Evaluation of Attackers’ Skill Levels in Multi-Stage Attacks †


Abstract
:1. Introduction
- Define alert correlation rules to identify multi-stage attacks.
- Revise the framework for evaluating an attacker’s skill level with regard to alerts.
2. Related Works
3. Methodology
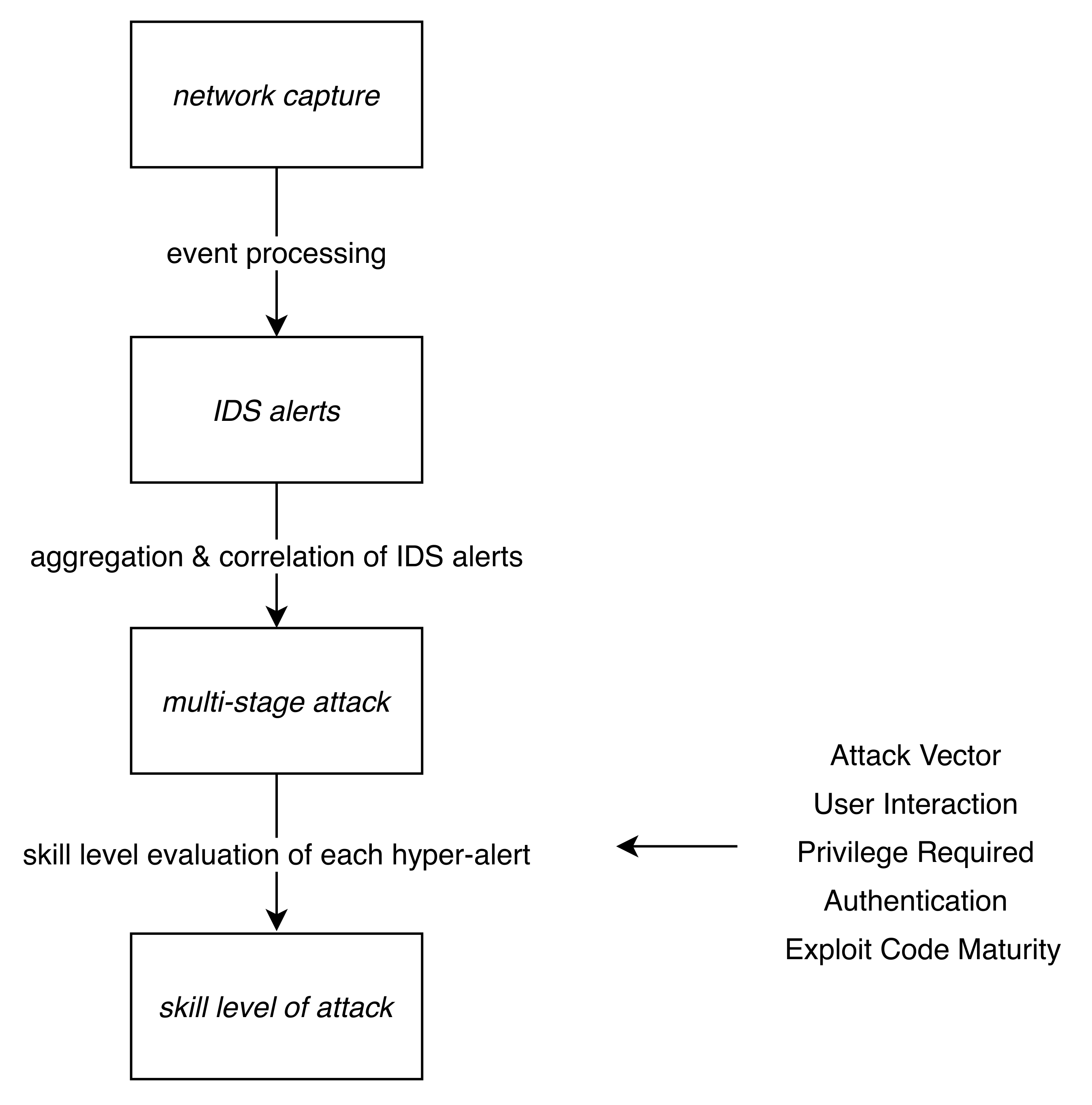
