Spatiotemporal Clustering Analysis of Bicycle Sharing System with Data Mining Approach

Abstract
1. Introduction
- Expensive investment for construction of docking stations and kiosk machines;
- The inflexibility of rent and return of bicycles in fixed rental stations so that the conventional schemes cannot provide door-to-door services;
- Impossibility to spot bicycles when users start their journeys, and/or impossibility to return the bicycles in the preferred destination;
- Slow and complicated register procedure for using the bicycle sharing system;
- Political and public resistance when there is a need to sacrifice car parking space [12].
2. Literature Review
2.1. Travel Patterns of Bicycle Sharing
2.2. Clustering Algorithms Used in Bicycle Sharing
3. Data Description
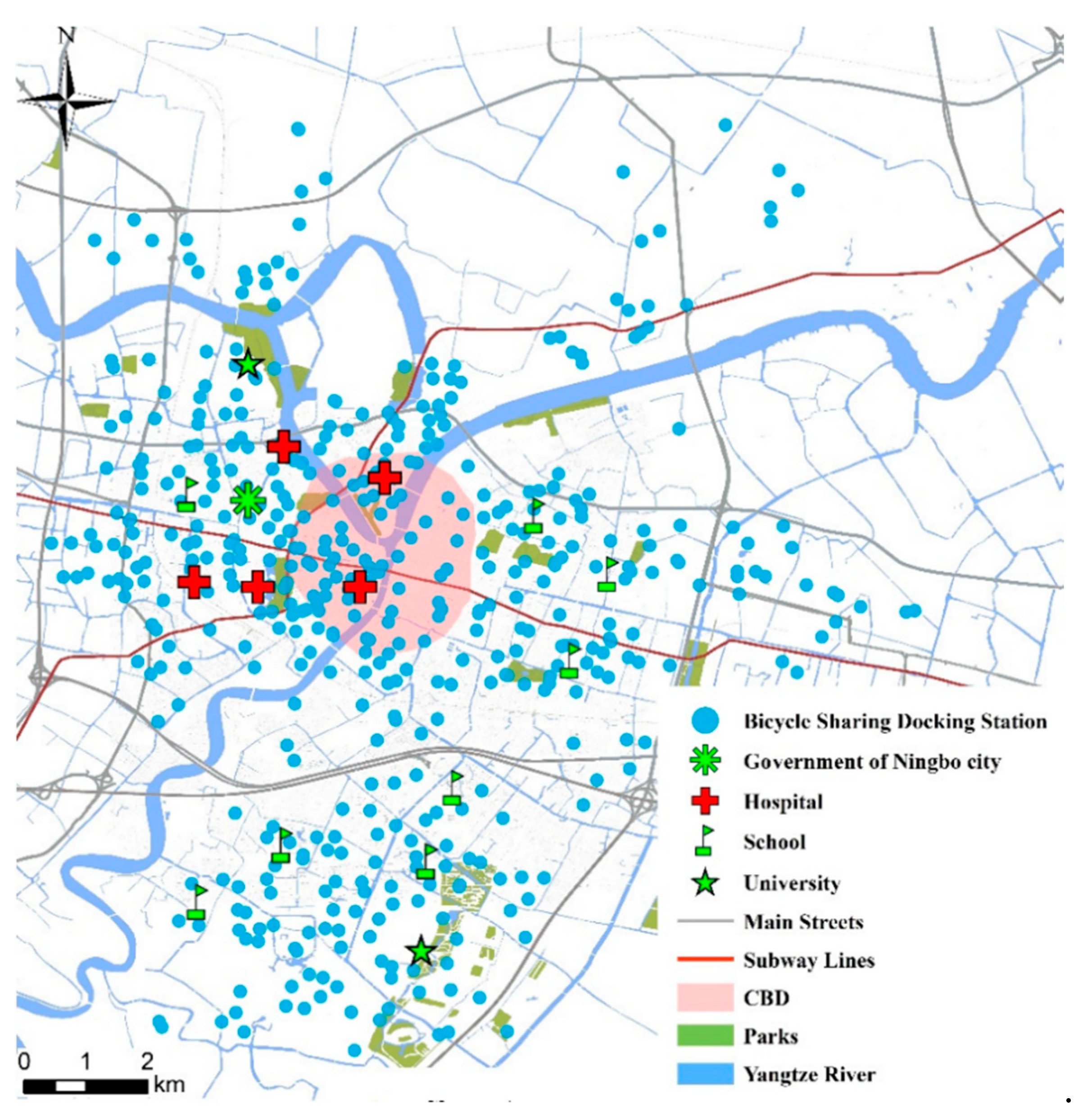
3.1. Study Area
3.2. Smart Card Data of Bicycle Sharing System
3.3. POI Data around Bicycle Sharing Docking Station
4. Methodology
4.1. Clustering Algorithms and Clustering Validation Measures
4.2. Temporal Variables
4.3. Spatial Variables
4.3.1. GWR Model
4.3.2. Inputs of GWR Model
4.3.3. Output of the GWR Model
5. Results of Clustering
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Maizlish, N.; Woodcock, J.; Co, S.; Ostro, B.; Fanai, A.; Fairley, D. Health Cobenefits and Transportation-Related Reductions in Greenhouse Gas Emissions in the San Francisco Bay Area. Am. J. Public Health 2013, 103, 703–709. [Google Scholar] [CrossRef]
- Yang, M.; Liu, X.; Wang, W.; Li, Z.; Zhao, J. Empirical Analysis of a Mode Shift to Using Public Bicycles to Access the Suburban Metro: Survey of Nanjing, China. J. Urban Plan. Dev. 2016, 142, 05015011. [Google Scholar] [CrossRef]
