Cross-Domain Text Sentiment Analysis Based on CNN_FT Method


Abstract
:1. Introduction
2. Related Works
2.1. Transfer Learning
2.2. Cross-Domain Text Sentiment Analysis
3. Transfer Learning Method Based on Deep Learning Model
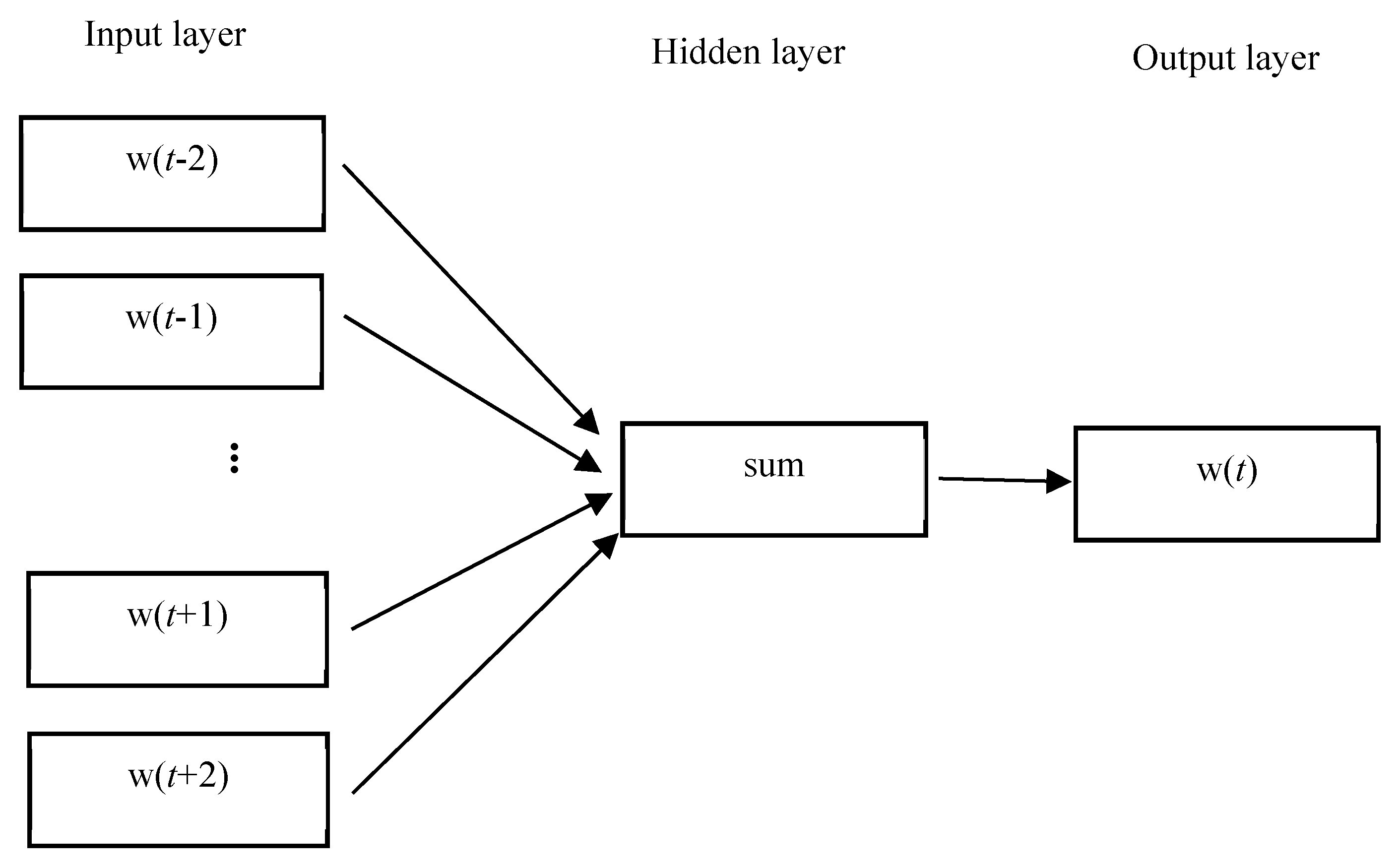
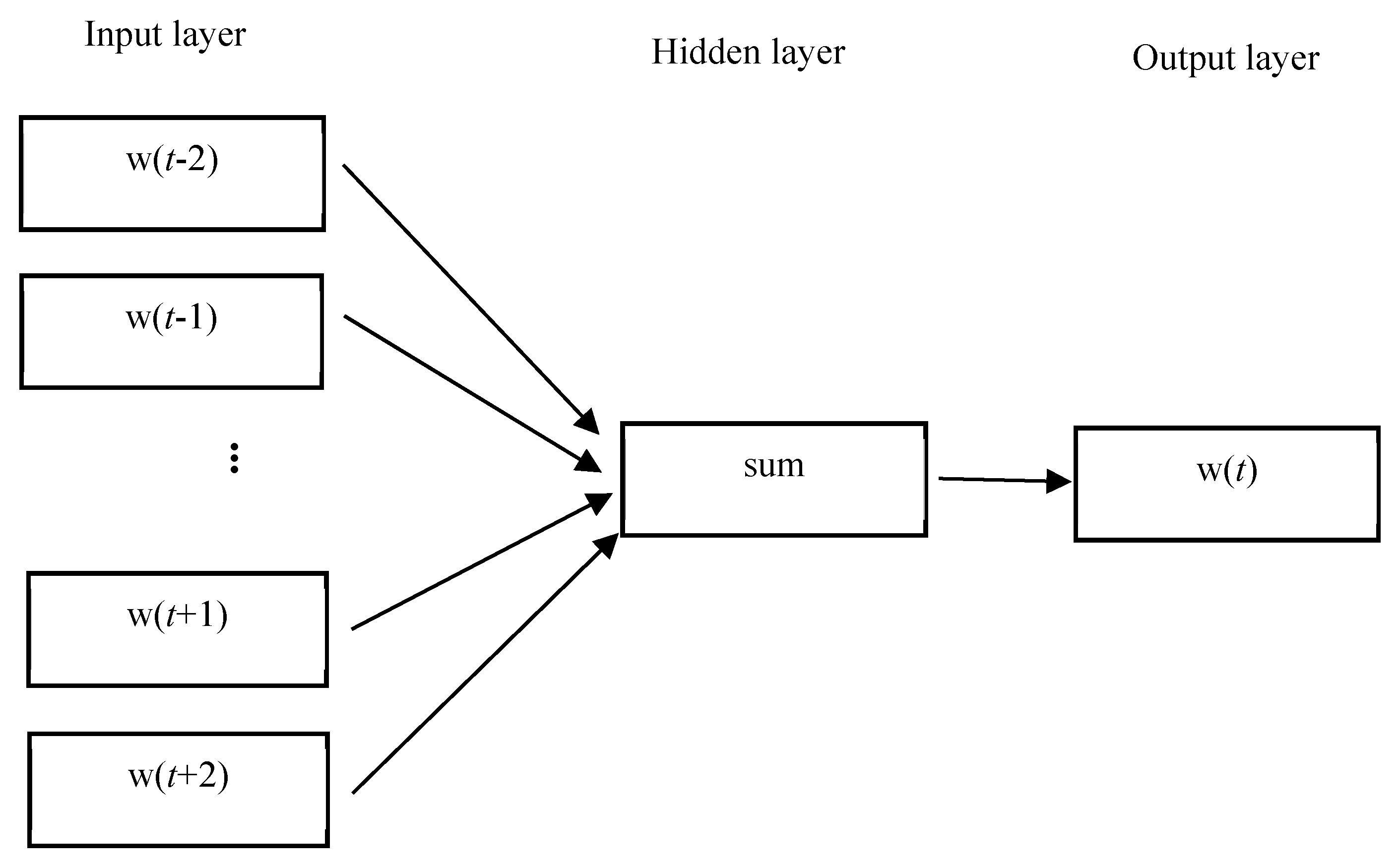
3.1. Feature Representation
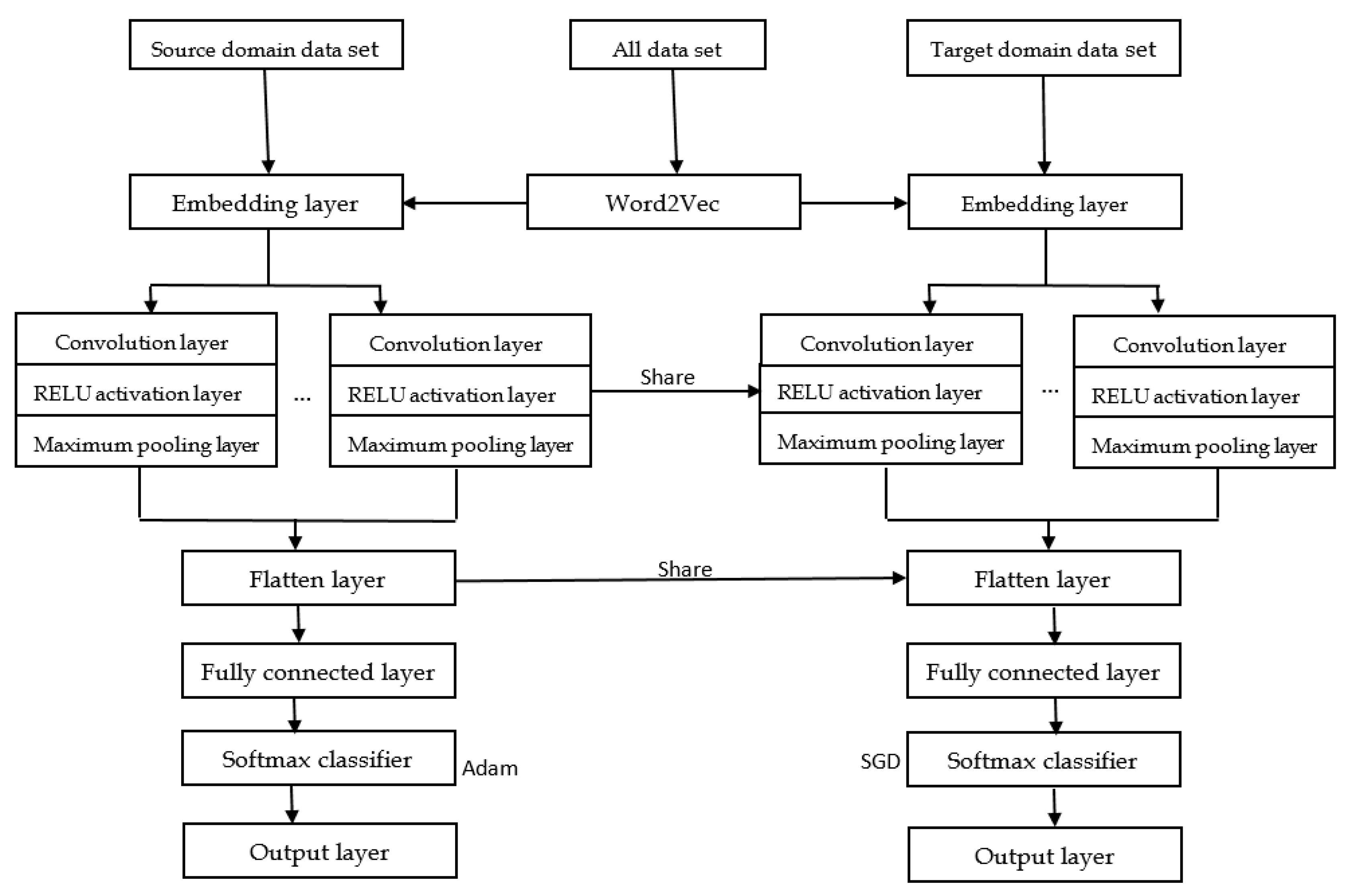
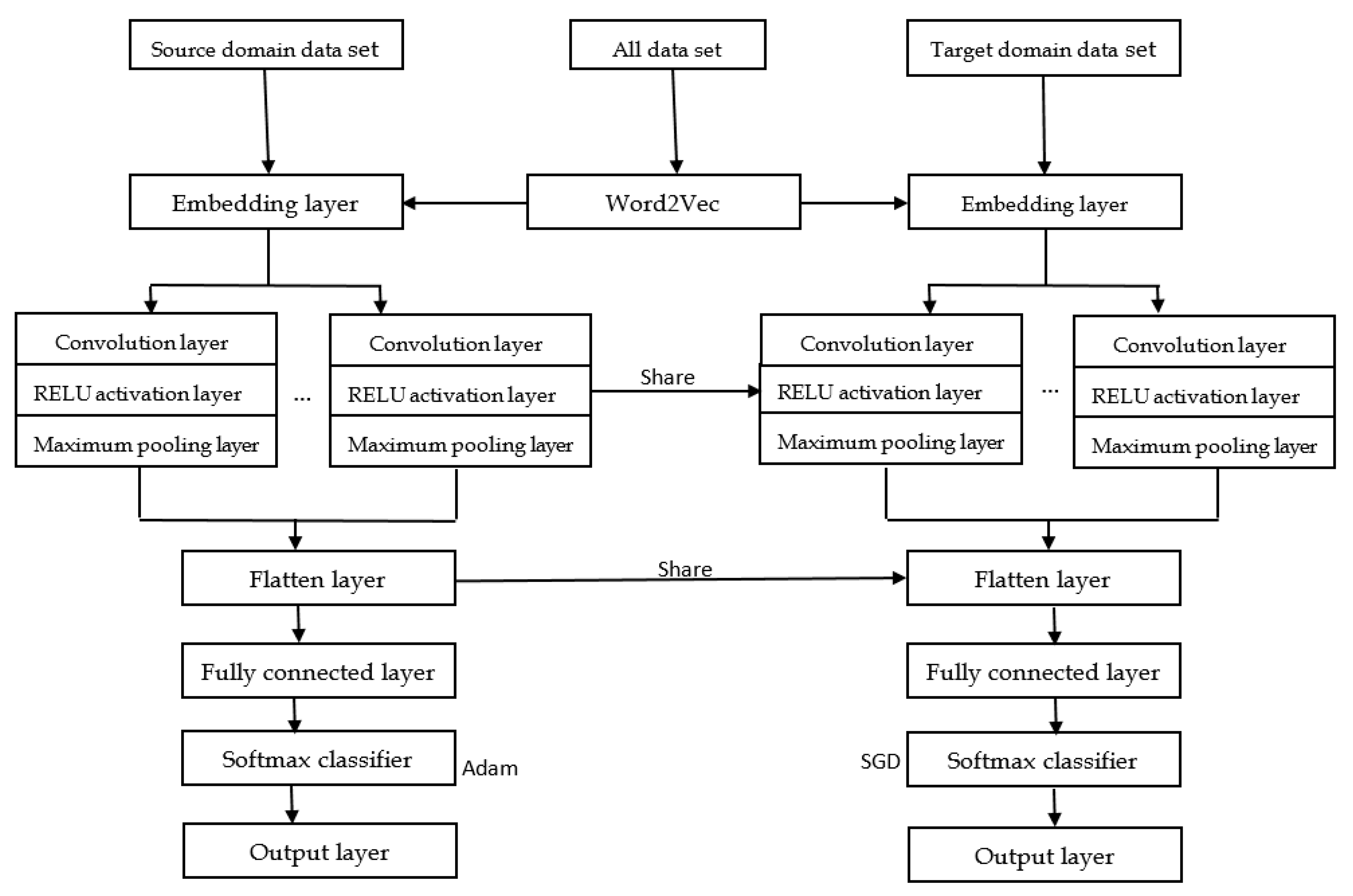
3.2. Convolutional Neural Network Structure
4. Experiment Results and Analysis
4.1. Datasets
4.2. Parameter Setting
4.3. Baseline Methods
4.4. Experimental Results and Analysis
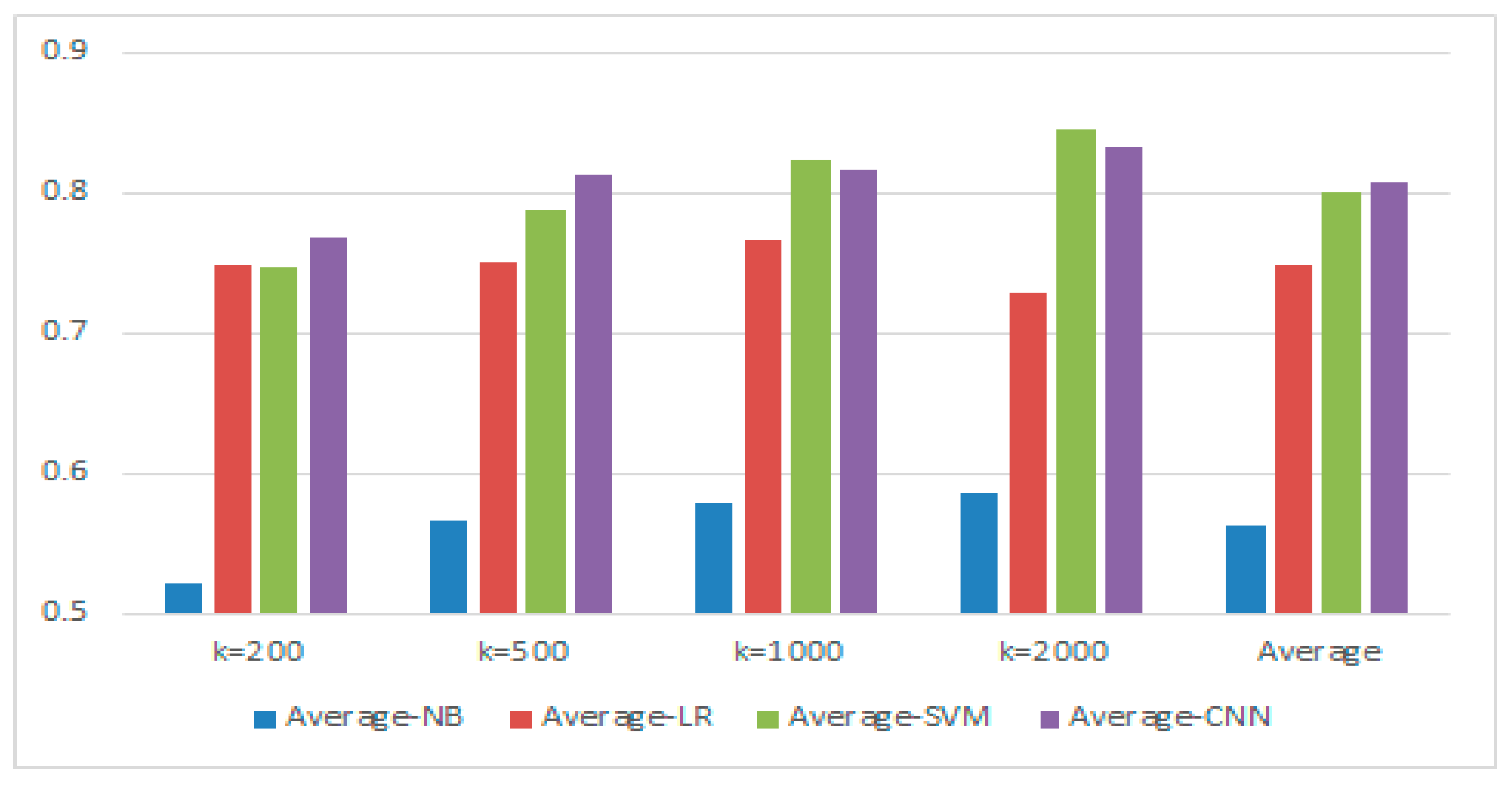
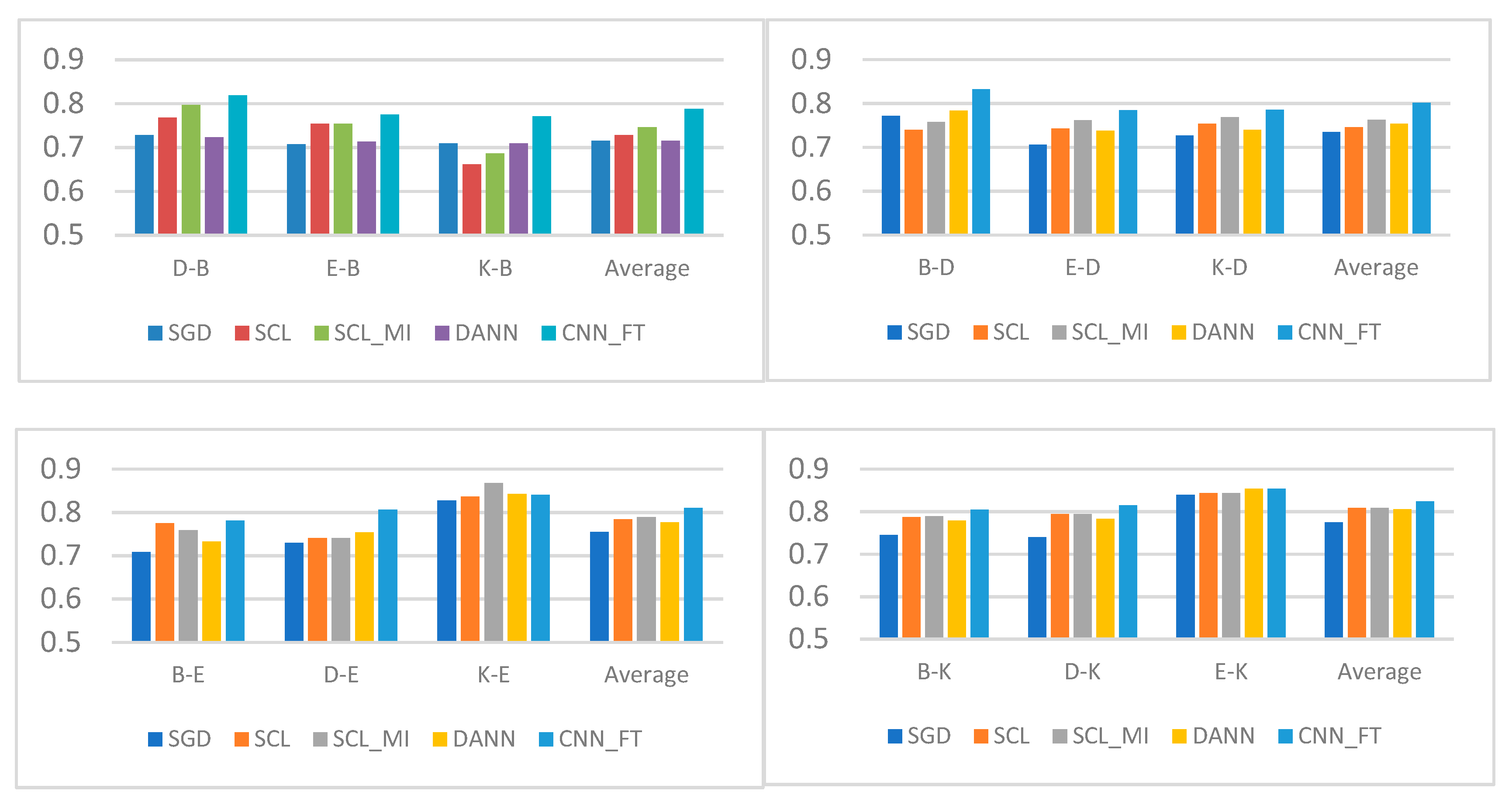
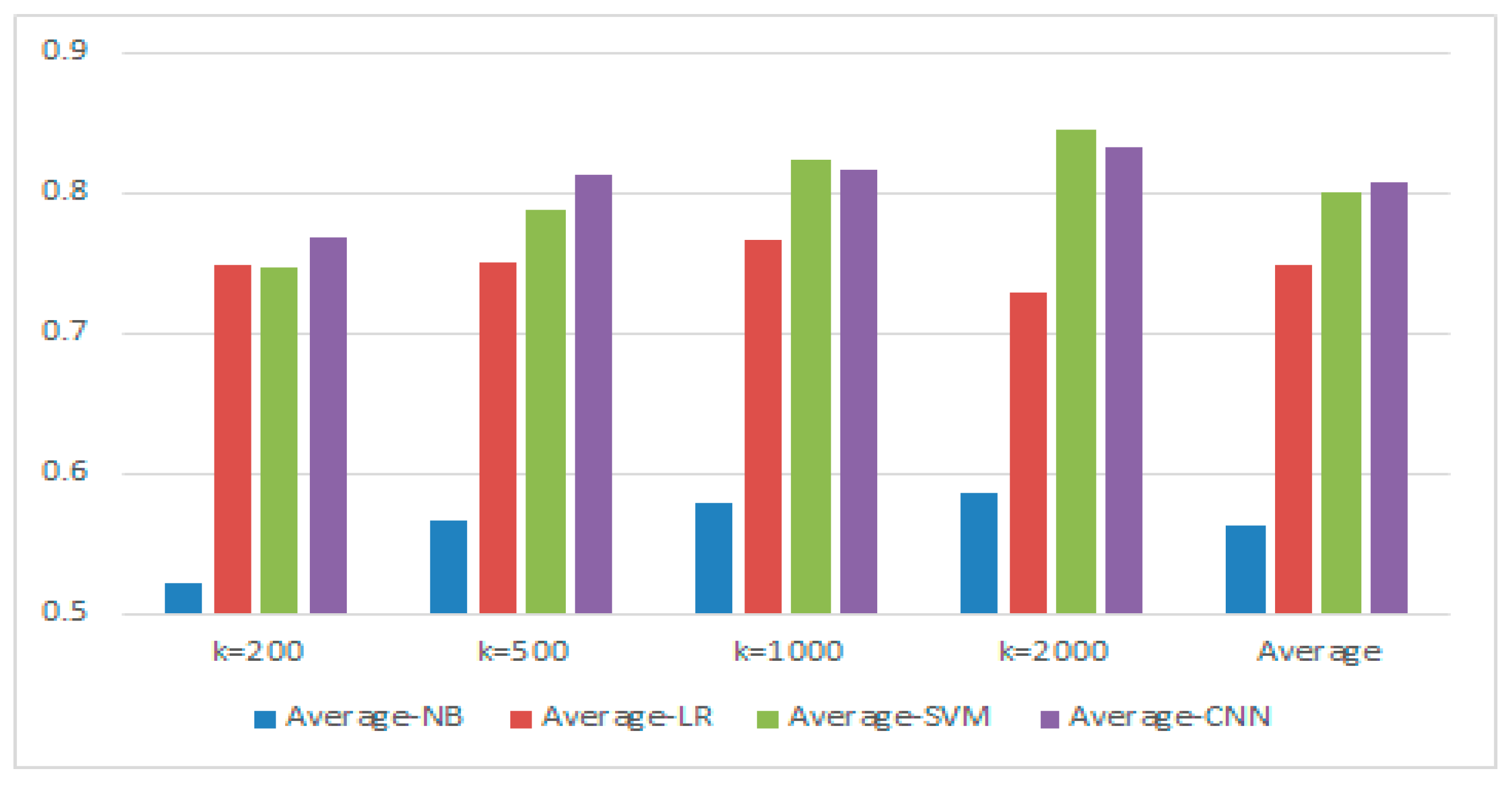
4.4.1. Experimental Results and Analysis of Chinese Corpus
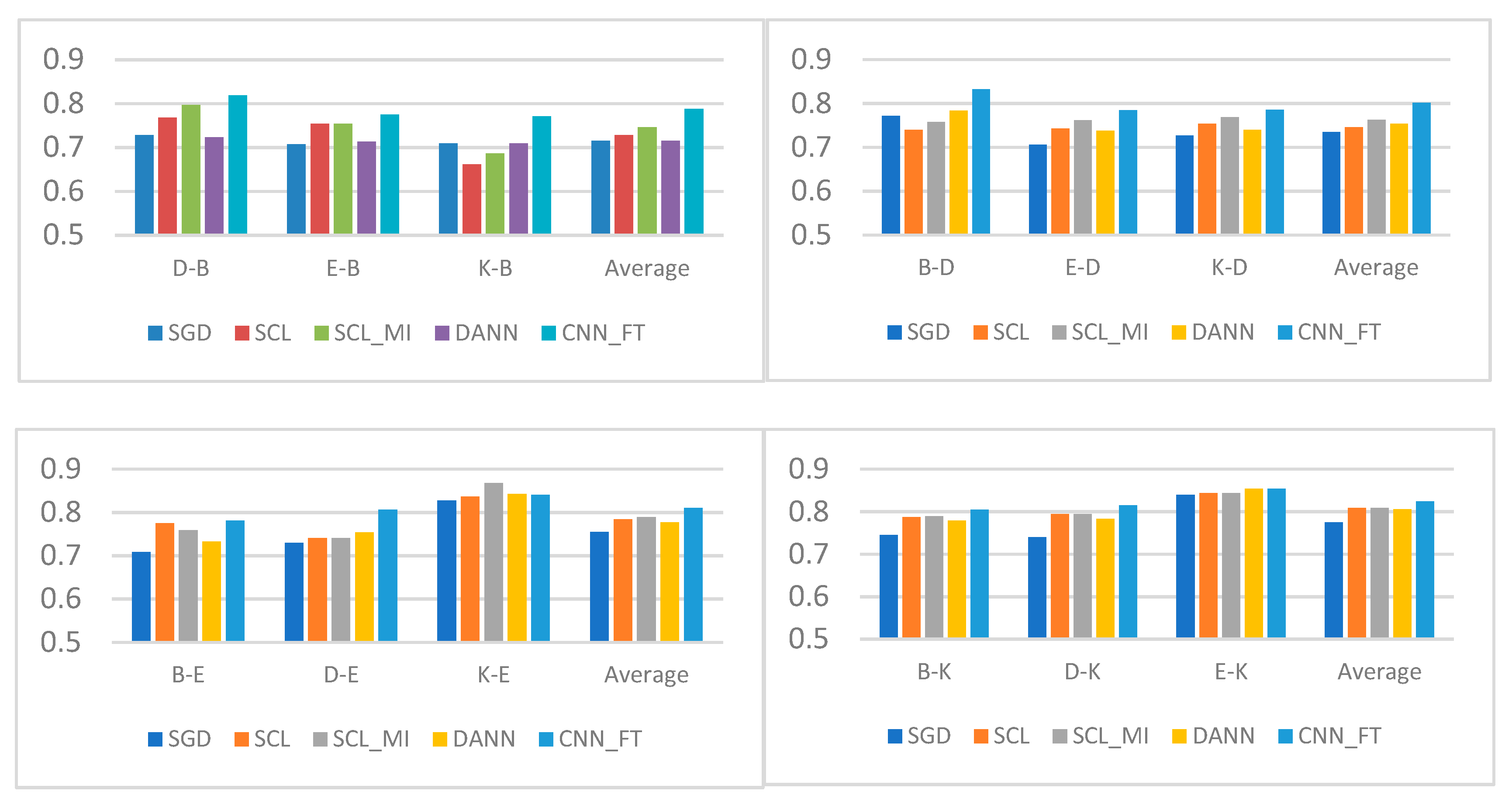
4.4.2. Experimental Results and Analysis of English Corpus
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tahmoresnezhad, J.; Hashemi, S. Visual domain adaptation via transfer feature learning. Knowl. Inf. Syst. 2017, 50, 585–605. [Google Scholar] [CrossRef]
