Spelling Correction of Non-Word Errors in Uyghur–Chinese Machine Translation

Abstract
:1. Introduction
2. Background
- Step 1.
- Use the shortest edit distance for misspelled words to find the most likely candidates.
- Step 2.
- The lower the PPL, the more likely the word is the correct word, using the n-Gram language model to select candidate sentences.
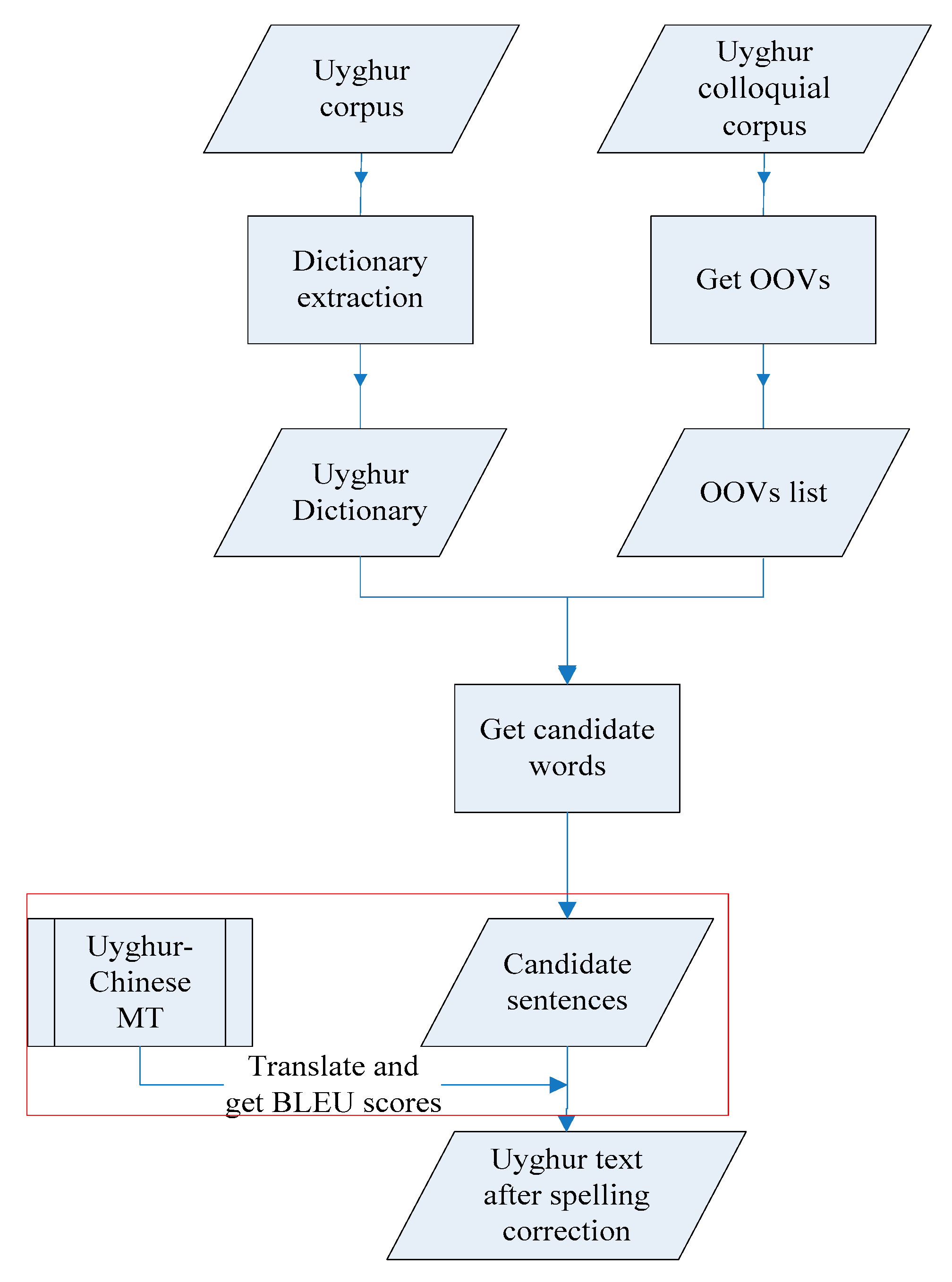
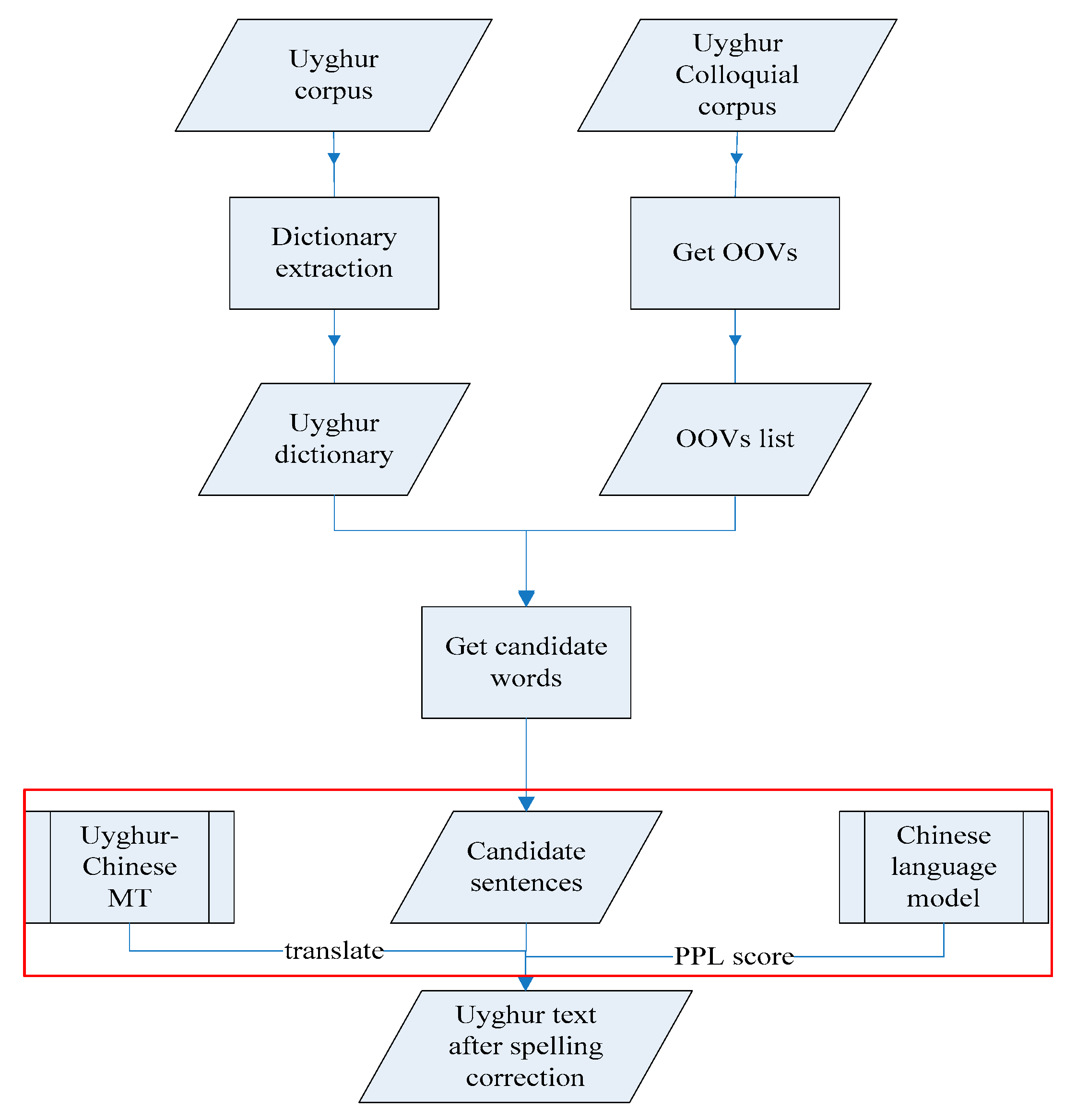
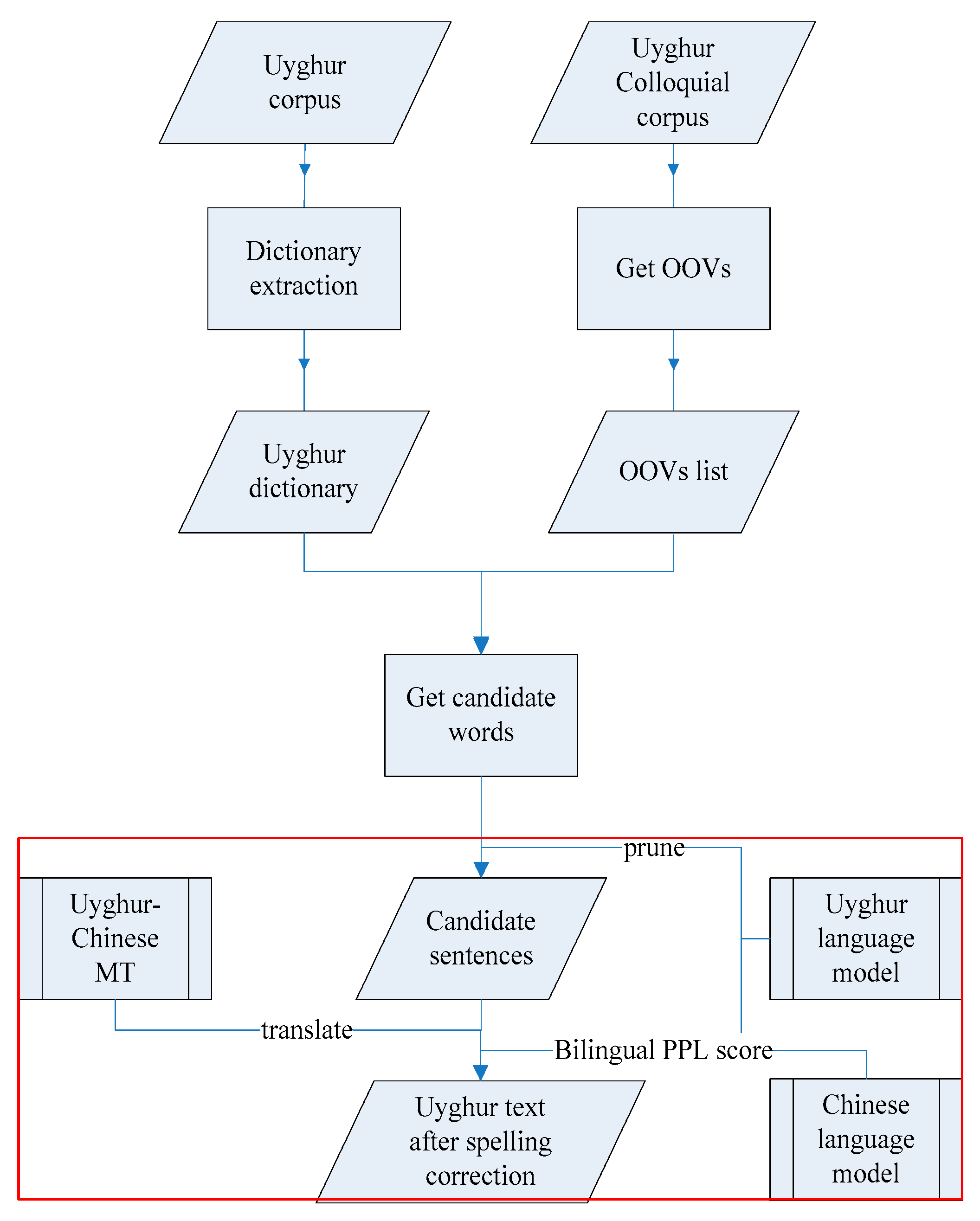
3. Using Uyghur–Chinese Machine Translation for Uyghur Spelling Correction
3.1. Using BLEU Score for Spelling Correction
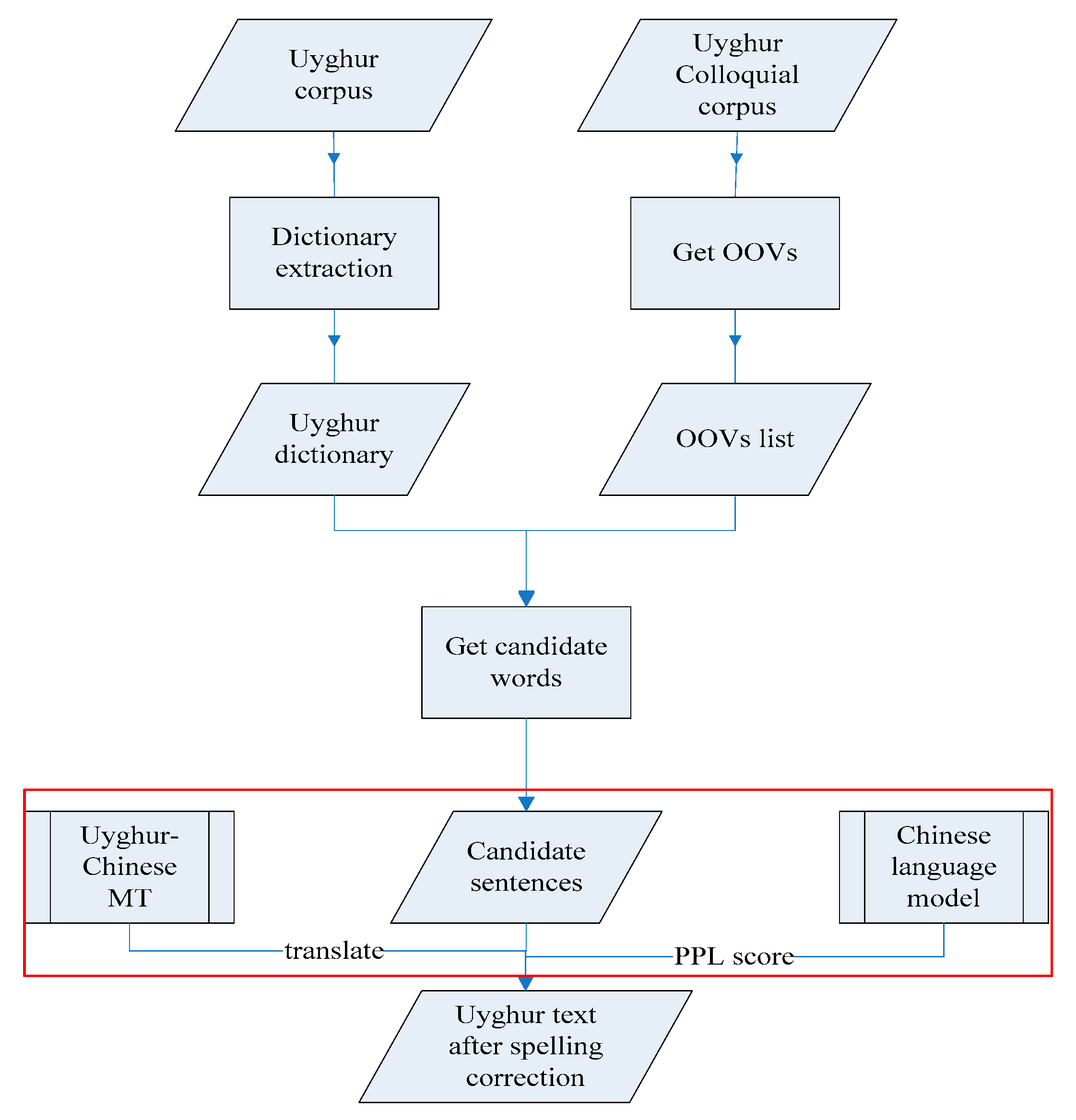
3.2. Using the Chinese Language Model for Spelling Correction
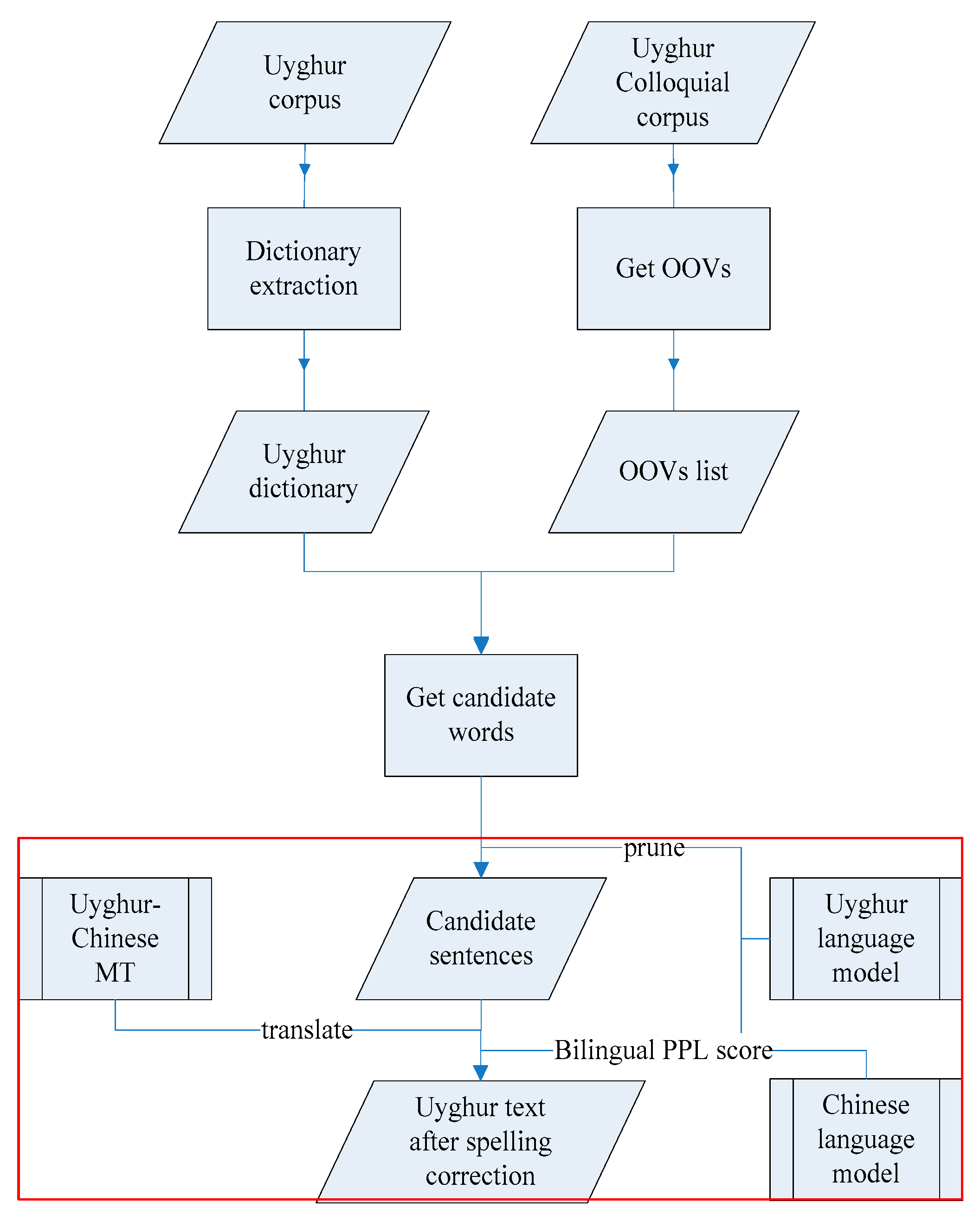
3.3. Using Bilingual Language Models for Spelling Correction
4. Corpus and Result
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, J.; Zhai, F.; Zong, C. Handling unknown words in statistical machine translation from a new