1. Introduction
Natural language is a valuable and rich source of information for many applications. Still, natural language is discrete and sparse, and as such a challenging source of data. For text to be usable as input data, it first has to be transformed into a suitable representation, which is usually a vector of the text’s features, hence a vector of numbers. The vector representations of text can be constructed in many different ways, this paper provides a survey of the neural models that generate continuous and dense text representations.
The basic non-neural text representation methods, which preserve a very limited amount of information, are one-hot encoding and TFIDF (term frequency inverse document frequency) [
1]. One-hot encoding creates a Boolean vector of values for each word. The length of one-hot vectors is equal to the vocabulary size, and all the elements are coded with “0” except the word in focus, which is coded with “1”. Each dimension in that vector space corresponds to one word. Vectors from that space are used as inputs for machine learning. To represent larger units of text (multi-word units like phrases, sentences, or documents), one-hot vectors have a “1” for each of the words in the unit in focus (bag-of-words representation). TFIDF vectors extend Boolean values from one-hot vectors with frequencies, normalized by the inverse document frequencies.
This survey is focused on neural models that learn text representations as vectors in a continuous n-dimensional space [
2]. The learned n-dimensional vector space can be structured to capture semantics, syntax, knowledge, or other language properties. The process of representing text elements as continuous and dense vectors is called embedding (e.g., word embedding). The representations can be learned for any unit of text like subwords, words, phrases, sentences, and documents. The current challenge in neural text representation learning is to construct task-independent representations, hence representations that generalize well to multiple unrelated tasks [
3]. Therefore, in this work, the tasks the models are applied to (downstream tasks) are not put in the front, and the main focus is on representation properties and qualities. Still, researchers evaluate models on a variety of tasks, which we cross-reference in
Table A2.
Due to the nature of neural networks, when a model has learned to perform well at a task, a byproduct is a dense low dimensional representation that is formed in the hidden layers of the neural network. Compared to the traditional representation methods, neural models learn which text features to incorporate in representations. Moreover, the learned representations have a smaller dimensionality which makes them more efficient on downstream tasks. As is mentioned in the book [
4]: “generally, a good representation is one that makes a downstream learning task easier.” The neural representation learning can be treated as a pre-training step or language modeling step for one or multiple downstream tasks (e.g., machine translation [
5], sentiment analysis [
6], text generation [
3], question answering [
7], text summarization [
8], topic detection [
9], or any other natural language processing task. An important property of the pre-trained representations is faster portability between tasks, or a form of transfer learning, where representations learned for one task can be utilized as the pre-training step for a new task. The dense representation vectors in a continuous space can be readily used for simpler tasks like similarity assessment or as a substitute for the features used for machine learning [
10].
This research aims to systematically compare neural models that learn text representations, identify their advantages and drawbacks, and subsequently identify the promising directions for the construction of neural text representation models. More specifically, we aim to identify neural text representation research directions that are feasible for research teams with limited computational resources. To do so, we analyze 50 models published in research papers and at NLP (natural language processing) conferences in the last decade. Papers for the survey are selected following three major criteria. First, we consider papers with a reasonable number of citations. Second, we prefer models with novel ideas or with improvements in any aspect over the previous models. Third, we opt for task-independent (general) representation models. Task-independent representation models perform well on a variety of downstream tasks. Still, to ensure the integrity of this survey, we include some task-dependent models that have largely influenced the field. The representation models included are mainly limited to English texts, except for models trained on machine translation tasks.
Compared to other works reviewing deep learning models for NLP (e.g., [
11]), this survey focuses on text representation learning and, as such, reviews models from that perspective. Among similar surveys that analyzed neural network models for text representation are a survey of neural language models [
12], a survey of vector representation of meaning [
13], a survey of cross-lingual word embedding models [
14], and a comparability study of pre-trained language models [
15]. The authors in [
12] elaborate upon different architectures of the classic neural network language models and their improvements, but it lacks a deep survey and is focused on a narrower set of language models. The survey of vector representation of meaning in [
13] presents a comprehensive survey of the wide range of techniques for sense representation; however, it is focused on sense representation models exclusively. The survey of cross-lingual word embedding models in [
14] provides a comprehensive typology of models; however, it is framed with cross-lingual word embedding models. The work about language models in [
15] proposes starting points for defining reporting standards which are applied when it comes to comparing pre-trained language models (the model architecture, number of parameters, hyperparameter tuning method and tuning time, experimental time, computational resources, training time, lexical resource information and availability, the benchmark performance on un-tuned and tuned single model); however, its survey is focused on several large pre-trained language models.
Our survey goes a step further, categorizing and summarizing the most prominent models created in the last decade. Additionally, we did not limit the scope to a specific architecture, task, or the representation level, instead, we opted for multi-categorization indicating the subtle differences among models, emphasizing their advantages and drawbacks.
To systematically compare the representation models, we used five criteria: (1) representation level (the level of linguistic units for which representations are being learned); (2) input level (the granularity of data on input); (3) model type (the general strategy for representation learning); (4) model architecture (neural network architecture), and (5) model supervision (an indication of the need for labeled training data). Additionally, we review standard datasets and tasks used for the evaluation of neural representation models. The generality of the neural representation model is measured by its capability to perform well on a variety of tasks (e.g., word/sentence+ similarity, word analogy, sentiment classification, paraphrase detection, machine translation, natural language inference, subjectivity, question answering and classification, text retrieval, coreference resolution, reading comprehension, and summarization).
The rest of the paper is organized as follows.
Section 2 covers datasets used for the evaluation in the covered papers.
Section 3 presents the evaluation tasks used in the described models.
Section 4 describes the categorizations that we use to analyze representation models (representation level, input level, model type, model architecture, model supervision).
Section 5 through to
Section 9 cover representation models.
Section 10 is a discussion, and
Section 11 concludes the paper.
3. Evaluation Tasks
The quality of the learned representation space has to be evaluated. The evaluations are performed indirectly on different downstream tasks, and each task can provide one perspective about the representation space quality.