- Wu, Q.; Tan, S. A two-stage framework for cross-domain sentiment classification. Expert Syst. Appl. 2011, 38, 14269–14275. [Google Scholar] [CrossRef]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boomboxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 25–27 June 2007. [Google Scholar]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2015, 17, 2096–2030. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Lai, W.H.; Qiao, Y.P. Spam messages recognizing methods based on word embedding and convolutional neural network. J. Comput. Appl. 2018, 38, 2469–2476. [Google Scholar]
- Li, Z.; Zhang, Y.; Wei, Y.; Wu, Y.; Yang, Q. End-to-end adversarial memory network for cross-domain sentiment classification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Fortuna, L.; Arena, P.; Balya, D.; Zarandy, A. Cellular neural networks: A paradigm for nonlinear spatio-temporal processing. IEEE Circuits Syst. Mag. 2001, 1, 6–21. [Google Scholar] [CrossRef]
- Dai, W.; Yang, Q.; Xue, Gu.; Yu, Y. Boosting for transfer learning. In Proceedings of the International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007. [Google Scholar]
- Tan, B.; Song, Y.; Zhong, E.; Yang, Q. Transitive transfer learning. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Tan, B.; Zhang, Y.; Pan, S.J.; Yang, Q. Distant domain transfer learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Blitzer, J.; Mcdonald, R.; Pereira, F. Domain adaptation with structural correspondence learning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006. [Google Scholar]
- Long, M.; Wang, J.; Cao, Y.; Sun, J.; Philip, S.Y. Deep learning of transferable representation for scalable domain adaptation. IEEE Trans. Knowl. Data Eng. 2016, 28, 2027–2040. [Google Scholar] [CrossRef]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Sener, O.; Song, H.O.; Saxena, A.; Savarese, S. Learning transferrable representations for unsupervised domain adaptation. In Proceedings of the 13th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In Proceedings of the 28th International conference on machine learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Davis, J.; Domingos, P. Deep transfer via second-order markov logic. In