Application of an Ecosystem Methodology Based on Legal Language Processing for the Transformation of Court Decisions and Legal Opinions into Open Data


Abstract
:1. Introduction
2. Related Work
3. Open Data Methodology
- Identify online sources of legal documents: While publishing of data in fragmented sources is considered to pose severe impediments to their reuse [10], legal documents are usually published through a variety of web platforms and there is not a single access point. Moreover, sometimes the same documents reside in more than one web locations. Consequently, a first step in the process is the identification and evaluation of available online sources of legal documents.
- Collect documents: During this step, legal documents are gathered from the selected sources of the previous step. This task requires the development of software that takes advantage of available APIs and web services or, in the frequent case that such services are not provided, the implementation of web scrapers. Unfortunately, in the latter case, apart from the required effort for the development of a different script for each source, there is also the disadvantage that even a small change in the source’s structure may turn the scraper not functional.
- Transform to plain text: Legal documents are often published in closed, not machine-processable formats, such as PDF or Microsoft Word. In order to extract the legal content from these files, it is required to convert them in plain text. This step includes also pre-processing tasks for the removal of erroneous or irrelevant elements (e.g., page numbers, footers, headers, etc.) injected from the conversion process.
- Modelling: Several standards for the modeling of legal resources have been developed as part either of national or international initiatives [26]. Each standard defines a set of metadata and structural and semantic elements. In this step, the appropriate model must be adopted according to the project requirements. In our case, the Akoma Ntoso document model is used and the reasons for this choice are explained in Section 5.
- Transform to structured format: During this step, NLP techniques are applied in order to identify the metadata of the legal schema (in case they are not available from the original source) and the structural parts of the documents. In addition, semantic information about elements of the documents (e.g., legal references, persons, locations, dates, etc.) is extracted. The legal language processing approach we followed to accomplish the transformation is presented in Section 6.
- Store: This step involves decisions related to the storage of the generated open datasets. Data can be uploaded to existing repositories (e.g., national data portals) or to newly deployed data managements systems. Moreover, in this step the datasets can get linked to other available open datasets and APIs or web services providing access to them can be developed.
- Publish: In this final step, legal issues related to the license under which data are published and to intellectual properties rights are covered.
4. Sources of Legal Texts
5. Modelling of Legal Documents
5.1. The Akoma Ntoso Data Model
5.2. Legal Metadata
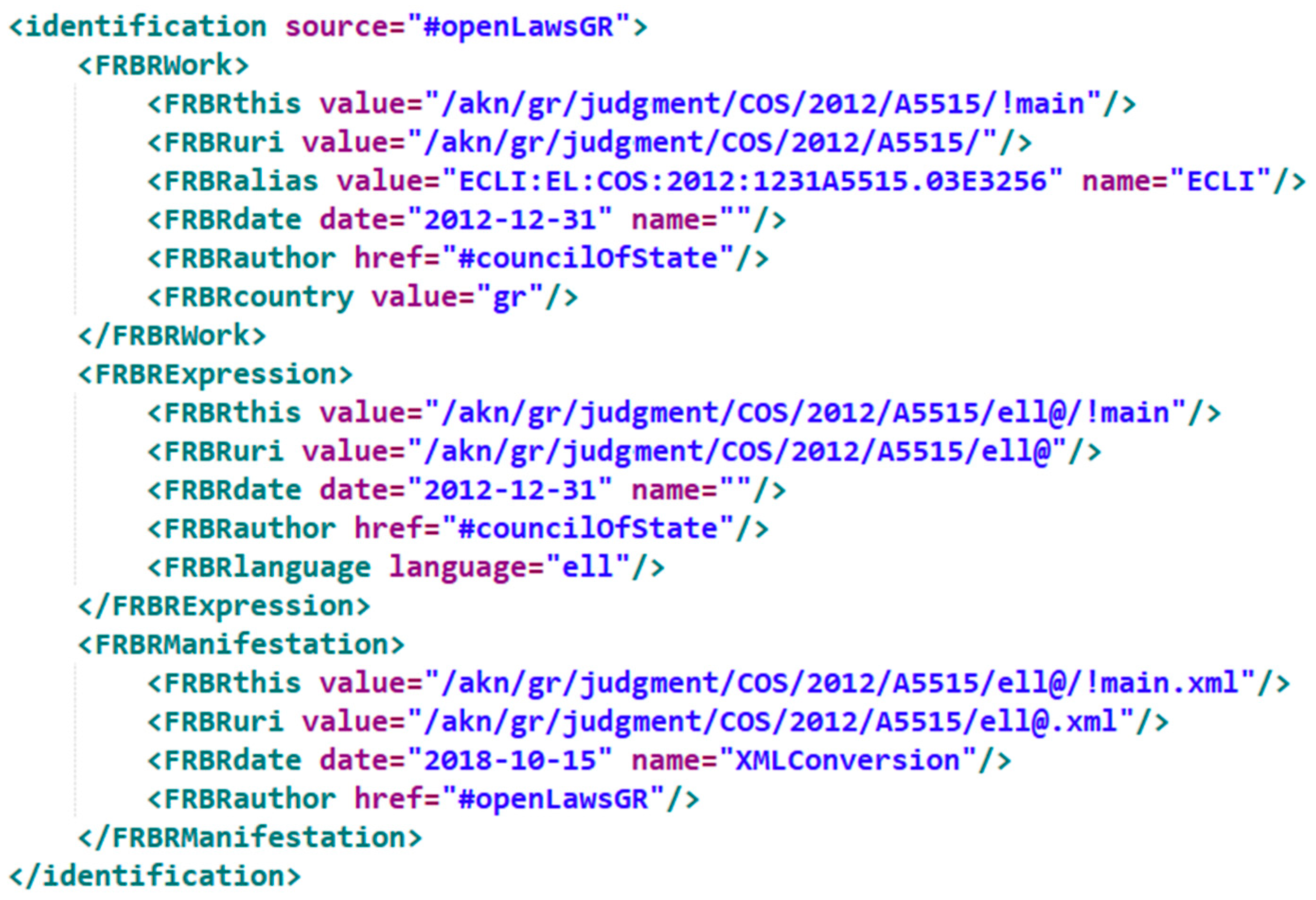
- <identification>: a block for the unique identification of the document according to the FRBR model. We are using this block in accordance to the Akoma Ntoso Naming Convention in order to define the International Resource Identifiers (IRIs) for the different levels of the FRBR model (Work, Expression and Manifestation) for the collected court decisions and legal opinions (Figure 4).
