Urdu Documents Clustering with Unsupervised and Semi-Supervised Probabilistic Topic Modeling



Abstract
:1. Introduction
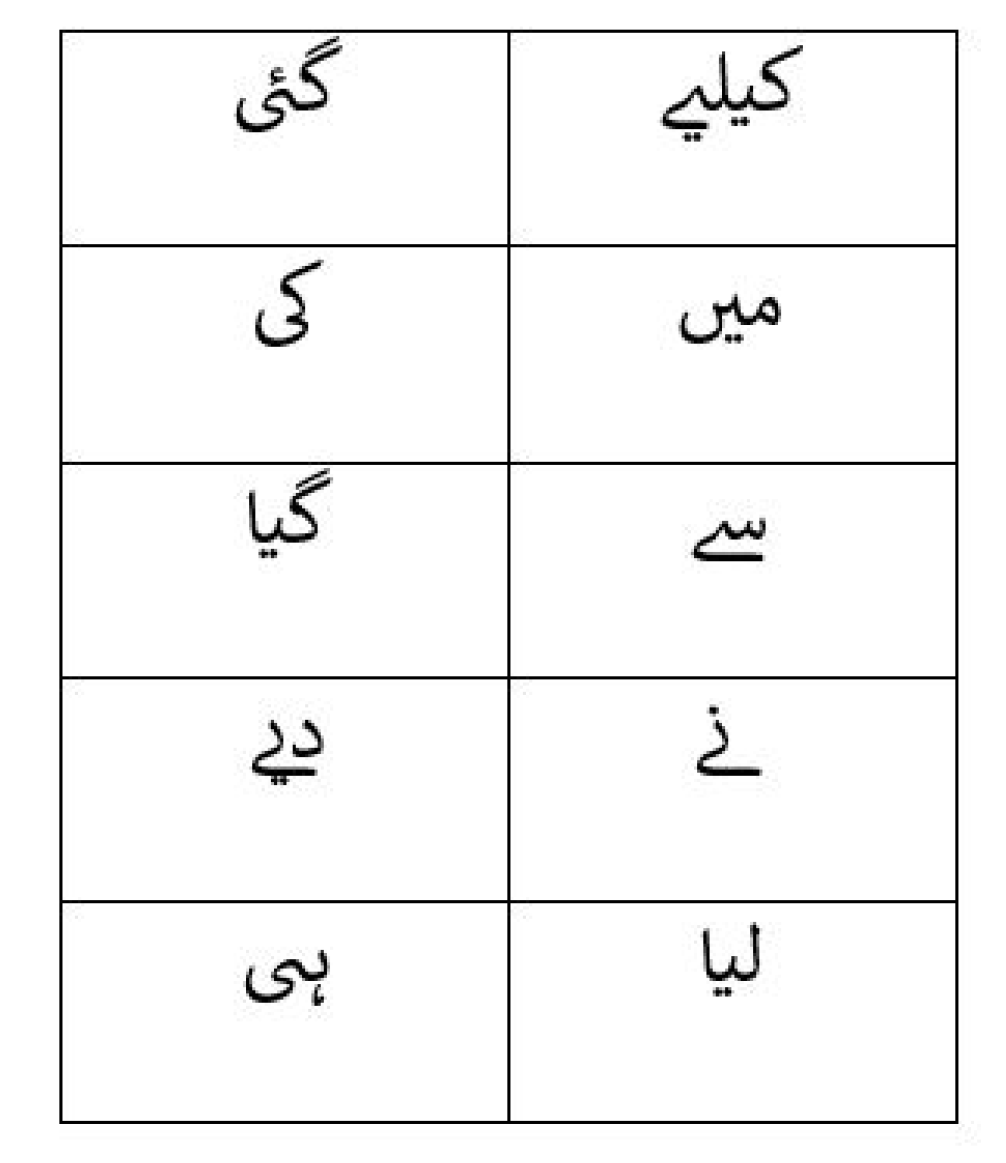
2. Urdu Language
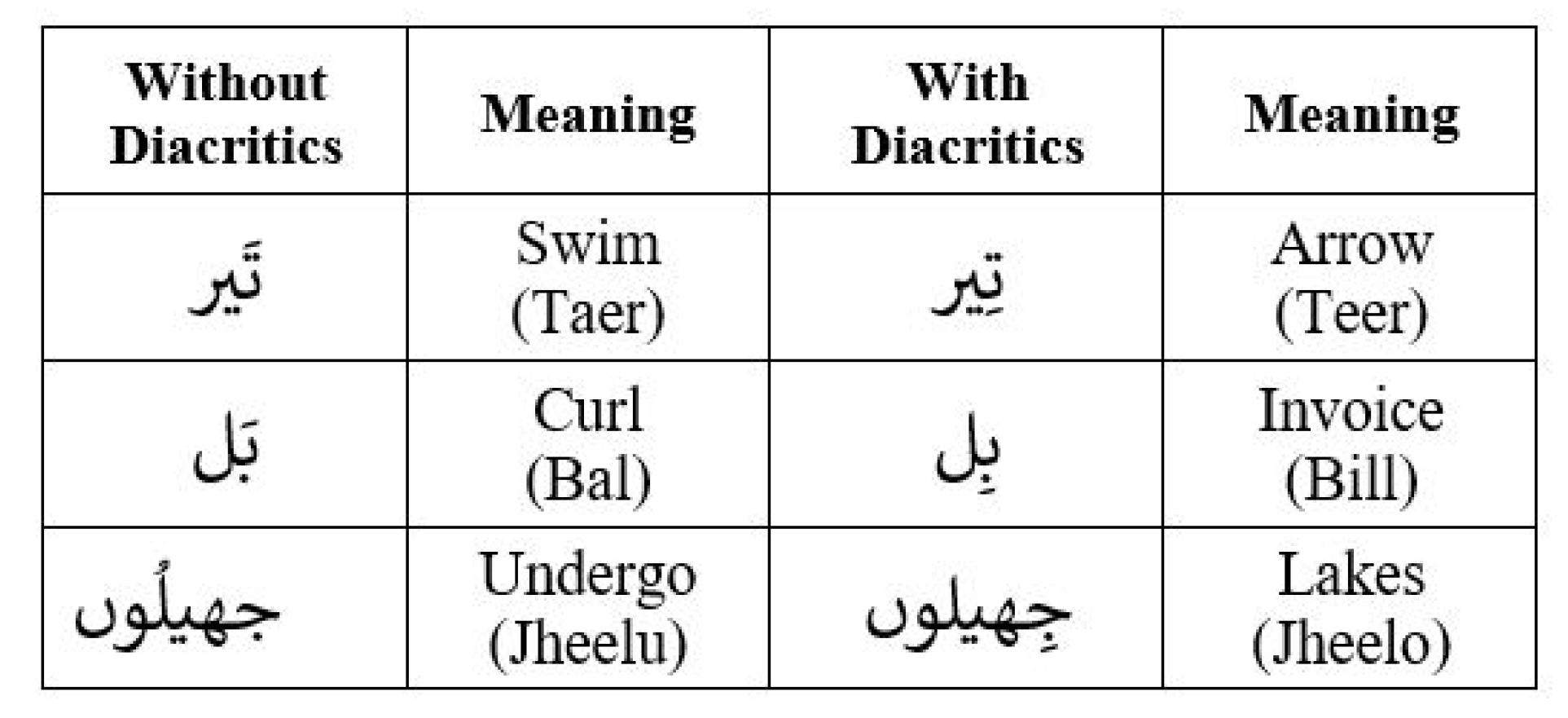
2.1. Particularities
2.2. Urdu Language and Clustering
3. Clustering Methods
3.1. K-Means
- Input: A set of N numbers and K.
