Optimization and Security in Information Retrieval, Extraction, Processing, and Presentation on a Cloud Platform


Abstract
1. Introduction
2. Proposed Solution
2.1. General Overview
- The user can find product information pertaining to a single specific vertical.
- The overall number of crawled websites is rather small and known beforehand.
- The location in the webpage of the items that have to be extracted is determined manually for each website and is provided to the system in a configuration file.
- The search engine must be publicly available to the end-user.
2.2. System Architecture
2.3. Retrieve Action
2.4. Proposed Method for Representing the Crawler Configuration
- −
- database connection string—host, port, username, password, database name, and type;
- −
- minimum and maximum waiting times between crawls from the same site—a random value between that interval is chosen when retrieving each page;
- −
- recrawl interval/time—the recrawl takes place after a specified time from the last recrawl or at a specified time each day;
- −
- web service URL and credentials—used to upload the site and product information;
- −
- a list of site-specific parameters.
- −
- name, url, logoUrl—the site name, URL, and logo URL, which are needed by the presentation system component; the url property also serves as unique key for the purpose of determining if the site already exists in the database;
- −
- fetchUrlRegEx—regular expression used to determine if a URL is added to the database for retrieval;
- −
- seedList—list of webpages used to start the crawling process on that website;
- −
- extractor—an object describing the extraction parameters:
- −
- extractUrlRegEx—a regular expression denoting which pages contain extractable data;
- −
- baseSelector—a custom selector describing the in-page location of the information that needs to be extracted;
- −
- properties—an object with key-value pairs, where the key is the product feature name, and the value is a custom selector relative to the base selector and contains the feature value that is to be extracted;
- −
- uniqueKeyProperty—property name from the properties object that serves as a unique key for the purpose of uniquely identifying a product belonging to a website.