- <publication>: this block contains information about the publication source of the document; however, it is optional for our document types and it is not used.
- <classification>: this section is used to assign classification keywords to the document or part of it. As previously mentioned, legal opinions are published on the Legal Council’s website followed by a set of descriptive keywords. These keywords are included within this section (an example is shown in Figure 5).
- <lifecycle>: this block lists the events that modify the document.
- <workflow>: this block lists the events that are involved with the legislative, parliamentary or judiciary process. In our case, these are the necessary procedural steps for the delivery of the decision or legal opinion (e.g., public hearing, court conference, decision publication).
- <analysis>: in case of court decisions, it contains the result of the decision and the qualification of the case law citations.
- <references>: a section that models references to other documents or ontology classes. We are using this block and the elements (e.g., TLCLocation, TLCPerson, TLCOrganization, TLCRoles, TLCEvent etc.) of the abstract ontological mechanism of the model (Top Level Classes) to denote references to concepts representing locations, persons, organizations, roles and events. For an overview of the ontological structure of the Akoma Ntoso model, one may refer to [34].
- <proprietary>: this block can be used for capturing local or proprietary metadata elements. For example, in the case of legal opinions, we are using this block to place gathered metadata that do not belong to the previous blocks (e.g., a short summary of the opinion, the unique identifier assigned to the opinion from the Diavgeia platform, information about their acceptance or rejection from the responsible body according to the law etc.)
5.3. Modeling Court Decisions
Compliance with ECLI
5.4. Modelling Legal Opinions
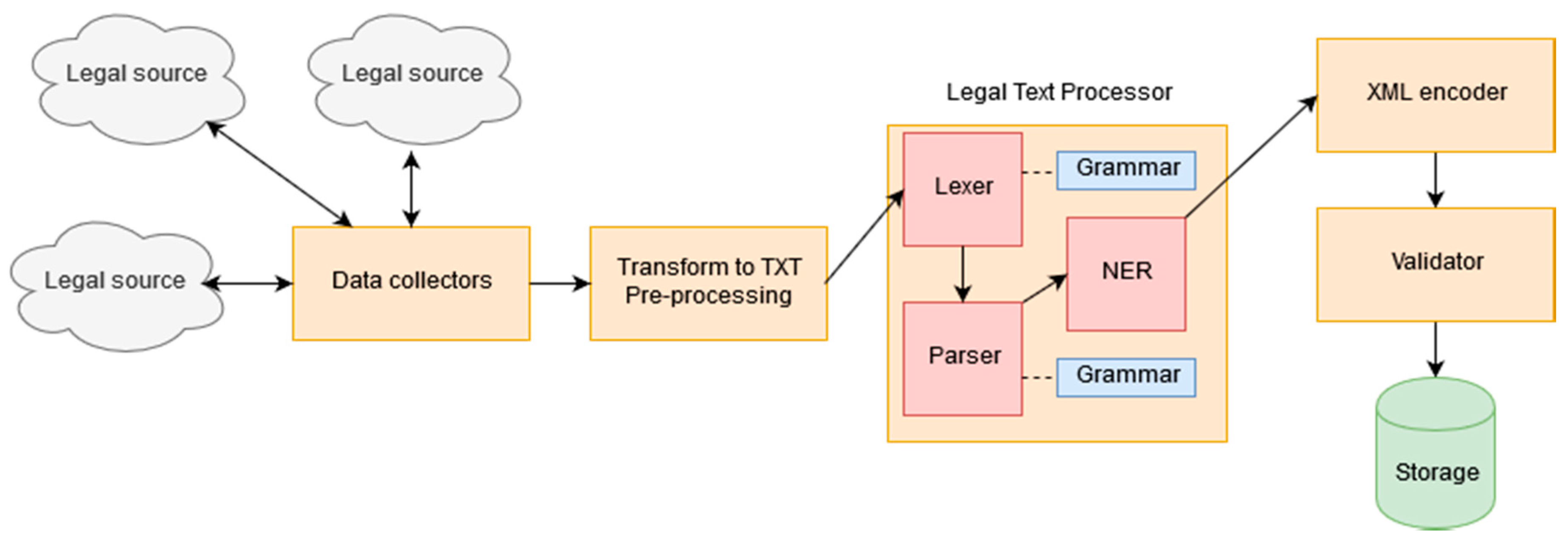
6. Legal Language Processing
6.1. Legal Structure Identification
- The lexer, which performs the lexical analysis (also known as tokenization) process on the input text. During this process a sequence of characters are converted into a sequence of tokens, which are then passed to the parser.
- The parser, which performs syntactic analysis of the input text, based on the tokens sequence of the lexical analysis and the parser grammar, transforming it to a structured representation, such as a parse tree.