- Output: A group of numbers into k clusters.
- Step 1: K random elements are randomly selected at the beginning and are regarded a centroid, such as .
- Step 2: Assign each number to the cluster, which has minimum distance .
- Step 3: Assign all other elements to the nearest centroid and recalculate the new centroid.
- Step 4: Repeat steps 2 and 3 until no other elements move from one cluster to another.
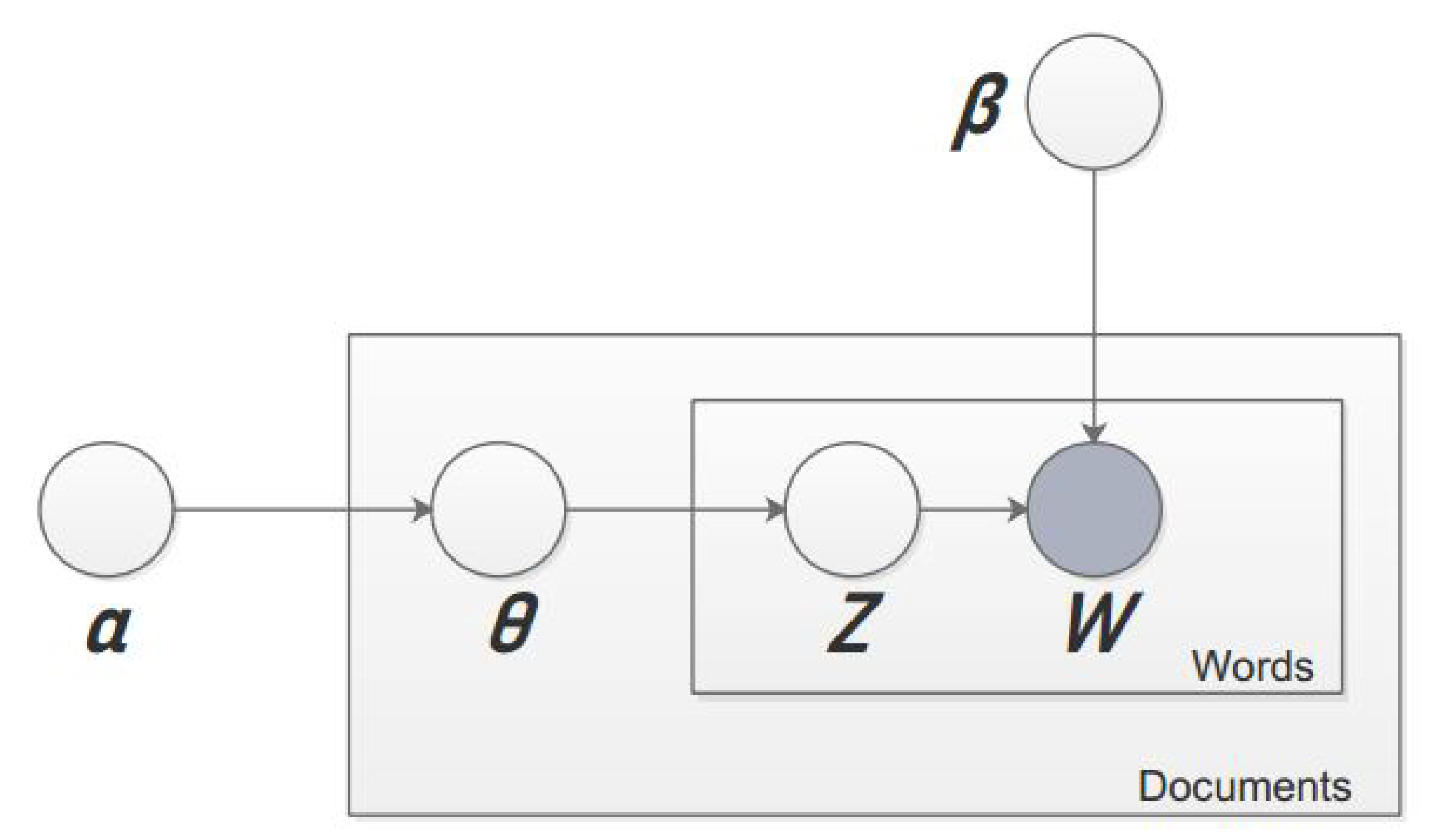
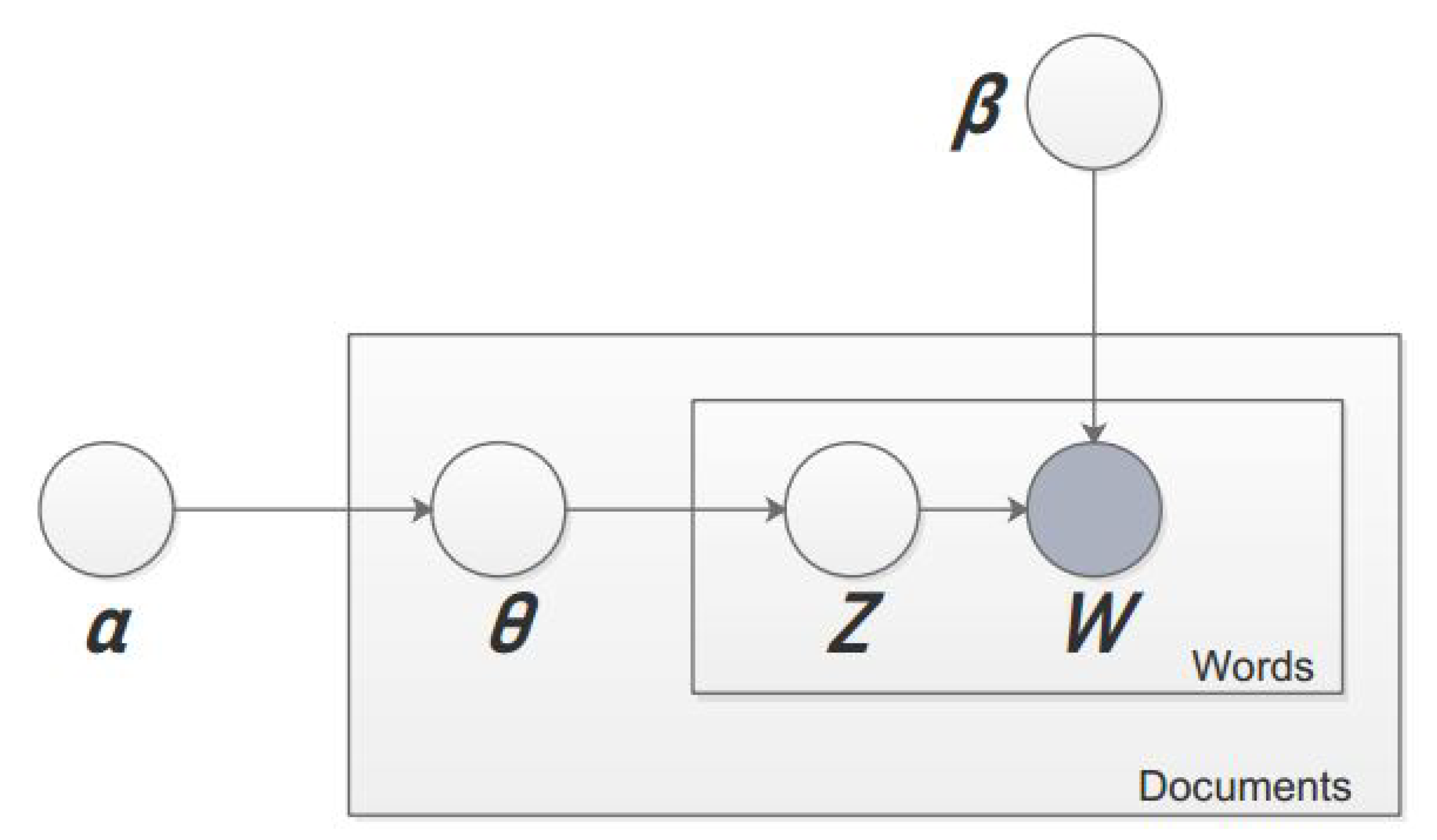
3.2. Latent Dirichlet Allocation
3.3. Non-Negative Matrix Factorization
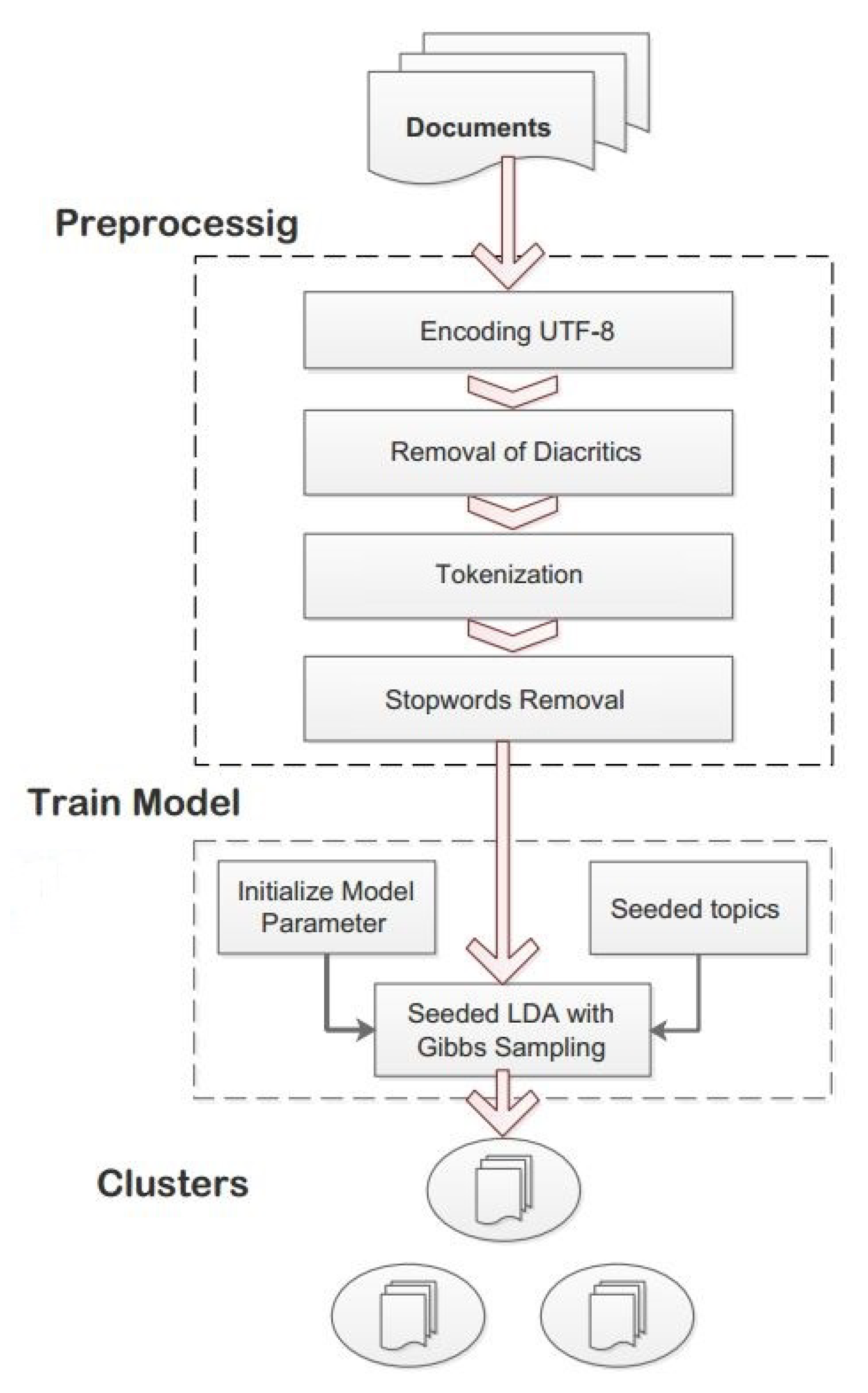
3.4. Seeded-ULDA Framework
3.4.1. Preprocessing
Enconding UTF-8
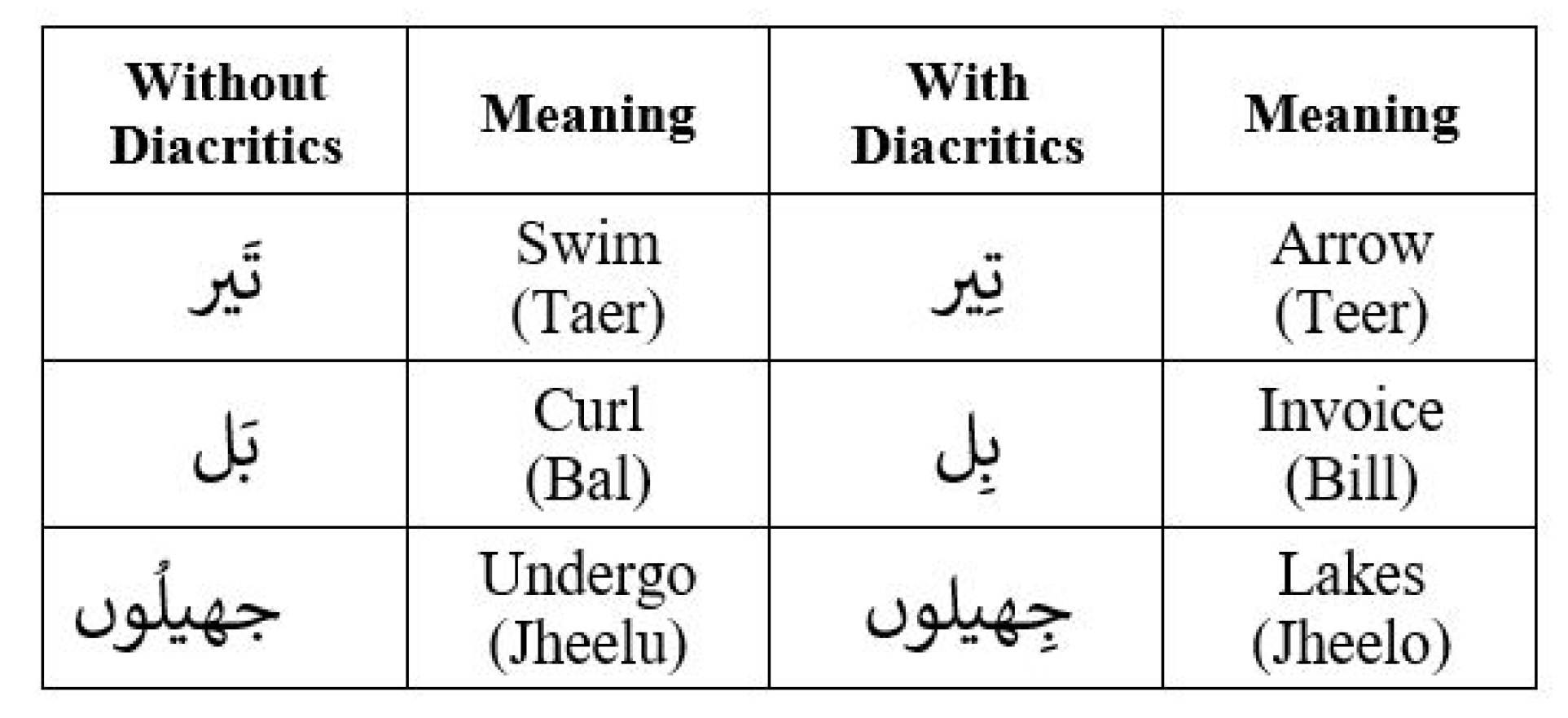
Removal of Diacritics
Tokenization
Stopwords Removal
3.4.2. Seeded-LDA
3.4.3. Gibbs Sampling
3.4.4. Seed Topics
3.5. Topic Modeling and Clustering
4. Evaluation Techniques
4.1. F-Measure
4.2. Rand Index
5. Experiment and Evaluation
5.1. Dataset
5.2. Experiment
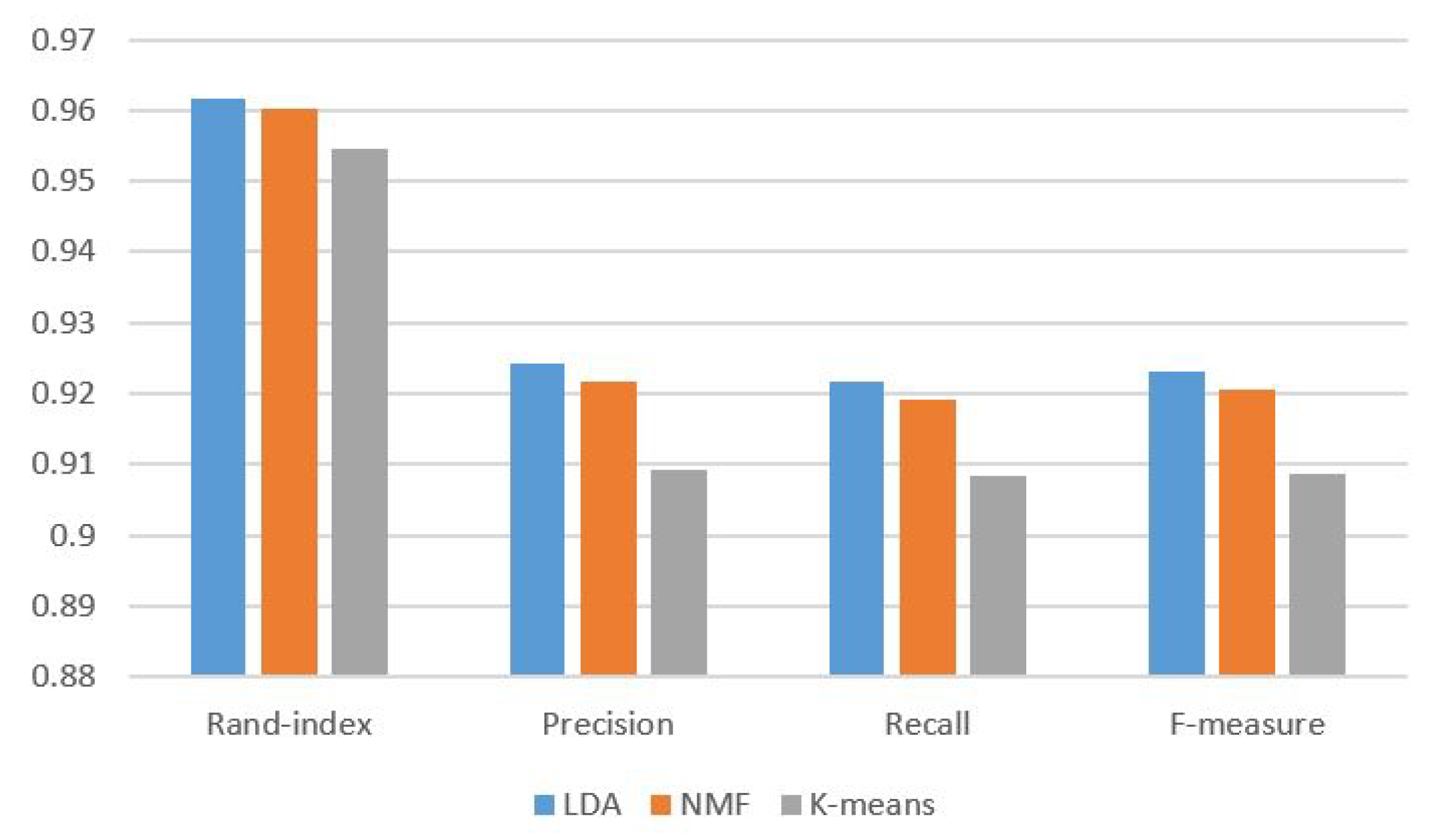
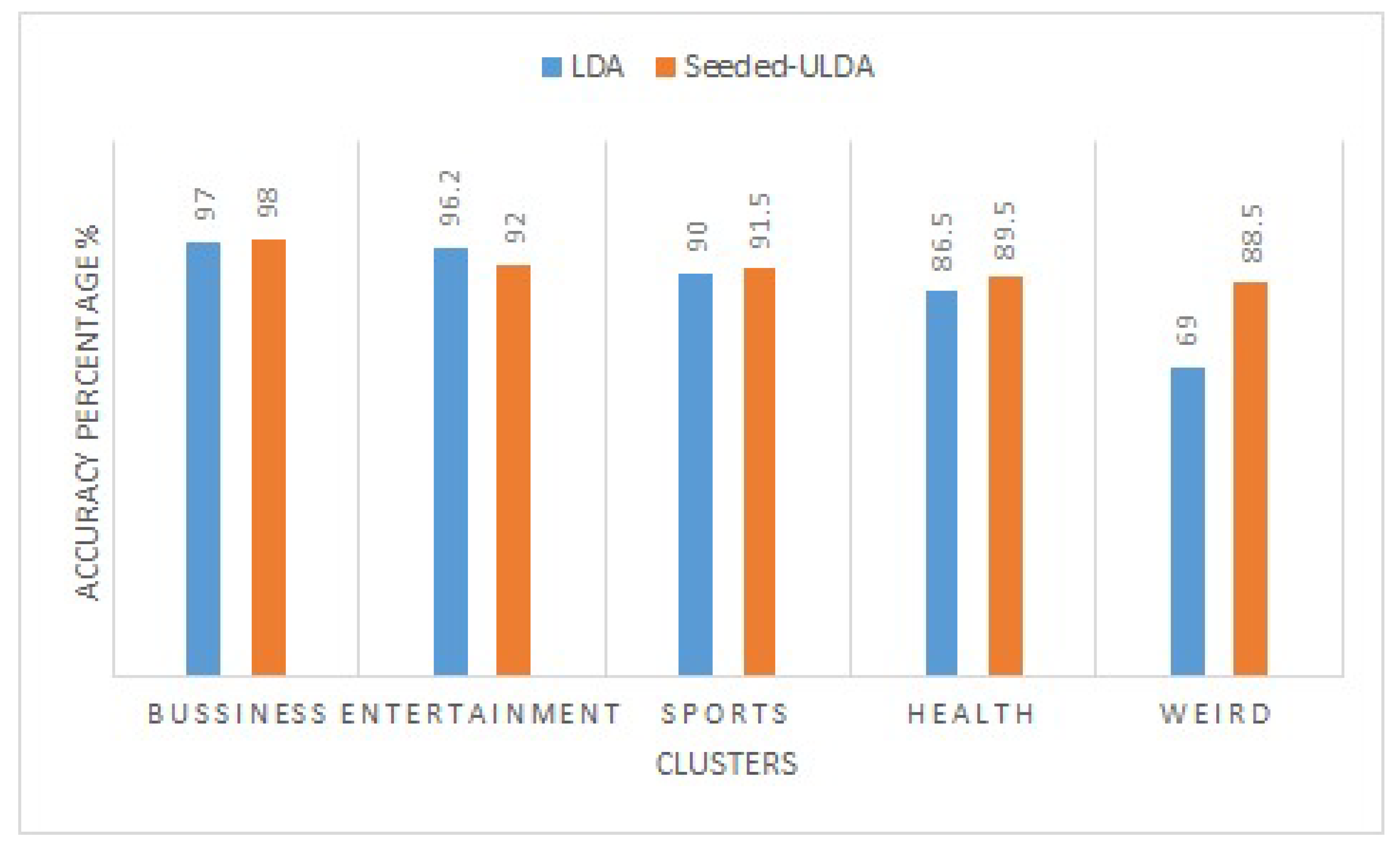
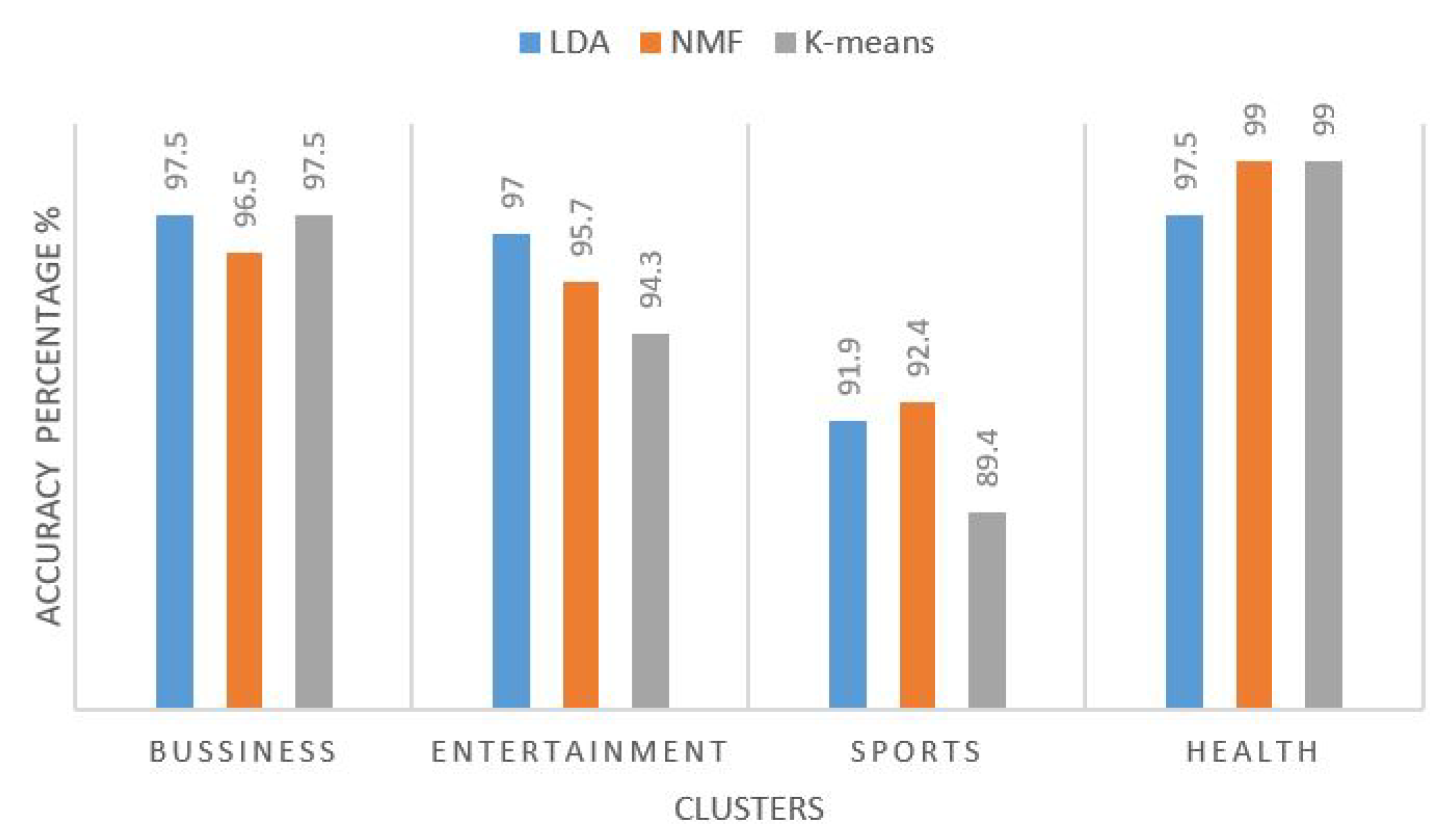
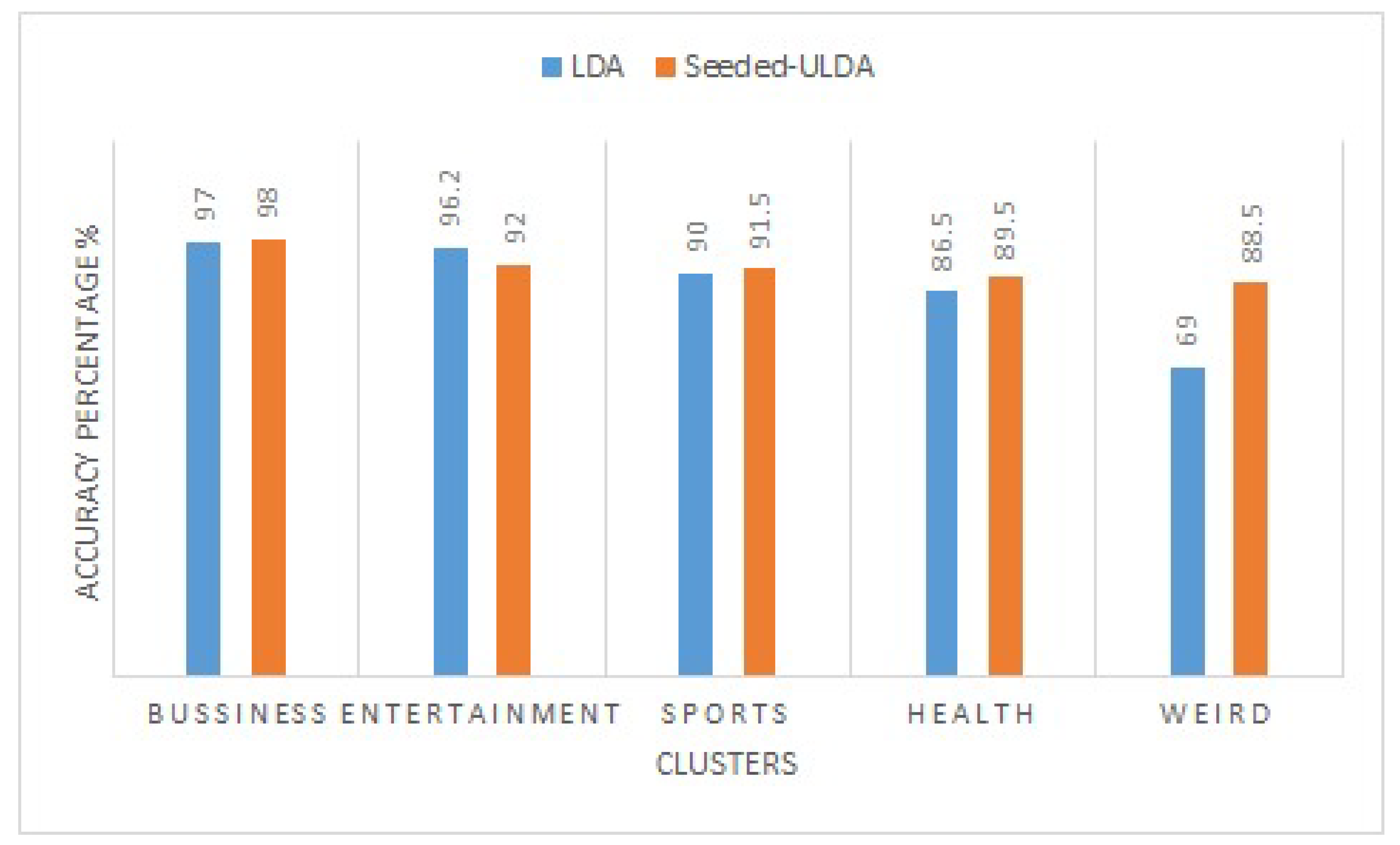
5.3. Results and Discussion
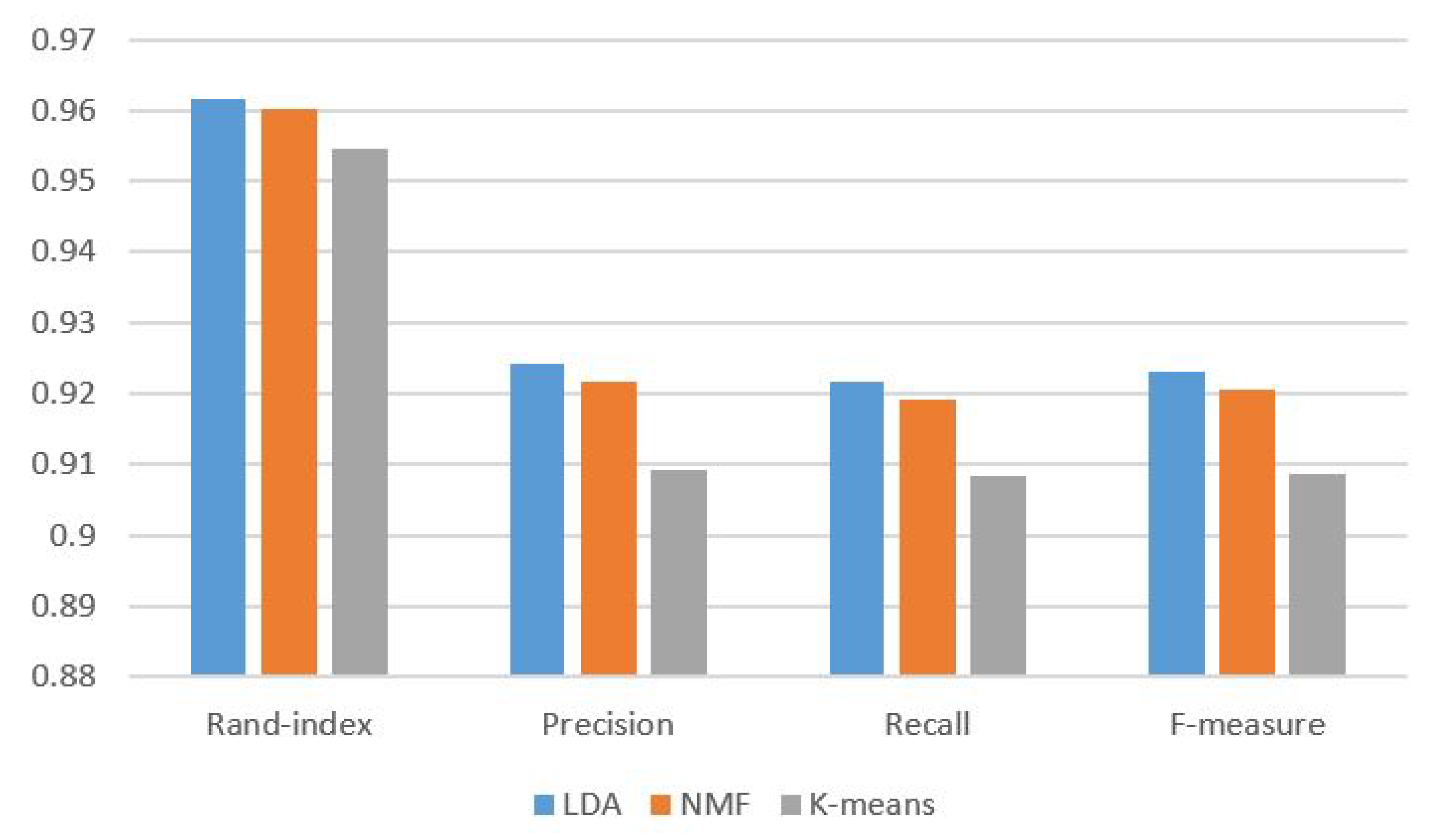
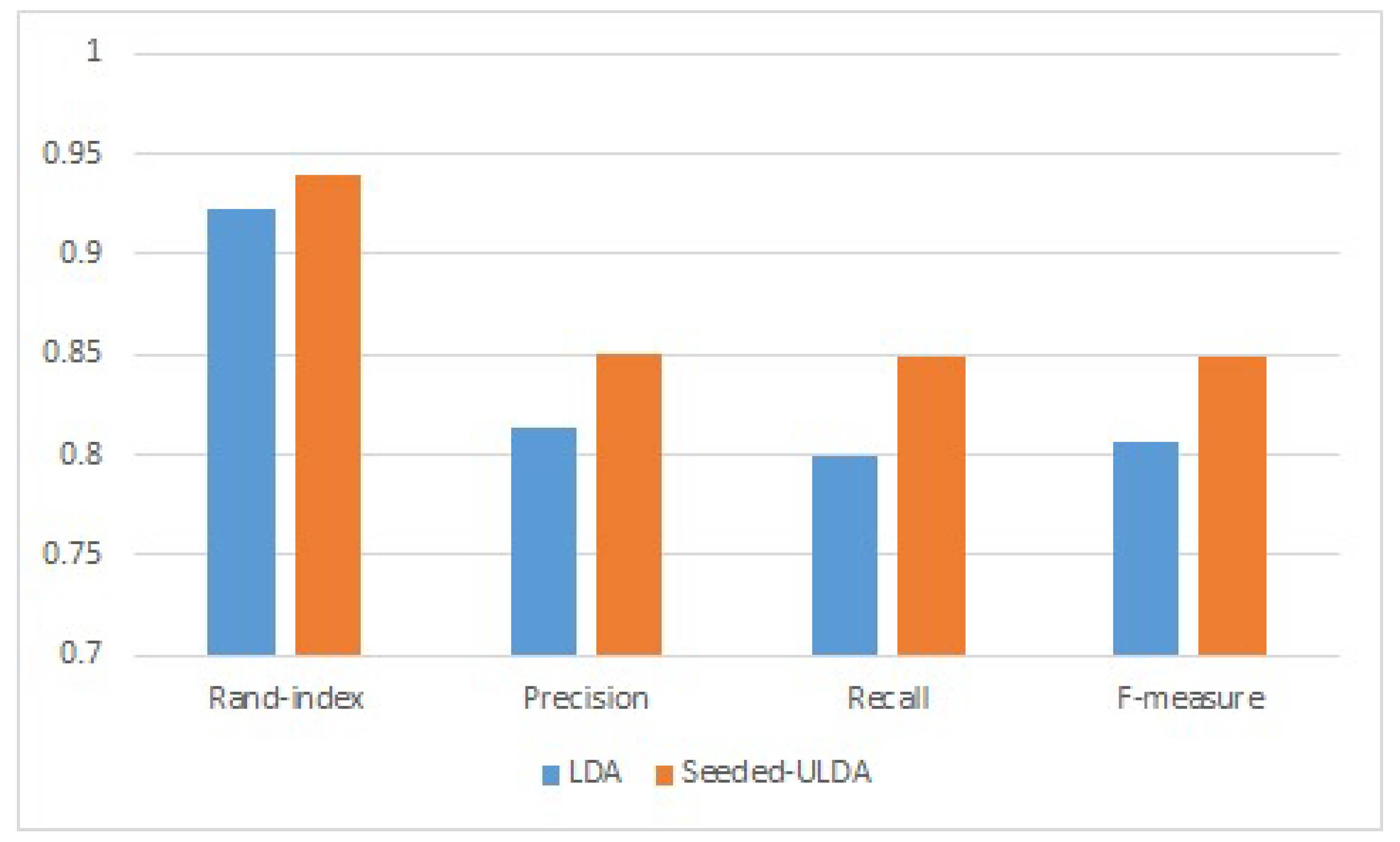
5.4. Evaluation
6. Conclusions and Future Plan
Author Contributions
Funding
Conflicts of Interest
References
- Kumar, K.; Santosh, G.S.K.; Varma, V. Multilingual Document Clustering Using Wikipedia as External Knowledge. In Multidisciplinary Information Retrieval; Hanbury, A., Rauber, A., de Vries, A.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 108–117. [Google Scholar]