Proceedings of the 26th International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T. Word2vec Project [DB/OL]. Available online: http://code.google.com/p/word2vec/ (accessed on 20 March 2019).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vectorspace. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015. [Google Scholar]
- Mohammad, S.M.; Zhu, X.; Kiritchenko, S.; Martin, J. Sentiment, emotion, purpose, and style in electoral tweets. Inf. Process. Manag. 2015, 51, 480–499. [Google Scholar] [CrossRef]
- Xing, F.; Pallucchini, F.; Cambria, E. Cognitive-inspired domain adaptation of sentiment lexicons. Inf. Process. Manag. 2019, 56, 554–564. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up: Sentiment classification using machine learning techniques. In Proceedings of the International Conference on Experience Methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002. [Google Scholar]
- Desai, M.; Mehta, M.A. Techniques for sentiment analysis of twitter data: A comprehensive survey. In Proceedings of the International Conference on Computing, Communication and Automation, Greater Noida, India, 29–30 April 2016. [Google Scholar]
- Meng, J.N.; Yu, Y.H.; Zhao, D.D.; Sun, S. Cross-domain sentiment analysis based on combination of feature and instance-transfer. J. Chin. Inf. Process. 2015, 79, 74–79, 143. [Google Scholar]
- Huang, R.Y.; Kang, S.Z. Improved EM-based cross-domain sentiment classification method. Appl. Res. Comput. 2017, 34, 2696–2699. [Google Scholar]
- Xia, R.; Zong, C.Q.; Hu, X.L.; Cambria, E. Feature ensemble plus sample selection: Domain adaptation for sentiment classification. IEEE Intell. Syst. 2013, 28, 10–18. [Google Scholar] [CrossRef]
- Deshmukha, J.S.; Tripathy, A.K. Entropy based classifier for cross-domain opinion mining. Appl. Comput. Inform. 2017, 14, 55–64. [Google Scholar] [CrossRef]
- Tang, D.Y.; Qin, B.; Liu., T. Deep learning for sentiment analysis: Successful approaches and future challenges. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 292–303. [Google Scholar] [CrossRef]
- Yu, J.F.; Jiang, J. Learning sentence embeddings with auxiliary tasks for cross-domain sentiment classification. In Proceedings of the Conference on Empirical Methods in Natural Language, Stroudsburg, PA, USA, 1–4 November 2016. [Google Scholar]