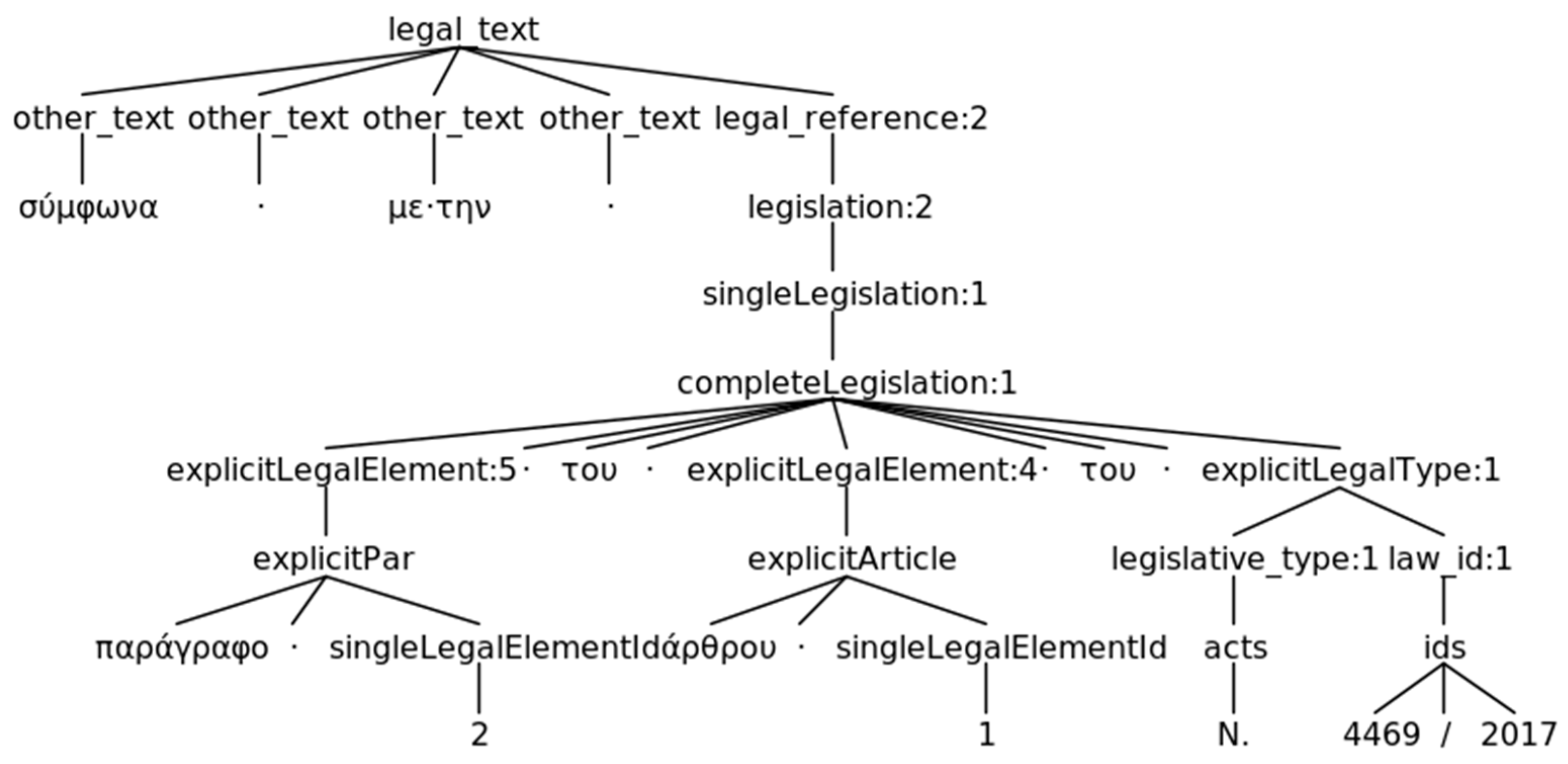
6.2. Legal References Extraction
6.3. Named Entity Recognition
7. Components’ Integration and Documents Transformation
8. Evaluation Results
9. Discussion
10. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bing, J. Celebrating Gnaeus Flavius and Open Access to Law. J. Open Access Law 2013, 1, 1. [Google Scholar]
- Peruginelli, G. Law Belongs to the People: Access to Law and Justice. Leg. Inf. Manag. 2016, 16, 107–110. [Google Scholar] [CrossRef]
- Greenleaf, G.; Mowbray, A.; Chung, P. The Meaning of “Free Access to Legal Information”: A Twenty Year Evolution. J. Open Access Law 2013, 1. [Google Scholar] [CrossRef] [Green Version]
- Agnoloni, T.; Sagri, M.T.; Tiscornia, D. Opening Public Data: A Path towards Innovative Legal Services. 2011. Available online: www.hklii.hk/conference/paper/2D2.pdf (accessed on 21 December 2019).
- Wass, C. openlaws.eu–Building Your Personal Legal Network. J. Open Access Law 2017, 5, 1. [Google Scholar]
- Custers, B. Methods of data research for law. In Research Handbook in Data Science and Law; Edward Elgar Publishing: Cheltenham, UK, 2018. [Google Scholar]
- Casanovas, P.; Palmirani, M.; Peroni, S.; van Engers, T.; Vitali, F. Semantic Web for the Legal Domain: The next step. Semantic Web 2016, 7, 213–227. [Google Scholar] [CrossRef] [Green Version]
- Janssen, M.; Charalabidis, Y.; Zuiderwijk, A. Benefits, Adoption Barriers and Myths of Open Data and Open Government. Inf. Syst. Manag. 2012, 29, 258–268. [Google Scholar] [CrossRef] [Green Version]
- Janssen, M.; Matheus, R.; Longo, J.; Weerakkody, V. Transparency-by-design as a foundation for open government. Transform. Gov. People Process Policy 2017, 11, 2–8. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Janssen, M.; Choenni, S.; Meijer, R.; Alibaks, R.S. Socio-technical Impediments of Open Data. Electron. J. E-Gov. 2012, 10, 156–172. [Google Scholar]
- Palmirani, M.; Vitali, F. Legislative drafting systems. In Usability in Government Systems; Elsevier: Amsterdam, The Netherlands, 2012; pp. 133–151. [Google Scholar]
- Sannier, N.; Adedjouma, M.; Sabetzadeh, M.; Briand, L.; Dann, J.; Hisette, M.; Thill, P. Legal Markup Generation in the Large: An Experience Report. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; pp. 302–311. [Google Scholar]
- Dragoni, M.; Villata, S.; Rizzi, W.; Governatori, G. Combining NLP Approaches for Rule Extraction from Legal Documents. In Proceedings of the 1st Workshop on MIning and REasoning with Legal texts (MIREL 2016), Sophia Antipolis, France, 16 December 2016. [Google Scholar]
- Gibbons, J.P. Language and the Law; Routledge: Abingdon, UK, 2014; ISBN 978-1-315-84432-9. [Google Scholar]
- Nazarenko, A.; Wyner, A. Legal NLP Introduction. TAL 2017, 58, 7–19. [Google Scholar]
- Boella, G.; Di Caro, L.; Graziadei, M.; Cupi, L.; Salaroglio, C.E.; Humphreys, L.; Konstantinov, H.; Marko, K.; Robaldo, L.; Ruffini, C.; et al. Linking Legal Open Data: Breaking the Accessibility and Language Barrier in European Legislation and Case Law. In Proceedings of the 15th International Conference on Artificial Intelligence and Law, San Diego, CA, USA, 8–12 June 2015; ACM: New York, NY, USA, 2015; pp. 171–175. [Google Scholar]
- Virkar, S.; Udokwu, C.; Novak, A.-S.; Tsekeridou, S. Facilitating Public Access to Legal Information. In Proceedings of the 2nd International Data Science Conference, iDSC2019, Puch/Salzburg, Austria, 22–24 May 2019; pp. 77–82. [Google Scholar]
- Cifuentes-Silva, F.; Labra Gayo, J.E. Legislative Document Content Extraction Based on Semantic Web Technologies. In Proceedings of the Semantic Web, ESWC 2019, Portorož, Slovenia, 2–6 June 2019; pp. 558–573. [Google Scholar]
- Chalkidis, I.; Nikolaou, C.; Soursos, P.; Koubarakis, M. Modeling and Querying Greek Legislation Using Semantic Web Technologies. In Proceedings of the Semantic Web, ESWC 2017, Portorož, Slovenia, 28 May–1 June 2017; pp. 591–606. [Google Scholar]
- Koniaris, M.; Papastefanatos, G.; Anagnostopoulos, I. Solon: A Holistic Approach for Modelling, Managing and Mining Legal Sources. Algorithms 2018, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Charalabidis, Y.; Zuiderwijk, A.; Alexopoulos, C.; Janssen, M.; Lampoltshammer, T.; Ferro, E. The Multiple Life Cycles of Open Data Creation and Use. In The World of Open Data: Concepts, Methods, Tools and Experiences; Charalabidis, Y., Zuiderwijk, A., Alexopoulos, C., Janssen, M., Lampoltshammer, T., Ferro, E., Eds.; Springer: Cham, Switzerland, 2018; pp. 11–31. [Google Scholar]
- Zuiderwijk, A.; Janssen, M.; Davis, C. Innovation with open data: Essential elements of open data ecosystems. Inf. Polity 2014, 19, 17–33. [Google Scholar] [CrossRef] [Green Version]
- Charalabidis, Y.; Alexopoulos, C.; Loukis, E. A taxonomy of open government data research areas and topics. J. Organ. Comput. Electron. Commer. 2016, 26, 41–63. [Google Scholar] [CrossRef]
- Lnenicka, M.; Komarkova, J. Big and open linked data analytics ecosystem: Theoretical background and essential elements. Gov. Inf. Q. 2019, 36, 129–144. [Google Scholar] [CrossRef]
- Garofalakis, J.; Plessas, K.; Plessas, A.; Spiliopoulou, P. A Project for the Transformation of Greek Legal Documents into Legal Open Data. In Proceedings of the 22nd Pan-Hellenic Conference on Informatics, Athens, Greece, 29 November–1 December 2018; pp. 144–149. [Google Scholar]
