1. Introduction
Data quality (DQ) and information quality (IQ) are recognized by business managers as key factors affecting the efficiency of their companies. In the U.S. economy alone, it is estimated that poor data quality costs 3.1 trillion U.S. dollars per year [
1]. In order to obtain better information quality, researchers have suggested considering data as a product, and have established the manufacturing of information (MI) approach [
2], where data are input to produce output data [
3,
4,
5,
6,
7,
8,
9] or output information [
10,
11,
12].
The concept of quality for products has been defined as “fitness for use” [
5,
13,
14,
15,
16,
17]. Meanwhile, for information products (IP), this definition applies only for “information quality” (not for the information alone), because it depends on the perspective of the user. According to the context, one piece of information could be relevant for one user and not relevant for another [
16]. For that reason, data and information quality assessment should be evaluated according to required attributes for the business. Some desirable attributes are accuracy, objectivity, reputation, added value, relevancy (related to usefulness), timeliness (related to temporal relevance), completeness, appropriate amount of data (here called “sufficiency”), interpretability, ease of understanding, representational consistency, accessibility, and access security [
6,
16,
17,
18,
19,
20,
21]. Although extensive research has been carried out in this field, data units (
dus) have always been represented as indivisible blocks (file, document, and so on). No single study exists that represents a
du in a different way.
For the DQ and IQ assessment, for our part, we consider that the
du structure constitutes a data block (DB), such as a document. This DB is composed of several
dus, and each
du can be represented according to its particular characteristics for two types of materials: the first being a pure (simple) material, and the second being a composite material (formed from two or more elements). These characteristics relate to the attributes of sufficiency and relevance and, thus, could have some impact on the IQ assessment of the information products (IP). Relevance has been related to the concept of usefulness [
6,
16,
22], and sufficiency is related to having a quantity of data that is good enough for the purposes for which it is being used [
6], not too little nor too much [
23]. Both attributes are closely interconnected. The sufficiency of data is a consequence of counting only the relevant information in the system [
6]. In order to have relevant information, the document should ideally have only a sufficient quantity of data.
Therefore, the aim of this paper is to explore the effectiveness of representing the data as a composite unit, rather than as an indivisible data block, as has been previously considered. This paper conducts research by the model CD-PI-A (classification of data, processing data into information, and assessment), which is developed to class data, weigh it, and assess the information quality. Data quality is considered to be a dependent factor of (1) the degree of usefulness of the data and (2) the data composition.
The applicability of this model is presented through the processing analysis of two organizational forms. These forms are considered as the communication channel which contains requested data. The message is communicated between a sender and a recipient. Once the message is received, the data is transformed into information. The policy, proceedings, and regulations of the organization constitute the context in which communication is done.
In summary, the main contributions of this paper are as follows:
The results suggest that this new representation of the data input should be considered in the evaluation of information quality output from a communication system (CS). With the application of the CD-PI-A model developed here, we show that it is possible to pursue and achieve the same objective with two different documents. Thus, it is possible to capture the same information content with a smaller amount of data and produce a better quality of information;
This new representation and model for evaluating data and information should help highlight the necessity of the consistent use of data and information terminology;
This study shows that, for the already established attributes, a new classification should be considered, according to the moment when the analysis process is made;
From the applicability of the CD-PI-A model, we found that the quality of information output can increase without necessarily having a corresponding increase in the quantity of data input.
The remainder of this article is organized as follows: in
Section 2, the main case of analysis, an application form is presented. Then, in
Section 3, the CD-PI-A model is developed. In
Section 4, the results, and its respective discussions are presented. Finally, in
Section 5, we present our main conclusions and perspectives for further research.