2.5. Extract Action
2.6. Proposed Method for Representing the Extractor Template
- −
- td.productlisting_price>.productSpecialPrice/td.productlisting_price>.pricereturns the text from the element that has the productSpecial class attribute, which has a <td> parent element with class productlisting_price; if there is no such element, then it returns the text from the element with class price, which has the same parent.
- −
- div.product-details>p.price%returns the text from element <p> with class price (not including the text from the child elements), which has a <div> parent with class product-details.
- −
- div.image>img%class=~outofstockreturns true if it is not outofstock, the value of the <img> element’s class attribute, which is a child of a <div> element with the class image.
- −
- div.name>a%abs:hrefreturns the absolute URL from the value of the href attribute of an <a> element having a parent of type <div> with class name.
2.7. Process Action
2.8. Present Action
2.9. Proposed Solution for Product Indexing
2.10. Security and Ethics
2.10.1. Crawler Security and Ethics
2.10.2. Presentation Layer Security
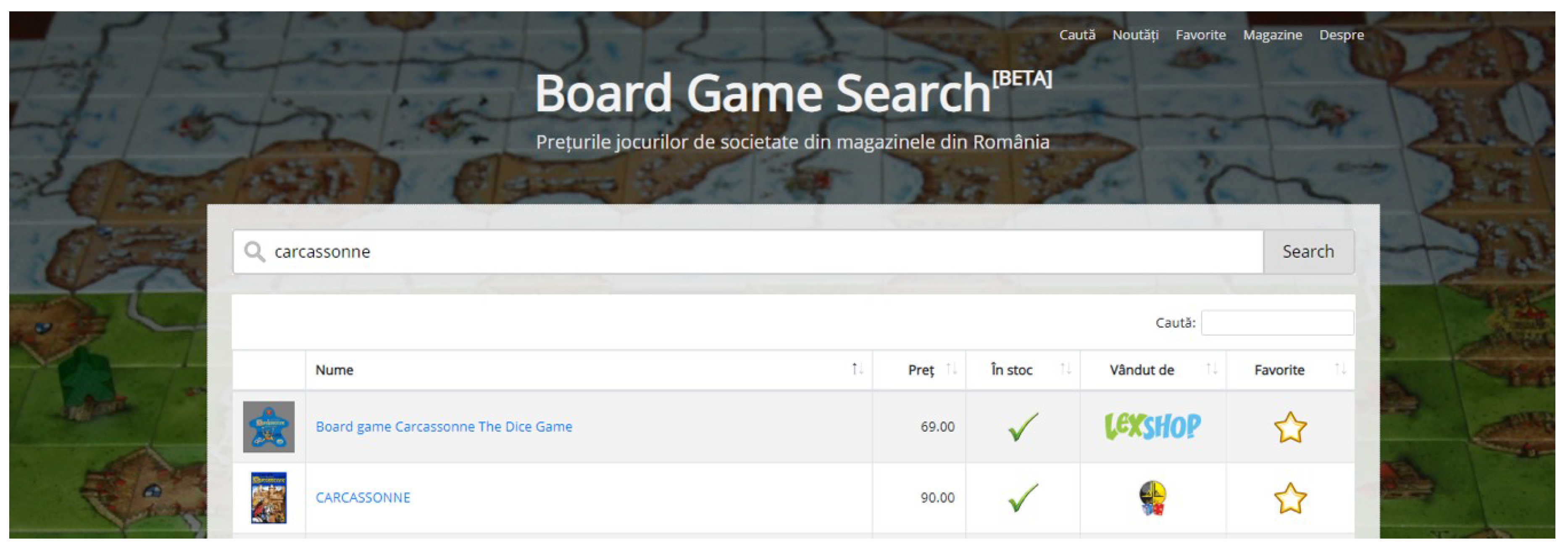
3. Use—Case Scenario and Results
{
“name”: “lexshop.ro”,
“url”: “https://www.lexshop.ro”,
“logoUrl”: “https://www.lexshop.ro/app/images/logo.png”,
“fetchUrlRegEx”: “\\Qhttps://www.lexshop.ro/?page=produse&categorie=8&n=\\E[0-9]*”,
“seedList”: [
“c8-board-games”
],
“extractor”: {
“extractUrlRegEx”: “\\Qhttps://www.lexshop.ro/?page=produse&categorie=8&n=\\E[0-9]*”,
“baseSelector”: “div.list-products>div>div>div[data-href]”,
“uniqueKeyProperty”: “url”,
“properties”: {
“url”: “div.product_img_container>a%abs:href”,
“name”: “div.prod_title_container>a”,
“image”: “div.product_img_container>a>img%abs:data-original”,
“price”: “div.prod_prices>span.actual_price”,
“availability”: “div.product_img_container>div.eticheta-stoc=~STOC EPUIZAT”
}
}
}
4. Discussion
- Similarities between shopping search engines that use retailer-provided feeds and the proposed solution
- Advantages of shopping search engines that use retailer-provided feeds vs. the proposed solution