- Francesconi, E. A Review of Systems and Projects: Management of Legislative Resources. In Legislative XML for the Semantic Web: Principles, Models, Standards for Document Management; Sartor, G., Palmirani, M., Francesconi, E., Biasiotti, M.A., Eds.; Springer: Dordrecht, The Netherlands, 2011; pp. 173–188. [Google Scholar]
- Van Opijnen, M. The EU Council Conclusions on the Online Publication of Court Decisions. In Knowledge of the Law in the Big Data Age; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2019; pp. 81–90. [Google Scholar]
- Pełech-Pilichowski, T.; Cyrul, W.; Potiopa, P. On Problems of Automatic Legal Texts Processing and Information Acquiring from Normative Acts. In Advances in Business ICT; Mach-Król, M., Pełech-Pilichowski, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 53–67. [Google Scholar]
- Palmirani, M.; Vitali, F. Akoma-Ntoso for Legal Documents. In Legislative XML for the Semantic Web: Principles, Models, Standards for Document Management; Sartor, G., Palmirani, M., Francesconi, E., Biasiotti, M.A., Eds.; Springer: Dordrecht, The Netherlands, 2011; pp. 75–100. [Google Scholar]
- Boer, A.; van Engers, T. A MetaLex and Metadata Primer: Concepts, Use, and Implementation. In Legislative XML for the Semantic Web: Principles, Models, Standards for Document Management; Sartor, G., Palmirani, M., Francesconi, E., Biasiotti, M.A., Eds.; Springer: Dordrecht, the Netherlands, 2011; pp. 131–149. [Google Scholar]
- Biasiotti, M.; Francesconi, E.; Palmirani, M.; Sartor, G.; Vitali, F. Legal Informatics and Management of Legislative Documents; Global Centre for ICT in Parliament Working Paper No. 2; IPU: Geneva, Switzerland, 2008. [Google Scholar]
- Tillett, B. What is FRBR? A conceptual model for the bibliographic universe. Aust. Libr. J. 2005, 54, 24–30. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Jeffery, K.; Janssen, M. The Potential of Metadata for Linked Open Data and its Value for Users and Publishers. JeDEM 2012, 4, 222–244. [Google Scholar] [CrossRef] [Green Version]
- Barabucci, G.; Cervone, L.; Palmirani, M.; Peroni, S.; Vitali, F. Multi-layer Markup and Ontological Structures in Akoma Ntoso. In Proceedings of the International Workshop on AI Approaches to the Complexity of Legal Systems. Complex Systems, the Semantic Web, Ontologies, Argumentation, and Dialogue, Beijing, China, 19 September 2009; pp. 133–149. [Google Scholar]
- Van Opijnen, M. European Case Law Identifier: Indispensable Asset for Legal Information Retrieval. In Proceedings of the Workshop: From Information to Knowledge—Online Access to Legal Information, Florence, Italy, 6 May 2011; pp. 91–103. [Google Scholar]
- Sandoval, A.M. Text Analytics: the convergence of Big Data and Artificial Intelligence. Int. J. Interact. Multimed. Artif. Intell. 2016, 3, 57–64. [Google Scholar]
- Venturi, G. Legal Language and Legal Knowledge Management Applications. In Semantic Processing of Legal Texts: Where the Language of Law Meets the Law of Language; Francesconi, E., Montemagni, S., Peters, W., Tiscornia, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 3–26. [Google Scholar]
- Strembeck, M.; Zdun, U. An approach for the systematic development of domain-specific languages. Softw. Pract. Exp. 2009, 39, 1253–1292. [Google Scholar] [CrossRef] [Green Version]
- Parr, T.; Harwell, S.; Fisher, K. Adaptive LL(*) Parsing: The Power of Dynamic Analysis. In Proceedings of the 2014 ACM International Conference on Object Oriented Programming Systems Languages & Applications, Portland, OR, USA, 20–24 October 2014; pp. 579–598. [Google Scholar]
- Bacci, L.; Agnoloni, T.; Marchetti, C.; Battistoni, R. Improving Public Access to Legislation through Legal Citations Detection: The Linkoln Project at the Italian Senate. In Proceedings of the Law via the Internet 2018, Florence, Italy, 11–12 October 2018; pp. 149–158. [Google Scholar]
- Agnoloni, T.; Venturi, G. Semantic Processing of Legal Texts. In Handbook of Communication in the Legal Sphere; De Gruyter Mouton: Berlin, Germany/Boston, MA, USA, 2018. [Google Scholar]
- Sannier, N.; Adedjouma, M.; Sabetzadeh, M.; Briand, L. An automated framework for detection and resolution of cross references in legal texts. Requir. Eng. 2017, 22, 215–237. [Google Scholar] [CrossRef] [Green Version]
- Stenetorp, P.; Pyysalo, S.; Topić, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. BRAT: A Web-based Tool for NLP-assisted Text Annotation. In Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 102–107. [Google Scholar]
- De Maat, E.; Winkels, R.; van Engers, T. Automated Detection of Reference Structures in Law. In Proceedings of the 19th Annual Conference on Legal Knowledge and Information Systems: JURIX 2006, Paris, France, 7–9 December 2006; pp. 41–50. [Google Scholar]
- Giouli, V.; Konstandinidis, A.; Desypri, E.; Papageorgiou, H. Multi-domain Multi-lingual Named Entity Recognition: Revisiting & Grounding the resources issue. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy, 24–26 May 2006. [Google Scholar]
- Tange, O. GNU Parallel 2018. Available online: https://zenodo.org/record/1146014#.Xf2abI8RVPY (accessed on 21 December 2019).