- Meddin, R.; Demaio, P.J. The Bike-Sharing World Map. Available online: www.bikesharingmap.com (accessed on 27 February 2019).
- Yang Fang, M.G. Report of Shared Bicycle. Available online: http://tech.sina.com.cn/roll/2018-03-07/doc-ifxtevrp244313 (accessed on 27 February 2019).
- Tang, Y.; Pan, H.; Shen, Q. Bike-sharing systems in Beijing, Shanghai, and Hangzhou and their impact on travel behavior (No. 11-3862). In Proceedings of the Transportation Research Board 90th Annual Meeting, Washington, DC, USA, 23–27 January 2011. [Google Scholar]
- Shaheen, S.A.; Zhang, H.; Martin, E.; Guzman, S. China’s Hangzhou Public Bicycle. Transp. Res. Record J. Transp. Res. Board 2011, 2247, 33–41. [Google Scholar] [CrossRef]
- Fishman, E.; Washington, S.; Haworth, N. Bike Share: A Synthesis of the Literature. Urban Transp. China 2013, 33, 148–165. [Google Scholar] [CrossRef]
- Industry, T.I.o.C. The Information of China Industry, The Analysis of History, Status Quo and Scale of China’s Public Bicycle in 2017. Available online: http://www.chyxx.com/industry/201704/513812.html (accessed on 27 February 2019).
- GuangZhou Planning Bureau. The Case of Big Data Combined with City Planning. Available online: https://mp.weixin.qq.com/s?__biz=MzA3OTU3ODgxNA==&mid=2650583825&idx=1&sn=4a1e2f4df6d96e0d08ba639278f1da8e&chksm=87b940c0b0cec9d65ee7a76a0d25232d7811a83ab3858052d019bfb98780669aed6d4ed67139&mpshare=1&scene=23&srcid=0628YETa2Iyklv5UMuD51Exy#rd (accessed on 27 February 2019).