- Jain, A.K. Data Clustering: 50 Years Beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Peng, M.; Zhu, J.; Wang, H.; Li, X.; Zhang, Y.; Zhang, X.; Tian, G. Mining Event-Oriented Topics in Microblog Stream with Unsupervised Multi-View Hierarchical Embedding. ACM Trans. Knowl. Discov. Data 2018, 12, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Peng, M.; Zhu, J.; Li, X.; Huang, J.; Wang, H.; Zhang, Y. Central Topic Model for Event-oriented Topics Mining in Microblog Stream. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, CIKM ’15, Melbourne, Australia, 19–23 October 2015; ACM: New York, NY, USA, 2015; pp. 1611–1620. [Google Scholar] [CrossRef]
- Ghosh, J.; Strehl, A. Similarity-Based Text Clustering: A Comparative Study. In Grouping Multidimensional Data: Recent Advances in Clustering; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Liu, L.; Kang, J.; Yu, J.; Wang, Z. A comparative study on unsupervised feature selection methods for text clustering. In Proceedings of the International Conference on Natural Language Processing and Knowledge Engineering, Wuhan, China, 30 October–1 November 2005; pp. 597–601. [Google Scholar] [CrossRef]
- Rahman, A.U.; Khan, K.; Khan, W.; Khan, A.; Saqia, B. Unsupervised Machine Learning based Documents Clustering in Urdu. EAI Endorsed Trans. Scalable Inf. Syst. 2018, 5. [Google Scholar] [CrossRef] [Green Version]
- Alhawarat, M.; Hegazi, M. Revisiting K-Means and Topic Modeling, a Comparison Study to Cluster Arabic Documents. IEEE Access 2018, 6, 42740–42749. [Google Scholar] [CrossRef]