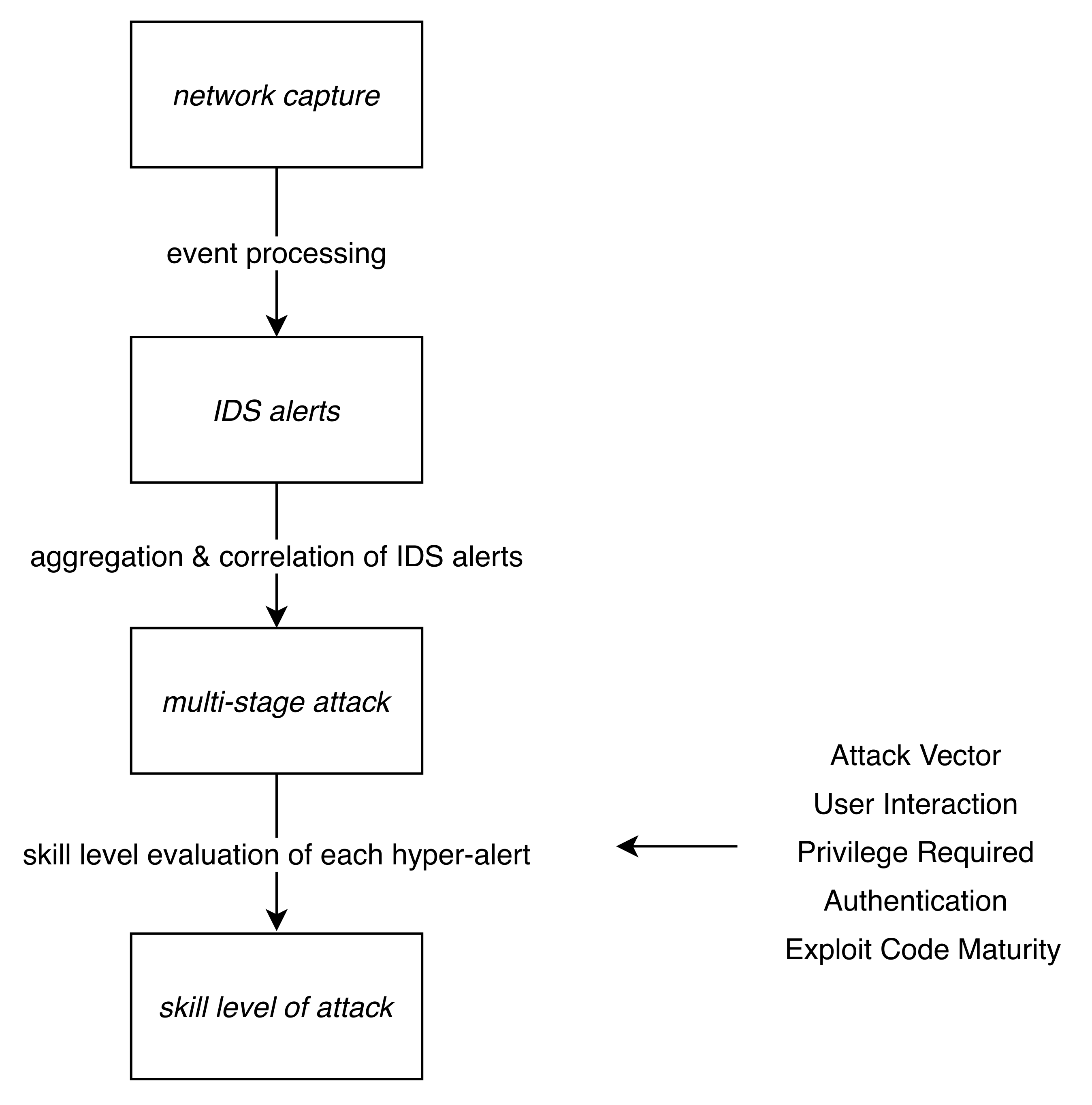
3.1. Data Set
3.2. Processing Data and Identification of Attacks
- Date and time;
- Source and destination IP addresses;
- Source and destination network ports;
- Protocol;
- Identifier of the rule (sid);
- Rule name or message;
- Alert severity.