- Du, M.; Cheng, L. Better Understanding the Characteristics and Influential Factors of Different Travel Patterns in Free-Floating Bike Sharing: Evidence from Nanjing, China. Sustainability 2018, 10, 1244. [Google Scholar] [CrossRef]
- Transportation, D.O. Guidance to Encourage and Regulate Bike Sharing Was Issued. Available online: http://www.gov.cn/xinwen/2017-08/03/content_5215640.htm (accessed on 27 February 2019).
- Nikitas, A. Understanding bike-sharing acceptability and expected usage patterns in the context of a small city novel to the concept: A story of ‘Greek Drama’. Transp. Res. Part F Traffic Psychol. Behav. 2018, 56, 306–321. [Google Scholar] [CrossRef]
- Froehlich, J.E.; Neumann, J.; Oliver, N. Sensing and predicting the pulse of the city through shared bicycling. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 17 July 2009. [Google Scholar]
- De Chardon, C.M.; Caruso, G.; Thomas, I. Bike-share rebalancing strategies, patterns, and purpose. J. Transp. Geogr. 2016, 55, 22–39. [Google Scholar] [CrossRef]
- Fishman, E. Bikeshare: A Review of Recent Literature. Transp. Rev. 2016, 36, 92–113. [Google Scholar] [CrossRef]
- Shaheen, S.A.; Cohen, A.P.; Martin, E.W. Public Bikesharing in North America: Early Operator Understanding and Emerging Trends. Transp. Res. Rec. J. Transp. Res. Board 2013, 1568, 83–92. [Google Scholar] [CrossRef]
- Ricci, M. Bike sharing: A review of evidence on impacts and processes of implementation and operation. Res. Transp. Bus. Manag. 2015, 15, 28–38. [Google Scholar] [CrossRef]
- Zhang, Y. Survey on the reorganization and using status of public bicycle system in urban fringe areas: Taking Tongzhou and Daxing Districts of Beijing for example. Urban Probl. 2015, 3, 42–46. [Google Scholar]
- Fishman, E.; Washington, S.; Haworth, N. Erratum to Bike share: A synthesis of the literature (Transport Reviews). Transp. Rev. 2013, 33. [Google Scholar] [CrossRef]
- Kaltenbrunner, A.; Meza, R.; Grivolla, J.; Codina, J.; Banchs, R. Urban cycles and mobility patterns: Exploring and predicting trends in a bicycle-based public transport system. Pervasive Mob. Comput. 2010, 6, 455–466. [Google Scholar] [CrossRef]
- Rahul, T.M.; Verma, A. A study of acceptable trip distances using walking and cycling in Bangalore. J. Transp. Geogr. 2014, 38, 106–113. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, J.; Deng, W. Exploring bikesharing travel time and trip chain by gender and day of the week. Transp. Res. Part C 2015, 58, 251–264. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Zhang, R.; Lu, Y.; Xie, S. Overcoming Barriers to Cycling: Exploring Influence Factors of Cyclists’ Preference in Free-Floating Bikesharing; Technical Report No. 18-02707; The National Academies of Sciences, Engineering, and Medicine: Washington, DC, USA, 8 January 2018. [Google Scholar]
- Mauri, C. Card loyalty. A new emerging issue in grocery retailing. J. Retail. Consum. Serv. 2003, 10, 13–25. [Google Scholar] [CrossRef]
- Borgnat, P.; Abry, P.; Flandrin, P.; Robardet, C.; Rouquier, J.-B.; Fleury, E. Shared bicycles in a city: A signal processing and data analysis perspective. Adv. Complex Syst. 2011, 14, 415–438. [Google Scholar] [CrossRef]
- Come, E.; Randriamanamihaga, N.A.; Oukhellou, L.; Aknin, P. Spatio-temporal analysis of dynamic origin-destination data using latent dirichlet allocation: Application to vélib’bike sharing system of paris. In Proceedings of the TRB 93rd Annual Meeting, Washington, DC, USA, 12–16 January 2014; p. 19. [Google Scholar]
- Austwick, M.Z.; O’Brien, O.; Strano, E.; Viana, M. The structure of spatial networks and communities in bicycle sharing systems. PLoS ONE 2013, 8, e74685. [Google Scholar]
- O’brien, O.; Cheshire, J.; Batty, M. Mining bicycle sharing data for generating insights into sustainable transport systems. J. Transp. Geogr. 2014, 34, 262–273. [Google Scholar] [CrossRef]
- System, C.o.N.B.S. Ningbo Public Bicycle Service Development Co. Operational Information. Available online: http://www.nbbicycle.com (accessed on 27 February 2019).