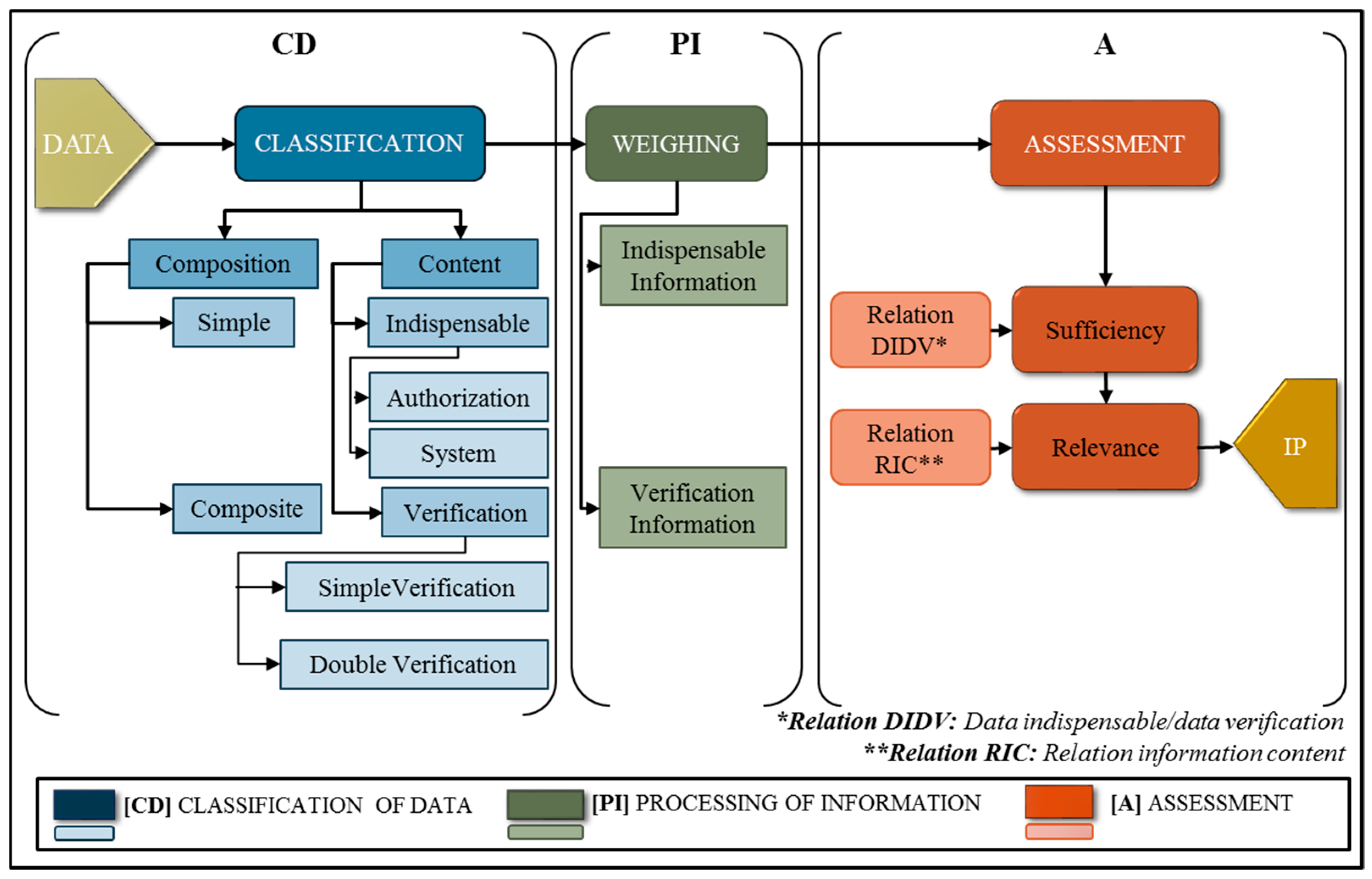
3. Model of Information Quality Assessment: CD-PI-A
The purpose of the model CD-PI-A is to explore the effectiveness of representing the composition of data in information quality assessment. This model is comprised of three phases: (1) classification of data [CD], (2) processing data into information [PI], and (3) assessment of information quality [A], as shown in
Figure 1.
Regarding the CS from the context of the MI approach, it is possible to distinguish three main stages in the data processing: (1) the raw material at the entrance (data); (2) the processing period, where data is transformed into pre-processed information. It is considered to be pre-processed as the information that passes from one phase will be the raw material for the next phase, until the end of the process; and (3) the finished product—the information products obtained at the output of the system.