- Advantages of the proposed solution vs. shopping search engines that use retailer-provided feeds
5. Conclusions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Barlogul cu jocuri | LeleGames | LexShop | Ludicus | Pionul | Red Goblin | Regatul jocurilor | Total | |
|---|---|---|---|---|---|---|---|---|
| Sum of page retrieval times | 43.05 | 43.90 | 185.60 | 106.81 | 27.38 | 211.78 | 947.70 | 1566.21 |
| Sum of link extraction times | 0.30 | 2.13 | 8.94 | 1.00 | 4.22 | 5.25 | 19.39 | 41.22 |
| Sum of product extraction times | 2.75 | 9.04 | 32.42 | 23.09 | 10.44 | 54.30 | 51.08 | 183.11 |
| Sum of server upload times | 0.44 | 4.84 | 47.50 | 10.63 | 7.31 | 24.19 | 52.24 | 147.14 |
| Sum of processing times | 46.53 | 59.91 | 274.46 | 141.53 | 49.34 | 295.51 | 1070.41 | 1937.68 |
| Average of page retrieval times | 4.78 | 1.83 | 0.78 | 5.09 | 0.76 | 2.75 | 2.13 | 1.84 |
| Average of link extraction times | 0.03 | 0.09 | 0.04 | 0.05 | 0.12 | 0.07 | 0.04 | 0.05 |
| Average of product extraction times | 0.31 | 0.38 | 0.14 | 1.10 | 0.29 | 0.71 | 0.11 | 0.22 |
| Average of server upload times | 0.05 | 0.20 | 0.20 | 0.51 | 0.20 | 0.31 | 0.12 | 0.17 |
| Average of processing times | 5.17 | 2.50 | 1.15 | 6.74 | 1.37 | 3.84 | 2.41 | 2.28 |
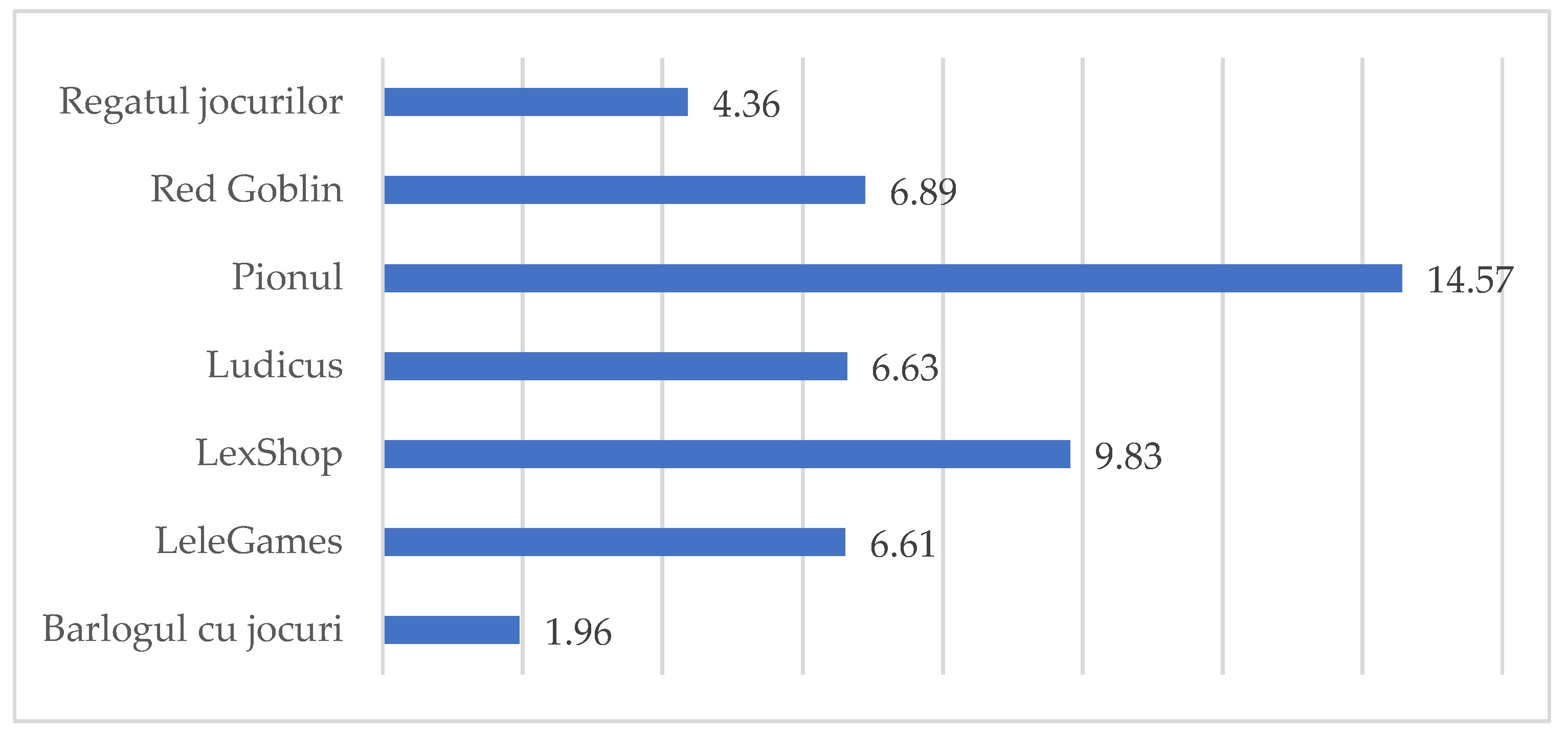
| Barlogul cu jocuri | LeleGames | LexShop | Ludicus | Pionul | Red Goblin | Regatul jocurilor | Total | |
|---|---|---|---|---|---|---|---|---|
| Sum of number of found links | 2065 | 4552 | 70682 | 5317 | 4858 | 65596 | 131527 | 284597 |
| Sum of number of found products | 103 | 432 | 2858 | 1246 | 719 | 4620 | 9151 | 19130 |
| Average of number of found links | 229 | 190 | 296 | 253 | 135 | 852 | 296 | 334 |
| Average of number of found products | 11 | 18 | 12 | 59 | 20 | 60 | 21 | 22 |
| Number of retrieved pages | 9 | 24 | 239 | 21 | 36 | 77 | 445 | 851 |
| Number of uniquely extracted products | 91 | 396 | 2697 | 939 | 719 | 2037 | 4672 | 11551 |
Appendix B

References
- The 10 Best Shopping Engines—Search Engine Watch Search Engine Watch. Available online: https://searchenginewatch.com/sew/study/2097413/shopping-engines (accessed on 4 October 2018).