The more tasks a model is evaluated on, the more accurate the evaluation of its generality is. We notice a trend in the number of tasks that the neural text representation models are evaluated on (
Table A2), throughout recent years, we can see a growth in the number of tasks each of the models uses for its evaluation. In addition, this is an indication of shifting toward learning more general representation models. In the rest of this section, we cross-reference tasks with datasets used for evaluation and provide a brief description of the tasks. The word/sentence+ similarity task is widely used but is too simple to be able to test better representations, as even shallow text representations perform reasonably well on such tasks. In this task, a model has to quantify the similarity of two words or sentences. The datasets used to evaluate models on the similarity task are WordSim-353, SICK, MRPC, and STS. The most used evaluation measures are Spearman and sometimes Pearson correlation.
The word analogy task can be used as well and can tell us the representation space structure quality. This task evaluates the ability of a model to recognize analogy relations. The datasets used for evaluation on this task are SSWR and MSR. The prevalent evaluation measure for the word analogy task is accuracy.
The sentiment classification task can provide more information about the sentence representation quality. It is used to evaluate the ability of a model to recognize sentiments in text. The datasets used for this task are SST, IMDB, MR, CR, MPQA, and SemEval’17. The most used evaluation measure for the sentiment classification task is accuracy.
The paraphrase detection task is similar to the word/sentence+ similarity task. Models trained on this task learn to recognize if two texts are semantically equivalent. The dataset used for evaluation on this task is MRPC. The most used evaluation measure for the paraphrase detection task is accuracy.
The machine translation task is able to inform us about the sentence encoding quality. In this task, models learn to translate text from the source language into text in the target language. WMT is frequently used as a dataset for machine translation evaluation. The usual evaluation measure for the translation task is the BLEU score, utilized in the majority of machine translation downstream tasks.
The natural language inference task is able of high-quality evaluation as well. It evaluates the ability of a model to recognize textual entailment between two sentences. The datasets used to evaluate models on this task are SICK, SNLI, and MultiNLI. The most used evaluation measure for the inference task is accuracy.
The subjectivity task detects if a text is subjective or objective. The dataset used for evaluation is SUBJ. The most used evaluation measure for the subjectivity task is accuracy.
Representations that perform well at question answering tasks preserve the knowledge and understanding of text semantics. In this task, models learn to answer questions. Question classification is a similar and yet simpler task. The dataset used for evaluation in the question answering task is SQuAD, and the dataset used for question classification is TREC.The most used evaluation measure for the question answering task is the F1 score.
The text retrieval task in its core functions similarly to the word/sentence+ similarity task. Text retrieval models have to retrieve the most relevant text to the query text from the collection of texts. The dataset used for evaluation is TREC. The most used evaluation measure for the text retrieval task is accuracy.
In addition to the frequently engaged downstream tasks above, coreference resolution, reading comprehension, and summarization are occasionally utilized. Coreference resolution is a task of linking related linguistic units referring to the same entity in a text (i.e., linking pronouns to nouns). The reading comprehension task is almost equivalent to the question answering task. The dataset used for evaluation is RACE. Summarization is the task of creating short versions of a text while preserving the most important meaning of the longer text. Additionally, several studies engage perplexity as the standard measure for the evaluation of language models [
39].
Some of the models are evaluated on tasks that test their ability to recognize polysemy or anaphora. Models that are able to recognize polysemy are the model by Huang et al. [
40], ELMo [
41], the model by Akbik et al. [
42], and CDWE [
43]. Models that are able to work with anaphora (evaluated on the Winograd schema challenge) are GPT [
44] and XLNet [
45]. Some of the papers that evaluated the models used other evaluation tasks as well. In
Table A2, those tasks are categorized as “Classification tasks” and “Other”.
4. Model Categorization
To compare and contrast the models, we used five categorization criteria: (1) the representation level shows the level of linguistic units for which representations are learned; (2) the input level shows the granularity of data a model receives upon input; (3) the model type elaborates the strategy for representation learning; (4) the model architecture covers the main neural network architecture of the model; (5) the model supervision shows how much labeling is needed in training data. Each of these categorizations is described in the rest of this section. For recursive models, we used one more categorization, the parsing tree source (which we describe in
Section 7).
5. Shallow Models
Shallow models use shallow architectures (usually one hidden layer), which can learn simple representations (Word2Vec architecture is shown in
Figure 1). In this category, we include two non-neural models that are frequently used for the same purpose as the rest of the models and are shown to be comparable [
56,
57]. As a result of their simplicity, shallow models are fast to train and generalize well. Learned shallow representations can be used as input for deeper models that can learn better representations. While performing very well on simple tasks (e.g., word similarity), shallow models do not perform well on complex tasks (tasks that require a deeper understanding, e.g., question answering, summarization). To generate a phrase, sentence, or document representation, shallow representations are combined, resulting in a bag-of-words representation. The most prominent shallow models are systematized in
Table 1 according to the input and representation level. The majority of shallow models for text representation learn word-level representations. Usually, they are autoencoding models learned by predicting the missing information upon input.
Language models, and more specifically shallow models described in this section, follow the distributional hypothesis, which states that the words with similar meanings occur in similar contexts [
58,
59]. To learn representations that reflect the distributional hypothesis, shallow models are trained to predict neighboring words (i.e., context) around the target word and vice versa, to predict the target word from neighboring words. Shallow models mostly contain only one hidden layer in which text representations are learned. The representation being learned dictates how the input vector transforms into the output vector. The input vector is a one-hot representation of the target word or the neighboring words. In contrast, the output vector is a probability distribution that describes which words are most probably the target or the neighboring words. In the learned vector space, representations are closer together for similar words. Relationships between the words are preserved (i.e., king and man are positioned in the same way as queen and woman, and the positions of countries and their capitals preserve meaningful information).
Table 1.
The categorization of shallow models by input and representation level. All listed models are unsupervised.
| Model | Input | Representation |
|---|
| Huang et al. [40] | word | word |
| Word2Vec [22,47] | word | word |
| Deps [60] | word | word |
| GloVe [61] | word | word |
| Doc2Vec [62] | word | sentence+ |
| FastText [49] | n-grams | word |
The unsupervised model presented by Huang et al. [
40] uses both local and global context via a joint training objective. It learns multiple representations per word, which is effective for homonyms and polysemous words. The meaning of a word can be ambiguous given only local context. By using a global context, the meaning of a word can be disambiguated more precisely. On the task of measuring similarity and relatedness, it achieves a Spearman correlation of 0.713 on the WordSim-353 dataset, which outperforms C&W (convolutional model described in
Section 8) by 0.16.