perspective. In Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Zhang, J.J.; Zhai, F.F.; Zong, C.Q. A substitution-translation-restoration framework for handling unknown words in statistical machine translation. J. Comput. Sci. Technol. 2013, 28, 907–918. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Liu, A.; Kirchhoff, K. Context models for oov word translation in low-resource languages. arXiv 2018, arXiv:1801.08660 2018. [Google Scholar]
- Islam, N.; Ranga, K.K. A process to improve the accuracy of voice recognition system by using word correction system. Compusoft 2014, 3, 822. [Google Scholar]
- Damerau, F.J. A technique for computer detection and correction of spelling errors. Commun. ACM 1964, 7, 171–176. [Google Scholar] [CrossRef]
- Kernighan, M.D.; Church, K.W.; Gale, W.A. A spelling correction program based on a noisy channel model. In Proceedings of the 13th conference on Computational linguistics, Helsinki, Finland, 20–25 August 1990. [Google Scholar]
- Church, K.W.; Gale, W.A. Probability scoring for spelling correction. Stat. Comput. 1991, 1, 93–103. [Google Scholar] [CrossRef]
- Brill, E.; Moore, R.C. An improved error model for noisy channel spelling correction. In Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, Hong Kong, China, 3–6 October 2000; pp. 286–293. [Google Scholar]
- Pedler, J. Computer Correction of Real-Word Spelling Errors in Dyslexic Text. Ph.D. Thesis, University of London, London, UK, 2007. [Google Scholar]
- Choudhury, M.; Saraf, R.; Jain, V.; Mukherjee, A.; Sarkar, S.; Basu, A. Investigation and modeling of the structure of texting language. Int. J. Doc. Anal. Recognit. 2007, 10, 157–174. [Google Scholar] [CrossRef]
- Haddad, B.; Yaseen, M. Detection and correction of non-words in arabic: A hybrid approach. Int. J. Comput. Process. Orient. Lang. 2007, 20, 237–257. [Google Scholar] [CrossRef]
- Attia, M.; Pecina, P.; Samih, Y.; Shaalan, K.; Van Genabith, J. Arabic spelling error detection and correction. Nat. Lang. Eng. 2016, 22, 751–773. [Google Scholar] [CrossRef]