This model initially considers the distinction between the data and information concepts. Here, data has been defined as a string of elementary symbols [
24] that can be linked to a meaning related to communication and can be manipulated, operated, and processed [
25], and information [
26,
27] has been defined as a coherent collection of data, messages, or signs, organized in a certain way that has meaning in a specific human system [
28]. In addition, we assume that (1) the communication system works technically well, (2) the office document referred to is a form that belongs to an administrative process, (3) this form is the communication channel in the simplest information system (see reference [
29]), and (4) the form flows inside an organization according to its objectives and policies.
4. Results and Discussion
Once the data were classified and organized according to their composition and content (
Table 3), the
was assigned. In form F1–00, two redundant fields were detected. This was possibly due to the structure and organization of the form; the two fields were student ID and employee ID. For our analysis, these two fields were in one instance considered as indispensable data and the rest of the time as double verification data, as it was required only once to carry out the processing.
As shown in
Table 3, in F1–00 there are six indispensable
du and 26 verification
du, which leads to a DIDV 1:4.33 ratio. This is to say, that for each indispensable data that is requested, there are four data units used to verify it. The current structure and design of the form contributes to the generation of data overload in the information manufacturing system. In this case, the data quality attribute of sufficiency is, consequently, not achieved. Unless a security information criterion exists, this relation can be improved by making the relation between different factors shorter. If a security information aspect is not what led to this ratio of 1:4.33, it is necessary to consider form re-engineering in the structure and field composition to request such data. If the organization continues to use the present form, it will continue to contribute to data overload problems in the system.
Regarding the RIC relationship, which considers, in addition to the content, the composition that generates this information, the F1–00 form has 0.57 information productss of a verification type (IVacc), and 0.43 information productss of an indispensable type (IIacc). According Equation (9), the RIC is equal to 1.32. Ideally, this value should be equal to or less than 1, because the form should request the same amount or less verification information than that of the indispensable type. This relationship works as an indicator of the relevant information content in the CS.
Due to the results of both relationships, it strongly recommended that the form is re-designed. In this case, we present an alternative.
4.1. Re-Engineering
As the proceedings for the F1–00 did not establish any set-points regarding extreme security concerns about data gathering, following the document processor’s recommendations, we propose a new design for this form. The new design was called F1–01, which is comprised of three main sections: (I) identification, (II) status, and (III) authorization; five fewer sections than the original. Furthermore, the new form is comprised of 16 fields in total.
If the document is chosen to be computerized, then the fields are proposed as drop-down menus. If it is chosen to be in paper format, multiple-option questions are proposed. At a data unit level, in an efficiency assessment we would get a higher value simply by reducing the amount of du. At an information product level, due to its contextual aspect, it is necessary to follow the DC-PI-A model in order to assess its quality. Once the results are obtained, it is possible to observe the impact of representing the du composition in the assessment of the information quality.
Table 4 shows the data classification and its corresponding transformation into information for the F1–01. A total of 100% of the
du in the F1–00 form was taken as a reference to calculate the F1–01 form.
As shown in
Table 4, in the F1–01 form, five
dus correspond to indispensable data. These represent 16% (31% of 50%) of the content that was retained in the document. The 11 remaining
dus represent 34% (69% of 50%) of the same. In the case of the information products, 58% of the preserved fields represent indispensable information, while 42% remained as verification information.
With the new streamlining of the form, it is possible to (1) reduce the data requested, (2) enhance the information quality produced, and (3) improve the efficiency of the CS. This finding, while preliminary, suggests that a reduction of data does not necessarily mean an improvement in quality of information but a change in the composition of the dus do. Additionally, this implies that the quality of information output can increase without necessitating a corresponding increase in the quantity of the data input.