- Chang, J.; Boyd-Graber, J.; Wang, C.; Gerrish, S.; Blei, D.M. Reading Tea Leaves: How Humans Interpret Topic Models. In Neural Information Processing Systems; Curran Associates, Inc.: Chatsworth, ON, Canada, 2009. [Google Scholar]
- Jagarlamudi, J.; Daumé III, H.; Udupa, R. Incorporating Lexical Priors into Topic Models. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Avignon, France, 2012; pp. 204–213. [Google Scholar]
- Pritchard, J.K.; Stephens, M.; Donnelly, P. Inference of Population Structure Using Multilocus Genotype Data. Genetics 2000, 155, 945–959. [Google Scholar]
- Gad, W.K.; Kamel, M.S. Enhancing Text Clustering Performance Using Semantic Similarity. In Enterprise Information Systems; Filipe, J., Cordeiro, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 325–335. [Google Scholar]
- Blei, D.M. Probabilistic Topic Models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Kelaiaia, A.; Merouani, H.F. Clustering with Probabilistic Topic Models on Arabic Texts. In Modeling Approaches and Algorithms for Advanced Computer Applications; Amine, A., Otmane, A.M., Bellatreche, L., Eds.; Springer International Publishing: Cham, Switzerland, 2013; pp. 65–74. [Google Scholar] [CrossRef]
- Humayoun, M. Urdu Morphology, Orthography and Lexicon Extraction; CAASL-2, the Second Workshop on Computational Approaches to Arabic Script-based Languages; Linguistic Institute, Stanford University: Stanford, CA, USA, 2007. [Google Scholar]
