Underwater Fish Body Length Estimation Based on Binocular Image Processing

Abstract
1. Introduction
2. Methodology
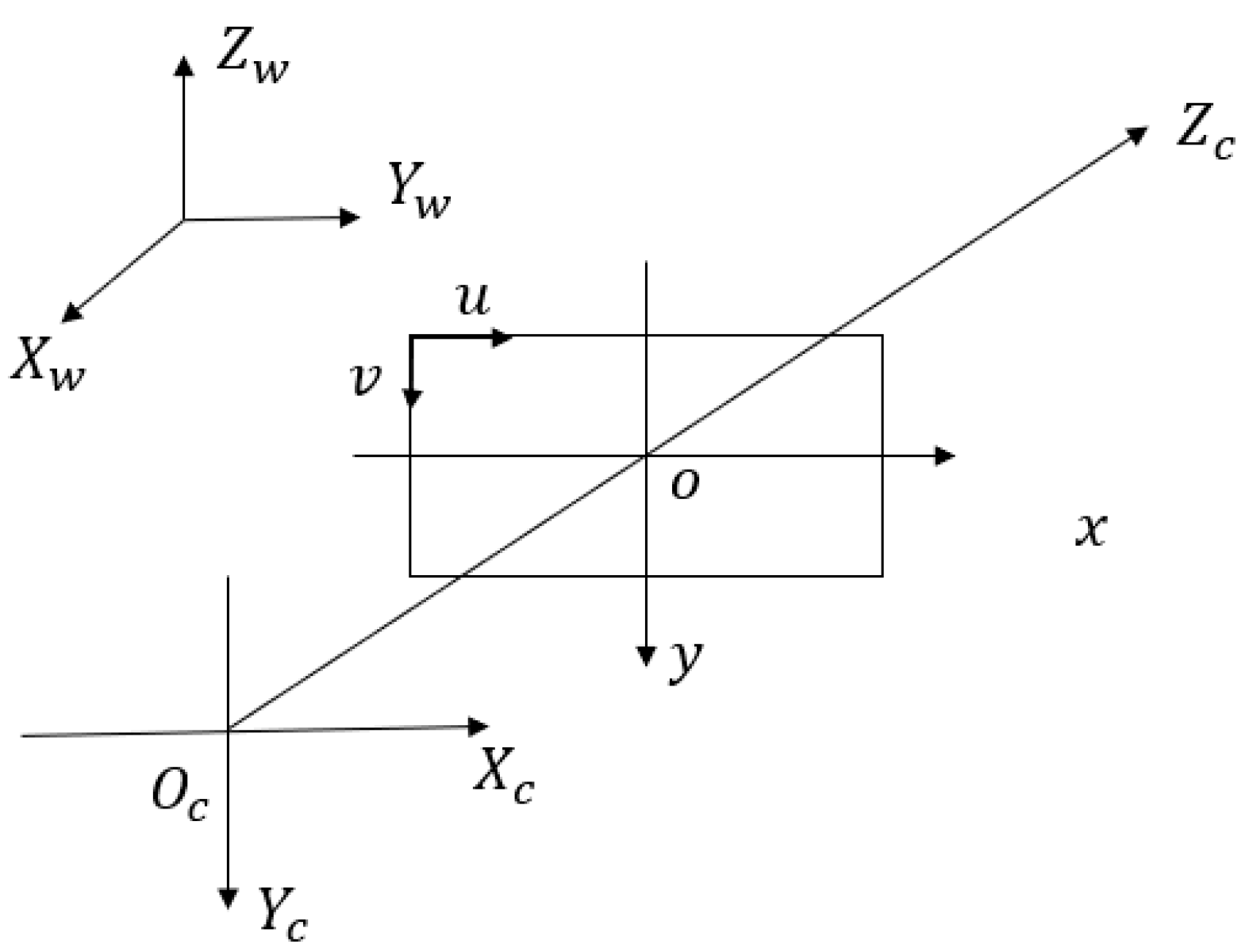
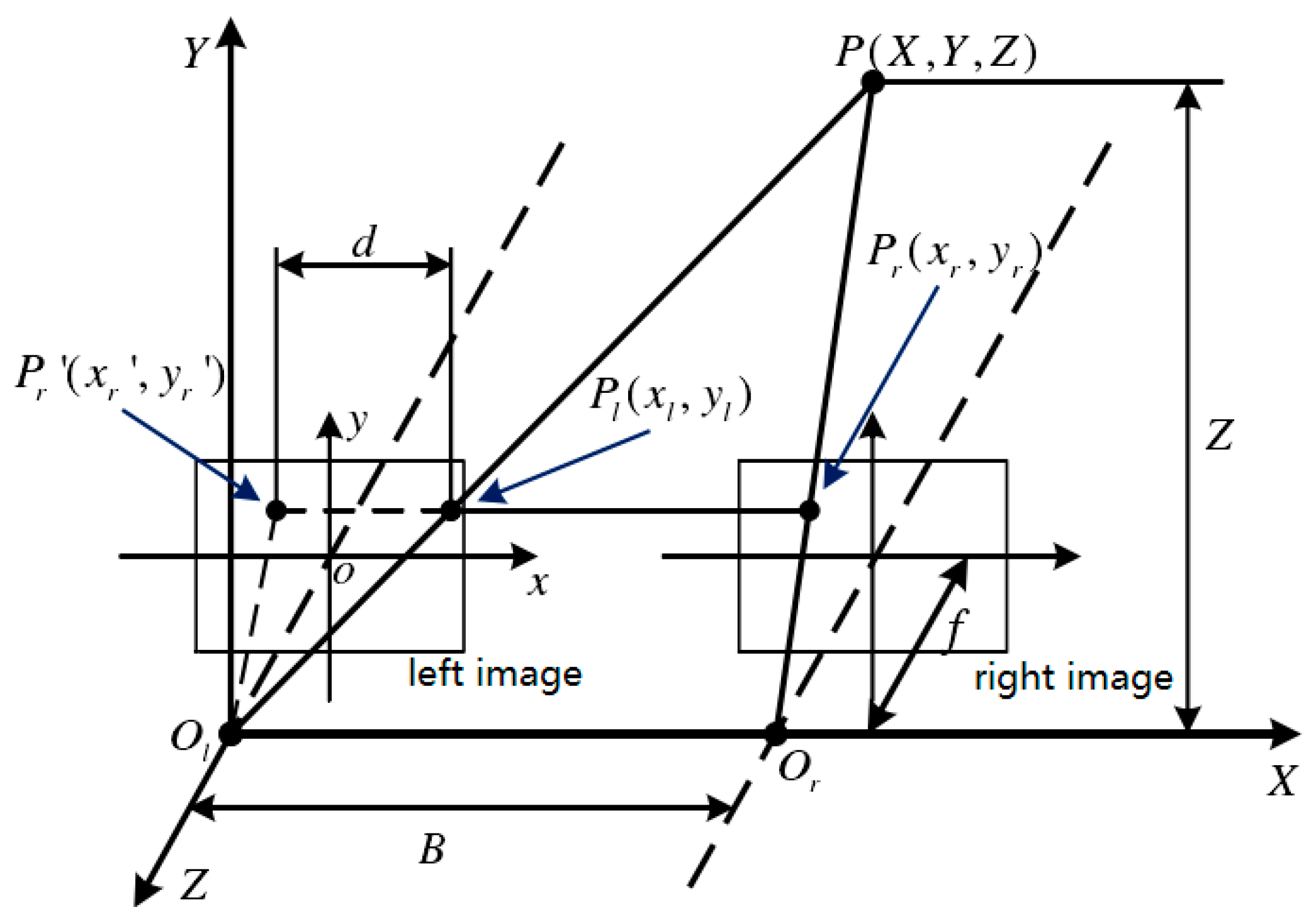
2.1. Camera Calibration
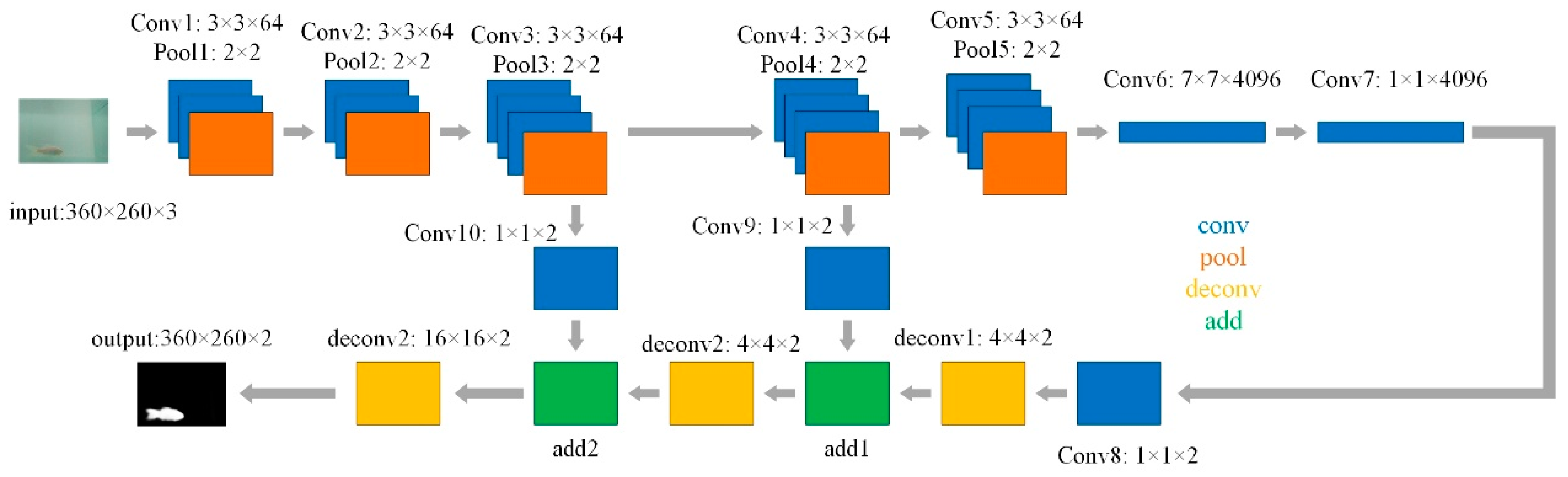
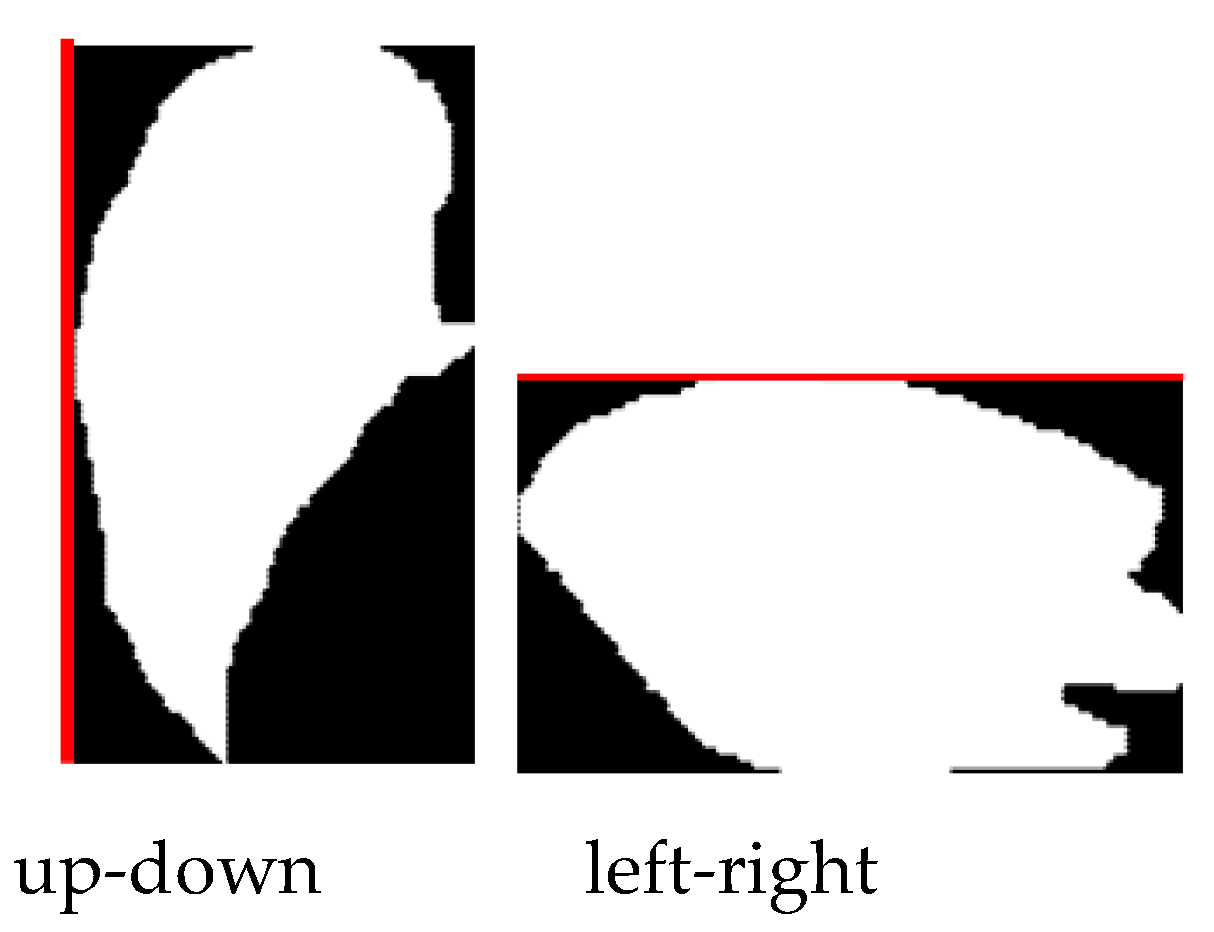
2.2. Fully Convolutional Network
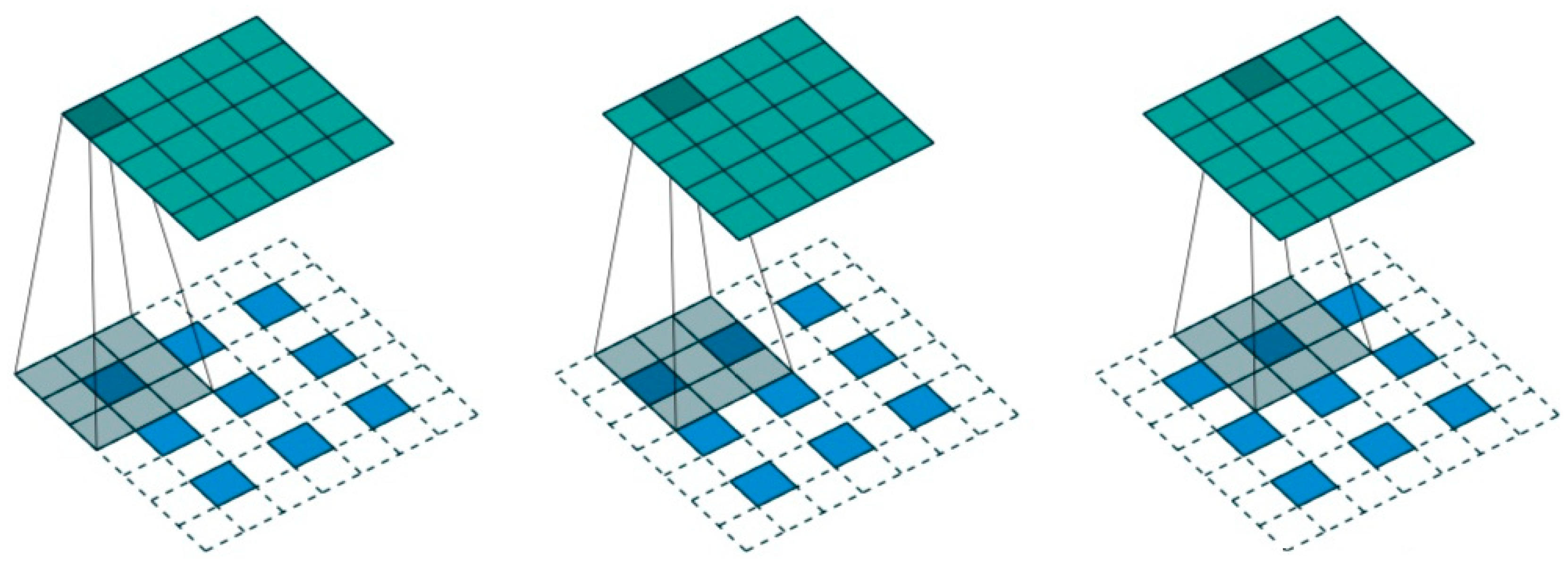
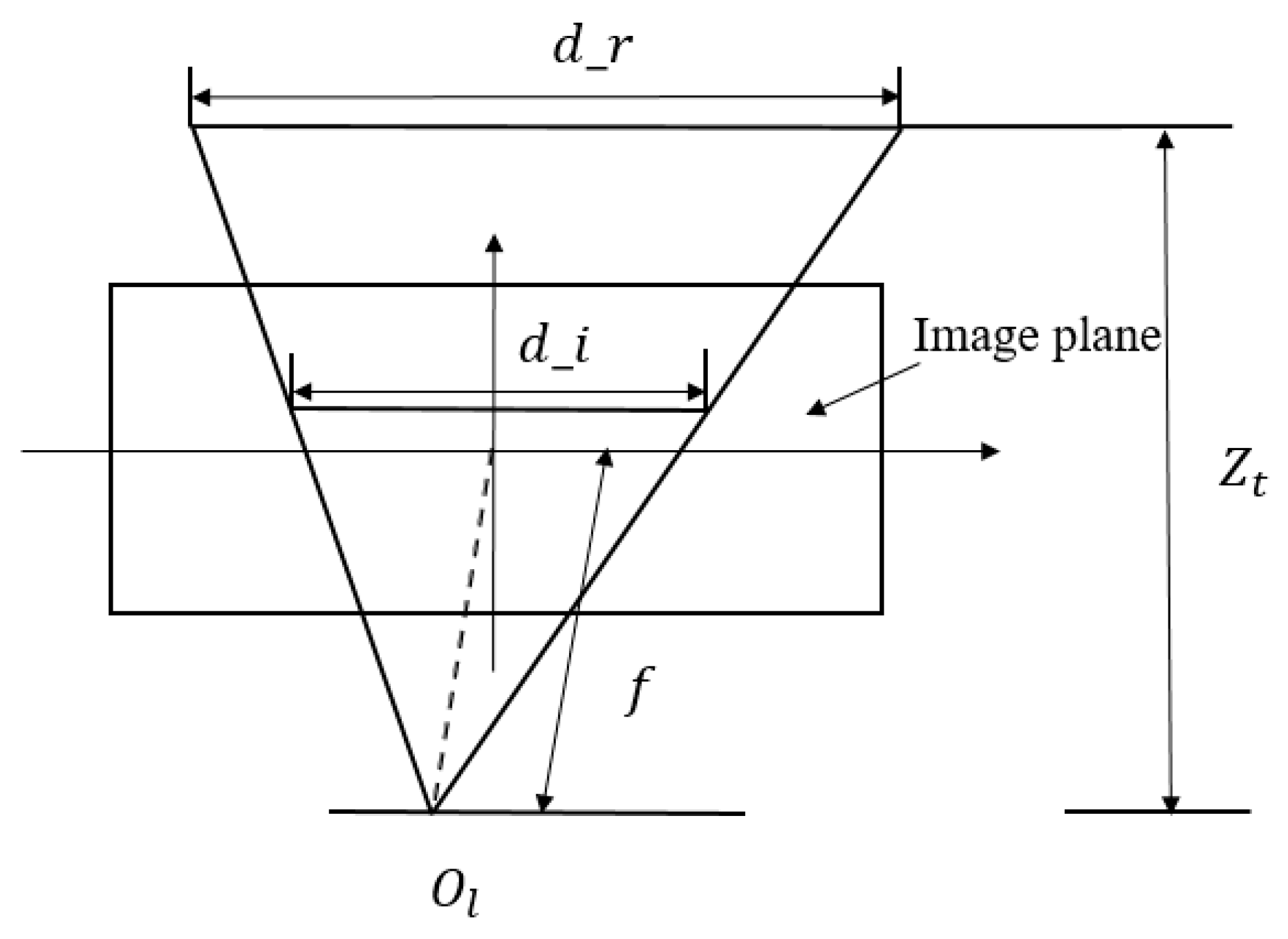
2.3. Depth Prediction
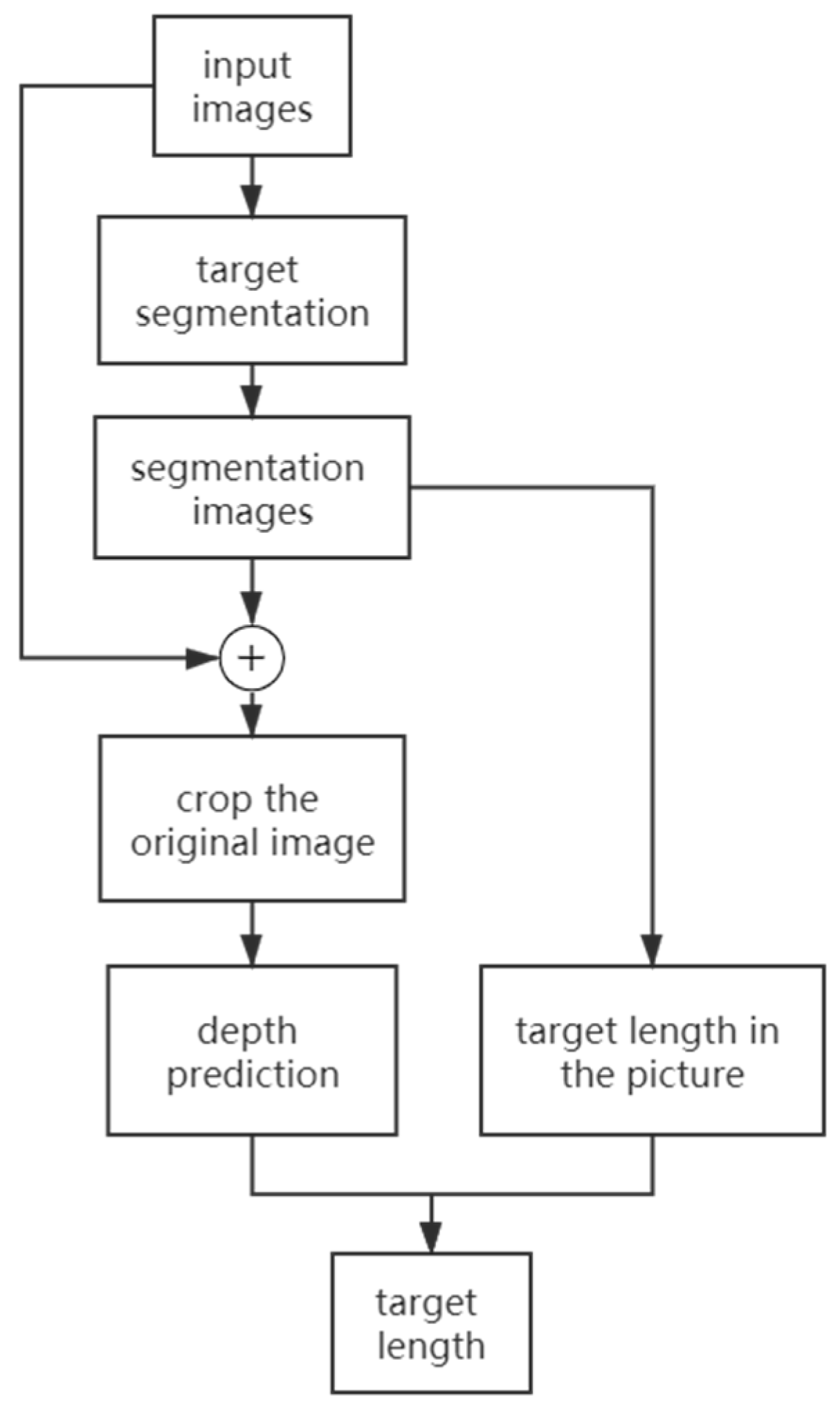
2.4. Estimation of Fish Body Length
3. Experiments
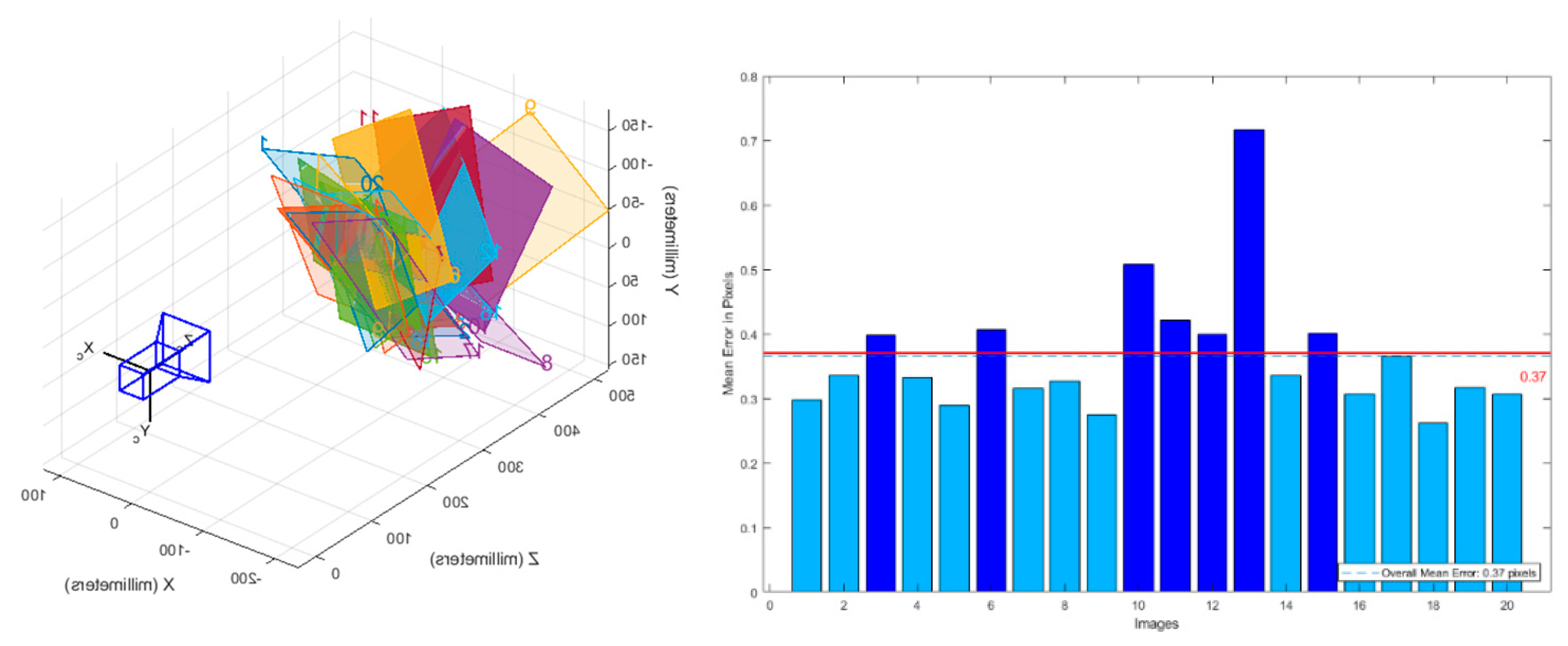
3.1. Camera Calibration
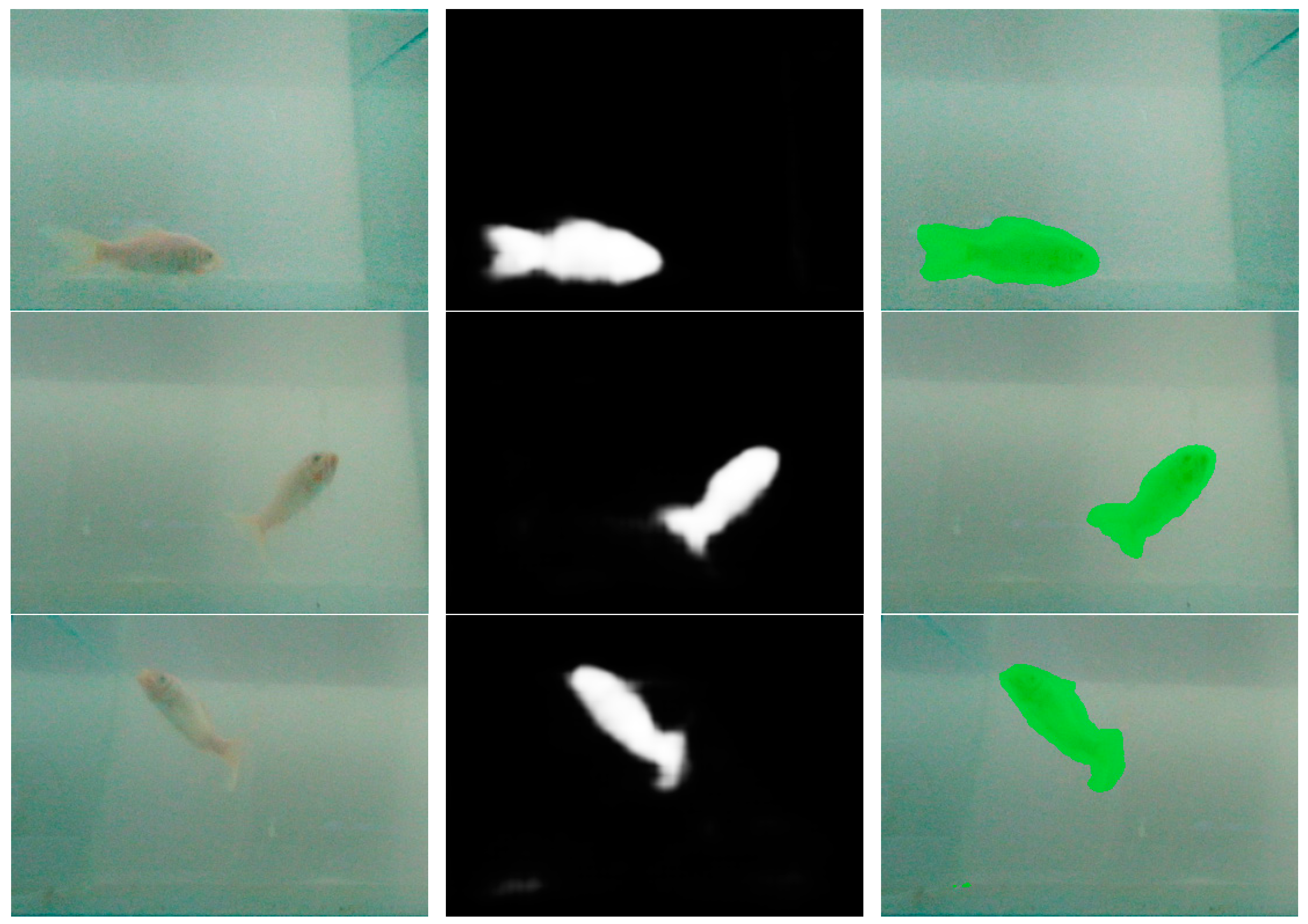
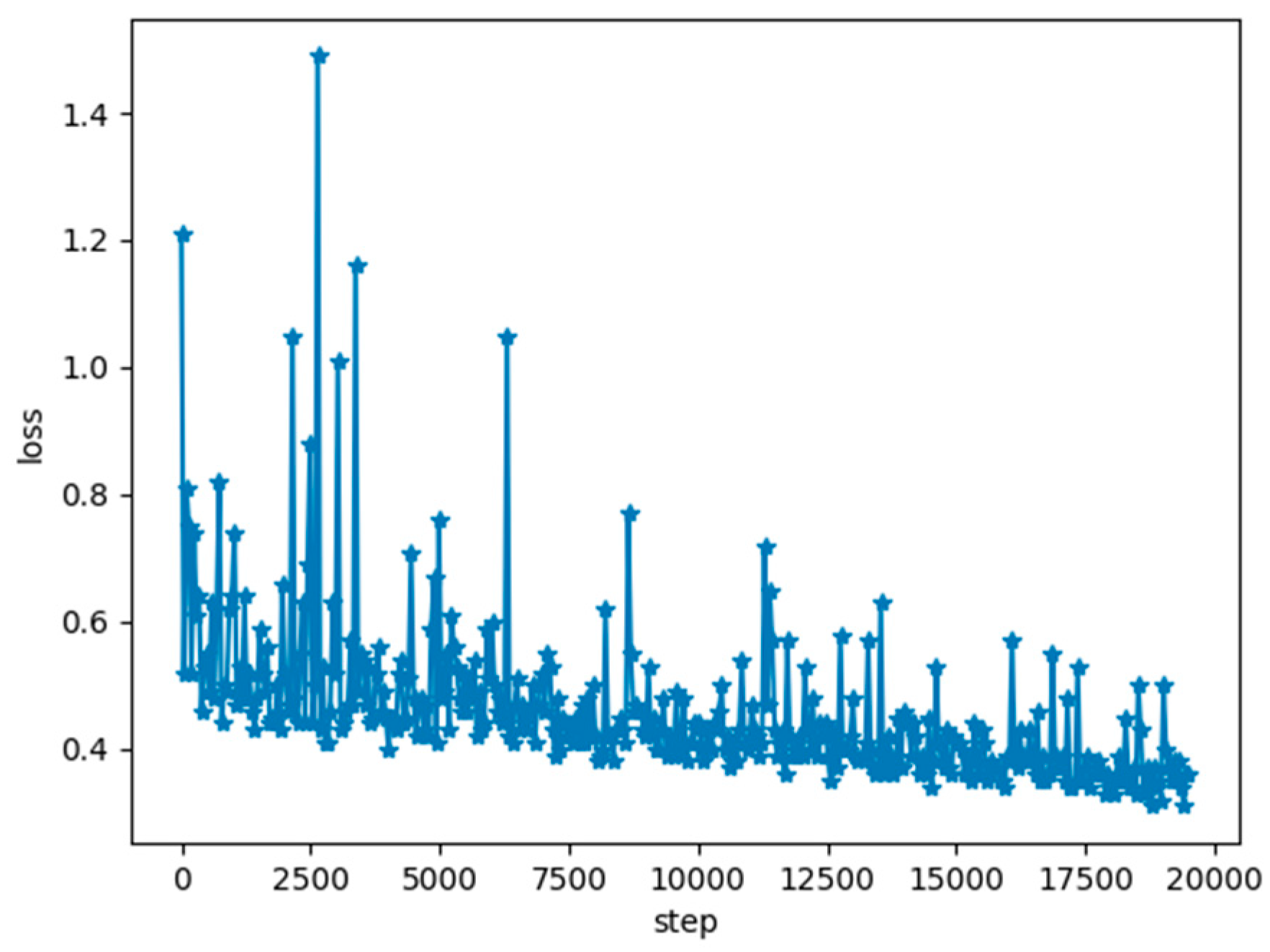
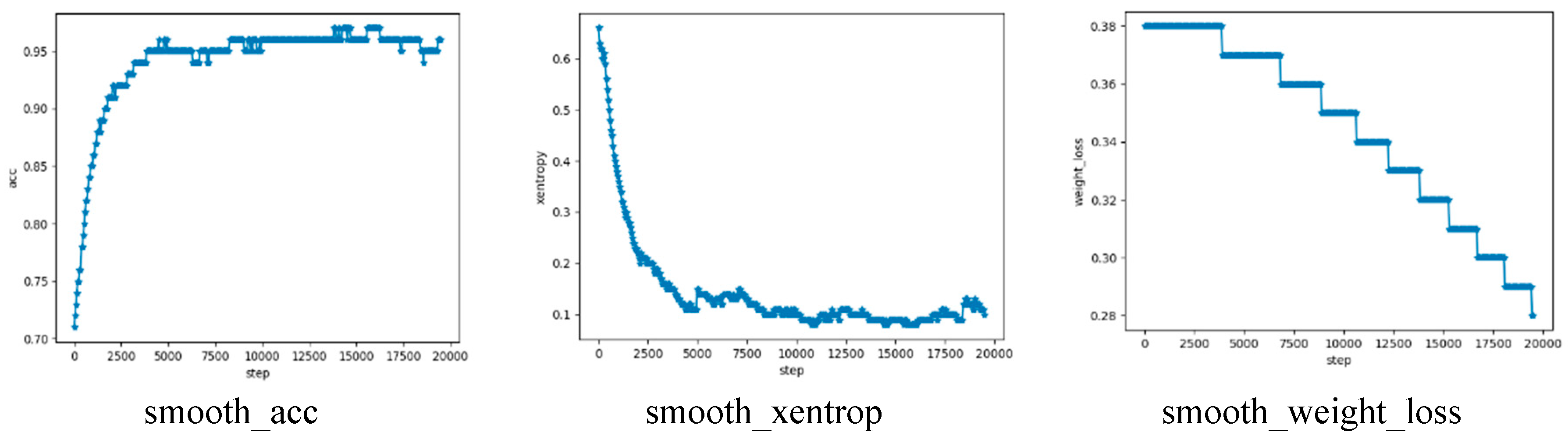
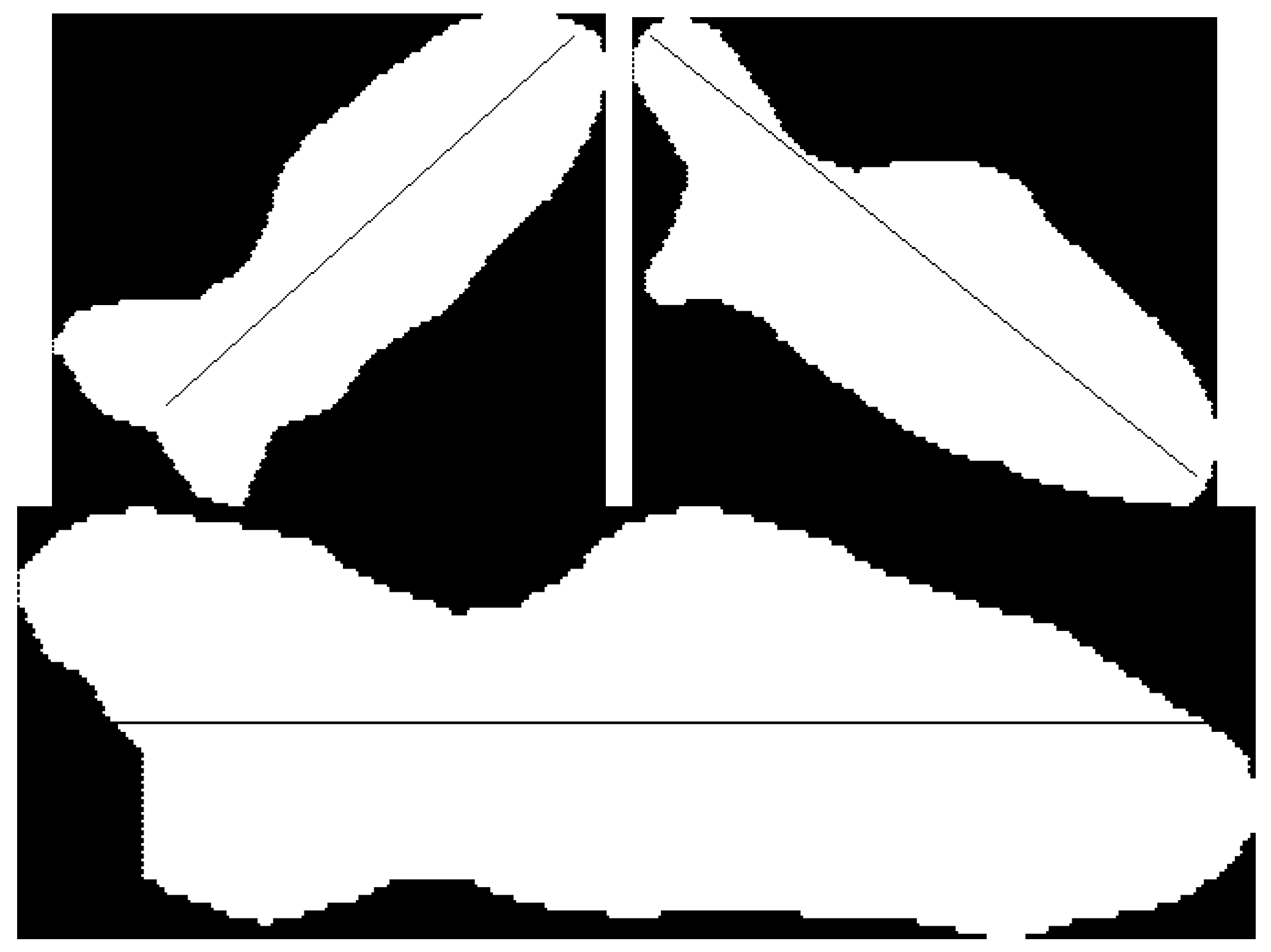
3.2. Fish Segment Based on FCN
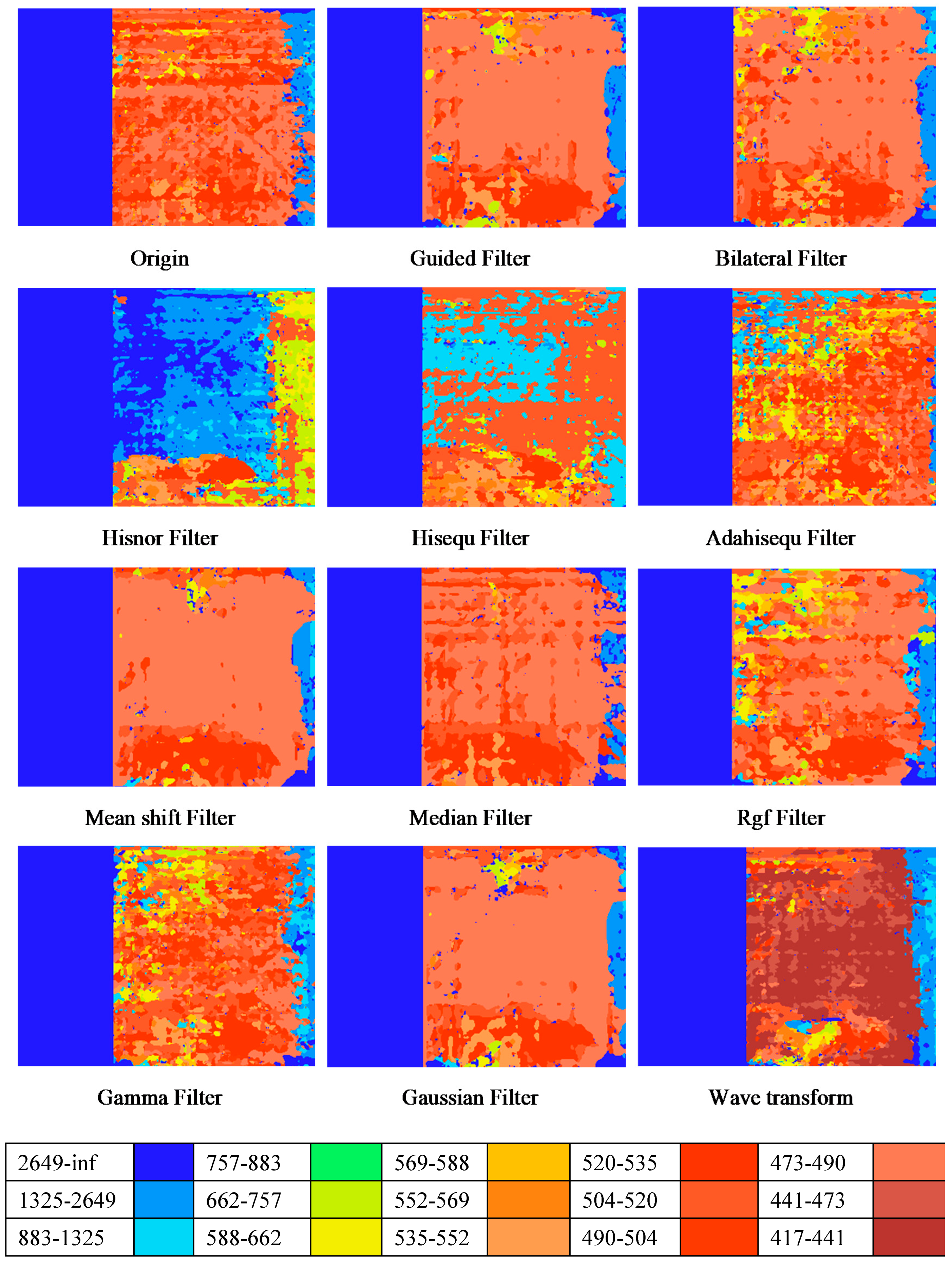
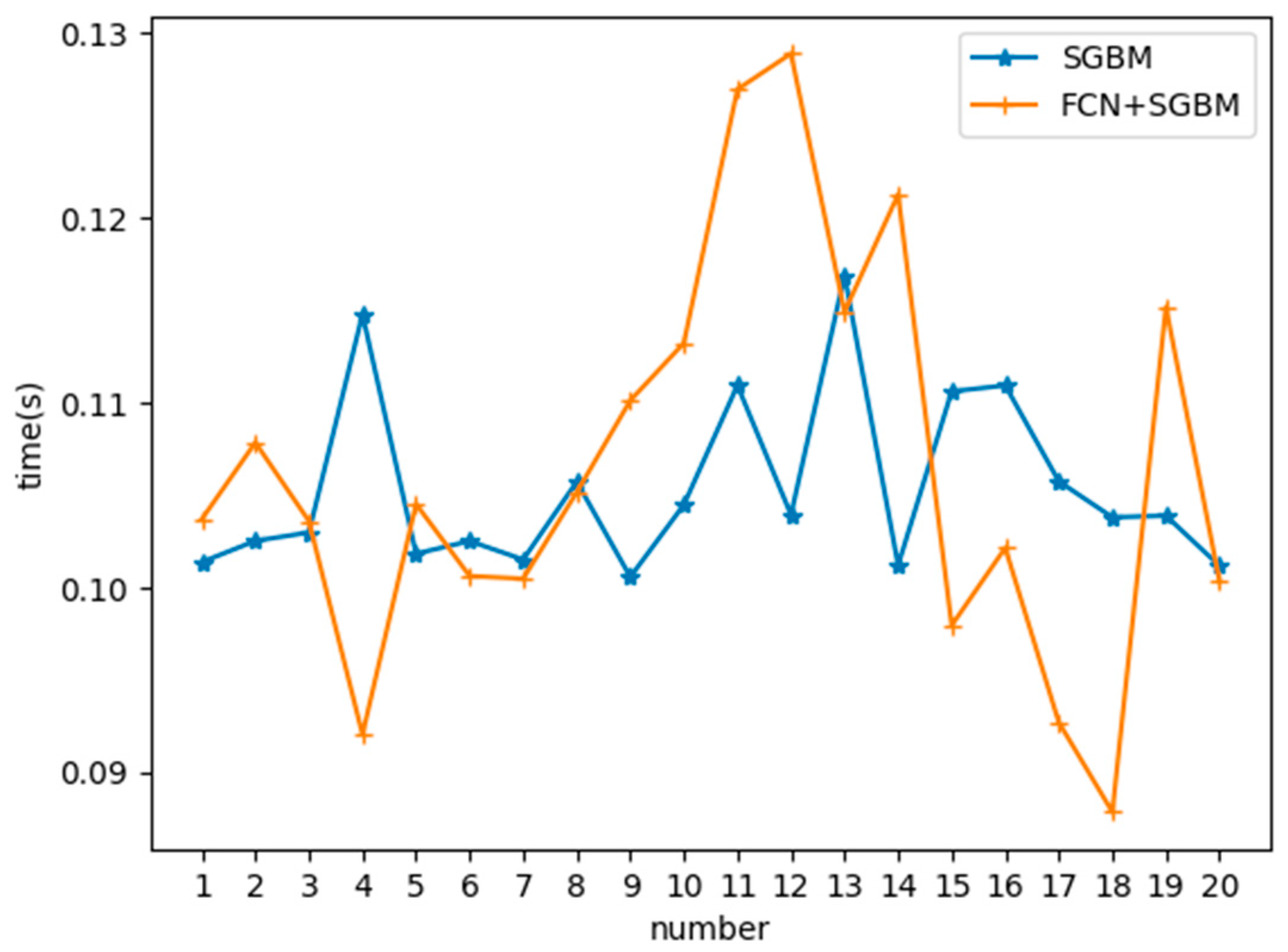