- Al-Jefri, M.M.; Mohammed, S.A. Arabic spell checking technique. U.S. Patent 9,037,967, 19 May 2015. [Google Scholar]
- Azgurli, L.; Yusuf, A. Corpus-based Uyghur text proofreading system principle. Inf. Comput. 2012, 12, 156–157. (In Chinese) [Google Scholar]
- Abdurexiti, R. Design and Implementation of Uyghur Word Auto-Proofreading System. Master’s Thesis, University of Electronic Science and Technology, Chengdu, China, 2013. (In Chinese). [Google Scholar]
- Maihefureti, A.W.; Aili, M.; Yibulayin, T.; Jian, Z.H.A.N.G. Spelling Check Method of Uyghur Languages Based on Dictionary and Statistics. J. Chin. Inf. Process. 2014, 28, 66–71. [Google Scholar]
- Mutula, M.; Gurinigar, M.; Mauridan, N.; Escale, A. Uygur Spelling Error Detection and Automatic Correction Based on Context Relation. In Proceedings of the 14th National Academic Conference on Man-Machine Speech Communication, Lianyungang, China, 11–13 October 2017. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| No. | Candidate Sentences | Uyghur LM PPL Scores | Translation Result | BLEU(2-Gram) | Chinese LM PPL Scores |