Word2Vec [
22,
47] popularized shallow word representation using neural networks. Word2Vec has two separate autoencoding models: continuous bag-of-words (CBOW) and skip-gram. Both learn word representations through unsupervised learning. The CBOW model scans over the text with a context window and learns to predict the target word. The context window contains
n preceding and
n succeeding words around the target word. The skip-gram model conversely predicts the words in the context from the target word. Word2Vec neural network has only one hidden layer, and word representations are extracted from that layer. The accuracies for the skip-gram model on the SSWR dataset for semantics and syntax are 50% and 55.9%, respectively, outperforming the model by Huang et al. by 36.7% and 44.3%. The accuracy on the MSR dataset for the skip-gram model is 56%.
Whereas Word2Vec uses local neighboring words as context, its extension Deps [
60] uses neighboring words in dependency parse trees to learn word representations. Deps generalizes skip-gram to include arbitrary contexts and uses dependency-based contexts derived from parse trees.
GloVe [
61] directly captures global corpus statistics through unsupervised learning. It is inspired by neural models but is not a neural model itself. GloVe combines global matrix factorization and local context window methods through a bilinear regression model. By doing so, it trains by using the co-occurrence matrix and learns word representations in a way that it can predict co-occurrence probability ratios. An example was given in [
61]. Let
and
, if
, we expect the ratio
to be large (
is probability of words x and y occurring together). If
, the ratio should be small. For words that are related to both
and
, or to neither, the ratio should be closer to 1. This is used instead of raw probabilities because ratios distinguish relevant words from irrelevant words better. It is shown, that mathematically GloVe is similar to Word2Vec [
56,
57]. GloVe slightly outperforms Word2Vec on multiple tasks. On the SSWR dataset, GloVe has 75% total accuracy (81.9% semantics and 69.3% syntax), which is an improvement of 9.4% over Word2Vec. GloVe is evaluated on five word similarity tasks (including WordSim-353 where it achieves a 0.759 Spearman correlation), and in each evaluation, GloVe outperforms Word2Vec.
The shallow models above can learn representations for words. Doc2Vec [
62] is an extension of Word2Vec that can learn representations for documents (or parts of texts). While predicting context words of a target word, Doc2Vec receives the target word and the document ID upon input. Through learning, as it learns useful relations between documents and words, it learns not only representations for words but documents as well. The accuracy on the SST dataset is 87.8% for binary classification, and 48.7% for fine-grained classification, outperforming the recursive model by Socher et al. [
24] by 2.4% and 3%, respectively. Accuracy on the IMDB dataset is 92.58%.
All models described above use word-level input, but subword-level input can be beneficial. FastText [
49] is an unsupervised non-neural model inspired by neural models. Similarly to Word2Vec, it has two separate models, CBOW and skip-gram. It learns representations for character n-grams, and each word is represented as a bag-of-character n-grams. Previous models were limited to assigning a distinct vector to each word. Representations on the subword level are shown to perform better for morphologically rich languages and rare words. On the WordSim-353 dataset, FastText has a Spearman correlation of 0.71 (similar to Word2Vec’s 0.72). On the SSWR dataset, it achieves 77.8% semantic and 74.9% syntactic accuracy, performing on the semantic task similarly as Word2Vec and outperforming it on the syntactic task by 4.8%.
6. Recurrent Models
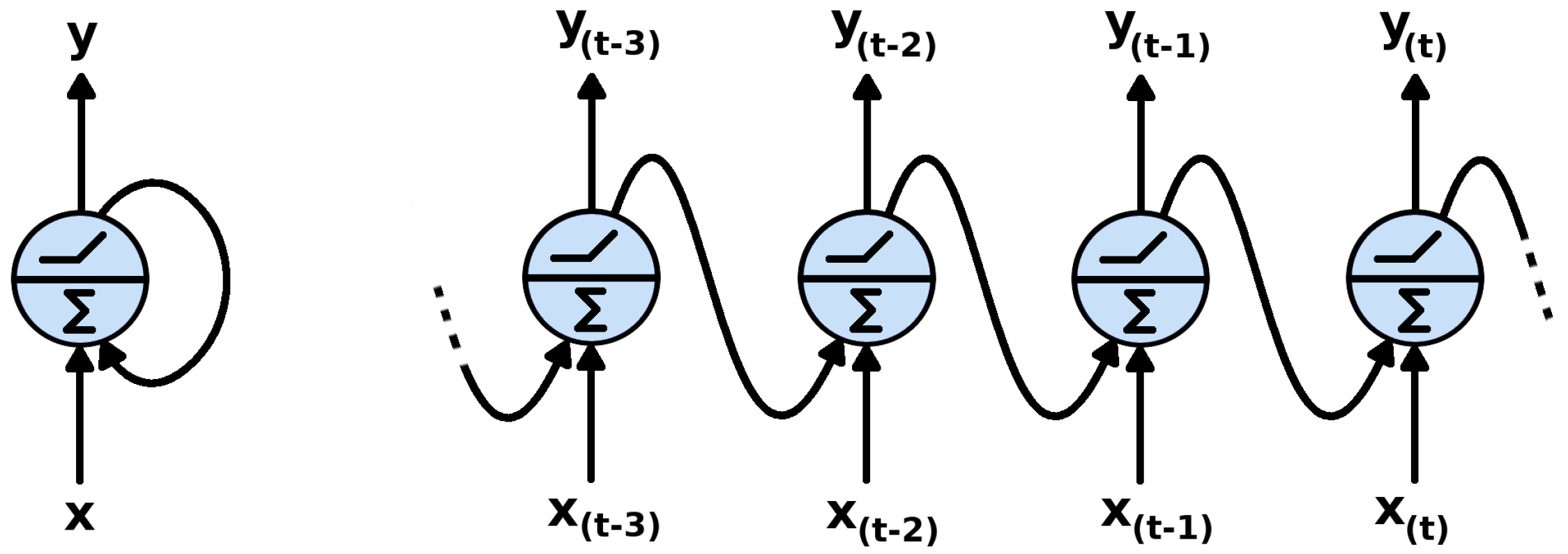
Models like Word2Vec are insensitive to word order, they only capture the relations between words—if a word is in the context of another word. The ordering of words in a text is meaningful, since different orderings of words can denote different meanings. RNNs (recurrent neural networks) process input as a sequence and learn ordered representations from a text, hence they are well suited for learning representations of longer linguistic units like phrases, sentences, paragraphs, or documents. While tokens from the input sequence are processed, the history of all the previous tokens is preserved as a state in the neurons (
Figure 2). The most influential RNN models are listed in
Table 2 according to their input level, representation level, and model supervision. The majority of RNNs for text representation are autoregressive models. Output tokens are generated by taking previous output tokens as an additional input (together with the representation of the encoded sequence, currently being learned).