- Mukund, S.; Srihari, R.; Peterson, E. An Information-Extraction System for Urdu—A Resource-Poor Language. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2010, 9, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Patil, A.; Pharande, K.; Nale, D.; Agrawal, R. Article: Automatic Text Summarization. Int. J. Comput. Appl. 2015, 109, 18–19. [Google Scholar]
- Daud, A.; Khan, W.; Che, D. Urdu language processing: A survey. Artif. Intell. Rev. 2017, 47, 279–311. [Google Scholar] [CrossRef]
- Shabbir, S.; Javed, N.; Siddiqi, I.; Khurshid, K. A comparative study on clustering techniques for Urdu ligatures in nastaliq font. In Proceedings of the 13th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 27–28 December 2017; pp. 1–6. [Google Scholar]
- Khan, N.H.; Adnan, A.; Basar, S. Urdu ligature recognition using multi-level agglomerative hierarchical clustering. Clust. Comput. 2018, 21, 503–514. [Google Scholar] [CrossRef]
- Rafeeq, M.J.; Rehman, Z.; Khan, A.; Khan, I.A.; Jadoon, W. Ligature Categorization Based Nastaliq Urdu Recognition Using Deep Neural Networks. Comput. Math. Organ. Theory 2019, 25, 184–195. [Google Scholar] [CrossRef]
- Khan, S.A.; Anwar, W.; Bajwa, U.I.; Wang, X. A Light Weight Stemmer for Urdu Language: A Scarce Resourced Language. In Proceedings of the 3rd Workshop on South and Southeast Asian Natural Language Processing, Mumbai, India, 8–15 December 2012; The COLING 2012 Organizing Committee: Mumbai, India, 2012; pp. 69–78. [Google Scholar]