3.3. Depth Prediction
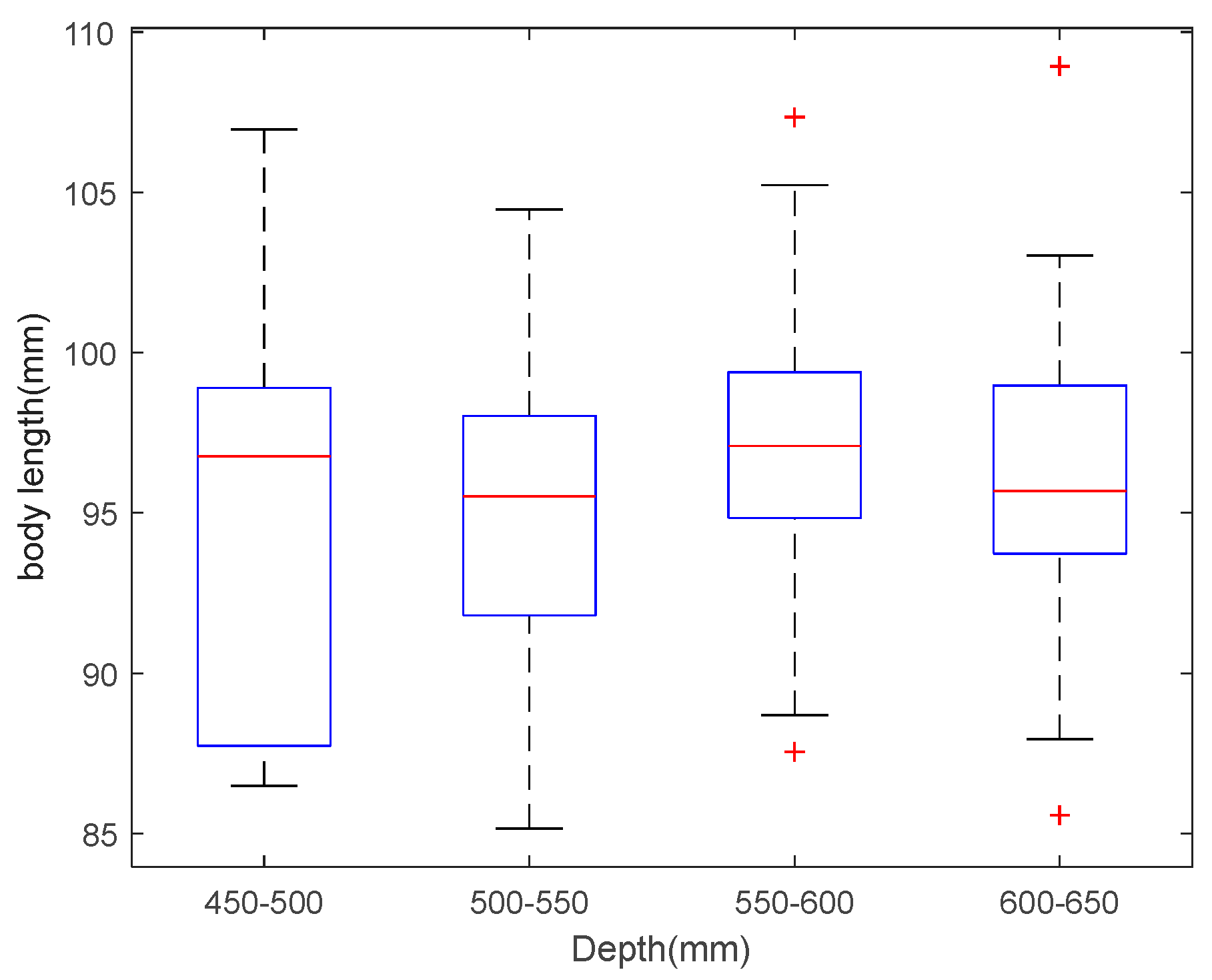
3.4. Fish Body Length Estimation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Recuero Virto, L. A preliminary assessment of the indicators for Sustainable Development Goal (SDG) 14 “Conserve and sustainably use the oceans, seas and marine resources for sustainable development”. Mar. Policy 2018, 98, 47–57. [Google Scholar] [CrossRef]
- Pauly, D.; Zeller, D. Comments on FAOs State of World Fisheries and Aquaculture (SOFIA 2016). Mar. Policy 2017, 77, 176–181. [Google Scholar] [CrossRef]
- van Hoof, L.; Fabi, G.; Johansen, V.; Steenbergen, J.; Irigoien, X.; Smith, S.; Lisbjerg, D.; Kraus, G. Food from the ocean; towards a research agenda for sustainable use of our oceans’ natural resources. Mar. Policy 2019, 105, 44–51. [Google Scholar] [CrossRef]