- Santos, C.N.; Gattit, M. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of the 25th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. Comput. Sci. 2012, 3, 212–223. [Google Scholar]
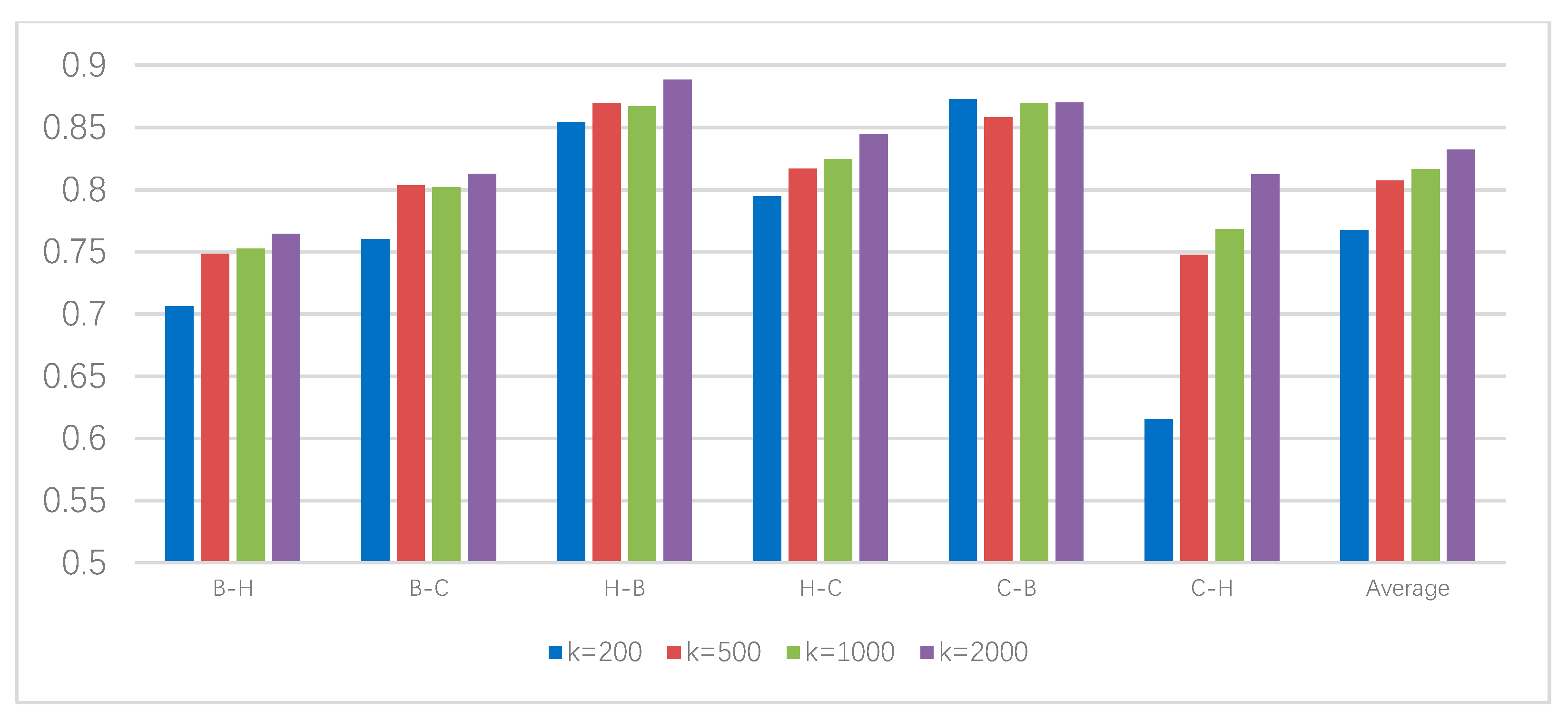

{kind=link}
{kind=link}
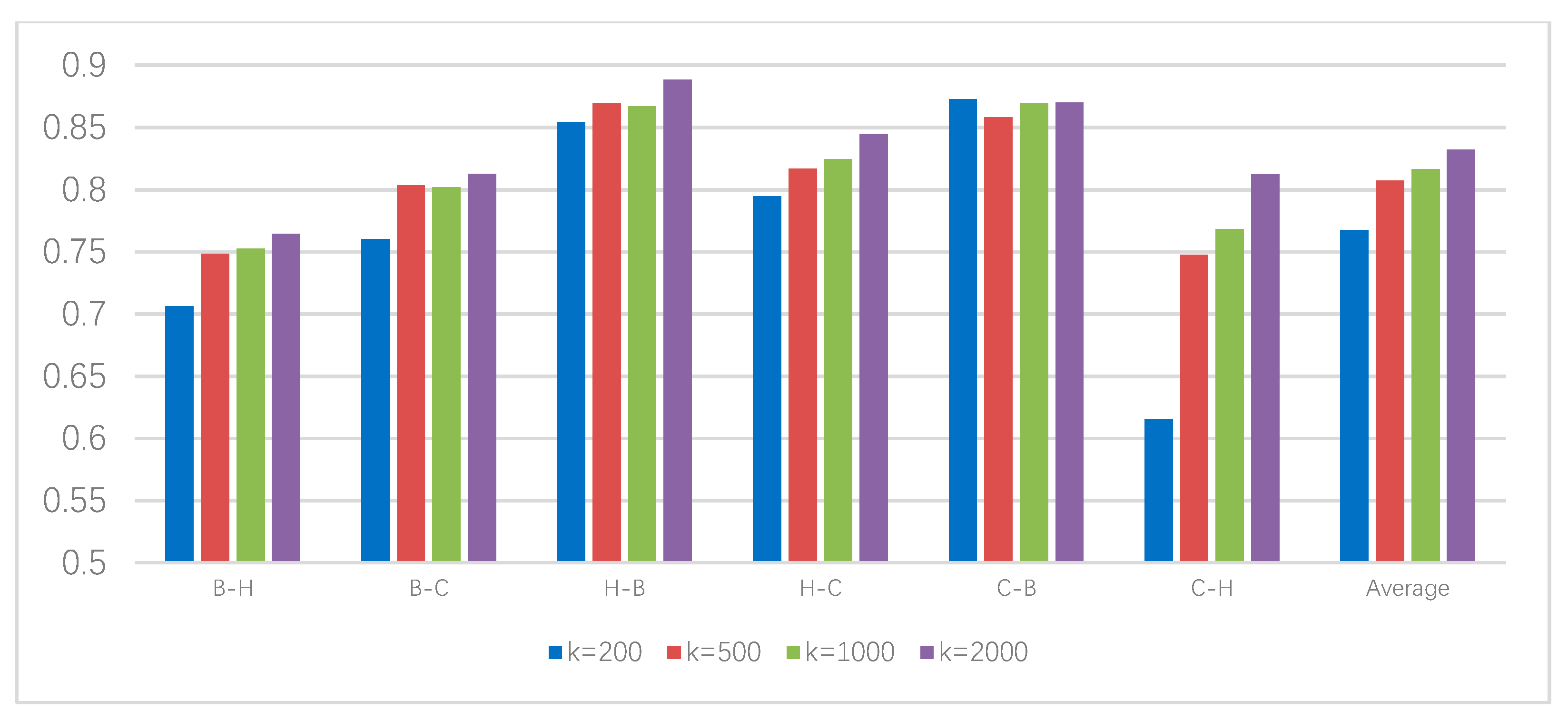{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive Sample Number | Negative Sample Number |
|---|---|---|
| Book | 2000 | 2000 |
| Computer | 2000 | 2000 |
| Hotel | 2000 | 2000 |
| Dataset | Positive Sample Number | Negative Sample Number |
|---|---|---|
| Book | 2000 | 2000 |
| Kitchen | 2000 | 2000 |
| DVD | 2000 | 2000 |
| Electronic | 2000 | 2000 |
| Parameter Name | Parameter Value |
|---|---|
| Sentence length | 100 |
| Number of convolution kernels | 256 |
| Convolution kernel filter word length | 3, 4, 5 |
| Word vector dimension | 64 |
| Batch size | 32 |
| Dropout | 0.2 |
| Number of iterations (epoch) | 20 |
| Target domain training data size (k) | 0, 200, 500, 1000, 2000 |