In shallow feedforward models, the hidden layer and ultimately the output is affected only by the current input. In recurrent models, the hidden layer (or layers) and the output are affected not only by the current input but also by the previous inputs. That is achieved by using recurrence, where the recurrent layers propagate information not only to the next layer but back to their input as well. To train neural networks, gradients are calculated and used to update parameters in a direction that depends on the loss function. With longer texts, RNNs have a vanishing (and exploding) gradient problem as the gradient is calculated through a long chain of recurrence. That problem is reduced by LSTM (long short term memory unit) and its variants like GRU (gated recurrent unit), which have gates that learn what information is important and, as such, has to be propagated more strongly. LSTM’s architecture is shown in
Figure 3. It has a cell state (horizontal line on the top), which is used for memory. Gates below control information flow by selectively forgetting old and memorizing new information relevant for the current task.
A supervised encoder–decoder model introduced by Cho et al. [
63] uses two RNNs. One RNN encodes a sequence of symbols into a representation vector, and the other decodes the representation into another sequence of symbols. The sequence of symbols can be a phrase, part of a sentence, a sentence, or a longer linguistic unit. The model is trained on a machine translation task. The model achieves a 34.54 BLEU score on the English–French translation task from the WMT’14 dataset, which is an improvement of 1.24 points over the baseline method (Moses).
With the addition of LSTM units, the Seq2Seq [
5] model improves performance on longer sequences over basic RNN models. It is learned in a supervised way on a machine translation task. Seq2Seq uses LSTM units in recurrent layers. This model can produce representations for phrases and sentences. Seq2Seq scores 34.81 BLEU on the English–French translation task from the WMT’14 dataset, outperforming the recurrent model by Bahdanau et al. [
70] by 6.36 points.
Whereas most recurrent models learn text representations by sequentially predicting words (autoregressive models), Skip-Thoughts [
64] is an unsupervised encoder–decoder model that learns to reconstruct the surrounding sentences of an encoded sentence, and in that aspect, it is similar to other autoencoding models. It uses encoder with GRU activations and an RNN decoder with a conditional GRU. Skip-Thoughts learns representations for sentences and performs just as well as the LSTM approach. On the SICK semantic relatedness subtask, Skip-Thoughts performs with the Pearson correlation 0.8655 and the Spearman correlation 0.7995, which is similar to Tree-LSTM (recursive model described in
Section 7). Accuracy on the MRPC dataset is 75.8% and the F1 score is 83.
RCNN [
65] (recurrent convolutional neural network) is a supervised bidirectional RNN (BiRNN) with a pooling layer after the BiRNN layer. Sentence representations are learned through the BiRNN, which scans over texts upon input in both directions (forward and backward), whereas normal RNNs scan texts only in the forward direction. The pooling layer learns to select the most important words for a text classification task. Fine-grained classification accuracy on the SST dataset is 47.21%, similar to the accuracy achieved by Doc2Vec.
A simple variant of the Skip-Thoughts model FastSent [
66] is an unsupervised model with GRUs. FastSent receives a bag-of-words representation of a sentence upon input and predicts adjacent sentences, which are also represented as bag-of-words representations. FastSent outperforms Skip-Thoughts on unsupervised tasks: the Spearman correlation for the SICK dataset is 0.61, which is an improvement of 0.04 over Skip-Thoughts, whereas for STS tasks the Spearman correlation is 0.63, which is an improvement of 0.36 over Skip-Thoughts. FastSent under-performs Skip-Thoughts on six supervised sentence classification tasks (on MRPC, MR, CR, SUBJ, MPQA, and TREC dataset). Overall, FastSent has an average accuracy of 77.92% on the supervised tasks, under-performing Skip-Thoughts by 5.83%.
CoVe [
67] (Context Vectors) is a supervised bidirectional LSTM (BiLSTM) encoder with an attentive LSTM decoder trained for machine translation. Word representations are extracted from the BiLSTM encoder. The attentive LSTM decoder first uses the LSTM to produce a hidden state, after which the attention mechanism computes the relevance between each encoding time-step and the current state. CoVe is evaluated on seven classification tasks (on SST-2, SST-5, IMDB, TREC-6, TREC-50, SNLI, and SQuAD dataset). Overall, its average accuracy is 84.8%, which outperforms GloVe by 1.8% and Skip-Thoughts by 2.2%.
Models mentioned previously produced one vector for each subword, word, or sentence, which cannot account for polysemy (multiple meanings of the same word). ELMo [
41] (Embeddings from Language Models) is an unsupervised model that uses BiLSTM and can learn polysemy. ELMo’s word representations are learned functions of the internal states of the BiLSTM. In different contexts, the same word has different representation vectors, which can account for different word meanings. ELMo achieves 54.7% fine-grained classification accuracy on the SST dataset, outperforming CoVe by 1.8%.
The model introduced by Akbik et al. [
42] is an unsupervised character-level language model. The word representations are extracted from BiLSTM hidden states. As word representations are contextualized by their surrounding text, the same word can have different meanings depending on its context, which can model polysemy. Word representations are concatenations of hidden states of the forward pass through a sentence until the last character in the word, and the backward pass through a sentence until the first character in the word. This model has 93.09% accuracy on the CoNLL’03 dataset, outperforming ELMo by 0.87%.
