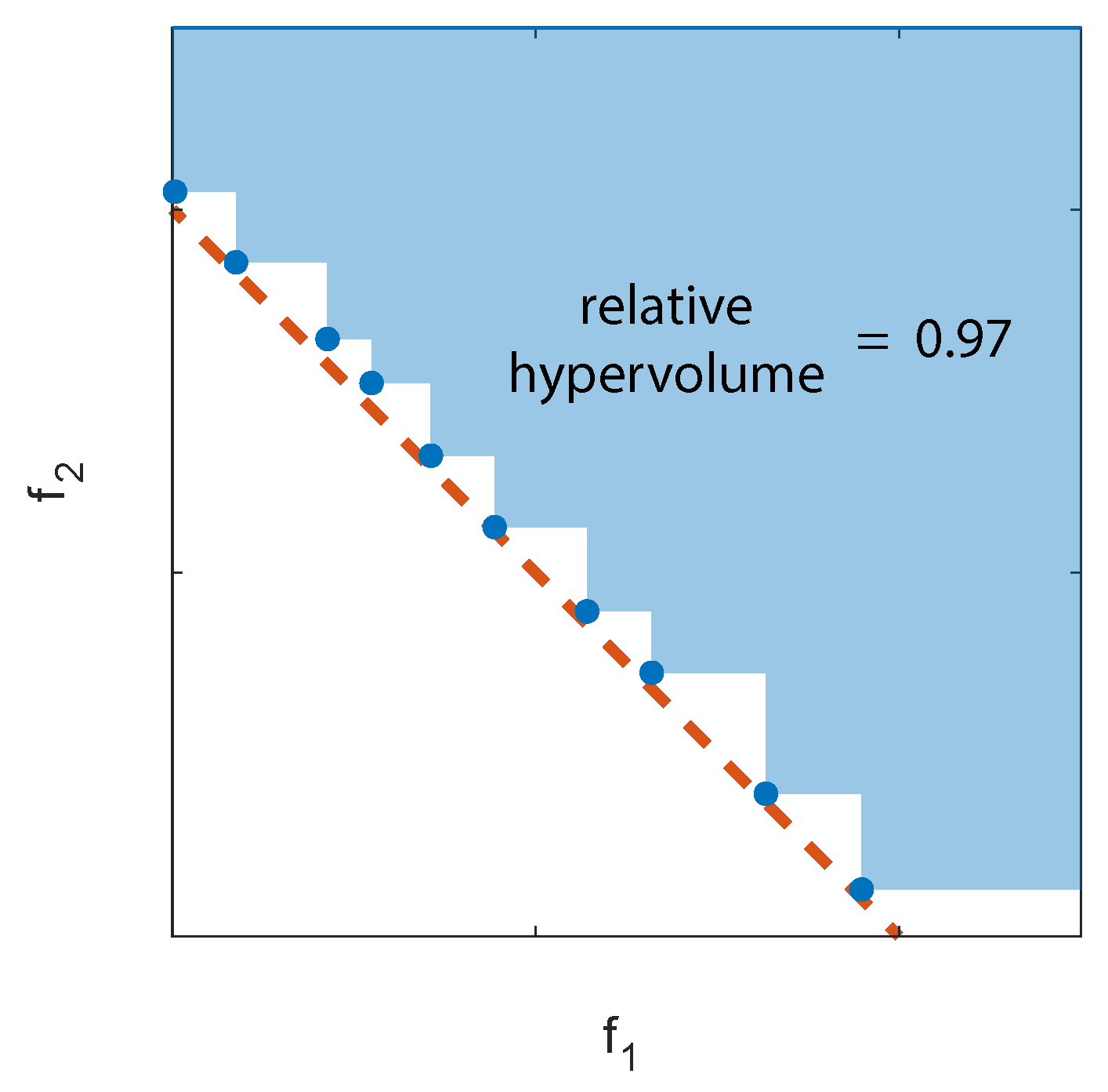
2. Genetic Algorithms’ Operators and Performances Evaluation
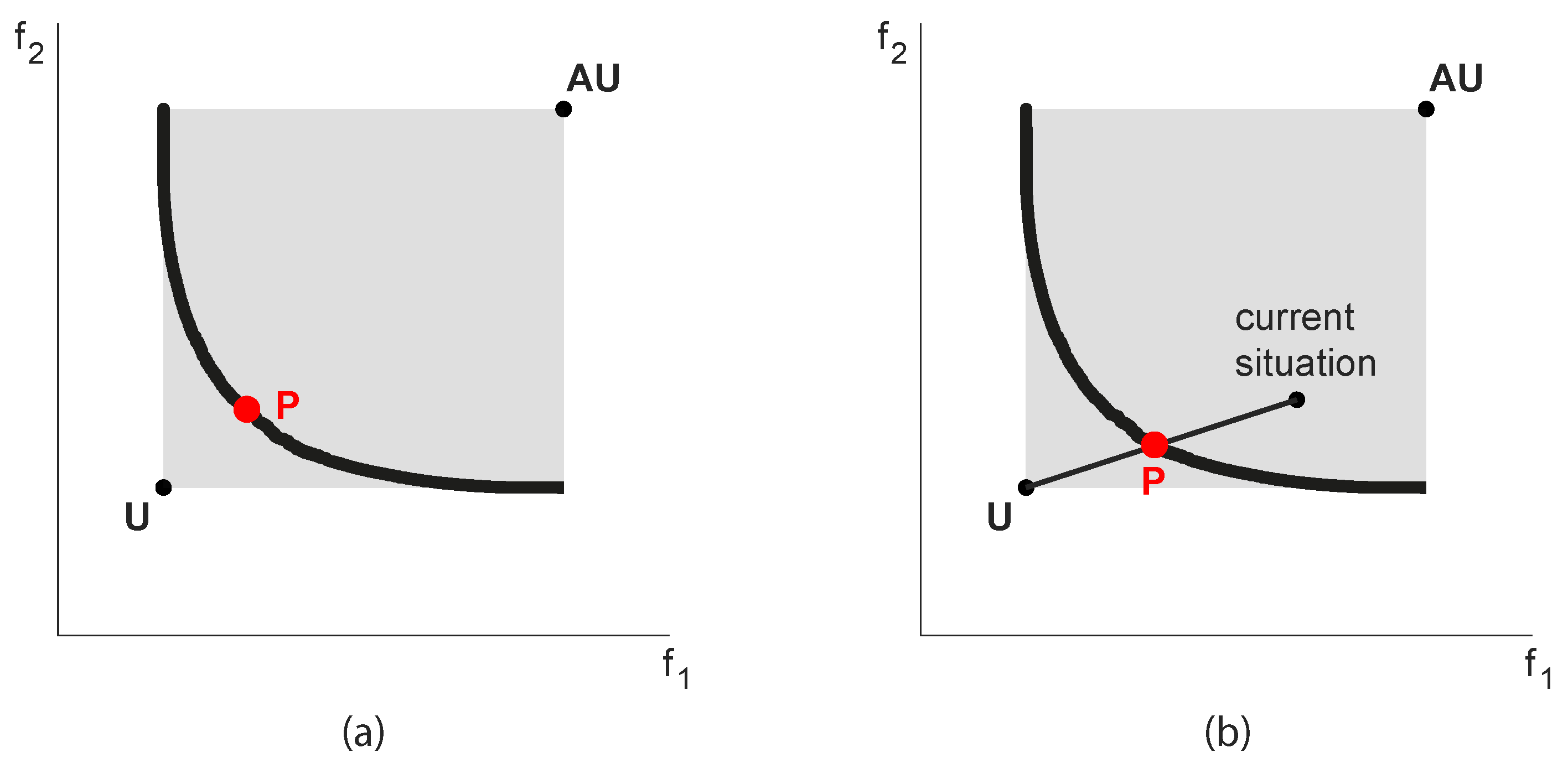
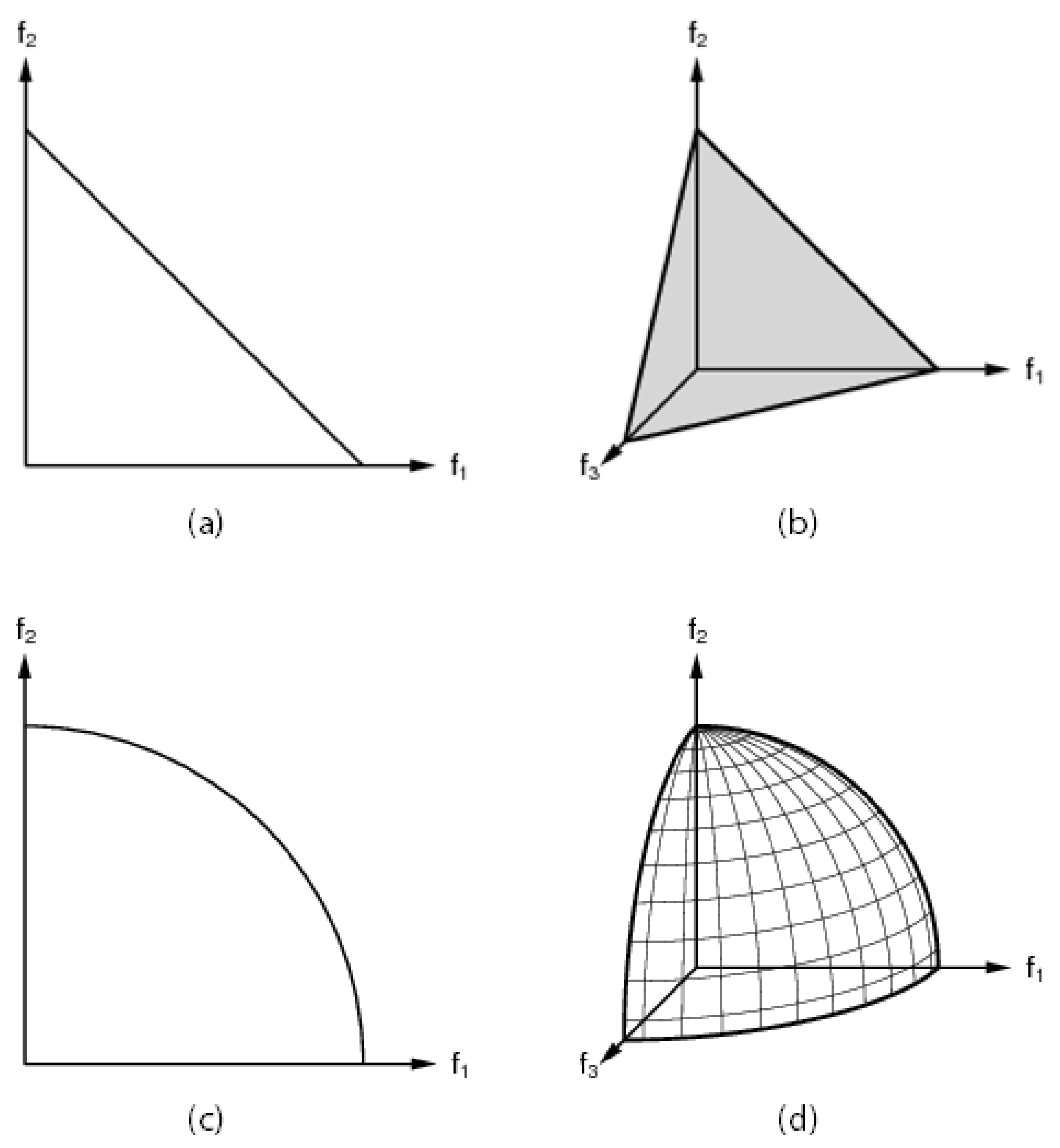