- 2018-03-02 17:50:16.251431, 114.86.88.5, 172.31.69.26, 2010939ET SCAN Suspicious inbound to PostgreSQL port 5432
- Each of two compared hyper-alerts has at least one identical source IP address and at least one identical destination IP address.
- Each of two compared hyper-alerts has at least one identical sid and at least one identical destination IP address.
- Each of two compared hyper-alerts has at least one identical sid and at least one identical source IP address.
- Each of two compared hyper-alerts has at least one identical sid and at least one of the destination IP addresses of the first alert; and one of the source IP addresses of the second alert is the same for both.
- Each of two compared hyper-alerts has at least one source IP address in common with the other.
- In each of two compared hyper-alerts, at least one of the destination IP addresses of the first alert and one of the source IP addresses of the second alert are identical.
3.3. Evaluation of Attacker Skill Level of the Hyper-Alert
4. Results and Discussion
4.1. Denial of Service Attack
4.2. Brute-Force Attacks
- ET SCAN Potential SSH Scan
- ET SCAN LibSSH Based Frequent SSH Connections Likely BruteForce Attack
4.3. SQL Injection Attack
- 2x ET WEB_SERVER SQL Errors in HTTP 200 Response (error in your SQL syntax)
- 4x ET WEB_SERVER Possible SQL Injection Attempt UNION SELECT
- 2x ET WEB_SERVER Possible Attempt to Get SQL Server Version in URI using SELECT VERSION
- 2x ET WEB_SERVER Possible SQL Injection Attempt UNION SELECT
- 2x ET WEB_SERVER SQL Errors in HTTP 200 Response (error in your SQL syntax)
- 8x ET WEB_SERVER Possible SQL Injection Attempt UNION SELECT
- 2x ET WEB_SERVER Possible MySQL SQLi Attempt Information Schema Access
- 2x ET WEB_SERVER Possible SQL Injection Attempt SELECT FROM
- 2x ET WEB_SERVER SQL Errors in HTTP 200 Response (error in your SQL syntax)
- 2x ET WEB_SERVER Possible SQL Injection Attempt UNION SELECT
- 2x ET WEB_SERVER Possible MySQL SQLi Attempt Information Schema Access
- 4x ET WEB_SERVER Possible SQL Injection Attempt UNION SELECT
- 2x ET WEB_SERVER Possible MySQL SQLi Attempt Information Schema Access
- 2x ET WEB_SERVER Possible SQL Injection Attempt SELECT FROM
- 2x ET WEB_SERVER ATTACKER SQLi - SELECT and Schema Columns
4.4. Infiltration Attacks
- 2x ET POLICY Dropbox.com Offsite File Backup in Use
- ET TROJAN Windows dir Microsoft Windows DOS prompt command exit OUTBOUND
- ET SCAN Behavioral Unusual Port 135 traffic Potential Scan or Infection
- ET SCAN Behavioral Unusual Port 445 traffic Potential Scan or Infection
- CVSS:3.0/AV:N/AC:H/PR:N/UI:N/S:U/C:H/I:H/A:H
- AV:N/AC:M/Au:N/C:C/I:C/A:C
- ET TROJAN Possible Metasploit Payload Common Construct Bind_API (from server)
- ET SCAN Behavioral Unusual Port 139 traffic Potential Scan or Infection
- ET SCAN Behavioral Unusual Port 1434 traffic Potential Scan or Infection
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mézešová, T.; Sokol, P.; Bajtoš, T. Evaluation of Attacker Skill Level for Multi-stage Attacks. In Proceedings of the 2019 11th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Pitesti, Romania, 27–29 June 2019; pp. 1–6. [Google Scholar]
- Paulauskas, N.; Garsva, E. Attacker skill level distribution estimation in the system mean time-to- compromise. In Proceedings of the 2008 1st International Conference on Information Technology, Gdansk, Poland, 18–21 May 2008; pp. 1–4. [Google Scholar]