A semi-supervised model introduced by Subramanian et al. [
68] uses bidirectional GRU (BiGRU) for sentence representation multi-task learning. The tasks that the model is trained on are skip-thought, machine translation, constituency parsing, and natural language inference. The authors demonstrate that multi-task learning leads to consistent improvements over previous single-task methods (some of which are FastSent, Skip-Thoughts, and CNN-LSTM, which is described in
Section 8).
LASER [
69] (Language-Agnostic SEntence Representations) learns joint multilingual sentence representations for 93 languages through a supervised machine translation task. The learned representations are general with respect to the input language and the task. It uses the BiLSTM encoder to generate a sentence representation, and the LSTM decoder to generate a sentence in a target language. The encoder receives no information about what the input language is, due to which it learns language-independent representations. The model is trained by translating all 91 languages to both English and Spanish languages. On the XNLI (cross-lingual natural language inference) dataset [
71], with 70.19% average accuracy on 15 languages, this model archives similar results as BERT (attention model described in
Section 9).
7. Recursive Models
Recurrent models learn representations with ordered information; however, recursive neural networks go one step further and learn deeply structured information like trees. Recursive neural networks’ (RecNN) process inputs in a recursive fashion through a tree structure (example given in
Figure 4). Each node in a tree for a word, phrase, sentence, or a larger unit of text is associated with a respective representation. The most influential RecNN models are shown in
Table 3 with their model supervision, and tree source (given, learned, or latent). Most of the RecNNs for text representation are autoencoding or classification models. The representation for each node can be learned either by an autoencoding method similar to the shallow models or through a classification task.
Recursive neural networks are generalized recurrent neural networks. Whereas recurrent neural networks read input in a linear chain, recursive neural networks read input in any hierarchical structure. Representations are merged recursively throughout the tree structure, where merging combines two or more representations from the lower level into one higher-level representation. Hence, learning of the recursive neural representations enables combining representations of more granular linguistic units into larger linguistic units (e.g., from characters to sentences, or from words to documents). The merging process is repeated recursively until the root node is reached. The root node represents the whole input sequence (
Figure 4) and leaf nodes are input tokens. The tree structure can be given upon input, learned from labeled texts (texts paired with their parse trees), or implicitly generated by a neural network with no supervision (latent trees).
RAE [
72] (Recursive AutoEncoders) introduced an architecture based on recursive autoencoders for sentence-level prediction of sentiment label polarity. An autoencoder is a type of neural network that learns representations of input data in an unsupervised manner. The encoder part of the network encodes the input into a dense representation, while the decoder part of the network decodes that representation into output (that should be as close as possible to the input). While RAE can learn text representation through supervised learning of sentiment distribution, it can learn text representation through unsupervised learning as well. An important RAE feature is the ability to learn latent parsing trees, meaning that they are not learned or given upon input, but generated by concatenating neighboring pairs of words or phrases and combining the ones with the lowest reconstruction error (in the autoencoder) into parent nodes. On sentiment classification, RAE achieves an accuracy of 77.7% on the MR dataset and 86.4% on the MPQA opinion dataset, which is a slight improvement over Tree-CRF [
79].
MV-RNN [
73] (Matrix-Vector recursive neural network) learns vector and matrix representations for every node in the tree (phrases and sentences). The vector captures the meaning of the node, whereas the matrix captures how it changes the meaning of neighboring words or phrases. Supervised training for each of the tasks is done by adding a softmax classifier on top of each parent node. The model receives parse trees from a parser. It achieves 79% accuracy on the MR dataset, which is an 1.3% improvement over RAE.
Whereas other RecNNs process inputs as trees, AdaSent [
74] process inputs in a hierarchical fashion (pyramid structure) which does not require parse trees upon input. The pyramid structure forms a hierarchy of representations from words to sentences. The model is trained on supervised classification tasks. Classification uses the hierarchy of representations as input. The hierarchy of representations is first summed on each level of the hierarchy, and then a gating network calculates a weight for each of the levels. AdaSent has 83.1% accuracy on the MR dataset, outperforming RAE by 5.4%. Its accuracy on the MPQA opinion dataset is 93.3%, outperforming RAE by 6.9%. It outperforms MV-RNN as well on the MR dataset by 6.9% with a 93.3% accuracy.
Tree-LSTM [
75] introduced a generalization of LSTM to tree-structured network topologies. The model is trained on a supervised sentiment task and it requires parse trees upon input. LSTM architectures can process only sequential information, Tree-LSTM extends LSTM in a way which can process structured information. Tree-LSTM performs better than an RecNN with basic RNNs because of the same reasons LSTM outperforms RNN. It has 51% fine-grained classification accuracy on the SST dataset, outperforming RAE, and MV-RNN by 7.8% and 6.6%, respectively.
RL-SPINN [
76] (Reinforcement Learning SPINN) uses reinforcement learning to learn sentence representations. RL-SPINN’s architecture is based on the SPINN model (Stack-augmented Parser-Interpreter Neural Network) [
80]. Parse trees are latent, meaning that the tree structures are not learned from labeled data or given upon input, but are unsupervisedly optimized for the downstream task. RL-SPINN performs similarly as Tree-LSTM and DCNN (the convolutional model described in a later section) on the SST dataset with an 86.5% accuracy for binary classification. It has a 0.359 mean squared error on the SICK dataset, under-performing Tree-LSTM by 0.067.
ST-Gumbel [
77] (Straight-Through Gumbel-softmax estimator) is a Tree-LSTM modification as well. ST-Gumbel uses latent trees that are computed with a composition query vector that measures the validity of a composition. Text representation is learned through unsupervised training. On the SST dataset, it achieves 53.7% accuracy for fine-grained classification, and 90.7% accuracy for binary classification, outperforming Tree-LSTM by 2.7% in both fine-grained and binary classification.
DIORA [
78] (Deep Inside–Outside Recursive Autoencoders) is an unsupervised model that learns to predict each word in a sentence while being conditioned on the rest of the sentence. It considers all possible trees over the input sentence. The CYK (Cocke–Younger–Kasami) parsing algorithm extracts the highest-scoring parse tree (latent trees). The architecture consists of recursive autoencoders. The training is done through inside–outside passes, where the inside representations of each node are encoded by using the children of the nodes, and outside representations of each node are encoded using only the context of the node subtree. On WSJ dataset, DIORA has a 55.7 F1 score, which is an increase of 32.9 with respect to ST-Gumbel, and an increase of 42.5 with respect to RL-SPINN.