- Lin, L.; He, Y.; Guo, H.; Fan, J.; Zhou, L.; Guo, Q.; Li, G. SESQ: A model-driven method for building object level vertical search engines. In Proceedings of the International Conference on Conceptual Modeling, Barcelona, Spain, 20–24 October 2008; Springer: Berlin, Germany, 2008; pp. 516–517. [Google Scholar]
- Ahmedi, L.; Abdurrahmani, V.; Rrmoku, K. E-Shop: A vertical search engine for domain of online shopping. In Proceedings of the 13th International Conference on Web Information Systems and Technologies, Porto, Portugal, 25–27 April 2017; pp. 376–381. [Google Scholar]
- Mahto, D.; Singh, L. A dive into Web Scraper world. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 689–693. [Google Scholar]
- Gogar, T.; Hubacek, O.; Sedivy, J. Deep Neural Networks for Web Page Information Extraction. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Thessaloniki, Greece, 16–18 September 2016; Springer: Cham, Germany, 2016; pp. 154–163. [Google Scholar]
- Kamanwar, N.V.; Kale, S.G. Web data extraction techniques: A review. In Proceedings of the 2016 World Conference on Futuristic Trends in Research and Innovation for Social Welfare (Startup Conclave), Coimbatore, India, 29 February–1 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Ferrara, E.; De Meo, P.; Fiumara, G.; Baumgartner, R. Web data extraction, applications and techniques: A survey. Knowl.-Based Syst. 2014, 70, 301–323. [Google Scholar] [CrossRef]
- Alexandrescu, A. A distributed framework for information retrieval, processing and presentation of data. In Proceedings of the 2018 22nd International Conference on System Theory, Control and Computing, ICSTCC 2018, Sinaia, Romania, 10–12 October 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Lampesberger, H. Technologies for web and cloud service interaction: A survey. Serv. Oriented Comput. Appl. 2016, 10, 71–110. [Google Scholar] [CrossRef]
- He, B.; Patel, M.; Zhang, Z.; Chang, K.C.-C. Accessing the deep web: A survey. Commun. ACM 2007, 50, 94–101. [Google Scholar] [CrossRef]
- Hedley, J. jsoup: Java HTML Parser. Available online: https://jsoup.org/ (accessed on 23 February 2019).