- Hu, H.; Liu, Y.; Zhang, H.; Zhang, Y. Security metric methods for network multistep attacks using AMC and big data correlation analysis. Secur. Commun. Netw. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- ben Othmane, L.; Ranchal, R.; Fernando, R.; Bhargava, B.; Bodden, E. Incorporating attacker capabilities in risk estimation and mitigation. Comput. Secur. 2015, 51, 41–61. [Google Scholar] [CrossRef]
- van Rensburg, A.J.; Nurse, J.R.; Goldsmith, M. Attacker-parametrised attack graphs. In Proceedings of the Tenth International Conference on Emerging Security Information, Systems and Technologies, Nice, France, 24–28 July 2016. [Google Scholar]
- Rocchetto, M.; Tippenhauer, N.O. On attacker models and profiles for cyber-physical systems. In Proceedings of the European Symposium on Research in Computer Security, Heraklion, Greece, 26–30 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 427–449. [Google Scholar]
- Fraunholz, D.; Anton, S.D.; Schotten, H.D. Introducing gamfis: A generic attacker model for information security. In Proceedings of the 2017 25th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 21–23 September 2017; pp. 1–6. [Google Scholar]
- Ošt’ádal, R.; Švenda, P.; Matyáš, V. Reconsidering attacker models in Ad-Hoc networks. In Proceedings of the Cambridge International Workshop on Security Protocols, Brno, Czech Republic, 7–8 April 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 219–227. [Google Scholar]
- Krautsevich, L.; Martinelli, F.; Yautsiukhin, A. Towards modelling adaptive attacker’s behaviour. In Proceedings of the International Symposium on Foundations and Practice of Security, Montreal, QC, Canada, 25–26 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 357–364. [Google Scholar]
- Mohammadian, M. Intelligent security and risk analysis in network systems. In Proceedings of the 2017 International Conference on Infocom Technologies and Unmanned Systems (Trends and Future Directions) (ICTUS), Dubai, UAE, 18–20 December 2017; pp. 826–830. [Google Scholar]
- Hassan, S.; Guha, R. A probabilistic study on the relationship of deceptions and attacker skills. In Proceedings of the 2017 IEEE 15th International Conference on Dependable, Autonomic and Secure Computing, 15th International Conference on Pervasive Intelligence and Computing, 3rd International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Orlando, FL, USA, 6–10 November 2017; pp. 693–698. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Funchal, Portugal, 22–24 January 2020; pp. 108–116. [Google Scholar]
- Gamage, S.; Samarabandu, J. Deep learning methods in network intrusion detection: A survey and an objective comparison. J. Netw. Comput. Appl. 2020, 169, 102767. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]
- de Souza, C.A.; Westphall, C.B.; Machado, R.B.; Sobral, J.B.M.; dos Santos Vieira, G. Hybrid approach to intrusion detection in fog-based IoT environments. Comput. Netw. 2020, 180, 107417. [Google Scholar] [CrossRef]
- Mézešová, T.; Bahsi, H. Expert Knowledge Elicitation for Skill Level Categorization of Attack Paths. In Proceedings of the 2019 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Oxford, UK, 3–4 June 2019; pp. 1–8. [Google Scholar]
- Mell, P.; Scarfone, K.; Sasha, R. A Complete Guide to the Common Vulnerability Scoring System Version 2.0. Published by FIRST-Forum of Incident Response and Security Teams. 2007. Available online: https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=51198 (accessed on 19 November 2020).