8. Convolutional Models
Recurrent and recursive neural networks are a good fit for textual modality (as they are appropriate for sequential data), whereas convolutional neural networks (CNN) are originally used for 2-D data, and as such had to be modified to fit textual modality. CNNs proved successful with visual data (images and videos); however, they can also be used for text representation learning (the architecture is shown in
Figure 5). CNNs by their nature learn to abstract input data through multiple convolutional levels and detect specific patterns on each level (e.g., textures or borders of objects in images, syllables, or word n-grams in text). The most representative CNN models used for learning text representations are shown in
Table 4 with their input level, representation level, and model supervision. CNNs for text representation were in the beginning mostly classification models, but later CNN models were combined with other architectures, typically with autoencoding or autoregressive models.
Convolutional models for images learn to recognize patterns from the lowest level (e.g., edges, corners) to the highest level (e.g., cat, dog, house). Similarly, convolutional models for text learn patterns like syllables, syntax, and phrases. The notable difference between convolutions for images and text is the dimensionality of the convolutions. Convolutions for images are two-dimensional, and convolutions for text are mostly one-dimensional. In
Figure 5, input is connected to the convolution layer. The convolution layer in this example has four filters. Each filter has a kernel (a matrix of weights) trained to detect patterns that are of importance to the task at hand. Kernel slides over the values from the previous layer (in this example, input values) and outputs an activation that corresponds to how much that region of image or text fits the pattern. Next, the convolution layer is connected to the fully connected layer. Whereas recurrent and recursive models can easily read inputs of undefined length, convolutional models need pooling layers to process inputs of different sizes. The pooling layer lowers the previous layer’s dimensionality by forwarding (pooling) the maximum or average of each region.
The model introduced by C&W [
81] (Collobert and Weston) uses a single convolutional neural network architecture that, given a sentence upon input, outputs part-of-speech tags, chunks, named entity tags, semantic roles, semantically similar words, and the likelihood that the sentence makes sense. All of these tasks are trained jointly, resulting in an implicitly trained language model. While the language model is learned unsupervisedly, downstream tasks are learned supervisedly. During learning, all the tasks share weights, resulting in better language representation. Note that individual word representations can be extracted from the trained network.
DCNN [
82] (dynamic convolutional neural network) is a convolutional model supervised for each downstream task separately. The architecture consists of multiple one-dimensional convolutional layers and dynamic k-max pooling layers, which induce a latent tree over the input sentence. The last layer, which is fully connected, contains the representation of the input sentence. This model achieves an 48.5% and 86.8% accuracy for fine-grained and binary classification on the SST dataset, outperforming the baseline method (Naive Bayes) by 7.5% and 5%, respectively. On the SST dataset, its performance is similar to the recursive model RL-SPINN described in
Section 7.
CNNs are a good fit for character-level input, which is why CharCNN [
48] (character-level convolutional neural network) is an unsupervised model that relies only on character-level inputs to learn word representations. In CharCNN architecture, single-layer character-level CNN reads the input, and LSTM generates the output. Each of the filters in the CNN detects a single character n-gram. The perplexity of this model on the English Penn Treebank test set [
34] is 78.9, which is similar to the perplexity of the recurrent model by Zaremba et al. [
85] that contains a double number of parameters.
Similarly to CharCNN, ByteNet [
83] relies only on character-level inputs. It is unsupervised for the language modeling task and supervised for the machine translation task. ByteNet implements two mechanisms: the first mechanism allows the preservation of the temporal resolution of the sequences, and the second mechanism allows the network to process source and target sequences of different lengths. The model runs in a time that is linear to the length of the sequence. On the WMT’14 and WMT’15 dataset, it achieves a 23.75 and 26.26 BLEU score, respectively, outperforming the recurrent model by Chung et al. [
86] by 2.42 and 2.81 points, respectively.
CNN-LSTM [
84] is an unsupervised encoder–decoder architecture with a CNN encoder and LSTM decoder. It has two modes of training: autoencoder and future predictor. The autoencoder reconstructs the input sentence, whereas the future predictor predicts the rest of the sentence. The average accuracy for five-sentence classification tasks (on MR, CR, SUBJ, MPQA, and TREC dataset) is 87.1%, which is an improvement of 8% over FastSent.
By using deconvolution (transposed convolution) CDWE [
43] (Convolution–Deconvolution Word Embedding) can learn multiple vectors for each word. CDWE is supervised for each downstream task. It generates multiple prototypes in the deconvolution layer for each word, which can model polysemy. After that, according to the context, a proper prototype for a word is selected. The average accuracy for three sentence classification tasks (on TREC, AG News, and MR dataset) is 90.9%, which is an improvement of 13% over CharCNN.
9. Attention Models
The architectures from the previous sections (shallow, recurrent, recursive, and convolutional) are either very general or are originally developed for a different modality of input data. The neural attention mechanism was created to capture long-range dependencies and was inspired by how humans read and understand longer texts [
87]. Long-range dependencies exceed the dependencies captured within the limited boundaries of context windows as used in shallow models. RNNs are better at capturing long-range dependencies but are not as good as attention models since they are focused equally on every word in the input. Conversely, neural networks with attention can focus on parts of a text that are more important for a current task, and thus perform better with long texts (an example is shown in
Figure 6). The most influential attention models are shown in
Table 5 with their input level and model supervision. As attention mechanisms can be implemented in a wide range of architectures, the models using them can be autoencoding, autoregressive, or classification models. Models that greatly gain upon the attention mechanism (e.g., Transformer, which is described later) are mostly autoencoding or autoregressive models.
Attention mechanism learns which parts of the input vector are important for each part of the output vector (e.g., while translating a sentence from one language to another, each output word depends more on some parts of the input than the other parts, so it makes sense to pay more attention to those parts when deciding what the next word in the output is). Self-attention is similar, and it learns dependency as well, but between words in the input rather than between the input and output (e.g., when predicting the next word of the sentence “I am eating a green”, it makes sense to pay more attention to words “eating” and “green” to predict the next word “apple”). The attention mechanism has multiple heads, which are similar to filters in convolutions. Each head learns to pay attention in different ways. One head can learn to attend to words that help decide the tense of the next word, whereas another head can learn to attend to entity names.