- Charalabidis, Y.; Zuiderwijk, A.; Alexopoulos, C.; Janssen, M.; Lampoltshammer, T.; Ferro, E. Open Data Value and Business Models. In The World of Open Data: Concepts, Methods, Tools and Experiences; Charalabidis, Y., Zuiderwijk, A., Alexopoulos, C., Janssen, M., Lampoltshammer, T., Ferro, E., Eds.; Springer: Cham, Switzerland, 2018; pp. 115–136. [Google Scholar]
- The Open Data Barometer, 4th ed.; World Wide Web Foundation: Washington, DC, USA, 2017.
- Marsden, C. Twenty Years of the Public Internet: Assessing Online Developments in Good Law and Better Regulation. In Proceedings of the Law via the Internet 2013, Jersey (Channel Islands), UK, 26–27 September 2013. [Google Scholar]
- Van Loenen, B.; Vancauwenberghe, G.; Crompvoets, J.; Dalla Corte, L. Open Data Exposed. In Open Data Exposed; van Loenen, B., Vancauwenberghe, G., Crompvoets, J., Eds.; T.M.C. Asser Press: The Hague, The Netherlands, 2018; pp. 1–10. [Google Scholar]
- Opijnen, M. The European Legal Semantic Web: Completed Building Blocks and Future Work. In Proceedings of the European Legal Access Conference, Paris, France, 21–23 November 2012. [Google Scholar]
- Chiticariu, L.; Li, Y.; Reiss, F.R. Rule-Based Information Extraction is Dead! Long Live Rule-Based Information Extraction Systems! In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 827–832. [Google Scholar]
- Munné, R. Big Data in the Public Sector. In New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe; Cavanillas, J.M., Curry, E., Wahlster, W., Eds.; Springer: Cham, Switzerland, 2016; pp. 195–208. [Google Scholar]
- Tiscornia, D.; Fernández-Barrera, M. Knowing the Law as a Prerequisite to Participative eGovernment: The Role of Semantic Technologies. In Empowering Open and Collaborative Governance: Technologies and Methods for Online Citizen Engagement in Public Policy Making; Charalabidis, Y., Koussouris, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 119–138. [Google Scholar]
- Van Opijnen, M.; Peruginelli, G.; Kefali, E.; Palmirani, M. Online Publication of Court Decisions in Europe. Leg. Inf. Manag. 2017, 17, 136–145. [Google Scholar] [CrossRef] [Green Version]
- Angelidis, I.; Chalkidis, I.; Koubarakis, M. Named Entity Recognition, Linking and Generation for Greek Legislation. In Proceedings of the Thirty-first Annual Conference on Legal Knowledge and Information Systems, JURIX 2018, Groningen, The Netherlands, 12–14 December 2018; pp. 1–10. [Google Scholar]
- Garofalakis, J.; Plessas, K.; Plessas, A.; Spiliopoulou, P. Modelling Legal Documents for Their Exploitation as Open Data. In Proceedings of the 22nd International Conference on Business Information Systems, Seville, Spain, 26–28 June 2019; pp. 30–44. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Extended Open Data Lifecycle [23] | Our Methodology | BOLD Analytics Lifecycle [24] |
|---|---|---|
| Create/Gather | 1. Identify online sources of legal documents | Acquisition and extraction |
| 2. Collect documents | ||
| Pre-process | 3. Transform to plain text | Management and Preparation |
| 4. Modelling | ||
| Curate | 5. Transform to structured format | |
| Store | 6. Store | Storage and Archiving |
| Processing and Analysis | ||
| Visualization and Use | ||
| Publish | 7. Publish | Publication, Sharing and Reuse |
| ECLI Metadata Element | Akoma Ntoso Metadata Element or Default Value |
|---|---|
| dcterms:identifier | The URL from which the text of the decision can be retrieved |
| dcterms:isVersionOf | The ECLI (<FRBRwork> → <FRBRalias>) |
| dcterms:creator | <FRBRWork> → <FRBRauthor> |
| dcterms:coverage | <FRBRWork> → <FRBRcountry> |
| dcterms:date | <FRBRWork> → <FRBRdate> |
| dcterms:language | <FRBRExpression> → <FRBRlanguage> |
| dcterms:publisher | <FRBRWork> → <FRBRauthor> |
| dcterms:accessRights | “public” |
| dcterms:type | “judgment” |
| Number of Documents | Number of Words | Mean Number of Words Per Document | |
|---|---|---|---|
| Supreme Civil and Criminal Court | 25 | 54278 | 2171 |
| Council of State | 25 | 50112 | 2004 |
| Legal Council | 25 | 86374 | 3454 |
| Total | 75 | 190764 | 2543 |
| Lexer Rule | English Translation | Description |
|---|---|---|