- CVSS Special Interest Group. Common Vulnerability Scoring System v3.1: Specification Document. 2019. Available online: https://www.first.org/cvss/v3-1/cvss-v31-specification_r1.pdf (accessed on 19 November 2020).
- Andel, T.R.; Yasinsac, A. Adaptive threat modeling for secure ad hoc routing protocols. Electron. Notes Theor. Comput. Sci. 2008, 197, 3–14. [Google Scholar] [CrossRef] [Green Version]
- Allodi, L.; Banescu, S.; Femmer, H.; Beckers, K. Identifying relevant information cues for vulnerability assessment using CVSS. In Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, Tempe, AZ, USA, 19–21 March 2018; pp. 119–126. [Google Scholar]
- Elbaz, C.; Rilling, L.; Morin, C. Fighting N-day vulnerabilities with automated CVSS vector prediction at disclosure. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Dublin, Ireland, 25–28 August 2020; pp. 1–10. [Google Scholar]
- Watters, P.; Scolyer-Gray, P.; Kayes, A.; Chowdhury, M.J.M. This would work perfectly if it weren’t for all the humans: Two factor authentication in late modern societies. First Monday 2019, 24. [Google Scholar] [CrossRef]
- Kayes, A.; Rahayu, W.; Watters, P.; Alazab, M.; Dillon, T.; Chang, E. Achieving security scalability and flexibility using Fog-Based Context-Aware Access Control. Future Gener. Comput. Syst. 2020, 107, 307–323. [Google Scholar] [CrossRef]
- ET Labs. Emerging Threats Rules; ET Labs: Austin, TX, USA, 2020. [Google Scholar]

{kind=link}
| Keywords or Observations | Corresponding Metric Value | Skill Level |
|---|---|---|
| external source IP address | : Network | script kiddies |
| internal source & external destination IP address | : Network | script kiddies |
| internal source & destination IP address | : Adjacent | moderately skilled |
| small time differences in timestamps or regularity | : None | script kiddies |
| none - explicitly stated so references | : Required | moderately skilled |
| default | : None/Low | script kiddies |
| classtype “successful-admin” or “Admin” in message | : High | moderately skilled |
| default | : None | script kiddies |
| “Authentication Success” in message | : Single | script kiddies |
| more alerts with “Authentication Success” | : Multiple | moderately skilled |
| scanning or Metasploit in message or classtype | : High | script kiddies |
| malware names in message or classtype | : High | script kiddies |
| references in rule to ready-to-use payloads | : High | script kiddies |
| tagged with SQL injection or Cross-site scripting | : High | script kiddies |
| classtypes rootkit or backdoor (or in message) | : Functional/Proof of Concept | moderately skilled |
| classtype Web-application-attack | : Functional/Proof of Concept | moderately skilled |
| default | : Unproven | highly skilled |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mézešová, T.; Sokol, P.; Bajtoš, T. Evaluation of Attackers’ Skill Levels in Multi-Stage Attacks. Information 2020, 11, 537. https://doi.org/10.3390/info11110537
Mézešová T, Sokol P, Bajtoš T. Evaluation of Attackers’ Skill Levels in Multi-Stage Attacks. Information. 2020; 11(11):537. https://doi.org/10.3390/info11110537
Chicago/Turabian StyleMézešová, Terézia, Pavol Sokol, and Tomáš Bajtoš. 2020. "Evaluation of Attackers’ Skill Levels in Multi-Stage Attacks" Information 11, no. 11: 537. https://doi.org/10.3390/info11110537
APA StyleMézešová, T., Sokol, P., & Bajtoš, T. (2020). Evaluation of Attackers’ Skill Levels in Multi-Stage Attacks. Information, 11(11), 537. https://doi.org/10.3390/info11110537