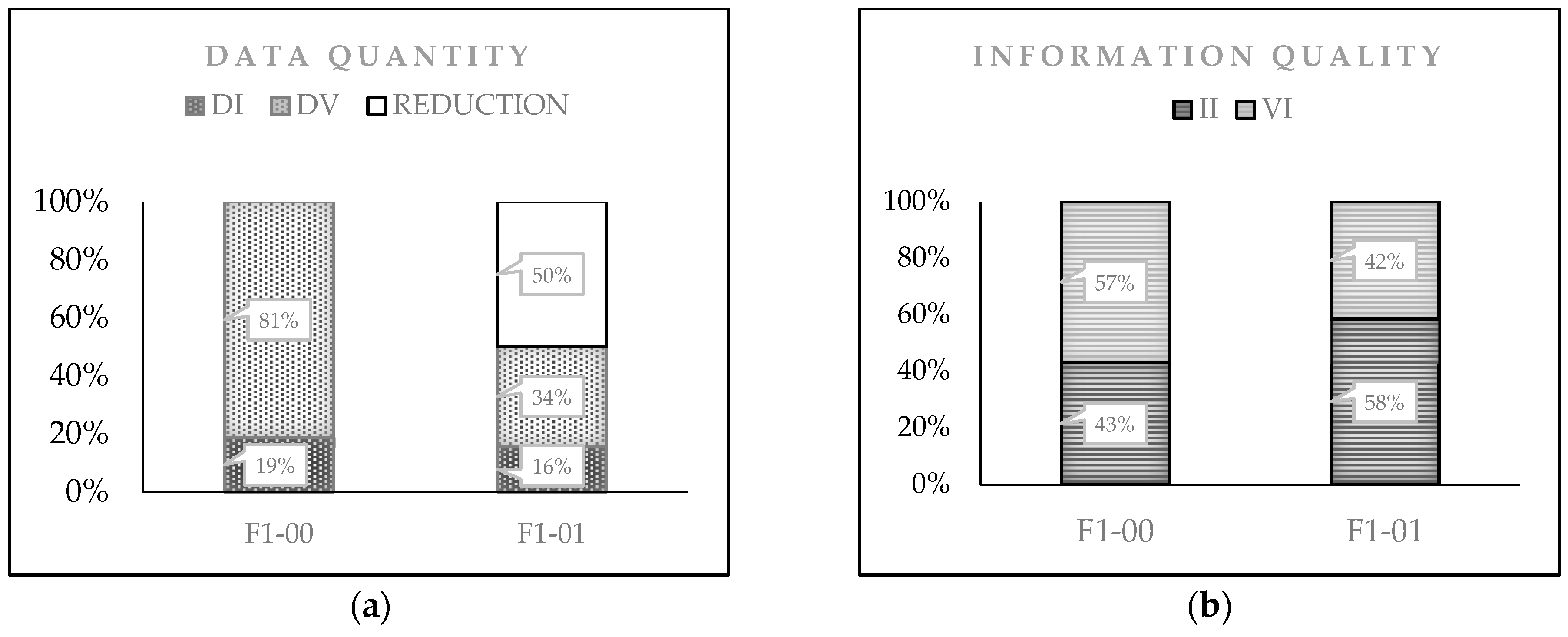
As shown in
Figure 2, the inbound
du amount into the system was reduced by 50% in the F1–01 form. This reduction was achieved due to the four major modifications made to the document. In the first place, the redundant fields were eliminated: in the F1–00 form, there were eight different fields asking for the same
du type. In the second place, in the F1–00 form two
dus that were considered as indispensable and simple data (first name and last name) were merged in the F1–01 form, becoming only one indispensable composed
du. The way to convert these
du from simple to composite (2
Ds times w) was by writing in the same field (with a low ink saturation) the format in which it is expected to become the new
du (last name/first name). In the third place, the computerization of the document considers the possibility of using drop-down menus to select a choice among those already established. The F1–01 form has fewer open fields and more multiple-option fields. Finally, in the fourth place, as a consequence of this type of menu, now there are more explanatory texts that attempt to clarify and specify to the user the requested
du.
With regard to the two proposed relationships (DIDV and RIC) to evaluate the
du input and information output (see
Table 5), we can mention the following.
First, the DIDV relation for the F1–00 is equal to 1:4.33 and, for F1–01, this same relation is equal to 1:2.2. In the current study, comparing both results shows that with the new streamlining of the form, the ratio was cut in half. This new design of the form uses only two fields to verify every one. This certainly leads to an improvement in the efficiency of the organization’s information system.