3. Defining the Full Search Space
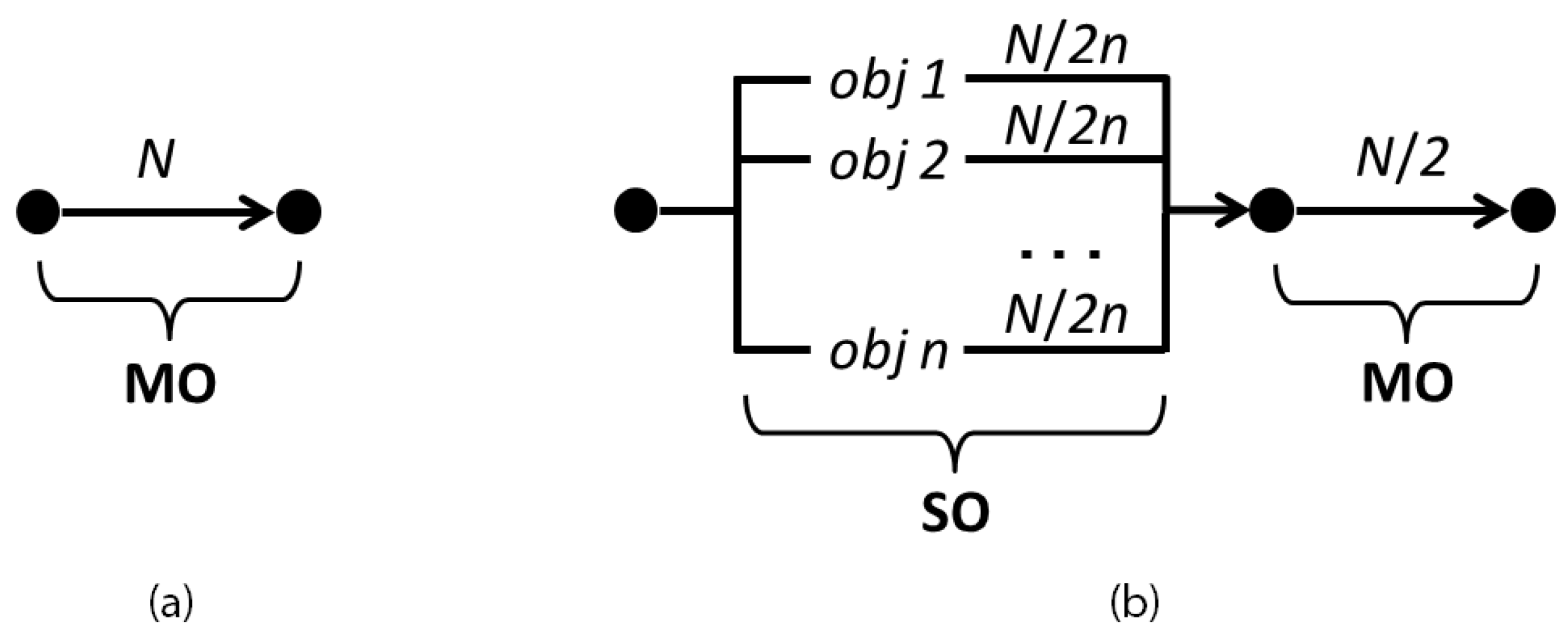
- First, solve separately n single-objective (SO) problems;
- Include the n optimal solutions (individuals) in the initial population of the MO problem;
- These solutions cannot be dominated and thus always remain in the elite set;
- Span the Pareto frontier with these solutions always in the population.