- Chandio, A.A.; Asikuzzaman, M.; Pickering, M.; Leghari, M. Cursive-Text: A Comprehensive Dataset for End-to-End Urdu Text Recognition in Natural Scene Images. Data Brief 2020, 31, 105749. [Google Scholar] [CrossRef]
- Nasim, Z.; Haider, S. Cluster analysis of urdu tweets. J. King Saud Univ. Comput. Inf. Sci. 2020, in press. [Google Scholar]
- Nawaz, A.; Bakhtyar, M.; Baber, J.; Ullah, I.; Noor, W.; Basit, A. Extractive Text Summarization Models for Urdu Language. Inf. Process. Manag. 2020, 57, 102383. [Google Scholar] [CrossRef]
- Bruni, R.; Bianchi, G. Website categorization: A formal approach and robustness analysis in the case of e-commerce detection. Expert Syst. Appl. 2020, 142, 113001. [Google Scholar] [CrossRef] [Green Version]
- Ehsan, T.; Asif, H.M.S. Finding Topics in Urdu: A Study of Applicability of Document Clustering in Urdu Language. Pak. J. Eng. Appl. Sci. 2018, 23, 77–85. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.A.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques. arXiv 2017, arXiv:1707.02919,2017. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Clustering Algorithms. In Mining Text Data; Aggarwal, C.C., Zhai, C., Eds.; Springer US: Boston, MA, USA, 2012; pp. 77–128. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. In Proceedings of the Fourth International Conference on Statistical Methods for the Environmental Sciences, Espoo, Finland, 17–21 August 1992. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Wells, J.C. Orthographic Diacritics and Multilingual Computing. Proc. Lang. Probl. Lang. Plan. 2001, 47, 279–311. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Mei, Q.; Zhai, C. Investigating task performance of probabilistic topic models: An empirical study of PLSA and LDA. Inf. Retr. 2011, 14, 178–203. [Google Scholar] [CrossRef]