Second, for the RIC ratio, the result for the F1–00 form was 1.32 and the result for the F1–01 was 0.71. Due to the proposed re-engineering, the RIC ratio for the F1–01 is less than 1. This means that there was less information to verify than indispensable information to achieve the process.
The difference in percentage points of the relevant (or indispensable) information quality between the F1–00 and F1–01 forms was 15 points (43% versus 58%). Accordingly, we can infer that the information quality was improved by 15%. What is most interesting is that we pursued the same objective with both forms (the F1–00 and F1–01); both forms achieved the same purpose and captured the same content information and, yet, the second form contained a smaller amount of data and, therefore, a better quality of information.
Below is presented another applicability case where the requested fields have a different characterization in their classification.
5. Conclusions
The present study was designed to explore the effectiveness of representing data as composite entities rather than indivisible blocks in the manufacturing of information domain, in order to assess the quality of information produced.
In order to evaluate this effectiveness, the authors opted to integrate a communication system vision into the manufacturing information approach in order to establish a new data classification method that considered the context in which this information was produced.
Based on this approach, a new model to evaluate the information product quality was developed: the DC-PI-A model. This model uses three stages: data classification (DC), processing of data into information (PI), and quality assessment (A). In the first stage, data are classified according to their usefulness and composition. In the second stage, the previous classification data are weighted in order to process them. In the third stage, in order to conduct the assessment, two relationships are proposed. These relationships work as indicators of the attributes mentioned below.
The relationship DIDV works as an indicator of the sufficiency of the input data. In an investigation, with the application of this relationship and the new streamlining of a form, 50% of the input data to a system was reduced. The relationship RIC works as an indicator of relevance of information output of the system. In our case, the comparison between the original form F1–00 and the re-designed form F1–01 showed that the quality of information, in relation to its relevance, could be improved by 15%.
We pursued the same objective with different forms (F1–00 and F1–01), where both forms achieved the same purpose and captured the same information content, yet the second form contained a smaller amount of data and, therefore, had better quality of information. Additionally, it was shown that by using more composite type data (FIAP–00) it can be possible to have higher information quality channels within the CS.
The results of this investigation show that both the content and the composition of data (among other factors) are important aspects of determining the value of the information; value that, in the end, will have an impact on the quality of the whole communication and information system. We found that the relation between data quantification and information quality evaluation is not just a “simple” positive correlation. The quality of information output can increase without there necessarily being any corresponding increase in the quantity of the data input.
This new representation and model for evaluating data and information should help to highlight the necessity of consistent use of data and information terminology. In the information era, it is not possible to continue to use these two terms as synonyms. Once delimiting this distinction, users can treat their data in a more conscious and responsible way.
This study shows that the attributes already established should be considered as a new classification. This new classification should be applied at the moment of the process when the analysis is made. If it is at the beginning of the process, the entities must be treated as data and have to be evaluated with data quality attributes (in this case, sufficiency). If it is at the exit of the system, the entities must be treated as information and have to be evaluated with an information quality attribute (in this case, relevance).
Additionally, this study has raised important questions about the nature of the design of forms. This should be a matter of content more than an aesthetic issue. Inside an organization, the forms should respond to the particular business requirements, where the context determines the meaning.
The scope of this study was limited to exploring only two attributes of quality: sufficiency and relevance. Further work will need to be done to determine more accurate information values from this same approach. We wish to include other attributes, such as accuracy, completeness, or timeliness. Additionally, including the syntactic and pragmatic levels of information would be valuable. Likewise, as one external reviewer suggested, the inter-connection between the DB concept, here presented, and the data granularity linked with different types of documents may be of interest.
The findings of this study have a number of practical implications in the field of information management. One example of these implications would be the development of new methodologies to evaluate the IQ. These methodologies could be converted into tools for business management. These tools would be used to design better forms that gather useful and sufficient data. All these changes would lead us, in general, to have more efficient and environmentally friendly information manufacturing systems.
We hope our study exploring the effectiveness of representing data as composite units will introduce some guidelines for further research and will inspire new investigations in the same field but at a more detailed level.



{kind=link}
{kind=link}