- Vogel, P.; Greiser, T.; Mattfeld, D.C. Understanding bike-sharing systems using data mining: Exploring activity patterns. Procedia-Soc. Behav. Sci. 2011, 20, 514–523. [Google Scholar] [CrossRef]
- Yahya, B. Overall bike effectiveness as a sustainability metric for bike sharing systems. Sustainability 2017, 9, 2070. [Google Scholar] [CrossRef]
- Xu, C.; Wang, Y.; Wang, C.; Liu, P. Investigation of Contributing Factors to Travel Demand of Free-floating Bike Sharing: A Geographically Weighted Regression Approach (No. 19-03556). In Proceedings of the Transportation Research Board 98th Annual Meeting, Washington, DC, USA, 13–17 January 2019. [Google Scholar]
- Corporation, B. Classification of Poi Data. Available online: http://lbsyun.baidu.com/index.php?title=lbscloud/poitags (accessed on 27 February 2019).
- Wu, C.; Inhi, K.; Hyungchul, C. A geographically weighted regression model to explore the relationship between built 1 environment and public sharing bike flow: Evidence from Suzhou, China. In Proceedings of the TRB 98th Annual Meeting, Washington, DC, USA, 13–17 January 2019. [Google Scholar]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Teboulle, M.; Berkhin, P.; Dhillon, I.; Guan, Y.; Kogan, J. Clustering with Entropy-Like K-Means Algorithms; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Tan, P.N. Introduction to Data Mining; Pearson Education India: Noida, India, 2018; Available online: https://www-users.cs.umn.edu/~kumar001/dmbook/sol.pdf (accessed on 27 February 2019).
- Handl, J.; Knowles, J.; Kell, D.B. Computational cluster validation in post-genomic data analysis. Bioinformatics 2005, 21, 3201–3212. [Google Scholar] [CrossRef] [PubMed]
- Brock, G.; Pihur, V.; Datta, S.; Datta, S. clValid, an R package for cluster validation. J. Stat. Softw. 2011. Available online: https://cran.microsoft.com/web/packages/clValid/vignettes/clValid.pdf (accessed on 27 February 2019).
- Dunn, J.C. Well separated clusters and fuzzy partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Datta, S.; Datta, S. Comparisons and validation of statistical clustering techniques for microarray gene expression data. Bioinformatics 2003, 19, 459–466. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, S.; Charlton, M. Geographically weighted regression. J. R. Stat. Soc. Ser. D 1998, 47, 431–443. [Google Scholar] [CrossRef]
- Huang, Y.; Leung, Y. Analysing regional industrialisation in Jiangsu province using geographically weighted regression. J. Geogr. Syst. 2002, 4, 233–249. [Google Scholar] [CrossRef]
- Cahill, M.; Mulligan, G. Using geographically weighted regression to explore local crime patterns. Soc. Sci. Comput. Rev. 2007, 25, 174–193. [Google Scholar] [CrossRef]
- Wu, C.; Ye, X.; Ren, F.; Du, Q. Check-in behaviour and spatio-temporal vibrancy: An exploratory analysis in Shenzhen, China. Cities 2018, 77, 104–116. [Google Scholar] [CrossRef]
- Bebber, D. Spatial autocorrelations. Trends Ecol. Evol. 1999, 14, 196. [Google Scholar] [CrossRef]
- Bao, J.; Liu, P.; Yu, H.; Xu, C. Incorporating twitter-based human activity information in spatial analysis of crashes in urban areas. Accid. Anal. Prev. 2017, 106, 358–369. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The Analysis of Spatial Association by Use of Distance Statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Charlton, M.; Fotheringham, A. Geographically Weighted Regression (White Paper). National Centre for Geocomputation National University of Ireland, Maynooth. GWR_WhitePaper. pdf 2009. Available online: https://www.geos.ed.ac.uk/~gisteac/fspat/gwr/gwr_arcgis/GWR_WhitePaper.pdf (accessed on 27 February 2019).