| NEXT_LINE: '\n' | '\r' | Line break | |
| NUM: [0–9]+ | Numerical sequence | |
| DOT: '.' | Dot | |
| COMMA: ',' | Comma | |
| OUTCOME: Απορρίπτει' | 'Δέχεται' (SPACE 'εν' SPACE 'μέρει')? | 'Αναβάλλει' | 'Παραπέμπει' | 'Αναιρεί' | 'Καταδικάζει' | OUTCOME: 'Rejects' | 'Accepts' (SPACE 'partially')? | 'Postpones' | 'Refers' | 'Overturns' | 'Condemns' | Token representing the outcome of the court’s decision (e.g., dismiss, approve, remit etc.) |
| HISTORY_HEADER: 'Σύντομο' SPACE 'Ιστορικό' | 'Ιστορικό' SPACE 'Ερωτήματος' | 'Σύντομο Ιστορικό' | 'Ιστορικό' | 'Ανάλυση' | 'Ιστορικό' SPACE 'της' SPACE 'υπόθεσης' | HISTORY_HEADER: 'Brief' SPACE 'History' | 'Question' SPACE 'History' | 'History' | 'Analysis' | 'Background of' SPACE 'the' SPACE 'case' | Phrases used to indicate the header of the legal opinions’ section containing the history/background of the case that led the administrative body to submit an official question (e.g., History, Short History, History of the case, Analysis etc.). |
| Rule | Syntax Diagram |
|---|---|
| judgment |  |
| judgmentBody | 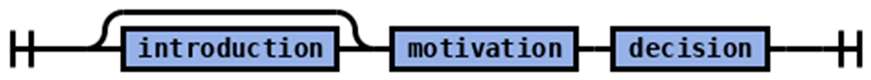 |
| decision |  |
| decisionPar |  |
| outcome (English translation in Table 4) |  |
| Rule | Syntax Diagram |
|---|---|
| judgment | 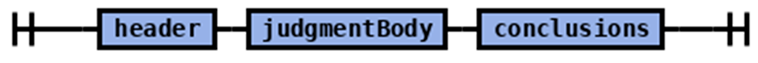 |
| judgmentBody |  |
| background |  |
| Background Division Paragraph |  |
| Background Division ParagraphNum |  |
| Reference Classification | Example | ||
|---|---|---|---|
| Complete | Complex | Multi-valued | articles 12 and 13 of law 4386/2017 |
| Multi-layered | paragraph 2 of article 1 of law 4469/2017 | ||
| Simple | according to law 4554/2018 | ||
| Incomplete | Complex | Multi-valued | the two previous paragraphs were modified |
| Multi-layered | taking into account the second paragraph of the same article | ||
| Simple | the same article states | ||
| Type of Documents | # of Refs | # of Simple Refs | # of Complex Refs | # of Complete Refs | # of Incomplete Refs |
|---|---|---|---|---|---|
| Decisions of the Council of State | 815 | 447 | 368 | 486 | 329 |
| Decisions of the Supreme Civil and Criminal Court | 718 | 319 | 399 | 492 | 226 |
| Legal Opinions | 1631 | 837 | 794 | 1051 | 580 |
| Total | 3164 | 1603 | 1561 | 2029 | 1135 |
| Rule Name | Rule Content |
|---|---|
| completeLegislation | explicitLegalElement OF SPACE explicitLegalElement OF SPACE explicitLegalType |
| explicitLegalElement | explicitPart|explicitChapter|explicitArticle|explicitPar|explicitSubPar|explicitCase|explicitAlinea|explicitPoint |
| explicitPar | PAR_TEXT SPACE? (multipleLegalElementIds|singleLegalElementId|range_id) |
| explicitArticle | ARTICLE_TEXT SPACE? (multipleLegalElementIds|singleLegalElementId|range_id) |
| singleLegalElementId | NUM|GREEK_NUM|TEXTUAL_NUM |
| explicitLegalType | legislative_type SPACE? (OF SPACE)? law_id|law_id SPACE legislative_type |
| legal_id | ids | ALL_CHARS SLASH NUM |
| ids | NUM SPACE? SLASH SPACE? NUM |
| legislative_type | acts | presidential_decree | compulsory_law | decree_law | decree | royal_decree |
| PAR_TEXT | 'paragraph' | 'paragraphs' | 'par.' | '§' | '§§' |
| ARTICLE_TEXT | 'article' | 'articles' | 'art.' | 'ar.' |
| NUM | [0–9]+ |
| Element | Recognition Method | Remarks |
|---|---|---|
| <doctype> | ANTLR Grammar | The type of document (e.g,. legal opinion) |
| <docProponent> | ANTLR Grammar | The issuing authority (e.g., Council of State) |
| <docNumber> | ANTLR Grammar | The number of the decision or opinion |
| <person> | ILSP NER component | Elements connected to the abstract Top Level Classes (TLCPerson, TLCOrganization, TLCLocation) with the refersTo attribute |
| <organization> | ILSP NER component | |
| <location> | ILSP NER component | |
| <date> | Regular expressions | Court conference date, public hearing date and decision publication date. Connected with the TLCEvent classes and the steps of the judiciary process of the <workflow> metadata element |
| <outcome> | ANTLR Grammar | The outcome of the decision, found within the <decision> element (e.g., dismiss, approve, remit etc.) |
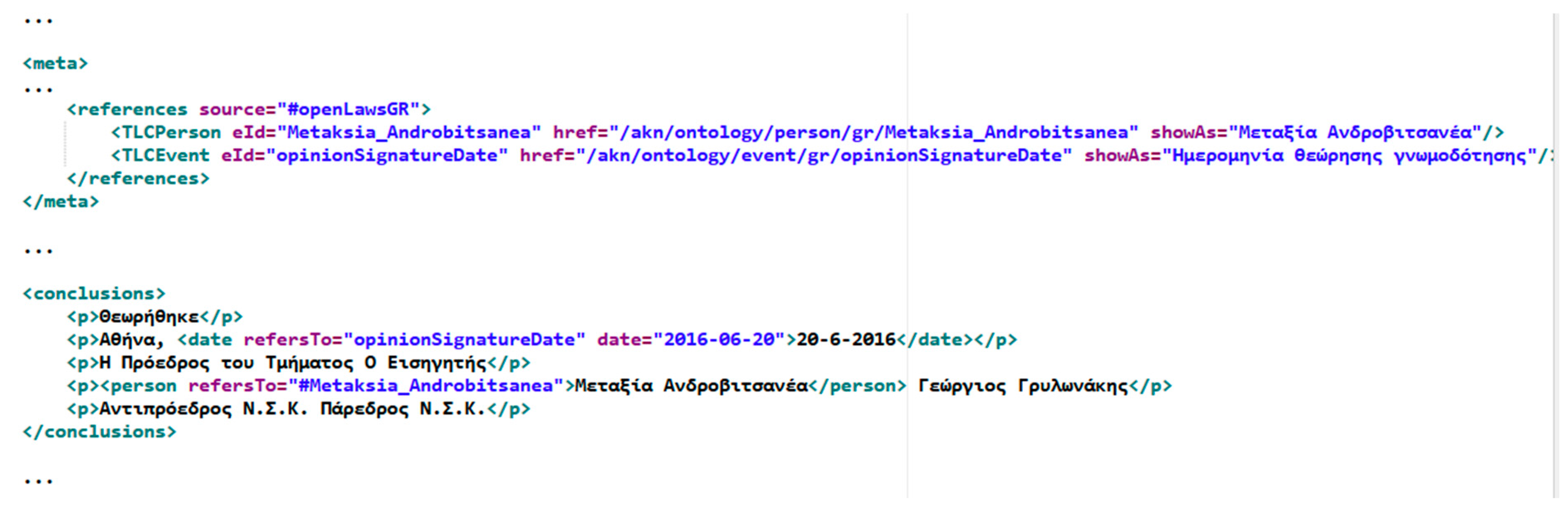
| Sample Decision’s Akoma Ntoso Markup |
|---|