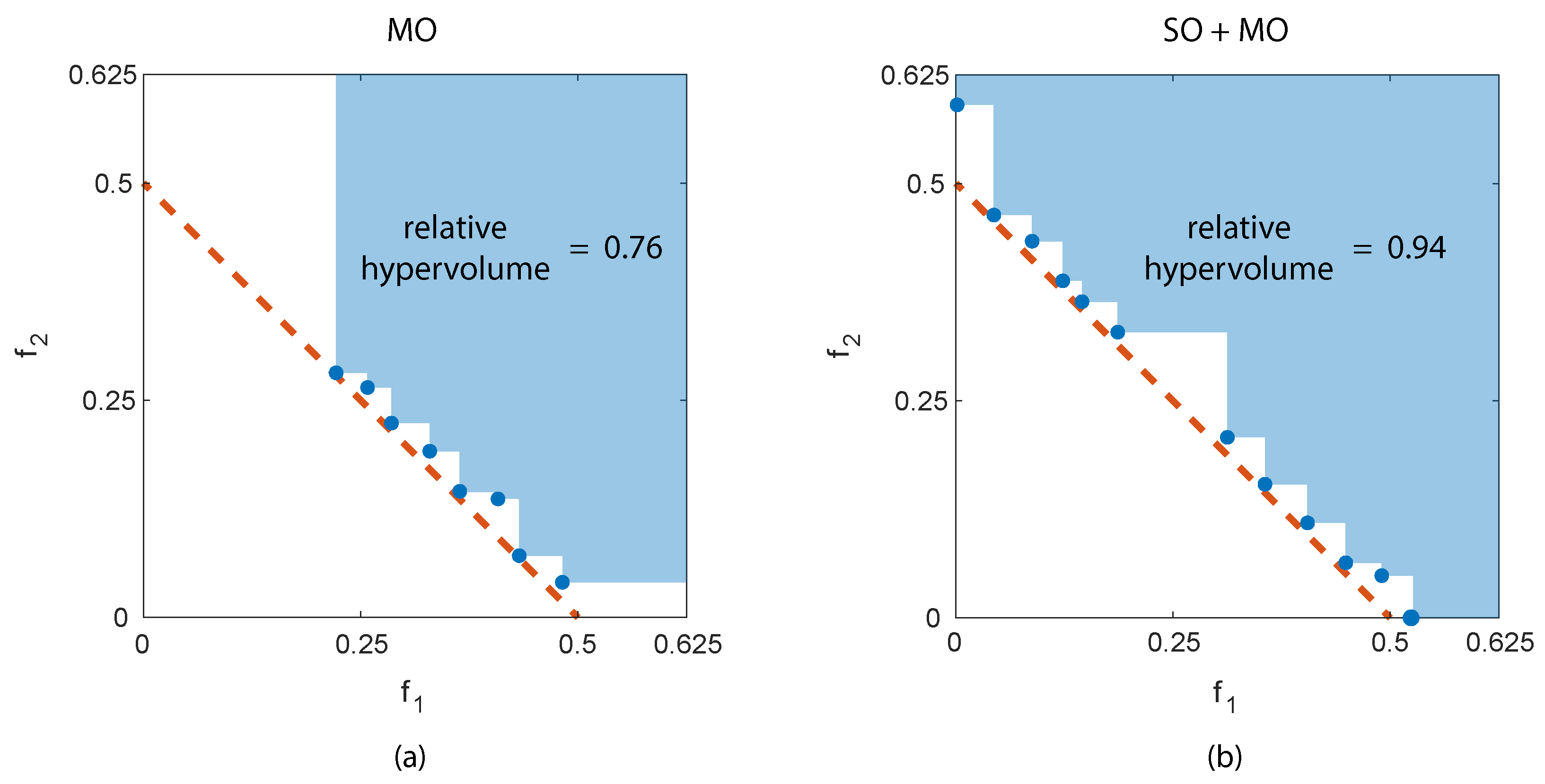
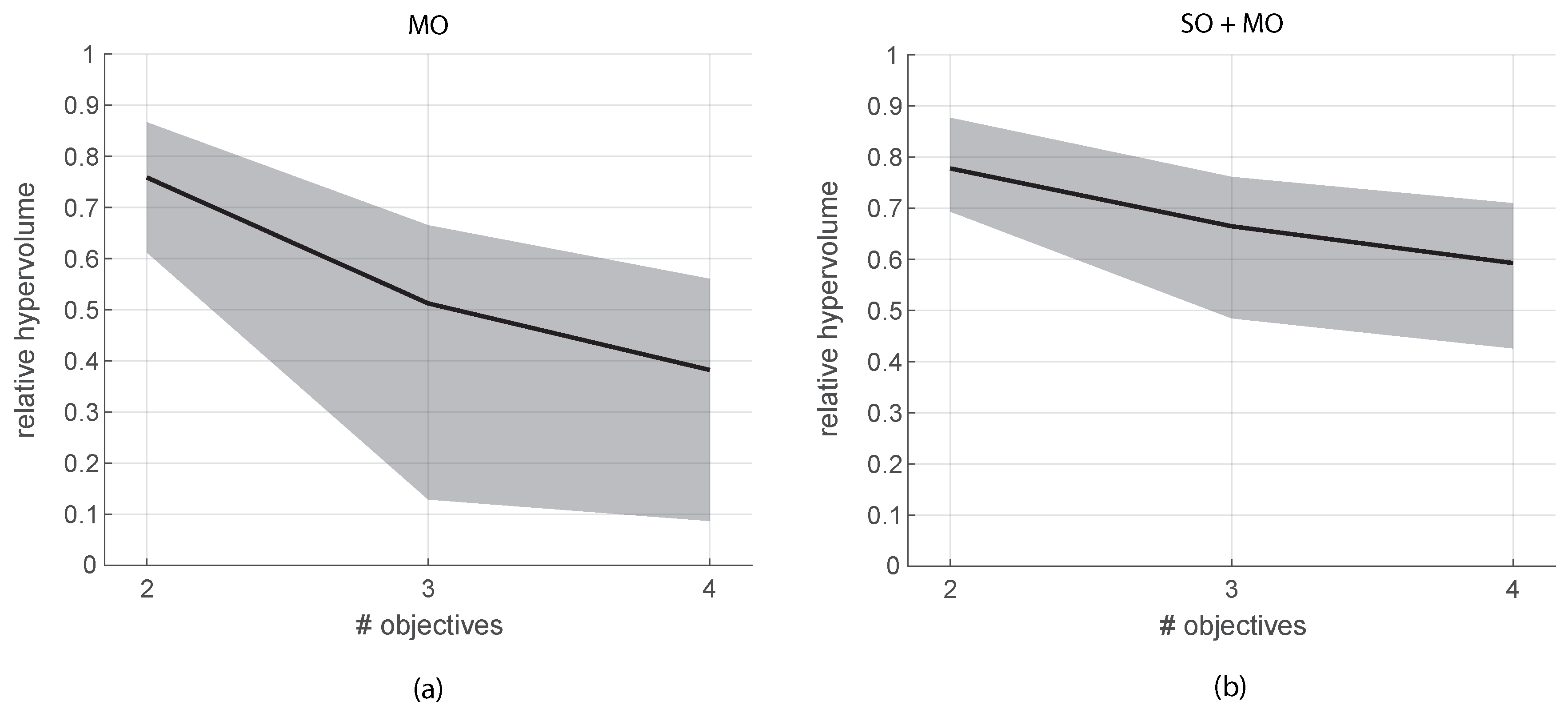
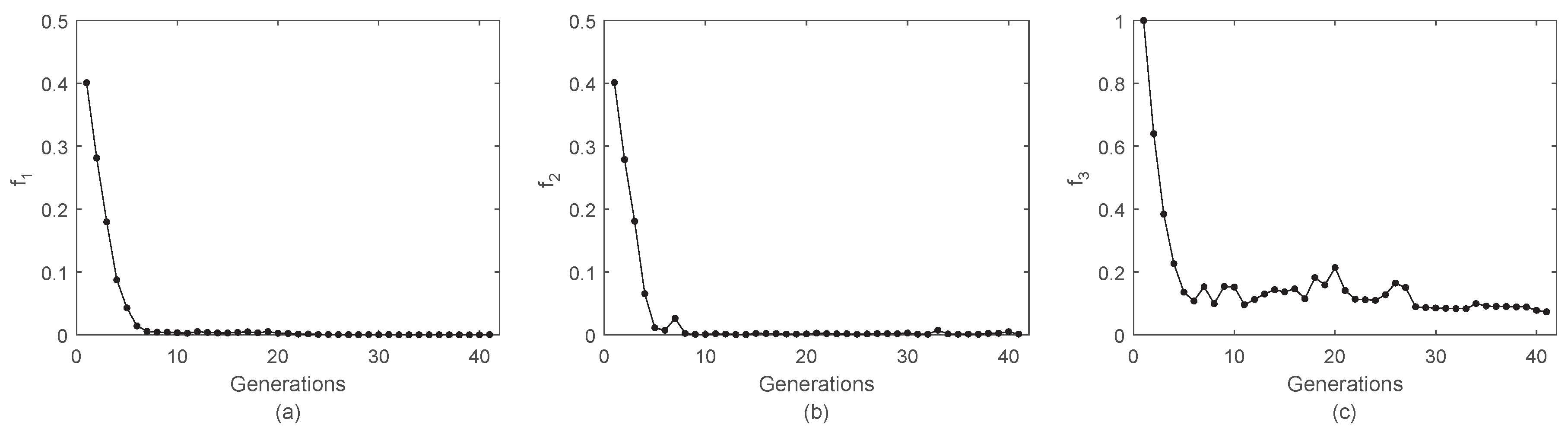
4. Analytical Tests
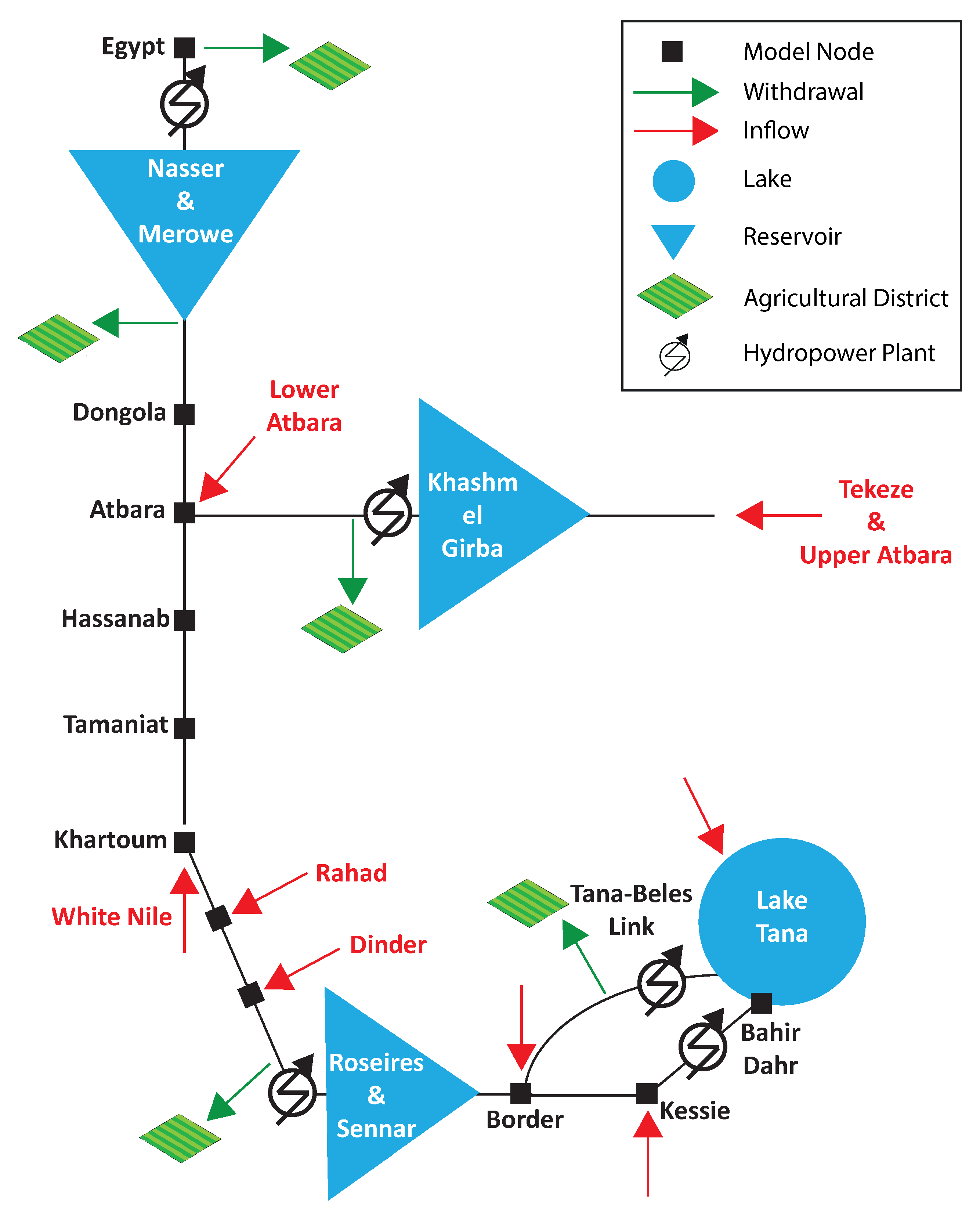
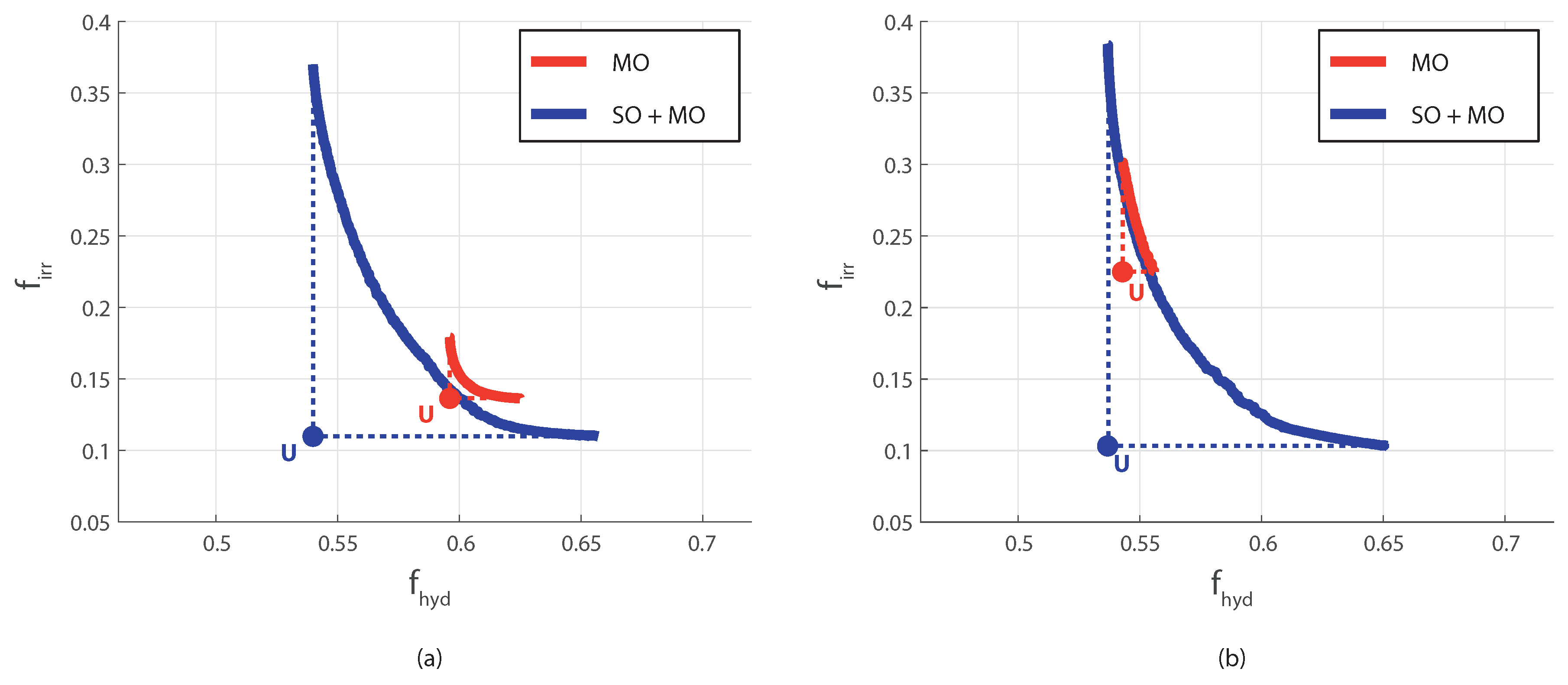
5. Real-World Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rajesh, J.; Gupta, S.; Rangaiah, G.; Ray, A. Multi-objective optimization of industrial hydrogen plants. Chem. Eng. Sci. 2001, 56, 999–1010. [Google Scholar] [CrossRef]
- Ayala, H.V.H.; dos Santos Coelho, L. Tuning of PID controller based on a multiobjective genetic algorithm applied to a robotic manipulator. Expert Syst. Appl. 2012, 39, 8968–8974. [Google Scholar] [CrossRef]
- Nisi, K.; Nagaraj, B.; Agalya, A. Tuning of a PID controller using evolutionary multi objective optimization methodologies and application to the pulp and paper industry. Int. J. Mach. Learn. Cybern. 2019, 10, 2015–2025. [Google Scholar] [CrossRef]
- Tapia, M.G.C.; Coello, C.A.C. Applications of multi-objective evolutionary algorithms in economics and finance: A survey. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 532–539. [Google Scholar]
- Bevilacqua, V.; Pacelli, V.; Saladino, S. A novel multi objective genetic algorithm for the portfolio optimization. In Proceedings of the International Conference on Intelligent Computing, Zhengzhou, China, 11–14 August 2011; pp. 186–193. [Google Scholar]
- Pai, G.V.; Michel, T. Metaheuristic multi-objective optimization of constrained futures portfolios for effective risk management. Swarm Evol. Comput. 2014, 19, 1–14. [Google Scholar] [CrossRef]
- Srinivasan, S.; Kamalakannan, T. Multi criteria decision making in financial risk management with a multi-objective genetic algorithm. Comput. Econ. 2018, 52, 443–457. [Google Scholar] [CrossRef]
- Giuliani, M.; Quinn, J.D.; Herman, J.D.; Castelletti, A.; Reed, P.M. Scalable multiobjective control for large-scale water resources systems under uncertainty. IEEE Trans. Control. Syst. Technol. 2017, 26, 1492–1499. [Google Scholar] [CrossRef]
- Sangiorgio, M.; Guariso, G. NN-based implicit stochastic optimization of multi-reservoir systems management. Water 2018, 10, 303. [Google Scholar] [CrossRef]