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Qian, X.; Ukkusuri, S.V. Spatial variation of the urban taxi ridership using GPS data. Appl. Geogr. 2015, 59, 31–42. [Google Scholar] [CrossRef]
- Mcmillen, D.P. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships. Am. J. Agric. Econ. 2004, 86, 554–556. [Google Scholar] [CrossRef]
- Calvo, F.; Eboli, L.; Forciniti, C.; Mazzulla, G. Factors influencing trip generation on metro system in Madrid (Spain). Transp. Res. Part D Transp. Environ. 2019, 67, 156–172. [Google Scholar] [CrossRef]


{kind=link}
| Variable | Description | Unit | Source | Mean |
|---|---|---|---|---|
| Dependent Variable | ||||
| ADR | Average daily returns of each bicycle sharing docking station | Trips/day | Smartcard | 173.87 |
| ADP | Average daily pickups of each bicycle sharing docking station | 175.56 | ||
| Explanatory Variable | ||||
| Catering | Total number of 13 types of POI data around bicycle sharing docking station | Number of POI | Electronic Map | 21.33 |
| Hotel | 2.71 | |||
| Shopping | 13.23 | |||
| Living Service | 13.55 | |||
| Tourist Sites | 3.14 | |||
| Leisure & Entertainment | 2.46 | |||
| Education | 1.52 | |||
| Medical | 1.59 | |||
| Traffic Facilities | 3.08 | |||
| Financial Institutions | 3.26 | |||
| Real Estate | 5.43 | |||
| Corporations | 16.94 | |||
| Government Institution | 4.18 | |||
| Returns | Pickups | ||||||
| Variables | Lower Quartile | Median | Upper Quartile | Lower Quartile | Median | Upper Quartile | VIF |
| Catering | 6.569 | 12.946 | 18.367 | 11.519 | 19.741 | 26.735 | 3.88 |
| Hotel | 1.010 | 3.547 | 5.798 | 1.588 | 3.967 | 6.399 | 3.74 |
| Shopping | 22.442 | 30.306 | 37.345 | 22.181 | 31.112 | 38.640 | 1.99 |
| Living Service | 3.578 | 5.768 | 9.346 | 3.157 | 8.707 | 9.296 | 1.42 |
| Tourist Sites | 1.644 | 7.873 | 12.121 | 2.282 | 5.142 | 9.476 | 1.58 |
| Leisure & Entertainment | −0.290 | 2.256 | 6.950 | −0.575 | 2.116 | 6.250 | 4.14 |
| Education | 5.370 | 16.331 | 21.590 | 5.043 | 16.809 | 20.277 | 1.10 |
| Medical | −0.164 | 2.603 | 6.065 | 0.169 | 2.901 | 6.439 | 4.33 |
| Traffic Facilities | 4.796 | 10.926 | 17.607 | 4.407 | 10.225 | 17.089 | 1.25 |
| Financial Institutions | 4.141 | 11.804 | 18.530 | 3.984 | 12.025 | 18.477 | 4.22 |
| Real Estate | 8.502 | 12.482 | 17.145 | 8.765 | 13.110 | 17.331 | 2.36 |
| Corporations | 3.469 | 11.114 | 20.388 | 2.944 | 12.955 | 17.292 | 1.26 |
| Government Institution | 3.140 | 5.136 | 8.935 | 2.174 | 4.174 | 8.442 | 3.15 |
| CONSTANT | 169.831 | 184.617 | 197.535 | 169.705 | 185.525 | 199.314 | - |