- Garcia, R.; Prados, R.; Quintana, J.; Tempelaar, A.; Gracias, N.; Rosen, S.; Vågstøl, H.; Løvall, K. Automatic segmentation of fish using deep learning with application to fish size measurement. ICES J. Mar. Sci. 2019, 77, 1354–1366. [Google Scholar] [CrossRef]
- Salman, A.; Siddiqui, S.A.; Shafait, F.; Mian, A.; Shortis, M.R.; Khurshid, K.; Ulges, A.; Schwanecke, U. Automatic fish detection in underwater videos by a deep neural network-based hybrid motion learning system. ICES J. Mar. Sci. 2019, 77, 1295–1307. [Google Scholar] [CrossRef]
- Spampinato, C.; Chenburger, J.; Nadarajan, G.; Fisher, B. Detecting, Tracking and Counting Fish in Low Quality Unconstrained Underwater Videos. In Proceedings of the Third International Conference on Computer Vision Theory and Applications, Madeira, Portugal, 22–25 January 2008; pp. 514–519. [Google Scholar]
- Lu, Y.; Tung, C.; Kuo, Y. Identifying the species of harvested tuna and billfish using deep convolutional neural networks. ICES J. Mar. Sci. 2019, 77, 1318–1329. [Google Scholar] [CrossRef]
- Sung, M.; Yu, S.; Girdhar, Y. Vision based real-time fish detection using convolutional neural network. In Proceedings of the OCEANS 2017—Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–6. [Google Scholar]
- Mahmood, A.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F.; Hovey, R.; Kendrick, G. Automatic detection of Western rock lobster using synthetic data. ICES J. Mar. Sci. 2019, 77, 1308–1317. [Google Scholar] [CrossRef]
- Álvarez-Ellacuría, A.; Palmer, M.; Catalán, I.A.; Lisani, J. Image-based, unsupervised estimation of fish size from commercial landings using deep learning. ICES J. Mar. Sci. 2019, 77, 1330–1339. [Google Scholar] [CrossRef]