- Larsen, B.; Aone, C. Fast and Effective Text Mining Using Linear-time Document Clustering. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’99, San Diego, CA, USA, 15–18 August 1999; ACM: New York, NY, USA, 1999; pp. 16–22. [Google Scholar] [CrossRef] [Green Version]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Newton, MA, USA, 1979. [Google Scholar]
- Rand, W.M. Objective Criteria for the Evaluation of Clustering Methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Same Cluster | Different Cluster | |
|---|---|---|
| Similar Documents | True Positive (TP) | False Negative (FN) |
| Different Documents | False Positive (FP) | True Negative (TN) |
| Topic | Documents | Tokens |
|---|---|---|
| Business | 200 | 37,933 |
| Entertainment | 210 | 29,621 |
| Sports | 200 | 32,224 |
| Health | 200 | 55,934 |
| Total | 810 | 155,712 |
| Topic | Documents | Tokens |
|---|---|---|
| Business | 200 | 37,933 |
| Entertainment | 210 | 29,621 |
| Sports | 200 | 32,224 |
| Health | 200 | 55,934 |
| Weird | 200 | 32,365 |
| Total | 1010 | 188,077 |
| Categories | Topic 0 | Topic 1 | Topic 2 | Topic 3 | Topic 4 |
|---|---|---|---|---|---|
| Business | 85% | 0% | 0% | 2% | 12.5% |
| Entertainment | 3% | 93% | 1% | 3% | 0% |
| Sports | 3.5% | 5.5% | 90% | 1% | 0% |
| Health | 1% | 0% | 0% | 99% | 0% |
| Weird | 6% | 4.5% | 0.5% | 86.5% | 2.5% |