- Guariso, G.; Sangiorgio, M. Performance of Implicit Stochastic Approaches to the Synthesis of Multireservoir Operating Rules. J. Water Resour. Plan. Manag. 2020, 146, 04020034. [Google Scholar] [CrossRef]
- Guariso, G.; Sangiorgio, M. Spanning the Pareto Frontier of Environmental Problems. In Proceedings of the 10th International Congress on Environmental Modeling and Software, Brussels, Belgium, 14–18 September 2020. [Google Scholar]
- Yu, W.; Li, B.; Jia, H.; Zhang, M.; Wang, D. Application of multi-objective genetic algorithm to optimize energy efficiency and thermal comfort in building design. Energy Build. 2015, 88, 135–143. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, S.; Zhao, Y.; Yan, C. Renewable energy system optimization of low/zero energy buildings using single-objective and multi-objective optimization methods. Energy Build. 2015, 89, 61–75. [Google Scholar] [CrossRef]
- Guariso, G.; Sangiorgio, M. Multi-objective planning of building stock renovation. Energy Policy 2019, 130, 101–110. [Google Scholar] [CrossRef]
- Hamarat, C.; Kwakkel, J.H.; Pruyt, E.; Loonen, E.T. An exploratory approach for adaptive policymaking by using multi-objective robust optimization. Simul. Model. Pract. Theory 2014, 46, 25–39. [Google Scholar] [CrossRef]
- Guariso, G.; Sangiorgio, M. Integrating Economy, Energy, Air Pollution in Building Renovation Plans. IFAC-PapersOnLine 2018, 51, 102–107. [Google Scholar] [CrossRef]
- Mayer, M.J.; Szilágyi, A.; Gróf, G. Environmental and economic multi-objective optimization of a household level hybrid renewable energy system by genetic algorithm. Appl. Energy 2020, 269, 115058. [Google Scholar] [CrossRef]
- Guariso, G.; Sangiorgio, M. Valuing the Cost of Delayed Energy Actions. IFAC-PapersOnLine 2020, in press. [Google Scholar]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2001; Volume 16. [Google Scholar]
- Yang, X.S. Review of meta-heuristics and generalised evolutionary walk algorithm. Int. J. Bio-Inspired Comput. 2011, 3, 77–84. [Google Scholar] [CrossRef]