| <?xml version = '1.0' encoding = 'UTF-8'?> |
| <akomaNtoso xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xmlns = "http://docs.oasis-open.org/legaldocml/ns/akn/3.0" xsi:schemaLocation = "http://docs.oasis-open.org/legaldocml/akn-core/v1.0/os/part2-specs/schemas/akomantoso30.xsd"> |
| <judgment name = "decision"> |
| <meta> |
| <identification source = "#openLawsGR"> |
| <FRBRWork> |
| <FRBRthis value = "/akn/gr/judgment/SCCC/2013/1294/!main"/> |
| <FRBRuri value = "/akn/gr/judgment/SCCC/2013/1294/"/> |
| <FRBRdate name = "" date = "2013-10-31"/> |
| <FRBRauthor href="#SCCC"/> |
| <FRBRcountry value = "gr"/> |
| </FRBRWork> |
| <FRBRExpression> |
| <FRBRthis value = "/akn/gr/judgment/SCCC/2013/1294/ell@/!main"/> |
| <FRBRuri value = "/akn/gr/judgment/SCCC/2013/1294/ell@"/> |
| <FRBRdate name = "" date = "2013-10-31"/> |
| <FRBRauthor href = "#SCCC"/> |
| <FRBRlanguage language = "ell"/> |
| </FRBRExpression> |
| <FRBRManifestation> |
| <FRBRthis value = "/akn/gr/judgment/SCCC/2013/1294/ell@/!main.xml"/> |
| <FRBRuri value = "/akn/gr/judgment/SCCC/2013/1294/[email protected]"/> |
| <FRBRdate date = "2019-11-05" name = "XMLConversion"/> |
| <FRBRauthor href = "#openLawsGR"/> |
| </FRBRManifestation> |
| </identification> |
| <lifecycle source = "#openLawsGR"> |
| <eventRef date = "2019-11-05" source = "#original" type = "generation"/> |
| </lifecycle> |
| <workflow source = "#openLawsGR"> |
| <step by = "#SCCC" date = "2013-10-31" refersTo = "#courtConferenceDate"/> |
| <step by = "#SCCC" date = "2013-10-31" refersTo = "#decisionPublicationDate"/> |
| <step by="#SCCC" date = "2013-10-08" refersTo = "#publicHearingDate"/> |
| </workflow> |
| <references source = "#openLawsGR"> |
| <original eId = "original" href = "/akn/gr/judgment/SCCC/2013/1294/ell@" showAs = "Original"/> |
| <TLCOrganization eId = "dikastirio_areios_pagos" href = "/akn/ontology/organization/gr/dikastirio_areios_pagos" showAs = "ΤΟ ΔΙΚΑΣΤΗΡΙΟ ΤΟΥ ΑΡΕΙΟΥ ΠΑΓΟΥ"/> |
| <TLCPerson eId = "Grigorios_Koytsopoylo" href = "/akn/ontology/person/gr/Grigorios_Koytsopoylo" showAs = "Γρηγόριο Κουτσόπουλο"/> |
| <TLCPerson eId = "Xaralampos_Athanasios" href="/akn/ontology/person/gr/Xaralampos_Athanasios" showAs="Χαράλαμπου Αθανασίου"/> |
| <TLCOrganization eId = "trimelis_plimmeleiodikeio_Athina" href = "/akn/ontology/organization/gr/trimelis_plimmeleiodikeio_Athina" showAs="Τριμελούς Πλημμελειοδικείου Αθηνών"/> |
| <TLCEvent eId = "publicHearingDate" href = "/akn/ontology/event/gr/publicHearingDate" showAs = "Ημερομηνία δημόσιας συνεδρίασης"/> |
| <TLCEvent eId = "decisionPublicationDate" href = "/akn/ontology/event/gr/decisionPublicationDate" showAs = "Ημερομηνία δημοσίευσης απόφασης"/> |
| <TLCEvent eId = "courtConferenceDate" href = "/akn/ontology/event/gr/courtConferenceDate" showAs = "Ημερομηνία διάσκεψης"/> |
| </references> |
| </meta> |
| <header> |
| <p>Αριθμός<docNumber>1294/2013</docNumber></p> |
| <p> |
| <docProponent> |
| <organization refersTo = "#dikastirio_areios_pagos">ΤΟ ΔΙΚΑΣΤΗΡΙΟ ΤΟΥ ΑΡΕΙΟΥ ΠΑΓΟΥ</organization> |
| </docProponent> |
| </p> |
| <p>ΣΤ' Ποινικό Τμήμα</p> |
| <p>Συγκροτήθηκε από τους Δικαστές: <person refersTo = "#Grigorios_Koytsopoylo">Γρηγόριο Κουτσόπουλο</person>, Αντιπρόεδρο Αρείου Πάγου, …</p> |
| <p>Συνήλθε σε δημόσια συνεδρίαση στο Κατάστημά του στις <date refers To = "publicHearingDate" date = "2013-10-08">8 Οκτωβρίου 2013</date> με την παρουσία του Αντεισαγγελέα του Αρείου Πάγου Νικολάου Παντελή (γιατί κωλύεται η Εισαγγελέας) και του Γραμματέως <person refersTo = "#Xaralampos_Athanasios">Χαράλαμπου Αθανασίου</person>, για να δικάσει την αίτηση του αναιρεσείοντος - κατηγορουμένου, Σ. Ν. του Ι., κατοίκου …, που δεν παραστάθηκε στο ακροατήριο, περί αναιρέσεως της <ref href = "/akn/gr/judgment/MagistrateCourtAthens/2012/60989/!main">60989/2012 αποφάσεως του <organization refers To = "#trimelis_plimmeleiodikeio_Athina">Τριμελούς Πλημμελειοδικείου Αθηνών</organization></ref>.</p> |
| </header> |
| <judgmentBody> |
| <introduction> |
| <p>Το Τριμελές Πλημμελειοδικείου Αθηνών, με την ως άνω απόφασή του διέταξε όσα λεπτομερώς αναφέρονται σ' αυτή και ο αναιρεσείων - κατηγορούμενος ζητεί την αναίρεση αυτής, για τους λόγους που αναφέρονται στην από 1 Απριλίου 2013 αίτησή του αναιρέσεως, η οποία καταχωρίστηκε στο οικείο πινάκιο με τον αριθμό 620/13.</p> |