| NB | LR | SVM | |
|---|---|---|---|
| Book | 0.8301 | 0.8900 | 0.8850 |
| Computer | 0.8550 | 0.8860 | 0.8530 |
| Hotel | 0.6062 | 0.8575 | 0.7598 |
| NB | LR | SVM | CNN | |
|---|---|---|---|---|
| Book→Hotel | 0.5822 | 0.7750 | 0.7897 | 0.6080 |
| Book→Computer | 0.7632 | 0.7360 | 0.7312 | 0.6787 |
| Hotel→Book | 0.4897 | 0.6935 | 0.7107 | 0.7120 |
| Hotel→Computer | 0.1557 | 0.6992 | 0.7152 | 0.8182 |
| Computer→Book | 0.5212 | 0.5397 | 0.538 | 0.8267 |
| Computer→Hotel | 0.4247 | 0.5507 | 0.5412 | 0.6232 |
| Average | 0.4895 | 0.6657 | 0.671 | 0.7111 |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Book→Hotel | 0.7485 | 0.7645 | 0.7180 | 0.7407 |
| Book→Computer | 0.8034 | 0.8153 | 0.7845 | 0.7996 |
| Hotel→Book | 0.8691 | 0.8831 | 0.8508 | 0.8667 |
| Hotel→Computer | 0.8168 | 0.8123 | 0.8240 | 0.8180 |
| Computer→Book | 0.8580 | 0.8683 | 0.8440 | 0.8559 |
| Computer→Hotel | 0.7477 | 0.7533 | 0.7365 | 0.7448 |
| Average | 0.8072 | 0.8161 | 0.7929 | 0.8042 |
| NB | LR | SVM | CNN | |
|---|---|---|---|---|
| Book→Hotel | 0.6180 | 0.7426 | 0.7317 | 0.7508 |