- Beheshti, Z.; Shamsuddin, S.M.H. A review of population-based meta-heuristic algorithms. Int. J. Adv. Soft Comput. Appl. 2013, 5, 1–35. [Google Scholar]
- Du, K.L.; Swamy, M. Simulated annealing. In Search and Optimization by Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 29–36. [Google Scholar]
- Dorigo, M.; Stützle, T. Ant colony optimization: Overview and recent advances. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 311–351. [Google Scholar]
- Rajabioun, R. Cuckoo optimization algorithm. Appl. Soft Comput. 2011, 11, 5508–5518. [Google Scholar] [CrossRef]
- Lee, C.K.H. A review of applications of genetic algorithms in operations management. Eng. Appl. Artif. Intell. 2018, 76, 1–12. [Google Scholar] [CrossRef]
- Houck, C.R.; Joines, J.; Kay, M.G. A genetic algorithm for function optimization: A Matlab implementation. Ncsu-ie tr 1995, 95, 1–10. [Google Scholar]
- Purohit, G.; Sherry, A.M.; Saraswat, M. Optimization of function by using a new MATLAB based genetic algorithm procedure. Int. J. Comput. Appl. 2013, 61, 15. [Google Scholar]
- Sheppard, C. Genetic Algorithms with Python, Smashwords ed.; CreateSpace Independent Publishing Platform: Charleston, SC, USA, 2017. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Ursem, R.K. Diversity-guided evolutionary algorithms. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Granada, Spain, 7–11 September 2002; pp. 462–471. [Google Scholar]
- Chen, C.M.; Chen, Y.p.; Zhang, Q. Enhancing MOEA/D with guided mutation and priority update for multi-objective optimization. In Proceedings of the 2009 IEEE Congress on Evolutionary Computation, Trondheim, Norway, 18–21 May 2009; pp. 209–216. [Google Scholar]
- Tan, K.C.; Chiam, S.C.; Mamun, A.; Goh, C.K. Balancing exploration and exploitation with adaptive variation for evolutionary multi-objective optimization. Eur. J. Oper. Res. 2009, 197, 701–713. [Google Scholar] [CrossRef]
- Liagkouras, K.; Metaxiotis, K. A new probe guided mutation operator for more efficient exploration of the search space: An experimental analysis. Int. J. Oper. Res. 2016, 25, 212–251. [Google Scholar] [CrossRef]
