3. Sequential Estimation of RTF
In (4) and (5), we assume that the analysis interval of the STFT is sufficiently long enough for the observed signal in the
lth frame to be considered stationary. In addition, we have assumed that the ambient noise
ni(
m) is stationary. Thus, the cross power spectral density (CPSD) between
Yi and
Y1 in the
lth frame is written as
Note that since Ui is uncorrelated with Si, is independent of the time index l.
Let
denote an estimate of
, then by using (6), it can be rewritten as
where
is the estimation error. We now consider the acoustic data of a finite duration corresponding to the first
l frames of the analysis segment of the input signal for estimating
Pi(
ω). Via the BLS approach,
Pi(
ω) can be obtained from the following Equations (1) and (2):
The idea behind the SLS is to recursively update the least squares estimate as new observations are acquired [
4]. The following vectors are defined for sequentially solving Equation (8).
Then, (8) can be rewritten as
where
Let
denote the SLS solution at the
lth frame when the measurement
is given. By using (10) and (14) and the given measurement vector
,
is determined as follows (note that we omitted
ω in the following derivation for compactness of the expression)
Let
D(
l) denote the inverse of the Gram matrix of
A(
l) such that
Use of the matrix-inversion lemma and (15) leads us to
where
Then, substituting (16) and (17) into (15) yields the SLS solution which is recursively updated.
Pi(
ω), the first element of
which estimates the RTF between the
ith microphone and the speaker, is the key signal to be captured here. Since we have assumed the background noise is stationary, by using (7), (10) and (13),
in (18) would lead to the estimation error of the RTF as follows:
Equations (18) and (19) tell us that the error is reflected to the update of the current estimate of the RTF with gain .
Rearranging (18) in deriving the RTF update formula leads us to
where
Equation (18) seems similar to that of the recursive least squares (RLS). Unlike the RLS, however, the SLS formulation seeks the solution which minimizes the total estimated error with equal weight placed on each error component ranging from the start of the adaptation process to the latest time frame. The RLS technique, on the other hand, weighs the contribution of the error components depending on the temporal proximity to the present time by assigning the “forgetting factor” somewhere between zero and one, as shown below [
5].
with the minimized total error defined as
It should be apparent that
equals 1 in the case of the SLS method. With the
value less than 1, the RLS method would exhibit adaptability with a limited memory, while the SLS method would retain its memory infinitely. In this sense, the SLS method would result in identical parameters to those calculated by the BLS method up to the batch length of the BLS method. It can be inferred that the SLS method would result in smaller errors in comparison to the RLS method, so long as the sound source remains in the same direction. Due to the smaller size of the influential memory, the RLS method is expected to exhibit a better solution in the early stage of the adaptation if there was a significant change in the sound source direction. Nevertheless, the SLS method would eventually reduce the overall error better than the RLS once the SLS accumulates enough of the input data for its adaptation to the change. A case study of the SLS and the RLS determined that of the two algorithms implemented on CMOS circuits, the SLS delivered better performance [
6].
One disadvantage of having an infinite influential memory, as in the case with the SLS, is that the method may not be nimble in adapting to any abrupt change of the sound source. One way of correcting this problem is by resetting the memory once it is determined that a change occurred in the sound source. If there is an alternate mean of alerting the beam former of a significant change, we contend that the SLS technique would yield a better overall result.
In considering the convergence of the parameter estimates when
lμ→∞, Nassiri-Toussi and Ren [
7] showed that the parameter estimated by least square-type minimization algorithms converged to its true value provided that the estimation error was white noise. The numerical errors and system noise are presumably considered as white noise. In the white noise condition, the least square solution converges if the estimation period gets longer and longer since the proposed method reformulates the BLS estimation to enable the parameter estimation in a sequential manner. During the first few hundreds of milliseconds, it can show unstable behavior. However, the resultant estimates by the SLS are expected to converge with a sufficient number of the input samples to the one derived from the BLS estimation.
Now, the next question concerns the length of the input sample sufficient for tolerable performance of the estimated RTF. We experimentally analyzed the convergence of the RTF in terms of speed and of the values compared to those obtained from the BLS.