| Result of GWR Model | Result of OLS Model | ||||||
| Number of samples | 477 | Number of samples | 477 | ||||
| Adj. R-square | 0.497 | Adj. R-square | 0.308 | ||||
| AICC | 6231 | AICC | 6381 | ||||
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| Connectivity | Hierarchical-2 | Hierarchical-7 | Kmeans-2 | Kmeans-3 |
| Dunn | Kmeans-7 | Kmeans-15 | Kmeans-16 | Kmeans-18 |
| Silhouette | Kmeans-7 | Kmeans-8 | Kmeans-2 | EM-3 |
| APN | Kmeans-7 | Kmeans-8 | Hierarchical-3 | Hierarchical-19 |
| AD | EM-20 | EM-19 | EM-18 | EM-17 |
| ADM | Kmeans-7 | Kmeans-9 | Hierarchical-3 | EM-4 |
| Stations of Each Cluster | Clusters | Most Significant POI (s) | Usage Peak Hour Period(s) |
|---|---|---|---|
| 138 | Cluster 1 (Pickups) | Corporations, Financial Institutions | 7:00–9:00, 17:00–19:00 |
| Cluster 1 (Returns) | Corporations, Financial Institutions | 7:00–9:00, 17:00–19:00 | |
| 58 | Cluster 2 (Pickups) | Real Estate, Shopping | 7:00–9:00, 19:00–20:00 |
| Cluster 2 (Returns) | Real Estate, Shopping | 8:00–10:00, 17:00–19:00 | |
| 74 | Cluster 3 (Pickups) | Catering, Shopping | 7:00–9:00, 11:00–14:00, 17:00–20:00 |
| Cluster 3 (Returns) | Catering, Shopping | 7:00–9:00, 11:00–14:00, 17:00–20:00 | |
| 27 | Cluster 4 (Pickups) | Education, Catering | 7:00–9:00,13:00–14:00 |
| Cluster 4 (Returns) | Education, Catering | 11:00–12:00, 17:00–19:00 | |
| 45 | Cluster 5 (Pickups) | Traffic Facilities | 7:00–19:00 |
| Cluster 5 (Returns) | Traffic Facilities | 7:00–19:00 | |
| 70 | Cluster 6 (Pickups) | Government Institution, Medical | 7:00–9:00 |
| Cluster 6 (Returns) | Government Institution, Medical | 17:00–19:00 | |
| 65 | Cluster 7 (Pickups) | Leisure & Entertainment, Tourist Sites | 17:00–20:00 |
| Cluster 7 (Returns) | Leisure & Entertainment, Tourist Sites | 17:00–20:00 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.; Cao, R.; Jin, Y. Spatiotemporal Clustering Analysis of Bicycle Sharing System with Data Mining Approach. Information 2019, 10, 163. https://doi.org/10.3390/info10050163
Ma X, Cao R, Jin Y. Spatiotemporal Clustering Analysis of Bicycle Sharing System with Data Mining Approach. Information. 2019; 10(5):163. https://doi.org/10.3390/info10050163
Chicago/Turabian StyleMa, Xinwei, Ruiming Cao, and Yuchuan Jin. 2019. "Spatiotemporal Clustering Analysis of Bicycle Sharing System with Data Mining Approach" Information 10, no. 5: 163. https://doi.org/10.3390/info10050163
APA StyleMa, X., Cao, R., & Jin, Y. (2019). Spatiotemporal Clustering Analysis of Bicycle Sharing System with Data Mining Approach. Information, 10(5), 163. https://doi.org/10.3390/info10050163