| Book→Computer | 0.6931 | 0.7951 | 0.7991 | 0.8014 |
| Hotel→Book | 0.7291 | 0.7411 | 0.7237 | 0.8788 |
| Hotel→Computer | 0.7431 | 0.8043 | 0.8103 | 0.8425 |
| Computer→Book | 0.7663 | 0.7520 | 0.7477 | 0.8625 |
| Computer→Hotel | 0.7583 | 0.7366 | 0.7463 | 0.7457 |
| Average | 0.7180 | 0.7620 | 0.7598 | 0.8136 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, J.; Long, Y.; Yu, Y.; Zhao, D.; Liu, S. Cross-Domain Text Sentiment Analysis Based on CNN_FT Method. Information 2019, 10, 162. https://doi.org/10.3390/info10050162
Meng J, Long Y, Yu Y, Zhao D, Liu S. Cross-Domain Text Sentiment Analysis Based on CNN_FT Method. Information. 2019; 10(5):162. https://doi.org/10.3390/info10050162
Chicago/Turabian StyleMeng, Jiana, Yingchun Long, Yuhai Yu, Dandan Zhao, and Shuang Liu. 2019. "Cross-Domain Text Sentiment Analysis Based on CNN_FT Method" Information 10, no. 5: 162. https://doi.org/10.3390/info10050162
APA StyleMeng, J., Long, Y., Yu, Y., Zhao, D., & Liu, S. (2019). Cross-Domain Text Sentiment Analysis Based on CNN_FT Method. Information, 10(5), 162. https://doi.org/10.3390/info10050162