4. Experiments
The mean square error (MSE) is used for evaluating the performance. The MSE represents the amount of difference between the target RTF and the estimated RTF. We measured the MSE at each segmented frame of the input signal per microphone except the first microphone, the reference, and it can be formed by
The RTF is obtained by a room impulse response (RIR) generator [
8] that produces the imaginary data formed with respect to the specified environment. The input signals are generated by filtering the speech signal with the RIR. The imaginary room has a size of 4 × 6 × 3 m (width, length and height) and the reverberation time is set to 0.128 s. The four-microphone array (spaced by 5 cm) is located in the middle of the room, as depicted in
Figure 2. The distance between the sound sources and the microphone array is 0.3 m. The sound source is initially set to −45° with respect to the center normal of the microphone array, as depicted in
Figure 2. The experiment began with the source at −45° for the first 14 s, then it moved to −40° instantaneously and collected the signal for the next duration of 10.5 s. Finally, the source was moved to −10° and the acoustic signal was recorded for the remainder of the experiment. It should be noted that we do not need to know the exact location of the sound object but need to know whether there is a location change of the targeted sound object. To detect such changes, we rely on the visual sensor/algorithm as described in [
9]. This is to consider the situation that the sound object can move without making any sound since usually a sound-based object tracking algorithm can lose the object’s track when there is a long pause (silence).
We conducted the evaluation to compare the two conventional methods—the BLS method [
1,
2] and LMS method [
3]—with the proposed SLS method.
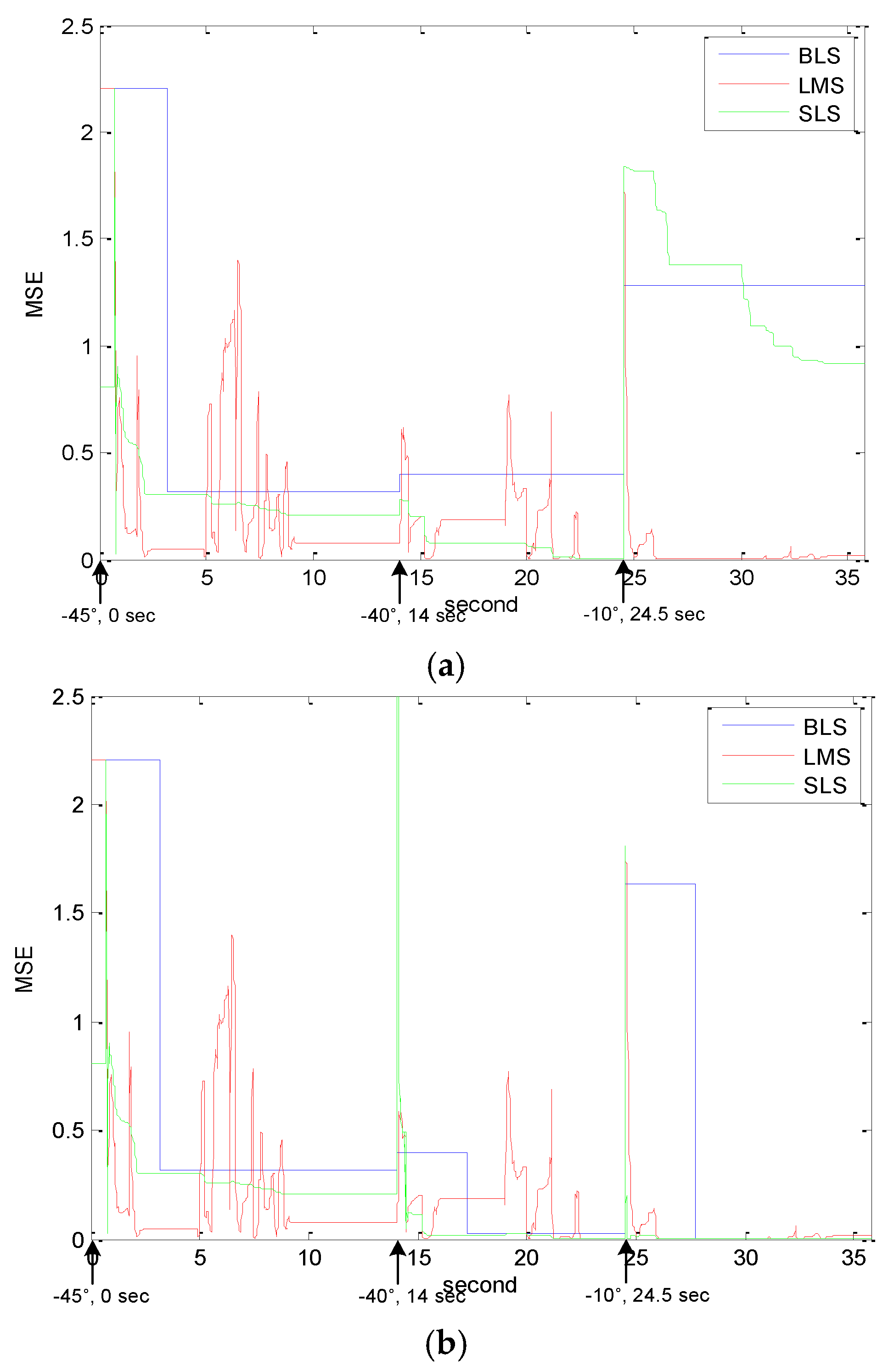
Figure 3 and
Table 1 summarize the MSEs evaluated for the three methods. The “no reset” in
Figure 3a and
Table 1 means that the RTF estimate values of the BLS and the SLS methods were not reinitialized after the movement of the target. The proposed method shows a lower MSE than that of the BLS method on average because of its cumulative nature in the RTF estimation yielding more accurate values in the long run. The same cumulative nature, however, caused it to have greater errors at least in the earlier time frame when the speaker was at −10° (at 24.5 s). The adaptive nature of the SLS-based estimator corrected its RTF values to more accurate values than the one computed by the batch method after about five seconds. The errors exhibited by the SLS after 24.5 s are of an artificial nature in that the speaker location changed abruptly from −40° to −10°. In actual applications of beamforming in isolating the subject speaker from others, it is safe to assume that the subject speaker moves from one location to another at moderate speed. Therefore, it is very unlikely that a human speaker would move instantaneously from one location to another by 30° as it was the case in the experiment. The cumulative and gradual nature of updating the RTF in the case of the SLS approach is therefore more suitable for tracking and isolating a moving speaker.
In comparison to the LMS method, it is shown in