HAN [
88] (Hierarchical Attention Network) is a supervised hierarchical attention network for a document classification task. HAN architecture is based on BiGRUs and attention mechanisms on the word and sentence level. First HAN learns sentence representations and then aggregates those representations into a document representation. The attention mechanism enables it to attend to different words when building sentence representations, and to different sentences when building document representations. On the IMDB dataset, HAN achieves 49.4% accuracy, outperforming Doc2Vec by 15.3%.
Authors Kim et al. [
89] introduce structured attention networks (a generalization of the basic attention procedure), which can attend to partial segments or subtrees while learning representations. This approach does not consider non-projective dependency structures and its inside–outside algorithm is difficult to parallelize. To overcome the parallelization problem, Liu et al. [
94] implicitly consider non-projective dependency trees and make each step of the learning process differentiable. Evaluated on the SNLI dataset, this model achieves 86.5% accuracy, which outperforms the recursive model SPINN [
80] by 3.3%.
The supervised model introduced by Lin et al. [
90] instead of a vector to represent text uses a 2-D matrix. Each row in that matrix representation is attending to a different part of the sentence. The model has two parts, the first part is a BiLSTM, and the second part is a self-attention mechanism. Each LSTM hidden state provides only a short-term context information around each word, whereas self-attention captures longer-range dependencies by summing the weighted LSTM hidden states. Evaluated on the SNLI dataset, this model achieves 84.4% accuracy slightly under-performing the model by Kim et al.
Most of the sequence translation models use recurrent or convolutional neural networks with an encoder and a decoder. Some also connect the encoder and decoder through an attention mechanism. Transformer [
51] is a sequence translation model that is used by many models created subsequently. Transformer is a neural network architecture based exclusively on attention mechanisms, dispensing recurrent or convolutional layers. Self-attention mechanisms in Transformer show the ability to correctly resolve anaphora. The goal of some of the convolutional neural network models is to reduce sequential computation by relating signals between two positions in a sequence. Hence, in CNN models the number of computations grows linearly or logarithmically with the distance between those positions. In Transformer architecture, the number of computations is constant, which makes it easier to learn dependencies between distant positions. On the WMT’14 dataset (English–German translation task), Transformer achieves a 28.4 BLEU score, outperforming ByteNet by 4.65 points.
Similarly to Transformer, DiSAN [
91] (Directional Self-Attention Network) and ReSAN [
93] (Reinforced Self-Attention Network) are based only on attention mechanisms without any RNN or CNN structure. DiSAN is composed of a directional self-attention, followed by a multi-dimensional attention that creates a vector representation. It achieves 85.62% accuracy on the SNLI dataset. It has a 90.8% average accuracy on four-sentence classification datasets (on CR, MPQA, SUBJ, and TREC dataset), outperforming Skip-Thoughts by 2.2%. ReSAN integrates both soft and hard attention into one model, outperforming DiSAN on the SNLI dataset by 0.7%. On the SICK dataset it achieves a Spearman correlation of 0.8163, close to the DiSAN’s correlation of 0.8139. Star-Transformer [
96] is a lightweight alternative to Transformer which reduces model complexity by sparsification. Sparsification replaces the fully connected structure with a star-shaped structure, which reduces the number of connections from
to
. On the SNLI dataset, it performs with 86% accuracy, outperforming Transformer by 3.8%. Whereas Transformer takes 49.31 ms on test time, Star-Transformer takes 10.94 ms.
BERT [
54] (Bidirectional Encoder Representations from Transformers) is a deep bidirectional Transformer. Deep bidirectional means that it is conditioned on every word in the left and right contexts at the same time. It does so by masking some percentage of the input tokens at random and then predicts those masked tokens. BERT is an unsupervised model that learns sentence representations. It achieves an 82.1% average accuracy on a subset of GLUE datasets, which is a 7% improvement over GPT (a model mentioned below). ALBERT [
100] (A Lite BERT) optimizes BERT by lowering memory consumption and increasing the training speed. Evaluated on five datasets (on SquAD1.1, SQuAD2.0, MultiNLI, SST-2, and RACE dataset), ALBERT performs with an 88.7% average accuracy, outperforming BERT by 3.5%. SpanBERT [
101] extends BERT by masking random spans (sections of text) whereas BERT is masking random tokens, and by training the representations to predict the entire content of the masked span. It has an 82.8% average accuracy on a subset of GLUE datasets, which is an improvement of 2.4% over BERT.
GPT [
44] (Generative pre-trained Transformer) is a semi-supervised model based on Transformer. Its training is unsupervised for pre-training of the language model and supervised for fine-tuning to a downstream task. To avoid interventions into the architecture for each of the downstream tasks, they convert structured inputs into an ordered sequence that GPT can process. Largely following GPT architecture, GPT-2 [
3] learns byte sequence representations through unsupervised training. The main task of this model is language modeling. GPT-2 performs well with anaphora. It is the state-of-the-art at the time of the publishing of the GPT-2 paper, outperforming other models in seven out of eight tested language modeling datasets.
Authors in XLM [
95] (cross-lingual Language Model) introduced two methods to learn cross-lingual language models based on Transformer. One method is supervised and uses monolingual data, the other method is unsupervised and uses parallel texts in each of the languages. XLM has a 0.69 Pearson correlation on the SemEval’17 dataset, outperforming the model by Conneau et al. [
103] by 0.04.
Standard Transformer learns short dependencies, and context becomes fragmented because of the segmentation of input contexts while training. Transformer-XL [
97] is based on Transformer architecture with an added segment-level recurrence mechanism. Whereas the basic Transformer can learn dependencies of length only equal to the segment length, Transformer-XL can learn long-range dependencies by using its recurrence mechanism. It can learn dependencies that are 80% longer than dependencies in RNNs and 450% longer than dependencies in basic Transformers. Transformer-XL also solves the problem of context fragmentation, which appears in Transformer because of its segmentation. Similarly to Transformer-XL, Bi-BloSAN [
92] (Bi-directional Block Self-Attention Network) captures long-range dependency. It does so with a segment-level self-attention mechanism. When evaluated on datasets CR, MPQA, SUBJ, TREC, and SST, Bi-BloSAN performs similarly to DiSAN.