- Tillett, R.; Mcfarlane, N.; Lines, J. Estimating Dimensions of Free-Swimming Fish Using 3D Point Distribution Models. Comput. Vis. Image Und. 2000, 79, 123–141. [Google Scholar] [CrossRef]
- Al-Jubouri, Q.; Al-Nuaimy, W.; Al-Taee, M.; Young, I. An automated vision system for measurement of zebrafish length using low-cost orthogonal web cameras. Aquacult. Eng. 2017, 78, 155–162. [Google Scholar] [CrossRef]
- Miranda, J.M.; Romero, M. A prototype to measure rainbow trout’s length using image processing. Aquacult. Eng. 2017, 76, 41–49. [Google Scholar] [CrossRef]
- Viazzi, S.; Van Hoestenberghe, S.; Goddeeris, B.M.; Berckmans, D. Automatic mass estimation of Jade perch Scortum barcoo by computer vision. Aquacult. Eng. 2015, 64, 42–48. [Google Scholar] [CrossRef]
- Abdullah, N.; Mohd Rahim, M.S.; Amin, I.M. Measuring fish length from digital images (FiLeDI). In Proceedings of the 2nd International Conference on Interaction Sciences: Information Technology, Culture and Human, Seoul, Korea, 24–26 November 2009; pp. 38–43. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Liu, L.; Huo, J. Apple Image Recognition Multi-Objective Method Based on the Adaptive Harmony Search Algorithm with Simulation and Creation. Information 2018, 9, 180. [Google Scholar] [CrossRef]
- He, Y.; Ni, L.M. A Novel Scheme Based on the Diffusion to Edge Detection. IEEE Trans. Image Process. 2019, 28, 1613–1624. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Wei, Z.; Yao, L. A Novel Approach to Component Assembly Inspection Based on Mask R-CNN and Support Vector Machines. Information 2019, 10, 282. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Jiang, Y.; Li, Y.; Zhang, H. Hyperspectral Image Classification Based on 3-D Separable ResNet and Transfer Learning. IEEE Geosci. Remote Sens. 2019, 16, 1949–1953. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Yadav, G.; Maheshwari, S.; Agarwal, A. Contrast limited adaptive histogram equalization based enhancement for real time video system. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), New Delhi, India, 24–27 September 2014; pp. 2392–2397. [Google Scholar]
- Zhang, Q.; Shen, X.; Xu, L.; Jia, J. Rolling guidance filter. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 815–830. [Google Scholar]
- Principe, J.C.; De Vries, B. THE GAMMA FILTER. IEEE Trans. Signal Process. 1993, 41, 649–656. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Depth (mm) | Body Length (mm) | Image No. |
|---|---|---|
| 450–500 | 94.9682 | 7 |
| 500–550 | 95.3670 | 10 |
| 550–600 | 96.9442 | 24 |
| 600–650 | 95.8932 | 19 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, R.; Zhang, C.; Xu, Q.; Liu, G.; Song, Y.; Yuan, X.; Sun, J. Underwater Fish Body Length Estimation Based on Binocular Image Processing. Information 2020, 11, 476. https://doi.org/10.3390/info11100476
Cheng R, Zhang C, Xu Q, Liu G, Song Y, Yuan X, Sun J. Underwater Fish Body Length Estimation Based on Binocular Image Processing. Information. 2020; 11(10):476. https://doi.org/10.3390/info11100476
Chicago/Turabian StyleCheng, Ruoshi, Caixia Zhang, Qingyang Xu, Guocheng Liu, Yong Song, Xianfeng Yuan, and Jie Sun. 2020. "Underwater Fish Body Length Estimation Based on Binocular Image Processing" Information 11, no. 10: 476. https://doi.org/10.3390/info11100476
APA StyleCheng, R., Zhang, C., Xu, Q., Liu, G., Song, Y., Yuan, X., & Sun, J. (2020). Underwater Fish Body Length Estimation Based on Binocular Image Processing. Information, 11(10), 476. https://doi.org/10.3390/info11100476