Figure 3a that the performance of the proposed method declined when the sound source moved abruptly in large angles. Since our sequential method does not include any speech detector which would prompt re-initialization of the RTF estimates for any movement of the source, the data corresponding to previous positions of the source give rise to adverse effects on estimating the RTF when the source moves in large angles. Due to the speech detector coupled with the RTF estimation based on recursive updating, the LMS method shows reasonable performance after the sound source moved abruptly. The LMS method, however, was shown to be sensitive to noise as its performance degraded significantly between 5 and 9 s, and between 19 and 21 s intervals. Incorporating the speech detector in the processing may have led to incorrect RTF estimate values as the detector reacted to false alarms in these time intervals.
In another comparison of the three methods as depicted in
Figure 3b, RTFs were re-initialized for both the batch method and the sequential method when the target source moved. Since the LMS method per se has the function of adapting to any environmental change [
3], the initialization was unnecessary. In this evaluation, the proposed method shows the best performance in
Table 1. The batch method needs an input data block in its initialization to estimate the RTF, therefore high MSE values appear in the duration corresponding to the beginning input data blocks: 0–3.2 s, 14.5–17.7 s and 25–28.2 s For the BLS to be capable to estimate the RTF, at least a 3.2 s block was required. In the experiments, it is not considered that the user moves within the BLS block size to see the performance of the algorithm itself (not due to insufficient data). Regardless of the block size and algorithms, the RTF value should be re-initialized with the corresponding data. Otherwise, it will show the simulation result as depicted in
Figure 3a. That experiment simulated the situation:
The targeted user started to speak initially at −45° and paused.
5° change) The user moved to −40 degrees and spoke again at 14 s and paused.
(30° change) The user moved again to 10° and spoke again at 24.5 s.
Figure 3a has shown that if the RFT is not initialized, the estimation error gets a higher value as the angular distance gets farther. When comparing the 5° (−45° to −40°) and 30° changes (−40° to −10°), it can be easily seen that the MSE gap increased significantly when the 30° change was made.
In the two experiments conducted, the proposed SLS method with re-initializations of the RTFs demonstrated the best performance among the considered methods in the case of a moving sound source. This result is promising considering that the angular position change of a sound source of interest occurs frequently in real-life environments, and such position change can be detected by another sensor as assumed in [
9]. However, it must be reminded that the proposed method performed well when the source location change was moderate such as the 5° displacement as considered in the experiment. For following acoustic speech from a moving source, the SLS without any source position change detection may yet perform well in the current implementation.




{kind=link}
{kind=link}
{kind=link}