MASS [
98] (MAsked Sequence to Sequence pre-training) is a semi-supervised model (unsupervised pre-training and supervised fine-tuning to a specific task) based on Transformer. The encoder receives a sentence with a randomly masked fragment, while the decoder predicts that masked fragment. MASS is a generalization of GPT and BERT. It has a hyperparameter that defines the length of the masked fragment, which when set to 1 makes MASS equivalent to BERT, and when set to the number of tokens in a sentence makes MASS equivalent to GPT. For the machine translation task evaluated on NewsTest’14 and NewsTest’16 from the WMT dataset, MASS scores a 34 average BLEU score, which is an improvement of 1.85 points over XLM.
A modification of BERT, SBERT [
99] (Sentence-BERT) is a supervised model trained on pairs of sentences. SBERT uses Siamese and triplet network structures. The Siamese structure consists of two BERT networks with tied weights, which are then fed into one layer that calculates the similarity between the inputs of the two BERTs. The Triplet structure receives upon input an anchor sentence, a positive sentence, and a negative sentence. The triplet network is then trained in a way to make the distance between the anchor sentence and the positive sentence smaller while making the distance between the anchor sentence and the negative sentence bigger. BERT is slow on large-scale tasks like semantic similarity comparison, information retrieval, and clustering. It takes BERT 65 hours to find the most similar sentence pair in a collection of 10,000 sentences, whereas SBERT takes 5 seconds to compute 10,000 sentence representations and 0.01 seconds to compute cosine similarity.
Generally, autoencoding models (e.g., BERT) perform better than autoregressive models (e.g., Transformer-XL), but BERT is not optimal because it neglects the dependency between the masked positions and suffers from a pre-train/finetune discrepancy [
45]. Autoencoding models perform better because of their ability to model bidirectional contexts. XLNet [
45] is an unsupervised model that combines BERT and Transformer-XL. XLNet integrates ideas from Transformer-XL while learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order. As a result of its autoregressive formulation, XLNet overcomes the limitations of BERT. XLNet is able to model anaphora. It outperforms BERT on 20 evaluated datasets [
45].
Models similar to BERT (that use masked language modeling training methods) corrupt the input by replacing some tokens with a mask and then train a model to reconstruct those tokens. ELECTRA [
102] (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) has a more efficient training method. It replaces selected tokens with alternatives produced by a generator network and then trains a discriminative model to predict for each token if it was replaced by another plausible token or not. The architecture has two components: the generator, which is typically a small masked language model, and the discriminator—the ELECTRA model. The generator and the discriminator are trained jointly: the generator of the output text with tokens replaced with plausible alternatives, and the discriminator to detect which tokens are replaced. The ELECTRA model is similar to a generative adversarial network (GAN), but the generator is not trained to generate text that would deceive the discriminator, instead it produces tokens that have the highest likelihood. On the GLUE datasets, ELECTRA performs similarly as XLNet with an average accuracy of 89.5%, outperforming BERT by 5.5%.
REALM [
7] (Retrieval-Augmented Language Model) is a semi-supervised masked language model. Language models typically capture world knowledge implicitly, REALM does it in a more modular and interpretable way by incorporating knowledge retriever in the learning procedure. Two main components of REALM are: the neural knowledge retriever, which finds a document containing the answer to the question, and the knowledge-augmented encoder, which outputs the answer to the question with the help of the retrieved document. The knowledge retriever uses a BERT-style architecture, and the knowledge-augmented encoder uses a vanilla Transformer architecture. After fine-tuning on the Open-domain Question Answering task, REALM outperforms BERT on the NQ and WQ datasets by 13.9% and 23%, achieving 40.4% and 40.7% accuracy, respectively.
10. Discussion
In this survey, we have systematized the findings according to the defined criteria: the representation level (the level of linguistic units for which representations are being learned); the input level (the granularity of data upon input); the model type (the general strategy for representation learning); the model architecture (neural network architecture); and the model supervision (an indication of the need for labeled training data). Still, there are additional insights into the criteria for comparing, selecting, and evaluating the representation models, as well as insights into which model properties are important to consider when building or choosing an architecture for a specific downstream task and language.
10.1. Comparison
The majority of shallow models are unsupervised, learn word-level representations, and take word-level input. They perform well on simple tasks like measuring word similarity and are the easiest architecture to train.
Word-level input was popular among recurrent models, but recently subword-level input is more frequently used. In this study, we noticed that recurrent models do not prefer one type of supervision or representation level more frequently than other types.
The majority of recursive models work with word-level input and learn sentence+ representations for larger chunks of text like phrases, sentences, paragraphs, or entire documents. Recently, recursive models that generate latent trees are preferable due to the low data preparation requirement, but unsupervised learning is still not the norm. They are a good fit for semantic and sentiment tasks [
75] where the tree structure of a text is important. Recursive models are currently underexplored, and some of the popular neural network libraries (e.g., TensorFlow) do not support them well (with some exceptions like DyNet).
Convolutional and attention models mainly use subword or word-level input. Attention models most frequently learn sentence+ representations. Unsupervised models are preferred again because of large amounts of data usable without any manual labeling. For tasks that process long texts with long-range dependencies, attention models outperform all the other models. Lately, attention models are increasing in size to improve the performance but at the cost of increased training time and higher memory requirements.
Shallow models are effective when dealing with word-level units, but if the downstream task depends on higher-level units (e.g., phrases, sentences, etc.), recursive, convolutional, or attention models are a better choice. Currently, a significant drawback with recursive models is a complicated training procedure that is hard to implement and leads to slower training times. Convolutional models can learn local patterns and are a good fit for computer vision tasks. It has been shown that convolutions can be used for text, but currently, attention models outperform them on text-related tasks as attention mechanisms can learn long-range dependencies.
Subword input provides the most flexibility, as unseen and rare words are easily dealt with, and input vectors are not as large. The subword-level facilitates the learning of neural models for morphologically rich languages. Complex downstream tasks benefit from sentence+ representations, but word representations and shallow models still work well for simple downstream tasks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