|---|---|---|---|---|---|
| 1 | axsham uxlap qaptikenmen sizge xet yazmaptu | 1247.37683387 | 昨晚睡觉了他没写信给你 | 30 | 39.4232909338 |
| 2 | axsham uxlap qaptikenmen sizge xet yazmapsiz | 1305.01848157 | 昨晚睡觉了你没写信给你 | 30 | 37.6604732108 |
| 3 | axsham uxlap qaptikenmen sizge xet yazattim | 1370.68035299 | 昨晚睡觉了我要写信给你 | 40 | 41.6196380647 |
| 4 | axsham uxlap qaptikenmen sizge xet yazmamtim | 1783.78385363 | 昨晚睡觉了yazmamtim信给你 | 37.5 | 270.052007821 |
| 5 | axsham uxlap qaptikenmen sizge xet yazmaptimen | 1796.53781059 | 昨晚睡觉了我没写信给你 | 70 | 35.522803018 |
| Corpus | Numbers |
|---|---|
| Parallel corpus | 692 |
| Uyghur words | 3993 |
| Number of sentences containing OOVs | 471 |
| Number of non-word errors | 312 |
| Methods | Precision | Recall | F1 |
|---|---|---|---|
| Using BLEU scores | 0.89 | 0.60 | 0.72 |
| Using Chinese LM PPL | 0.70 | 0.51 | 0.59 |
| Using Uyghur-Chinese LM PPL | 0.74 | 0.65 | 0.69 |
| Methods | BLEU |
|---|---|
| baseline | 11.67 |
| Using BLEU scores correct | 13.64(+1.97) |
| Using Chinese LM PPL | 12.72(+1.05) |
| Using Uyghur-Chinese LM PPL | 13.07(+1.4) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, R.; Yang, Y.; Jiang, T. Spelling Correction of Non-Word Errors in Uyghur–Chinese Machine Translation. Information 2019, 10, 202. https://doi.org/10.3390/info10060202
Dong R, Yang Y, Jiang T. Spelling Correction of Non-Word Errors in Uyghur–Chinese Machine Translation. Information. 2019; 10(6):202. https://doi.org/10.3390/info10060202
Chicago/Turabian StyleDong, Rui, Yating Yang, and Tonghai Jiang. 2019. "Spelling Correction of Non-Word Errors in Uyghur–Chinese Machine Translation" Information 10, no. 6: 202. https://doi.org/10.3390/info10060202
APA StyleDong, R., Yang, Y., & Jiang, T. (2019). Spelling Correction of Non-Word Errors in Uyghur–Chinese Machine Translation. Information, 10(6), 202. https://doi.org/10.3390/info10060202