- Kesireddy, A.; Carrillo, L.R.G.; Baca, J. Multi-Criteria Decision Making-Pareto Front Optimization Strategy for Solving Multi-Objective Problems. In Proceedings of the 2020 IEEE 16th International Conference on Control & Automation (ICCA), Singapore, 9–11 October 2020; pp. 53–58. [Google Scholar]
- Laumanns, M.; Thiele, L.; Deb, K.; Zitzler, E. Combining convergence and diversity in evolutionary multiobjective optimization. Evol. Comput. 2002, 10, 263–282. [Google Scholar] [CrossRef]
- Zhao, G.; Luo, W.; Nie, H.; Li, C. A genetic algorithm balancing exploration and exploitation for the travelling salesman problem. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; Volume 1, pp. 505–509. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and exploitation in evolutionary algorithms: A survey. ACM Comput. Surv. (CSUR) 2013, 45, 1–33. [Google Scholar] [CrossRef]
- Hussain, A.; Muhammad, Y.S. Trade-off between exploration and exploitation with genetic algorithm using a novel selection operator. Complex Intell. Syst. 2019, 6, 1–14. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multiobjective optimization using evolutionary algorithms—A comparative case study. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Amsterdam, The Netherlands, 27–30 September 1998; pp. 292–301. [Google Scholar]
- Bader, J.; Deb, K.; Zitzler, E. Faster hypervolume-based search using Monte Carlo sampling. In Multiple Criteria Decision Making for Sustainable Energy and Transportation Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 313–326. [Google Scholar]
- Salazar, J.Z.; Reed, P.M.; Herman, J.D.; Giuliani, M.; Castelletti, A. A diagnostic assessment of evolutionary algorithms for multi-objective surface water reservoir control. Adv. Water Resour. 2016, 92, 172–185. [Google Scholar] [CrossRef]
- Goldenberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley Professional: Boston, MA, USA, 1989. [Google Scholar]
- Vrajitoru, D. Large population or many generations for genetic algorithms? Implications in information retrieval. In Soft Computing in Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2000; pp. 199–222. [Google Scholar]