| Categories | Topic 0 | Topic 1 | Topic 2 | Topic 3 | Topic 4 |
|---|---|---|---|---|---|
| Business | 22% | 0% | 7.5% | 70.5% | 0% |
| Entertainment | 0% | 6% | 17% | 6% | 71% |
| Sports | 0.5% | 90% | 7% | 0.5% | 2% |
| Health | 0% | 0% | 99% | 1% | 0% |
| Weird | 2% | 0% | 97.5% | 0% | 0.5% |
| Categories | Topic 0 | Topic 1 | Topic 2 | Topic 3 | Topic 4 |
|---|---|---|---|---|---|
| Business | 1% | 2% | 96.5% | 0% | 0.5% |
| Entertainment | 96% | 3% | 0% | 1% | 0% |
| Sports | 6% | 0.5% | 2% | 91% | 0.5% |
| Health | 0% | 5% | 3% | 1% | 91% |
| Weird | 15% | 71% | 2% | 0.5% | 11.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mustafa, M.; Zeng, F.; Ghulam, H.; Muhammad Arslan, H. Urdu Documents Clustering with Unsupervised and Semi-Supervised Probabilistic Topic Modeling. Information 2020, 11, 518. https://doi.org/10.3390/info11110518
Mustafa M, Zeng F, Ghulam H, Muhammad Arslan H. Urdu Documents Clustering with Unsupervised and Semi-Supervised Probabilistic Topic Modeling. Information. 2020; 11(11):518. https://doi.org/10.3390/info11110518
Chicago/Turabian StyleMustafa, Mubashar, Feng Zeng, Hussain Ghulam, and Hafiz Muhammad Arslan. 2020. "Urdu Documents Clustering with Unsupervised and Semi-Supervised Probabilistic Topic Modeling" Information 11, no. 11: 518. https://doi.org/10.3390/info11110518
APA StyleMustafa, M., Zeng, F., Ghulam, H., & Muhammad Arslan, H. (2020). Urdu Documents Clustering with Unsupervised and Semi-Supervised Probabilistic Topic Modeling. Information, 11(11), 518. https://doi.org/10.3390/info11110518