| </introduction> |
| <motivation> |
| <p>Α φ ο ύ ά κ ο υ σ ε |
| Τον Αντεισαγγελέα που πρότεινε να απορριφθεί ως ανυποστήρικτη η προκείμενη αίτηση.</p> |
| <p>ΣΚΕΦΤΗΚΕ ΣΥΜΦΩΝΑ ΜΕ ΤΟ ΝΟΜΟ</p> |
| <blockList eId = "motivation_list_1"> |
| <item eId = "motivation_list_1__item_1"> |
| <num>1.</num> |
| <p>…</p> |
| </item> |
| <item eId = "motivation_list_1__item_2"> |
| <num>2.</num> |
| <p>Στην προκειμένη περίπτωση, όπως προκύπτει από το υπό ημερομηνία 18 Ιουνίου 2013 αποδεικτικό επίδοσης της επιμελήτριας Δικαστηρίων Εισαγγελίας του Αρείου Πάγου .ο αναιρεσείων κλητεύθηκε από τον Εισαγγελέα του Αρείου Πάγου νόμιμα και εμπρόθεσμα, για να εμφανισθεί στη συνεδρίαση που αναφέρεται στην αρχή της απόφασης αυτής, πλην όμως δεν εμφανίσθηκε κατ" αυτήν και την εκφώνηση της υπόθεσης ενώπιον του Δικαστηρίου τούτου. Κατά συνέπεια, η υπό κρίση αίτηση αναίρεσης πρέπει να απορριφθεί και να επιβληθούν στον αναιρεσείοντα τα δικαστικά έξοδο (<ref href = "/akn/gr/act/presidentialDecree/1986/258/!main#art_583__par_1">άρθρο 583 παρ. 1 Κ.Ποιν.Δ</ref>.)</p> |
| </item> |
| </blockList> |
| </motivation> |
| <decision> |
| <p>ΓΙΑ ΤΟΥΣ ΛΟΓΟΥΣ ΑΥΤΟΥΣ</p> |
| <p><outcome>Απορρίπτει</outcome>την από 1-4-2013 αίτηση του Σ. Ν. του Ι…..</p> |
| <p><outcome>Καταδικάζει</outcome> τον αναιρεσείοντα στα δικαστικά έξοδα που ανέρχονται σε διακόσια πενήντα (250) ευρώ.</p> |
| </decision> |
| </judgmentBody> |
| <conclusions> |
| <p>Κρίθηκε και αποφασίσθηκε στην Αθήνα στις <date refersTo = "courtConferenceDate" date = "2013-10-31">31 Οκτωβρίου 2013</date> . Και</p> |
| <p>Δημοσιεύθηκε στην Αθήνα, σε δημόσια συνεδρίαση στο ακροατήριό του, στις <date refers To = "decisionPublicationDate" date = "2013-10-31">31 Οκτωβρίου 2013</date>.</p> |
| <p>Ο ΑΝΤΙΠΡΟΕΔΡΟΣ Ο ΓΡΑΜΜΑΤΕΑΣ</p> |
| </conclusions> |
| </judgment> |
| </akomaNtoso> |
| Number of Documents | Number of Words | Mean Number of Words Per Document | |
|---|---|---|---|
| Supreme Civil and Criminal Court | 25 | 51914 | 2076 |
| Council of State | 25 | 39840 | 1593 |
| Legal Council | 25 | 86305 | 3452 |
| Total | 75 | 178059 | 2374 |
| # of Basic Structural Elements | # of FC Structural Elements | # of PC Structural Elements | # of M Structural Elements | |
|---|---|---|---|---|
| Supreme Civil and Criminal Court | 148 | 139 | 8 | 1 |
| Council of State | 150 | 150 | 0 | 0 |
| Legal Council | 136 | 120 | 10 | 6 |
| Total | 434 | 409 | 18 | 7 |
| # of Simple Refs | # of Correct Simple Refs | # of Complex Refs | # of Correct Complex Refs | # of Total Refs | # of Correct Refs | # of False Positives | |
|---|---|---|---|---|---|---|---|
| Supreme Civil and Criminal Court | 138 | 121 | 339 | 252 | 477 | 373 | 2 |
| Council of State | 105 | 99 | 210 | 165 | 315 | 264 | 3 |
| Legal Council | 243 | 216 | 633 | 503 | 876 | 719 | 1 |
| Total | 486 | 436 | 1182 | 920 | 1668 | 1356 | 6 |
| Precision | Recall | F1 Score | |
|---|---|---|---|
| Supreme Civil and Criminal Court | 99.47% | 78.20% | 87.56% |
| Council of State | 98.88% | 83.81% | 90.72% |
| Legal Council | 99.86% | 82.08% | 90.10% |
| Total | 99.56% | 81.29% | 89.50% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garofalakis, J.; Plessas, K.; Plessas, A.; Spiliopoulou, P. Application of an Ecosystem Methodology Based on Legal Language Processing for the Transformation of Court Decisions and Legal Opinions into Open Data. Information 2020, 11, 10. https://doi.org/10.3390/info11010010
Garofalakis J, Plessas K, Plessas A, Spiliopoulou P. Application of an Ecosystem Methodology Based on Legal Language Processing for the Transformation of Court Decisions and Legal Opinions into Open Data. Information. 2020; 11(1):10. https://doi.org/10.3390/info11010010
Chicago/Turabian StyleGarofalakis, John, Konstantinos Plessas, Athanasios Plessas, and Panoraia Spiliopoulou. 2020. "Application of an Ecosystem Methodology Based on Legal Language Processing for the Transformation of Court Decisions and Legal Opinions into Open Data" Information 11, no. 1: 10. https://doi.org/10.3390/info11010010