- Deb, K.; Thiele, L.; Laumanns, M.; Zitzler, E. Scalable multi-objective optimization test problems. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), Boston, MA, USA, 12–17 May 2002; Volume 1, pp. 825–830. [Google Scholar]
- Huband, S.; Hingston, P.; Barone, L.; While, L. A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evol. Comput. 2006, 10, 477–506. [Google Scholar] [CrossRef]
- Sangiorgio, M. A neural Approach for Multi-Reservoir SYSTEM operation. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2016. [Google Scholar]
- Yao, H.; Georgakakos, A. Nile Decision Support Tool River Simulation and Management; Georgia Water Resources Institute: Atlanta, GA, USA, 2003. [Google Scholar]
- Jeuland, M.A. Planning Water Resources Development in an Uncertain Climate Future: A Hydro-Economic Simulation Framework Applied to the Case of the Blue Nile. Ph.D. Thesis, The University of North Carolina at Chapel Hill, Chapel Hill, NC, USA, 2009. [Google Scholar]
- Hadka, D.; Reed, P.M.; Simpson, T.W. Diagnostic assessment of the Borg MOEA for many-objective product family design problems. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–10. [Google Scholar]
- Hadka, D.; Reed, P. Borg: An auto-adaptive many-objective evolutionary computing framework. Evol. Comput. 2013, 21, 231–259. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guariso, G.; Sangiorgio, M. Improving the Performance of Multiobjective Genetic Algorithms: An Elitism-Based Approach. Information 2020, 11, 587. https://doi.org/10.3390/info11120587
Guariso G, Sangiorgio M. Improving the Performance of Multiobjective Genetic Algorithms: An Elitism-Based Approach. Information. 2020; 11(12):587. https://doi.org/10.3390/info11120587
Chicago/Turabian StyleGuariso, Giorgio, and Matteo Sangiorgio. 2020. "Improving the Performance of Multiobjective Genetic Algorithms: An Elitism-Based Approach" Information 11, no. 12: 587. https://doi.org/10.3390/info11120587
APA StyleGuariso, G., & Sangiorgio, M. (2020). Improving the Performance of Multiobjective Genetic Algorithms: An Elitism-Based Approach. Information, 11(12), 587. https://doi.org/10.3390/info11120587