- Hiemstra, D.; Hauff, C. MIREX: MapReduce Information Retrieval Experiments. Comput. Res. Repos. arxiv 2010, arXiv:1004.4489. [Google Scholar]
- Knollmann, T.; Scheideler, C. A Self-stabilizing Hashed Patricia Trie. In Proceedings of the 20th International Symposium on Stabilization, Safety, and Security of Distributed Systems, Tokyo, Japan, 4–7 November 2018; Springer: Cham, Switzerland, 2018; pp. 1–15. [Google Scholar]
- Sun, Y.; Councill, I.G.; Giles, C.L. The Ethicality of Web Crawlers. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Washington, DC, USA, 31 August–3 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 668–675. [Google Scholar]
- Nawrocki, M.; Wählisch, M.; Schmidt, T.C.; Keil, C.; Schönfelder, J. A Survey on Honeypot Software and Data Analysis. arxiv 2016, arXiv:1608.06249. [Google Scholar]
- Subashini, S.; Kavitha, V. A survey on security issues in service delivery models of cloud computing. J. Netw. Comput. Appl. 2011, 34, 1–11. [Google Scholar] [CrossRef]
- Deepa, G.; Thilagam, P.S. Securing web applications from injection and logic vulnerabilities: Approaches and challenges. Inf. Softw. Technol. 2016, 74, 160–180. [Google Scholar] [CrossRef]
- Cloud Computing Services | Google Cloud. Available online: https://cloud.google.com/ (accessed on 15 January 2019).



| Symbol | Usage | Description |
|---|---|---|
| / (slash) | selector/selector | Separates multiple selectors. The value that is returned is the one found by the first matching selector in the list. If the custom selector ends with a slash and no element was selected, then an empty string is returned instead of an exception being thrown. |
| % (percent) | selector%attr | Returns the value for the attribute name following the symbol from the element selected by the string preceding the symbol. |
| selector% | If there is no expression after the symbol, then it returns the element text not including the text from that node’s children elements. | |
| = (equals) | selector%attr=expr selector%=expr | Returns a Boolean value depending on whether the left-hand value obtained from the selector matches the right-hand expression. |
| ~ (tilde) | selector%attr=~expr | Returns a Boolean by negating a right-hand expression when used with the equals sign. |
| abs: (abs colon) | selector%abs:attr | Returns the absolute URL for an attribute value; can only be used after the percent symbol (%). |
| URL | HTTP Method | Payload / Query | Description |
|---|---|---|---|
| /sites | GET | - | Returns the websites |
| POST 1 | website | Adds a new website | |
| PUT 1 | website list | Replaces the website list | |
| DELETE 1 | - | Removes all the websites | |
| /sites/siteUrl | PUT 1 | website | Replaces the website |
| /products | GET | search=terms | Performs a product search by name |
| newest=true | Returns the products that were added in the last week (limited to 100 items) | ||
| ids=listOfIds | Returns the products with the specified IDs (limited to 100 items) | ||
| PATCH 1 | product list | Batch-updates the products | |
| DELETE 1 | - | Removes all the products | |
| /productindex | GET 1 | Returns the product index | |
| PUT 1 | product index | Replaces the product index |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexandrescu, A. Optimization and Security in Information Retrieval, Extraction, Processing, and Presentation on a Cloud Platform. Information 2019, 10, 200. https://doi.org/10.3390/info10060200
Alexandrescu A. Optimization and Security in Information Retrieval, Extraction, Processing, and Presentation on a Cloud Platform. Information. 2019; 10(6):200. https://doi.org/10.3390/info10060200
Chicago/Turabian StyleAlexandrescu, Adrian. 2019. "Optimization and Security in Information Retrieval, Extraction, Processing, and Presentation on a Cloud Platform" Information 10, no. 6: 200. https://doi.org/10.3390/info10060200
APA StyleAlexandrescu, A. (2019). Optimization and Security in Information Retrieval, Extraction, Processing, and Presentation on a Cloud Platform. Information, 10(6), 200. https://doi.org/10.3390/info10060200